SIEM depths: out-of-box correlations. Part 3.2. Event Normalization Methodology
How to normalize the event correctly? How to normalize similar events from different sources, without forgetting anything and not mistaking it? And what if it will be done by two experts independently of each other? In this article we will share the general methodology of normalization, which can help in solving this problem.

Image: Martinoflynn.com
Most often, the correlation rules are based on normalized events. Thus, the normalization of events and how correctly it is executed directly affect the accuracy of the correlation rules.
The problems arising from the normalization of events, we formulated in the first article ( here ), and suggested ways to solve them in subsequent articles ( here and here ). Now we will generalize the previously described and form a general approach to the normalization of events.
To begin, let us recall what tools of the level of normalization we have developed:
The whole methodology of event normalization consists of three steps:
To make it easier to understand how the tool works, we select an event and consider in detail all the steps of normalization according to our methodology.
Suppose we have a source - Oracle Database DBMS with the following network addressing:
From this source, the SIEM agent unloads the following event:

At the very beginning of the event normalization process, it is important to understand what the event is about. It is enough to say its essence to yourself. If an expert, from the original, not yet normalized, events, does not understand which processes occurring at the source are referred to - with high probability he incorrectly normalizes it. Then what is the correct operation of the correlation rules?
The problem with how well the expert interprets the event correctly is quite real. For example, can an expert not understand what the next event means?
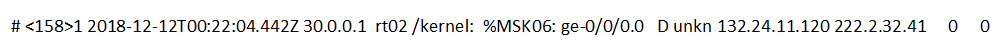
If, in the original example, the essence can be grasped from the text of the event itself, then in this case it is necessary to understand well what source you are working with and in what cases it generates a similar event. Sometimes it is even necessary to deploy a separate stand with a source in order to fully reproduce the situation in which it sends a complex and difficult to interpret event to SIEM.
Let's return to the original example with an event from the Oracle Database DBMS. At this stage, the expert should reflect like this:
“ I, as an expert, consider that the initial event describes the process of a role being withdrawn by one user from another in the Oracle Database DBMS ”.
The previous step allows you to make sure that we can understand at least the general meaning of the event. Now we will analyze in detail how to select entities and determine the pattern of their interaction.
According to this methodology, for each interaction scheme, it is necessary to describe the rules for distributing key identifiers of entities across the fields of a normalized event. At the same time, the rules for:
It is important to remember that there are schemes in which the Subject is equal to the Object and equal to the Source. For such schemes, it is necessary to explicitly define the rules for filling in the fields of all three entities. If this is not done, then problems will begin at the level of correlation rules or the search for events and additional logic will appear for the correct interpretation of empty fields. About this - in an article on interaction schemes .
Let's look at the work of this step of the methodology on the original example :
For these schemes, the following normalization rules can be defined:
After all the key entities of the event have been identified, it is necessary to describe the essence of the process itself, as reflected in the event, and transfer it to the normalization language. For these purposes, serves a system of categorization of events. The event categorization system was discussed in detail in a separate article , now let's see how it works in practice.
In order to unify normalization, the categorization system defines the following rules:
Thus, the category selected for the event establishes a direct correspondence between:
This approach allows a category of any event to clearly understand what data in which fields of the normalized event are located.
If, with the support of new sources, it turns out that it is necessary to additionally extract some more important information from the events of a certain category, then it is recorded in the directory. In this case, you need:
Thus, the consistency of the changes is maintained. Consider the original example.
According to the categorization system, this event has the following categories:
The directory for this category looks like this:
We gave this handbook to demonstrate the principle of its formation; therefore, it does not claim to be accurate and complete.
As a result, an event normalized by this methodology looks like this:

Example of a normalized event in the third step of the methodology.
Experience shows that it is often the errors of normalization and the lack of uniform rules of normalization that often lead to false positives of the correlation rules. Now we have an approach that allows, if not getting rid of, then at least to minimize the impact of the problem.
So, to summarize - the approach includes three steps:
Now, the only thing that separates us from the construction of the correlation rules “working out of the box” is the problem of constantly changing the entities themselves - the assets. They change addresses, introduce new assets, decommission old ones, switch cluster nodes, and virtual machines move from one data center to another and, sometimes, even with a change of addressing. How to overcome these problems, we will talk in the next article of the cycle.
Cycle of articles:
SIEM depths: out-of-box correlations. Part 1: Pure marketing or unsolvable problem?
SIEM depths: out-of-box correlations. Part 2. The data scheme as a reflection of the model of the "world"
Depth SIEM: correlation "out of the box." Part 3.1. Categorization of events
Depth SIEM: out-of-box correlations. Part 3.2. Event Normalization Methodology ( This article )
SIEM Depths: Out-of-Box Correlations. Part 4. System model as a context of correlation rules.
