The evolution of cluster interaction. How we implemented ActiveMQ and Hazelcast
Over the past 7 years, together with the team, I have been supporting and developing the core of the Miro product (ex-RealtimeBoard): client-server and cluster interaction, working with the database.
We have Java with different libraries on board. Everything is launched outside the container, through the Maven plugin. It is based on the platform of our partners, which allows us to work with the database and flows, manage client-server interaction, etc. DB - Redis and PostgreSQL (my colleague wrote about how we move from one database to another ).
In terms of business logic, the application contains:
In 2011, when we were just starting, the whole Miro was on the same server. Everything was on it: Nginx on which php for a site turned, a Java application and databases.
The product developed, the number of users and the content that they added to the boards grew, so the load on the server also grew. Due to the large number of applications on our server, at that moment we could not understand what exactly gives the load and, accordingly, could not optimize it. To fix this, we split everything into different servers, and we got a web server, a server with our application and database server.
Unfortunately, after some time, problems arose again, as the load on the application continued to grow. Then we thought about how to scale the infrastructure.

Next, I’ll talk about the difficulties that we encountered in developing clusters and scaling Java applications and infrastructure.
We started by collecting metrics: the use of memory and CPU, the time it takes to execute user queries, the use of system resources, and working with the database. From the metrics, it was clear that the generation of user resources was an unpredictable process. We can load the processor 100% and wait tens of seconds until everything is done. User requests for boards also sometimes gave an unexpected load. For example, when a user selects a thousand widgets and begins to move them spontaneously.
We began to think about how to scale these parts of the system and came to obvious solutions.
Scale work with boards and content. The user opens the board like this: the user opens the client → indicates which board he wants to open → connects to the server → a stream is created on the server → all users of this board connect to one stream → any change or creation of the widget occurs within this stream. It turns out that all work with the board is strictly limited by the flow, which means we can distribute these flows between the servers.
Scale user resource generation . We can take out the server to generate resources separately, and it will receive messages for generation, and then respond that everything is generated.
Everything seems to be simple. But as soon as we began to study this topic more deeply, it turned out that we needed to additionally solve some indirect problems. For example, if a paid subscription expires for users, then we must notify them of this, no matter on which board they are. Or, if the user has updated the version of the resource, you need to make sure that the cache is correctly flushed on all servers and we give the right version.
We have identified system requirements. The next step is to understand how to put this into practice. In fact, we needed a system that would allow the servers in the cluster to communicate with each other and based on which we would realize all our ideas.
We did not choose the first version of the system, because it was already partially implemented in the partner platform that we used. In it, all servers were connected to each other via TCP, and using this connection we could send RPC messages to one or all servers at once.
For example, we have three servers, they are connected to each other via TCP, and in Redis we have a list of these servers. We start a new server in the cluster → it adds itself to the list in Redis → reads the list to find out about all the servers in the cluster → connects to all.
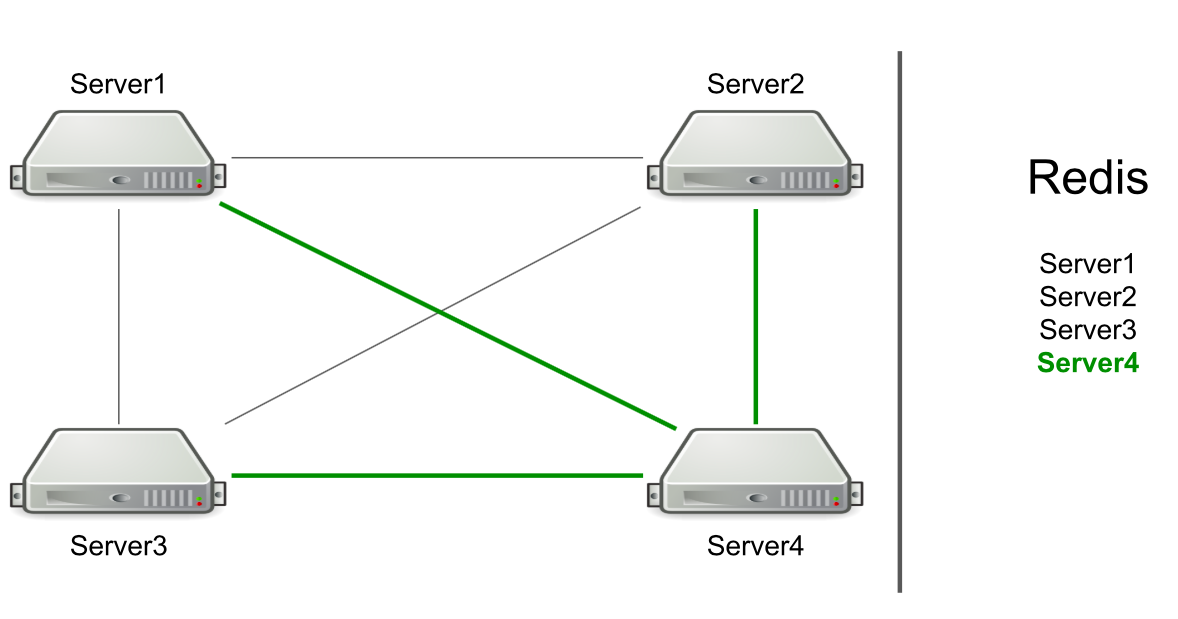
Based on RPC, support for flushing the cache and redirecting users to the desired server has already been implemented. We had to do a generation of user resources and notify users that something had happened (for example, an account had expired). To generate resources, we chose an arbitrary server and sent him a request for generation, and for notifications about the expiration of a subscription, we sent a command to all servers in the hope that the message would reach the goal.
