R c H2O on Spark in HDInsight
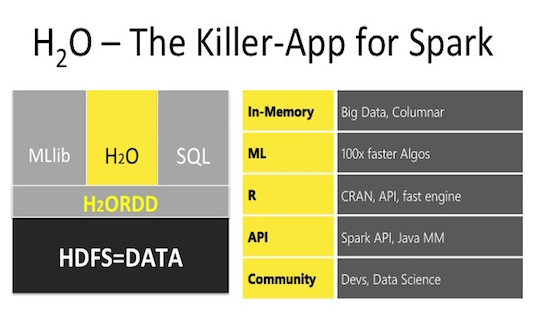 H2O is a machine learning library designed for both local computing and using clusters created directly using H2O or working on a Spark cluster . The integration of H2O in Spark clusters created in Azure HDInsight was recently added and in this publication (which is a complement to my last article: R and Spark ) we will consider the construction of machine learning models using H2O on such a cluster and compare it (time, metric) with the models provided sparklyr , is H2O a killer app for Spark ?
H2O is a machine learning library designed for both local computing and using clusters created directly using H2O or working on a Spark cluster . The integration of H2O in Spark clusters created in Azure HDInsight was recently added and in this publication (which is a complement to my last article: R and Spark ) we will consider the construction of machine learning models using H2O on such a cluster and compare it (time, metric) with the models provided sparklyr , is H2O a killer app for Spark ?
Overview of H20 Features in the HDInsight Spark Cluster
As mentioned in a previous post, at that time there were three ways to construct MO models using R on a cluster of the Spark , I remind you, is:
1) Package sparklyr , which offers different ways to read from different data sources, convenient dplyr data -manipulyatsiyu and a large set of different models.
2) R Server for Hadoop , software from Microsoft , using its functions for data manipulation and its own implementation of MO models.
3) The SparkR package , which offers its implementation of data manipulation and offers a small number of MO models (currently, in the version of Spark 2.2, the list of models has expanded significantly).
More functionality of each option can be found in Table 1 of the previous post.
Now a fourth way has appeared - to use H2O in Spark HDInsight clusters . Let's consider briefly its possibilities:
- Read-write, data manipulation - they are not directly in H2O, it is necessary to transfer (convert) finished data from Spark to H20 .
- There are slightly fewer machine learning models than sparklyr, but all the basic ones are available, here is a list of them:
- Generalized linear model
- Multilayer perceptron
- Random forest
- Gradient Boosting Machine
- Naive bayes
- Principal Components Analysis
- Singular value decomposition
- Generalized low rank model
- K-Means Clustering
- Anomaly Detection via Deep Learning Autoencoder.
- Additionally, you can use ensembles and stacking of several models using the h2oEnsemble package .
- The convenience of H2O models is that it is possible to immediately evaluate quality metrics, both on a training and on a validation sample.
- Tuning hyperparameters of algorithms on a fixed grid or random selection.
- The resulting models can be saved in binary form or in pure Java " Plain Old Java Object " code . ( POJO )
In general, the algorithm for working with H2O is as follows:
- Reading data using sparklyr package features .
- Manipulation, transformation, data preparation using sparklyr and replyr .
- Convert data to H2O format using rsparkling package .
- Building MO models and predicting data using h2o .
- Returning the results to Spark and / or locally to R using rsparkling and / or sparklyr .
Resources used
- H2O Cluster Artificial Intelligence for HDInsight 2.0.2.
This cluster is a complete solution with API for Python and Scala . R (apparently so far) is not integrated, but adding it is not difficult, this requires the following: - Install R and sparklyr , h2o , rsparkling packages on all nodes: head and work
- Install RStudio on the head node
- putty client locally to establish an ssh session with the head node of the cluster and tunnel the RStudio port to the local host port to access RStudio through a web browser.
Important: you need to install the h2o package from the source, choosing the version that matches both the Spark version and the rsparkling package , if necessary , specify the sparklingwater version to use before loading rsparkling (in this case options (rsparkling.sparklingwater.version = '2.0.8' . The table with the version dependencies is shown here : Installing software and packages on the head nodes is permissible directly through the node console, but there is no direct access to the working nodes, so the deployment of additional software must be done through Action Script .
First, we deploy the H2O Artificial Intelligence for HDInsight cluster , the configuration is the same, with 2 D12v2 head nodes and 4 D12v2 work nodes and 1 Sparkling water (service) node . After successfully deploying the cluster, using ssh connection to the head node, we install R , RStudio there (the current version of RStudio already has integrated capabilities for viewing Spark frames and cluster status), and the necessary packages. To install packages on work nodes, create an installation script (R and packages) and initiate it through Action Script . It is possible to use ready-made scripts located here:on the head nodes and on the working nodes . After all successful installations, we reset the ssh connection using tunneling to localhost: 8787 . So, now in the browser at localhost: 8787, we connect to RStudio and continue to work.