Depth SIEM: out-of-box correlations. Part 5. Methodology for developing correlation rules
Image: Martinoflynn.com
Most often, the correlation rules are based on normalized events. Thus, the normalization of events and how correctly it is executed directly affect the accuracy of the correlation rules.
The problems arising from the normalization of events, we formulated in the first article ( here ), and suggested ways to solve them in subsequent articles ( here and here ). Now we will generalize the previously described and form a general approach to the normalization of events.
To begin, let us recall what tools of the level of normalization we have developed:
- Universal field mapping required for storing data retrieved from events. Her features:
- It takes into account the presence of an entity in the event: Subject, Object, Source and Event Transmitter, as well as Resource.
- Provides correct normalization in cases when entities with network and application layers are present in the event , and when there is more than one Subject and / or Object in it.
- Allows you to clearly identify and preserve the structure of the process of interaction between the Subject and the Object
- Event categorization system capable of reflecting the semantics of IT or IB events.
Event Normalization Methodology
The whole methodology of event normalization consists of three steps:
- Expert evaluation of the event.
- The definition of the interaction scheme.
- Definition of event category.
To make it easier to understand how the tool works, we select an event and consider in detail all the steps of normalization according to our methodology.
Suppose we have a source - Oracle Database DBMS with the following network addressing:
- IP : 10.0.0.1;
- Hostname : myoracle;
- FQDN : myoracle.local.
From this source, the SIEM agent unloads the following event:
Step 1. Expert assessment of the event
At the very beginning of the event normalization process, it is important to understand what the event is about. It is enough to say its essence to yourself. If an expert, from the original, not yet normalized, events, does not understand which processes occurring at the source are referred to - with high probability he incorrectly normalizes it. Then what is the correct operation of the correlation rules?
The problem with how well the expert interprets the event correctly is quite real. For example, can an expert not understand what the next event means?
If, in the original example, the essence can be grasped from the text of the event itself, then in this case it is necessary to understand well what source you are working with and in what cases it generates a similar event. Sometimes it is even necessary to deploy a separate stand with a source in order to fully reproduce the situation in which it sends a complex and difficult to interpret event to SIEM.
Let's return to the original example with an event from the Oracle Database DBMS. At this stage, the expert should reflect like this:
“ I, as an expert, consider that the initial event describes the process of a role being withdrawn by one user from another in the Oracle Database DBMS ”.
Step 2. Defining the interaction scheme
The previous step allows you to make sure that we can understand at least the general meaning of the event. Now we will analyze in detail how to select entities and determine the pattern of their interaction.
According to this methodology, for each interaction scheme, it is necessary to describe the rules for distributing key identifiers of entities across the fields of a normalized event. At the same time, the rules for:
- Network level entities;
- Entity level entities.
It is important to remember that there are schemes in which the Subject is equal to the Object and equal to the Source. For such schemes, it is necessary to explicitly define the rules for filling in the fields of all three entities. If this is not done, then problems will begin at the level of correlation rules or the search for events and additional logic will appear for the correct interpretation of empty fields. About this - in an article on interaction schemes .
Let's look at the work of this step of the methodology on the original example :
- Interaction scheme at the network level : a complete scheme of direct collection, without a transmitter.
- Interaction scheme at the application level : interaction through a resource.
For these schemes, the following normalization rules can be defined:
- Entities network level:
- Subject :
- Field: src.ip = <empty>
- Field: src.hostname = alex_host
- Field: src.fqdn = <empty>
- Object :
- Field: dst.ip = 10.0.0.1
- Field: dst.hostname = myoracle
- Field: dst.fqdn = myoracle.local
- Source (same as Object) :
- Field: event_source.ip = 10.0.0.1
- Field: event_source.hostname = myoracle
- Field: event_source.fqdn = myoracle.local
- Transmitter :
- Field: forwarder.ip = <empty>
- Field: forwarder.hostname = <empty>
- Field: forwarder.fqdn = <empty>
- Interaction channel :
- Field: interaction.id = 2342594
- Subject :
- Application level entities (collection of elements):
- Subject :
- Field: subject [1] .name = “Alex”
- Field: subject [1] .type = “account”
- Object :
- Field: object [1] .name = “Bob”
- Field: object [1] .type = “account”
- Resource :
- Field: resource [1] .name = “MYROLE”
- Field: resource [1] .type = “role”
- Subject :
Step 3. Defining the event category
After all the key entities of the event have been identified, it is necessary to describe the essence of the process itself, as reflected in the event, and transfer it to the normalization language. For these purposes, serves a system of categorization of events. The event categorization system was discussed in detail in a separate article , now let's see how it works in practice.
