Online flower shop, or how we screwed up on Valentine's Day
Holidays have all passed, profit and loss are calculated. The time has come for the narration. This story is about how, due to a technical error, the online flower delivery store lost several hundred orders and revenues of 1 million rubles on Valentine's Day.
There are good moments in life that you want to share, to tell, to be praised and rejoiced for you. And there are situations that have a negative connotation and from which no one is safe. You just need to learn from them and not allow a repetition in the future. As promised, in this section I publish not only positive, but also instructive stories. In the end, the error did not happen through my fault, but somehow I was part of the team that day (and still remain in it), and share the responsibility with everyone. It remains only to tell what happened and what was the root cause.
You all know very well that flowers are in demand at any time of the year, as they are given for holidays, birthdays, when they want someone to like or make something pleasant, they love someone, and sometimes even without reason. But it is also known that the flower business has some seasonality.
If you look at the history of requests through wordstat.yandex for one of the most popular requests “flower delivery” , then for any previous year you can see the characteristic rises: from late January to mid-March, in August and late November.
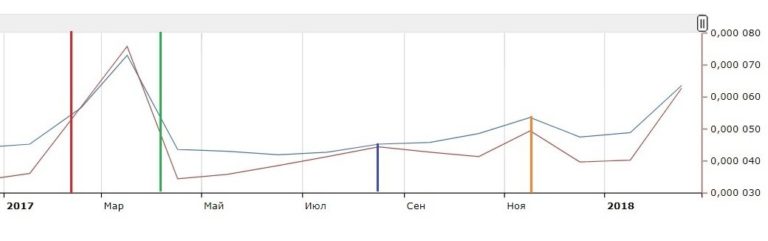
Here are the dates that triggered these trends:
And the first three months of each new year are the most eventful for the owner of this business. It is very important to approach these holidays fully equipped. We tried, from year to year everything was fine, but on February 14, 2018 we were disappointed.
A little about the project: an online flower shop with delivery in Moscow and Moscow Region, the main sources of promotion are contextual advertising (20%, I am responsible for this direction) and SEO promotion (75%) and e-mail marketing (5%). Social networks are practically not involved. Site on 1C-Bitrix, conventional hosting timeweb. The latter is very important, then I will explain why. And the development team overseeing our project was a remote place. And this to some extent played a role.
There is a myth that “flower growers” earn almost a six-month rate of return for these holidays, which allows them to relax the buns in other months. This is not true. Yes, there are more orders, many times more revenue. But not always arrived anymore. Because the cost of buying a flower, the services of a florist, packing, renting a room, the cost of couriers, advertising costs, returns - all this during a period of high demand increases significantly.
