Snippet vs Clover - we beat the most popular quiz in real time
April 2018. I was 14. My friends and I played the very popular online quiz “Clover” from VKontakte. One of us (usually me) was always behind the laptop in order to try to quickly google questions and look for the right answer in search results. But suddenly I realized that I was performing the same action every time, and decided to try to write it in Python 3, which was partially known to me then.
For a start, I will refresh in your memory the clover mechanic.
The game for all begins at the same time - at 13:00 and at 20:00 Moscow time. To play, you need to go into the app at this time and connect to the live broadcast. The game lasts 15 minutes, during which the participants are simultaneously answered questions on the phone . The answer is given 10 seconds. Then the correct answer is announced. All who guessed pass on. There are 12 questions in total, and if you answer everything, you will receive a cash prize.
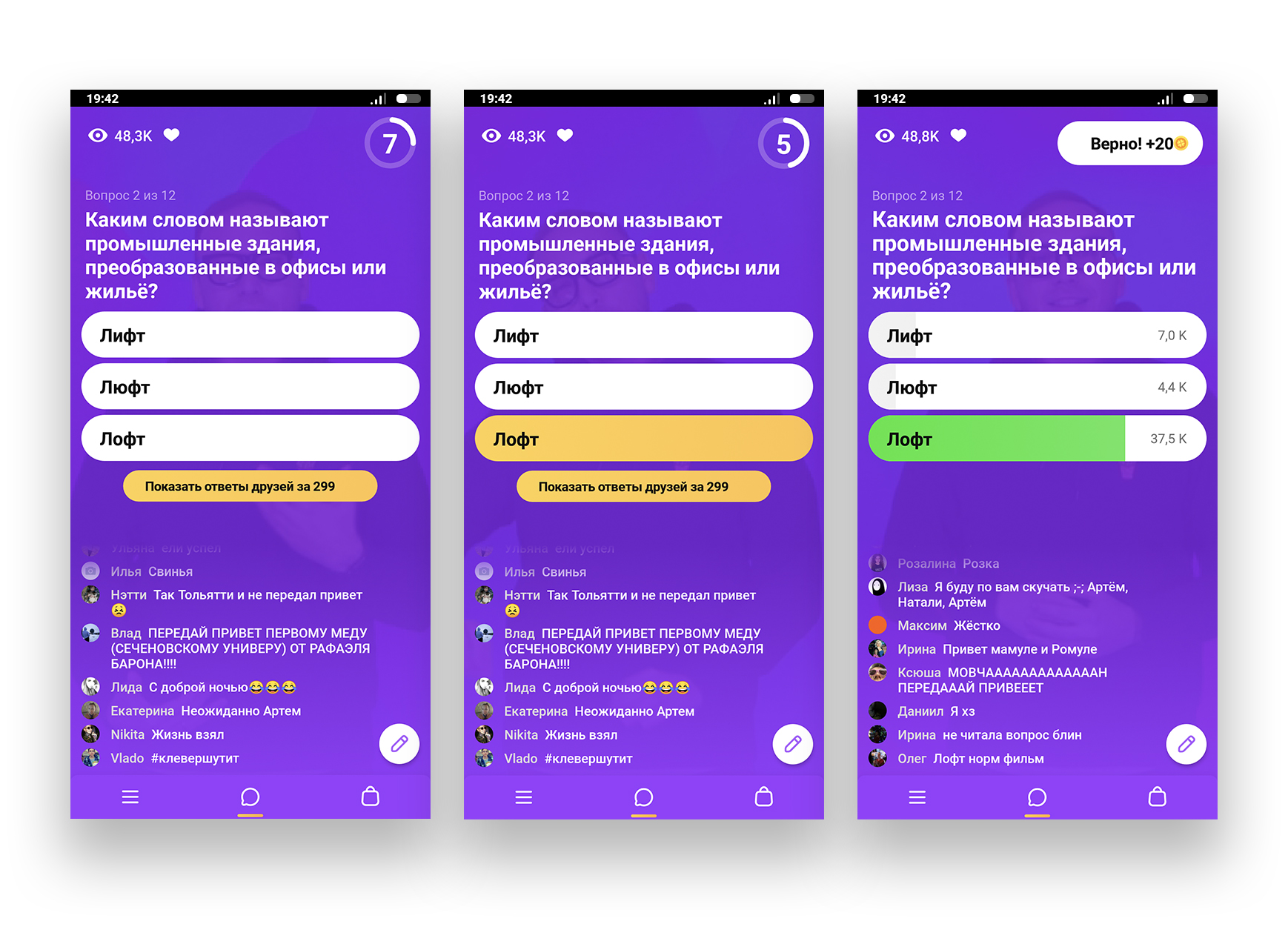
It turns out, our task is to instantly catch new questions from the Clover server, process them through any search engine, and determine the correct answer based on the results of the issue. It was decided to output the answer in a telegram bot, so that notifications from it would pop up on the phone during the game. And all this is desirable for a couple of seconds, because the response time is very limited. If you want to see how fairly simple, but the working code (and it will be useful for newbies to look at it) helped us beat Clover, welcome under the cat.
