Another option for generating thumbnails for images using AWS Lambda & golang + nodejs + nginx
Hello dear users of Habr!
My name is Nikita, at the moment I am working as a backend developer in the startup of a mobile application. Finally, I got a really non-trivial and quite interesting task, the solution of which I want to share with you.
What will the conversation actually be about? In the developed mobile application there is work with images. As you can easily guess: where there are pictures, there are likely to appear previews. Another condition, almost the first general task that was set for me: to make it all work and scale in the cloud on Amazon. If a little lyricism: there was a telephone conversation with a friend of a business partner in speakerphone mode, where I received a bunch of valuable directions whose main idea sounds simple: get away from server thinking. Well, ok, we’re leaving.
Image generation is a rather expensive operation in terms of resources. This backend section predictably showed itself poorly on such a kind of “load testing” that I conducted on a very dead VDS-ke with almost default LAMP settings, at least without additional tuning, where all non-optimized places will come out immediately and guaranteed. For this reason, I decided to remove this task away from the php backend. Let him do what gives a more or less uniform load, namely database queries, application logic and JSON responses, and the like, an uninteresting API routine. Those familiar with Amazon will say: what's the problem? Why it is impossible to configure scaling of EC2 instances in the automatic mode and leave this task in PHP? The answer is: "so microservice." But seriously - there are a lot of nuances in the context of the backend architecture that go beyond the scope of this article, so I will leave this question unanswered. Everyone will answer it in the context of their architecture, if it arises. I just want to offer a solution and you are welcome to cat.
Introductory: images are stored in the conditional s3 bucket.mydomain, hereinafter referred to everywhere as bucket. The contents of bucket are considered static and public, but listing is prohibited, so each object has a public-read ACL, while bucket itself is non public read, the file structure inside bucket looks like folder / subfolder / filename.ext.
This article does not fully describe the architecture of the file operation of the backend, only a part (simplified) is described here using an example with a preview for a photograph. The rest of the work of the backend with the file system is beyond the scope of this article.
I am a proponent of decisions when a picture of the right size is pre-generated and simply transferred from the file system. Although there was an experience of applying watermarkes dynamically (that is, the image was always generated in a new way) which showed quite good results (I expected more load than it turned out). Do not be directly afraid to make them dynamically, in this approach I also have the right to life, but on the whole I think the most optimal solution is when the preview is generated 1 time for some event and then is given from the file system, if it is there, in case if not, an attempt is made to generate it again. This gives a fairly good controllability and can be useful if the requirements for preview sizes suddenly change. This approach was implemented in the current task. But there is one important point - it is necessary to "agree" (possibly with yourself) on the uri-scheme. In my case (again, simplified again) it looks like this:
A new word preset has appeared , what is it? In the process of implementation, I thought, and if you parse the second uri segment for width / height, then it turns out you can dig a hole for yourself. And what will happen if some wise guy wants to go through the values of the second uri segment from 1 to over9000? On this, I agreed with other participants in the development process on the topic of what size previews are needed. It turned out several "presets" of different sizes whose name is passed as the second segment of uri. Again, returning to the issue of manageability, if for some reason you need to change the size of the preview, it will be enough to correct the environment variables in the prewmanager, which will be discussed a bit later and delete irrelevant files from the file system.
