Conference DEFCON 18. Troll reverse engineering with the help of mathematics
- Transfer
Trolling with math is what I'm going to talk about. This is not some kind of fashionable hacker stuff, rather it’s artistic expression, a funny intelligent technology so that people would consider you a jerk. Now I will check if my report is ready for display on the screen. It seems everything is going fine, so I can introduce myself.

My name is Frank Tu, it is written frank ^ 2 and @franksquared on Twitter, because Twitter also has some kind of spammer called "frank 2". I tried to apply social engineering to them so that they would delete his account, because technically it is spam and I have the right to get rid of it as a clone. But apparently, if you are honest with them, they do not reciprocate you, because despite my request to delete the spam account, they didn’t do anything with it, so I sent this fucking Twitter to hell.
Many people recognize me by my cap. I work in regional groups DefCon DC949 and DC310. I also work with Rapid7, but I can’t talk about it here without obscenities, and my manager doesn’t want me to swear. So, I prepared this gig for DefCon and I’m going to meet in 15 minutes, although this is quite a difficult topic. In essence, this is a standard presentation, which is dedicated to reverse engineering and related funny things.
When discussing this topic on Twitter, two camps were formed. One guy said: “I have no idea what this fucking frank ^ 2 is talking about, but it's awesome!” The second guy from Reddit saw my slides and was upset about the links to things that were not relevant to the topic, got angry that such a serious topic was not fully covered, so I wished for my presentation to have “more content and less garbage”.

Therefore, I want to focus on this quote. Nothing personal, dude from Reddit - I say this not only in case he is present in this room, but also because it was a fair criticism. Because a conversation that does not contain enough useful content is just empty talk.
The topic of my conversation represents a standard routine for hackers, but it seems to me that, in fact, the speakers usually do not try to present their information in an entertaining way, even when it is possible, preferring dry, diluted conclusions. “Here is the IP, here is the ESP, here's how you can perform the exploit, here is my“ zero day ”, now clap!” - and everyone claps their hands.
Thanks for the applause, I appreciate it! It seems to me that there are many interesting points in my material, so it deserves to be expounded in a somewhat entertaining manner, which I will try to do.
You will see an extremely superficial attitude towards computer science and a completely childlike humor, so I hope you appreciate what I am going to show here. I am very sorry if you came here looking for a serious conversation.
On the slide, you see a scientific analysis of my last report comparing the proportion of a strictly scientific approach and the proportion of “medicine” that provides computer security.

You see, the “medications” are much more, but don’t worry, now the share of science has slightly increased.

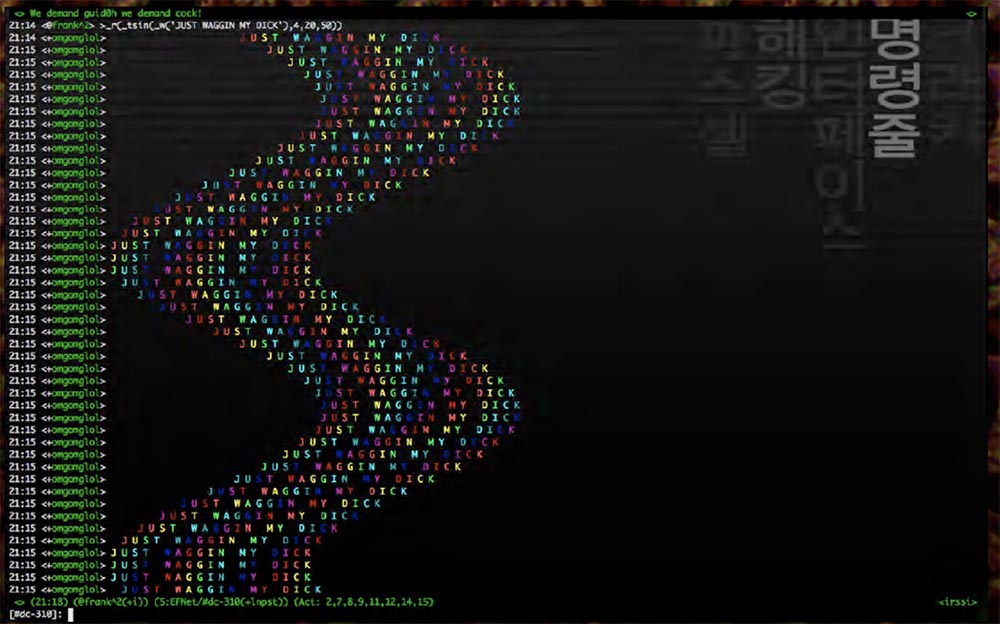
So, some time ago, my friend Merlin, who is sitting in the front row, wrote an amazing bot based on the IRC Python script, which occupies just one line.
This is really a terrific exercise for learning functional programming, which is a lot of fun. You can simply add one function after another and get combinations of all sorts of different functions, and all this is drawn on the screen as a rainbow wave, in general, this is one of the most stupid things you can do.
I thought, what if apply this principle to binary files? I do not know where I came up with this idea, but it turned out awesome! However, I want to clarify some basic concepts.
It is possible that your math teacher introduced these functions much more difficult than they really are.

So, the formula f (x) is very simple in its meaning, it works like normal functions. You have X, you have input, and then you get X 7 times, and this is equal to your value. In Python, you can make a function (lambda x: x * 7). If you want to work with Java - I'm sorry, I hope you never want to do it - you can do something like:
You know, math functions can even be much more complicated, but that's all we need to know about them at the moment.
If we consider the assembly of the code, we can notice that the JMP and CALL instructions are not tied to specific values, they work with an offset. If you use a debugger, you can see that the JMP00401000 is more like the instruction “jump over several bytes” than a specific instruction to jump over 5 or 10 bytes. The same applies to the CALL function, except that it pushes a whole bunch of things into your stack. The exception is the case when you “paste” the address to the register, that is, refer to a specific address. Here everything is completely different. After you hook an address to a register and do something like CALL EAX, the function accesses a specific value in EAX. The same goes for CALL [EAX] or JMP [EAX] - it just dereferences EAX and goes to this address. When using a debugger, you may not be able to determine which specific address CALL refers to. This can be a problem, so you should be aware of this.