It sounds like a feature, not a problem. But the server focuses only on the connection to another server. If there are connections, then there is a candidate for sending a message.
The problem is that server number 1 does not know that server number 4 is under high load right now and cannot answer it quickly enough. As a result, server # 1 requests are processed more slowly than they could.
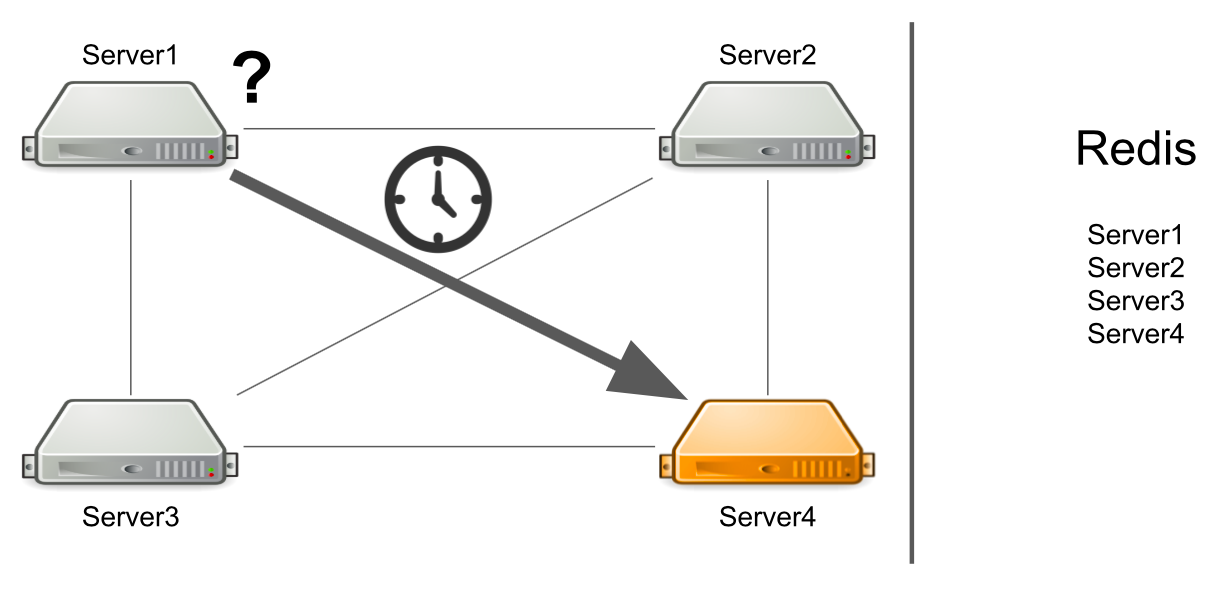
But what if the server is not just heavily loaded, but generally freezes? Moreover, it hangs so that it no longer comes to life. For example, I have exhausted all available memory.
In this case, server # 1 does not know what the problem is, so it continues to wait for an answer. The remaining servers in the cluster also do not know about the situation with server No. 4, so they will send a lot of messages to server No. 4 and wait for a response. So it will be until server number 4 dies.
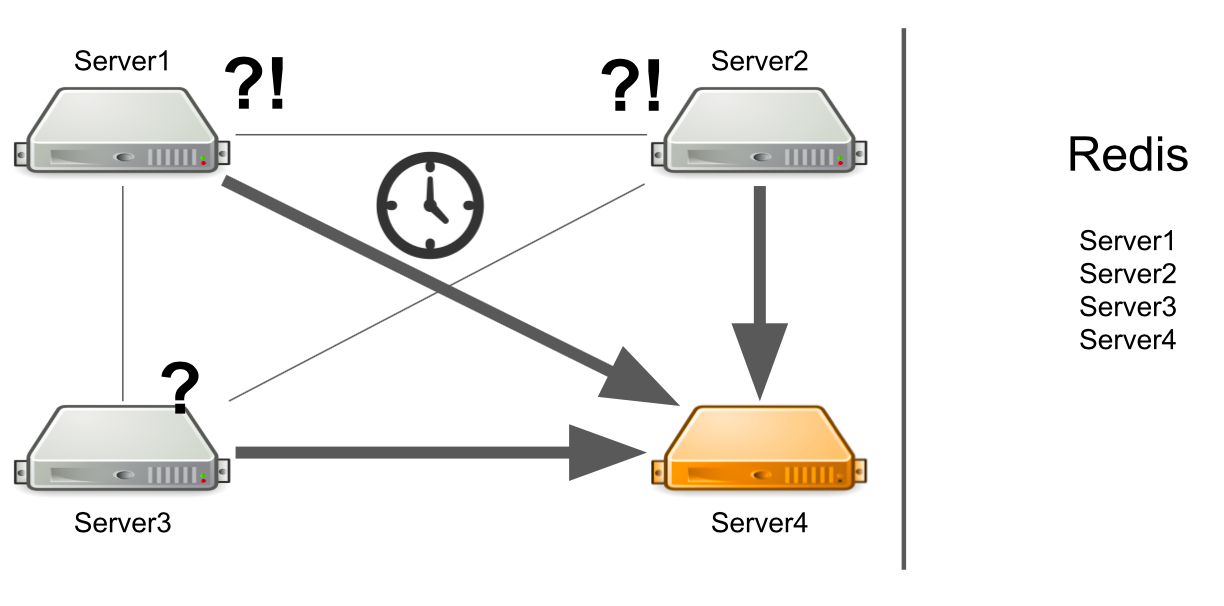
What to do? We can independently add a server status check to the system. Or we can redirect messages from “sick” servers to “healthy” ones. All this will take too much developers time. In 2012, we had little experience in this area, so we started looking for ready-made solutions to all our problems at once.
