We are testing PostgreSQL on an SSD RAID-0 array with a table of 10 billion entries. (Part 1)

During the development of the service for optimizing the cost of cellular communications Dr. Tariff ( iOS , Android ) for a joint pilot with one of the partners we needed a large and productive relational database.
The performance of the HDD was clearly not enough. The size of the database was supposed to be several hundred gigabytes, so placing it in RAM would be too expensive. An SSD is best suited for this task. But one SSD drive might not be enough, so it was decided to assemble a RAID-0 array of two drives. Taking this opportunity, we decided to conduct PostgreSQL performance testing on one and two SSD disks.
The main goals of testing
1. Compare the performance of PostgreSQL on a SSD RAID-0 array with the performance on a single SSD.
2. To study the performance of basic operations (SELECT and UPDATE) depending on the size of the table, the number of connections, server settings and other parameters.
Testing was carried out in several iterations. For each part, it was decided to write a detailed article with reports:
- Testing a single SSD drive
- Testing a RAID-0 array of 2 SSD drives
- The impact of server settings on database performance
- Comparison of SSD with HDD
Iron part
All testing was carried out in the following configuration:
- Intel i7 4770.
- 16 Gb RAM.
- Intel SSD for the system drive.
- Intel SSD 480 Gb 530 series for drive in with a database. Model - SSDSC2BW480A401
- Toshiba HDD 3000 Gb. Model - DT01ACA300
- The file system of all partitions is Ext4. Disks are connected via SATA 3.
Software
The Linux Mint 17.2 operating system is installed on the test computer. PostgreSQL version is “PostgreSQL 9.4.4 on x86_64-unknown-linux-gnu, compiled by gcc (Ubuntu / Linaro 4.6.3-1ubuntu5) 4.6.3, 64-bit”
After formatting on the SSD, 440GB is available. The graph below shows the performance of one SSD drive.
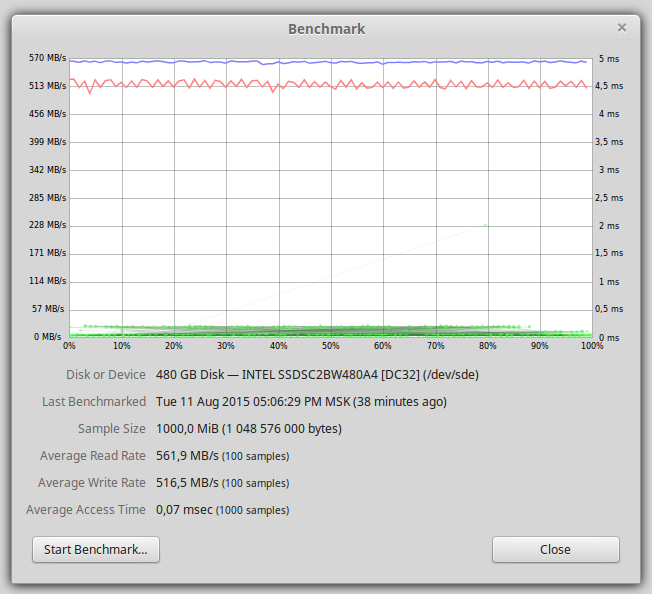
Read and write performance of about 500 Mb / s, the bottleneck is the SATA interface.
Postgres settings are standard except for the following parameters:
shared_buffers = 2048 Mb
port = 5400
max_connections = 1000
Testing
There were 3 options as a load source:
- standard pg_bench
- Python client with Psycopg2
- Python client with SQLAlchemy
The first pgBench tests showed good performance, but they worked on newly generated tables. We wanted the test to be as close to real conditions as possible. Of course, you can write your own test script, but Python was preferred to the client.
The first customer candidate was SQLAlchemy. It has the ability to call raw SQL commands through the execute method. The very first tests on a small sample showed that SQLAlchemy consumes a lot (tens of percent) of CPU.
When testing the Psycopg2 client, the processor consumption was around 15%, which is quite acceptable for testing, since the disk subsystem was the bottleneck in most cases. All further tests were performed using the Python client with Psycopg2. A separate Python process was created for each database connection.
Test Pattern:
CREATE TABLE numbers
(
"number" bigserial NOT NULL,
operator smallint,
region smallint,
CONSTRAINT numbers_pkey PRIMARY KEY (number)
)
To test reading, the following command was used:
'SELECT * FROM numbers WHERE number=%d'
The number was chosen randomly.
To test the record, the command was used:
'UPDATE numbers set region=%d, operator=%d WHERE number=%d'
All parameters are random from valid ranges. UPDATE reads and writes data to disk without changing the size of the database, so it was decided to use it for a complex write load. INSERT and DELETE were not used during testing. Each individual test took several minutes. Separate tests were run several times, and the resulting performance coincided with an accuracy of about 1%.
To create a RAID-0 array, mdadm was used . RAID was created using the entire disk, not over partitions.
To record a large number of lines, the COPY function was used. Data was previously written to a temporary file, and then imported into the database. With this approach, 1 billion records were entered into the database a little more than 1 hour.
Testing was performed on one SSD disk immediately after filling the database. The size of the table is 1 billion records. On the disk, 42GB was occupied by the table and 21GB per index. The bottleneck is the disk subsystem. Let's consider how database performance changes depending on the number of active connections.
