Incident management: “give away cannot be left” or the art of placing commas
Have you noticed how any niche market, becoming popular, attracts marketers from information security, trading fear? They convince you that if a cyber attack happens, the company will not be able to cope with any of the incident response tasks on its own. And then, of course, a good wizard appears - a service provider who, for a certain amount, is ready to save the customer from any troubles and the need to make any decisions. We explain why such an approach can be dangerous not only for the wallet, but also for the level of security of the company, what practical benefits the involvement of the service provider can bring and what solutions should always remain in the area of responsibility of the customer.

First of all, let's look at the terminology. When it comes to incident management, you often hear two abbreviations, SOC and CSIRT, the meaning of which is important to understand in order to avoid marketing manipulations.
Despite the fact that CSIRT is often guided in its activities by the NIST standard, which includes a full cycle of incident management, currently the emphasis in the marketing space is often placed on response activities, denying this SOC function and contrasting these two terms.
Is the SOC concept wider with respect to CSIRT? In my opinion, yes. SOC is not limited to incidents in its activities, it can rely on cyber intelligence data, forecasts and analysis of the level of security of the organization and include broader security tasks.
But back to the NIST standard, as one of the most popular approaches describing the procedure and phases of incident management. The general procedure of the NIST SP 800-61 standard is as follows:
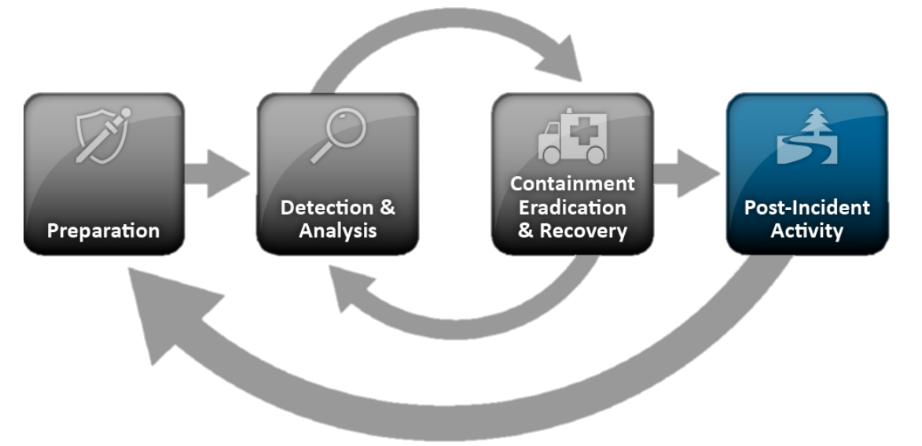
Despite the fact that the NIST standard is devoted to Incident Response, a significant part of the response is taken by the section “Detecting and analyzing incidents”, which actually describes the classic tasks of monitoring and handling incidents. Why are they given such attention? To answer the question, let's take a closer look at each of these blocks.
The task of identifying incidents begins with the creation and "landing" of a threat model and a model of an offender on the rules for identifying incidents. Incidents can be detected by analyzing information security events (logs) from various information protection tools, IT infrastructure components, application systems, elements of technological systems (ACS), and other information resources. Of course, you can do it manually, with scripts, reports, but for effective real-time detection of information security incidents, specialized solutions are still needed.
Here, SIEM systems come to the rescue, but their operation is no less a quest than the analysis of “raw” logs, and at every stage, starting with connecting sources and ending with the creation of incident rules. Difficulties are related to the fact that events coming from different sources should have a uniform appearance, and the key event parameters should be mapped to the same event fields in the SIEM, regardless of the class / manufacturer of the system or hardware.
The rules for detecting incidents, lists of compromise indicators, cyber threats trends form the so-called “content” SIEM. It should perform tasks to collect network and user activity profiles, accumulate statistics on various types of events, and identify typical information security incidents. The logic of triggering incident detection rules should take into account the particular infrastructure and business processes of a particular company. As there is no standard infrastructure of the company and business processes proceeding in it, there can be no unified content of the SIEM system.Therefore, all changes in the IT infrastructure of a company should be reflected in a timely manner both in the settings and tuning of protection tools, and in SIEM. If the system has been configured only once, at the start of the services, or updated once a year, it reduces the chances of detecting combat incidents and successful filtering of false alarms several times.
Thus, setting up security tools, connecting sources to a SIEM system, and adapting SIEM content are primary tasks in incident response, a base without which it is impossible to move on. After all, if the incident was not recorded in a timely manner and did not go through the phases of detection and analysis, there is no longer any reaction, we can only work with its consequences.