We decided to go towards Message broker in order to correctly configure communication between the servers. They chose ActiveMQ because of the ability to configure receiving messages on consumer at a certain time. True, we never took this opportunity, so we could choose RabbitMQ, for example.
As a result, we transferred our entire cluster system to ActiveMQ. What it gave:
The scheme looks simple: all servers are connected to the broker, and it controls communication between them. Everything works, messages are sent and received, resources are created. But there are new problems.
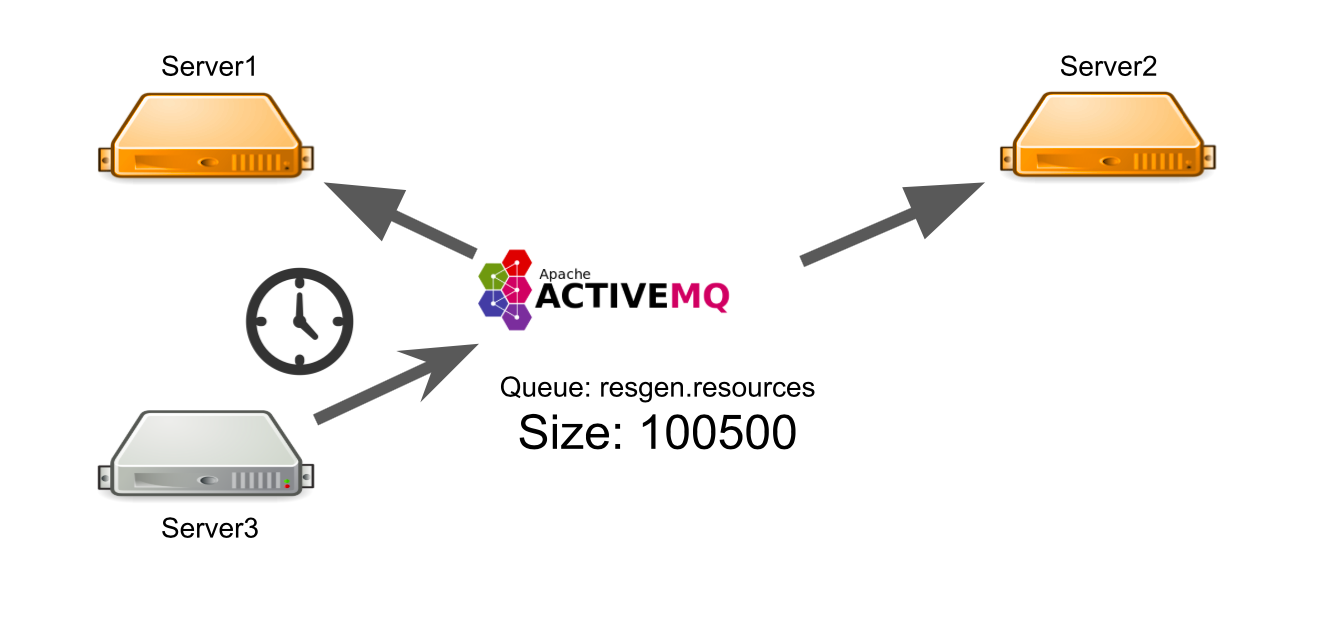
Let's say server # 3 wants to send a message to generate resources in a queue. He expects his message to be processed. But he does not know that for some reason there is not a single recipient of the message. For example, recipients crashed due to an error.
For all the waiting time, the server sends a lot of messages with a request, which is why a queue of messages appears. Therefore, when working servers appear, they are forced to first process the accumulated queue, which takes time. On the user’s side, this leads to the fact that the image uploaded by him does not appear immediately. He is not ready to wait, so he leaves the board.
As a result, we spend server capacity on the generation of resources, and no one needs the result.
How can I solve the problem? We can set up monitoring, which will notify you of what is happening. But from the moment when the monitoring reports something, until the moment when we understand that our servers are bad, time will pass. This does not suit us.
Another option is to run Service Discovery, or a registry of services that will know which servers with which roles are running. In this case, we will immediately receive an error message if there are no free servers.
This is a problem of our early code, not ActiveMQ. Let me show you an example:
We have a service for working with user rights on the board: the user can be the owner of the board or its editor. There can be only one owner at the board. Suppose we have a scenario where we want to transfer ownership of a board from one user to another. On the first line we get the current owner of the board, on the second - we take the user who was the editor, and now becomes the owner. Further, the current owner we put the role of EDITOR, and the former editor - the role of OWNER.
Let's see how this will work in a multi-threaded environment. When the first thread establishes the EDITOR role and the second thread tries to take the current OWNER, it may turn out like this - OWNER does not exist, but there are two EDITOR.
The reason is the lack of synchronization. We can solve the problem by adding a synchronize block on the board.
This solution will not work in the cluster. The SQL database could help us with this with the help of transactions. But we have Redis.
Another solution is to add distributed locks to the cluster so that synchronization is inside the entire cluster, and not just one server.
The model of interaction between the client and server is stateful. So we must store the state of the board on the server. Therefore, we made a separate role for servers - BoardServer, which handles user requests related to boards.
Imagine that we have three BoardServer, one of which is the main one. The user sends him the request “Open me the board with id = 123” → the server looks in its database whether the board is open and on which server it is. In this example, the board is open.
