CRISP-DM: Proven Methodology for Data Scientists
Setting machine learning problems is mathematically very simple. Any classification, regression, or clustering task is essentially a normal optimization task with constraints. Despite this, the existing variety of algorithms and methods for solving them makes the profession of data analytics one of the most creative IT professions. So that the solution of the problem does not turn into an endless search for a “golden” solution, but is a predictable process, it is necessary to adhere to a fairly clear sequence of actions. This sequence of actions is described by methodologies such as CRISP-DM.
The CRISP-DM data analysis methodology is mentioned in many posts on Habré, but I could not find its detailed Russian-language descriptions and decided to fill this gap with my article. My material is based on the original description.and adapted description from IBM . An overview lecture on the benefits of using CRISP-DM can be seen, for example, here . * Crisp (English) - Crisp, chips I have been working at CleverDATA (part of the LANIT group) as a data scientist since 2015. We are engaged in projects in the field of big data and machine learning, mainly in the field of data-driven marketing (that is, marketing based on a “deep” analysis of customer data). Also developing data management platform 1DMP and Exchange 1DMC data . Our typical machine learning projects are the development and implementation of predictive (predictive) and prescriptive

(recommending the best action) models to optimize key customer business indicators. In a number of similar projects, we used the CRISP-DM methodology.
CRoss Industry Standard Process for Data Mining (CRISP-DM) is a standard that describes the general processes and approaches to data analytics used in industrial data-mining projects, regardless of the specific task and industry.
A well-known analytical portal kdnuggets.org periodically publishes a survey (for example, here ), according to which CRISP-DM regularly takes the first place among data analysis methodologies, then SEMMA goes by a wide margin, and the KDD Process is least often used.
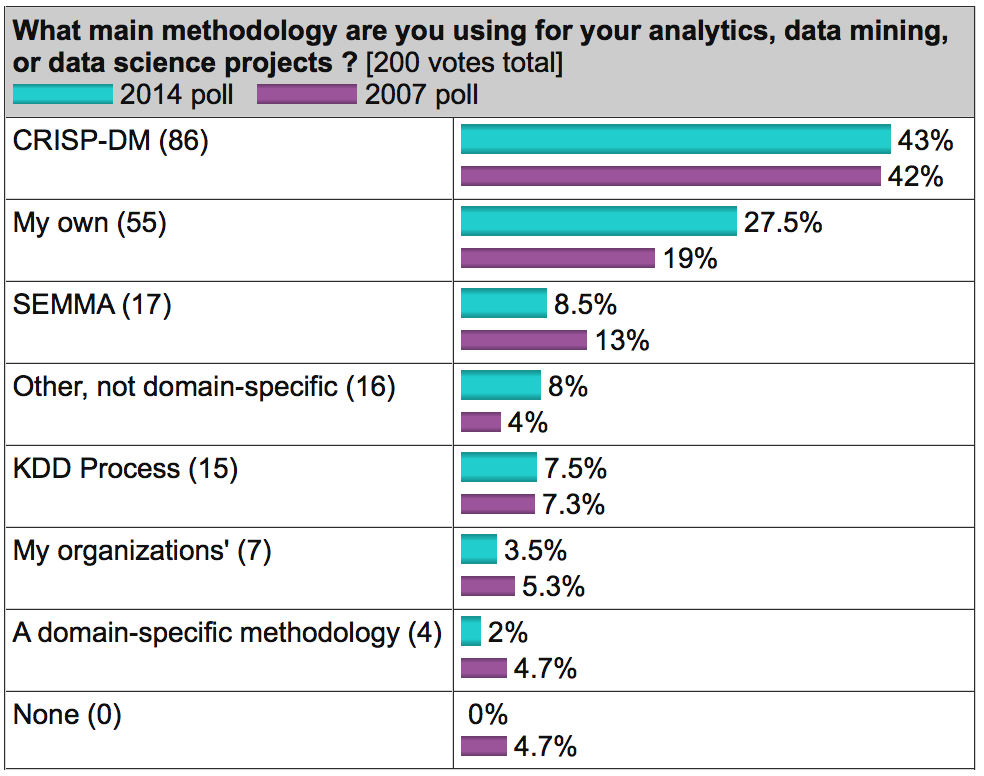 Source: kdnuggets.com
Source: kdnuggets.com
In general, these three methodologies are very similar to each other (it is difficult to come up with something fundamentally new here). However, CRISP-DM has earned its popularity as the most comprehensive and detailed. Compared to it, KDD is more general and theoretical, and SEMMA is just the organization of functions for the intended purpose in the SAS Enterprise Miner tool and affects exclusively the technical aspects of modeling, not touching on the business setting of the task.
The methodology was developed in 1996 on the initiative of three companies (the current DaimlerChrysler, SPSS and Teradata) and was further developed with the participation of 200 companies from various industries with experience in data-mining projects. All these companies used different analytical tools, but the process for everyone was built very similarly.
The methodology is actively promoted by IBM. For example, it is integrated with IBM SPSS Modeler (formerly SPSS Clementine).
An important property of the methodology is paying attention to the business goals of the company. This allows management to perceive data analysis projects not as a sandbox for experiments, but as a full-fledged element of the company's business processes.
The second feature is a fairly detailed documentation of each step. According to the authors, a well-documented process allows management to better understand the essence of the project, and analysts to more influence decision making.
