Overview of cases of interesting Big Data implementations in companies in the financial sector
Case Studies on Big Data
in Financial Sector Companies
 Why this article?
Why this article? This review discusses cases of implementation and application of Big Data in real life using the example of "live" projects. For some, especially interesting, in every sense, cases I dare to give my comments.
The range of cases reviewed is limited to examples presented publicly on the Cloudera website .
What is Big Data?
 There is a joke in technical circles that Big Data is data for which Excel 2010 on a powerful laptop is not enough. That is, if to solve the problem you need to operate with 1 million rows per sheet or more or 16 thousand columns or more, then congratulations, your data is classified as "Big".
There is a joke in technical circles that Big Data is data for which Excel 2010 on a powerful laptop is not enough. That is, if to solve the problem you need to operate with 1 million rows per sheet or more or 16 thousand columns or more, then congratulations, your data is classified as "Big". Among the many more stringent definitions, we give, for example, the following: “Big data” - data sets that are so voluminous and complex that the use of traditional processing tools is impossible. The term usually characterizes the data over which the methods of predictive analytics or other methods of extracting value from the data are applied and rarely correlates only with the amount of data.
Wikipedia Definition: Big data is the designation of structured and unstructured data of huge volumes and significant variety, effectively processed by horizontally scaled (English scale-out) software tools that appeared in the late 2000s and are alternative to traditional database management systems Business Intelligence class data and solutions.
Big Data Analytics
That is, in order to get the effect of the data, it is necessary to process, analyze and extract from this data valuable information, preferably a predictive property (that is, in other words, try to look and predict the future).
Analysis and extraction of valuable information from data or simply “Big Data Analytics” is implemented through analytical models.
The quality of models or the quality of identifying dependencies in the available data is largely determined by the amount and variety of data on which a particular model works or is "trained" by the
Big Data Infrastructure. Technological platform for storing and processing data
If you ignore exceptions, the main rule of Big Data Analytics is that the more and more diverse the data, the better the quality of the models. Quantity goes into quality. The issue of growing technological capacities for storing and processing large amounts of data is an acute issue. The corresponding power is provided by a combination of computing clusters and GPU graphics accelerators.
Big Data Infrastructure. Data collection and preparation
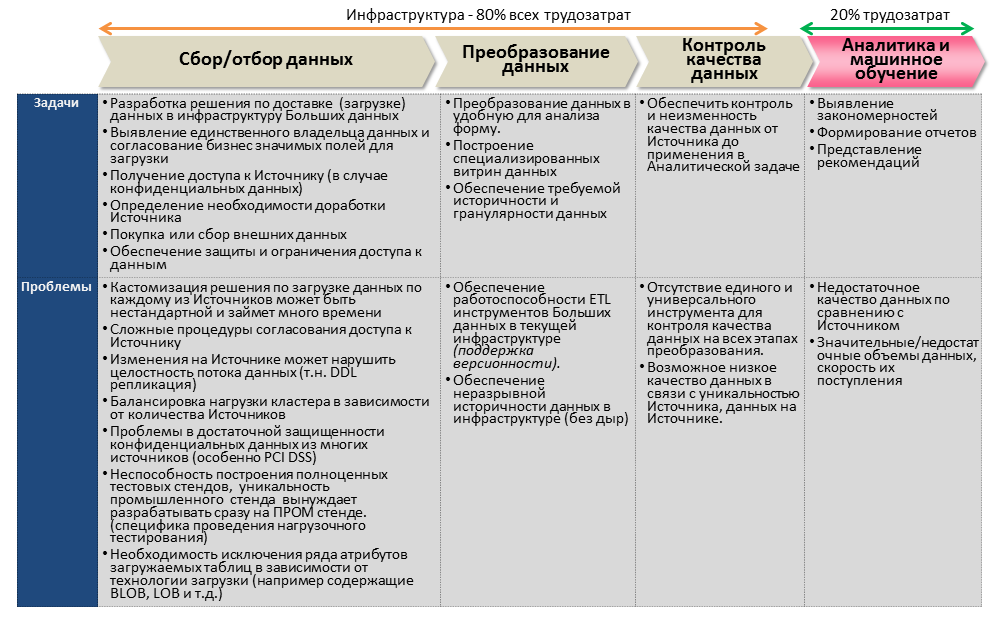
According to the book "Big Data: A Revolution That Will Transform How We Live, Work, and Think" by Viktor Mayer-Schönberger, up to 80% of all the labor involved in implementing Big Data projects falls on infrastructure tasks to provide a technological platform, platform , data collection and transformation, data quality control. And only 20% - directly to the Analytics itself, modeling and machine learning.
Case Studies of Big Data in Financial Sector Companies


