Development of a biometric identification system for speech
Hello colleagues! In this article, I will briefly talk about the features of building biometric verification / identification systems that our DATA4 team faced when creating its own solution.
The task of identity authentication is used in areas with the need for access control. These are banks, insurance companies, and other areas where confidential information is used.
Traditionally, authentication uses the principle of knowing a “key,” such as a password, control word, or passport number. The described method has a drawback - it is not the identity that is confirmed, but the information known to the person.
Biometric solutions do not have this drawback.
A promising approach to solving the problem is voice authentication. The voice of each person is unique, and with a given accuracy, you can say who he belongs to. For identification tasks, this approach is not applicable, since at the current level of technology, the error of “false pass” gives an error of 3-5%. The accuracy of the algorithms is 95–97%, which allows the use of technology in the verification task.
An additional advantage of voice verification is the reduction of authentication time in the contact center, which gives an economic effect proportional to the number of operators (saving on wages and communications). According to our calculations, the achievable effect of implementation is up to 27 million rubles. per year for a contact center of 100 operators (including taxes, telephony costs, operators' work in 2 shifts, etc.), but the figure depends on the specific case.
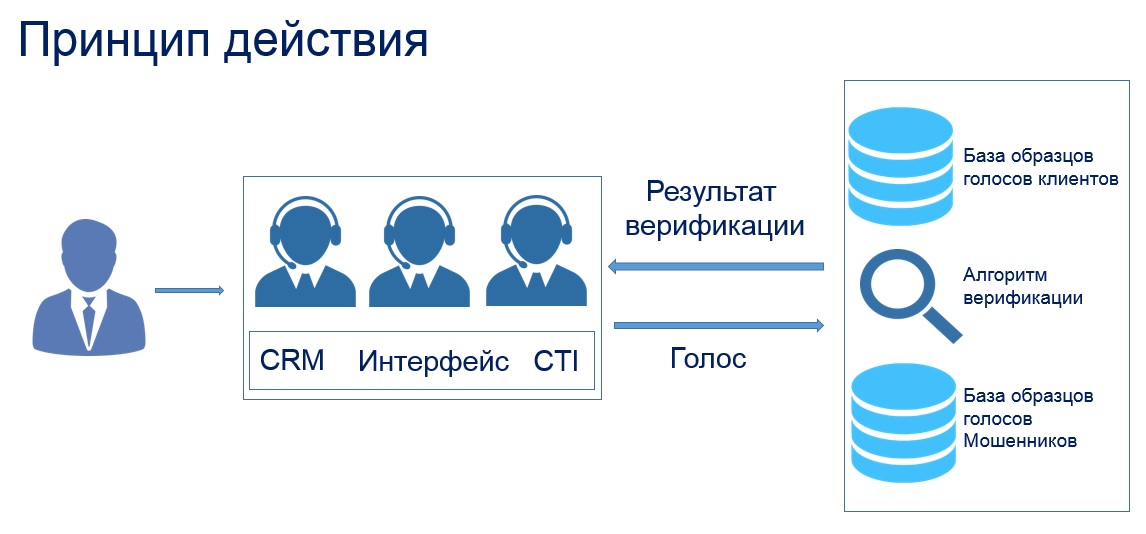
Recording a person’s voice is a signal that needs to be processed, to extract features and build a classifier.
Our solution consists of 4 subsystems: digital signal processing subsystem, feature extraction subsystem, speech highlighting subsystem and classifier [1].
For correct operation, it is required to set the error coefficients of the first and second kind. If it is required to minimize the error of false acceptance, then the “penalty” of the error of false acceptance exceeds the “penalty” of the error of false rejection by 100-1000 times. We used a coefficient of 100.
To build a verification solution, we need data labeled by speakers and the presence of speech. It is recommended to use at least several hundred speakers in different acoustic conditions, such as phone models, types of rooms, etc., in the amount of speech for at least 5-10 hours. We used our own dataset of more than 5 thousand audio files. This is necessary to avoid retraining the algorithm. Cross-validation and regularization should additionally be used to minimize retraining.
As VAD (speech detector), you can use the following solution from Google. But, if you want to understand how it works, it is better to write your own solution based on XGboost. Achievable metric quality accuracy> 99%. From our experience, it is precisely the quality of work of VAD that is the “bottleneck” for the final quality of work.
For digital signal processing tasks, Bob's solution is known .
To build a speech verification solution, data, skills in digital signal processing and machine learning are required.
You can get acquainted with the principles of the device of verification solutions in more detail and with the basics of machine learning and DSP in the attached literature.
References:
1. A.V. Kozlov, O.Yu. Kudashev, Yu.N. Matveev, T.S. Pekhovsky, K.K. Simonchik, A.K. Shulipa. "Voice over speaker identification system for the NIST SRE contest." 2013
2. Yu.N. Matveev. "The study of the informativeness of the signs of speech for automatic speaker identification systems." 2013
3. D.V. Baker, S.G. Tikhorenko. "The algorithm for the use of Gausovye mixtures to identify the speaker by voice in technical systems."