At first it seemed the most difficult stage. I already took a deep breath and was ready to climb into the wilds like computer vision, intercepting traffic or decompiling the application ... Suddenly a surprise was waiting for me - Klever had an open API! It is not documented anywhere, but if during the game, as soon as all the players were asked a question, make a request to api.vk.com, then in response we will receive the asked question and answer options to it in JSON:
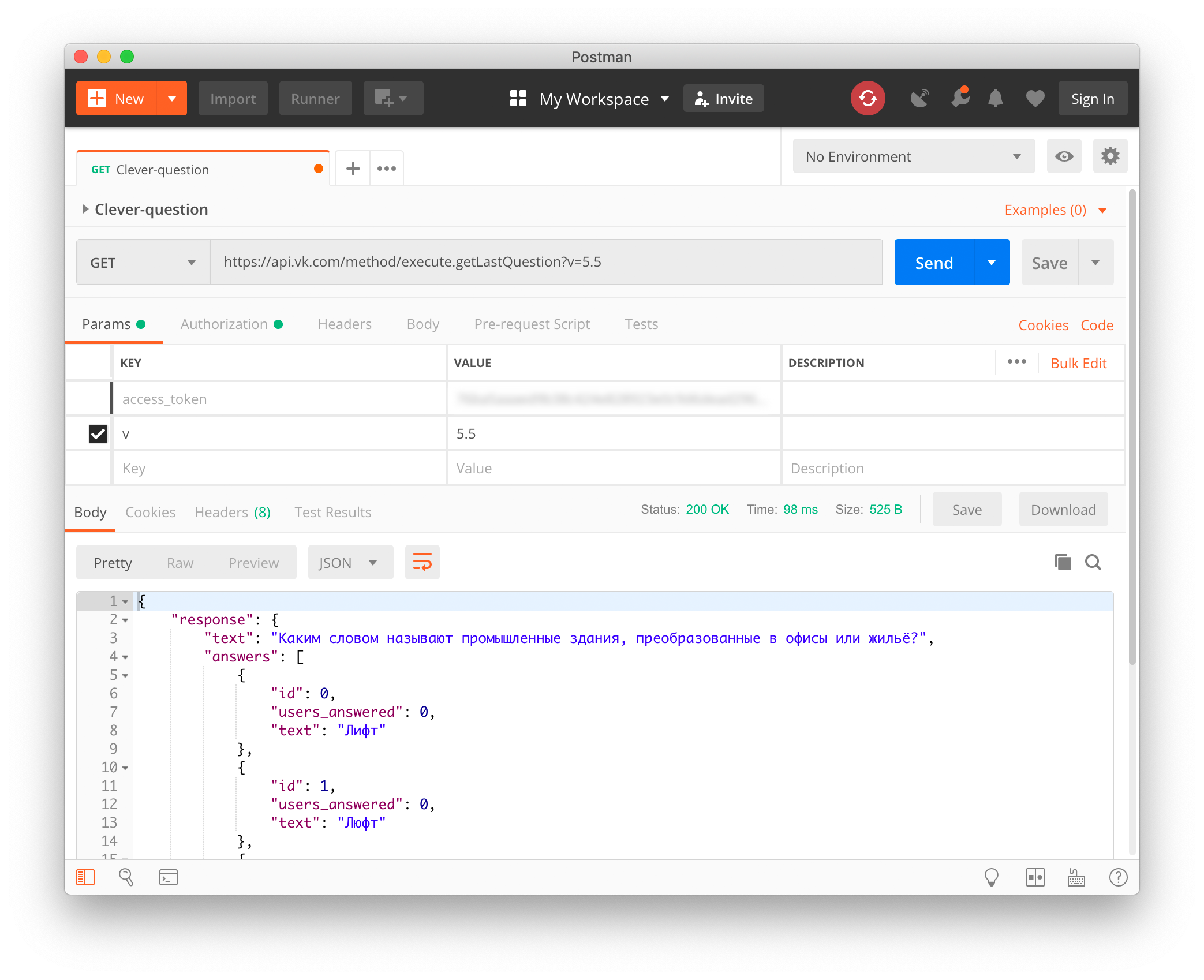
As an access_token, it is necessary to transfer an API token to any VKontakte user, but it is important that it was originally written out specifically for Clover. Its app_id is 6334949.
There were two options: use the official API of search engines or add search arguments directly to the address bar, and parse the results. At first I tried the second one, but not only did I sometimes catch captcha, I also lost a lot of time, because the pages were loaded on average in 2 seconds. And I remind you that it is desirable for us to keep within these two seconds. Well and the main thing - I did not receive from search engines large and structured texts on the desired topic, since only small pieces of the necessary material, which are called snippets, hang on the search page :

Therefore, I started looking for an API. Google didn’t fit - their solutions were very limited and returned very little data. The most generous was Yandex.XML- it permits to send 10,000 requests per day, not more than 5 per second, and returns data very quickly. In the request to it, the number of pages (up to 100) and the number of passages are special values that are used to form snippets. We receive the data in XML. However, these are all the same snippets.
So that you can read and play with what Yandex returns, here is an example of the answer to the query “What is the name of the main antagonist in the video game series The Legend of Zelda?”: Yandex. Drive .
I was lucky, and it turned out that in pypi under this already exists a separate module yandex-search . And so, I tried to get the question from the server, find it in Yandex, from the snippets to make one big text and break it into sentences:
