Is it so scary Rust, as he is painted
Some time ago I began to understand the need to diversify my programming experience exclusively in C #. After some study of various options, such as Haskell, Scala, Rust and some others, the choice fell on the last one. Over time, I began to notice that Rust is increasingly being advertised solely as a "system language", which is needed for extremely complex compilers and super-loaded systems, with special security and multithreading requirements, and for simpler options there is Go / Python / Java / ..., while I gladly and very successfully used it as a replacement for my workhorse C #.

In this article I wanted to tell why I consider this trend as a whole harmful, and why Rust is a good general-purpose language in which you can do any projects, starting with any microservices, and ending with the scripting of the daily routine.
Introduction
Why, in fact, learn a new language, the more difficult? It seems to me that the answer of the article “Overcoming Mediocrity” is the closest to the truth , namely:
Everyone knows that writing the entire program manually in machine language is wrong. But they understand much less often that there is a more general principle: if there is a choice of several languages, it is wrong to program on something other than the most powerful one, unless other reasons influence the choice.
The more complex the language, the richer the phrases composed with its help, and the better it can express the desired subject area. Because concepts are usually studied once, and are applied many times, much more profitable from the point of view of investing their own time to study all kinds of scary words like "monadic transformers" (and, preferably, their meaning), in order to save their mental forces and spend them for something more nice And therefore, it is very sad to see the trend of some companies to make specially “simplified” languages. As a result, the vocabulary of these languages is much smaller, and it is not difficult to learn it, but then reading the “my yours to buy onion” programs is very difficult, not to mention possible ambiguous interpretations.
The basics
As usual, a novice gets acquainted with a programming language? He google the most popular book on the language, pulls it, and begins to read. As a rule, it contains HelloWorld, a compiler installation guide, and then basic information on the language with a gradual complication. In the case of rasta, this is a deskscore , and the first example is reading a number from the console and displaying it on the screen. How would we do this in the same C #? Well, probably something like that
var number = int.Parse(Console.ReadLine());
Console.WriteLine($"You guessed: {number}");And what we have in the plant?
letmut guess = String::new();
io::stdin().read_line(&mut guess)
.expect("Failed to read line");
let guess: u32 = guess.trim().parse()
.expect("Please type a number!");
println!("You guessed: {}", guess);Triple the amount of code, all these curtsies with the creation of a variable before use (hello Pascal!), Calling a heap of auxiliary code, etc. "What a horror" the average developer will think and once again be convinced of the "consistency" of the language.
But in fact it can be written much easier:
letmut guess = String::new();
io::stdin().read_line(&mut guess)?;
let guess: u32 = guess.trim().parse()?;
println!("You guessed: {}", guess);There is still a separate creation of the variable and reading into it from the stream, but here the ideology of the rasta imposes an imprint that it transfers the allocation of the buffer to the user. At first it is unusual, but then you realize that with responsibility comes the corresponding strength. Well, for those who are not soared, there is always the option to write a three-line function and forget this question once and for all.
Why is the example in the book made in this way? Most likely due to the fact that the explanation of error handling occurs much later, and ignoring them as in the case of C # does not allow the rasta paradigm, which controls all possible paths where something can go wrong.
Lifetime and Boroucheker
Oh, those terrible beasts. People rush obscure spells like
fnsearch<F>(self, hash: u64, is_match: F, compare_hashes: bool)
-> RawEntryMut<'a, K, V, S>
wherefor<'b> F: FnMut(&'b K) -> boolNewcomers run in panic, the guys from go say "we warned you about unnecessary complexity," Haskellists say "so much difficulty for a language that even has no effects," and the javist twist their fingers at the temple "did it cost a fence for only GC refuse".
In fact, when writing an application program, you probably will not need to specify a single lifetime at all. The reason for this is that in Rastas there are rules for outputting Lifestyle, which is almost always the compiler can set itself. Here they are:
- Each life position in input position becomes a distinct lifetime parameter.