The monitoring service should deal with incidents in real-time mode around the clock and seven days a week. This rule, like the basics of safety, is written in blood: about half of critical cyber attacks begin at night, very often on Friday (this was the case, for example, with the WannaCry encryption virus). If you do not take protective measures within the first hour, then it may be too late. In this case, simply transfer all recorded incidents to the next step described in the NIST standard, i.e. at the localization stage is impractical, and here's why:
Usually, the first line of engineers who deal directly with the potential incidents recorded by the SIEM-system works 24/7 in the monitoring service. The number of such incidents can reach several thousand per day (again, further to the localization stage to transfer?), But, fortunately, most of them fit into the known patterns. Therefore, to increase the speed of their processing, you can use scripts and instructions that describe the necessary actions step by step.
This is a proven practice that reduces the burden on analysts 2 and 3 - they will be transferred only to those incidents that do not fit into any of the existing scripts. Otherwise, either the escalation of incidents to the second and third line of monitoring will reach 80%, or the first line will have to be planted by expensive specialists with high expertise and a long training period.
Thus, in addition to first-line employees, analysts and architects are needed who will create scripts and instructions, train first-line specialists, create content in the SIEM, connect sources, maintain performance and integrate SIEM with IRP, CMDB and other class systems.
An important task of monitoring is the search, processing and implementation of various reputation databases, APT reports, newsletters and subscriptions in the SIEM system, which ultimately turn into indicators of compromise (IoC). They allow you to identify hidden attacks of attackers on the infrastructure, malware, not detected by anti-virus vendors, and much more. However, just like connecting event sources to a SIEM system, adding all this information about threats first requires solving a number of tasks:
Above, I have touched upon only a part of the aspects of the process of monitoring and analyzing incidents that any company will have to face as it builds an incident response process. In my opinion, this is the most important task in the whole process, but let's move on and move on to the block of work with information security incidents already recorded and analyzed.
This unit, according to some information security experts, is decisive in distinguishing between the monitoring team and the incident response team. Let's take a closer look at what NIST puts into it.
According to NIST, the main task in the localization of an incident is the elaboration of a strategy, that is, the definition of measures to prevent the spread of the incident within the company's infrastructure. A set of these measures can include various actions - isolating the hosts involved in the incident at the network level, switching the operation of information protection tools, and even stopping the company's business processes to minimize damage from the incident. In fact, a strategy is a playbook, consisting of a matrix of actions depending on the type of incident.
The implementation of these actions may relate to the area of responsibility of the IT shift on-duty technical support, owners and administrators of systems (including business systems), a third-party contractor company, information security services. Actions can be performed manually, EDR components, and even self-written scripts used on command.
Since the decisions made at this stage can directly affect the company's business processes, deciding to apply a specific strategy in the absolute majority of cases remains the task of the internal information security manager (often with the involvement of business systems owners), and this task cannot be outsourced of the company. The role of the provider of information security services in the localization of the incident is reduced to the operational application of the strategy chosen by the customer.
After operational measures have been taken to localize the incident, a thorough investigation is needed, gathering all the information to assess the extent. This task is divided into two subtasks:
A person should also be appointed to coordinate the actions of all units in the investigation of the incident. This specialist must have the authority and contacts of all employees involved in the investigation. Can this role be performed by a contractor employee? More likely no than yes. It is more logical to entrust this role to the specialist or the head of the information security service of the customer.
After receiving a complete picture of the incident from various departments, the coordinator develops measures to eliminate the consequences of the incident. This procedure may include:
When developing measures, we recommend that the coordinator consult with the relevant departments responsible for specific systems, GIS administrators, forensics group and the information security monitoring service. But, again, the final decision on the use of certain measures is taken by the coordinator of the incident review team.
In this section, NIST actually talks about the tasks of the IT department and the business systems operation service. All work comes down to the restoration and verification of the performance of IT systems and business processes of the company. It makes no sense to dwell on this point, since most companies are faced with solving these problems, if not as a result of information security incidents, then, at least, after failures that occasionally occur even in the most stable and fault-tolerant systems installations.
The fourth section of the Incident Response methodology is devoted to the work on the bugs and the improvement of the company's security technologies.
For the preparation of a report on the incident, the filling of the knowledge base and TI, as a rule, the forensics group is responsible, together with the monitoring service. If the localization strategy was not developed in due time for this incident, its writing is included in this block.