According to CRISP-DM, an analytical project consists of six main steps that are carried out sequentially:
The methodology is not tough. It allows variation depending on the specific project - you can return to the previous steps, you can skip some steps if they are not important for the task being solved:
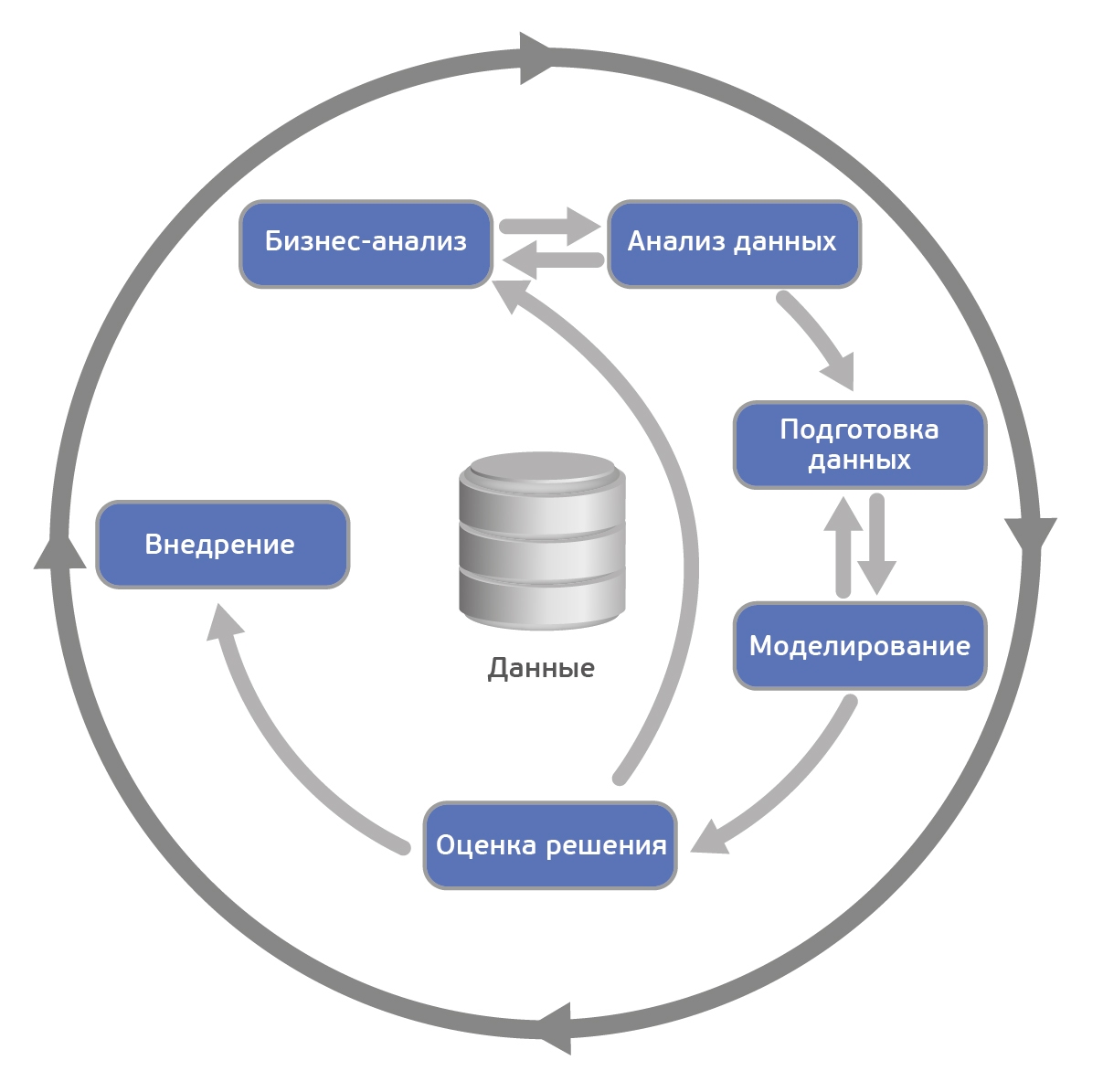 Wikipedia source
Wikipedia source
Each of these stages is in turn divided into tasks. At the output of each task, a certain result should be obtained. The tasks are as follows:
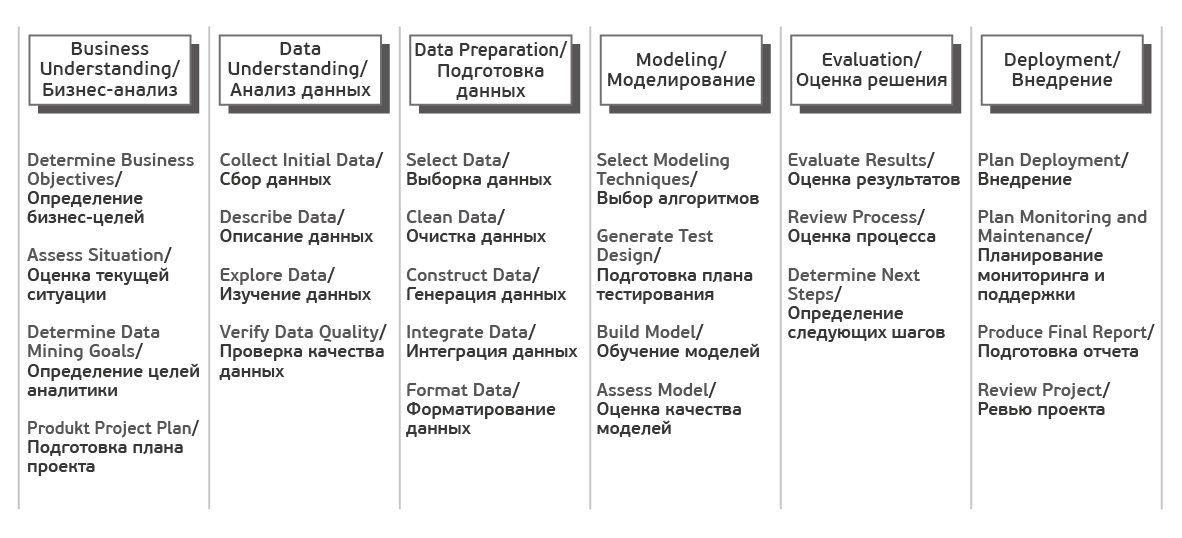
Source Crisp_DM Documentation
In the description of the steps, I will not deliberately go into mathematics and algorithms, since the focus of the article is on the process. I assume that the reader is familiar with the basics of machine learning, but just in case, the following paragraph describes the basic terms.
