We optimize the web with Vitaliy Fridman, - compression, pictures, fonts, features HTTP / 2 and Resource Hints
We bring to your attention a selection of all kinds of lifehacks and tricks to optimize the amount of downloaded code and files, as well as the overall acceleration of loading web pages.
The article is based on a transcript of the speech of Vitaliy Fridman from Smashing Magazine at the December conference of Holy JS 2017 Moscow.
So that you and I would not be bored, I decided to submit this story in the format of a small game, calling it Responsive Adventures.

There will be five levels in the game, and we will start with a simple level - compression.

Compression is compression, and you can compress in the frontend, for example, images, text, fonts, and so on. If there is a need to optimize the page in terms of text, then in practice they usually use a library to compress gzip data. The most commonly used gzip implementation is zlib, which uses a combination of the LZ77 and Huffman coding algorithms.
Usually we are interested in how much the library should compress, because the better it does, the more time this process takes. Usually we choose either fast compression or good, because it is impossible to achieve fast and good compression at the same time. But as developers, we care about two aspects: file size and compression / decompression speed - for static and dynamic web content.
There are data compression algorithms Brotli and Zopfli. Zopfli can be seen as a more efficient but slower version of gzip. Brotli is a new lossless compression and decompression format.

In the future we will be able to use Brotli. But now not all browsers support it, but we need full support.


The strategy is as follows:

But what will we do with the images?
Let's imagine you have a nice landing page with fonts and images. The page needs to load very fast. And we are talking about an extreme level of image optimization. This is a problem, and it is not far-fetched. We prefer not to talk about it, because unlike JS, images do not block page rendering. This is actually a big problem, because the size of images increases over time. Now there are already 4K screens in use, soon there will be 8K.

In general, 90% of users see 5.4 MB of images on a page - that's a lot. This is a problem that needs to be resolved.
We specify the problem. What if you have a large picture with a transparent shadow, as in the example below.

How to compress it? After all, png is quite heavy, and after compression the shadow will not look very good. Which format to choose? Jpeg? The shadow will also not look good enough. What can be done?

One of the best options is to split the images into two components. Place the base of the image in jpeg, and the shadow in png. Next, connect the two pictures in svg.

Why is it good? Because the image, which weighed 1.5 MB, now occupies 270 KB. This is a big difference.
But there are a couple more tricks. Here is one of them.
Let's take two images that are visually displayed on a website with the same proportions.

The first - with very poor quality, has a real and visual size of 600 x 400 px, and below it is the same, but visually reduced to 300 x 200 px.

Let's compare this image with an image that has a real size of 300 x 200 px but is saved at 80% quality.

Most users are unable to distinguish between these images, but the picture on the left weighs 21 KB, and on the right - 7 KB.
There are two problems:
An interesting test that used this technique was conducted by the Swedish online magazine Aftonbladet. The initial image quality setting was set to 30%.

As a result, their main page with 40 images using this technique took 450 KB. Impressive!
Here is another good technique.
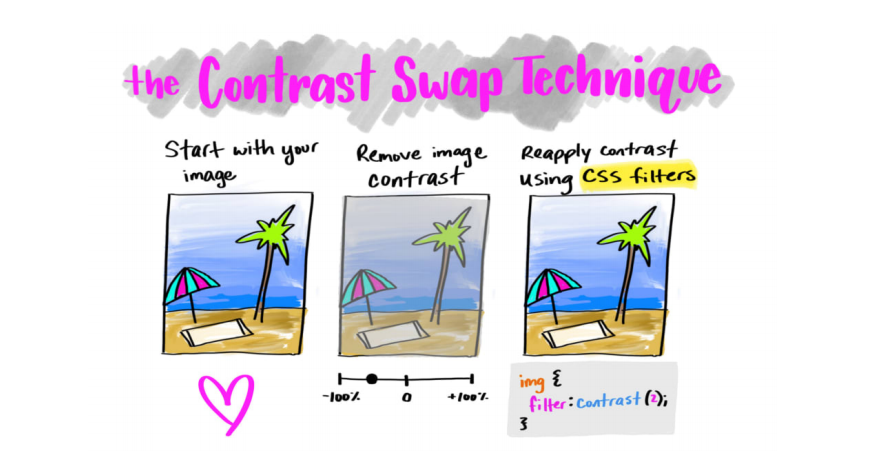
We have a picture, and we need to reduce its size. What will make it better compress? Contrast! What if you remove or reduce it significantly, and then return it using CSS filters? But then again, anyone who wants to download this image will face poor quality.
This technique can achieve great results. Here are some examples:




Everything would be fine, but what about the extra rendering delays? After all, the browser has to apply filters to the image. But here everything is quite positive: 27 ms versus 23 ms without the use of filters - the difference is insignificant.
Filters are supported everywhere except IE.