Well, and obviously, a very important point in the work on the bugs is to develop a strategy to prevent similar incidents in the future:
Thus, the possible participation of the service provider in various stages of incident response can be presented in the form of a matrix:
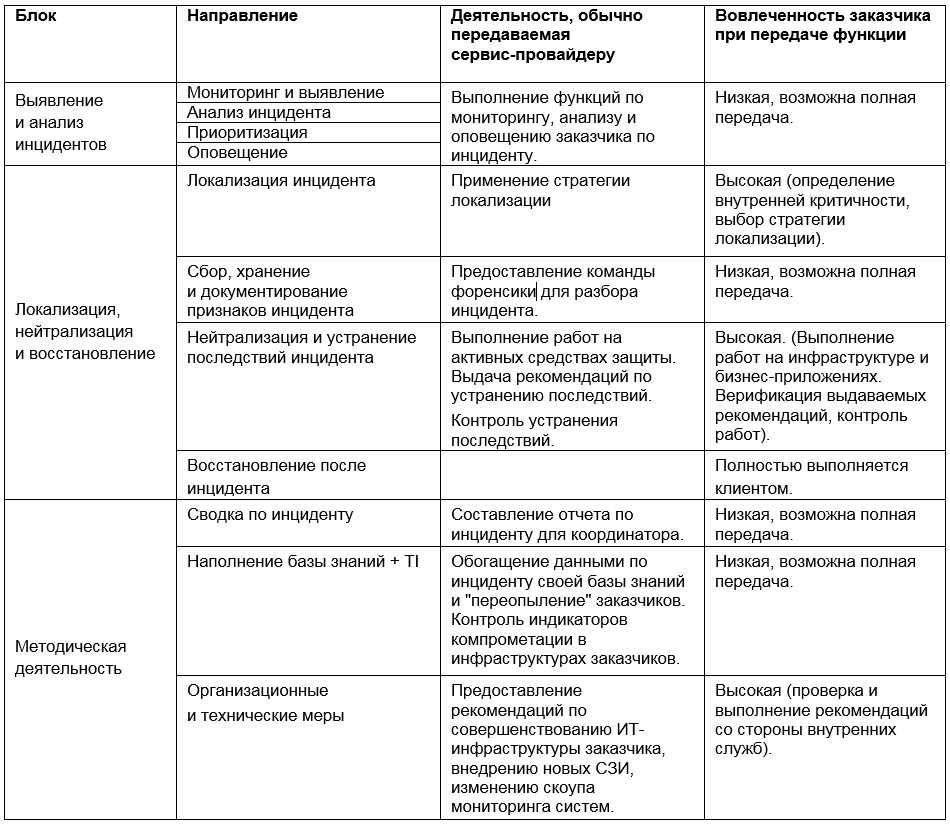
Choosing tools and approaches to incident management is one of the most difficult tasks of information security. The temptation to trust the promises of a service provider and give him all the functions may be great, but we advise you to sensibly assess the situation and keep a balance between the use of internal and external resources - in the interests of both economic and process efficiency.
First of all, let's look at the terminology. When it comes to incident management, you often hear two abbreviations, SOC and CSIRT, the meaning of which is important to understand in order to avoid marketing manipulations.
SOC (security operations center) is a division that deals with information security operational tasks. Most often, speaking of the functions of SOC, people mean monitoring and identifying incidents. However, SOC is usually responsible for any tasks related to information security processes, including response and response to incidents, methodological activities to improve the IT infrastructure and increase the level of security of the company. At the same time SOC is quite often an independent staff unit, including specialists of various profiles.
CSIRT (cybersecurity incident response team) - a group / temporarily formed team or unit responsible for responding to incidents. CSIRT usually has a permanent backbone consisting of information security specialists, GIS administrators and forensic groups. However, the final composition of the team in each case is determined by the threat vector and can be supplemented by IT services, owners of business systems and even company management with a PR service (to level the negative background in the media).
Despite the fact that CSIRT is often guided in its activities by the NIST standard, which includes a full cycle of incident management, currently the emphasis in the marketing space is often placed on response activities, denying this SOC function and contrasting these two terms.
Is the SOC concept wider with respect to CSIRT? In my opinion, yes. SOC is not limited to incidents in its activities, it can rely on cyber intelligence data, forecasts and analysis of the level of security of the organization and include broader security tasks.