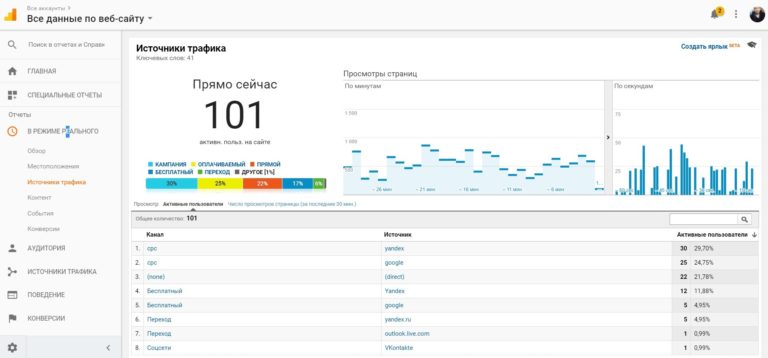
So, everything was fine until February 14, 12:30 Moscow time. By this time, we have already accepted more than 120 orders totaling 500,000 rubles. And they were going to get another 200+ orders from the experience of last year. I even recorded a record of simultaneous visits to 100+ users:
At 12:43 the first failure occurred. Of course, we immediately turned for help to our developers on the remote. The correspondence with the owner on WhatsApp was something like this: The
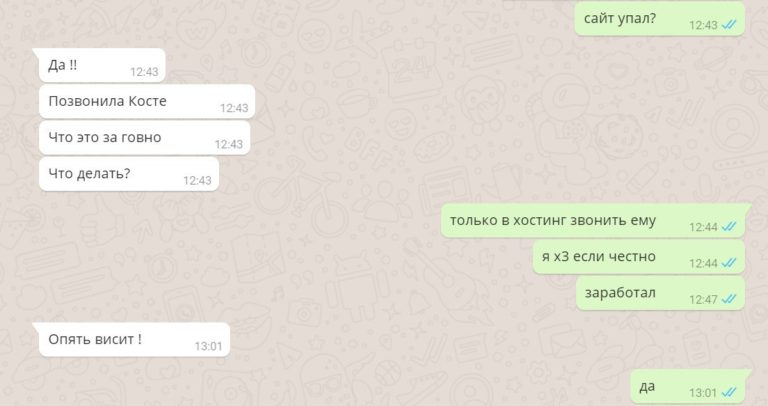
error was 502 Bad Gateway, and at some point I managed to fix even this:

And this is the peak time for sales and orders. The developers could not find out the problem on their own and wrote to the technical support of the hosting. After some time, we received the following answer:

Next, here is the following site crash chain:
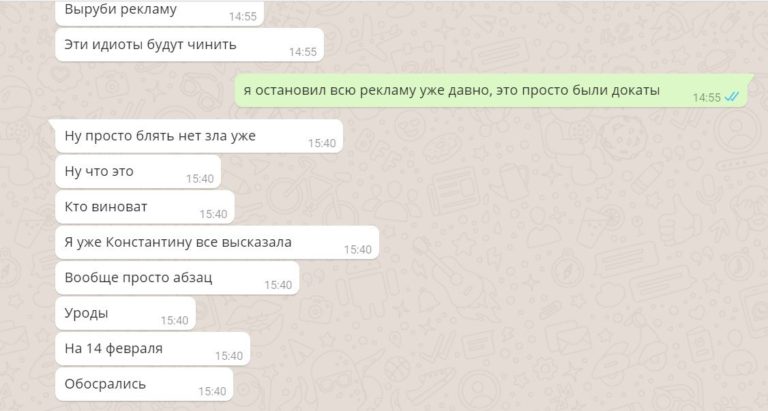
And such a dialogue with the owner:
I was not at that point at that moment (thank God!), And therefore I could only guess from all the messages and emotions from the messages. It was scary that there was no copy of the site (or rather, it fell along with the main site), and all the flowers (bouquets) of the florists had to be collected from memory. There were orders, they fell to the mail, but here are the colors, quantity, shape, pictures and some non-standard bouquets - all this now had to be asked from the client or remembered independently.
The developers were not able to determine the cause of the fall of the site. At some point, they even began to believe in the theory of conspiracy and DDoS attacks of competitors. Hosting could not stand it? We thought about this, but before February 14, it was also February 13, a day no less intense in terms of loads. But everything went smoothly there.
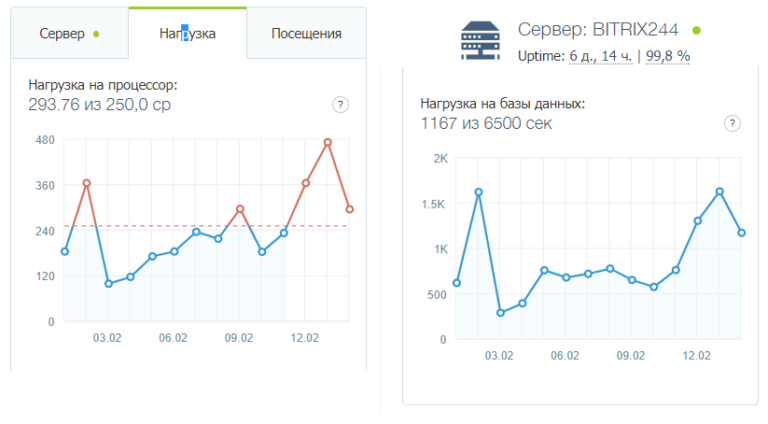
Our online store remained lying until February 15 (for the remaining time we received only 30 orders), until I turned to the person who was recently performing our freelance task for us, as an independent expert.
The first thing that the programmer immediately advised was to change the hosting to at least VPS (virtual server), and put this site on a separate VPS, since the virtual server is more powerful and more stable.
Analysis of the log files showed that there was no attack. True, once someone just turned off the site on the hosting (13: 01-13: 18), i.e. it most likely was not a DDoS attack or an error on the side of PHP, but it was more like someone on the hosting turned off this site for a given period of time. This was so - the hosting staff disconnected us manually due to the extremely high load on the server. And what was the reason for such a sharp jump - had to find out further.