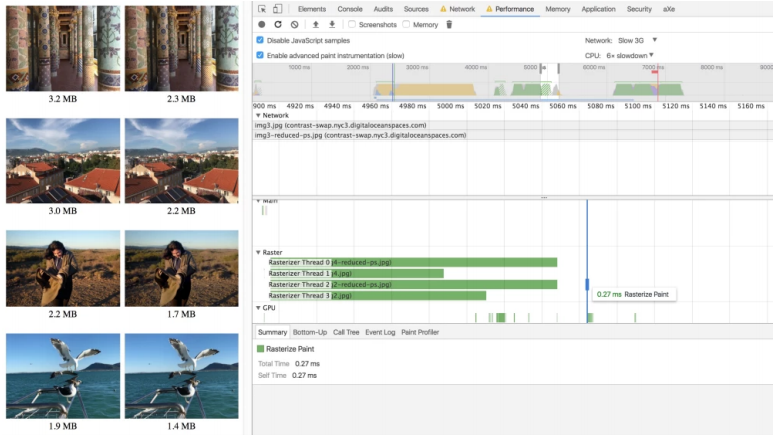
What other tricks are there? Compare two photos:


The difference is the blur of irrelevant details of the photo, which allows you to reduce the size to 147 KB. But this is not enough! Let's go to JPEG encoding. Suppose you have a consistent and progressive JPEG.

Serial JPEG is loaded on the page line by line, progressive - at first in poor quality immediately as a whole, and then the quality gradually improves.
If you look at how encoders work, you can see several levels of scanning.

Many different scan levels are in this file. Our goal, as developers, is to immediately show detailed information about this picture. Then you can make sure that Ships Fast and Shows Soon are with some coefficients that may fit the picture better, and then at the first level we will see the structure, and not just something blurry. And on the second - almost everything.


There are libraries and utilities that allow you to do such tricks: Adept, mozjpeg or Guetzli.

I remember seven to ten years ago - I wanted fonts, added font-face and you're done. And now, no, you need to think about what I want to do and how to download. So, what is the best method to choose for downloading fonts?

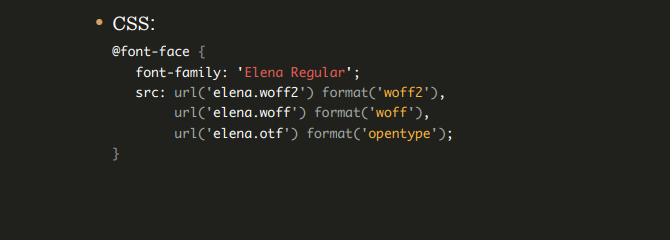
We can use the font-face syntax to avoid common pitfalls along the way:

If we want to support only more or less normal browsers, we can write even shorter:
What happens when we have this font-face in css? Browsers look to see if there is an indication of a font in the body or somewhere else, and if so, then the browser starts loading it. And we have to wait.
If the fonts are not yet cached, they will be requested, downloaded, and applied, deferring rendering.

But different browsers act differently. There are FOUT and FOIT mapping approaches.

FOIT (Flash of Invisible Text) - nothing is displayed until the fonts load.
FOUT (Flash Unstyled Text) - the content is displayed immediately with default fonts, and then the necessary fonts are loaded.
Typically, browsers wait for font downloads for three seconds, and if they do not have time to load, then the default fonts are substituted. There are browsers that do not wait. But the most unpleasant thing is that there are browsers that are waiting all the way. Will not work! There are many different options for getting around this. One of them is the CSS Font Loading API. Create a new font-face in JS. If the fonts are loading, then we hang them in the appropriate places. If they do not load, we hang the standard ones.
We can also use new properties in CSS, for example, font-rendering, which allows us to emulate either FOIT or FOUT, but in fact we do not even need them, because there is Font Rendering Optional.