- If there is a lifespan, it is assigned to all elite output lifetimes.
- It has been assigned that it has been assigned a life span.
- Otherwise, it is an error to elide an output lifetime.
Or, if in a nutshell, in the case of static functions, the lifetime of all arguments is assumed to be equal, in the case of instance methods, the lifetime of all resulting references is equal to the lifetime of the instance on which we call the method. And in practice, this is almost always respected in the case of application code. Therefore, there instead of horror above you will usually write something like
structPoint(i32, i32);
impl Point {
pubfnget_x(&self) -> &i32 {
&self.0
}
pubfnget_y(&self) -> &i32 {
&self.1
}
}And the compiler will happily output everything that is needed for it to work.
Personally, I see the beauty of the concept in automatic control in several aspects.
- from the point of view of a person with programming experience in a language with GC, memory is not a separate type of resource. C # has a whole story with an interface
IDisposable, which is used for deterministic cleaning of resources, precisely because the GC deletes the object “when there”, and we may need to release the resource immediately. As a result, there is a whole heap of consequences: one should not forget about the correct implementation of finalizers, and the whole keyword was introduced for this (as well as Java try-with-resources), and the compiler should be cracked to generate foreach with this in mind ... Unification of all types resources that are released automatically, and as quickly as possible after the last use, it is very nice. I opened the file for myself and work with it, it will close when needed without any scoping. I’ll immediately answer the potential objection that DI containers make life a little easier, but they don’t solve all the problems. - from the point of view of a person with programming experience in a manual language, in 99% of cases it is not necessary to use smart pointers, it is enough to use ordinary links.
As a result, the code is clean (as in the language with GC), but at the same time, all resources are released as quickly as possible (as in the manual language). And lifetime: a declarative description of the expected lifetime of the object. A declarative description is always better than the imperative "free the object here."
Cruel compiler
Some consequence of the previous paragraph. There is a good picture, it generally describes many languages, but drawn specifically for the case of Rasta:
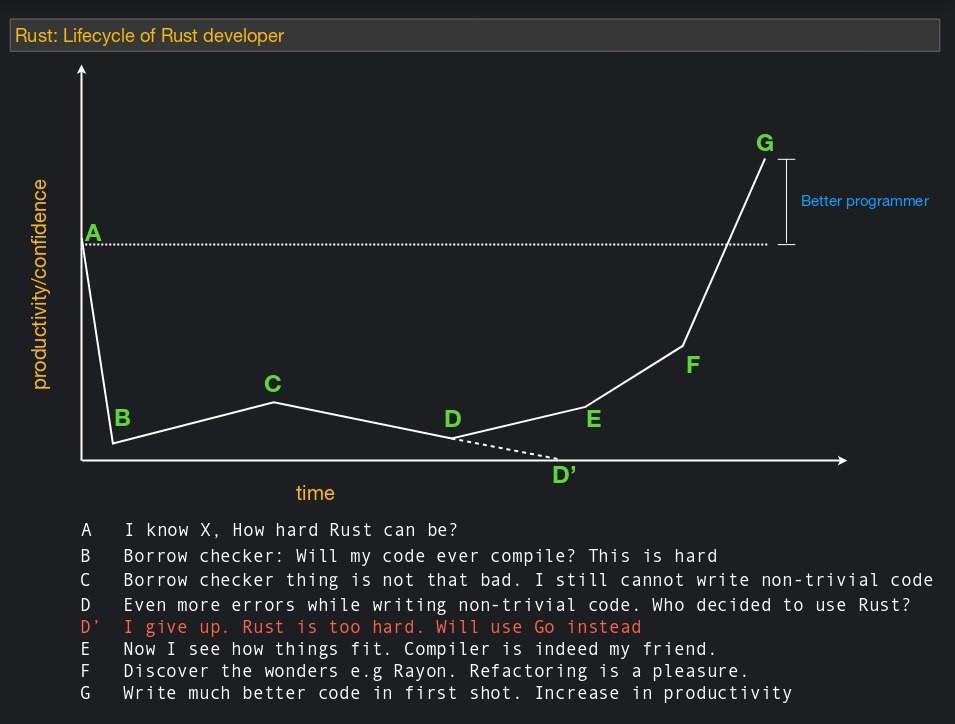
Actually, the compiler is really pretty picky. This was especially true before the appearance of Rust 2018, when the compiler in some cases did not miss the obvious code. But now there are problems, especially from a misunderstanding of the concept of ownership. For example, when a person tries to implement a doubly linked list. With a naive implementation, he first tries to do
pubstructNode {
value: u64,
next: Option<Box<Node>>,
prev: Option<Box<Node>>,
}The compiler will compile the declaration of this structure, but it will not work, because Box<Node>is the owning reference, or unique_ptrin C ++ terms. A unique link, of course, can only be one
The next person attempt may look like this:
pubstructNode {
value: u64,
next: Option<&Box<Node>>,
prev: Option<&Box<Node>>,