Initially, the task to accurately recognize the answer by snippets seemed unreal to me (I remind you that at the time of writing the code I was an absolute novice). Therefore, I decided to first simplify the task that we performed during the manual search.
What did my friends and I do when we drove our question into a search engine? They began to quickly look for answers in the results. What is the problem with this approach? Inmnogabukv the presence of a large number of unnecessary, not containing information about the answers, suggestions. Sometimes I had to look for the eyes for a long time. Therefore, the first thing I decided to do was to highlight all the sentences mentioning any of the answers and display them on the screen, so that we would look for the answer in a very small text that accurately contains the information we need.
It would seem, get the necessary sentences, read them and answer correctly. But what to do if we did not find a single sentence? In this case, I decided to cut the words so as not to lose them if they are in a different case. And to capture those that are formed from the original. In short, I just cut off their ending by two characters:
But even after such a safety net, there were still cases where the hint remained empty, simply because the results did not always at least somehow affect the answers. For example, the question “Which of these writers has a story, named the same as the song of group Bi 2?” Cannot be answered accurately. In this case, I resorted to the opposite approach - inquired on the answers and deduced the option based on how often the words from the question are mentioned in the results.
At this point, the script has gained basic functionality. And now, after just a week and a half after the release of Clover, we are sitting and already playing with such samopisny "cheat". You should see our faces with a friend when we first won the game , reading the magic of the sentences that appear on the command line!
