JOIN local collection and DbSet in the Entity Framework
- Transfer
A little more than a year with my participation the following "dialogue" took place:
.Net App : Hey Entity Framework, kindly give me a lot of data!
Entity Framework : Sorry, I did not understand you. What do you mean?
.Net App : Yes, I just flew a collection of 100k transactions. And now we need to quickly check the correctness of the prices for the papers that are indicated there.
Entity Framework : Ahh, well, let's try ...
.Net App : Here's the code:
var query = from p in context.Prices
join t in transactions on
new { p.Ticker, p.TradedOn, p.PriceSourceId } equals
new { t.Ticker, t.TradedOn, t.PriceSourceId }
select p;
query.ToList();Entity Framework :

Classic! I think many people are familiar with this situation: when I really want to “beautifully” and quickly do a search in the database using the JOIN of the local collection and DbSet . Usually this experience is frustrating.
In this article (which is a free translation of another of my articles ) I will conduct a series of experiments and try different ways to get around this limitation. There will be a code (simple), reflections and something like a happy ending.
Introduction
Everyone knows about the Entity Framework , many use it every day, and there are many good articles on how to prepare it correctly (use simpler requests, use parameters in Skip and Take, use VIEW, request only the required fields, monitor the caching of requests and etc.), however, the JOIN topic of the local collection and DbSet is still a weak point.
Task
Suppose that there is a database with prices and there is a collection of transactions that need to check the correctness of prices. And suppose we have the following code.
var localData = GetDataFromApiOrUser();
var query = from p in context.Prices
join s in context.Securities on p.SecurityId equals s.SecurityId
join t in localData on
new { s.Ticker, p.TradedOn, p.PriceSourceId } equals
new { t.Ticker, t.TradedOn, t.PriceSourceId }
select p;
var result = query.ToList();This code does not work in Entity Framework 6 at all. In Entity Framework Core - it works, but everything will be done on the client side even in the case when there are millions of records in the database - this is not the way out.
As I said, I will try different ways to get around this. From simple to complex. For my experiments, I use the code from the following repository . The code is written using: C # , .Net Core , EF Core and PostgreSQL .
I also shot some metrics: elapsed time and memory consumption. Disclaimer: if the test was performed for more than 10 minutes - I interrupted it (restriction from above). Machine for tests Intel Core i5, 8 GB RAM, SSD.

Только 3 таблицы: prices, securities and price sources. Prices — содержит 10 миллионов записей.
Method 1. Naive
Let's start with a simple one and use the following code:
var result = new List<Price>();
using (var context = CreateContext())
{
foreach (var testElement in TestData)
{
result.AddRange(context.Prices.Where(
x => x.Security.Ticker == testElement.Ticker &&
x.TradedOn == testElement.TradedOn &&
x.PriceSourceId == testElement.PriceSourceId));
}
}The idea is simple: in a loop we read the records from the database one by one and add them to the resulting collection. This code has only one advantage - simplicity. And one drawback is low speed: even if there is an index in the database, communication with the database server will take most of the time. Metrics turned out such:
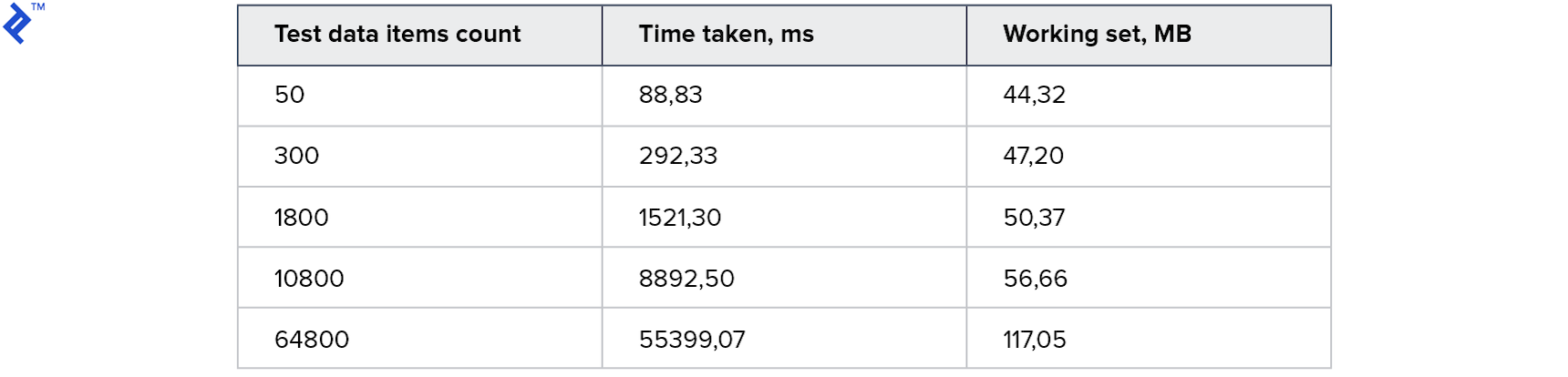
Memory consumption is low. For a large collection takes 1 minute. Not bad for a start, but I want it faster.