Let's look at the JMP SHORT “short jump” function. This is a special instruction in the x86 architecture that allows you to use an offset of 1 byte instead of an offset of 4 bytes, which reduces the used memory space. This will make a difference later for all the manipulations that will occur with individual instructions. It is important to keep in mind that JMP SHORT has a range of 256 bytes. However, there is no such thing as CALL SHORT.

Now consider the witchcraft of computer science. In the middle of creating these slides, I realized that in fact you can define an assembly as zero space, that is, technically there is zero space between each instruction. If you look at the individual instructions, you will see that each is executed one by one after the other instruction. Technically, this can be interpreted as an unconditional jump to the next instruction. This gives us the space between each assembly instruction, while each instruction is correspondingly associated with an unconditional leap.
If you look at this example of assembly, by the way, these are very simple things that I recommend to decode using ASCII, so, this is just a set of normal instructions.
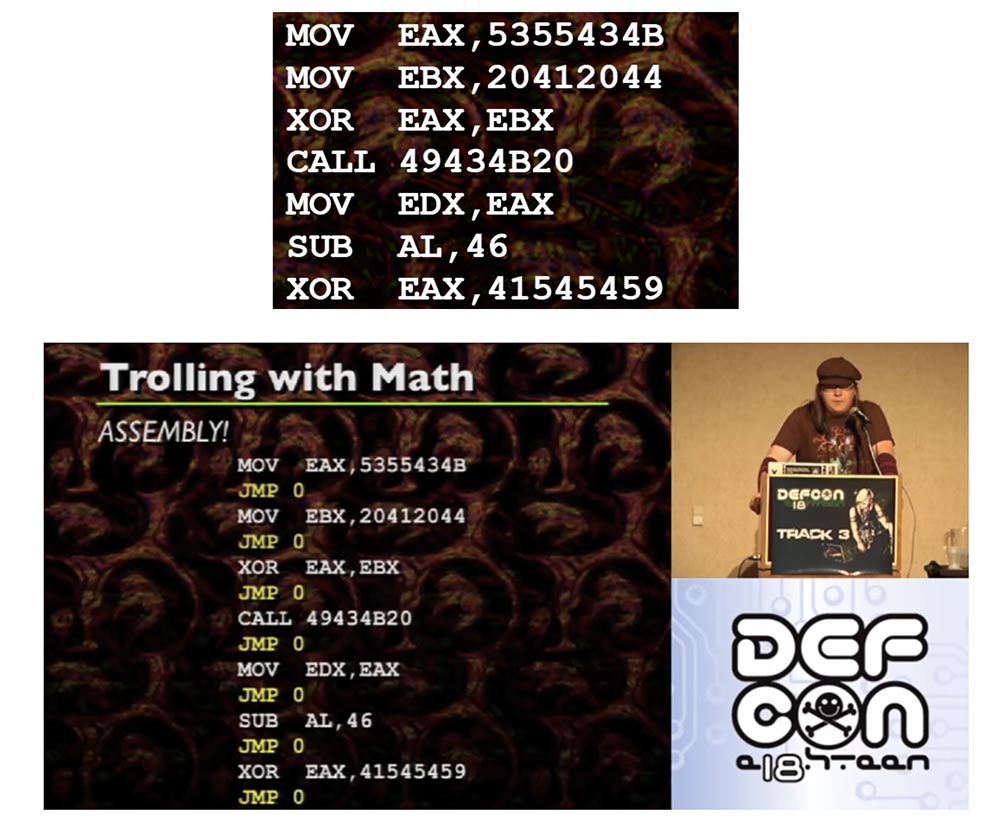
JMP 0, located between each instruction, are unconditional jumps that you usually do not see. They follow each other after each instruction. Therefore, it is possible to place each individual assembly instruction in an arbitrary place of memory if and only if each individual instruction is accompanied by an unconditional jump to the next instruction. Because if you transfer the assembly and you need to use the same code as before, you must attach an unconditional jump to each instruction.
Let's look further. A one-dimensional array can technically be interpreted as a two-dimensional array, it just takes a bit of math, rows or something like them, I won’t say for sure, but it’s not too complicated. This gives us the opportunity to interpret the location in memory in the form of a lattice (x, y). Combined with the interpretation of the empty space between instructions as unconditional jumps that can be linked to each other, we can literally draw instructions. This is amazing!
In order to implement this in practice, the following steps are necessary:
Unfortunately, many questions arise here. It's like with gravity, which works only in theory, but in practice we see a completely different one. Because in reality, x86 sends your JMP instructions, CALL instructions to the line, distorts your self-referential code, a self-modifying code that uses iteration.

Let's start with JMP instructions. Since JMP instructions have an offset, when placed in an arbitrary location, they no longer point to where you think they should be. SHORT JMP find themselves in a similar position. Randomly placed by your function (x, y), they will not indicate what you are counting on. But unlike “long” JMP, “short” JMP is easier to fix, especially if you are dealing with a one-dimensional array. SHORT JMP is easy to convert to regular JMP, but then you have to figure out what the new offset has become.
Working with register-based JMP is also a headache, and because they require hard shifts and can be calculated during execution, there is no easy way to know where they are going. To automatically determine each register, you need to use a bunch of knowledge from compilation theory. In the process of execution there may be function pointers, class pointers, and the like. However, if you do not want to do additional work in order to do all this, then you can not do it. The functions f (x) work in real code is not as elegant as on paper. If you want to do it properly, you need to do a lot of work.
To define class pointers and similar things, you need to conjure with C and C ++. Before saving, during disassembly, convert your SHORT JMP to regular JMP, because you have to deal with the offset, it is quite simple.
Trying to calculate actual displacements is a huge headache. All instructions found by you have offsets that will move when the code is moved, and must be recalculated. This means that you need to follow the instructions and where they move, like goals. I find it difficult to explain to you on slides, but an example of how to achieve this is on the CD with the materials of this conference.
