How to "glue" Intel-based server and overcome the scale-up ceiling in 8 processors
If you are engaged in growing large databases and suddenly run into the ceiling of performance - it's time to expand. It is clear with the scale-out extension: you add servers and do not know grief. Scale-up is not so fun. According to the standard glueless architecture, we take two processors, then add two more to them ... so we get to eight and that's it. More Intel has not provided, save up for a new server.

But there is an alternative - glued-architecture. In it, the dual processor computing units are interconnected through the node controllers. With their help, the upper threshold for one server rises to 16 or more processors. In this post we will talk in more detail about the glued-architecture in general and how it is implemented in our servers.
Before turning to glued-architecture, to be honest, let’s dwell on the pros and cons of glueless.
Solutions made according to the glueless architecture are typical. The processors communicate with each other without an additional device, and through a standard QPI bus \ UPI. The result is a bit cheaper than with glued. But after every eight processors have to spend a lot of money - to put a new server.

A typical glueless-architecture
A with a glued-architecture, as we have said, the ceiling increases to 16 or more processors per server.
The advantages of the Bull BCS2 architecture are provided by two components - node controllers (Resilient eXternal Node-Controller) and processor caching. Commands compatible with Intel Xeon E7-4800 / 8800 v4 series processors are supported.

Glued-architecture Bull BCS2. All connections in the server are visible here. Each BCS node has 7 XQPI links.
Due to caching, the amount of interaction between processors is reduced - the processors in each module have access to a common cache. This reduces the load on the RAM. The node, in turn, works as a traffic switch and solves the problem of “bottlenecks” - it redirects traffic along the least used path.
As a result, the Bull BCS2 architecture consumes only 5-10% of the bandwidth of the Intel QPI bus, the standard for the glueless architecture. As for local memory access delays, they are comparable to 4-socket glueless systems and 44% less than 8-socket glueless systems. According to the characteristics, the total data transfer rate of the BCS node is 230 GB / s - for each of the 7 ports, 25.6 GB / s is obtained. The maximum bandwidth is 300 GB / s.

In every Bullion S server on the motherboard there is such a switch. One XQPI link (16 sockets) for the speed provided is equivalent to ten to 10 GigE ports.

Bullion S lineup
In configurations on 4 and 8 processors, the difference between glued and glueless architecture is negligible. However, the situation changes when switching to 16 processors. We remember that in glueless you need two servers for this. And in the Bullion S server with the glued-architecture, everything fits like this: Dual-
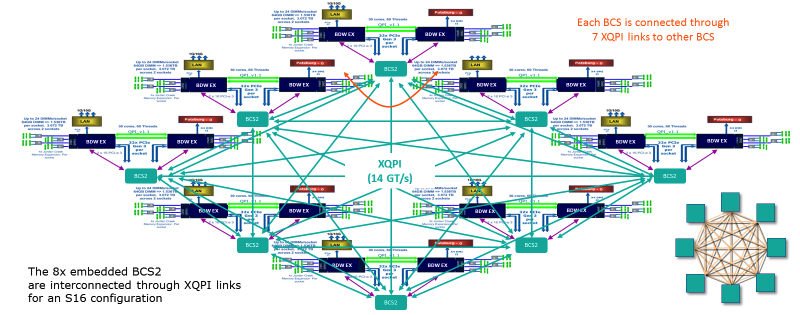
processor modules are interconnected via an XQPI network, whose throughput is 14 GT / s (billions of transactions per second)
The slots host any processor from the E7 family, with the exception of the E7-8893, which can only be used in dual-processor configurations. Compared to local memory access, the latency of the NUMA system reaches about x1.5 inside the module and about x4 between the modules. The node controller manages the hardware partitioning and allows you to create up to 8 separate partitions in the Bullion S servers operating in the operating system.
As a result, we are able to place up to 384 processor cores in one server. As for the RAM, the ceiling here is 384 DDR4 modules of 64 GB each. In total, we get 24 terabytes.
The described configuration is relevant for our workhorse - Bullion S servers. In addition to it, we have the BullSequana S line, which can include up to 32 physical processors based on the Intel Purley platform and Skylake and Cascadelake architectures (Q1 2019).
Bullion S is designed for resource-intensive tasks - SAP HANA, Oracle, MS SQL, Datalake (with Cloudera certification on BullSequana S), virtualization / VDI on VMware, and hyper-convergent solutions based on VMware vSAN. Partly on Bullion S servers, Siemens has created the largest SAP HANA platform in the world. Also based on Bullion S, PWC has built a huge solution for Hadoop and analytics. Total Bull solutions are used by about 300 companies in the world.
In order for you to estimate the capabilities of our servers, we’ll give you a plan for migrating an Oracle database from Power to x86 at branches of a Russian telecom operator:

Thanks to processor caching, the glued-architecture allows processors to communicate directly with other processors in a node. And fast links - do not slow down when interacting with other clusters. To date, up to 16 processors (384 cores) and up to 24 TB of RAM fit into one Bullion S server. The scaling step is two processors - this facilitates the distribution of the financial burden in creating the IT infrastructure.
In future materials, we plan to disassemble our servers in more detail. We will be happy to answer your questions in the comments.
But there is an alternative - glued-architecture. In it, the dual processor computing units are interconnected through the node controllers. With their help, the upper threshold for one server rises to 16 or more processors. In this post we will talk in more detail about the glued-architecture in general and how it is implemented in our servers.
Before turning to glued-architecture, to be honest, let’s dwell on the pros and cons of glueless.
Solutions made according to the glueless architecture are typical. The processors communicate with each other without an additional device, and through a standard QPI bus \ UPI. The result is a bit cheaper than with glued. But after every eight processors have to spend a lot of money - to put a new server.
A typical glueless-architecture
A with a glued-architecture, as we have said, the ceiling increases to 16 or more processors per server.
How does the Bull BCS2 glued architecture work?
The advantages of the Bull BCS2 architecture are provided by two components - node controllers (Resilient eXternal Node-Controller) and processor caching. Commands compatible with Intel Xeon E7-4800 / 8800 v4 series processors are supported.
Glued-architecture Bull BCS2. All connections in the server are visible here. Each BCS node has 7 XQPI links.
Due to caching, the amount of interaction between processors is reduced - the processors in each module have access to a common cache. This reduces the load on the RAM. The node, in turn, works as a traffic switch and solves the problem of “bottlenecks” - it redirects traffic along the least used path.
As a result, the Bull BCS2 architecture consumes only 5-10% of the bandwidth of the Intel QPI bus, the standard for the glueless architecture. As for local memory access delays, they are comparable to 4-socket glueless systems and 44% less than 8-socket glueless systems. According to the characteristics, the total data transfer rate of the BCS node is 230 GB / s - for each of the 7 ports, 25.6 GB / s is obtained. The maximum bandwidth is 300 GB / s.
In every Bullion S server on the motherboard there is such a switch. One XQPI link (16 sockets) for the speed provided is equivalent to ten to 10 GigE ports.
Bullion S lineup
In configurations on 4 and 8 processors, the difference between glued and glueless architecture is negligible. However, the situation changes when switching to 16 processors. We remember that in glueless you need two servers for this. And in the Bullion S server with the glued-architecture, everything fits like this: Dual-
processor modules are interconnected via an XQPI network, whose throughput is 14 GT / s (billions of transactions per second)
The slots host any processor from the E7 family, with the exception of the E7-8893, which can only be used in dual-processor configurations. Compared to local memory access, the latency of the NUMA system reaches about x1.5 inside the module and about x4 between the modules. The node controller manages the hardware partitioning and allows you to create up to 8 separate partitions in the Bullion S servers operating in the operating system.
As a result, we are able to place up to 384 processor cores in one server. As for the RAM, the ceiling here is 384 DDR4 modules of 64 GB each. In total, we get 24 terabytes.
The described configuration is relevant for our workhorse - Bullion S servers. In addition to it, we have the BullSequana S line, which can include up to 32 physical processors based on the Intel Purley platform and Skylake and Cascadelake architectures (Q1 2019).
Integration Examples
Bullion S is designed for resource-intensive tasks - SAP HANA, Oracle, MS SQL, Datalake (with Cloudera certification on BullSequana S), virtualization / VDI on VMware, and hyper-convergent solutions based on VMware vSAN. Partly on Bullion S servers, Siemens has created the largest SAP HANA platform in the world. Also based on Bullion S, PWC has built a huge solution for Hadoop and analytics. Total Bull solutions are used by about 300 companies in the world.
In order for you to estimate the capabilities of our servers, we’ll give you a plan for migrating an Oracle database from Power to x86 at branches of a Russian telecom operator:
Conclusion
Thanks to processor caching, the glued-architecture allows processors to communicate directly with other processors in a node. And fast links - do not slow down when interacting with other clusters. To date, up to 16 processors (384 cores) and up to 24 TB of RAM fit into one Bullion S server. The scaling step is two processors - this facilitates the distribution of the financial burden in creating the IT infrastructure.
In future materials, we plan to disassemble our servers in more detail. We will be happy to answer your questions in the comments.