Method 2. Naive parallel
Let's try to add parallelism. The idea is to access the database from several threads.
var result = new ConcurrentBag<Price>();
var partitioner = Partitioner.Create(0, TestData.Count);
Parallel.ForEach(partitioner, range =>
{
var subList = TestData.Skip(range.Item1)
.Take(range.Item2 - range.Item1)
.ToList();
using (var context = CreateContext())
{
foreach (var testElement in subList)
{
var query = context.Prices.Where(
x => x.Security.Ticker == testElement.Ticker &&
x.TradedOn == testElement.TradedOn &&
x.PriceSourceId == testElement.PriceSourceId);
foreach (var el in query)
{
result.Add(el);
}
}
}
});Result:
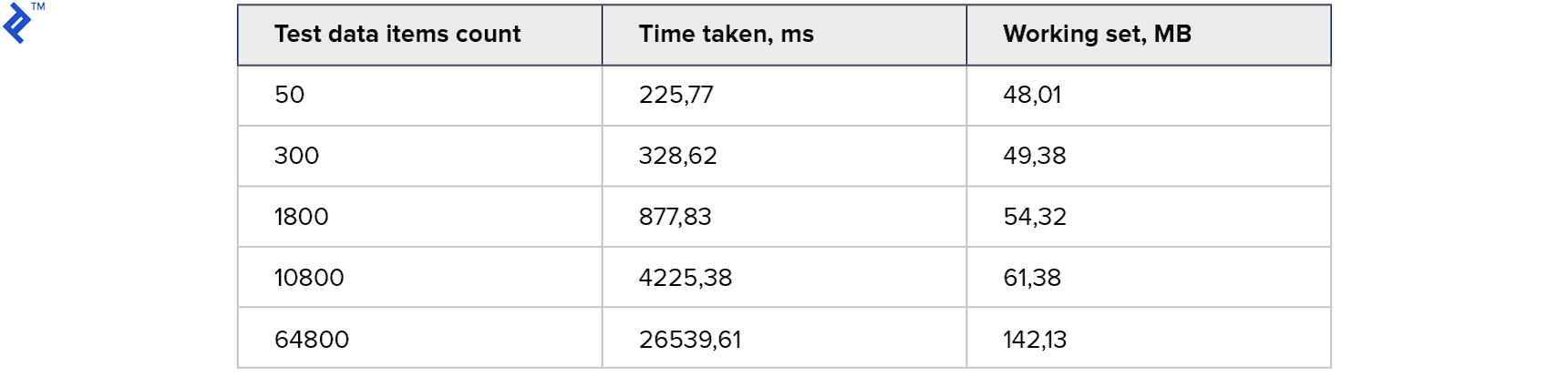
For small collections, this approach is even slower than the first method. And for the biggest - 2 times faster. Interestingly, 4 threads were spawned on my car, but this did not lead to 4x acceleration. This suggests that the overhead in this method is significant: both on the client side and on the server side. Memory consumption has increased, but only slightly.