The main server responds that you need to connect to server No. 1 → the user is connecting. Obviously, if the main server dies, then the user will no longer be able to access new boards.
Then why do we need a server that knows where the boards are open? So that we have a single point of decision. If something happens to the servers, we need to understand if the board is actually available in order to remove the board from the registry or reopen somewhere else. It would be possible to organize this with the help of a quorum, when several servers solve a similar problem, but at that time we did not have the knowledge to independently implement the quorum.
One way or another, we coped with the problems that arose, but it may not be the most beautiful way. Now we needed to understand how to solve them correctly, so we formulated a list of requirements for a new cluster solution:
It was the year 2015. We opted for Hazelcast - In-Memory Data Grid, a cluster system for storing information in RAM. Then we thought that we had found a miracle solution, the holy grail of the world of cluster interaction, a miracle framework that can do everything and combines distributed data structures, locks, RPC messages and queues.
As with ActiveMQ, we transferred almost everything to Hazelcast:
Hazelcast can be configured in two topologies. The first option is Client-Server, when members are located separately from the main application, they themselves form a cluster, and all applications connect to them as a database.
The second topology is Embedded, when Hazelcast members are embedded in the application itself. In this case, we can use fewer instances, data access is faster, because the data and the business logic itself are in the same place.
We chose the second solution because we considered it more effective and economical to implement. Effective, because the speed of accessing Hazelcast data will be lower, because perhaps this data is on the current server. Economical, because we do not need to spend money on additional instances.
A couple of weeks after turning on Hazelcast, problems appeared on the prod.
At first, our monitoring showed that one of the servers began to gradually overload memory. While we were watching this server, the rest of the servers started to load too: the CPU grew, then the RAM, and after five minutes all the servers used all available memory.
At this point in the consoles we saw these messages:
Here, Hazelcast checks to see if the operation that was sent to the first “dying” server is in progress. Hazelcast tried to keep abreast and checked the status of the operation several times per second. As a result, he spammed all the other servers with this operation, and after a few minutes they flew out of memory, and we collected several GB of logs from each of them.
The situation was repeated several times. It turned out that this is a bug in Hazelcast version 3.5, in which the heartbeating mechanism was implemented, which checks the status of requests. It did not check some of the boundary cases that we encountered. I had to optimize the application so as not to fall into these cases, and after a few weeks Hazelcast fixed the error at home.
The next issue we discovered is adding and removing members from Hazelcast.
First, I’ll briefly describe how Hazelcast works with partitions. For example, there are four servers, and each one stores some part of the data (in the figure they are of different colors). The unit is the primary partition, the deuce is the secondary partition, i.e. backup of the main partition.

When a server is turned off, partitions are sent to other servers. In case the server dies, partitions are transferred not from it, but from those servers which are still alive and keep a backup of these partitions.
This is a reliable mechanism. The problem is that we often turn servers on and off to balance the load, and rebalancing partitions also takes time. And the more servers are running and the more data we store in Hazelcast, the more time it takes to re-balance partitions.
Of course, we can reduce the number of backups, i.e. secondary partitions. But this is not safe, as something will definitely go wrong.
Another solution is to switch to Client-Server topology so that turning servers on and off does not affect the core Hazelcast cluster. We tried to do this, and it turned out that RPC requests cannot be performed on clients. Let's see why.
To do this, consider the example of sending one RPC request to another server. We take the ExecutorService, which allows you to send RPC messages, and do submit with a new task.
The task itself looks like a regular Java class that implements Callable.
The problem is that Hazelcast clients can be not only Java applications, but also C ++ applications, .NET and others. Naturally, we cannot generate and convert our Java class to another platform.
One option is to switch to using http-requests in case we want to send something from one server to another and get an answer. But then we will have to partially abandon Hazelcast.
Therefore, as a solution, we chose to use queues instead of ExecutorService. To do this, we independently implemented a mechanism for waiting for an element to be executed in the queue, which processes boundary cases and returns the result to the requesting server.
Lay flexibility in the system. The future is constantly changing, so there are no perfect solutions. It will not work out right “right”, but you can try to be flexible and put it into the system. This allowed us to put off important architectural decisions until the moment when it is no longer impossible to accept them.
Robert Martin in Clean Architecture writes about this principle:
Universal tools and solutions do not exist. If it seems to you that some framework solves all your problems, then most likely this is not so. Therefore, when implementing any framework, it is important to understand not only what problems it will solve, but which ones it will bring along with it.
Do not immediately rewrite everything.If you are faced with a problem in architecture and it seems that the only right solution is to write everything from scratch, wait. If the problem is really serious, find a quick fix and watch how the system will work in the future. Most likely, this will not be the only problem in architecture, with time you will find more. And only when you pick up a sufficient number of problem areas can you start refactoring. Only in this case there will be more advantages from it than its value.
We have Java with different libraries on board. Everything is launched outside the container, through the Maven plugin. It is based on the platform of our partners, which allows us to work with the database and flows, manage client-server interaction, etc. DB - Redis and PostgreSQL (my colleague wrote about how we move from one database to another ).
In terms of business logic, the application contains:
- work with custom boards and their content;
- functionality for user registration, creation and management of boards;
- custom resource generator. For example, it optimizes large images uploaded to the application so that they do not slow down on our clients;
- many integrations with third-party services.
In 2011, when we were just starting, the whole Miro was on the same server. Everything was on it: Nginx on which php for a site turned, a Java application and databases.
The product developed, the number of users and the content that they added to the boards grew, so the load on the server also grew. Due to the large number of applications on our server, at that moment we could not understand what exactly gives the load and, accordingly, could not optimize it. To fix this, we split everything into different servers, and we got a web server, a server with our application and database server.