There is another way - critical FOFT with Data URI. Instead of loading via the JavaScript API, the web font is embedded directly in the markup as an embedded Data URI.
Two-stage rendering: first a Roman font, and then the rest:
This method will block the initial display, but since we embed only a small subset of the simple font, this is a low price in order to eliminate FOUT. Moreover, this method has the fastest font loading strategy to date.
I thought I could do even better. Instead of using sessionStorage, we embed the web font in the markup and use Service Workers.
For example, we have some kind of font, but we don’t need all of it. And we are not doing subsetting, but rather choosing what is needed for this page. For example, take italic, reduce it, first load it, display it on the page, and it will look like normal, bold will be like normal, everything will be like normal. Then everything is loaded as needed. Next, do subsetting and send it to Service Workers.
Then, when the user comes to the page for the first time, we check for the font, if it is not there, then we display the text immediately, asynchronously download the font and add it to Service Workers, for short. When a user logs in a second time, the idea should already be in Service Workers. Next, we check to see if he is there, and if there is, then we immediately take it from there, and if not, then all these actions occur again.
There is a problem with caching here. What is the likelihood that someone comes to your site and has all the files that should be in the cache that are in it?

The image above shows the results of a 2007 study, which says that 40-60% of users have an empty cache, and 20% of all page views occur with an empty cache. Why is that? Because browsers do not know how to cache? No, we just visit a large number of sites and if everything was cached, the drive of a PC or smartphone would fill up very quickly.
Browsers remove from the cache what they no longer consider necessary.

Let's look at the example of Chrome, what happens in it when we try to open a page on the Web. If you look at the fonts line, you can see that the fonts are in the memory cache or HTTP cache in the best case in 70% of cases. These are actually unpleasant numbers. If the fonts are downloaded every time again, each time the user comes to the site and watches the font style change. From a UX point of view, not very good.
Care must be taken to ensure that fonts really remain in the cache. We used to rely on local storage, but now it’s more reasonable to rely on Service Workers. Because if I put something in Service Workers, then it will be there.
What else can be done? You can use unicode-range. Many people think that dynamic subsetting is happening, that is, we have a font, it is dynamically parsed, and only the specified part is loaded in unicode-range. This is actually not the case, and the entire font is loaded.

Indeed, this is useful when we have a unicode-range, for example, for Cyrillic and for English text. Instead of downloading a font that has English and Russian texts, we can split it into several parts and load Russian, if we have Russian text on the page, and do the same with English.
What else can be done? There is a cool thing to use always and everywhere - preload.

Preload makes it possible to load resources at the beginning of page loading, which in turn makes it less likely to block page rendering. This approach improves productivity.
We can also use font-display: optional. This is a new property in css. How does it work?

Font-display has several meanings. Let's start with block. This property sets the font lock for three seconds, during which the font is loaded, then the font is replaced and then directly displayed.
The swap property works almost the same, but with a few exceptions. The browser immediately draws the text in a spare font, and when the specified one loads, it will replace.

Fallback sets a short lock period of 100 ms, the replacement period will be 3 s, after which the font will be replaced. If the font has not been loaded during this time, the browser will draw the text with the spare font.
And finally we come to optional. The lock period is 100 ms, if during this time the font has not been loaded, the text is displayed immediately. If you have a slow connection, the browser may stop loading the font. When the font loads, you will still see the default font. To see the registered font, you must reload the page.

There are many techniques that we used before http / 2, for example, concatenation, sprites, etc. But with the advent of http / 2, the need to use them disappeared, because unlike http / 1.1, the new version loads almost everything at once, and this is great, because you can use many additional features.
In theory, the transition to http / 2 promises us 64% (23% on mobile) faster page loading. But in practice, everything works more slowly.
If most of your target audience constantly visits the resource while on the bus, car, etc., then it is entirely possible that http / 1.1 will be in a better position.
Take a look at the test results below. It shows that in some situations, http / 1.1 is faster.
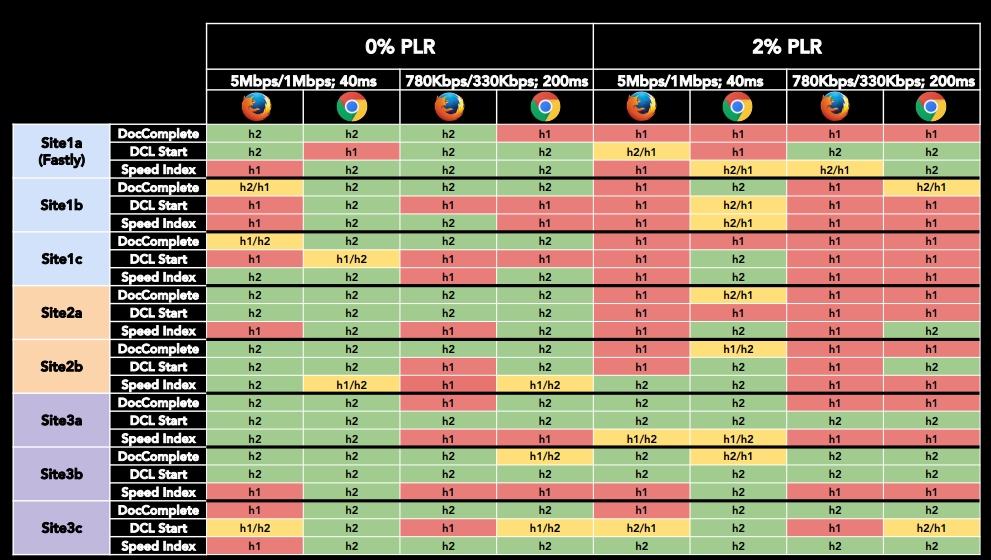
There are wonderful features in http / 2, for example, HPACK, which must be used always and everywhere, and server push as well. But there is a small problem. It arises depending on the browser and server. Suppose we load a page, we do not have any server push.