In order to unify normalization, the categorization system defines the following rules:
- For each category of each level of IT and IB events, an expert compiles a directory with a list of the information that needs to be found in the original event and normalized.
- If an event has been assigned to any category, the expert, in accordance with the directory, is obliged to find the required information and normalize it.
- Each category defines a set of fields for the scheme of a normalized event that must be filled.
Thus, the category selected for the event establishes a direct correspondence between:
- event semantics;
- important information to be extracted from the event, according to the assigned category;
- a set of fields of the scheme of the normalized event, in which this information must be "put".
This approach allows a category of any event to clearly understand what data in which fields of the normalized event are located.
If, with the support of new sources, it turns out that it is necessary to additionally extract some more important information from the events of a certain category, then it is recorded in the directory. In this case, you need:
- define the rules for filling in the event schema fields;
- conduct an audit of normalization for events in this category of all previously supported sources;
- add new information to previously normalized events.
Thus, the consistency of the changes is maintained. Consider the original example.
According to the categorization system, this event has the following categories:
- Categorization system : IT events
- First Level Category (Level 1) : User and Rights
- Second level category (Level 2) : User
- Third Level Category (Level 3) : Manipulation
The directory for this category looks like this:
- When normalizing the “ User and Rights ” category events , it is important to understand:
- If privilege escalation was used, then on whose behalf the process is implemented.
- Field: subject [i] .assign
- Have the actions been successful.
- Field: result.status
- What is the return code.
- Field: result.status.code
- If privilege escalation was used, then on whose behalf the process is implemented.
- When normalizing the “ User ” category events , it is important to understand:
- Is there any information about the ip-address, host name or fqdn of the user's machine?
- Fields: src.ip, src.hostname, src.fqdn
- Fields: dst.ip, dst.hostname, dst.fqdn
- What user account did you use?
- Fields: subject [i] .name, object [i] .name
- Is there information about his account in the OS.
- Fields: subject [i] .osname, object [i] .osname
- Is there any information about the domain account.
- Fields: subject [i] .domain, object [i] .domain
- Is there any information about the user application.
- Fields: subject [i] .application, object [i] .application
- Is there any information about the ip-address, host name or fqdn of the user's machine?
- When normalizing events of the “ Manipulation ” category , it is important to understand:
- Type of transaction.
- Field: interaction.type
- What have changed.
- Field: object [i] .name, object [i] .type - when changing in accounts
- Field: resource [i] .name, resource [i] .type - with a change in resources
- What changed.
- Field: object [i] .modify
- Field: resource [i] .modify
- If the operation was on a resource, who owns it.
- Field: resource [i] .owner
- Type of transaction.
We gave this handbook to demonstrate the principle of its formation; therefore, it does not claim to be accurate and complete.
As a result, an event normalized by this methodology looks like this:
Example of a normalized event in the third step of the methodology.
findings
Experience shows that it is often the errors of normalization and the lack of uniform rules of normalization that often lead to false positives of the correlation rules. Now we have an approach that allows, if not getting rid of, then at least to minimize the impact of the problem.
So, to summarize - the approach includes three steps:
- Step 1 . The expert tries to understand the general essence of the phenomenon described in the original event.
- Step 2 . The expert identifies the main entities of the network and application level in the event: Subject, Object, Source, Transmitter, Resource, Interaction Channel. Selects them in the event and defines the scheme of interaction of these entities. Each scheme forms the rules for allocating these entities in the fields of the normalized event - scheme. Details about this were written in the article devoted to the schemes of interaction of entities.
- Step 3 . The expert determines the category of the first, second and third levels. For each category, it creates a reference book that includes a description of the data that is important to find in the event when it is normalized, information about which fields of the normalized event it is necessary to “put” the found data.
Now, the only thing that separates us from the construction of the correlation rules “working out of the box” is the problem of constantly changing the entities themselves - the assets. They change addresses, introduce new assets, decommission old ones, switch cluster nodes, and virtual machines move from one data center to another and, sometimes, even with a change of addressing. How to overcome these problems, we will talk in the next article of the cycle.
Cycle of articles:
SIEM depths: out-of-box correlations. Part 1: Pure marketing or unsolvable problem?
SIEM depths: out-of-box correlations. Part 2. The data scheme as a reflection of the model of the "world"
Depth SIEM: correlation "out of the box." Part 3.1. Categorization of events
Depth SIEM: out-of-box correlations. Part 3.2. Event Normalization Methodology ( This article )
SIEM Depths: Out-of-Box Correlations. Part 4. System model as a context of correlation rules.
Depth SIEM: out-of-box correlations. Part 5. Methodology for developing correlation rules