Unfortunately, after some time, problems arose again, as the load on the application continued to grow. Then we thought about how to scale the infrastructure.
Next, I’ll talk about the difficulties that we encountered in developing clusters and scaling Java applications and infrastructure.
Scale infrastructure horizontally
We started by collecting metrics: the use of memory and CPU, the time it takes to execute user queries, the use of system resources, and working with the database. From the metrics, it was clear that the generation of user resources was an unpredictable process. We can load the processor 100% and wait tens of seconds until everything is done. User requests for boards also sometimes gave an unexpected load. For example, when a user selects a thousand widgets and begins to move them spontaneously.
We began to think about how to scale these parts of the system and came to obvious solutions.
Scale work with boards and content. The user opens the board like this: the user opens the client → indicates which board he wants to open → connects to the server → a stream is created on the server → all users of this board connect to one stream → any change or creation of the widget occurs within this stream. It turns out that all work with the board is strictly limited by the flow, which means we can distribute these flows between the servers.
Scale user resource generation . We can take out the server to generate resources separately, and it will receive messages for generation, and then respond that everything is generated.
Everything seems to be simple. But as soon as we began to study this topic more deeply, it turned out that we needed to additionally solve some indirect problems. For example, if a paid subscription expires for users, then we must notify them of this, no matter on which board they are. Or, if the user has updated the version of the resource, you need to make sure that the cache is correctly flushed on all servers and we give the right version.
We have identified system requirements. The next step is to understand how to put this into practice. In fact, we needed a system that would allow the servers in the cluster to communicate with each other and based on which we would realize all our ideas.
The first cluster out of the box
We did not choose the first version of the system, because it was already partially implemented in the partner platform that we used. In it, all servers were connected to each other via TCP, and using this connection we could send RPC messages to one or all servers at once.
For example, we have three servers, they are connected to each other via TCP, and in Redis we have a list of these servers. We start a new server in the cluster → it adds itself to the list in Redis → reads the list to find out about all the servers in the cluster → connects to all.
Based on RPC, support for flushing the cache and redirecting users to the desired server has already been implemented. We had to do a generation of user resources and notify users that something had happened (for example, an account had expired). To generate resources, we chose an arbitrary server and sent him a request for generation, and for notifications about the expiration of a subscription, we sent a command to all servers in the hope that the message would reach the goal.
The server itself determines to whom to send the message.
It sounds like a feature, not a problem. But the server focuses only on the connection to another server. If there are connections, then there is a candidate for sending a message.
The problem is that server number 1 does not know that server number 4 is under high load right now and cannot answer it quickly enough. As a result, server # 1 requests are processed more slowly than they could.
The server does not know that the second server is frozen
But what if the server is not just heavily loaded, but generally freezes? Moreover, it hangs so that it no longer comes to life. For example, I have exhausted all available memory.
In this case, server # 1 does not know what the problem is, so it continues to wait for an answer. The remaining servers in the cluster also do not know about the situation with server No. 4, so they will send a lot of messages to server No. 4 and wait for a response. So it will be until server number 4 dies.
What to do? We can independently add a server status check to the system. Or we can redirect messages from “sick” servers to “healthy” ones. All this will take too much developers time. In 2012, we had little experience in this area, so we started looking for ready-made solutions to all our problems at once.
Message broker. Activemq
We decided to go towards Message broker in order to correctly configure communication between the servers. They chose ActiveMQ because of the ability to configure receiving messages on consumer at a certain time. True, we never took this opportunity, so we could choose RabbitMQ, for example.
As a result, we transferred our entire cluster system to ActiveMQ. What it gave:
- The server no longer decides for itself to whom to send the message, because all messages go through the queue.
- Configured fault tolerance. To read the queue, you can run not one, but several servers. Even if one of them falls, the system will continue to work.
- The servers appeared roles, which allowed to divide the server by type of load. For example, a resource generator can only connect to a queue for reading messages to generate resources, and a server with boards can connect to a queue for opening boards.
- Did RPC communication, i.e. each server has its own private queue where other servers send events to it.
- You can send messages to all servers through Topic, which we use to reset subscriptions.
The scheme looks simple: all servers are connected to the broker, and it controls communication between them. Everything works, messages are sent and received, resources are created. But there are new problems.
What to do when all the necessary servers are lying?
Let's say server # 3 wants to send a message to generate resources in a queue. He expects his message to be processed. But he does not know that for some reason there is not a single recipient of the message. For example, recipients crashed due to an error.
For all the waiting time, the server sends a lot of messages with a request, which is why a queue of messages appears. Therefore, when working servers appear, they are forced to first process the accumulated queue, which takes time. On the user’s side, this leads to the fact that the image uploaded by him does not appear immediately. He is not ready to wait, so he leaves the board.
As a result, we spend server capacity on the generation of resources, and no one needs the result.
How can I solve the problem? We can set up monitoring, which will notify you of what is happening. But from the moment when the monitoring reports something, until the moment when we understand that our servers are bad, time will pass. This does not suit us.
Another option is to run Service Discovery, or a registry of services that will know which servers with which roles are running. In this case, we will immediately receive an error message if there are no free servers.
Some services cannot be scaled horizontally
This is a problem of our early code, not ActiveMQ. Let me show you an example:
Permission ownerPermission = service.getOwnerPermission(board);
Permission permission = service.getPermission(board,user);
ownerPermission.setRole(EDITOR);
permission.setRole(OWNER);
We have a service for working with user rights on the board: the user can be the owner of the board or its editor. There can be only one owner at the board. Suppose we have a scenario where we want to transfer ownership of a board from one user to another. On the first line we get the current owner of the board, on the second - we take the user who was the editor, and now becomes the owner. Further, the current owner we put the role of EDITOR, and the former editor - the role of OWNER.