But back to the NIST standard, as one of the most popular approaches describing the procedure and phases of incident management. The general procedure of the NIST SP 800-61 standard is as follows:
- Training:
- Creation of the technical infrastructure necessary for dealing with incidents
- Creating incident detection rules
- Detection and analysis of incidents:
- Monitoring and Detection
- Incident analysis
- Prioritization
- Alert
- Localization, neutralization and recovery:
- Localization of the incident
- Collecting, storing, and documenting incident signs
- Neutralization and elimination of the consequences of the incident
- Recovery after incident
- Methodical activity:
- Incident Summary
- Filling knowledge base + Threat Intelligence
- Organizational and technical measures
Despite the fact that the NIST standard is devoted to Incident Response, a significant part of the response is taken by the section “Detecting and analyzing incidents”, which actually describes the classic tasks of monitoring and handling incidents. Why are they given such attention? To answer the question, let's take a closer look at each of these blocks.
Training
The task of identifying incidents begins with the creation and "landing" of a threat model and a model of an offender on the rules for identifying incidents. Incidents can be detected by analyzing information security events (logs) from various information protection tools, IT infrastructure components, application systems, elements of technological systems (ACS), and other information resources. Of course, you can do it manually, with scripts, reports, but for effective real-time detection of information security incidents, specialized solutions are still needed.
Here, SIEM systems come to the rescue, but their operation is no less a quest than the analysis of “raw” logs, and at every stage, starting with connecting sources and ending with the creation of incident rules. Difficulties are related to the fact that events coming from different sources should have a uniform appearance, and the key event parameters should be mapped to the same event fields in the SIEM, regardless of the class / manufacturer of the system or hardware.
The rules for detecting incidents, lists of compromise indicators, cyber threats trends form the so-called “content” SIEM. It should perform tasks to collect network and user activity profiles, accumulate statistics on various types of events, and identify typical information security incidents. The logic of triggering incident detection rules should take into account the particular infrastructure and business processes of a particular company. As there is no standard infrastructure of the company and business processes proceeding in it, there can be no unified content of the SIEM system.Therefore, all changes in the IT infrastructure of a company should be reflected in a timely manner both in the settings and tuning of protection tools, and in SIEM. If the system has been configured only once, at the start of the services, or updated once a year, it reduces the chances of detecting combat incidents and successful filtering of false alarms several times.
Thus, setting up security tools, connecting sources to a SIEM system, and adapting SIEM content are primary tasks in incident response, a base without which it is impossible to move on. After all, if the incident was not recorded in a timely manner and did not go through the phases of detection and analysis, there is no longer any reaction, we can only work with its consequences.
Detection and analysis of incidents
The monitoring service should deal with incidents in real-time mode around the clock and seven days a week. This rule, like the basics of safety, is written in blood: about half of critical cyber attacks begin at night, very often on Friday (this was the case, for example, with the WannaCry encryption virus). If you do not take protective measures within the first hour, then it may be too late. In this case, simply transfer all recorded incidents to the next step described in the NIST standard, i.e. at the localization stage is impractical, and here's why:
- Get more information about what is happening or filter out false positives easier and more accurate at the stage of analysis, rather than the localization of the incident. This allows you to minimize the number of incidents transmitted to the next stages of the Incident Response process, where higher-level specialists such as incident management managers, response teams, IT system administrators and GIS should be involved in their consideration. It is more logical to build the process in such a way as not to escalate every trifle, including false positives, to the CISO level.
- An incident response and “repression” activity always carries with it business risks. Incident response may include work on blocking suspicious accesses, isolating the host, escalating to the management level. In the case of false positives, each of these steps will directly affect the availability of infrastructure elements and force the incident management team to “put out” its own escalation with multi-page reports and memos.
Usually, the first line of engineers who deal directly with the potential incidents recorded by the SIEM-system works 24/7 in the monitoring service. The number of such incidents can reach several thousand per day (again, further to the localization stage to transfer?), But, fortunately, most of them fit into the known patterns. Therefore, to increase the speed of their processing, you can use scripts and instructions that describe the necessary actions step by step.
This is a proven practice that reduces the burden on analysts 2 and 3 - they will be transferred only to those incidents that do not fit into any of the existing scripts. Otherwise, either the escalation of incidents to the second and third line of monitoring will reach 80%, or the first line will have to be planted by expensive specialists with high expertise and a long training period.
Thus, in addition to first-line employees, analysts and architects are needed who will create scripts and instructions, train first-line specialists, create content in the SIEM, connect sources, maintain performance and integrate SIEM with IRP, CMDB and other class systems.
An important task of monitoring is the search, processing and implementation of various reputation databases, APT reports, newsletters and subscriptions in the SIEM system, which ultimately turn into indicators of compromise (IoC). They allow you to identify hidden attacks of attackers on the infrastructure, malware, not detected by anti-virus vendors, and much more. However, just like connecting event sources to a SIEM system, adding all this information about threats first requires solving a number of tasks:
- Automation of adding indicators
- Assessment of their applicability and relevance
- Prioritization and accounting for obsolescence of information
- And the most important thing is an understanding of the means of protection with which information can be obtained to verify these indicators. If everything is quite simple with network ones - checking on firewalls and proxies, then it is more difficult with host-based ones - with what to compare hashes, how on all hosts to check launched processes, registry branches and files that are written to the hard disk?