After you place all the instructions, replace the old offsets with the new offsets. If you do not damage the offset, then everything will work out. Now, when you are prepared, there is a real opportunity to translate ideas at the highest level. For this you need:
If you put everything in the right places, then we get strange things - everything gets confused, instructions jump to strange places of memory, and it all looks just enchanting.

Does all this have any practical significance or is it just a circus performance? The applied value of such transformations is as follows. The isolation of assembly instructions and several steps to calculate f (x) allow us to place these assembly instructions anywhere in the buffer without any user interaction. To confuse the paths of code execution, all you need to do is to mathematically write function and pointers in some assembler, choosing them randomly.
This greatly simplifies polymorphic encoding methods. Instead of writing code every time that manipulates your code in a certain way, you can write a number of functions that randomly determine the position of your code, and then select these functions as random, etc.
Anti-reversing is not as cool and fresh as antidebugging technique.
Anti-reversing is not about how much fun you will get from making it impossible to use IDA and not how much your computer will use the Last Measure pictures from GNAA, although it's pretty darn fun. Anti-reversing is just being an asshole, because if you, as the last asshole, get a reviser, dude who breaks the protections of different systems, he will simply get angry, send this malicious program to hell and go.
In the meantime, you can sell all your bots to Russian business networks, because you “omit” everyone who does reverse engineering with your software. Everyone knows how to find antidebugging techniques on Google, but they won’t find a solution to the problems posed by creative things. The most creative anti-fans will force revermers to break off their fingers on the keyboard and leave fist-sized holes in the walls. Reversy will boil with anger, they will not understand what the hell you did, because your code messed up.
This is a kind of game on the nerves, a psychological thing, if you creatively approach this business and create a truly amazing anti-reverse, you can be proud of it. But you know that in reality, just trying to keep them away from your code.
So what am I going to do? I am going to take the functions of entanglement and confuse them. Then I am going to use the second version of the entanglement of entangled functions and apply the entanglement again. So let's pull out the code. This is a sample of mathematical trolling, which I took as an example.
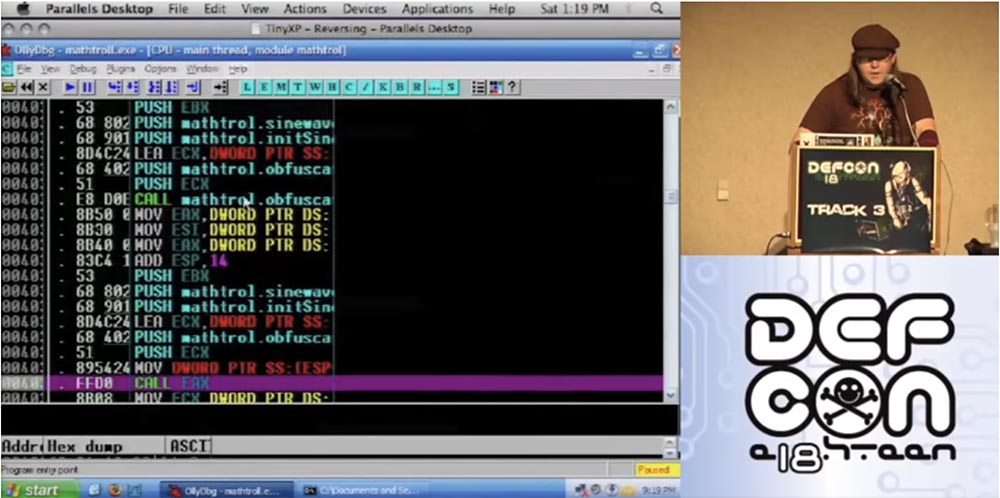
So, I enter the command "to confuse by the formula" in the opened window.
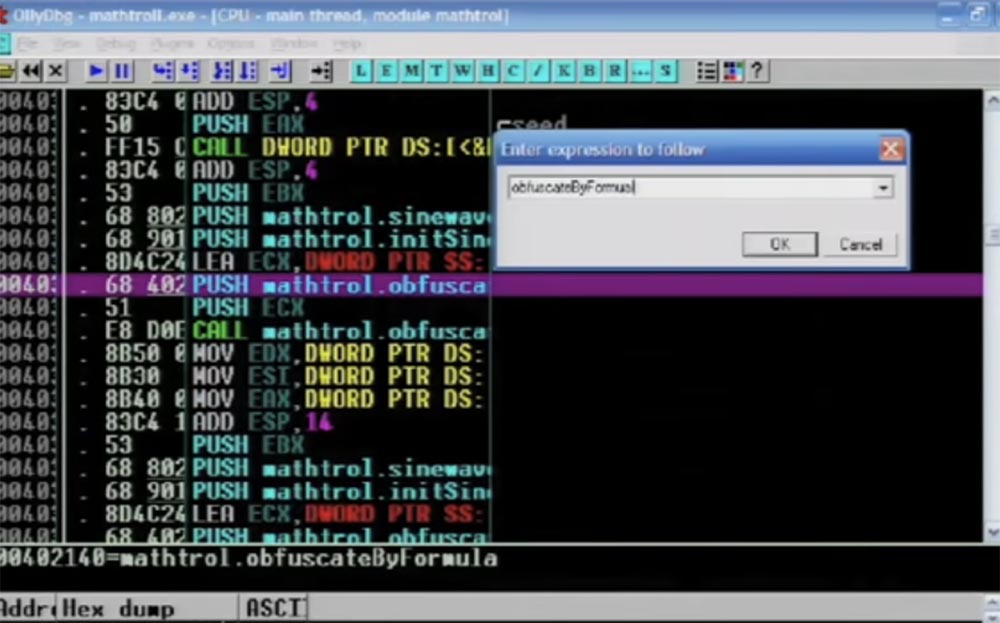
Further you see assembly instructions which perform the work. Notice that I use C ++ here, although at the slightest opportunity I try to avoid it.