If the page reloads, then everything is in the cache.

But if we do server push, then our css will reach the user much faster.

But also this means that even if css is in the cache, they will still be forwarded.

That is, if you push a lot of files from the server, they will be downloaded many times.
Move on. There are some recommended limits on page load times. For example, for a mediocre device on android, it is five seconds. This is not so much, considering that we have, for example, 3G.

If you look at the recommended download size limit that you need to start rendering, which Google mentions, it’s 170 KB.

Therefore, when it comes to frameworks, we need to think about parsing, compilation, network quality, cost of runtime, etc.
There are various options for uploading files, for example, the classic way, which is a bit outdated - scout. We start the scout.js file, it is in html, we load it. Its task is to make the rest of the environment as cached as possible and at the same time to report changes in it in a timely manner.

This means that this file needs a short time to be stored in the cache, and if something changes in the environment, then scout immediately initiates the update. This is an effective way, because every time we do not need to load and replace html.
What to do with http / 2? After all, we know that we can send as many files as you like and there is no need to combine them into packages. Let's load 140 modules then, why not? This is actually a very bad idea. Firstly, if we have many files, and we do not use a library, for example gzip for compression, then the files will be larger. Secondly, browsers are not yet optimized for such workflows. As a result, we started experimenting and looking for the right amount, and it turned out that it was optimal to send about 10 packets.
Packages are best bundled based on the frequency of file updates: often updated in some packages, and rarely updated in others to avoid unnecessary downloads. For example, pack libraries with utilities, etc. Nothing special. So what to do with css, how to load it? Server push will not work here.
In the beginning, we all downloaded as minimized files, then we thought that some should be loaded into critical css, because we have only 14 KB, and they need to be downloaded as quickly as possible. We started to do loadCSS, write logic, then added display: none.

But it all looked somehow bad. In http / 2, we thought that it was necessary to split, minify and load all files. It turned out that the best option was the option in the image below.

Unusual! This option works well in Chrome, poorly in IE, in Firefox the work slowed down a bit, as they changed the rendering. Thus, we improved the speed of work by 120 ms.
If you look at working with progressive css and without. With progressive css, everything loads faster, but in parts, but without it, it’s slower, because css is located in header and blocks the page as js.

And the last level, which I cannot but tell you about is Resource Hints. This is a great feature that allows you to do many useful things. Let's go through some of them.
Prefetch - tells the browser that we will need this or that file soon, and the browser loads it with low priority.

Prerender - this function is no longer there, but it helped to do the page prerender earlier. Perhaps she will have an alternative ...

Dns-prefetch also speeds up the page loading process. Using dns-prefetch assumes that the browser preloads the server address of the specified domain name.

Preconnect allows you to do preliminary handshake with the specified servers.

Preload - tells the browser which resources to preload with high priority. Preload can be used for scripts and fonts.

I remember in 2009 reading the article " Gmail for Mobile HTML5 Series: Reducing Startup Latency ", and it changed my views on the classic rules. See for yourself! We have a JS code, but we don’t need all of it now. So why don’t we comment out most of the JS code, and then, when necessary, uncomment and execute in eval?