I also draw attention to the fact that the methodology is equally applicable both for internal projects and for situations when the project is done by consultants.
As a rule, the main result of an analytical project is a mathematical model. What is a model?
Let the business have a certain value of interest to it - y (for example, the likelihood of an outflow of the client). And also there is data - x (for example, customer support calls), on which y may depend . The business wants to understand exactly how y depends on x , so that in the future, through the setting of x, it can influence y . Thus, the task of the project is to find the function f that best models the studied dependence y = f ( x ).
Under the modelwe will understand the formula f (x) or a program that implements this formula. Any model is described, firstly, by its learning algorithm (it can be regression, decision tree, gradient boosting, etc.), and secondly, by a set of its parameters (which each algorithm has its own). Model training is the process of searching for parameters in which the model best approximates the observed data.
Training set - a table containing pairs x and y . Rows in this table are called cases , and columns are called attributes . Attributes with sufficient predictive ability will be called predictors.. In the case of “without a teacher” training (for example, in clustering problems), the training sample consists of only x . Scoring is the application of the found function f (x) to new data, for which y is still unknown. For example, in the task of credit scoring, the probability of late payment by a client is modeled first, and then the developed model is applied to new applicants to assess their creditworthiness.

A source
At the first step, we need to determine the goals and scope of the project.
First of all, we get acquainted with the customer and try to understand what he really wants (or tell him). The following questions would be good to get an answer.

Source
When together with the customer we figured out what we want, we need to evaluate what we can offer, taking into account current realities.
We evaluate whether there are enough resources for the project.
It is necessary to describe the likely risks of the project, as well as to determine an action plan to reduce them.
Typical risks are as follows.
It is important that the customer and the contractor speak the same language, so before starting a project it is better to compile a glossary and agree on the terminology used in the project. So, if we are making an outflow model for telecom, we must immediately agree on what exactly we will consider an outflow - for example, the absence of significant charges on the account for 4 consecutive weeks.
Next is (at least roughly) to evaluate the ROI. In machine-learning projects, a reasonable assessment of the payback can often be obtained only upon completion of the project (or pilot modeling), but understanding the potential benefits can be a good driver for everyone.
After the task is set in business terms, it is necessary to describe it in technical terms. In particular, we answer the following questions.
As soon as answers to all the basic questions are received and the purpose of the project is clear, it is time to draw up a project plan. The plan should include an assessment of all six phases of implementation.
We start the project and first look at the data. There is no simulation at this step, only descriptive analytics is used.
The goal of the step is to understand the strengths and weaknesses of the data provided, to determine their sufficiency, to offer ideas on how to use them, and to better understand the customer’s processes. To do this, we build graphs, make selections and calculate statistics.

Source
First you need to understand what data the customer has. The data may be:
It is necessary to analyze all sources accessed by the customer. If your own data is not enough, it may be worth buying third-party or organizing the collection of new data.
Next, we look at the data available to us.
Using graphs and tables, we examine the data to formulate hypotheses as to how these data will help solve the problem.
In the mini-report, we fix that interesting things were found in the data, as well as a list of attributes that are potentially useful.
It is important to evaluate the quality of the data even before the simulation, since any discrepancies can affect the progress of the project. What can be the difficulties with the data?

Source
Data preparation is traditionally the most time-consuming stage of the machine learning project (the description says about 50-70% of the project time, in our experience there may be even more). The purpose of the stage is to prepare a training set for use in modeling.
First you need to select the data that we will use to train the model.
Both attributes and cases are selected.
For example, if we make product recommendations to website visitors, we restrict ourselves to analyzing only registered users.
When choosing data, the analyst answers the following questions.
When potentially interesting data were selected, we check their quality.
The output is 3 attribute lists - quality attributes, corrected attributes, and rejected ones.
Often, feature engineering is the most important step in the preparation of data: a well-designed feature can significantly improve the quality of the model.
Data generation can include:
It’s good when data is taken from a corporate storage (QCD) or a pre-prepared storefront. Often, however, data must be downloaded from several sources, and integration of the training sample is required. Integration is understood as a “horizontal” connection (Merge), and a “vertical” connection (Append), as well as data aggregation. The output, as a rule, is a single analytical table suitable for delivery to analytical software as a training sample.
