Monte Carlo tree search and tic-tac-toe
It turned out that to get a programming machine the poor first-timers were asked one interesting task: to write a program that searches the tree using the Monte Carlo method.
Of course, it all started with finding information on the Internet. In the great and powerful Russian language there were only a couple of articles from Habr, verbally explaining the essence of the algorithm, and an article from Wikipedia, redirecting to the problem of playing Go and the computer. For me, this is already a good start. I google in English for completeness and stumble upon an English Wikipedia article in which the algorithm is also verbally explained.
Bit of theory
The Monte Carlo method for searching the tree has long been used in games for artificial intelligence. The task of the algorithm is to choose the most winning scenario. A tree is a structure in which, in addition to the move and pointers, there are the number of games played and the number of games won. Based on these two parameters, the method selects the next step. The following image will demonstrate the operation of the algorithm:
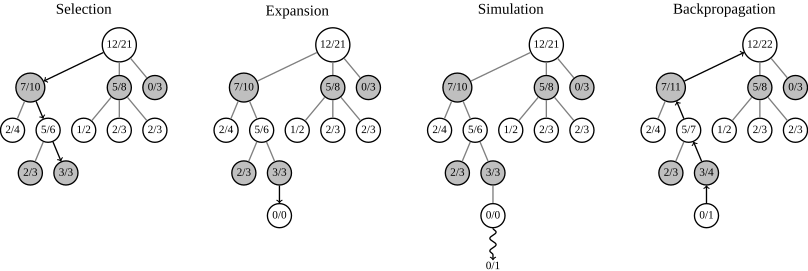
Step 1: Selection - Selection. At this step, the algorithm chooses the move of its opponent. If such a move exists, we will choose it; if not, add it.
Step 2: Expansion. To the selected node with the opponent’s move, we will add a node with its own move and with zero results.
Step 3: Simulation - Simulation. We will play the game from the current state of the playing field to someone else's victory. From here we take only the first move (i.e. our move) and the results.
Step 4: Backpropagation. We will distribute the results from the simulation from the current to the root. To all the parent nodes we will add one to the number of games played, and if we stumble upon the winner node, then we will add one to the number of games won in such a node.
As a result, a bot with such an algorithm will make winning moves for it.
Actually, the algorithm is not so complicated. Rather volumetric.
Implementation
I decided to implement the algorithm as a bot for the game Tic Tac Toe. The game is simple and perfect for example. But the devil is in the details ...
The problem is that we have to play the game in the simulation step without a real player. It was possible, of course, to force the algorithm to make random moves in such simulations, but I wanted some meaningful behavior.
Then a simple bot was written that knew only two things - to interfere with the player and make random moves. This was more than enough to simulate.
Like everyone else, the bot with the algorithm had information about the current state of the field, the state of the field from the last move, its own tree of moves and the current selected node in this tree. To begin with, I will find a new opponent move.
// 0. add node with new move.
bool exist = false;
int enemyx = -1, enemyy = -1;
this->FindNewStep ( __field, enemyx, enemyy );
for ( MCBTreeNode * node : this->mCurrent->Nodes )
{
if ( node->MoveX == enemyx && node->MoveY == enemyy )
{
exist = true;
this->mCurrent = node;
}
}
if ( !exist )
{
MCBTreeNode * enemymove = new MCBTreeNode;
enemymove->Parent = this->mCurrent;
enemymove->MoveX = enemyx;
enemymove->MoveY = enemyy;
enemymove->Player = (this->mFigure == TTT_CROSS) ? TTT_CIRCLE : TTT_CROSS;
this->mCurrent->Nodes.push_back ( enemymove );
this->mCurrent = enemymove;
}As you can see, if there is such an enemy move in the tree, then we will choose it. If not, add.
// 1. selection
// select node with more wins.
MCBTreeNode * bestnode = this->mCurrent;
for ( MCBTreeNode * node : this->mCurrent->Nodes )
{
if ( node->Wins > bestnode->Wins )
bestnode = node;
}Here we make a choice.
// 2. expanding
// create new node.
MCBTreeNode * newnode = new MCBTreeNode;
newnode->Parent = bestnode;
newnode->Player = this->mFigure;
this->mCurrent->Nodes.push_back ( newnode );Expand the tree.
// 3. simulation
// simulate game.
TTTGame::Field field;
for ( int y = 0; y < TTT_FIELDSIZE; y++ )
for ( int x = 0; x < TTT_FIELDSIZE; x++ )
field[y][x] = __field[y][x];
Player * bot1 = new Bot ();
bot1->SetFigure ( (this->mFigure == TTT_CROSS) ? TTT_CIRCLE : TTT_CROSS );
Player * bot2 = new Bot ();
bot2->SetFigure ( this->mFigure );
Player * current = bot2;
while ( TTTGame::IsPlayable ( field ) )
{
current->MakeMove ( field );
if ( newnode->MoveX == -1 && newnode->MoveY == -1 )
this->FindNewStep ( field, newnode->MoveX, newnode->MoveY );
if ( current == bot1 )
current = bot2;
else
current = bot1;
}Let's play the game between the bots. I think we need to explain a little here: the current state of the field is copied and the bots play out on this copy, the second bot goes first and we will remember its first move.
// 4. backpropagation.
int winner = TTTGame::CheckWin ( field );
MCBTreeNode * currentnode = newnode;
while ( currentnode != nullptr )
{
currentnode->Attempts++;
if ( currentnode->Player == winner )
currentnode->Wins++;
currentnode = currentnode->Parent;
}And the last: we get the result and spread it up the tree.
// make move...
this->mCurrent = newnode;
TTTGame::MakeMove ( __field, this->mFigure, mCurrent->MoveX, mCurrent->MoveY );And in the end, we just make a move and put our new node from the second step as the current node.
Conclusion
As you can see, the algorithm is not so scary and complicated. Of course, my implementation is far from ideal, but it shows the essence and some practical application.
Full code is available on my GitHub .
Good to all.