But soon this format is tired. First, it was necessary to sit on each game with a laptop. Secondly, the script was asked by friends, and I was tired of explaining to everyone how to insert their VK token, how to configure Yandex.XML (it is tied to IP, that is, it was necessary to create an account for each user of the script) and how to install python on the computer.
It would be much better if the answers appeared in push notifications on the phone during the game! Just looked at the top of the screen and responded as written in the push notification! And you can organize it for everyone, if you create your telegram channel for the script! Wonderful!
But simply displaying the same sentences in telegrams is not an option. Reading them from the phone is extremely inconvenient. So I had to learn the script myself to understand which answer is correct.
Import telebotand we change all the print () functions to send_tg () and notsure () , which we will use in the last method, since it misses more often than the others:
And at this moment I realized that snippets are much better suited for detailed texts! Because the search engine is trying very hard to give an answer to our query, and not just to find matches by words. And he succeeds - snippets often contained correct answers than incorrect ones, that is, there was no need to analyze the text. Yes, and I, in fact, did not know how.
So uncomplicatedly count the references to the words in the results:
What happened in the end:

For the sake of justice, I must say that the death machine did not work for me. On average, the bot answered correctly only 9-10 questions out of 12. It is understandable, because there were tricky ones who did not succumb to the Yandex search parsing. I, and my friends, are tired of constantly flying over a couple of questions and waiting for a successful game in which the bot will finally answer everything correctly. A miracle did not happen, the script was no longer wanted to be finalized, and then we, having ceased to hope for an easy victory, abandoned the game.
Over time, my idea began to creep into the heads of other young developers. By the end of 2018, there were at least 10 bots and sites displaying their insights on the issues in Klever. The task is not so difficult. But surprisingly, none of them have crossed the bar to 9-10 questions per game, and later everyone fell to 7-8, like my bot. Apparently, the drafters of the questions cut through how to make up the questions so that the work of the search engines would be irrelevant.
Unfortunately, the bot is no longer finalized, because on December 31, Clover spent the last broadcast, but I have not saved any questions. However, it was a great experience for a novice programmer. And surely there would be a great challenge for an advanced one - just imagine the word2vec and text2vec duet, asynchronous requests to Yandex, Google and Wikipedia at the same time, an advanced question classifier and an algorithm to reformulate the question in case of failure ... Eh! Perhaps for such opportunities I loved this game more than the gameplay itself.
Step 0. What's happening here
For a start, I will refresh in your memory the clover mechanic.
The game for all begins at the same time - at 13:00 and at 20:00 Moscow time. To play, you need to go into the app at this time and connect to the live broadcast. The game lasts 15 minutes, during which the participants are simultaneously answered questions on the phone . The answer is given 10 seconds. Then the correct answer is announced. All who guessed pass on. There are 12 questions in total, and if you answer everything, you will receive a cash prize.
It turns out, our task is to instantly catch new questions from the Clover server, process them through any search engine, and determine the correct answer based on the results of the issue. It was decided to output the answer in a telegram bot, so that notifications from it would pop up on the phone during the game. And all this is desirable for a couple of seconds, because the response time is very limited. If you want to see how fairly simple, but the working code (and it will be useful for newbies to look at it) helped us beat Clover, welcome under the cat.
Step 1. Get questions from the server
At first it seemed the most difficult stage. I already took a deep breath and was ready to climb into the wilds like computer vision, intercepting traffic or decompiling the application ... Suddenly a surprise was waiting for me - Klever had an open API! It is not documented anywhere, but if during the game, as soon as all the players were asked a question, make a request to api.vk.com, then in response we will receive the asked question and answer options to it in JSON:
https://api.vk.com/method/execute.getLastQuestion?v=5.5&access_token=VK_USER_TOKENAs an access_token, it is necessary to transfer an API token to any VKontakte user, but it is important that it was originally written out specifically for Clover. Its app_id is 6334949.