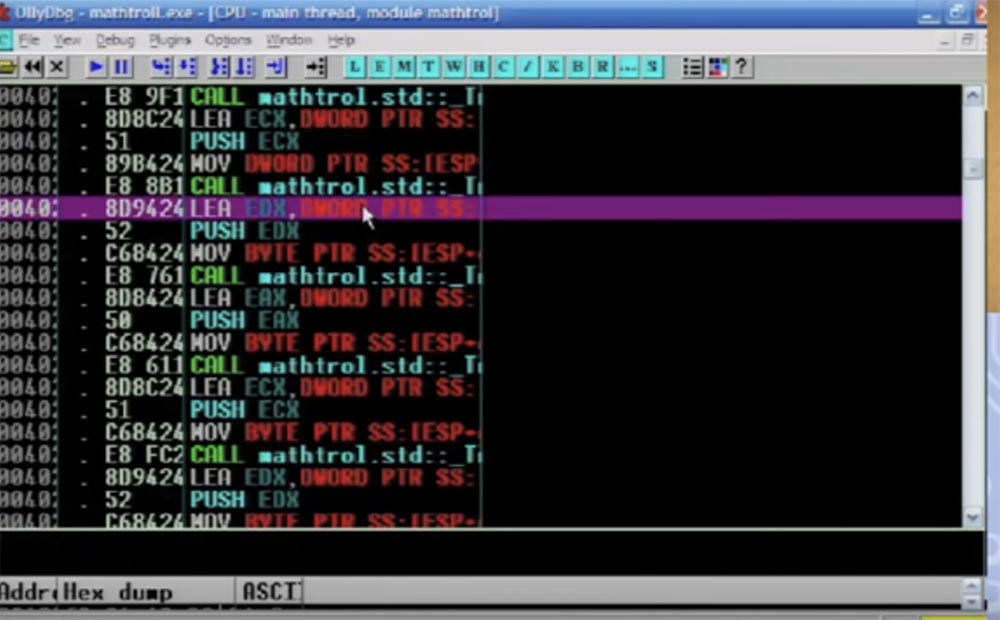
Here is the active function CALL EAX, followed by the jump instruction that will be applied, you see a bunch of different things in the buffer, and all this is done with each individual instruction.
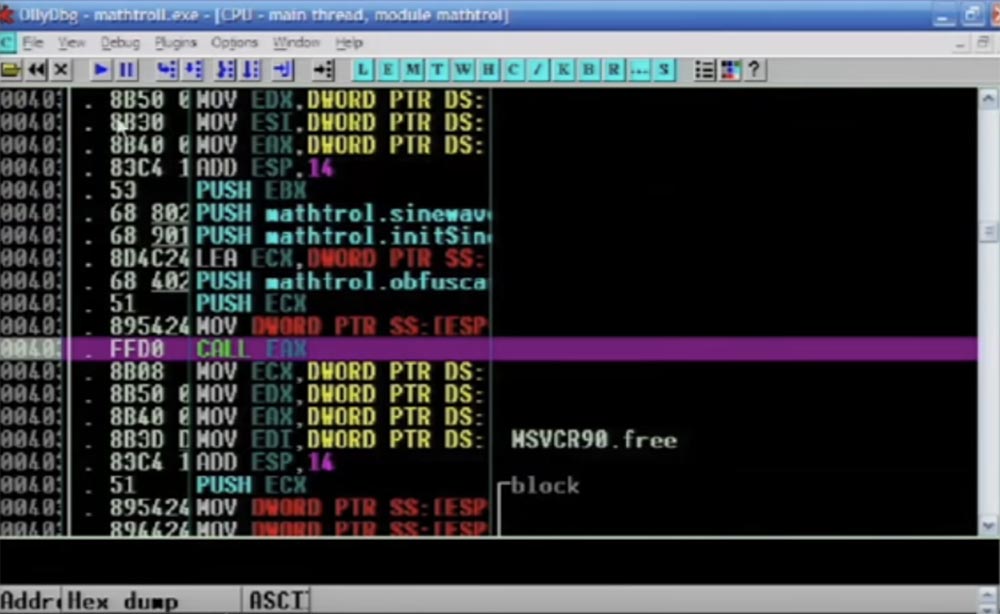

Now I rewind the program to the end, and you will see the result. So, the code still looks great, a bunch of JMP instructions are gathered here, it looks confusing, and in reality it is confusing.
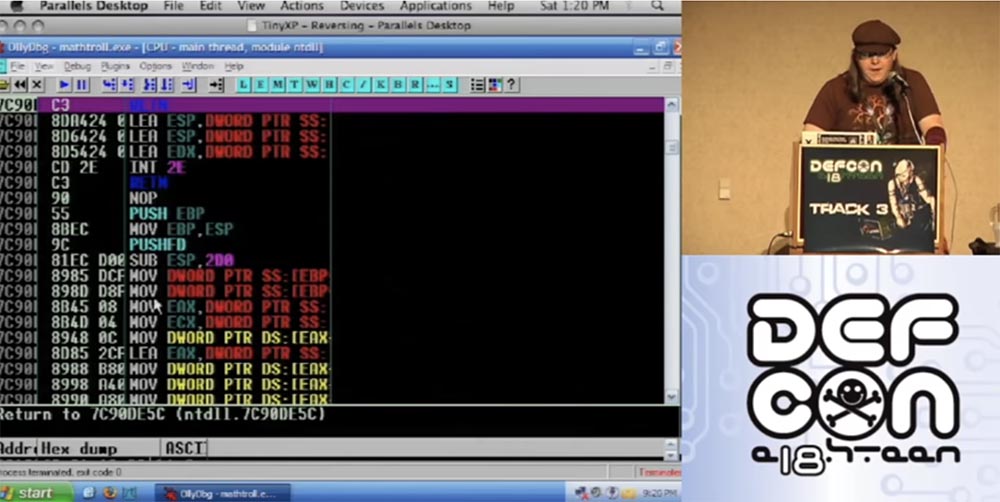
The next slide shows a graphical representation of how the stack looks.