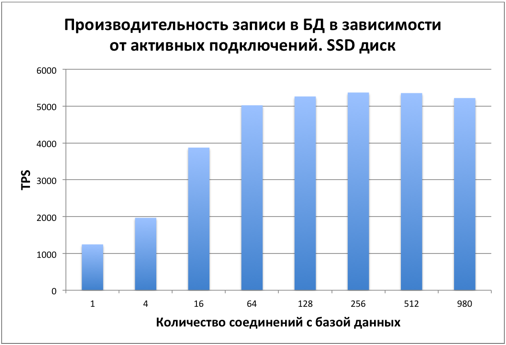
SELECT performance
At first, performance grows evenly depending on the number of connections. Starting with approximately 16 connections, overall performance stabilizes by abutting the disk.
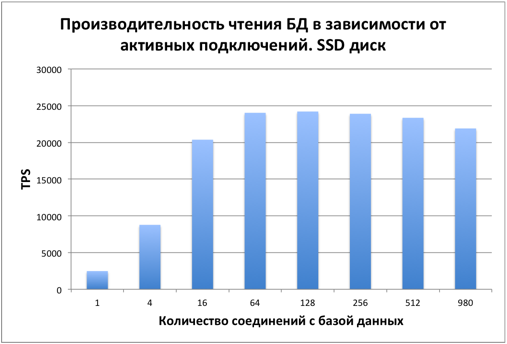
Performance UPDATE
When updating records, the picture is similar. With 16 users, performance stabilizes. The bottleneck is the disk.
PostgreSQL uses MVCC to provide ACID . This, in particular, explains that when changing the value of one column in the whole table, the size of this table changes by about 2 times.
After updating many records in the table and indexes, there were many dead records, which affects performance. Consider how this affected reading performance.
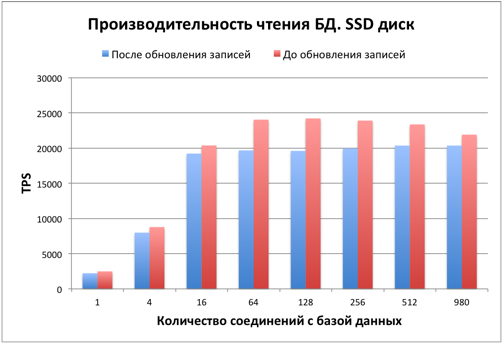
As you can see, reading performance fell by 15-20%. Also, the base has slightly increased in size. To increase productivity and free up space, the VACUUM command is required. This question is beyond the scope of the article; more details about it can be found in the documentation .
After all the tests and stopping PostgreSQL, we decided to repeat the test for read speed from disk.
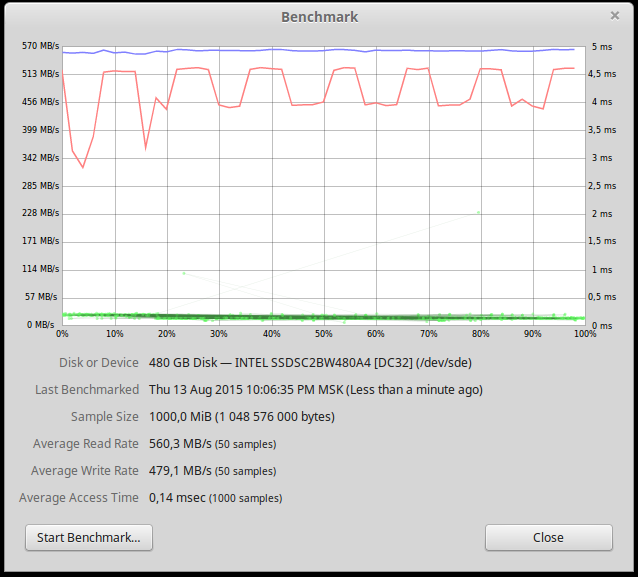
As you can see, the performance of writing to disk has fallen. This graph was stably reproduced at various sizes of read data. We have no explanation for this. We will be glad if someone explains the reasons for the drop in speed.
Summary
From these tests it can be seen that the database works well on an SSD drive with the number of entries in the table up to 1 billion.
The pleasant result was that the database performance practically did not decrease even with 980 active connections. Most likely, many active connections will consume more RAM and processor, the disk subsystem is the bottleneck with the number of connections less than a thousand, but this is the topic of a separate article.
The next article will test the database performance on a RAID-0 SSD and the table size will be increased to 10 billion entries.
Well, the Dr. Tariff on Android and iOS .
Other articles about Dr. Tariff and cellular analytics from our blog
Dr. Tariff calculated which mobile operator has more than 4G Internet (part 2)
Dr. Tariff counted which mobile operator has more than 4G Internet (part 1)
Caution! Hidden revenues of operators - follow the options “They called you!”, “Who called +”, “Be in the know +” (now paid)
The story of how a mobile operator deducted money from the developer Dr. Tariff (grab popcorn)
Dr. Tariff 2.0: new opportunities for Beeline, MegaFon and MTS subscribers
Decided to change the operator? Do not forget to choose the best rate with Dr. Tariff
dr Tariff (3 months later) - you can choose a tariff in 80 regions of Russia on Android and iOS
Dr. Tariff (tariffs and balance): How I began to help people save on mobile costs
Dr. Tariff counted which mobile operator has more than 4G Internet (part 1)
Caution! Hidden revenues of operators - follow the options “They called you!”, “Who called +”, “Be in the know +” (now paid)
The story of how a mobile operator deducted money from the developer Dr. Tariff (grab popcorn)
Dr. Tariff 2.0: new opportunities for Beeline, MegaFon and MTS subscribers
Decided to change the operator? Do not forget to choose the best rate with Dr. Tariff
dr Tariff (3 months later) - you can choose a tariff in 80 regions of Russia on Android and iOS
Dr. Tariff (tariffs and balance): How I began to help people save on mobile costs
Subscribe to our news and share information with your friends on Vkontakte and Facebook .