1. Intercontinental Exchange (ICE),
New York Stock Exchange (NYSE) - Exchange
Link to the case
Link to the company Company
description
ICE - provides the largest platform for trading futures, stocks and options, provides clearing and data services. NYSE
Project theme: # Infrastructure, # Compliance, # Data management.
Project goal:
The Exchange generates huge data sets in the course of its work, the use of this data is critical for optimizing and meeting the ever-growing demands of the market and customers. Once there came a time when the existing DataLake infrastructure did not allow timely processing of new and existing data, there was a problem of data separation (data silos).
According to the results of the project:
The updated technology platform (Cloudera Enterprise DataHub) provides internal and external users access to more than 20 petabytes of real-time data (30 terabytes is added daily), thereby improving the process of monitoring the market situation and monitoring compliance with the rules for trading its members (Compliance). The Legacy database was replaced by the Apache Impala CDH product, which allowed data subscribers to analyze the contents of DataLake.
Comment:
The theme of the case is interesting and undoubtedly in demand. Many sites generate real-time data streams that require operational analytics.
The case is exclusively infrastructural, not a word is said about analytics. The case description does not say anything about the timing of the project, the difficulties in switching to new technologies. In general, it would be interesting to study the details and get to know the participants.

2. Cartao Elo - a company for the production and maintenance of plastic cards in Brazil
Case
Link Company Link Company
Description:
Cartao Elo is a company that owns 11% of all issued plastic payment cards in Brazil, with more than one million transactions per day.
Project theme: #Infrastructure, #Marketing, #Business development.
Objective of the project:
The company has set a goal to bring customer relationships to the level of personalized offers. Even to be able to predict the wishes of customers for a short period of time in order to manage to offer an additional product or service. It requires an analytical platform capable of processing real-time data from sources such as geolocation data on the location of customers from its mobile devices, weather data, traffic jams, social networks, transaction history on payment cards, marketing campaigns of shops and restaurants.
According to the results of the project:
The company introduced DataLake on the Cloudera platform, which, in addition to transaction data, stores other “unstructured” information from social networks, geolocation of customers’s mobile devices, weather and traffic jams. DataLake stores 7 TB of information, and up to 10 GB is added daily. Personalized product offers are provided to customers.
A comment:
Personal product offerings are a topic that is in great demand especially in the Russian financial services market; many are developing it. It is unclear how the project managed to ensure the processing of transaction data (and social networks and geolocation) in real-time mode. Data from the main transaction accounting system should instantly get into DataLake, they are modestly silent about it in the case, although this is very difficult, given their volumes and the requirements for protecting card data. Also, the topic of “Big Data Ethics” was not disclosed, when a person is offered a product, on the basis of this proposal, he understands that he is “followed” and intuitively refuses the product simply out of irritation. And then it may completely change the credit card. Conclusion, most likely 95% of transaction data, 5% of data of social networks, etc. are stored in DataLake. and based on these data models are built.

3. Bank Mandiri. The largest bank in Indonesia
Link to the case
Link to the company Company
description:
Bank Mandiri is the largest bank in Indonesia.
Project theme: #Infrastructure, #Marketing, #Business development.
Project goal:
To realize a competitive advantage by introducing a technological solution that generates personalized product offers based on data for customers. Based on the results of the implementation, reduce the overall costs of IT infrastructure.
According to the results of the project:
As it is written in the case, after implementing the data-driven analytical solution Cloudera, IT infrastructure costs were reduced by 99%! .. Customers receive targeted product offers, which improves the results of cross sell and upsell sales campaigns. Campaign costs are significantly reduced due to more targeted modeling. The big data scale of the solution is 13tB.
Comment:
Case as if hinting that according to the results of implementation, the company completely abandoned the infrastructure of relational databases for modeling product offers. Even reduced IT costs by as much as 99%.
The data sources for the technological solution are still 27 relational databases, customer profiles, plastic card transaction data and (as expected) social network data.