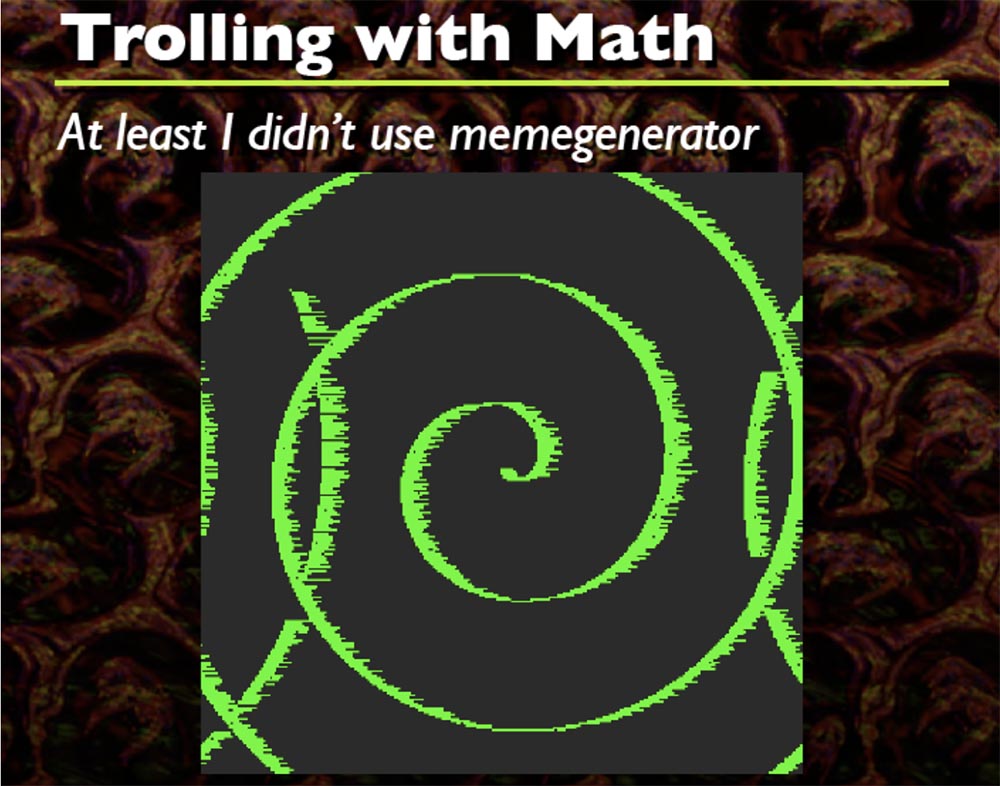
Every time this happens, I generate a random sine wave formula that wears an arbitrary shape, you see a bunch of different shapes, and that's cool. I think that the code starts somewhere at the top left, but I do not remember exactly. This is how it twists everything, you can not only make sinusoids, but also twist spirals.
Only two formulas work here that I have included in the source code. Based on this, you can do a lot of creative things that you want, in essence it's just a DIFF from the initial buffer to the final buffer.
The problem is that this code example uses unconditional jumps, which is really bad, because the code must be exactly the same as before, that is, unconditional jumps follow only in one direction. Therefore, you need to go from the entry point to the end in the same way, get rid of the jump instructions and you're done - you got your code! What to do? It is necessary to turn unconditional jumps into conditional ones. Conditional jumps are performed in two directions, it is much better, we can say that it is 50% better.
Here we have an interesting dilemma: if we need conditional jumps, then we also need to use unconditional jumps ... what the fuck? And what should we do? Opaque predicates will save us! For those who do not know, an opaque predicate is essentially a boolean statement that always holds for a particular version, regardless of anything.
So let's consider the zero space expansion that I mentioned earlier. If you have a set of instructions and they have unconditional jumps of transitions between each instruction, it follows that a series of assembly instructions that do not have a direct effect on the instructions we need may precede or follow a single instruction.
For example, if you have written very specific instructions that do not change the main assembly of what you are trying to confuse, that is, you try not to contact registers as long as you maintain the state of each assembly instruction. And this is even more amazing.
You can view each assembly instruction that can be confused, like a preamble, assembly data, and postscript. The preamble is what precedes the assembly instruction, and the postscript is what follows it. The preamble is usually used or can be used for two things:
But the preamble is substantially limited because you cannot do too much.
Postscript is more fun stuff. It can be used for:
Right now, I am working to make it possible to encrypt and decrypt each individual instruction so that when each instruction is executed, it decrypts the next section, the next section, the next, and so on. The next slide shows an example of this.

The preamble lines and the debugger call are highlighted in green. All that makes this call is that it checks if we have a debugger, and then we move to an arbitrary section of code.
Below we have a very simple opaque predicate. If you maintain the EAX value in postscript to the top instruction, then follow the XOR operator, so your JZ thinks: “well, I obviously can go left or right, I think I’d better go to the right, because there is 0”. Then POP EAX is executed, your EAX comes back, after which the next instruction is processed, and so on.
This obviously creates much bigger problems than our basic strategy, such as residual effects and the complication of generating different instruction sets. Therefore, it will be very difficult to determine how an instruction affects another instruction. You can throw slippers at me, because I have not finished this amazing program yet, but you can follow the progress of the development in my blog.

I note that our formulas f (x) need not be calculated iteratively, for example, f (1), f (2), ... f (n). Nothing prevents them from being randomly calculated. If you are smart, you can determine how many instructions you need, and then assign, for example, f (27), f (54), f (9) for each instruction, and this will be the place where your instruction will be placed randomly. When you do this, depending on how you wrote your code, you can stop it in advance, and the code will still bind your instructions randomly.
If your code is generated based on a predictable formula, then it follows that the entry point is also predictable, so you can take one level more before you finish getting the code, and significantly confuse the entry point in one way or another. For example, take 300 assembly instructions coming from one entry point.
Now let's talk about the shortcomings.