And the reason they did this is because the average smartphone has a parsing time of 8-9 times longer than the last iPhone.
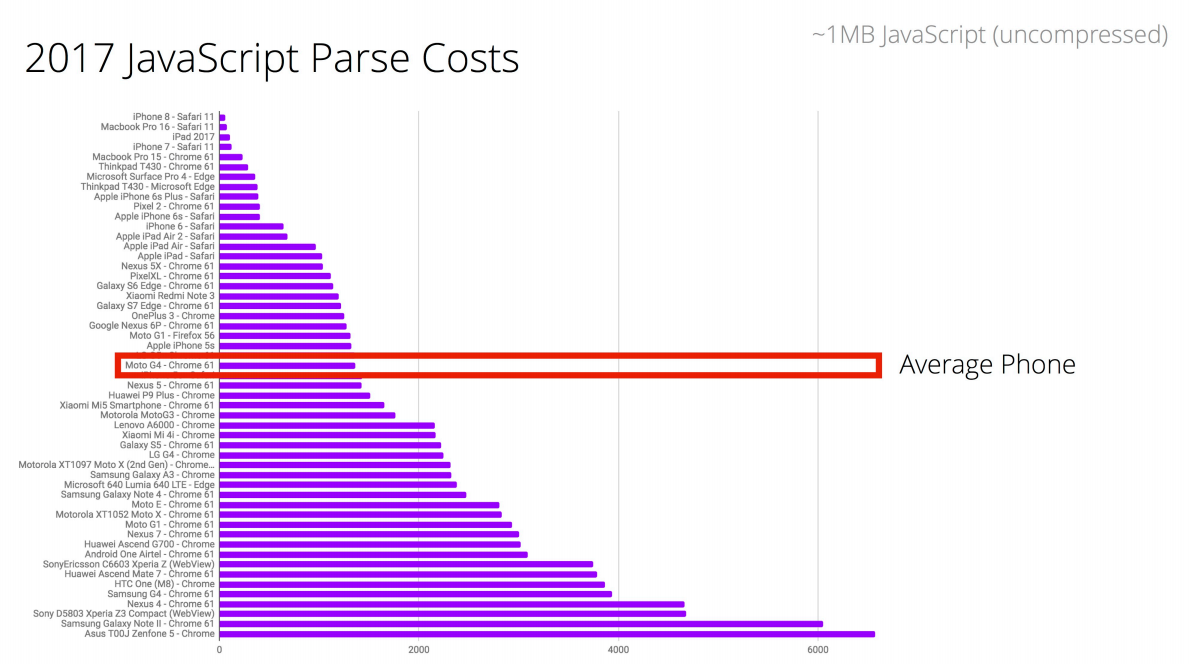
Let's look at the statistics. To parse 1 MB of code on an average phone, you need 4 s.

This is a lot! But we do not need 1 MB immediately. If we again look at the statistics, it turns out that sites use only 40% of the JS code from what they downloaded.