Let's see how this will work in a multi-threaded environment. When the first thread establishes the EDITOR role and the second thread tries to take the current OWNER, it may turn out like this - OWNER does not exist, but there are two EDITOR.
The reason is the lack of synchronization. We can solve the problem by adding a synchronize block on the board.
synchronized (board) {
Permission ownerPermission = service.getOwnerPermission(board);
Permission permission = service.getPermission(board,user);
ownerPermission.setRole(EDITOR);
permission.setRole(OWNER);
}
This solution will not work in the cluster. The SQL database could help us with this with the help of transactions. But we have Redis.
Another solution is to add distributed locks to the cluster so that synchronization is inside the entire cluster, and not just one server.
A single point of failure when entering the board
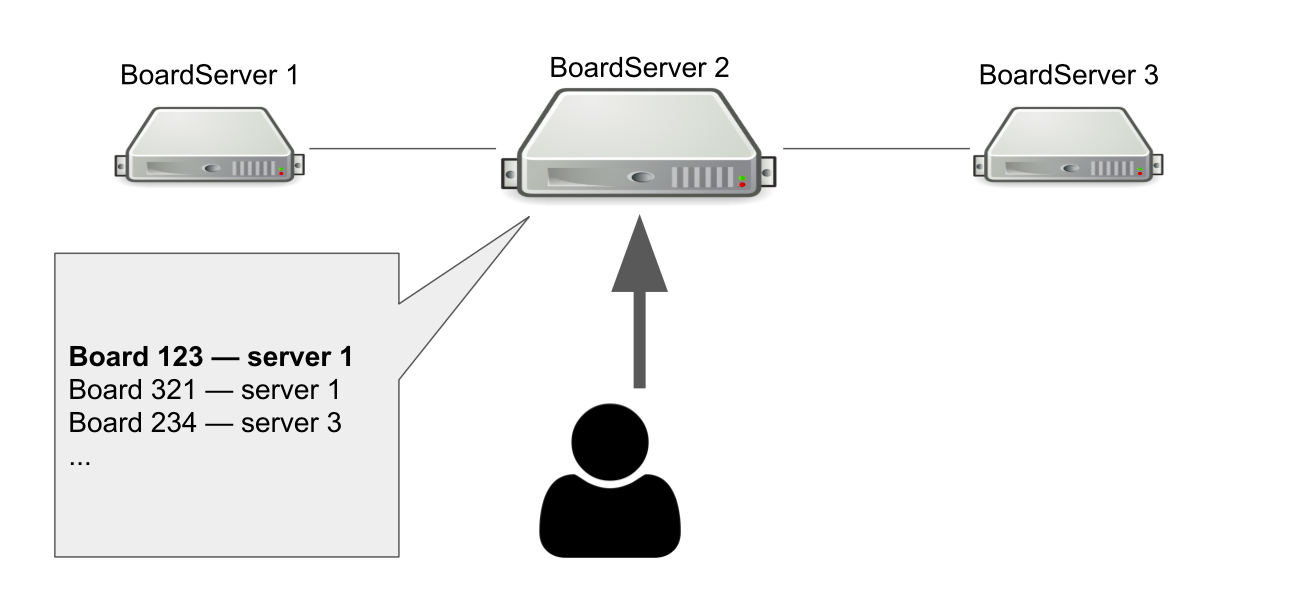
The model of interaction between the client and server is stateful. So we must store the state of the board on the server. Therefore, we made a separate role for servers - BoardServer, which handles user requests related to boards.
Imagine that we have three BoardServer, one of which is the main one. The user sends him the request “Open me the board with id = 123” → the server looks in its database whether the board is open and on which server it is. In this example, the board is open.
The main server responds that you need to connect to server No. 1 → the user is connecting. Obviously, if the main server dies, then the user will no longer be able to access new boards.
Then why do we need a server that knows where the boards are open? So that we have a single point of decision. If something happens to the servers, we need to understand if the board is actually available in order to remove the board from the registry or reopen somewhere else. It would be possible to organize this with the help of a quorum, when several servers solve a similar problem, but at that time we did not have the knowledge to independently implement the quorum.
Switch to Hazelcast
One way or another, we coped with the problems that arose, but it may not be the most beautiful way. Now we needed to understand how to solve them correctly, so we formulated a list of requirements for a new cluster solution:
- We need something that will monitor the status of all servers and their roles. Call it Service Discovery.
- We need cluster locks that will help ensure consistency when executing dangerous queries.
- We need a distributed data structure that will ensure that the boards are on certain servers and inform if something went wrong.
It was the year 2015. We opted for Hazelcast - In-Memory Data Grid, a cluster system for storing information in RAM. Then we thought that we had found a miracle solution, the holy grail of the world of cluster interaction, a miracle framework that can do everything and combines distributed data structures, locks, RPC messages and queues.
As with ActiveMQ, we transferred almost everything to Hazelcast:
- generation of user resources through ExecutorService;
- distributed lock when changing rights;
- roles and attributes of servers (Service Discovery);
- a single registry of open boards, etc.