Method 3. Multiple Contains
Time to try something different and try to reduce the task to the execution of a single request. Can be done as follows:
- Prepare 3 collections of unique Ticker , PriceSourceId and Date values
- Run query and use 3 contains
- Recheck results locally
var result = new List<Price>();
using (var context = CreateContext())
{
// Готовим коллекции
var tickers = TestData.Select(x => x.Ticker).Distinct().ToList();
var dates = TestData.Select(x => x.TradedOn).Distinct().ToList();
var ps = TestData.Select(x => x.PriceSourceId).Distinct().ToList();
// Запрос с использованием 3 Contains
var data = context.Prices
.Where(x => tickers.Contains(x.Security.Ticker) &&
dates.Contains(x.TradedOn) &&
ps.Contains(x.PriceSourceId))
.Select(x => new {
Price = x,
Ticker = x.Security.Ticker,
})
.ToList();
var lookup = data.ToLookup(x =>
$"{x.Ticker}, {x.Price.TradedOn}, {x.Price.PriceSourceId}");
// Перепроверка
foreach (var el in TestData)
{
var key = $"{el.Ticker}, {el.TradedOn}, {el.PriceSourceId}";
result.AddRange(lookup[key].Select(x => x.Price));
}
}The problem here is that the execution time and the amount of data returned strongly depends on the data itself (both in the query and in the database). That is, only the necessary data can be returned, and even extra records can be returned (even 100 times more).
This can be explained using the following example. Suppose there is the following table with data:

Suppose also that I need prices for Ticker1 with TradedOn = 2018-01-01 and for Ticker2 with TradedOn = 2018-01-02 .
Then unique values for Ticker = ( Ticker1 , Ticker2 )
And unique values for TradedOn = ( 2018-01-01 , 2018-01-02 )
However, the result will be returned 4 entries, because they really correspond to these combinations. This is bad because the more fields are used - the greater the chance of getting extra records as a result.
For this reason, the data obtained in this way must be further filtered on the client side. And this is the biggest drawback.
The metrics are as follows:
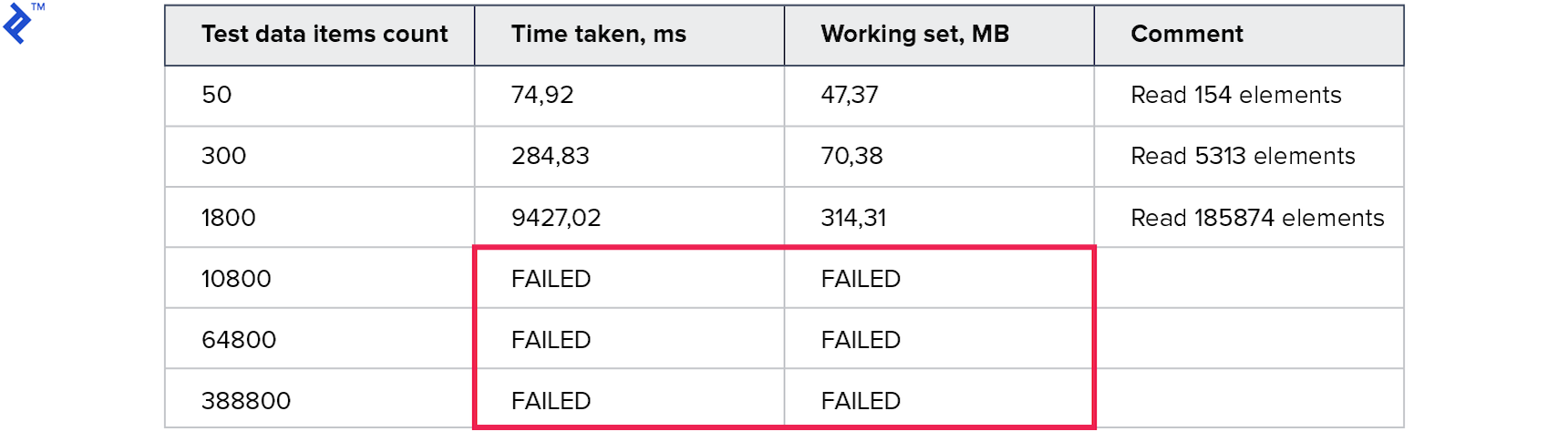
Memory consumption is worse than all previous methods. The number of read lines is many times the number of requested. Tests for large collections were interrupted for more than 10 minutes. This method is no good.