In general terms, the operation scheme looks like in the figure:
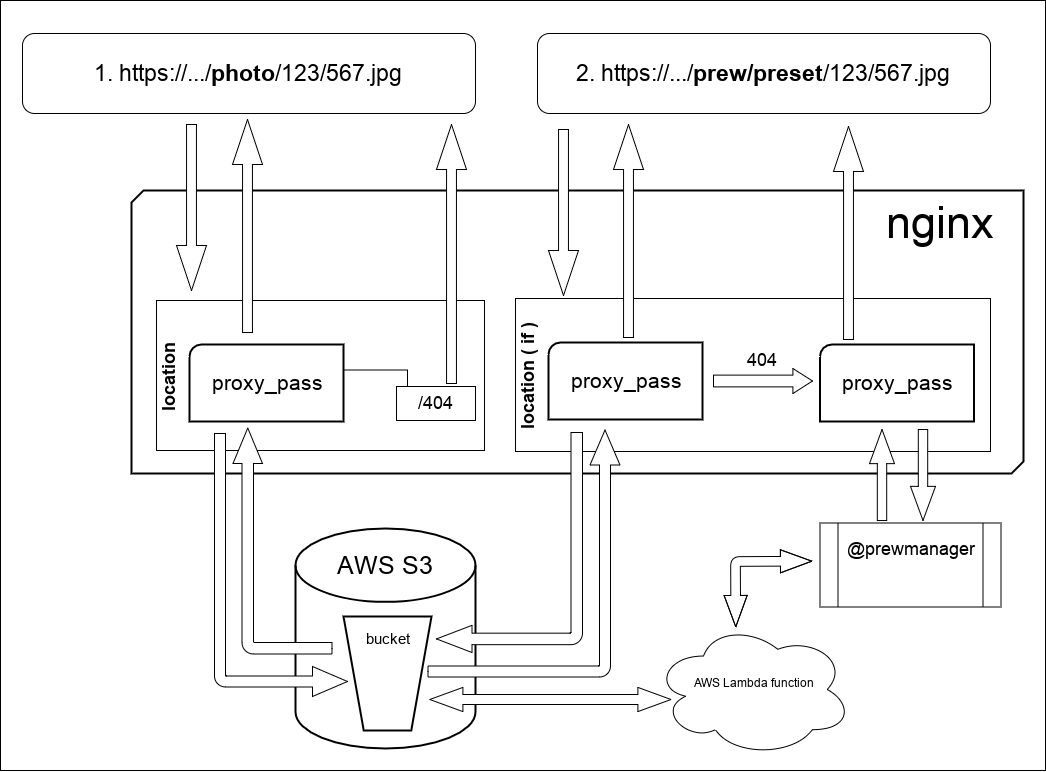
What happens here:
In request 1, which / photo / nginx proxies the request to s3. In principle, he does the same in request 2, since the files themselves and the preview are stored in one bucket since following the official AWS documentation, the number of objects inside a bucket is unlimited. But there is one difference, if is indicated on the diagram. He is engaged in changing the method of processing 403/404 responses from s3. By the way, about the 403 answer. The thing is that if you access the repository WITHOUT credentials (my case) i.e. actually having access ONLY to public-read objects, then due to the lack of listing rights (Amazon will give 403 instead of 404, this is due to the entry in the config: error_page 403 404 = 404 /404.jpg; A piece of the config where this work is described looks like this :
As you may have noticed, prewmanager is being proxied to some kind of network service. Here it is all the salt of this article. This service, written in nodejs, it runs aws lambda written in go, “blocks” further calls to the processed uri until the lambda function completes and gives the result of aws lambda to everyone who is waiting. Unfortunately, I can’t give the whole prewmanager code, so I’ll try to illustrate in separate sections (excuse me) the first fully functional version of the script. The production has a more beautiful version, but alas. However, nevertheless, in my opinion, this code is quite suitable for “understanding the logic of work” and it is possible to use it as a sketch.
Where did the radish come from and why? In this problem, I reasoned like this: since we are in a cloud where instances with radishes can be scaled as much as I like on the one hand, and on the other when the question arose about blocking repeated calls to functions with the same parameters, well, if not radish, which, moreover, already used in the project? Locally keep in mind and write nakoleochny "garbage collector"? Why, when can you just put this data (or the lock flag in the radish) with a certain lifetime and this wonderful tool will take care of all this. Well, it’s logical.