The advantage of using R lies in the fact that by installing a Shiny server on the same head node and creating a simple web interface on a flexdashboard , all calculations on the cluster, selection of hyperparameters, visualization of results, preparation of reports, etc., can be initiated on the created web- a site that will already be accessible from anywhere via a direct link in a browser (not considered here).
Data preparation and manipulation
I will use the same data set as last time, this is information about taxi rides and their payment. After downloading these files and placing them in hdfs , we read them from there and do the necessary conversions (the code is given in the last post).
Machine Learning Models
For a more or less comparable comparison, we choose the general models in both sparklyr and h2o , for the regression problems of such models there were three - linear regression, random forest and gradient boosting. The parameters of the algorithms were used by default, in case of differences, they were reduced to general (if possible), the accuracy of the model was checked on a holdout sample of 30%, according to the RMSE metric . The results are shown in Table 1 and in Figure 1.
Table 1. Model Results
| Model | Rmse | Time, sec |
|---|---|---|
| lm_mllib | 1,2507 | ten |
| lm_h2o | 1,2507 | 5,6 |
| rf_mllib | 1,2669 | 21.9 |
| rf_h2o | 1.2531 | 13,4 |
| gbm_mllib | 1.2553 | 108.3 |
| gbm_h2o | 1,2343 | 24.9 |

Fig. 1 Model results
As can be seen from the results, the advantage of the same h2o models is clearly visible over their implementation in sparklyr , both in runtime and in metric. The undisputed leader of h2o gbm , has good runtime and minimal RMSE . It is possible that by selecting hyperparameters for cross-validations, the picture could be different, but in this case, out of the box h2o is faster and better.
findings
In this article, supplemented functionality machine learning using R with H2O on a cluster Spark using platform HDInsight , and an example of the advantages of this method in contrast to the models of MO packet sparklyr , but in turn sparklyr has a significant advantage in easy pretreatment and data transformation.
###Подготовительная часть (подготовка данных) приведена в прошлом постеfeatures<-c("vendor_id",
"passenger_count",
"trip_time_in_secs",
"trip_distance",
"fare_amount",
"surcharge")
rmse <- function(formula, data) {
data %>%
mutate_(residual = formula) %>%
summarize(rmse = sqr(mean(residual ^ 2))) %>%
collect %>%
.[["rmse"]]
}trips_train_tbl <- sdf_register(taxi_filtered$training, "trips_train")
trips_test_tbl <- sdf_register(taxi_filtered$test, "trips_test")
actual <- trips.test.tbl %>%
select(tip_amount) %>%
collect() %>%
`[[`("tip_amount")
tbl_cache(sc, "trips_train")
tbl_cache(sc, "trips_test")
trips_train_h2o_tbl <- as_h2o_frame(sc, trips_train_tbl)
trips_test_h2o_tbl <- as_h2o_frame(sc, trips_test_tbl)
trips_train_h2o_tbl$vendor_id <- as.factor(trips_train_h2o_tbl$vendor_id)
trips_test_h2o_tbl$vendor_id <- as.factor(trips_test_h2o_tbl$vendor_id)
#mllib lm_mllib <- ml_linear_regression(x=trips_train_tbl, response = "tip_amount", features = features)
pred_lm_mllib <- sdf_predict(lm_mllib, trips_test_tbl)
rf_mllib <- ml_random_forest(x=trips_train_tbl, response = "tip_amount", features = features)
pred_rf_mllib <- sdf_predict(rf_mllib, trips_test_tbl)
gbm_mllib <-ml_gradient_boosted_trees(x=trips_train_tbl, response = "tip_amount", features = features)
pred_gbm_mllib <- sdf_predict(gbm_mllib, trips_test_tbl)
#h2olm_h2o <- h2o.glm(x =features, y = "tip_amount", trips_train_h2o_tbl)
pred_lm_h2o <- h2o.predict(lm_h2o, trips_test_h2o_tbl)
rf_h2o <- h2o.randomForest(x =features, y = "tip_amount", trips_train_h2o_tbl,ntrees=20,max_depth=5)
pred_rf_h2o <- h2o.predict(rf_h2o, trips_test_h2o_tbl)
gbm_h2o <- h2o.gbm(x =features, y = "tip_amount", trips_train_h2o_tbl)
pred_gbm_h2o <- h2o.predict(gbm_h2o, trips_test_h2o_tbl)
####pred.h2o <- data.frame(
tip.amount = actual,
as.data.frame(pred_lm_h2o),as.data.frame(pred_rf_h2o),as.data.frame(pred_gbm_h2o),
)
colnames(pred.h2o)<-c("tip.amount", "lm", "rf", "gbm")
result <- data.frame(
RMSE = c(
lm.mllib = rmse(~ tip_amount - prediction, pred_lm_mllib),
lm.h2o = rmse(~ tip.amount - lm, pred.h2o ),
rf.mllib = rmse(~ tip.amount - prediction, pred_rf_mllib),
rf.h2o = rmse(~ tip_amount - rf, pred.h2o),
gbm.mllib = rmse(~ tip_amount - prediction, pred_gbm_mllib),
gbm.h2o = rmse(~ tip.amount - gbm, pred.h2o)
)
)