Finally, you need to bring the data to a format suitable for modeling (only for those algorithms that work with a specific data format). So, if we are talking about the analysis of the time series - for example, we predict the monthly sales of the distribution network - perhaps it needs to be sorted beforehand.
In the fourth step, the fun part finally begins - model training. As a rule, it is performed iteratively - we try different models, compare their quality, do exhaustive search of hyperparameters and choose the best combination. This is the most enjoyable phase of the project.
It is necessary to decide which models we will use (good, there are many of them). The choice of model depends on the problem being solved, the types of attributes and complexity requirements (for example, if the model is further implemented in Excel, then RandomForest and XGBoost will obviously not work). When choosing, you should pay attention to the following.
Next, we need to decide what we will train on, and on what to test our model.
The traditional approach is to divide the sample into 3 parts (training, validation and test) in an approximate proportion of 60/20/20. In this case, the training sample is used to fit the parameters of the model, and the validation and test to obtain an assessment of its quality cleared of the effect of retraining . More sophisticated strategies involve the use of different cross-validation options .
Here we also figure out how we will do optimization of model hyperparameters - how many iterations will be for each algorithm, whether we will do grid-search or random-search .
We start the training cycle and after each iteration we fix the result. At the output, we get several trained models.
In addition, for each trained model, we fix the following.

Source
After the pool of models has been formed, you need to analyze them again in detail and select the winning models. The output is nice to have a list of models sorted by objective and / or subjective criteria.
Step Objectives:
If the success criterion is not achieved, then you can either improve the current model, or try a new one.
Before proceeding with the implementation, you need to make sure that:

Source
The result of the previous step is the constructed mathematical model (model), as well as the found patterns (findings). In the fifth step, we evaluate the results of the project.
If at the previous stage we evaluated the simulation results from a technical point of view, then here we evaluate the results from the point of view of achieving business goals.
We address the following questions:
It is worth gatheringover a beer at the table, analyzing the course of the project and formulating its strengths and weaknesses. To do this, go through all the steps:
Next, you need to either introduce the model if it suits the customer, or if the potential for improvement is visible, try to improve it further.
If at this stage we have several satisfactory models, then we select those that we will continue to implement.

Source
Before starting a project with the customer, the delivery method of the model is always negotiated. In one case, it can be just an accelerated customer base, in another - an SQL formula, in the third - a fully developed analytical solution integrated into an information system.
At this step, the model is implemented (if the project involves the implementation stage). Moreover, the implementation can be understood as the physical addition of functionality, as well as the initiation of changes in the company's business processes.
Finally, we gathered together all the results obtained. Now what?
Very often, the project includes work to support the solution. This is what makes a reservation.
At the end of the project, as a rule, a report is written on the results of the simulation, in which the results for each step are added, starting from the initial data analysis and ending with the introduction of the model. Recommendations for further development of the model can also be included in this report.
The written report is presented to the customer and all interested parties. In the absence of TK, this report is the main document of the project. It is also important to talk with the staff involved in the project (both from the customer and the contractor) and collect their opinion on the project.
It is important to understand that methodology is not a universal recipe. This is simply an attempt to formally describe the sequence of actions that, to one degree or another, is performed by any analyst engaged in data analysis.
At CleverDATA, following the methodology on data mining projects is not a strict requirement, but, as a rule, when drawing up a project plan, our detail fits quite accurately into this sequence of steps.
The methodology is applicable to completely different tasks. We followed it in a number of marketing projects, including when we predicted the probability of a customer of a retail network responding to an advertising offer, made a model for assessing the creditworthiness of a borrower for a commercial bank, and developed a service for recommending products for an online store.

Source
As planned by the authors, a report should be written after each step. However, in practice this is not very realistic. Like everyone else, we have projects where the customer sets very tight deadlines and you need to quickly get the result. It is clear that in such conditions it makes no sense to waste time on the detailed documentation of each step. If necessary, we fix all the intermediate information in such cases with a pencil “on a napkin”. This allows you to quickly engage in the implementation of the model and meet deadlines.
In practice, many things are done far less formally than the methodology requires. For example, we usually do not waste time choosing and coordinating the models used, but we test immediately all available algorithms (of course, if resources allow). We do the same with attributes - we prepare several variants of each attribute at once, so that you can try out the maximum number of variants. With this approach, irrelevant attributes are eliminated automatically using feature selection algorithms - automatic determination of the predictive ability of attributes.
I believe that the formalism of the methodology is explained by the fact that it was written back in the 90s, when there was not so much computing power and it was important to correctly plan each action. Now the availability and low cost of hardware simplifies many things.
There is always the temptation to “run through” the first two stages and go straight to implementation. Practice shows that this is not always justified.
At the stage of setting business goals (business understanding), it is important to speak in detail with the customer the proposed solution and make sure that your expectations coincide with it. It happens that a business expects to receive as a result of a certain “magic” robot that will immediately solve all its problems and instantly double its revenue. Therefore, in order for no one to have disappointments as a result of the project, you should always clearly state exactly what result the customer will receive and what he will give the business.
In addition, the customer is not always able to give a correct assessment of the accuracy of the model. As an example: suppose we analyze the response to an online advertising campaign. We know that approximately 10% of customers follow the link. The model developed by us selects the 1000 most responsive customers, and we see that among them every fourth clicks on the link - we get accuracy of 25%. The model shows a good result (2.5 times better than the "random" model), but for the customer the accuracy of 25% is too low (he expects figures in the region of 80-90%). And vice versa, a completely meaningless model that classifies everyone in one class will show accuracy of 90% and will formally satisfy the stated success criterion. Those. It is important, together with the customer, to choose the right measure of model quality and interpret it correctly.