Step 2. We process the question through a search engine
There were two options: use the official API of search engines or add search arguments directly to the address bar, and parse the results. At first I tried the second one, but not only did I sometimes catch captcha, I also lost a lot of time, because the pages were loaded on average in 2 seconds. And I remind you that it is desirable for us to keep within these two seconds. Well and the main thing - I did not receive from search engines large and structured texts on the desired topic, since only small pieces of the necessary material, which are called snippets, hang on the search page :
Therefore, I started looking for an API. Google didn’t fit - their solutions were very limited and returned very little data. The most generous was Yandex.XML- it permits to send 10,000 requests per day, not more than 5 per second, and returns data very quickly. In the request to it, the number of pages (up to 100) and the number of passages are special values that are used to form snippets. We receive the data in XML. However, these are all the same snippets.
So that you can read and play with what Yandex returns, here is an example of the answer to the query “What is the name of the main antagonist in the video game series The Legend of Zelda?”: Yandex. Drive .
I was lucky, and it turned out that in pypi under this already exists a separate module yandex-search . And so, I tried to get the question from the server, find it in Yandex, from the snippets to make one big text and break it into sentences:
import requests as req
import yandex_search
import json
apiurl = "https://api.vk.com/method/execute.getLastQuestion?access_token=VK_USER_TOKEN&v=5.5"
clever_response = (json.loads(req.get(apiurl).content))["response"]
# {'text': 'Какой из этих мультфильмов первым получил премию Оскар в номинации «Лучший анимационный полнометражный фильм»?', 'answers': [{'id': 0, 'users_answered': 0, 'text': '«История игрушек»'}, {'id': 1, 'users_answered': 0, 'text': '«Корпорация монстров»'}, {'id': 2, 'users_answered': 0, 'text': '«Шрек»'}], 'stop_time': 0, 'is_first': 0, 'is_last': 1, 'number': 12, 'id': 22, 'sent_time': 1533921436}
question = str(clever_response["text"])
ans1, ans2, ans3 = str(clever_response["answers"][0]["text"]).lower(), str(clever_response["answers"][1]["text"]).lower(), str(clever_response["answers"][2]["text"]).lower()
defyandexfind(question):
finded = yandex.search(question).items
snips = ""for i in finded:
snips += (i.get("snippet")) + "\n"return snips
items = yandexfind(question)
itemslist = list(items.split(". "))Step 3. Looking for answers
Initially, the task to accurately recognize the answer by snippets seemed unreal to me (I remind you that at the time of writing the code I was an absolute novice). Therefore, I decided to first simplify the task that we performed during the manual search.
What did my friends and I do when we drove our question into a search engine? They began to quickly look for answers in the results. What is the problem with this approach? In
hint = [] #Список предложений, содержащих один из вариантов ответаfor sentence in itemslist: #Чекаем каждое предложение из сниппетовif (ans1 in sentence) or (ans2 in sentence) or (ans3 in sentence):
hint.append(sentence)
if len(hint) > 4:
breakIt would seem, get the necessary sentences, read them and answer correctly. But what to do if we did not find a single sentence? In this case, I decided to cut the words so as not to lose them if they are in a different case. And to capture those that are formed from the original. In short, I just cut off their ending by two characters:
if len(hint) == 0:
defcut(string):if len(string) > 2:
return string[0:-2]
else:
return string
short_ans1, short_ans2, short_ans3 = cut(ans1), cut(ans2), cut(ans3)
for pred in itemslist: #Чекаем каждое предложение из сниппетовif (short_ans1 in pred) or (short_ans2 in pred) or (short_ans3 in pred)
hint.append(pred)But even after such a safety net, there were still cases where the hint remained empty, simply because the results did not always at least somehow affect the answers. For example, the question “Which of these writers has a story, named the same as the song of group Bi 2?” Cannot be answered accurately. In this case, I resorted to the opposite approach - inquired on the answers and deduced the option based on how often the words from the question are mentioned in the results.