To the question:
- “Why didn’t they tell us (current developers) that it is better to switch to another, more powerful and more secure server?”
I got a very concrete and robust answer:
- “Many programmers will not offer to transfer there. After all, to do this, you need some knowledge in Linux administration, and this is closer to system administration. ”
Everything immediately became clear - incompetence. From them we received the following messages:

At some point, SEO experts came into action with their advice. They are:
The developer, who helped us throughout this story, reacted mockingly to these edits and said that this had absolutely nothing to do with it. Something had to be done before someone cleaned up the tracks or made things worse.
We completely trusted the independent programmer and began to expect news from him. And the site was hanging, did not even let go to the admin panel. As a result, the developer took a copy of the site directly from the hosting and hosted it locally.
A small digression: the online store has been operating since 2015, during which time it has been serviced by several SEO promotion agencies. A sufficient number of developers have changed in these agencies and each of them had its own access. As it turned out later, almost every “dog” had administrative access to the site. And SEO-drivers as well.
First of all, all accesses were closed. Yes, of course, 1C-Bitrix is famous for that - you can not have access, but only a bunch of scripts that, when launched, can restore and add an administrator. And if one of the people who had access to the site (and there were a dozen of them) put such a script somewhere, then without any problems it can launch it and gain access as an admin and shit ...
After some time we got the first results from it : The

culprit was not named, but the person responsible was:
There is such a thing in Bitrix - the so-called agents. These are tasks (executable program code) that run in a certain period of time. The launch of these tasks (agents) occurs with hits of ordinary users who come to the site. Agents are created by developers if you need to execute some code in a certain period of time, which should do something on the site in this given period.
EKAM is an online cashier and retail automation. The module connects the online store with the fiscal registrar for generating checks from CMS “1C-Bitrix” according to “54-FZ on the use of cash registers” using the online ECAM cashier.
The cash desk itself is located locally (in the office), Bitrix’s regular cash desk functionality was not arranged due to the lack of feedback, while EKAM technical support responded immediately.
So, on the site the module “ЕКАМ.Online (cmskassa.ekam) cmskassa.ru” was installed and someone hung up the launch of one of the functions from this module “\ Bitrix \ CmskassaEkam \ CheckListTable :: loadUpdates ()” on the agent. This feature is very heavy (hanging) for the site. Thus, when the next launch of this agent took place, the site lay down for a very, very long time.
It remains to remember who we last connected to the task to resolve the issue with the EKAM module. As it turned out later, most recently the owner of an online store turned to EKAM specialists for help (checks were printed every other time), and they did something on the site, they were given access at the administrator level.
We managed to restore the site’s performance, but occasionally loads appeared and another 1-2 days forced the site to hang for 10-15 minutes. On February 15th, I was at a conference on electronic commerce and met EKAM employees at the booth. He described the current situation; our task was immediately given high priority. However, the answer was not very specific, and soon the technical support of EKAM completely forgot to answer and solve our question:

We were asked to do standard things ... But at the same time, EKAM employees forgot to mention the changes made in the module by their developer manually at the end of January on our website.
Further, we simply experimented with turning on / off the agents and the cash desk itself so that it would not print and vice versa. And as soon as they realized that we won’t get a response from the experts, that nobody was going to remodel the module, they decided to link the cash register and the store with full-time functional.
At the moment, everything is working well, we rehabilitated for Valentine's Day on March 8. At the same time, they have not even moved to a virtual server, although the load on the site on International Women's Day was much higher than on February 14.
From all this situation, on Valentine's Day, we learned a lot of useful things, namely:
Due to the fact that the site is the only source of attracting customers, it was necessary to pay more attention to its protection and all the processes built around it:
close administrative access to those who do not need it in principle;
Maintain LOG files of all tasks that have been done so that you can later find the extreme;
expand a copy of the site (it was, but on the same hosting, and fell along with the main site), pictures, product descriptions, so that you can look at least at your range.
As a rule, in agencies one team at the same time conducts a large number of projects. And the amount of time they spend working on one project per day is very limited. It makes no sense to recycle, as they are sitting at a salary. Motivation is minimal. Yes, a freelancer also conducts many projects at the same time, but here he answers with his reputation, while in the company an employee is an incoming / outgoing link. I didn’t get in touch - well, okay. The working day is over - I'll see it tomorrow.