Hazelcast Topologies
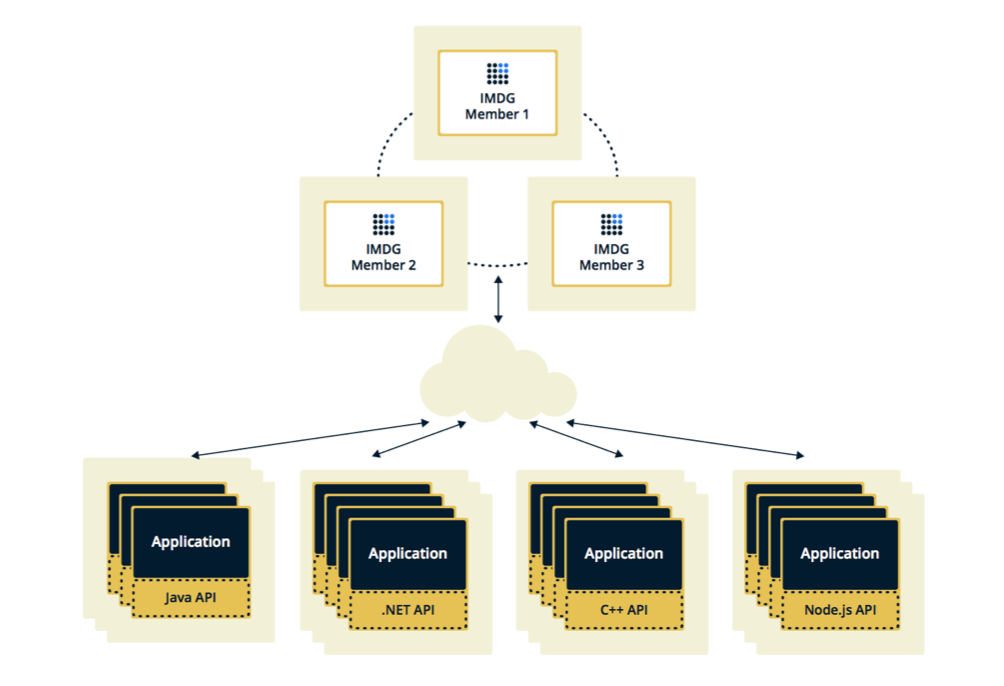
Hazelcast can be configured in two topologies. The first option is Client-Server, when members are located separately from the main application, they themselves form a cluster, and all applications connect to them as a database.
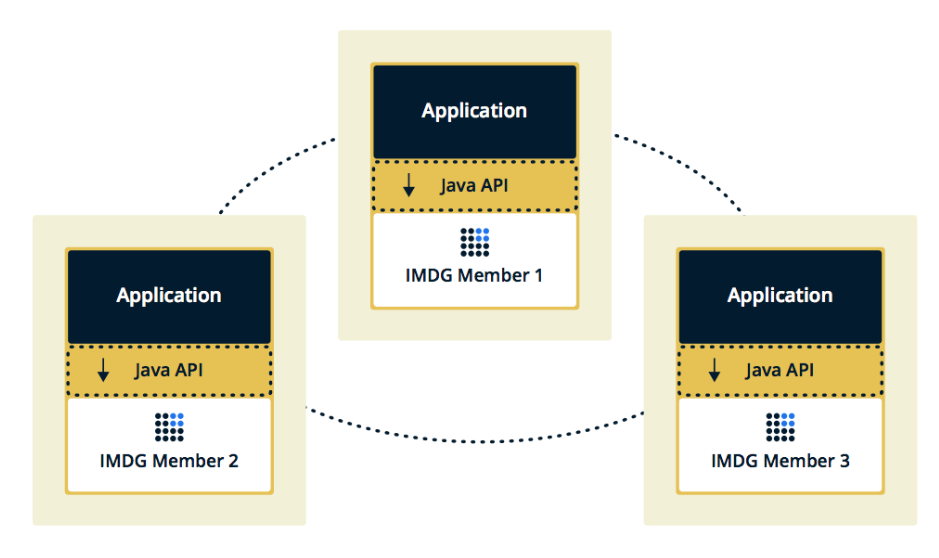
The second topology is Embedded, when Hazelcast members are embedded in the application itself. In this case, we can use fewer instances, data access is faster, because the data and the business logic itself are in the same place.
We chose the second solution because we considered it more effective and economical to implement. Effective, because the speed of accessing Hazelcast data will be lower, because perhaps this data is on the current server. Economical, because we do not need to spend money on additional instances.
Cluster hangs when member hangs
A couple of weeks after turning on Hazelcast, problems appeared on the prod.
At first, our monitoring showed that one of the servers began to gradually overload memory. While we were watching this server, the rest of the servers started to load too: the CPU grew, then the RAM, and after five minutes all the servers used all available memory.
At this point in the consoles we saw these messages:
2015-07-1515:35:51,466 [WARN] (cached18)
com.hazelcast.spi.impl.operationservice.impl.Invocation:
[my.host.address.com]:5701 [dev] [3.5] Asking ifoperation execution has been started: com.hazelcast.spi.impl.operationservice.impl.IsStillRunningService$InvokeIsStillRunningOperationRunnable@6d4274d7
2015-07-1515:35:51,467 [WARN] (hz._hzInstance_1_dev.async.thread-3) com.hazelcast.spi.impl.operationservice.impl.Invocation:[my.host.address.com]:5701 [dev] [3.5] 'is-executing': true -> Invocation{ serviceName='hz:impl:executorService',
op=com.hazelcast.executor.impl.operations.MemberCallableTaskOperation{serviceName='null', partitionId=-1, callId=18062, invocationTime=1436974430783,
waitTimeout=-1,callTimeout=60000}, partitionId=-1, replicaIndex=0,
tryCount=250, tryPauseMillis=500, invokeCount=1,
callTimeout=60000,target=Address[my.host2.address.com]:5701, backupsExpected=0, backupsCompleted=0}
Here, Hazelcast checks to see if the operation that was sent to the first “dying” server is in progress. Hazelcast tried to keep abreast and checked the status of the operation several times per second. As a result, he spammed all the other servers with this operation, and after a few minutes they flew out of memory, and we collected several GB of logs from each of them.
