Use AWS spot instances efficiently
Spot instances are essentially selling resources that are currently free at a great discount. Moreover, the instance can be turned off and taken back at any time. In this article, I will talk about the features and practice of working with this offer from AWS.
The cost of using a spot instance may change from time to time. During the order you place a bid - indicate the maximum price that you are willing to pay for use. It is the balance of rates and free resources that forms the final cost, which at the same time differs in different regions and even in the availability zones of the region.
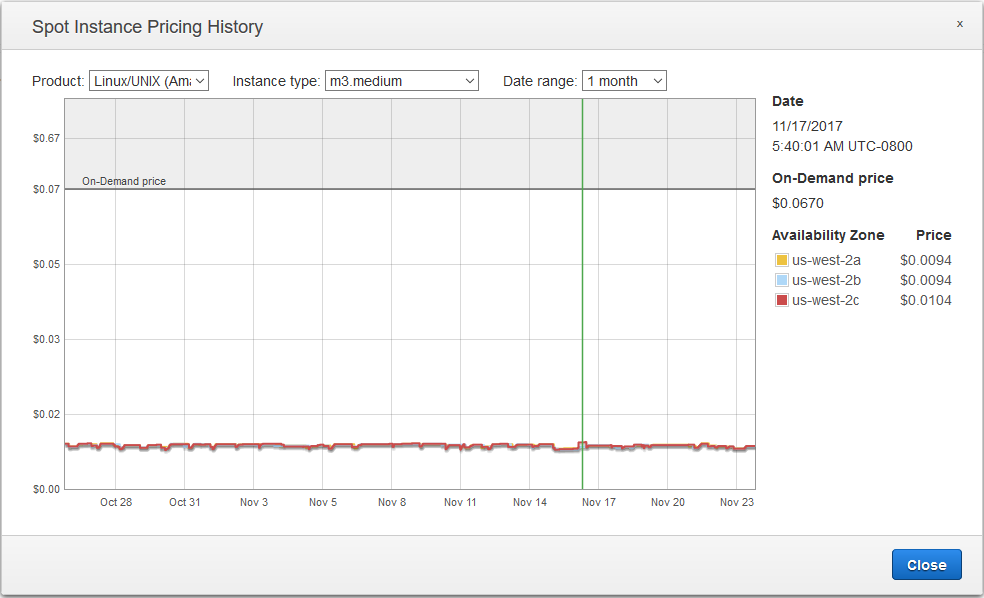
At some point, a weighted price may exceed the price of a regular on-demand instance. That is why you should not make excessive bets - you can really be sold an instance for $ 1000 per hour. If you don’t know what kind of bid to make, indicate the price of the on-demand instance (it is used by default).
Spot Instance Life Cycle
So, we form a request, and AWS gives us instances. As soon as Amazon needs the issued instances or the price exceeds the limit we specified, the request closes. This means that our instances will be terminated / hibernated.
Also, the request may be closed due to an error in the request. And here you need to be careful. For example, you created a request and received instances. And then they removed the associated IAM role. Your request will close with the status “error”. This will stop the instances.
And of course, you can cancel the request at any time, which will also lead to the suspension of instances.
The request itself may be:
- One-time - as soon as the instances were taken from us, the request is closed
- Permanent - instances are returned to us after re-inclusion.
- With guaranteed service for 1-6 hours.
As a result, we have two main tasks for the service with the desired 100% uptime:
- Generate optimal spot-requests
- Handle instance shutdown events
Facilities
One of the most powerful spot query tools is spot fleet. It allows you to dynamically form queries in such a way as to satisfy the given conditions. For example, if the instances have risen in price in one AvailabilityZone, then you can quickly launch the same in another. Also there is such a wonderful factor as the “weight” of the instance. For example, to complete a task, we need 100 single-core nodes. Or 50 dual-core. And that means, on the example of T2-type instances, that we can use 100 small or 50 large or 25 xlarge. It is the optimal distribution and redistribution that minimizes both the cost and the likelihood that the request will be unsatisfied. However, there is still a possibility that in all AvailabilityZones there will not be the right number of instances with our parameters.
Fortunately, AWS leaves us 2 minutes between deciding to stop and shutting down ourselves. Namely, this moment the shutdown timer will start returning from the link:
http://169.254.169.254/latest/meta-data/spot/termination-timeSomething like this would look like a simple handler that we can run as a daemon:
#!/usr/bin/env bash
while true
do
if [ -z $(curl -Is http://169.254.169.254/latest/meta-data/spot/termination-time | head -1 | grep 404 | cut -d \ -f 2) ]
then
echo “Instanсe is going to be terminated soon”
# Execute pre-shutdown stuff
break
else
# Spot instance is fine.
sleep 5
fi
doneLet's complicate the task a bit - our instances are connected to the Elastic Load Balancer (ELB). You can use the daemon from the snippet above and through the API inform the balancer of the status. But there is a more elegant way - SeeSpot project . In short, the daemon looks at both / spot / termination-time and, optionally, in the healthcheck url of your service. As soon as AWS is about to withdraw the instance, it is marked as OutOfService in the ELB and can optionally complete the final CleanUP task.
So, we figured out how to handle the shutdown correctly. It remains only to learn how to maintain the required system performance if we suddenly decided to pick up the instances. The autospotting project will help us here.. The idea is this: we create a regular autoscaling group containing on-demand instances. The autospotting script finds these instances and one by one replaces them with the fully appropriate spot instances (the search is done by tag). Autoscaling groups have their own Healthcheck. As soon as one of its members fails the test, the group tries to regain its volume and creates a “healthy” instance of the original type (which was on-demand). This way we can wait, for example, a price hike. As soon as spot-requests begin to be satisfied again, autospotting will begin a gradual replacement. I’ll add on my own that the project has been made quite qualitatively, and has, among other things, approaches for configuration using terraform or cloudformation.
In conclusion, I would like to recommend using spot instances for stateless services whenever possible. Or use S3 / EFS. For ECS configurations, you need to think about tasks re-balancing.