Testing and debugging MapReduce
At Rostelecom, we use Hadoop to store and process data downloaded from multiple sources using java applications. Now we have moved to the new version of hadoop with Kerberos Authentication. When moving, we encountered a number of problems, including the use of the YARN API. Using Hadoop with Kerberos Authentication deserves a separate article, and in this one we’ll talk about debugging Hadoop MapReduce.

When performing tasks in a cluster, starting the debugger is complicated by the fact that we do not know which node will process one or another part of the input data, and we cannot configure our own debugger in advance.
You can use time-tested
We can output messages to standard error. Everything that is written to stdout or stderr is
sent to the appropriate log file, which can be found on the web page of the extended information about the task or in the log files.
We can also include debugging tools in the code, update task status messages, and use custom counters to help us understand the scale of the disaster.
The Hadoop MapReduce application can be debugged in all three modes in which Hadoop can work:
In more detail we will focus on the first two.
Pseudo-distributed mode is used to simulate a real cluster. And it can be used for testing in an environment as close to productive as possible. In this mode, all Hadoop daemons will run on the same node!
If you have a dev server or another sandbox (for example, a Virtual Machine with a customized development environment, such as Hortonworks Sanbox with HDP), then you can debug a control program using remote debugging tools.
To start debugging need to set the environment variable:
Now, running the script
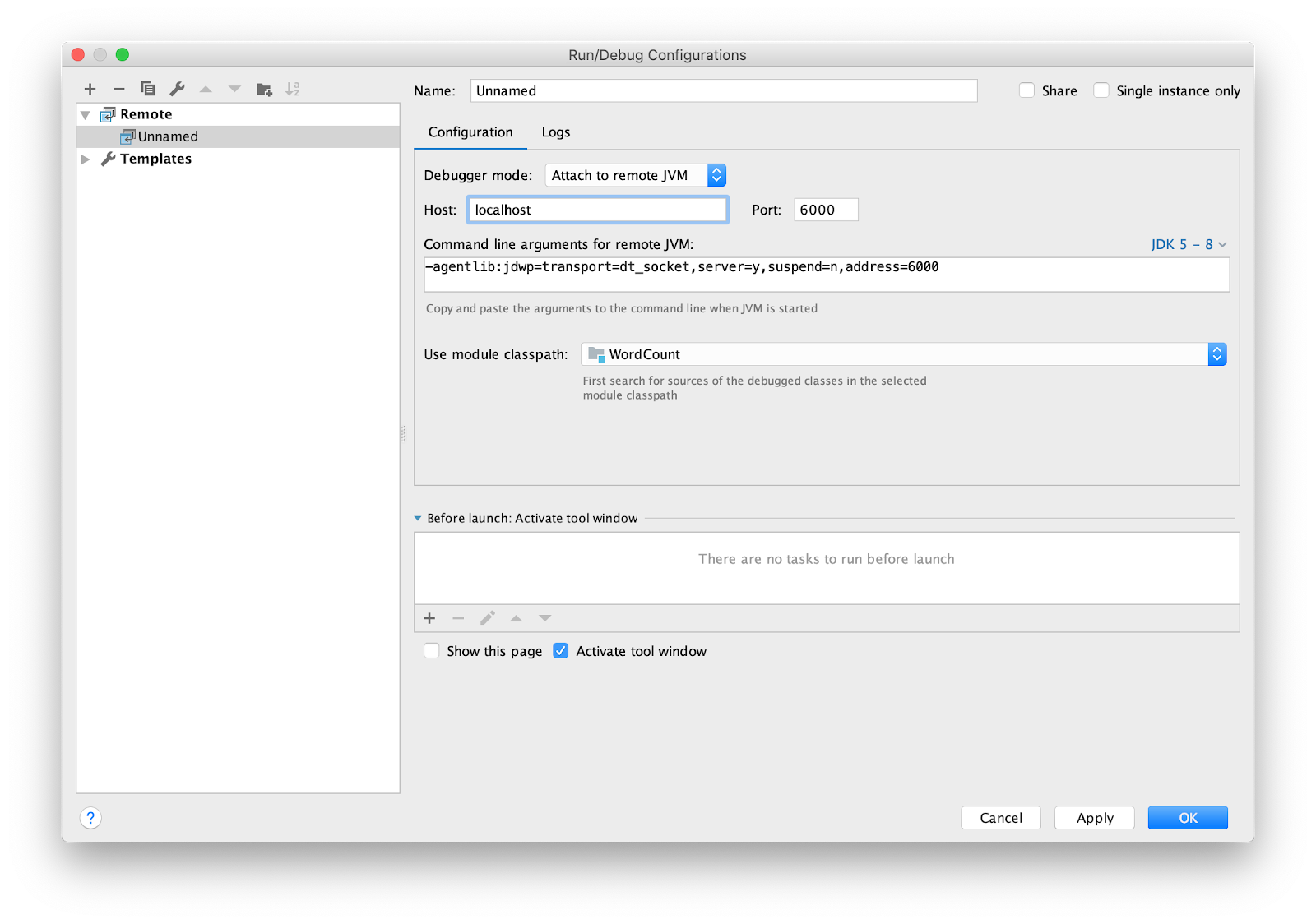
It remains to configure the IDE for remote debugging (remote debugging). I am using intellij IDEA. Go to the menu Run -> Edit Configurations ... Add a new configuration
Put a breakpoint in main and run.
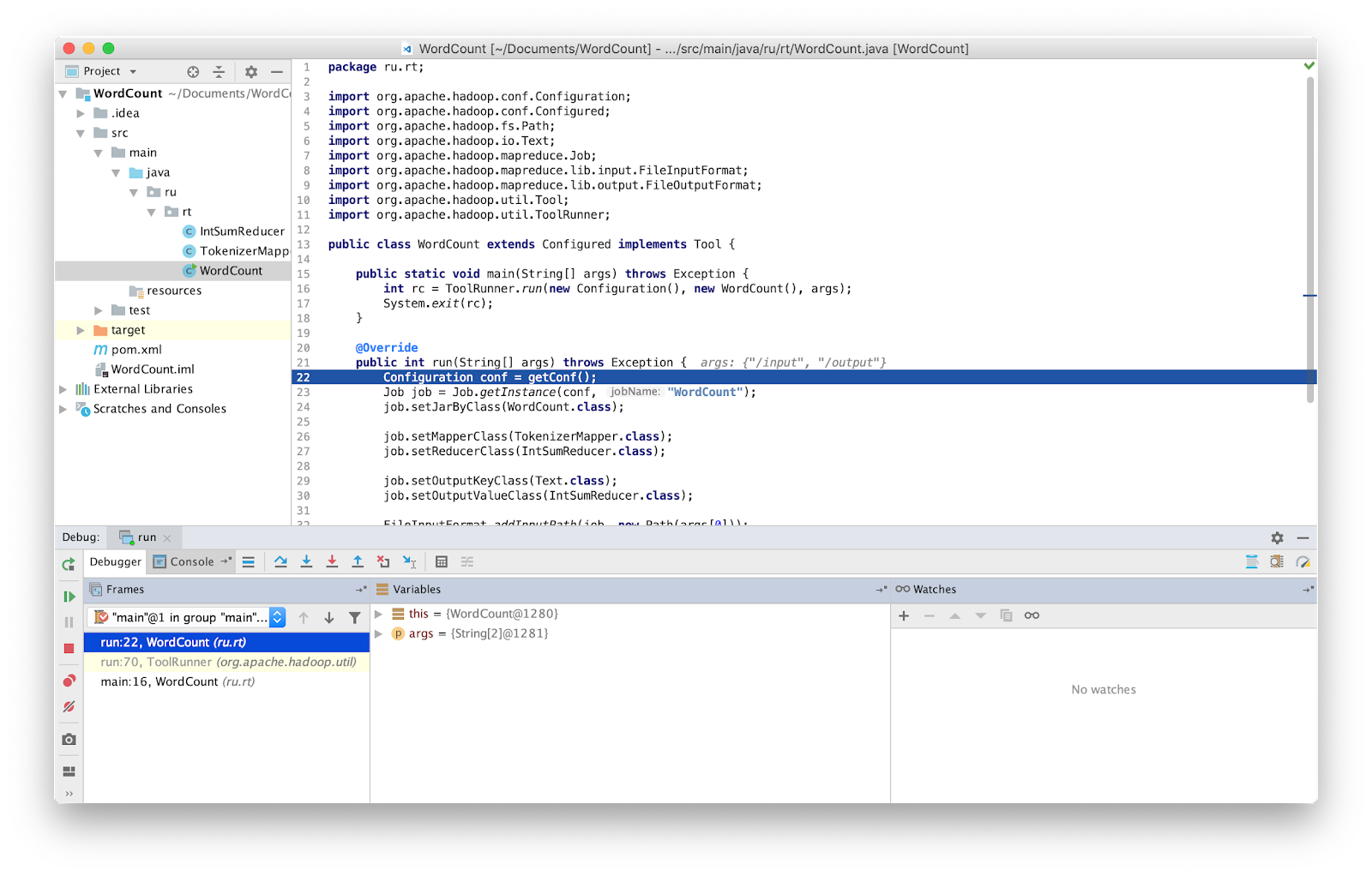
That's it, now we can debug the program as usual.