The stage of research (data understanding) is important in that it allows us and the customer to better understand his data. We had examples where, after the presentation of the results of the step, we agreed on the new ones along with the main project, since the customer saw the potential in the patterns found at this stage.
As another example, I’ll give one of our projects when we relied on a dialogue with the customer, limited ourselves to a superficial study of the data and at the modeling stage found that part of the data was not applicable due to numerous omissions. Therefore, it is always worthwhile to study in advance the data with which you have to work.
Finally, I want to note that, despite its completeness, the methodology is still quite general. It does not say anything about the choice of specific algorithms and does not provide ready-made solutions. Perhaps this is good, because there is always room for creative search, because, I repeat, today the data scientist profession is still one of the most creative in the IT field.
The CRISP-DM data analysis methodology is mentioned in many posts on Habré, but I could not find its detailed Russian-language descriptions and decided to fill this gap with my article. My material is based on the original description.and adapted description from IBM . An overview lecture on the benefits of using CRISP-DM can be seen, for example, here . * Crisp (English) - Crisp, chips I have been working at CleverDATA (part of the LANIT group) as a data scientist since 2015. We are engaged in projects in the field of big data and machine learning, mainly in the field of data-driven marketing (that is, marketing based on a “deep” analysis of customer data). Also developing data management platform 1DMP and Exchange 1DMC data . Our typical machine learning projects are the development and implementation of predictive (predictive) and prescriptive
(recommending the best action) models to optimize key customer business indicators. In a number of similar projects, we used the CRISP-DM methodology.
CRoss Industry Standard Process for Data Mining (CRISP-DM) is a standard that describes the general processes and approaches to data analytics used in industrial data-mining projects, regardless of the specific task and industry.
A well-known analytical portal kdnuggets.org periodically publishes a survey (for example, here ), according to which CRISP-DM regularly takes the first place among data analysis methodologies, then SEMMA goes by a wide margin, and the KDD Process is least often used.
In general, these three methodologies are very similar to each other (it is difficult to come up with something fundamentally new here). However, CRISP-DM has earned its popularity as the most comprehensive and detailed. Compared to it, KDD is more general and theoretical, and SEMMA is just the organization of functions for the intended purpose in the SAS Enterprise Miner tool and affects exclusively the technical aspects of modeling, not touching on the business setting of the task.
About methodology
The methodology was developed in 1996 on the initiative of three companies (the current DaimlerChrysler, SPSS and Teradata) and was further developed with the participation of 200 companies from various industries with experience in data-mining projects. All these companies used different analytical tools, but the process for everyone was built very similarly.
The methodology is actively promoted by IBM. For example, it is integrated with IBM SPSS Modeler (formerly SPSS Clementine).
An important property of the methodology is paying attention to the business goals of the company. This allows management to perceive data analysis projects not as a sandbox for experiments, but as a full-fledged element of the company's business processes.
The second feature is a fairly detailed documentation of each step. According to the authors, a well-documented process allows management to better understand the essence of the project, and analysts to more influence decision making.
According to CRISP-DM, an analytical project consists of six main steps that are carried out sequentially:
- Business Analysis
- Data Analysis
- Data preparation
- Modeling
- Evaluation
- Deployment
The methodology is not tough. It allows variation depending on the specific project - you can return to the previous steps, you can skip some steps if they are not important for the task being solved:
Each of these stages is in turn divided into tasks. At the output of each task, a certain result should be obtained. The tasks are as follows:
Source Crisp_DM Documentation
In the description of the steps, I will not deliberately go into mathematics and algorithms, since the focus of the article is on the process. I assume that the reader is familiar with the basics of machine learning, but just in case, the following paragraph describes the basic terms.
I also draw attention to the fact that the methodology is equally applicable both for internal projects and for situations when the project is done by consultants.
A few basic concepts of machine learning
As a rule, the main result of an analytical project is a mathematical model. What is a model?
Let the business have a certain value of interest to it - y (for example, the likelihood of an outflow of the client). And also there is data - x (for example, customer support calls), on which y may depend . The business wants to understand exactly how y depends on x , so that in the future, through the setting of x, it can influence y . Thus, the task of the project is to find the function f that best models the studied dependence y = f ( x ).
Under the modelwe will understand the formula f (x) or a program that implements this formula. Any model is described, firstly, by its learning algorithm (it can be regression, decision tree, gradient boosting, etc.), and secondly, by a set of its parameters (which each algorithm has its own). Model training is the process of searching for parameters in which the model best approximates the observed data.
Training set - a table containing pairs x and y . Rows in this table are called cases , and columns are called attributes . Attributes with sufficient predictive ability will be called predictors.. In the case of “without a teacher” training (for example, in clustering problems), the training sample consists of only x . Scoring is the application of the found function f (x) to new data, for which y is still unknown. For example, in the task of credit scoring, the probability of late payment by a client is modeled first, and then the developed model is applied to new applicants to assess their creditworthiness.
Step-by-step description of the methodology
A source
1. Business analysis (Business Understanding)
At the first step, we need to determine the goals and scope of the project.
The purpose of the project (Business objectives)
First of all, we get acquainted with the customer and try to understand what he really wants (or tell him). The following questions would be good to get an answer.