And we can use preload instead of eval for the same situations.
That is, we store the file in the cache, and then, when necessary, we add it to the page.
So, this is only half of what Vitaly Friedman planned to share. The remaining chips and life hacks will be in the decoding of his second performance at HolyJS 2017 Moscow, which we will also prepare and post on our blog.
And if you love the inside of JS as much as we do, you will probably be interested in these reports at our May HolyJS 2018 Piter conference , the key of which we again set the story of Vitaliy Fridman:
The article is based on a transcript of the speech of Vitaliy Fridman from Smashing Magazine at the December conference of Holy JS 2017 Moscow.
So that you and I would not be bored, I decided to submit this story in the format of a small game, calling it Responsive Adventures.
There will be five levels in the game, and we will start with a simple level - compression.
Level 1 - Compression
Compression is compression, and you can compress in the frontend, for example, images, text, fonts, and so on. If there is a need to optimize the page in terms of text, then in practice they usually use a library to compress gzip data. The most commonly used gzip implementation is zlib, which uses a combination of the LZ77 and Huffman coding algorithms.
Usually we are interested in how much the library should compress, because the better it does, the more time this process takes. Usually we choose either fast compression or good, because it is impossible to achieve fast and good compression at the same time. But as developers, we care about two aspects: file size and compression / decompression speed - for static and dynamic web content.
There are data compression algorithms Brotli and Zopfli. Zopfli can be seen as a more efficient but slower version of gzip. Brotli is a new lossless compression and decompression format.
In the future we will be able to use Brotli. But now not all browsers support it, but we need full support.
Brotli and Zopfli
- Brotli is significantly slower in data compression compared to gzip, but provides much better compression.
- Brotli is an open source lossless compression format.
- Brotli's decompression is fast - comparable to zlib.
- Brotli gives you the advantage of working with large files with slow connections.
- Brotli compresses more efficiently by 14-39%.
- Ideal for HTML, CSS, JavaScript, SVG and all text.
- Brotli support is limited to HTTPS connections.
- Zopfli is often used for compression on the fly, but it is a good alternative for compressing static content once.
Brotli / Zopfli Compression Strategy
The strategy is as follows:
- Precompress static resources with Brotli + Gzip.
- Compress with Brotli HTML on the fly with a compression level of 1-4.
- Check Brotli support on CDN (KeyCDN, CDN77, Fastly).
- Use Zopfli if it is not possible to install / maintain Brotli on the server.
Level 2 - Images
But what will we do with the images?
Let's imagine you have a nice landing page with fonts and images. The page needs to load very fast. And we are talking about an extreme level of image optimization. This is a problem, and it is not far-fetched. We prefer not to talk about it, because unlike JS, images do not block page rendering. This is actually a big problem, because the size of images increases over time. Now there are already 4K screens in use, soon there will be 8K.
In general, 90% of users see 5.4 MB of images on a page - that's a lot. This is a problem that needs to be resolved.
We specify the problem. What if you have a large picture with a transparent shadow, as in the example below.
How to compress it? After all, png is quite heavy, and after compression the shadow will not look very good. Which format to choose? Jpeg? The shadow will also not look good enough. What can be done?
One of the best options is to split the images into two components. Place the base of the image in jpeg, and the shadow in png. Next, connect the two pictures in svg.
Why is it good? Because the image, which weighed 1.5 MB, now occupies 270 KB. This is a big difference.
But there are a couple more tricks. Here is one of them.
Let's take two images that are visually displayed on a website with the same proportions.
The first - with very poor quality, has a real and visual size of 600 x 400 px, and below it is the same, but visually reduced to 300 x 200 px.
Let's compare this image with an image that has a real size of 300 x 200 px but is saved at 80% quality.
Most users are unable to distinguish between these images, but the picture on the left weighs 21 KB, and on the right - 7 KB.
There are two problems:
- the one who decides to save the picture will save it in poor quality
- the browser will have to zoom in or out
An interesting test that used this technique was conducted by the Swedish online magazine Aftonbladet. The initial image quality setting was set to 30%.
As a result, their main page with 40 images using this technique took 450 KB. Impressive!
Here is another good technique.
We have a picture, and we need to reduce its size. What will make it better compress? Contrast! What if you remove or reduce it significantly, and then return it using CSS filters? But then again, anyone who wants to download this image will face poor quality.
This technique can achieve great results. Here are some examples:
Everything would be fine, but what about the extra rendering delays? After all, the browser has to apply filters to the image. But here everything is quite positive: 27 ms versus 23 ms without the use of filters - the difference is insignificant.
Filters are supported everywhere except IE.
What other tricks are there? Compare two photos:
The difference is the blur of irrelevant details of the photo, which allows you to reduce the size to 147 KB. But this is not enough! Let's go to JPEG encoding. Suppose you have a consistent and progressive JPEG.
Serial JPEG is loaded on the page line by line, progressive - at first in poor quality immediately as a whole, and then the quality gradually improves.
If you look at how encoders work, you can see several levels of scanning.
Many different scan levels are in this file. Our goal, as developers, is to immediately show detailed information about this picture. Then you can make sure that Ships Fast and Shows Soon are with some coefficients that may fit the picture better, and then at the first level we will see the structure, and not just something blurry. And on the second - almost everything.