}Now we have non-owned links (they are the same shared_ptr), and there can be as many of them as one object. But here there are two problems: first, the owner should be somewhere. So, we will most likely get a bunch of compilation errors "the owner died when someone referred to his data," because dangling pointers are not allowed to grow. And secondly, what is more important, we will not be able to change these values, because of the rules of rasta, "either one is a mutable link, or an arbitrary number of immutable, and nothing else."
After that, a person usually begins to beat the keyboard, and writing articles that "even a coherent list cannot be implemented normally, it will not work . " Implement the same it is certainly possible , but a bit more difficult than other languages, it is necessary to add a reference counting hands (primitive Rc/ Arc/ Cell/ RefCell) to runtime count the number of these same links, because the compiler is powerless in this situation.
The reasons for this: this data structure does not fit well with the concept of ownership of rasta, the whole language and the ecosystem as a whole are built around. Any data structures where multiple owners are required will require some squatting, for example implementing all sorts of forests / trees / graphs or the same linked lists. But this is true for all programming languages: attempts to implement memory management in languages with GC lead to terrible monsters working through WeakReferences with huge byte[]arrays, resurrecting objects in destructors to bring them back to the pool, and other terrible necromancy. Trying to get away from the dynamic nature of JS to write productive code leads to even stranger things .
Thus, in any programming language there is a "pain point", and in the case of rasta, these are data structures with many owners. But, if we look from the application point of view of high-level programmers, our programs are arranged just in this way. For example, in my environment, a typical application looks like a certain layer of controllers that are linked between services. Each service has a link to some repositories that return some objects. All this fits perfectly into the concept of ownership. And if we consider that in practice, the main data structures are lists, arrays and hashmaps, it turns out that everything is not so bad.
What to do with this beast
In fact, the compiler struggles to help. Error messages in Rast, probably the most pleasant of all the programming languages with which I worked.
For example, if you try to use the first version of our linked list, get the message
error[E0382]: assign to part of moved value: `head`
--> src\main.rs:23:5
|
19 | prev: Some(Box::new(head)),
| ---- value moved here
...
23 | head.next = Some(Box::new(next));
| ^^^^^^^^^ value partially assigned here after move
|
= note: move occurs because `head` has type `Node`, which does not implement the `Copy` traitHe says just that we have transferred ownership of the link to one element, and can no longer reuse it. He also tells us that there is some kind of Copytreit that allows you to copy it instead of moving an object, which is why you can use it after “moving” because we moved a copy. If you didn’t know about its existence, then a compilation error will provide you with information for thinking "Or maybe we should add the implementation of this treit?".