Method 4. Predicate builder
Let's try now on the other hand: good old Expression . Using them, you can build 1 large query in the following form:
… (.. AND .. AND ..) OR (.. AND .. AND ..) OR (.. AND .. AND ..) …
This gives hope that it will be possible to build 1 query and get only the necessary data for 1 visit. Code:
var result = new List<Price>();
using (var context = CreateContext())
{
var baseQuery = from p in context.Prices
join s in context.Securities on
p.SecurityId equals s.SecurityId
select new TestData()
{
Ticker = s.Ticker,
TradedOn = p.TradedOn,
PriceSourceId = p.PriceSourceId,
PriceObject = p
};
var tradedOnProperty = typeof(TestData).GetProperty("TradedOn");
var priceSourceIdProperty = typeof(TestData).GetProperty("PriceSourceId");
var tickerProperty = typeof(TestData).GetProperty("Ticker");
var paramExpression = Expression.Parameter(typeof(TestData));
Expression wholeClause = null;
foreach (var td in TestData)
{
var elementClause =
Expression.AndAlso(
Expression.Equal(
Expression.MakeMemberAccess(
paramExpression, tradedOnProperty),
Expression.Constant(td.TradedOn)
),
Expression.AndAlso(
Expression.Equal(
Expression.MakeMemberAccess(
paramExpression, priceSourceIdProperty),
Expression.Constant(td.PriceSourceId)
),
Expression.Equal(
Expression.MakeMemberAccess(
paramExpression, tickerProperty),
Expression.Constant(td.Ticker))
));
if (wholeClause == null)
wholeClause = elementClause;
else
wholeClause = Expression.OrElse(wholeClause, elementClause);
}
var query = baseQuery.Where(
(Expression<Func<TestData, bool>>)Expression.Lambda(
wholeClause, paramExpression)).Select(x => x.PriceObject);
result.AddRange(query);
}The code turned out more complicated than in previous methods. Building an Expression manually is not the easiest or quickest operation.
Metrics:
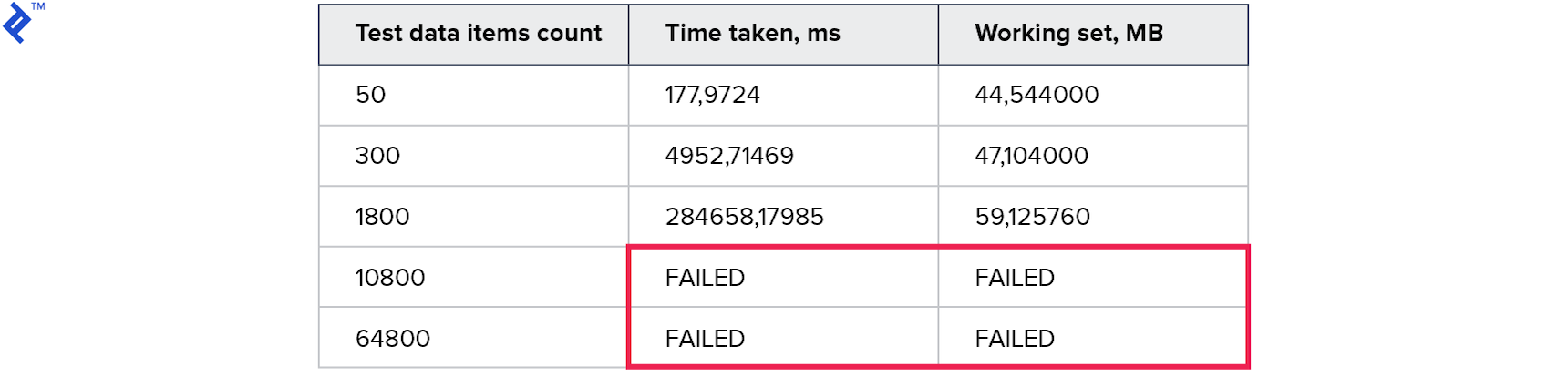
Temporary results were even worse than in the previous method. It seems that the overhead during the construction and passage through the tree turned out to be much greater than the gain from using one query.