- Organizational structure: who participates in the project on the part of the customer, who allocates money for the project, who makes key decisions, who will be the main user? We collect contacts.
- What is the business goal of the project?
For example, reducing churn of customers. - Are there any solutions already developed? If they exist, then what and what exactly does the current solution not like?
1.2 Current situation (Assessing current solution)
Source
When together with the customer we figured out what we want, we need to evaluate what we can offer, taking into account current realities.
We evaluate whether there are enough resources for the project.
- Is there any iron available or need to be purchased?
- Where and how is data stored, will access to these systems be provided, do I need to additionally purchase / collect external data?
- Will the customer be able to select their experts for consultations on this project?
It is necessary to describe the likely risks of the project, as well as to determine an action plan to reduce them.
Typical risks are as follows.
- Do not meet deadlines.
- Financial risks (for example, if the sponsor loses interest in the project).
- A small amount or poor quality of data that will not allow to obtain an effective model.
- These data are qualitative, but the laws are in principle absent and, as a result, the results are not interesting to the customer.
It is important that the customer and the contractor speak the same language, so before starting a project it is better to compile a glossary and agree on the terminology used in the project. So, if we are making an outflow model for telecom, we must immediately agree on what exactly we will consider an outflow - for example, the absence of significant charges on the account for 4 consecutive weeks.
Next is (at least roughly) to evaluate the ROI. In machine-learning projects, a reasonable assessment of the payback can often be obtained only upon completion of the project (or pilot modeling), but understanding the potential benefits can be a good driver for everyone.
1.3 Solved problems from the point of view of analytics (Data Mining goals)
After the task is set in business terms, it is necessary to describe it in technical terms. In particular, we answer the following questions.
- What metric will we use to evaluate the simulation result (and there are a lot to choose from: Accuracy, RMSE, AUC, Precision, Recall, F-measure, R 2 , Lift, Logloss, etc.)?
- What is the success criterion for the model (for example, we consider AUC equal to 0.65 - the minimum threshold, 0.75 - optimal)?
- If we do not use the objective quality criterion, how will the results be evaluated?
1.4 Project Plan
As soon as answers to all the basic questions are received and the purpose of the project is clear, it is time to draw up a project plan. The plan should include an assessment of all six phases of implementation.
2. Data Understanding
We start the project and first look at the data. There is no simulation at this step, only descriptive analytics is used.
The goal of the step is to understand the strengths and weaknesses of the data provided, to determine their sufficiency, to offer ideas on how to use them, and to better understand the customer’s processes. To do this, we build graphs, make selections and calculate statistics.
2.1 Data collection
Source
First you need to understand what data the customer has. The data may be:
- own (1 st party data),
- third-party data (3 rd party),
- “Potential” data (for which collection must be organized).
It is necessary to analyze all sources accessed by the customer. If your own data is not enough, it may be worth buying third-party or organizing the collection of new data.
2.2 Data description
Next, we look at the data available to us.
- It is necessary to describe the data in all sources (table, key, number of rows, number of columns, disk space).
- If the volume is too large for the software used, create a data sample.
- We consider key statistics on attributes (minimum, maximum, spread, cardinality, etc.).
2.3 Data exploration
Using graphs and tables, we examine the data to formulate hypotheses as to how these data will help solve the problem.
In the mini-report, we fix that interesting things were found in the data, as well as a list of attributes that are potentially useful.
2.4 Data quality
It is important to evaluate the quality of the data even before the simulation, since any discrepancies can affect the progress of the project. What can be the difficulties with the data?
- Missing Values.
For example, we are making a model for classifying bank customers by their product preferences, but since only borrowing clients fill out questionnaires, the attribute “salary level” for depositing clients is not filled. - Data Errors (typos)
- Inconsistent value encoding (for example, "M" and "male" in different systems)
3. Data Preparation
Source
{kind=link}
Data preparation is traditionally the most time-consuming stage of the machine learning project (the description says about 50-70% of the project time, in our experience there may be even more). The purpose of the stage is to prepare a training set for use in modeling.
3.1 Data Selection
First you need to select the data that we will use to train the model.
Both attributes and cases are selected.
For example, if we make product recommendations to website visitors, we restrict ourselves to analyzing only registered users.
When choosing data, the analyst answers the following questions.
- What is the potential relevance of the attribute to the task at hand?
So, email or a customer’s phone number as predictors for forecasting is clearly useless. But the mail domain (mail.ru, gmail.com) or the operator code in theory may already have predictive ability. - Is a quality attribute sufficient for use in the model?
If we see that most of the attribute values are empty, then the attribute is most likely useless. - Should attributes be correlated with each other?
- Are there any restrictions on the use of attributes?
For example, company policies may prohibit the use of attributes with personal information as predictors .
3.2 Data Cleaning
When potentially interesting data were selected, we check their quality.
- Missing values => you need to either fill them out or remove from consideration
- Data errors => try to fix manually or remove from consideration
- Inappropriate encoding => result in unified encoding
The output is 3 attribute lists - quality attributes, corrected attributes, and rejected ones.
3.3 Constructing new data
Often, feature engineering is the most important step in the preparation of data: a well-designed feature can significantly improve the quality of the model.