This method requires careful compilation of the code, mainly using GCC or God forbid, using C ++. Actually, C ++ is a pretty cool language for several reasons, but you know that all compilers suck. So the main thing in this business is a competent handwritten compilation, because if your attempt to confuse your own assembly causes the approval of the gang that invented the Conficker worm, then you screwed up.
You will need a large amount of memory. Remember the picture with sine waves. Red is the code, and blue space is the memory necessary for its work, and it should be enough for everything to work as it should.
You will probably deal with a giant dataset after you complete the code. And it will increase significantly if you want to confuse more than one function.
Function pointers behave unpredictably - sometimes correctly, sometimes not. It depends on what you are doing, and there will definitely be a problem, because you are not able to predict where and when the function pointer works in your assembly.
The smarter you generate the obfuscation and manipulate the assembly in the preamble and postscript, the more difficult the fix and debug. So writing such a code is like balancing between “well, I will carefully insert one or two JMPs here” and “how the hell can I figure this out in a short time”? So you just have to insert the instructions and then several months to understand what you have done.
Hope you learned something useful today. In my opinion, I really got drunk and therefore I don’t really understand what happened now. The next slide shows my contacts on Twitter, my blog and website, so come visit or write.

That's all, thank you for coming!
Thank you for staying with us. Do you like our articles? Want to see more interesting materials? Support us by placing an order or recommending to friends, 30% discount for Habr's users on a unique analogue of the entry-level servers that we invented for you: The whole truth about VPS (KVM) E5-2650 v4 (6 Cores) 10GB DDR4 240GB SSD 1Gbps from $ 20 or how to share the server? (Options are available with RAID1 and RAID10, up to 24 cores and up to 40GB DDR4).
VPS (KVM) E5-2650 v4 (6 Cores) 10GB DDR4 240GB SSD 1Gbps until January for free if you pay for a period of six months, you can order here .
Dell R730xd 2 times cheaper? Only we have 2 x Intel Dodeca-Core Xeon E5-2650v4 128GB DDR4 6x480GB SSD 1Gbps 100 TV from $ 249in the Netherlands and the USA! Read about How to build an infrastructure building. class c using servers Dell R730xd E5-2650 v4 worth 9000 euros for a penny?
My name is Frank Tu, it is written frank ^ 2 and @franksquared on Twitter, because Twitter also has some kind of spammer called "frank 2". I tried to apply social engineering to them so that they would delete his account, because technically it is spam and I have the right to get rid of it as a clone. But apparently, if you are honest with them, they do not reciprocate you, because despite my request to delete the spam account, they didn’t do anything with it, so I sent this fucking Twitter to hell.
Many people recognize me by my cap. I work in regional groups DefCon DC949 and DC310. I also work with Rapid7, but I can’t talk about it here without obscenities, and my manager doesn’t want me to swear. So, I prepared this gig for DefCon and I’m going to meet in 15 minutes, although this is quite a difficult topic. In essence, this is a standard presentation, which is dedicated to reverse engineering and related funny things.
When discussing this topic on Twitter, two camps were formed. One guy said: “I have no idea what this fucking frank ^ 2 is talking about, but it's awesome!” The second guy from Reddit saw my slides and was upset about the links to things that were not relevant to the topic, got angry that such a serious topic was not fully covered, so I wished for my presentation to have “more content and less garbage”.
Therefore, I want to focus on this quote. Nothing personal, dude from Reddit - I say this not only in case he is present in this room, but also because it was a fair criticism. Because a conversation that does not contain enough useful content is just empty talk.
The topic of my conversation represents a standard routine for hackers, but it seems to me that, in fact, the speakers usually do not try to present their information in an entertaining way, even when it is possible, preferring dry, diluted conclusions. “Here is the IP, here is the ESP, here's how you can perform the exploit, here is my“ zero day ”, now clap!” - and everyone claps their hands.
Thanks for the applause, I appreciate it! It seems to me that there are many interesting points in my material, so it deserves to be expounded in a somewhat entertaining manner, which I will try to do.
You will see an extremely superficial attitude towards computer science and a completely childlike humor, so I hope you appreciate what I am going to show here. I am very sorry if you came here looking for a serious conversation.
On the slide, you see a scientific analysis of my last report comparing the proportion of a strictly scientific approach and the proportion of “medicine” that provides computer security.
You see, the “medications” are much more, but don’t worry, now the share of science has slightly increased.
So, some time ago, my friend Merlin, who is sitting in the front row, wrote an amazing bot based on the IRC Python script, which occupies just one line.
This is really a terrific exercise for learning functional programming, which is a lot of fun. You can simply add one function after another and get combinations of all sorts of different functions, and all this is drawn on the screen as a rainbow wave, in general, this is one of the most stupid things you can do.
I thought, what if apply this principle to binary files? I do not know where I came up with this idea, but it turned out awesome! However, I want to clarify some basic concepts.
It is possible that your math teacher introduced these functions much more difficult than they really are.
So, the formula f (x) is very simple in its meaning, it works like normal functions. You have X, you have input, and then you get X 7 times, and this is equal to your value. In Python, you can make a function (lambda x: x * 7). If you want to work with Java - I'm sorry, I hope you never want to do it - you can do something like:
public static int multiplyBySevenAndReturn(Integer x)
{ return x * 7; }You know, math functions can even be much more complicated, but that's all we need to know about them at the moment.
If we consider the assembly of the code, we can notice that the JMP and CALL instructions are not tied to specific values, they work with an offset. If you use a debugger, you can see that the JMP00401000 is more like the instruction “jump over several bytes” than a specific instruction to jump over 5 or 10 bytes. The same applies to the CALL function, except that it pushes a whole bunch of things into your stack. The exception is the case when you “paste” the address to the register, that is, refer to a specific address. Here everything is completely different. After you hook an address to a register and do something like CALL EAX, the function accesses a specific value in EAX. The same goes for CALL [EAX] or JMP [EAX] - it just dereferences EAX and goes to this address. When using a debugger, you may not be able to determine which specific address CALL refers to. This can be a problem, so you should be aware of this.