Method 5. Shared query data table
Now let's try another option:
I created a new table in the database into which I will write the data necessary to fulfill the request (implicitly I need a new DbSet in context).
Now, to get the result you need:
- Start transaction
- Load query data into a new table.
- Run the query itself (using the new table)
- Roll back transaction (to clear data table for queries)
The code looks like this:
var result = new List<Price>();
using (var context = CreateContext())
{
context.Database.BeginTransaction();
var reducedData = TestData.Select(x => new SharedQueryModel()
{
PriceSourceId = x.PriceSourceId,
Ticker = x.Ticker,
TradedOn = x.TradedOn
}).ToList();
// Временно сохраняем данные в таблицу
context.QueryDataShared.AddRange(reducedData);
context.SaveChanges();
var query = from p in context.Prices
join s in context.Securities on
p.SecurityId equals s.SecurityId
join t in context.QueryDataShared on
new { s.Ticker, p.TradedOn, p.PriceSourceId } equals
new { t.Ticker, t.TradedOn, t.PriceSourceId }
select p;
result.AddRange(query);
context.Database.RollbackTransaction();
}First metrics:
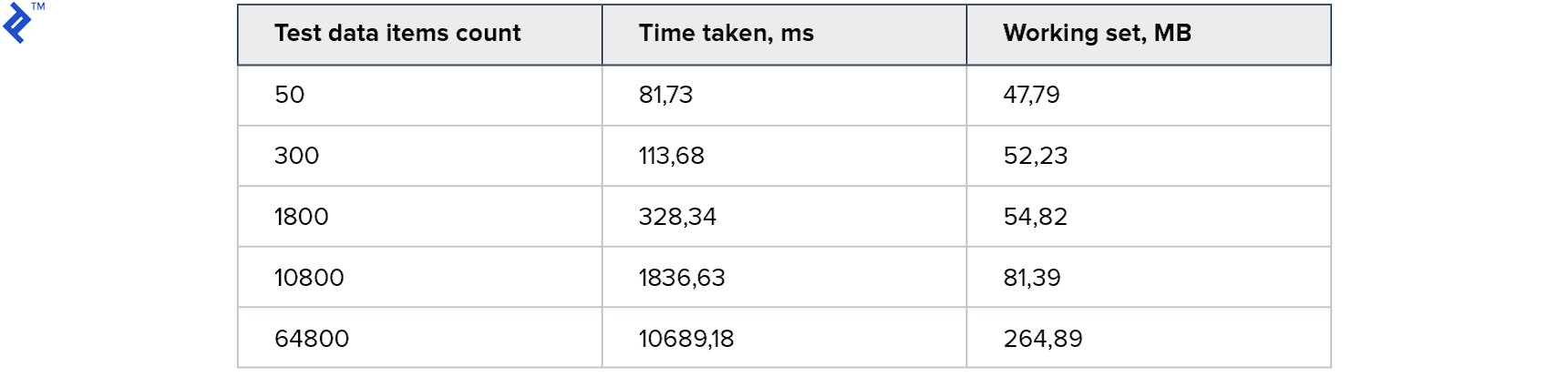
All tests worked and worked quickly! Memory consumption is also acceptable.
Thus, due to the use of a transaction, this table can be used simultaneously by several processes. And since this is a real-life table, all the features of the Entity Framework are available to us : you only need to load data into the table, build a query using the JOIN and execute it. At first glance, this is what is needed, but there are significant drawbacks:
- You must create a table for a specific type of query.
- You need to use transactions (and spend DBMS resources on them)
- And the very idea that you need to WRITE something when you need to READ looks strange. And on Read Replica it just will not work.
And the rest - the solution is more or less working, which can already be used.
Method 6. MemoryJoin extension
Now you can try to improve the previous approach. Reflections are:
- Instead of using a table that is specific to one type of query, you can use a generic version. Namely, create a table with a name like shared_query_data , and add several Guid fields to it , several Long , several String , etc. You can take simple names: Guid1 , Guid2 , String1 , Long1 , Date2 , etc. Then this table can be used for 95% of query types. Property names can be “corrected” later using the Select projection .
