Learning concepts through sensorimotor interaction
- Transfer
Thought experiment
Imagine that you are awake in a strange room. This is not a cozy bedroom in which you fell asleep, but a dimly lit chamber with a cold, damp floor. Cracked plaster on the walls. And the only entrance and exit supposedly is a massive iron door, locked with a padlock from the inside. A little higher on the wall is a barred window that lets in a bit of light. If glancing around you would conclude that you are trapped, it would be quite reasonable. It looks awful.
But does it satisfy you? Probably not. You will want to explore the room a little more, perhaps pull the padlock to try out its reliability. Or want to test the strength of these plastered walls. Perhaps a few strong blows and you will make a hole through which you can get out? Or maybe these lattices on the window are so large openings that you can climb out? Interaction with the environment gives you much more information than passive observation of it. Vision may be a hypothesis, but testing it requires real interaction with the environment.
Notion of concepts
Content and conclusion are concepts. The dog is also a concept. Just like running , forest , beauty , green or death . Concepts are abstractions that we distinguish from everyday interaction with the world. They form the reusable building blocks of knowledge that people need to understand the world.
When we have a conceptual understanding of something, it means that we have some experience with this thing, we have somehow mastered it. In the case of content, this experience means that we can identify container objects in the world that can contain something, separate them from “not containers”, put some things inside, take them back, and anticipate what will happen, if we will somehow interact with them. We can even look at new things and understand whether they can potentially contain something in themselves or vice versa — can they be enclosed in some other subject.
The main approaches of conceptual understanding in AI, including deep learning systems, trained on data arrays, like “ ImageNet», Apparently, have some of these abilities, but they lack a deeper understanding - experience, which comes from the interaction. Perceiving an image or even a video, these approaches may be able to determine whether there is a specific type of “container” on it, say a cup, house or bottle, and also determine where the object is in the image. But they will almost certainly fail when faced with a previously unknown type of such an object. A request to put yourself anywhere will meet with such a system only a complete misunderstanding, since it relates the concept of a container object to an array of visual signs, but does not have an active understanding of the term content within something.
Concepts from sensorimotor experience
Henri Poincare was one of the first to emphasize the role of sensorimotor concepts in human understanding. In his book, Science and Hypothesis, he argued that a motionless being could never master the concept of three-dimensional space. More recently, several cognitive scholars have suggested that conceptual representations arise from the integration of perception and action. For example, O'Regan and Noë define sensorimotor experience as “a rule structure defining sensory changes produced by various motor actions,” and passive observation as a “world exploration mode that relies on knowledge of sensorimotor experience.” Noë adds that "concepts are a kind of approach to managing what is around."
Despite the fact that the importance of sensorimotor experience was assessed within the cognitive community, these ideas resulted in only a few specific computational models exploring its role in the formation of concepts. In the article we presented at AAAI-18, we showed a computational model that studies concepts through interaction with the environment.
What we did
We planned to implement and study the two basic abilities that make up the conceptual understanding: the ability to actively discover a concept and the ability to draw conclusions or act on this concept. In addition, we wanted to explore situations in which interactive abilities are more preferable than passive approaches, and to understand how the use of already learned simple concepts can help in learning more complex ones.
We started by developing a special virtual test site for exploring active concepts, an environment that we call PixelWorld (can be found on github). In this world, things are arranged a little easier than in real. This is a discrete two-dimensional field containing a pixel agent and one or more objects of another type, also consisting of pixels (for example, lines, points, or containers).
The agent has a fairly simple implementation: it perceives only the space of 3 × 3 cells around it and can move up, down, left, right, or stop and send some information. Such an implementation requires the study of even the most basic ideas about the world, both the very concept of an object and the concept of interaction concepts. Despite the fact that this may seem like an excessive sensory deprivation, the elimination of rich visual perception allows us to focus on the role of transforming multifaceted behavior into a meaningful view of the world.
We trained agents for two different types of tasks. The first task was to explore the environment and report if the necessary concept was present in the environment. For example, a container. And it was rewarded if the answer was correct. The second task was to take action in relation to this concept. For example, place yourself in this container. This was rewarded if he faithfully fulfilled the task and reported it. For this we used training with reinforcements.