And finally, I will give the entire function code for AWS Lambda, which was written in Go. I ask you not to kick because it’s the third binarium after the “hello world” and the little things there that I wrote and compiled. Here is the link to githubwhere it is posted, I ask for pull requests if something is wrong. But in general, everything works, but as they say there is no limit to perfection. For the function to work, JSON-payload is required, if requests are received, I will add instructions on how to test the function on the github, an example of JSON-payload`a, etc.
A few words about configuring AWS Lambda: everything is simple there. Create a function, register enviroments, maximum time and memory allocation. Pour archive and use. But there is a nuance that is beyond the scope of this article: IAM is his name. The user, role, rights, too, will have to be configured, without this I'm afraid nothing will work.
In conclusion, I want to say that this system has already been tested in production, although I can’t boast of high-load loads, but in general there were no problems. In the context of the current political situation: yes, we were one of the first to fall under Amazon’s block. Literally on the first day. But they did not raise noise and distracted the work of lawyers, but set up nginx on a Russian hosting. In general, I believe that Amazon s3 is such a convenient, well-documented and maintained repository that because of the baldof brazzersMemas advisers and other non-surgeon surgeons should at least not abandon it. And here is the nginx config above, since all the statics on my subdomain are located, almost a line to a line with minimal changes was transferred to a server in the Russian Federation and during the course of a working day everyone forgot about it.
Thank you all for your attention.
My name is Nikita, at the moment I am working as a backend developer in the startup of a mobile application. Finally, I got a really non-trivial and quite interesting task, the solution of which I want to share with you.
What will the conversation actually be about? In the developed mobile application there is work with images. As you can easily guess: where there are pictures, there are likely to appear previews. Another condition, almost the first general task that was set for me: to make it all work and scale in the cloud on Amazon. If a little lyricism: there was a telephone conversation with a friend of a business partner in speakerphone mode, where I received a bunch of valuable directions whose main idea sounds simple: get away from server thinking. Well, ok, we’re leaving.
Image generation is a rather expensive operation in terms of resources. This backend section predictably showed itself poorly on such a kind of “load testing” that I conducted on a very dead VDS-ke with almost default LAMP settings, at least without additional tuning, where all non-optimized places will come out immediately and guaranteed. For this reason, I decided to remove this task away from the php backend. Let him do what gives a more or less uniform load, namely database queries, application logic and JSON responses, and the like, an uninteresting API routine. Those familiar with Amazon will say: what's the problem? Why it is impossible to configure scaling of EC2 instances in the automatic mode and leave this task in PHP? The answer is: "so microservice." But seriously - there are a lot of nuances in the context of the backend architecture that go beyond the scope of this article, so I will leave this question unanswered. Everyone will answer it in the context of their architecture, if it arises. I just want to offer a solution and you are welcome to cat.
Introductory: images are stored in the conditional s3 bucket.mydomain, hereinafter referred to everywhere as bucket. The contents of bucket are considered static and public, but listing is prohibited, so each object has a public-read ACL, while bucket itself is non public read, the file structure inside bucket looks like folder / subfolder / filename.ext.
This article does not fully describe the architecture of the file operation of the backend, only a part (simplified) is described here using an example with a preview for a photograph. The rest of the work of the backend with the file system is beyond the scope of this article.
I am a proponent of decisions when a picture of the right size is pre-generated and simply transferred from the file system. Although there was an experience of applying watermarkes dynamically (that is, the image was always generated in a new way) which showed quite good results (I expected more load than it turned out). Do not be directly afraid to make them dynamically, in this approach I also have the right to life, but on the whole I think the most optimal solution is when the preview is generated 1 time for some event and then is given from the file system, if it is there, in case if not, an attempt is made to generate it again. This gives a fairly good controllability and can be useful if the requirements for preview sizes suddenly change. This approach was implemented in the current task. But there is one important point - it is necessary to "agree" (possibly with yourself) on the uri-scheme. In my case (again, simplified again) it looks like this:
- / photo /some/file.jpg - give the source file
- / prew / preset /some/file.jpg - give preview for file.jpg
A new word preset has appeared , what is it? In the process of implementation, I thought, and if you parse the second uri segment for width / height, then it turns out you can dig a hole for yourself. And what will happen if some wise guy wants to go through the values of the second uri segment from 1 to over9000? On this, I agreed with other participants in the development process on the topic of what size previews are needed. It turned out several "presets" of different sizes whose name is passed as the second segment of uri. Again, returning to the issue of manageability, if for some reason you need to change the size of the preview, it will be enough to correct the environment variables in the prewmanager, which will be discussed a bit later and delete irrelevant files from the file system.