- Next you need to add DbSet for shared_query_data .
- And what if instead of writing data to the database - to transfer values using the VALUES construction ? That is, it is necessary that in the final SQL query, instead of referring to shared_query_data, there be an appeal to VALUES . How to do it?
- In Entity Framework Core - just using FromSql .
- In Entity Framework 6, you'll have to use DbInterception — that is, change the generated SQL by adding the VALUES construct right before execution. This will lead to the restriction: in one query - no more than one VALUES construct . But it will work!
- If we are not going to write to the database, does the table shared_query_data , created in the first step, turn out to be not needed at all? Answer: yes, it is not needed, but DbSet is still needed, since the Entity Framework needs to know the data schema in order to build queries. It turns out, you need a DbSet for some generalized model that does not exist in the database and is used only to instill the Entity Framework that it knows what it is doing.
- На вход поступила коллекция объектов следующего типа:
classSomeQueryData {publicstring Ticker {get; set;} public DateTimeTradedOn {get; set;} publicint PriceSourceId {get; set;} } - У нас в распоряжении есть DbSet с полями String1, String2, Date1, Long1, etc
- Пусть Ticker будет храниться в String1, TradedOn в Date1, а PriceSourceId в Long1 (int маппится в long, чтобы не делать отдельно поля для int и long)
- Тогда FromSql + VALUES будет таким:
var query = context.QuerySharedData.FromSql( "SELECT * FROM ( VALUES (1, 'Ticker1', @date1, @id1), (2, 'Ticker2', @date2, @id2) ) AS __gen_query_data__ (id, string1, date1, long1)") - Теперь можно сделать проекцию и вернуть удобный IQueryable, использующий тот же тип, который был на входе:
return query.Select(x => new SomeQueryData() { Ticker = x.String1, TradedOn = x.Date1, PriceSourceId = (int)x.Long1 });
I managed to implement this approach and even arrange it as a NuGet package EntityFrameworkCore.MemoryJoin ( code is also available). Despite the fact that the name has the word Core , Entity Framework 6 is also supported. I called it MemoryJoin , but in fact it sends local data to the DBMS in the VALUES construction and all the work is done on it.
The code is obtained as follows:
var result = new List<Price>();
using (var context = CreateContext())
{
// ВАЖНО: нужно выбрать только поля, которые будут использоваться в запросе
var reducedData = TestData.Select(x => new {
x.Ticker,
x.TradedOn,
x.PriceSourceId
}).ToList();
// Здесь IEnumerable<> превращается в IQueryable<>
var queryable = context.FromLocalList(reducedData);
var query = from p in context.Prices
join s in context.Securities on
p.SecurityId equals s.SecurityId
join t in queryable on
new { s.Ticker, p.TradedOn, p.PriceSourceId } equals
new { t.Ticker, t.TradedOn, t.PriceSourceId }
select p;
result.AddRange(query);
}Metrics:
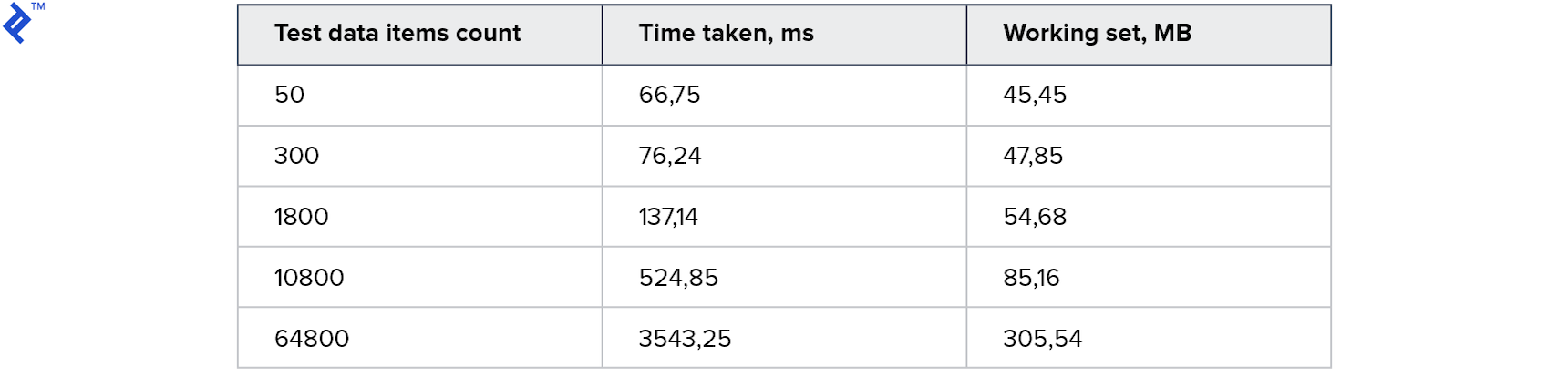
This is the best result I've ever tried. The code is very simple and straightforward, and at the same time working for Read Replica.