4. MasterCard. International payment system
Link to case
Link to company Company
description:
MasterCard earns not only as a payment system that unites 22 thousand financial institutions in 210 countries of the world, but also as a data provider for assessing financial risks (counterparties of the payment system) of credit risks of counterparties (merchants) when considering them applications for acquiring services.
Project topic: # Fraud, # Data management.
Objective of the project:
To help their clients, financial institutions to identify counterparties who were previously insolvent and trying to return to the payment system by changing their identity (name, address or other characteristics). MasterCard has created the MATCH database (MasterCard Alert to Control High-risk Merchants) for these purposes. This database contains the history of “hundreds of millions” of fraudulent businesses. Participants in the MasterCard payment system (acquirers) make up to a million queries to the MATCH database every month.
The competitive advantage of this product is determined by the requirements for a short waiting time for query results and the quality of detection of the subject of the request. With the growth of volumes and complexity of historical data, the existing relational DBMS has ceased to satisfy these requirements amid an increase in the number and quality of client requests.
According to the results of the project:
A platform for distributed storage and data processing (CDH) was introduced, which provides dynamic scaling and control of loading and complexity of search algorithms.
A comment:
The case is interesting and practically in demand. Well-thought out and mentioned an important and time-consuming component to ensure the infrastructure of access control and security. Nothing is said about the timing of the transition to the new platform. In general, a very practical case.

5. Experian. One of the three largest credit bureaus in the world.
Link to the case
Link to the company Company
description:
Experian is one of the three largest world companies (the so-called Big Three) of credit bureaus. It stores and processes information on credit history for ~ 1 billion borrowers (individuals and legal entities). In the United States alone, loan files for 235 million individuals and 25 million legal entities.
In addition to direct credit scoring services, the company sells organizations marketing support services, online access to credit history of borrowers and fraud protection and identity theft.
The competitive advantage of marketing support services (Experian Marketing Services, EMS) is based on the main asset of the company - accumulated data and physical and legal borrowers. EMS.
Theme of the project:#Infrastructure, #Marketing, #Business development.
Project goal:
EMS helps marketers gain unique access to their target audience by modeling it using accumulated geographical, demographic and social data. It is correct to apply accumulated (large) data about borrowers when modeling marketing campaigns, including such real time data as “last completed purchases”, “activity on social networks”, etc.
The accumulation and application of such data requires a technological platform that allows you to quickly process, save and analyze these various data.
According to the results of the project:
After several months of research, the choice was made on a platform development - the Cross Channel Identity Resolution (CCIR) engine, based on Hbase technology, a non-relational distributed database. Experian uploads data to the CCIR engine through ETL scripts from numerous in-house mainframe servers and relational DBMSs such as IBM DB2, Oracle, SQL Server, Sybase IQ.
At the time of writing the case, more than 5 billion rows of data were stored in Hive, with the prospect of 10-fold growth in the near future.
Comment:
The specifics of the case are very captivating, which is very rare:
- the number of cluster nodes (35),
- the timing of the project implementation (<6 months),
- the architecture of the solution is presented concisely and correctly:
Hadoop components: HBase, Hive, Hue, MapReduce, Pig
Cluster servers: HP DL380 (more than commodity)
Data Warehouse: IBM DB2
Data Marts: Oracle, SQL Server, Sybase IQ
- load characteristics (processing 100 million records per hour, growth performance by 500%).
ps
The “be patient and train a lot” advice makes you smile before embarking on industrial development of solutions on Hadoop / Hbase!
Very well presented case! I recommend reading it separately. Especially much is hidden between the lines for people in the subject!