The situation was repeated several times. It turned out that this is a bug in Hazelcast version 3.5, in which the heartbeating mechanism was implemented, which checks the status of requests. It did not check some of the boundary cases that we encountered. I had to optimize the application so as not to fall into these cases, and after a few weeks Hazelcast fixed the error at home.
Frequently adding and removing members from Hazelcast
The next issue we discovered is adding and removing members from Hazelcast.
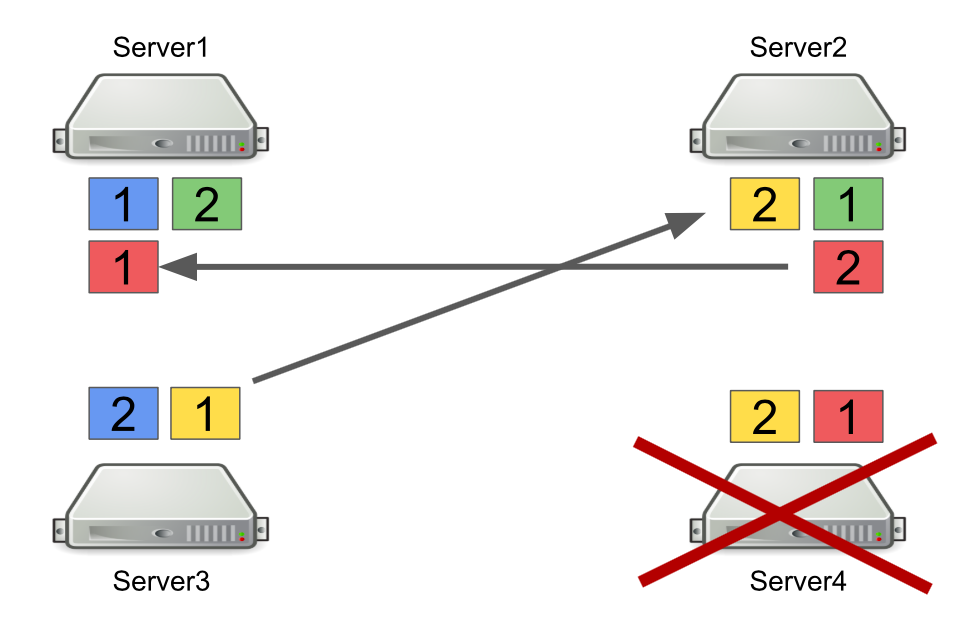
First, I’ll briefly describe how Hazelcast works with partitions. For example, there are four servers, and each one stores some part of the data (in the figure they are of different colors). The unit is the primary partition, the deuce is the secondary partition, i.e. backup of the main partition.
When a server is turned off, partitions are sent to other servers. In case the server dies, partitions are transferred not from it, but from those servers which are still alive and keep a backup of these partitions.
This is a reliable mechanism. The problem is that we often turn servers on and off to balance the load, and rebalancing partitions also takes time. And the more servers are running and the more data we store in Hazelcast, the more time it takes to re-balance partitions.
Of course, we can reduce the number of backups, i.e. secondary partitions. But this is not safe, as something will definitely go wrong.
Another solution is to switch to Client-Server topology so that turning servers on and off does not affect the core Hazelcast cluster. We tried to do this, and it turned out that RPC requests cannot be performed on clients. Let's see why.
To do this, consider the example of sending one RPC request to another server. We take the ExecutorService, which allows you to send RPC messages, and do submit with a new task.
hazelcastInstance
.getExecutorService(...)
.submit(new Task(), ...);
The task itself looks like a regular Java class that implements Callable.
public class Task implements Callable<Long> {
@Override
public Long call() {
return 42;
}
}
The problem is that Hazelcast clients can be not only Java applications, but also C ++ applications, .NET and others. Naturally, we cannot generate and convert our Java class to another platform.
One option is to switch to using http-requests in case we want to send something from one server to another and get an answer. But then we will have to partially abandon Hazelcast.
Therefore, as a solution, we chose to use queues instead of ExecutorService. To do this, we independently implemented a mechanism for waiting for an element to be executed in the queue, which processes boundary cases and returns the result to the requesting server.
What have we learned
Lay flexibility in the system. The future is constantly changing, so there are no perfect solutions. It will not work out right “right”, but you can try to be flexible and put it into the system. This allowed us to put off important architectural decisions until the moment when it is no longer impossible to accept them.
Robert Martin in Clean Architecture writes about this principle:
“The architect’s goal is to create a form for the system that makes politics the most important element, and the details that aren’t political. This will delay and delay decisions about details. ”
Universal tools and solutions do not exist. If it seems to you that some framework solves all your problems, then most likely this is not so. Therefore, when implementing any framework, it is important to understand not only what problems it will solve, but which ones it will bring along with it.
Do not immediately rewrite everything.If you are faced with a problem in architecture and it seems that the only right solution is to write everything from scratch, wait. If the problem is really serious, find a quick fix and watch how the system will work in the future. Most likely, this will not be the only problem in architecture, with time you will find more. And only when you pick up a sufficient number of problem areas can you start refactoring. Only in this case there will be more advantages from it than its value.