SELECT"p"."PriceId",
"p"."ClosePrice",
"p"."OpenPrice",
"p"."PriceSourceId",
"p"."SecurityId",
"p"."TradedOn",
"t"."Ticker",
"t"."TradedOn",
"t"."PriceSourceId"FROM"Price"AS"p"INNERJOIN"Security"AS"s"ON"p"."SecurityId" = "s"."SecurityId"INNERJOIN
( SELECT"x"."string1"AS"Ticker",
"x"."date1"AS"TradedOn",
CAST("x"."long1"AS int4) AS"PriceSourceId"FROM
( SELECT *
FROM (
VALUES (1, @__gen_q_p0, @__gen_q_p1, @__gen_q_p2),
(2, @__gen_q_p3, @__gen_q_p4, @__gen_q_p5),
(3, @__gen_q_p6, @__gen_q_p7, @__gen_q_p8)
) AS __gen_query_data__ (id, string1, date1, long1)
) AS"x"
) AS"t"ON (("s"."Ticker" = "t"."Ticker")
AND ("p"."PriceSourceId" = "t"."PriceSourceId")Здесь также видно, как обобщенная модель (с полями String1, Date1, Long1) при помощи Select превращается в ту, которая используется в коде (с полями Ticker, TradedOn, PriceSourceId).
All work is done for 1 query on the SQL server. And this is a small happy ending, which I mentioned at the beginning. And yet the use of this method requires an understanding of the following steps:
- You need to add an additional DbSet to your context (although you can not add the table itself)
- In the generalized model, which is used by default, 3 fields of the types Guid , String , Double , Long , Date , etc. are declared . That should be enough for 95% of request types. And if you pass a collection of objects with 20 fields to FromLocalList , Exception will be thrown , saying that the object is too complex. This is a mild restriction and it can be circumvented - you can declare your type and add at least 100 fields there. However, more fields - slower work.
- More technical details are described in my article .
Conclusion
In this article, I set out my thoughts on the JOIN of the local collection and DbSet. It seemed to me that my development using VALUES might be of interest to the community. At least I have not met such an approach when I solved this task myself. Personally, this method helped me overcome a number of performance problems in my current projects, maybe it will help you too.
Someone will say that the use of MemoryJoin is too "abstruse" and needs to be improved, but until then it is not necessary to use it. This is exactly the reason why I really doubted and did not write this article for almost a year. I agree that I would like it to work easier (I hope some day it will be so), but also I will say that optimization has never been the task of the Juniors. Optimization always requires an understanding of how the tool works. And if there is an opportunity to get acceleration ~ 8 times ( Naive Parallel vs MemoryJoin ), then I would master 2 points and documentation.