In earlier versions of Hadoop, a special class was delivered that allowed you to rerun the failed task - isolationRunner. The data that caused the failure was saved to disk at the address specified in the Hadoop environment variable mapred.local.dir. Unfortunately, in the latest versions of Hadoop, this class is no longer available.
Standalone is the standard mode in which Hadoop operates. It is suitable for debugging where HDFS is not used. With this debugging, you can use input and output through the local file system. Standalone mode is usually the fastest Hadoop mode, as it uses the local file system for all input and output data.
As mentioned earlier, you can embed debugging tools in your code, such as counters. Counters are defined by enum Java. The enumeration name defines the name of the group, and the enumeration fields define the names of the counters. The counter can be useful for assessing the problem,
and can be used as an addition to debugging output.
Ad and use counter:
For increment counter you need to use the method
After successful completion of the MapReduce task at the end displays the values of the counters.
Erroneous data can be output to stderr or to stdout, or to write output data in hdfs, using the class
Hadoop has the MRUnit library, which is used in conjunction with testing frameworks (for example, JUnit). When writing unit tests, we check that the output function produces the expected result. We use the MapDriver class from the MRUnit package, in whose properties we install the class under test. To do this, use the method
Here is our test.
As the name suggests, this is a mode in which all the power of Hadoop is used. The launched program MapReduce can run on 1000 servers. It is always difficult to debug MapReduce, since you have Mappers running on different machines with different inputs.
As it turned out, testing MapReduce is not as simple as it seems at first glance.
To save time searching for errors in MapReduce, I used all of these methods and advise everyone to use them too. This is especially useful in the case of large installations, such as those that work at Rostelecom.
When performing tasks in a cluster, starting the debugger is complicated by the fact that we do not know which node will process one or another part of the input data, and we cannot configure our own debugger in advance.
You can use time-tested
System.out.println("message"). But how to analyze the output System.out.println("message")scattered around these nodes? We can output messages to standard error. Everything that is written to stdout or stderr is
sent to the appropriate log file, which can be found on the web page of the extended information about the task or in the log files.
We can also include debugging tools in the code, update task status messages, and use custom counters to help us understand the scale of the disaster.
The Hadoop MapReduce application can be debugged in all three modes in which Hadoop can work:
- standalone
- pseudo-distributed mode
- fully distributed
In more detail we will focus on the first two.
Pseudo-distributed mode (pseudo-distributed mode)
Pseudo-distributed mode is used to simulate a real cluster. And it can be used for testing in an environment as close to productive as possible. In this mode, all Hadoop daemons will run on the same node!
If you have a dev server or another sandbox (for example, a Virtual Machine with a customized development environment, such as Hortonworks Sanbox with HDP), then you can debug a control program using remote debugging tools.