if len(hint) == 0:
questionlist = question.split(" ")
blacklist = ["что", "такое", 'как', 'называется', 'в', 'каком', 'году', 'для', 'чего', 'какой', 'какого', 'кого', 'кто', 'зачем', 'является', 'самым', 'большим', 'маленьким', 'из', 'этого', 'входит', 'этих', 'кого', 'у', 'а', 'сколько']
for w in questionlist:
if w in blacklist:
questionlist.remove(w)
yandex_ans1 = yandexfind(ans1)
yandex_ans2 = yandexfind(ans2)
yandex_ans3 = yandexfind(ans3)
#Чуть позже я сделал этот процесс асинхронным, но это было костыльно
count_ans1, count_ans2, count_ans3 = 0, 0, 0for w in questionlist:
count_ans1 += yandex_ans1.count(w)
count_ans2 += yandex_ans2.count(w)
count_ans3 += yandex_ans3.count(w)
if (count_ans1 + count_ans2 + count_ans3) > 5:
if count_ans1 > (count_ans2 + count_ans3):
print(ans1)
elif count_ans2 > (count_ans1 + count_ans3):
print(ans2)
elif count_ans3 > (count_ans2 + count_ans1):
print(ans3)
At this point, the script has gained basic functionality. And now, after just a week and a half after the release of Clover, we are sitting and already playing with such samopisny "cheat". You should see our faces with a friend when we first won the game , reading the magic of the sentences that appear on the command line!
Step 4. Conclusion of clear answers.
But soon this format is tired. First, it was necessary to sit on each game with a laptop. Secondly, the script was asked by friends, and I was tired of explaining to everyone how to insert their VK token, how to configure Yandex.XML (it is tied to IP, that is, it was necessary to create an account for each user of the script) and how to install python on the computer.
It would be much better if the answers appeared in push notifications on the phone during the game! Just looked at the top of the screen and responded as written in the push notification! And you can organize it for everyone, if you create your telegram channel for the script! Wonderful!
But simply displaying the same sentences in telegrams is not an option. Reading them from the phone is extremely inconvenient. So I had to learn the script myself to understand which answer is correct.
Import telebotand we change all the print () functions to send_tg () and notsure () , which we will use in the last method, since it misses more often than the others:
defsend_tg(ans):
bot.send_message("@autoclever", str(ans).capitalize())
print(str(ans))
returndefnotsure(ans):
send_tg(ans.capitalize() + ". Это неточно!")
hint.append("WE TRIED!")
And at this moment I realized that snippets are much better suited for detailed texts! Because the search engine is trying very hard to give an answer to our query, and not just to find matches by words. And he succeeds - snippets often contained correct answers than incorrect ones, that is, there was no need to analyze the text. Yes, and I, in fact, did not know how.
So uncomplicatedly count the references to the words in the results:
anscounts = {
ans1: 0,
ans2: 0,
ans3: 0
}
for s in hint:
for a in [ans1, ans2, ans3]:
anscounts[a] += s.count(a)
right = (max(anscounts, key=anscounts.get))
send_tg(right)
#Ура!What happened in the end:
Further fate
For the sake of justice, I must say that the death machine did not work for me. On average, the bot answered correctly only 9-10 questions out of 12. It is understandable, because there were tricky ones who did not succumb to the Yandex search parsing. I, and my friends, are tired of constantly flying over a couple of questions and waiting for a successful game in which the bot will finally answer everything correctly. A miracle did not happen, the script was no longer wanted to be finalized, and then we, having ceased to hope for an easy victory, abandoned the game.
Over time, my idea began to creep into the heads of other young developers. By the end of 2018, there were at least 10 bots and sites displaying their insights on the issues in Klever. The task is not so difficult. But surprisingly, none of them have crossed the bar to 9-10 questions per game, and later everyone fell to 7-8, like my bot. Apparently, the drafters of the questions cut through how to make up the questions so that the work of the search engines would be irrelevant.
Unfortunately, the bot is no longer finalized, because on December 31, Clover spent the last broadcast, but I have not saved any questions. However, it was a great experience for a novice programmer. And surely there would be a great challenge for an advanced one - just imagine the word2vec and text2vec duet, asynchronous requests to Yandex, Google and Wikipedia at the same time, an advanced question classifier and an algorithm to reformulate the question in case of failure ... Eh! Perhaps for such opportunities I loved this game more than the gameplay itself.