Data generation can include:
- aggregation of attributes (calculation of sum, avg, min, max, var, etc.),
- case generation (e.g. oversampling or SMOTE algorithm ),
- конвертацию типов данных для использования в разных моделях (например, SVM традиционно работает с интервальными данными, а CHAID с номинальными),
- нормализацию атрибутов (feature scaling),
- заполнение пропущенных данных (missing data imputation).
3.4 Интеграция данных (Integrating data)
It’s good when data is taken from a corporate storage (QCD) or a pre-prepared storefront. Often, however, data must be downloaded from several sources, and integration of the training sample is required. Integration is understood as a “horizontal” connection (Merge), and a “vertical” connection (Append), as well as data aggregation. The output, as a rule, is a single analytical table suitable for delivery to analytical software as a training sample.
3.5 Formatting Data
Finally, you need to bring the data to a format suitable for modeling (only for those algorithms that work with a specific data format). So, if we are talking about the analysis of the time series - for example, we predict the monthly sales of the distribution network - perhaps it needs to be sorted beforehand.
4. Modeling
In the fourth step, the fun part finally begins - model training. As a rule, it is performed iteratively - we try different models, compare their quality, do exhaustive search of hyperparameters and choose the best combination. This is the most enjoyable phase of the project.
4.1 Selecting the modeling technique
It is necessary to decide which models we will use (good, there are many of them). The choice of model depends on the problem being solved, the types of attributes and complexity requirements (for example, if the model is further implemented in Excel, then RandomForest and XGBoost will obviously not work). When choosing, you should pay attention to the following.
- Is there enough data since complex models typically require a larger sample?
- Will the model be able to process data gaps (some implementations of the algorithms can work with gaps, some not)?
- Will the model be able to work with existing data types or is conversion necessary?
4.2 Testing planning (Generating a test design)
Next, we need to decide what we will train on, and on what to test our model.
The traditional approach is to divide the sample into 3 parts (training, validation and test) in an approximate proportion of 60/20/20. In this case, the training sample is used to fit the parameters of the model, and the validation and test to obtain an assessment of its quality cleared of the effect of retraining . More sophisticated strategies involve the use of different cross-validation options .
Here we also figure out how we will do optimization of model hyperparameters - how many iterations will be for each algorithm, whether we will do grid-search or random-search .
4.3 Building the models
We start the training cycle and after each iteration we fix the result. At the output, we get several trained models.
In addition, for each trained model, we fix the following.
- Does the model show any interesting patterns?
For example, that 99% prediction accuracy is due to just one attribute. - What is the speed of training / application of the model?
If the model takes 2 days to learn, it might be worth looking for a more efficient algorithm or reducing the training set. - Have there been problems with data quality?
For example, cases with missing values were included in the test sample, and because of this, not the entire sample got through.
4.4 Assessing the model
Source
After the pool of models has been formed, you need to analyze them again in detail and select the winning models. The output is nice to have a list of models sorted by objective and / or subjective criteria.
Step Objectives:
- conduct a technical analysis of the quality of the model (ROC, Gain, Lift, etc.),
- assess whether the model is ready for implementation in QCD (or where needed),
- Are the specified quality criteria achieved
- evaluate the results in terms of achieving business goals. This can be discussed with customer analysts.
If the success criterion is not achieved, then you can either improve the current model, or try a new one.
Before proceeding with the implementation, you need to make sure that:
- the simulation result is understandable (model, attributes, accuracy)
- the simulation result is logical.
For example, we predict the outflow of customers and received a ROC AUC of 95%. Too good a result is an occasion to check the model again. - we tried all available models
- the infrastructure is ready for the implementation of the model
Customer: “Let's implement! Only we have no place in the window ... ".
5. Evaluation of the result (Evaluation)
Source
The result of the previous step is the constructed mathematical model (model), as well as the found patterns (findings). In the fifth step, we evaluate the results of the project.
5.1 Evaluating the results
If at the previous stage we evaluated the simulation results from a technical point of view, then here we evaluate the results from the point of view of achieving business goals.
We address the following questions:
- Формулировка результата в бизнес-терминах. Бизнесу гораздо легче общаться в терминах $ и ROI, чем в абстрактных Lift или R2
Классический пример диалога
Аналитик: Наша модель показывает десятикратный lift!
Бизнес: Я не впечатлён…
Аналитик: Вы заработаете дополнительных 100K$ в год!
Бизнес: С этого надо было начинать! Поподробнее, пожалуйста... - В целом насколько хорошо полученные результаты решают бизнес-задачу?
- Найдена ли какая-то новая ценная информация, которую стоит выделить отдельно?
К примеру, компания-ритейлер фокусировала свои маркетинговые усилия на сегменте «активная молодежь», но, занявшись прогнозированием вероятности отклика, с удивлением обнаружила, что их целевой сегмент совсем другой – «обеспеченные дамы 40+».
5.2 Review the process
It is worth gathering
- Could any steps have been made more effective?
For example, due to the slowness of the IT department of the customer, it took a month to coordinate access. Not a buzz! - What mistakes were made and how to avoid them in the future?
At the planning stage, they underestimated the difficulty of downloading data from sources and as a result did not meet the deadlines. - Were the hypotheses not working? If so, is it worth repeating them?
Analyst: “And now let's try a convolutional neural network ... Everything is getting better with neural networks!” - Were there any surprises in the implementation of the steps? How to foresee them in the future?
Customer: “Ok. And we thought that the training set for model development is not needed ... "
5.3 Deciding the next steps
Next, you need to either introduce the model if it suits the customer, or if the potential for improvement is visible, try to improve it further.