4. N.S. Klimenko, I.G. Gerasimov. "A study of the effectiveness of boosting in the task of text-independent identification of speakers." 2014
Useful resources:
1. Machine learning course from the Moscow Institute of Physics and Technology with a cursor;
2. DSP course from MIPT on the internal portal.
The task of identity authentication is used in areas with the need for access control. These are banks, insurance companies, and other areas where confidential information is used.
Traditionally, authentication uses the principle of knowing a “key,” such as a password, control word, or passport number. The described method has a drawback - it is not the identity that is confirmed, but the information known to the person.
Biometric solutions do not have this drawback.
A promising approach to solving the problem is voice authentication. The voice of each person is unique, and with a given accuracy, you can say who he belongs to. For identification tasks, this approach is not applicable, since at the current level of technology, the error of “false pass” gives an error of 3-5%. The accuracy of the algorithms is 95–97%, which allows the use of technology in the verification task.
An additional advantage of voice verification is the reduction of authentication time in the contact center, which gives an economic effect proportional to the number of operators (saving on wages and communications). According to our calculations, the achievable effect of implementation is up to 27 million rubles. per year for a contact center of 100 operators (including taxes, telephony costs, operators' work in 2 shifts, etc.), but the figure depends on the specific case.
The principles of the classical approach
Recording a person’s voice is a signal that needs to be processed, to extract features and build a classifier.
Our solution consists of 4 subsystems: digital signal processing subsystem, feature extraction subsystem, speech highlighting subsystem and classifier [1].
Digital Signal Processing Subsystem
- The signal is filtered, the investigated range is highlighted. The human ear hears frequencies of 20–20 thousand Hz, but the range of 300–3400 Hz is taken for biometric verification decisions.
- The signal is transferred to the frequency domain by the fast Fourier transform method.
Characteristics Subsystem
- The signal is divided into segments of 20-25 ml.s. Further we will call segments - frames.
- For each frame, fine-grained coefficients are determined - MFCC, and the first and second delta. The first 13 MFCC ratios are used. [2]
Speech Subsystems
- The feature vector is fed into a pre-trained binary classifier for the presence of speech. The classifier, for each frame, determines the presence of speech. To maximize quality, tree-based boosting models such as XGboost are used. Logistic regression or the SVM reference vector method are used to maximize work speed.
Classifier
- A mixture of distributions according to the selected features from the frames in which the speech was present is built [3]. It takes at least 24-30 seconds of pure speech to train the model and 12-15 seconds to test.
- Using the mixture of distributions, the final feature vector (i — vector) is constructed consisting of 100 values.
- The feature vector is fed to the binary classifier. In the traditional approach, SVM or boosting is used for classification. [4]
For correct operation, it is required to set the error coefficients of the first and second kind. If it is required to minimize the error of false acceptance, then the “penalty” of the error of false acceptance exceeds the “penalty” of the error of false rejection by 100-1000 times. We used a coefficient of 100.
To build a verification solution, we need data labeled by speakers and the presence of speech. It is recommended to use at least several hundred speakers in different acoustic conditions, such as phone models, types of rooms, etc., in the amount of speech for at least 5-10 hours. We used our own dataset of more than 5 thousand audio files. This is necessary to avoid retraining the algorithm. Cross-validation and regularization should additionally be used to minimize retraining.
As VAD (speech detector), you can use the following solution from Google. But, if you want to understand how it works, it is better to write your own solution based on XGboost. Achievable metric quality accuracy> 99%. From our experience, it is precisely the quality of work of VAD that is the “bottleneck” for the final quality of work.
For digital signal processing tasks, Bob's solution is known .
Summary
To build a speech verification solution, data, skills in digital signal processing and machine learning are required.
You can get acquainted with the principles of the device of verification solutions in more detail and with the basics of machine learning and DSP in the attached literature.
References:
1. A.V. Kozlov, O.Yu. Kudashev, Yu.N. Matveev, T.S. Pekhovsky, K.K. Simonchik, A.K. Shulipa. "Voice over speaker identification system for the NIST SRE contest." 2013
2. Yu.N. Matveev. "The study of the informativeness of the signs of speech for automatic speaker identification systems." 2013
3. D.V. Baker, S.G. Tikhorenko. "The algorithm for the use of Gausovye mixtures to identify the speaker by voice in technical systems."
4. N.S. Klimenko, I.G. Gerasimov. "A study of the effectiveness of boosting in the task of text-independent identification of speakers." 2014
Useful resources:
1. Machine learning course from the Moscow Institute of Physics and Technology with a cursor;
2. DSP course from MIPT on the internal portal.