In general terms, the operation scheme looks like in the figure:
What happens here:
In request 1, which / photo / nginx proxies the request to s3. In principle, he does the same in request 2, since the files themselves and the preview are stored in one bucket since following the official AWS documentation, the number of objects inside a bucket is unlimited. But there is one difference, if is indicated on the diagram. He is engaged in changing the method of processing 403/404 responses from s3. By the way, about the 403 answer. The thing is that if you access the repository WITHOUT credentials (my case) i.e. actually having access ONLY to public-read objects, then due to the lack of listing rights (Amazon will give 403 instead of 404, this is due to the entry in the config: error_page 403 404 = 404 /404.jpg; A piece of the config where this work is described looks like this :
location / {
set$s3_bucket'bucket.s3.amazonaws.com';
set$req_proxy_str$s3_bucket$1;
error_page403404 =404 /404.jpg;
if ($request_uri~* /prew/(.*)){
error_page403404 = @prewmanager;
}
proxy_http_version1.1;
proxy_set_header Authorization '';
proxy_set_header Host $s3_bucket;
proxy_set_header X-Real-IP $remote_addr;
proxy_set_header X-Forwarded-For $proxy_add_x_forwarded_for;
proxy_hide_header x-amz-id-2;
proxy_hide_header x-amz-request-id;
proxy_hide_header Set-Cookie;
proxy_ignore_headers"Set-Cookie";
proxy_bufferingoff;
proxy_intercept_errorson;
proxy_pass http://$req_proxy_str;
}
location /404.jpg {
root /var/www/error/;
internal;
}
location@prewmanager {
proxy_pass http://prewnamager_host:8180;
proxy_redirect http://prewnamager_host:8180 /;
proxy_set_header Host $host;
proxy_set_header X-Forwarded-For $proxy_add_x_forwarded_for;
proxy_set_header X-Forwarded-Proto $scheme;
access_logoff ;
}
As you may have noticed, prewmanager is being proxied to some kind of network service. Here it is all the salt of this article. This service, written in nodejs, it runs aws lambda written in go, “blocks” further calls to the processed uri until the lambda function completes and gives the result of aws lambda to everyone who is waiting. Unfortunately, I can’t give the whole prewmanager code, so I’ll try to illustrate in separate sections (excuse me) the first fully functional version of the script. The production has a more beautiful version, but alas. However, nevertheless, in my opinion, this code is quite suitable for “understanding the logic of work” and it is possible to use it as a sketch.