Skills and experience are very important. If we contacted an independent developer earlier, I’m 100% sure that the number of site crashes would be minimized.
I am responsible for advertising, florists - for the final bouquet, the developer - for the performance of the system, seo-shniki - for promotion, etc. No one should go into other people's processes. Alas, this does not always happen ...
The way it is. From the paragraph above it follows that everyone is doing his own thing. Competitors have enough worries and problems on this day. They are immersed in their processes, they have no time to think about what is happening around. And even more so, to arrange a DDoS attack on the site of not the most powerful player on the market. Although, I may be too naive and mistaken.
Perhaps an employee of EKAM made a mistake in his latest changes, which led to disastrous consequences on one of the most important days of the year. And he did it unintentionally. And maybe it's not just him. Who will figure it out now. And there’s no point in looking for the guilty. Each of us at his stage made a mistake, which ultimately led to the loss of 200 orders and 1 million rubles.
We have learned a lesson and hope that such problems will be avoided in the future.
There are good moments in life that you want to share, to tell, to be praised and rejoiced for you. And there are situations that have a negative connotation and from which no one is safe. You just need to learn from them and not allow a repetition in the future. As promised, in this section I publish not only positive, but also instructive stories. In the end, the error did not happen through my fault, but somehow I was part of the team that day (and still remain in it), and share the responsibility with everyone. It remains only to tell what happened and what was the root cause.
You all know very well that flowers are in demand at any time of the year, as they are given for holidays, birthdays, when they want someone to like or make something pleasant, they love someone, and sometimes even without reason. But it is also known that the flower business has some seasonality.
If you look at the history of requests through wordstat.yandex for one of the most popular requests “flower delivery” , then for any previous year you can see the characteristic rises: from late January to mid-March, in August and late November.
Here are the dates that triggered these trends:
- January 25 - Tatyana's Day;
- February 14 - Valentine's Day;
- February 23 - Defender of the Fatherland Day;
- March 8 - International Women's Day;
- mid-August - preparing children for school, gifts for teachers;
- November 25 is Mother's Day.
And the first three months of each new year are the most eventful for the owner of this business. It is very important to approach these holidays fully equipped. We tried, from year to year everything was fine, but on February 14, 2018 we were disappointed.
A little about the project: an online flower shop with delivery in Moscow and Moscow Region, the main sources of promotion are contextual advertising (20%, I am responsible for this direction) and SEO promotion (75%) and e-mail marketing (5%). Social networks are practically not involved. Site on 1C-Bitrix, conventional hosting timeweb. The latter is very important, then I will explain why. And the development team overseeing our project was a remote place. And this to some extent played a role.
There is a myth that “flower growers” earn almost a six-month rate of return for these holidays, which allows them to relax the buns in other months. This is not true. Yes, there are more orders, many times more revenue. But not always arrived anymore. Because the cost of buying a flower, the services of a florist, packing, renting a room, the cost of couriers, advertising costs, returns - all this during a period of high demand increases significantly.
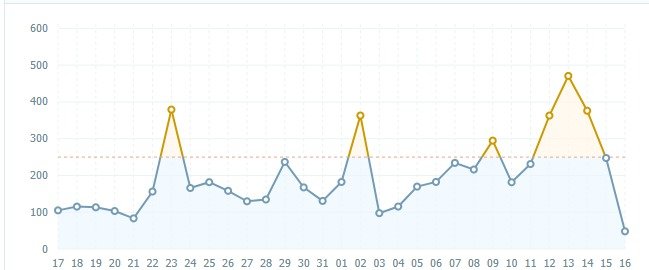
So, everything was fine until February 14, 12:30 Moscow time. By this time, we have already accepted more than 120 orders totaling 500,000 rubles. And they were going to get another 200+ orders from the experience of last year. I even recorded a record of simultaneous visits to 100+ users:
At 12:43 the first failure occurred. Of course, we immediately turned for help to our developers on the remote. The correspondence with the owner on WhatsApp was something like this: The
error was 502 Bad Gateway, and at some point I managed to fix even this:
And this is the peak time for sales and orders. The developers could not find out the problem on their own and wrote to the technical support of the hosting. After some time, we received the following answer:
Next, here is the following site crash chain:
- 12: 43-12: 47 = 4 minutes
- 13: 01-13: 18 = 17 minutes
- 13: 27-13: 42 = 15 minutes
- 13: 57-14: 17 = 20 minutes
- 14: 26-14: 54 = 28 minutes
- 14: 58-15: 15 = 17 minutes
- 15: 30-15: 46 = 16 minutes
- 16: 08-16: 27 = 19 minutes
- 16: 35-16: 37 = 2 minutes
- 16: 48-16: 51 = 3 minutes
And such a dialogue with the owner:
I was not at that point at that moment (thank God!), And therefore I could only guess from all the messages and emotions from the messages. It was scary that there was no copy of the site (or rather, it fell along with the main site), and all the flowers (bouquets) of the florists had to be collected from memory. There were orders, they fell to the mail, but here are the colors, quantity, shape, pictures and some non-standard bouquets - all this now had to be asked from the client or remembered independently.