To start debugging need to set the environment variable:
YARN_OPTS. Below is an example. For convenience, you can create a startWordCount.sh file and add the necessary parameters to it to start the application.#!/bin/bash
source /etc/hadoop/conf/yarn-env.sh
export YARN_OPTS='-agentlib:jdwp=transport=dt_socket,server=y,suspend=y,address=6000 ${YARN_OPTS}'
yarn jar wordcount-0.0.1.jar ru.rtc.example.WordCount /input /output
Now, running the script
`./startWordCount.sh`, we will see the messageListening for transport dt_socket at address: 6000
It remains to configure the IDE for remote debugging (remote debugging). I am using intellij IDEA. Go to the menu Run -> Edit Configurations ... Add a new configuration
Remote. Put a breakpoint in main and run.
That's it, now we can debug the program as usual.
ATTENTION. You need to make sure that you are working with the latest version of the source code. If not, you may have differences in the lines in which the debugger stops.
In earlier versions of Hadoop, a special class was delivered that allowed you to rerun the failed task - isolationRunner. The data that caused the failure was saved to disk at the address specified in the Hadoop environment variable mapred.local.dir. Unfortunately, in the latest versions of Hadoop, this class is no longer available.
Standalone (local launch)
Standalone is the standard mode in which Hadoop operates. It is suitable for debugging where HDFS is not used. With this debugging, you can use input and output through the local file system. Standalone mode is usually the fastest Hadoop mode, as it uses the local file system for all input and output data.
As mentioned earlier, you can embed debugging tools in your code, such as counters. Counters are defined by enum Java. The enumeration name defines the name of the group, and the enumeration fields define the names of the counters. The counter can be useful for assessing the problem,
and can be used as an addition to debugging output.
Ad and use counter:
package ru.rt.example;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
publicclassMapextendsMapper<LongWritable, Text, Text, IntWritable> {
private Text word = new Text();
enum Word {
TOTAL_WORD_COUNT,
}
@Override
publicvoidmap(LongWritable key, Text value, Context context){
String[] stringArr = value.toString().split("\\s+");
for (String str : stringArr) {
word.set(str);
context.getCounter(Word.TOTAL_WORD_COUNT).increment(1);
}
}
}
}
For increment counter you need to use the method
increment(1)....
context.getCounter(Word.TOTAL_WORD_COUNT).increment(1);
...
After successful completion of the MapReduce task at the end displays the values of the counters.
Shuffle Errors
BAD_ID=0
CONNECTION=0
IO_ERROR=0
WRONG_LENGTH=0
WRONG_MAP=0
WRONG_REDUCE=0
ru.rt.example.Map$Word
TOTAL_WORD_COUNT=655
Erroneous data can be output to stderr or to stdout, or to write output data in hdfs, using the class
MultipleOutputsfor further analysis. The obtained data can be transmitted to the application in standalone mode or when writing unit tests. Hadoop has the MRUnit library, which is used in conjunction with testing frameworks (for example, JUnit). When writing unit tests, we check that the output function produces the expected result. We use the MapDriver class from the MRUnit package, in whose properties we install the class under test. To do this, use the method
withMapper(), the input values withInputValue()and the expected result, withOutput()or withMultiOutput()if multiple output is used. Here is our test.
package ru.rt.example;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mrunit.mapreduce.MapDriver;
import org.apache.hadoop.mrunit.types.Pair;
import org.junit.Before;
import org.junit.Test;
import java.io.IOException;
publicclassTestWordCount{
private MapDriver<Object, Text, Text, IntWritable> mapDriver;
@Before
publicvoidsetUp(){
Map mapper = new Map();
mapDriver.setMapper(mapper)
}
@Test
publicvoidmapperTest()throws IOException {
mapDriver.withInput(new LongWritable(0), new Text("msg1"));
mapDriver.withOutput(new Pair<Text, IntWritable>(new Text("msg1"), new IntWritable(1)));
mapDriver.runTest();
}
}
Fully distributed mode (fully distributed mode)
As the name suggests, this is a mode in which all the power of Hadoop is used. The launched program MapReduce can run on 1000 servers. It is always difficult to debug MapReduce, since you have Mappers running on different machines with different inputs.
Conclusion
As it turned out, testing MapReduce is not as simple as it seems at first glance.
To save time searching for errors in MapReduce, I used all of these methods and advise everyone to use them too. This is especially useful in the case of large installations, such as those that work at Rostelecom.