Let's look at the JMP SHORT “short jump” function. This is a special instruction in the x86 architecture that allows you to use an offset of 1 byte instead of an offset of 4 bytes, which reduces the used memory space. This will make a difference later for all the manipulations that will occur with individual instructions. It is important to keep in mind that JMP SHORT has a range of 256 bytes. However, there is no such thing as CALL SHORT.
Now consider the witchcraft of computer science. In the middle of creating these slides, I realized that in fact you can define an assembly as zero space, that is, technically there is zero space between each instruction. If you look at the individual instructions, you will see that each is executed one by one after the other instruction. Technically, this can be interpreted as an unconditional jump to the next instruction. This gives us the space between each assembly instruction, while each instruction is correspondingly associated with an unconditional leap.
If you look at this example of assembly, by the way, these are very simple things that I recommend to decode using ASCII, so, this is just a set of normal instructions.
JMP 0, located between each instruction, are unconditional jumps that you usually do not see. They follow each other after each instruction. Therefore, it is possible to place each individual assembly instruction in an arbitrary place of memory if and only if each individual instruction is accompanied by an unconditional jump to the next instruction. Because if you transfer the assembly and you need to use the same code as before, you must attach an unconditional jump to each instruction.
Let's look further. A one-dimensional array can technically be interpreted as a two-dimensional array, it just takes a bit of math, rows or something like them, I won’t say for sure, but it’s not too complicated. This gives us the opportunity to interpret the location in memory in the form of a lattice (x, y). Combined with the interpretation of the empty space between instructions as unconditional jumps that can be linked to each other, we can literally draw instructions. This is amazing!
In order to implement this in practice, the following steps are necessary:
- disassemble each instruction to find out what the code is;
- allocate a place in memory that is much larger than the size of a set of instructions. I usually reserve 10 times the memory size of the code;
- for each instruction, determine f (x);
- set each instruction to the corresponding (x, y) memory location;
- add an unconditional jump to the instruction;
- Mark the memory as executable and run the code.
Unfortunately, many questions arise here. It's like with gravity, which works only in theory, but in practice we see a completely different one. Because in reality, x86 sends your JMP instructions, CALL instructions to the line, distorts your self-referential code, a self-modifying code that uses iteration.
Let's start with JMP instructions. Since JMP instructions have an offset, when placed in an arbitrary location, they no longer point to where you think they should be. SHORT JMP find themselves in a similar position. Randomly placed by your function (x, y), they will not indicate what you are counting on. But unlike “long” JMP, “short” JMP is easier to fix, especially if you are dealing with a one-dimensional array. SHORT JMP is easy to convert to regular JMP, but then you have to figure out what the new offset has become.
Working with register-based JMP is also a headache, and because they require hard shifts and can be calculated during execution, there is no easy way to know where they are going. To automatically determine each register, you need to use a bunch of knowledge from compilation theory. In the process of execution there may be function pointers, class pointers, and the like. However, if you do not want to do additional work in order to do all this, then you can not do it. The functions f (x) work in real code is not as elegant as on paper. If you want to do it properly, you need to do a lot of work.
To define class pointers and similar things, you need to conjure with C and C ++. Before saving, during disassembly, convert your SHORT JMP to regular JMP, because you have to deal with the offset, it is quite simple.
Trying to calculate actual displacements is a huge headache. All instructions found by you have offsets that will move when the code is moved, and must be recalculated. This means that you need to follow the instructions and where they move, like goals. I find it difficult to explain to you on slides, but an example of how to achieve this is on the CD with the materials of this conference.
After you place all the instructions, replace the old offsets with the new offsets. If you do not damage the offset, then everything will work out. Now, when you are prepared, there is a real opportunity to translate ideas at the highest level. For this you need:
- disassemble instructions;
- prepare a memory buffer;
- initialize existing constants f (x);
- iterate the values of f (x) and certain data pointers on which your code will be written while tracking fucking instructions;
- to assign instructions to the corresponding pointers created;
- fix all conditional jumps;
- Mark a new section of the memory as executable;
- execute code.
If you put everything in the right places, then we get strange things - everything gets confused, instructions jump to strange places of memory, and it all looks just enchanting.
Does all this have any practical significance or is it just a circus performance? The applied value of such transformations is as follows. The isolation of assembly instructions and several steps to calculate f (x) allow us to place these assembly instructions anywhere in the buffer without any user interaction. To confuse the paths of code execution, all you need to do is to mathematically write function and pointers in some assembler, choosing them randomly.
This greatly simplifies polymorphic encoding methods. Instead of writing code every time that manipulates your code in a certain way, you can write a number of functions that randomly determine the position of your code, and then select these functions as random, etc.
Anti-reversing is not as cool and fresh as antidebugging technique.
Anti-reversing is not about how much fun you will get from making it impossible to use IDA and not how much your computer will use the Last Measure pictures from GNAA, although it's pretty darn fun. Anti-reversing is just being an asshole, because if you, as the last asshole, get a reviser, dude who breaks the protections of different systems, he will simply get angry, send this malicious program to hell and go.
In the meantime, you can sell all your bots to Russian business networks, because you “omit” everyone who does reverse engineering with your software. Everyone knows how to find antidebugging techniques on Google, but they won’t find a solution to the problems posed by creative things. The most creative anti-fans will force revermers to break off their fingers on the keyboard and leave fist-sized holes in the walls. Reversy will boil with anger, they will not understand what the hell you did, because your code messed up.
This is a kind of game on the nerves, a psychological thing, if you creatively approach this business and create a truly amazing anti-reverse, you can be proud of it. But you know that in reality, just trying to keep them away from your code.
So what am I going to do? I am going to take the functions of entanglement and confuse them. Then I am going to use the second version of the entanglement of entangled functions and apply the entanglement again. So let's pull out the code. This is a sample of mathematical trolling, which I took as an example.
So, I enter the command "to confuse by the formula" in the opened window.
Further you see assembly instructions which perform the work. Notice that I use C ++ here, although at the slightest opportunity I try to avoid it.
Here is the active function CALL EAX, followed by the jump instruction that will be applied, you see a bunch of different things in the buffer, and all this is done with each individual instruction.