If at this stage we have several satisfactory models, then we select those that we will continue to implement.
6. Deployment
Source
Before starting a project with the customer, the delivery method of the model is always negotiated. In one case, it can be just an accelerated customer base, in another - an SQL formula, in the third - a fully developed analytical solution integrated into an information system.
At this step, the model is implemented (if the project involves the implementation stage). Moreover, the implementation can be understood as the physical addition of functionality, as well as the initiation of changes in the company's business processes.
6.1 Planning Deployment
Finally, we gathered together all the results obtained. Now what?
- It is important to fix what exactly and in what form we will implement, as well as prepare a technical implementation plan (passwords, attendance, etc.)
- Consider how users will work with the implemented model.
For example, on the screen of a call center employee we show the client’s tendency to connect additional services. - Define the principle of monitoring the solution. If necessary, prepare for pilot operation.
For example, we agree on using the model for a year and tuning the model once every 3 months.
6.2 Planning Monitoring Configuration
Very often, the project includes work to support the solution. This is what makes a reservation.
- What model quality indicators will be monitored?
In our banking projects, we often use the popular stability index PSI in banks . - Как понимаем, что модель устарела?
Например, если PSI больше 0.15, либо просто договариваемся о регулярном пересчете раз в 3 месяца. - Если модель устарела, достаточно ли будет ее переобучить или нужно организовывать новый проект?
При существенных изменениях в бизнес-процессах тюнинга модели недостаточно, нужен полный цикл переобучения – с добавлением новых атрибутов, отбором предикторов и.т.д.
6.3 Отчет по результатам моделирования (Final Report)
At the end of the project, as a rule, a report is written on the results of the simulation, in which the results for each step are added, starting from the initial data analysis and ending with the introduction of the model. Recommendations for further development of the model can also be included in this report.
The written report is presented to the customer and all interested parties. In the absence of TK, this report is the main document of the project. It is also important to talk with the staff involved in the project (both from the customer and the contractor) and collect their opinion on the project.
How about practice?
It is important to understand that methodology is not a universal recipe. This is simply an attempt to formally describe the sequence of actions that, to one degree or another, is performed by any analyst engaged in data analysis.
At CleverDATA, following the methodology on data mining projects is not a strict requirement, but, as a rule, when drawing up a project plan, our detail fits quite accurately into this sequence of steps.
The methodology is applicable to completely different tasks. We followed it in a number of marketing projects, including when we predicted the probability of a customer of a retail network responding to an advertising offer, made a model for assessing the creditworthiness of a borrower for a commercial bank, and developed a service for recommending products for an online store.
One hundred and one report
Source
As planned by the authors, a report should be written after each step. However, in practice this is not very realistic. Like everyone else, we have projects where the customer sets very tight deadlines and you need to quickly get the result. It is clear that in such conditions it makes no sense to waste time on the detailed documentation of each step. If necessary, we fix all the intermediate information in such cases with a pencil “on a napkin”. This allows you to quickly engage in the implementation of the model and meet deadlines.
In practice, many things are done far less formally than the methodology requires. For example, we usually do not waste time choosing and coordinating the models used, but we test immediately all available algorithms (of course, if resources allow). We do the same with attributes - we prepare several variants of each attribute at once, so that you can try out the maximum number of variants. With this approach, irrelevant attributes are eliminated automatically using feature selection algorithms - automatic determination of the predictive ability of attributes.
I believe that the formalism of the methodology is explained by the fact that it was written back in the 90s, when there was not so much computing power and it was important to correctly plan each action. Now the availability and low cost of hardware simplifies many things.
The importance of planning
There is always the temptation to “run through” the first two stages and go straight to implementation. Practice shows that this is not always justified.
At the stage of setting business goals (business understanding), it is important to speak in detail with the customer the proposed solution and make sure that your expectations coincide with it. It happens that a business expects to receive as a result of a certain “magic” robot that will immediately solve all its problems and instantly double its revenue. Therefore, in order for no one to have disappointments as a result of the project, you should always clearly state exactly what result the customer will receive and what he will give the business.
In addition, the customer is not always able to give a correct assessment of the accuracy of the model. As an example: suppose we analyze the response to an online advertising campaign. We know that approximately 10% of customers follow the link. The model developed by us selects the 1000 most responsive customers, and we see that among them every fourth clicks on the link - we get accuracy of 25%. The model shows a good result (2.5 times better than the "random" model), but for the customer the accuracy of 25% is too low (he expects figures in the region of 80-90%). And vice versa, a completely meaningless model that classifies everyone in one class will show accuracy of 90% and will formally satisfy the stated success criterion. Those. It is important, together with the customer, to choose the right measure of model quality and interpret it correctly.
The stage of research (data understanding) is important in that it allows us and the customer to better understand his data. We had examples where, after the presentation of the results of the step, we agreed on the new ones along with the main project, since the customer saw the potential in the patterns found at this stage.
As another example, I’ll give one of our projects when we relied on a dialogue with the customer, limited ourselves to a superficial study of the data and at the modeling stage found that part of the data was not applicable due to numerous omissions. Therefore, it is always worthwhile to study in advance the data with which you have to work.
Finally, I want to note that, despite its completeness, the methodology is still quite general. It does not say anything about the choice of specific algorithms and does not provide ready-made solutions. Perhaps this is good, because there is always room for creative search, because, I repeat, today the data scientist profession is still one of the most creative in the IT field.