Above, I have touched upon only a part of the aspects of the process of monitoring and analyzing incidents that any company will have to face as it builds an incident response process. In my opinion, this is the most important task in the whole process, but let's move on and move on to the block of work with information security incidents already recorded and analyzed.
Localization, neutralization and recovery
This unit, according to some information security experts, is decisive in distinguishing between the monitoring team and the incident response team. Let's take a closer look at what NIST puts into it.
Localization of the incident
According to NIST, the main task in the localization of an incident is the elaboration of a strategy, that is, the definition of measures to prevent the spread of the incident within the company's infrastructure. A set of these measures can include various actions - isolating the hosts involved in the incident at the network level, switching the operation of information protection tools, and even stopping the company's business processes to minimize damage from the incident. In fact, a strategy is a playbook, consisting of a matrix of actions depending on the type of incident.
The implementation of these actions may relate to the area of responsibility of the IT shift on-duty technical support, owners and administrators of systems (including business systems), a third-party contractor company, information security services. Actions can be performed manually, EDR components, and even self-written scripts used on command.
Since the decisions made at this stage can directly affect the company's business processes, deciding to apply a specific strategy in the absolute majority of cases remains the task of the internal information security manager (often with the involvement of business systems owners), and this task cannot be outsourced of the company. The role of the provider of information security services in the localization of the incident is reduced to the operational application of the strategy chosen by the customer.
Collecting, storing and documenting signs of an incident
After operational measures have been taken to localize the incident, a thorough investigation is needed, gathering all the information to assess the extent. This task is divided into two subtasks:
- Transfer of additional input to the monitoring team, connection of additional sources of information security events involved in the incident to the event collection and analysis system.
- Connecting the forensic team to analyze hard drive images, analyze memory dumps, malware samples and tools used by hackers in this incident.
A person should also be appointed to coordinate the actions of all units in the investigation of the incident. This specialist must have the authority and contacts of all employees involved in the investigation. Can this role be performed by a contractor employee? More likely no than yes. It is more logical to entrust this role to the specialist or the head of the information security service of the customer.
Neutralization and elimination of the consequences of the incident
After receiving a complete picture of the incident from various departments, the coordinator develops measures to eliminate the consequences of the incident. This procedure may include:
- Remove detected compromise indicators and traces of malware / intruders.
- "Reloading" of infected hosts and changing user passwords.
- Installing the latest updates and developing compensatory measures to eliminate the critical vulnerabilities used in the attack.
- Change protection profiles SZI.
- Control over the completeness of actions taken by the units involved and the lack of re-compromise of systems by hackers.
When developing measures, we recommend that the coordinator consult with the relevant departments responsible for specific systems, GIS administrators, forensics group and the information security monitoring service. But, again, the final decision on the use of certain measures is taken by the coordinator of the incident review team.
Recovery after incident
In this section, NIST actually talks about the tasks of the IT department and the business systems operation service. All work comes down to the restoration and verification of the performance of IT systems and business processes of the company. It makes no sense to dwell on this point, since most companies are faced with solving these problems, if not as a result of information security incidents, then, at least, after failures that occasionally occur even in the most stable and fault-tolerant systems installations.
Methodical activity
The fourth section of the Incident Response methodology is devoted to the work on the bugs and the improvement of the company's security technologies.
For the preparation of a report on the incident, the filling of the knowledge base and TI, as a rule, the forensics group is responsible, together with the monitoring service. If the localization strategy was not developed in due time for this incident, its writing is included in this block.
Well, and obviously, a very important point in the work on the bugs is to develop a strategy to prevent similar incidents in the future:
- Changing the architecture of IT infrastructure and existing IT systems.
- The introduction of new information security tools.
- Introduction of the process of patch management and monitoring of information security incidents (if absent).
- Adjustment of the company's business processes.
- Completing the staff of specialists in the department of information security.
- Changing the powers of information security officers.
Service Provider Role
Thus, the possible participation of the service provider in various stages of incident response can be presented in the form of a matrix:
Choosing tools and approaches to incident management is one of the most difficult tasks of information security. The temptation to trust the promises of a service provider and give him all the functions may be great, but we advise you to sensibly assess the situation and keep a balance between the use of internal and external resources - in the interests of both economic and process efficiency.