// тут были requre, process.env.* и т.д.const lambda = new AWS.Lambda({...});
const rc = redis.createClient(...);
const getAsync = promisify(rc.get).bind(rc);
functionmake404Response(response) {
// тут берем с файловой системы картинку и отдаем с 404 кодом -- типовая задача
}
functionmakeErrorResponse(response) {
// аналогично функции выше только картинка другая
}
// AWS Lambda возвращает в base64 данные картинки и content-typefunctionmakeResultResponse(response, response_payload) {
let buff = new Buffer(response_payload.data, 'base64');
response.statusCode = 200;
response.setHeader('Content-Type', response_payload.content_type);
response.end(buff);
return;
}
http.createServer(asyncfunction(request, response) {
// тут был разбор uri, генерация строкового ключа для редиса и т.д.// для redis, если ключа нет (null) значит необходимо запускать работу AWS lambda// и устанавливаем блокировку чтобы не запускалась функция дважды и более раз на данный запрос// если ключ есть -- дожидаемся ответа через функциюlet reply = false;
try {
reply = await getAsync(redis_key);
} catch (err) { }
if(reply === null) {
// ставим блокировку на 30 секунд
rc.set(redis_key, 'blocked', 'EX', 30);
// и выполняем операции в ламбде// пресеты, если требуемого пресета нет -- 404switch (preset) {
case"preset_name_1":
var request_payload = {
src_key: "photo/" + aws_ob_key,
src_bucket: src_bucket,
dst_bucket: dst_bucket,
root_folder: dst_root,
preset_name: preset,
rewrite_part: "photo",
width: 1440
};
var params = {
FunctionName: "my_lambda_function_name",
InvocationType: "RequestResponse",
LogType: "Tail",
Payload: JSON.stringify(request_payload),
};
lambda.invoke(params, function(err, data) {
if (err) {
makeErrorResponse(response);
} else {
rc.set(redis_key, data.Payload, 'EX', 30);
let response_payload = JSON.parse(data.Payload);
if(response_payload.status == true) {
makeResultResponse(response, response_payload);
} else {
console.log(response_payload.error);
makeErrorResponse(response);
}
}
});
break;
...
default:
make404Response(response);
}
} elseif (reply === false) {
// это если редис не отзывается
makeErrorResponse(response);
} else {
// тут в нормальной ситуации возможны 2 варианта// когда уже запрос выполняется -- blocked// когда он уже выполнился, т.е. есть данныеif(reply == 'blocked') {
let res;
let i = 0;
const intervalId = setInterval(asyncfunction() {
try {
res = await getAsync(redis_key);
} catch (err) { }
if (res != null && res != 'blocked') {
let response_payload = JSON.parse(res);
if(response_payload.status == true) {
makeResultResponse(response, response_payload);
} else {
console.log(response_payload.error);
makeErrorResponse(response);
}
clearInterval(intervalId);
} else {
i++;
// вечно это продолжаться не должноif(i > 100) {
makeErrorResponse(response);
clearInterval(intervalId);
}
}
}, 500);
}
}
}).listen(port);
Where did the radish come from and why? In this problem, I reasoned like this: since we are in a cloud where instances with radishes can be scaled as much as I like on the one hand, and on the other when the question arose about blocking repeated calls to functions with the same parameters, well, if not radish, which, moreover, already used in the project? Locally keep in mind and write nakoleochny "garbage collector"? Why, when can you just put this data (or the lock flag in the radish) with a certain lifetime and this wonderful tool will take care of all this. Well, it’s logical.
And finally, I will give the entire function code for AWS Lambda, which was written in Go. I ask you not to kick because it’s the third binarium after the “hello world” and the little things there that I wrote and compiled. Here is the link to githubwhere it is posted, I ask for pull requests if something is wrong. But in general, everything works, but as they say there is no limit to perfection. For the function to work, JSON-payload is required, if requests are received, I will add instructions on how to test the function on the github, an example of JSON-payload`a, etc.
A few words about configuring AWS Lambda: everything is simple there. Create a function, register enviroments, maximum time and memory allocation. Pour archive and use. But there is a nuance that is beyond the scope of this article: IAM is his name. The user, role, rights, too, will have to be configured, without this I'm afraid nothing will work.
In conclusion, I want to say that this system has already been tested in production, although I can’t boast of high-load loads, but in general there were no problems. In the context of the current political situation: yes, we were one of the first to fall under Amazon’s block. Literally on the first day. But they did not raise noise and distracted the work of lawyers, but set up nginx on a Russian hosting. In general, I believe that Amazon s3 is such a convenient, well-documented and maintained repository that because of the bald
Thank you all for your attention.