There are libraries and utilities that allow you to do such tricks: Adept, mozjpeg or Guetzli.
Level 3
I remember seven to ten years ago - I wanted fonts, added font-face and you're done. And now, no, you need to think about what I want to do and how to download. So, what is the best method to choose for downloading fonts?
We can use the font-face syntax to avoid common pitfalls along the way:
If we want to support only more or less normal browsers, we can write even shorter:
What happens when we have this font-face in css? Browsers look to see if there is an indication of a font in the body or somewhere else, and if so, then the browser starts loading it. And we have to wait.
If the fonts are not yet cached, they will be requested, downloaded, and applied, deferring rendering.
But different browsers act differently. There are FOUT and FOIT mapping approaches.
FOIT (Flash of Invisible Text) - nothing is displayed until the fonts load.
FOUT (Flash Unstyled Text) - the content is displayed immediately with default fonts, and then the necessary fonts are loaded.
Typically, browsers wait for font downloads for three seconds, and if they do not have time to load, then the default fonts are substituted. There are browsers that do not wait. But the most unpleasant thing is that there are browsers that are waiting all the way. Will not work! There are many different options for getting around this. One of them is the CSS Font Loading API. Create a new font-face in JS. If the fonts are loading, then we hang them in the appropriate places. If they do not load, we hang the standard ones.
We can also use new properties in CSS, for example, font-rendering, which allows us to emulate either FOIT or FOUT, but in fact we do not even need them, because there is Font Rendering Optional.
There is another way - critical FOFT with Data URI. Instead of loading via the JavaScript API, the web font is embedded directly in the markup as an embedded Data URI.
Two-stage rendering: first a Roman font, and then the rest:
- Download full fonts with all weights and styles
- Minimum subset of fonts (AZ, 0-9, punctuation)
- Use sessionStorage for back visits
- Download subscript (Roman) first
This method will block the initial display, but since we embed only a small subset of the simple font, this is a low price in order to eliminate FOUT. Moreover, this method has the fastest font loading strategy to date.
I thought I could do even better. Instead of using sessionStorage, we embed the web font in the markup and use Service Workers.
For example, we have some kind of font, but we don’t need all of it. And we are not doing subsetting, but rather choosing what is needed for this page. For example, take italic, reduce it, first load it, display it on the page, and it will look like normal, bold will be like normal, everything will be like normal. Then everything is loaded as needed. Next, do subsetting and send it to Service Workers.
Then, when the user comes to the page for the first time, we check for the font, if it is not there, then we display the text immediately, asynchronously download the font and add it to Service Workers, for short. When a user logs in a second time, the idea should already be in Service Workers. Next, we check to see if he is there, and if there is, then we immediately take it from there, and if not, then all these actions occur again.
There is a problem with caching here. What is the likelihood that someone comes to your site and has all the files that should be in the cache that are in it?
The image above shows the results of a 2007 study, which says that 40-60% of users have an empty cache, and 20% of all page views occur with an empty cache. Why is that? Because browsers do not know how to cache? No, we just visit a large number of sites and if everything was cached, the drive of a PC or smartphone would fill up very quickly.
Browsers remove from the cache what they no longer consider necessary.
Let's look at the example of Chrome, what happens in it when we try to open a page on the Web. If you look at the fonts line, you can see that the fonts are in the memory cache or HTTP cache in the best case in 70% of cases. These are actually unpleasant numbers. If the fonts are downloaded every time again, each time the user comes to the site and watches the font style change. From a UX point of view, not very good.
Care must be taken to ensure that fonts really remain in the cache. We used to rely on local storage, but now it’s more reasonable to rely on Service Workers. Because if I put something in Service Workers, then it will be there.
What else can be done? You can use unicode-range. Many people think that dynamic subsetting is happening, that is, we have a font, it is dynamically parsed, and only the specified part is loaded in unicode-range. This is actually not the case, and the entire font is loaded.
Indeed, this is useful when we have a unicode-range, for example, for Cyrillic and for English text. Instead of downloading a font that has English and Russian texts, we can split it into several parts and load Russian, if we have Russian text on the page, and do the same with English.
What else can be done? There is a cool thing to use always and everywhere - preload.
Preload makes it possible to load resources at the beginning of page loading, which in turn makes it less likely to block page rendering. This approach improves productivity.
We can also use font-display: optional. This is a new property in css. How does it work?
Font-display has several meanings. Let's start with block. This property sets the font lock for three seconds, during which the font is loaded, then the font is replaced and then directly displayed.
The swap property works almost the same, but with a few exceptions. The browser immediately draws the text in a spare font, and when the specified one loads, it will replace.
Fallback sets a short lock period of 100 ms, the replacement period will be 3 s, after which the font will be replaced. If the font has not been loaded during this time, the browser will draw the text with the spare font.
And finally we come to optional. The lock period is 100 ms, if during this time the font has not been loaded, the text is displayed immediately. If you have a slow connection, the browser may stop loading the font. When the font loads, you will still see the default font. To see the registered font, you must reload the page.
Level 4