The developers were not able to determine the cause of the fall of the site. At some point, they even began to believe in the theory of conspiracy and DDoS attacks of competitors. Hosting could not stand it? We thought about this, but before February 14, it was also February 13, a day no less intense in terms of loads. But everything went smoothly there.
Our online store remained lying until February 15 (for the remaining time we received only 30 orders), until I turned to the person who was recently performing our freelance task for us, as an independent expert.
The first thing that the programmer immediately advised was to change the hosting to at least VPS (virtual server), and put this site on a separate VPS, since the virtual server is more powerful and more stable.
Analysis of the log files showed that there was no attack. True, once someone just turned off the site on the hosting (13: 01-13: 18), i.e. it most likely was not a DDoS attack or an error on the side of PHP, but it was more like someone on the hosting turned off this site for a given period of time. This was so - the hosting staff disconnected us manually due to the extremely high load on the server. And what was the reason for such a sharp jump - had to find out further.
For each virtual account, the hoster allocates certain capacities, and when it suddenly goes beyond these allocated capacities, the hoster simply temporarily sends this account to ignore, and then writes a message to the account owner: “You have exceeded the threshold for allocated capacities, switch to a more powerful and expensive tariff ".
To the question:
- “Why didn’t they tell us (current developers) that it is better to switch to another, more powerful and more secure server?”
I got a very concrete and robust answer:
- “Many programmers will not offer to transfer there. After all, to do this, you need some knowledge in Linux administration, and this is closer to system administration. ”
Everything immediately became clear - incompetence. From them we received the following messages:
It looks like it's still DDoS, but it’s kind of tricky. Now there are almost no people on the site, and he makes 40,000 queries to the database per minute. The requests are large, and they overflow the cache, as a result, nothing is loaded. Yesterday the load was more in terms of the number of people, but the site coped, there were no such problems. We deployed a copy of the site, simulated the entry of a large number of users. He begins to freeze. We must move to VDS. Further the site will work and in a planned mode to understand.Now even I know that DDoS is not about database queries. If there are no requests to the web server, but there is a database, then this is not DDoS, but some internal problems ... In general, 0 level. The level of developers immediately became clear in a stressful and unusual situation. For 1.5 days, a team of 3-4 people could not understand the reason for the fall of the store and restore its performance.
At some point, SEO experts came into action with their advice. They are:
- Reduced the load on the site from Yandex bots through robots. So far we have set strict limits;
- Reduced the load on the part of Google bots on the site through Google Webmasters;
- Reduced the load on the site from various bots we didn’t need by closing them through the .htaccess file.
The developer, who helped us throughout this story, reacted mockingly to these edits and said that this had absolutely nothing to do with it. Something had to be done before someone cleaned up the tracks or made things worse.
We completely trusted the independent programmer and began to expect news from him. And the site was hanging, did not even let go to the admin panel. As a result, the developer took a copy of the site directly from the hosting and hosted it locally.
A small digression: the online store has been operating since 2015, during which time it has been serviced by several SEO promotion agencies. A sufficient number of developers have changed in these agencies and each of them had its own access. As it turned out later, almost every “dog” had administrative access to the site. And SEO-drivers as well.
First of all, all accesses were closed. Yes, of course, 1C-Bitrix is famous for that - you can not have access, but only a bunch of scripts that, when launched, can restore and add an administrator. And if one of the people who had access to the site (and there were a dozen of them) put such a script somewhere, then without any problems it can launch it and gain access as an admin and shit ...