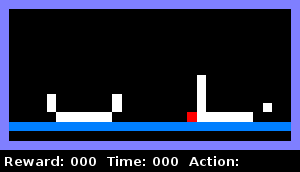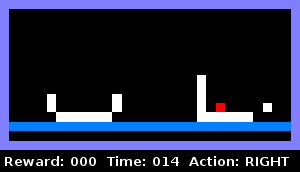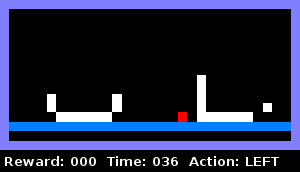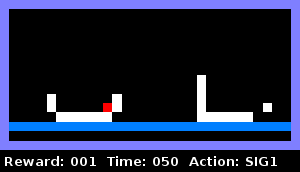
For example, we taught the agent to determine when it was enclosed in an object in the horizontal plane. The animation below demonstrates this behavior: the agent checks if there is a wall on the right, then checks if there is a wall on the left. As soon as both tests are successfully completed, he reports that he is "in custody."

We trained the next agent to understand the same thing when he is surrounded by two objects already on the sides: a solid container and a container with a hole. The animation shows that the agent climbs into the right object, checking whether it is a solid container. Detects a hole and then gets into the left container, eventually signaling that he is in custody.
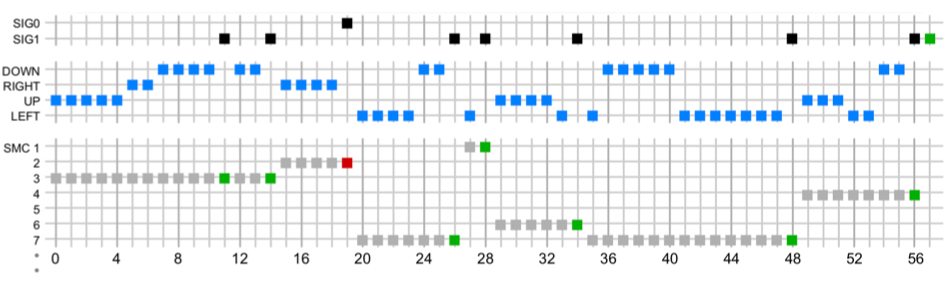
We can understand in more detail what the agent is doing by analyzing the recordings of his actions: The
figure above shows each action performed by the agent in the animation above. Each box represents an action, the time increases from left to right. “DOWN”, “RIGHT”, “UP” and “LEFT” are the main actions of the agent, and each line of “SMC” represents a special case of sensorimotor interaction that the agent can perform. SMC (sensorimotor contingencies - approx. trans. ) can be thought of as small programs that, when executed, use a sequence of basic actions, until the agent decides to stop and send one of two signals that indicate either success (“SIG1”, green) or defeat (“SIG0”, red ). Each of these SMCs emerged as an agent who was trained to solve a simpler conceptual problem. For example, “SMC 3” was trained to climb into a container if at the beginning it is on the floor to the left of it. And this is the first thing the agent does in the animation from step 0 to step 11. Thus, an agent can perform complex tasks, such as making a final conclusion on a conclusion, by performing a sequence of corresponding low-level SMCs.
After that, we expanded our concepts beyond the term of confinement and included such concepts as being at the top of an object or being left to two objects:


Training these agents in only one environment would not be enough, because to understand which aspects of the environment are related to the concepts and which are not, you need a lot of different environments. The presence of such a multitude of types of environments also allows us to determine the types in which an active approach and the reuse of previously developed behavior would benefit passive approaches.
To meet this need, we applied a special type of record based on first-order logic to prepare data arrays for experiments using logical expressions both for generating media and for marking them in relation to what concept is represented inside them. We have created 96 such arrays, organized into training blocks from simple to complex concepts. Both the recording system and the environments mentioned above are contained in the PixelWorld release.
What we got
We compared our active approach with a passive, using a convolutional neural network, trained to determine whether a concept is present, based on a static perception of the entire medium as a whole. For concepts using the “conclusion”, the interactive approach is clearly superior to the convolutional network. For concepts involving a variety of objects of a variety of forms and spatial relationships, we found that the convolution network in some cases worked better, but worse in others. It should be noted that, by definition, passive approaches cannot interact with the environment; therefore, in this case, the only thing that could be expected is a static detection of the concept. Only our active approach can be successful in environments that require an understanding of any interaction or relationship with the concept.
We also found that behavioral reuse improved the results for both tasks (discovery and interaction), with the most obvious results in those cases where concepts included multiple objects or required complex sequences of behavior.
findings
Our work shows that interactive sensorimotor conceptual representations can be formalized and internalized. While the experiments reflected in this article helped to define the role of interaction in a general way, combining them with the approach of the generative vision system could be useful for studying the concepts of the real world. Moreover, combining sensorimotor perceptions with techniques like Schema Networks would allow the agent to have an internal view of the outside world that he can use for simulation and planning.
Although running artificial intelligence is a topic that is best left for science fiction films, we believe that extracting concepts from sensorimotor interaction is one of the keys to going beyond modern passive artificial intelligence techniques.