There are many techniques that we used before http / 2, for example, concatenation, sprites, etc. But with the advent of http / 2, the need to use them disappeared, because unlike http / 1.1, the new version loads almost everything at once, and this is great, because you can use many additional features.
In theory, the transition to http / 2 promises us 64% (23% on mobile) faster page loading. But in practice, everything works more slowly.
If most of your target audience constantly visits the resource while on the bus, car, etc., then it is entirely possible that http / 1.1 will be in a better position.
Take a look at the test results below. It shows that in some situations, http / 1.1 is faster.
There are wonderful features in http / 2, for example, HPACK, which must be used always and everywhere, and server push as well. But there is a small problem. It arises depending on the browser and server. Suppose we load a page, we do not have any server push.
If the page reloads, then everything is in the cache.
But if we do server push, then our css will reach the user much faster.
But also this means that even if css is in the cache, they will still be forwarded.
That is, if you push a lot of files from the server, they will be downloaded many times.
Move on. There are some recommended limits on page load times. For example, for a mediocre device on android, it is five seconds. This is not so much, considering that we have, for example, 3G.
If you look at the recommended download size limit that you need to start rendering, which Google mentions, it’s 170 KB.
Therefore, when it comes to frameworks, we need to think about parsing, compilation, network quality, cost of runtime, etc.
There are various options for uploading files, for example, the classic way, which is a bit outdated - scout. We start the scout.js file, it is in html, we load it. Its task is to make the rest of the environment as cached as possible and at the same time to report changes in it in a timely manner.
This means that this file needs a short time to be stored in the cache, and if something changes in the environment, then scout immediately initiates the update. This is an effective way, because every time we do not need to load and replace html.
What to do with http / 2? After all, we know that we can send as many files as you like and there is no need to combine them into packages. Let's load 140 modules then, why not? This is actually a very bad idea. Firstly, if we have many files, and we do not use a library, for example gzip for compression, then the files will be larger. Secondly, browsers are not yet optimized for such workflows. As a result, we started experimenting and looking for the right amount, and it turned out that it was optimal to send about 10 packets.
Packages are best bundled based on the frequency of file updates: often updated in some packages, and rarely updated in others to avoid unnecessary downloads. For example, pack libraries with utilities, etc. Nothing special. So what to do with css, how to load it? Server push will not work here.
In the beginning, we all downloaded as minimized files, then we thought that some should be loaded into critical css, because we have only 14 KB, and they need to be downloaded as quickly as possible. We started to do loadCSS, write logic, then added display: none.
But it all looked somehow bad. In http / 2, we thought that it was necessary to split, minify and load all files. It turned out that the best option was the option in the image below.
Unusual! This option works well in Chrome, poorly in IE, in Firefox the work slowed down a bit, as they changed the rendering. Thus, we improved the speed of work by 120 ms.
If you look at working with progressive css and without. With progressive css, everything loads faster, but in parts, but without it, it’s slower, because css is located in header and blocks the page as js.
Level 5
And the last level, which I cannot but tell you about is Resource Hints. This is a great feature that allows you to do many useful things. Let's go through some of them.
Prefetch
Prefetch - tells the browser that we will need this or that file soon, and the browser loads it with low priority.
Prerender
Prerender - this function is no longer there, but it helped to do the page prerender earlier. Perhaps she will have an alternative ...
Dns-prefetch
Dns-prefetch also speeds up the page loading process. Using dns-prefetch assumes that the browser preloads the server address of the specified domain name.
Preconnect
Preconnect allows you to do preliminary handshake with the specified servers.
Preload
Preload - tells the browser which resources to preload with high priority. Preload can be used for scripts and fonts.
I remember in 2009 reading the article " Gmail for Mobile HTML5 Series: Reducing Startup Latency ", and it changed my views on the classic rules. See for yourself! We have a JS code, but we don’t need all of it now. So why don’t we comment out most of the JS code, and then, when necessary, uncomment and execute in eval?
And the reason they did this is because the average smartphone has a parsing time of 8-9 times longer than the last iPhone.
Let's look at the statistics. To parse 1 MB of code on an average phone, you need 4 s.
This is a lot! But we do not need 1 MB immediately. If we again look at the statistics, it turns out that sites use only 40% of the JS code from what they downloaded.
And we can use preload instead of eval for the same situations.
var preload = document.createElement("link");
link.href= "myscript.js" ;
link.rel= "preload";
link.as= "script";
document.head.appendChild(link);
That is, we store the file in the cache, and then, when necessary, we add it to the page.
So, this is only half of what Vitaly Friedman planned to share. The remaining chips and life hacks will be in the decoding of his second performance at HolyJS 2017 Moscow, which we will also prepare and post on our blog.
And if you love the inside of JS as much as we do, you will probably be interested in these reports at our May HolyJS 2018 Piter conference , the key of which we again set the story of Vitaliy Fridman:
- New Advenures In Front-End, Season 2 (Vitaliy Fridman, Smashing Magazine)
- RxJS: Performance and memory leaks in a large application (Evgeny Pozdnyakov Exadel)
- Mine crypto in the browser: WebWorkers, GPU, WebAssembly and other good things (Denis Radin, Evolution Gaming)
- JavaScript debugging using Chrome DevTools (Alexey Kozyatinsky, Google)
- What to expect from JavaScript in 2018? (Mikhail Poluboyarinov, Health Samurai)