After some time we got the first results from it : The
culprit was not named, but the person responsible was:
\Bitrix\CmskassaEkam\CheckListTable::loadUpdates()There is such a thing in Bitrix - the so-called agents. These are tasks (executable program code) that run in a certain period of time. The launch of these tasks (agents) occurs with hits of ordinary users who come to the site. Agents are created by developers if you need to execute some code in a certain period of time, which should do something on the site in this given period.
EKAM is an online cashier and retail automation. The module connects the online store with the fiscal registrar for generating checks from CMS “1C-Bitrix” according to “54-FZ on the use of cash registers” using the online ECAM cashier.
The cash desk itself is located locally (in the office), Bitrix’s regular cash desk functionality was not arranged due to the lack of feedback, while EKAM technical support responded immediately.
So, on the site the module “ЕКАМ.Online (cmskassa.ekam) cmskassa.ru” was installed and someone hung up the launch of one of the functions from this module “\ Bitrix \ CmskassaEkam \ CheckListTable :: loadUpdates ()” on the agent. This feature is very heavy (hanging) for the site. Thus, when the next launch of this agent took place, the site lay down for a very, very long time.
It remains to remember who we last connected to the task to resolve the issue with the EKAM module. As it turned out later, most recently the owner of an online store turned to EKAM specialists for help (checks were printed every other time), and they did something on the site, they were given access at the administrator level.
We managed to restore the site’s performance, but occasionally loads appeared and another 1-2 days forced the site to hang for 10-15 minutes. On February 15th, I was at a conference on electronic commerce and met EKAM employees at the booth. He described the current situation; our task was immediately given high priority. However, the answer was not very specific, and soon the technical support of EKAM completely forgot to answer and solve our question:
We were asked to do standard things ... But at the same time, EKAM employees forgot to mention the changes made in the module by their developer manually at the end of January on our website.
Further, we simply experimented with turning on / off the agents and the cash desk itself so that it would not print and vice versa. And as soon as they realized that we won’t get a response from the experts, that nobody was going to remodel the module, they decided to link the cash register and the store with full-time functional.
At the moment, everything is working well, we rehabilitated for Valentine's Day on March 8. At the same time, they have not even moved to a virtual server, although the load on the site on International Women's Day was much higher than on February 14.
From all this situation, on Valentine's Day, we learned a lot of useful things, namely:
- total control is needed;
Due to the fact that the site is the only source of attracting customers, it was necessary to pay more attention to its protection and all the processes built around it:
- move to a dedicated server;
close administrative access to those who do not need it in principle;
Maintain LOG files of all tasks that have been done so that you can later find the extreme;
expand a copy of the site (it was, but on the same hosting, and fell along with the main site), pictures, product descriptions, so that you can look at least at your range.
- It is necessary to hire interested and competent employees;
As a rule, in agencies one team at the same time conducts a large number of projects. And the amount of time they spend working on one project per day is very limited. It makes no sense to recycle, as they are sitting at a salary. Motivation is minimal. Yes, a freelancer also conducts many projects at the same time, but here he answers with his reputation, while in the company an employee is an incoming / outgoing link. I didn’t get in touch - well, okay. The working day is over - I'll see it tomorrow.
Skills and experience are very important. If we contacted an independent developer earlier, I’m 100% sure that the number of site crashes would be minimized.
- Everyone must do their job;
I am responsible for advertising, florists - for the final bouquet, the developer - for the performance of the system, seo-shniki - for promotion, etc. No one should go into other people's processes. Alas, this does not always happen ...
- these are not competitors, these are our hands are crooked;
The way it is. From the paragraph above it follows that everyone is doing his own thing. Competitors have enough worries and problems on this day. They are immersed in their processes, they have no time to think about what is happening around. And even more so, to arrange a DDoS attack on the site of not the most powerful player on the market. Although, I may be too naive and mistaken.
- the more links in the chain, the more difficult it is to find the extreme. And is it worth looking at all?
Perhaps an employee of EKAM made a mistake in his latest changes, which led to disastrous consequences on one of the most important days of the year. And he did it unintentionally. And maybe it's not just him. Who will figure it out now. And there’s no point in looking for the guilty. Each of us at his stage made a mistake, which ultimately led to the loss of 200 orders and 1 million rubles.
We have learned a lesson and hope that such problems will be avoided in the future.