6. Western Union. International Money Transfer Market Leader
Link to case
Link to company Company
description:
Western Union is the largest operator of the international money transfer market. Initially, the company provided telegraph services (the inventor of Morse code - Samuel Morse stood at the origins of its foundation).
As part of money transfer transactions, the company receives data about both senders and recipients. On average, the company carries out 29 transfers per second, with a total volume of 82 billion dollars (as of 2013).
Theme of the project: # Infrastructure. #Marketing, #Business development
Project goal:
Over the years, the company has accumulated large volumes of transactional information, which it plans to use to improve the quality of its product and strengthen its competitive advantage in the market.
Introduce a platform for consolidating and processing structured and unstructured data from multiple sources (Cloudera Enterprise Data Hub). Unstructured data includes, among others, exotic sources for Russia (according to the author) such as “click stream data” (data about client surfing when opening the company’s website), “sentiment data” (natural language processing - analysis of human interaction logs and chatbot, data from customer surveys (surveys) about the quality of the product and service, data from social networks, etc.).
According to the results of the project:
The data hub is created and populated with structured and unstructured data through streaming downloads (Apache Flume), batch downloads (Apache Sqoop) and the good old ETL (Informatica Big Data Edition).
The data hub is the same repository of customer data, allowing you to create accurate and accurate product offers, for example in San Francisco, WU creates separate targeted product offers for representatives
- Chinese culture for clients of local Chinatown departments
- immigrants from
Of the Philippines living in the Daly City area - Hispanics and Mexicans from the Mission District
For example, sending an offer is linked to the favorable exchange rate in the countries of origin for these national groups in relation to Americans to the dollar
Comment:
The cluster characteristics are mentioned - 64 nodes with the prospect of increasing to 100 nodes (nodes - Cisco Unified Computing System Server), data volume - 100tB.
Special emphasis is placed on ensuring security and restricting access to users (Apache Sentry and Kerberos). That speaks of thoughtful implementation and real practical application of the results of the work.
In general, I will assume that the project is currently not working at full capacity, there is a phase of data accumulation and there are even some attempts to develop and apply analytical models, but in general, the possibilities to correctly and systematically use unstructured data when developing models are greatly exaggerated.

7. Transamerica. Life Insurance & Asset Management Group
Link to the case
Link to the company Company
description:
Transamerica - a group of insurance and investment companies. Headquartered in San Francisco.
Project topic: # Infrastructure, # Marketing, # Business development
Project goal:
Due to the diversity of businesses, customer data may be present in the accounting systems of various group companies, which sometimes complicates their analytical processing.
Implement a marketing analytical platform (Enterprise Marketing & Analytics Platform, EMAP), which will be able to store both its own client data of all companies in the group and customer data from third-party suppliers (for example, all the same social networks). Based on this EPAM platform, form verified product offerings.
According to the results of the project:
As stated in the case, the following data are downloaded and analyzed in EPAM:
- own customer data
- CRM customer
data - Data on past insurance payments (solicitation data)
- Customer data from third-party partners (commercial data).
- Logs from the company's Internet portal
- Social media data.
Comment:
- Data is downloaded only using Informatica BDM, which is suspicious given the variability of sources and the diversity of the Architecture.
- The scale of “big data” is 30tB, which is very modest (especially considering the mention of data on 210 million customers at their disposal).
- Nothing is said about the characteristics of the cluster, the timing of the project, the difficulties encountered in the implementation.

8. mBank. 4th largest asset bank in Poland
Link to the company
Link to the case
Description of the company:
mBank, was founded in 1986, today it has 5 million retail and 20 thousand corporate customers in Europe.
Theme of the project: # Infrastructure, #.
Project goal: The
existing IT infrastructure could not cope with the ever-increasing volumes of data. Due to delays in the integration and systematization of data, the date Scientists were forced to work with the data in T-1 mode (i.e., yesterday).
As a result of the project:
A data warehouse was built on the infrastructure of the Cloudera platform, filled daily with 300GB of information from various sources.
Data sources:
• Flat source systems files (mainly OLTP systems)
• Oracle DB
• IBM MQ
Duration of data integration into the storage decreased by 67%.
ETL Tool - Informatica
Comment:
One of the rare cases of building a bank vault using Hadoop technology. No superfluous phrases “for shareholders” about a large-scale reduction of TCO for infrastructure or the capture of new markets due to the precise analysis of customer data. A pragmatic and believable case from real life.