In general, the first language for compiler-driven development is for me . You just run the compilation, if something doesn’t work, the language will simply tell you "hmm, something doesn’t converge. I think the problem is in X. Try adding this code here and it will work." A typical example, let's say we wrote two functions, and forgot to add a generic constraint:
fnfoo<T: Copy>() {
}
fnbar<T>() {
foo::<T>();
}Compile, we get the error:
error[E0277]: the traitbound `T: std::marker::Copy` is not satisfied
--> src\main.rs:6:5
|
6 | foo::<T>();
| ^^^^^^^^ the trait `std::marker::Copy` is not implemented for `T`
|
= help: consider adding a `where T: std::marker::Copy` bound
note: required by `foo`
--> src\main.rs:1:1
|
1 | fnfoo<T: Copy>() {
| ^^^^^^^^^^^^^^^^^
error: aborting due to previous errorCopy-paste where T: std::marker::Copyfrom the error message, compile, everything is ready , let's go to the prod!
Yes, the IDE of all modern languages can do this through all sorts of snippets, but firstly, the benefit is that you can see from which crate / namespace the restriction has come, and secondly, this support is from the compiler, not the IDE. This is very helpful in cross-platform development, when you have everything going locally, and on some matrix on the CI server somewhere, something falls due to conditional compilation. There is no IDE on the build server, and so the log looked, framed, and everything gathered. Conveniently.
I wrote some time ago a telegram-bot on a plant, as a language training. And I had a moment where I decided to refactor the entire application. I replaced everything I wanted, and then for half an hour I tried to build a project, and put in sentences from the compiler here and there. After this time, everything gathered and earned the first time.
Well, I can say that after a year from the moment I first started writing, I learned how to write simple snippets without errors from the first time. It sounds ridiculous, especially for people with dynamic PL, but for me it was a serious progress. And for all the time of working with the growth I debug included exactly two times. And in both cases I debugged FFI with C ++ code that was segmented. Raster code either worked correctly for me or was not going to. In the case of C #, I have much less confidence, all the time I’m thinking, “willn’t null here”, “will there be a KeyNotFoundException here”, “have I synchronized access to these variables from many streams correctly”, etc. . Well, in the case of JS (when I fullstepped and wrote the front as well), after each change, a mandatory check in the browser followed what had changed.
Confidence in what has gathered == works really takes place. This does not mean that there are no bugs in the code, it means that all the bugs are related to the application logic. You have no unexpected nulls, non-synchronized access, buffer overflow, and so on. And they are much easier to catch, and sometimes you can bring to the level of types (a good article on the topic ).
Total
Rast is an excellent language for writing absolutely any application, and not just high-loaded exchanges, blockchains and trading bots. Always instead of sending a link, you can simply copy the value. Yes, yes, perhaps, rastovanee cast aside stones at me, but instead of trying to explain to the compiler in a couple of places of my bot, I could easily share the variable, I cloned it, and passed a copy. Yes, this is not so cool, but I have no goal to write the most productive application, as there is no such goal for people using C # / Java / Go / ... I want to be as productive as possible and get the application at an acceptable speed. Implementing an application on Rastus according to all canons, eliminating all unnecessary copying is a very difficult task. But to write an application in the same time as in your favorite language,
Try to write an application on the grow. If you don’t manage to pass borrouchaker, check your data structures and their interconnections, because I gradually began to understand that borroucheker is not just a mechanism responsible for the possibility of freeing memory, but also an excellent detector of the application architecture, from why this object X depends on Y, I did not expect it! ". If you understand everything, but explaining the correct answer to borrouchaker is too difficult, just copy the value. Most likely, you will still get an application that works much faster (if you write in Java / C # / ..., like me), or much more stable (if you write in C / C ++), at the same time, which you would normally spend.
Rasta's concepts are very powerful, and work well at the application level, which does not reflect on performance, but rather only on developer productivity, speed of implementation of new features and ease of support. It is very sad to observe that such a different in all respects language increasingly receives the stigma of "strange and complex language for low-level geek tasks." I hope I have shaken this harmful myth a bit, and there will be more productive and happy developers in the world.