Now I rewind the program to the end, and you will see the result. So, the code still looks great, a bunch of JMP instructions are gathered here, it looks confusing, and in reality it is confusing.
The next slide shows a graphical representation of how the stack looks.
Every time this happens, I generate a random sine wave formula that wears an arbitrary shape, you see a bunch of different shapes, and that's cool. I think that the code starts somewhere at the top left, but I do not remember exactly. This is how it twists everything, you can not only make sinusoids, but also twist spirals.
Only two formulas work here that I have included in the source code. Based on this, you can do a lot of creative things that you want, in essence it's just a DIFF from the initial buffer to the final buffer.
The problem is that this code example uses unconditional jumps, which is really bad, because the code must be exactly the same as before, that is, unconditional jumps follow only in one direction. Therefore, you need to go from the entry point to the end in the same way, get rid of the jump instructions and you're done - you got your code! What to do? It is necessary to turn unconditional jumps into conditional ones. Conditional jumps are performed in two directions, it is much better, we can say that it is 50% better.
Here we have an interesting dilemma: if we need conditional jumps, then we also need to use unconditional jumps ... what the fuck? And what should we do? Opaque predicates will save us! For those who do not know, an opaque predicate is essentially a boolean statement that always holds for a particular version, regardless of anything.
So let's consider the zero space expansion that I mentioned earlier. If you have a set of instructions and they have unconditional jumps of transitions between each instruction, it follows that a series of assembly instructions that do not have a direct effect on the instructions we need may precede or follow a single instruction.
For example, if you have written very specific instructions that do not change the main assembly of what you are trying to confuse, that is, you try not to contact registers as long as you maintain the state of each assembly instruction. And this is even more amazing.
You can view each assembly instruction that can be confused, like a preamble, assembly data, and postscript. The preamble is what precedes the assembly instruction, and the postscript is what follows it. The preamble is usually used or can be used for two things:
- correction of the consequences of the opaque predicate of the previous preamble;
- anti-debugging code snippets.
But the preamble is substantially limited because you cannot do too much.
Postscript is more fun stuff. It can be used for:
- opaque predicates and intricate jumps to the following sections of the code;
- antidebugging and obfuscation of general code execution;
- encrypt and decrypt various code fragments in the program itself.
Right now, I am working to make it possible to encrypt and decrypt each individual instruction so that when each instruction is executed, it decrypts the next section, the next section, the next, and so on. The next slide shows an example of this.
The preamble lines and the debugger call are highlighted in green. All that makes this call is that it checks if we have a debugger, and then we move to an arbitrary section of code.
Below we have a very simple opaque predicate. If you maintain the EAX value in postscript to the top instruction, then follow the XOR operator, so your JZ thinks: “well, I obviously can go left or right, I think I’d better go to the right, because there is 0”. Then POP EAX is executed, your EAX comes back, after which the next instruction is processed, and so on.
This obviously creates much bigger problems than our basic strategy, such as residual effects and the complication of generating different instruction sets. Therefore, it will be very difficult to determine how an instruction affects another instruction. You can throw slippers at me, because I have not finished this amazing program yet, but you can follow the progress of the development in my blog.
I note that our formulas f (x) need not be calculated iteratively, for example, f (1), f (2), ... f (n). Nothing prevents them from being randomly calculated. If you are smart, you can determine how many instructions you need, and then assign, for example, f (27), f (54), f (9) for each instruction, and this will be the place where your instruction will be placed randomly. When you do this, depending on how you wrote your code, you can stop it in advance, and the code will still bind your instructions randomly.
If your code is generated based on a predictable formula, then it follows that the entry point is also predictable, so you can take one level more before you finish getting the code, and significantly confuse the entry point in one way or another. For example, take 300 assembly instructions coming from one entry point.
Now let's talk about the shortcomings.
This method requires careful compilation of the code, mainly using GCC or God forbid, using C ++. Actually, C ++ is a pretty cool language for several reasons, but you know that all compilers suck. So the main thing in this business is a competent handwritten compilation, because if your attempt to confuse your own assembly causes the approval of the gang that invented the Conficker worm, then you screwed up.
You will need a large amount of memory. Remember the picture with sine waves. Red is the code, and blue space is the memory necessary for its work, and it should be enough for everything to work as it should.
You will probably deal with a giant dataset after you complete the code. And it will increase significantly if you want to confuse more than one function.
Function pointers behave unpredictably - sometimes correctly, sometimes not. It depends on what you are doing, and there will definitely be a problem, because you are not able to predict where and when the function pointer works in your assembly.
The smarter you generate the obfuscation and manipulate the assembly in the preamble and postscript, the more difficult the fix and debug. So writing such a code is like balancing between “well, I will carefully insert one or two JMPs here” and “how the hell can I figure this out in a short time”? So you just have to insert the instructions and then several months to understand what you have done.
Hope you learned something useful today. In my opinion, I really got drunk and therefore I don’t really understand what happened now. The next slide shows my contacts on Twitter, my blog and website, so come visit or write.
That's all, thank you for coming!
Thank you for staying with us. Do you like our articles? Want to see more interesting materials? Support us by placing an order or recommending to friends, 30% discount for Habr's users on a unique analogue of the entry-level servers that we invented for you: The whole truth about VPS (KVM) E5-2650 v4 (6 Cores) 10GB DDR4 240GB SSD 1Gbps from $ 20 or how to share the server? (Options are available with RAID1 and RAID10, up to 24 cores and up to 40GB DDR4).
VPS (KVM) E5-2650 v4 (6 Cores) 10GB DDR4 240GB SSD 1Gbps until January for free if you pay for a period of six months, you can order here .
Dell R730xd 2 times cheaper? Only we have 2 x Intel Dodeca-Core Xeon E5-2650v4 128GB DDR4 6x480GB SSD 1Gbps 100 TV from $ 249in the Netherlands and the USA! Read about How to build an infrastructure building. class c using servers Dell R730xd E5-2650 v4 worth 9000 euros for a penny?