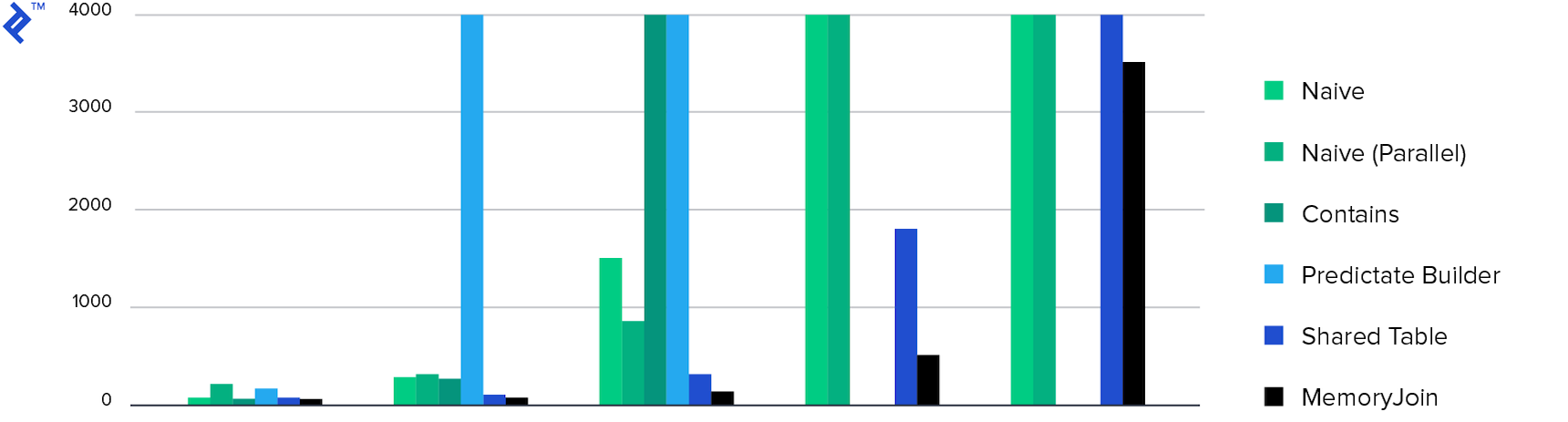
And finally, the charts:
Time spent Only 4 ways completed the task in less than 10 minutes, and MemoryJoin is the only way that completed the task in less than 10 seconds.
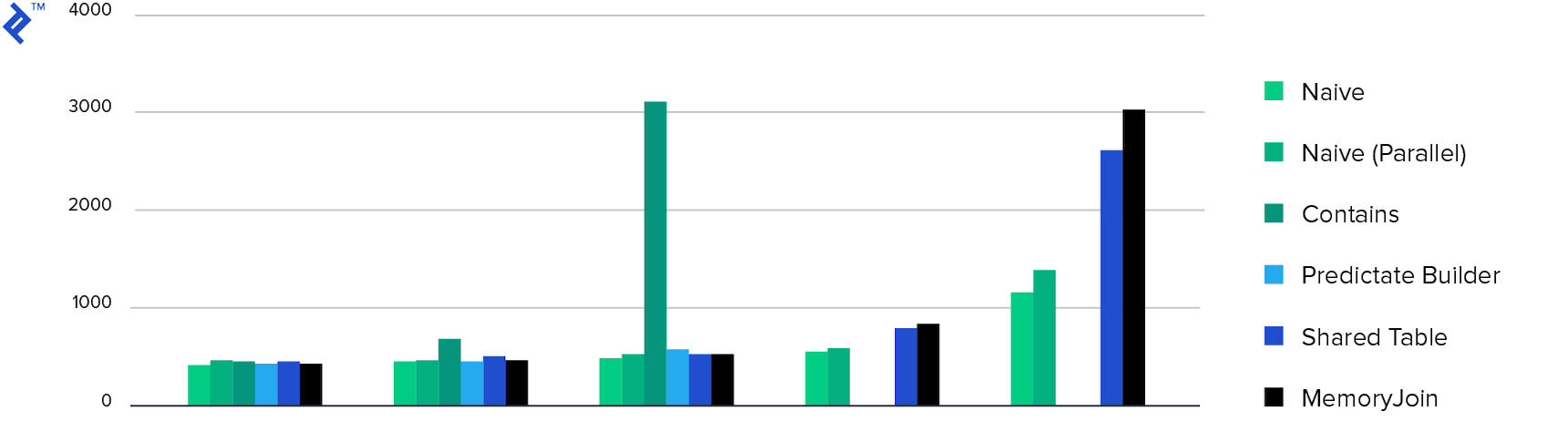
Memory consumption. All methods showed approximately the same memory consumption, except for Multiple Contains . This is due to the amount of data returned.
Thanks for reading!