MIT course "Computer Systems Security". Lecture 20: "Security of mobile phones", part 1
- Transfer
- Tutorial
Massachusetts Institute of Technology. Lecture course # 6.858. "Security of computer systems". Nikolai Zeldovich, James Mykens. year 2014
Computer Systems Security is a course on the development and implementation of secure computer systems. Lectures cover threat models, attacks that compromise security, and security methods based on the latest scientific work. Topics include operating system (OS) security, capabilities, information flow control, language security, network protocols, hardware protection and security in web applications.
Lecture 1: “Introduction: threat models” Part 1 / Part 2 / Part 3
Lecture 2: “Controlling hacker attacks” Part 1 / Part 2 / Part 3
Lecture 3: “Buffer overflow: exploits and protection” Part 1 /Part 2 / Part 3
Lecture 4: “Privilege Separation” Part 1 / Part 2 / Part 3
Lecture 5: “Where Security System Errors Come From” Part 1 / Part 2
Lecture 6: “Capabilities” Part 1 / Part 2 / Part 3
Lecture 7: “Native Client Sandbox” Part 1 / Part 2 / Part 3
Lecture 8: “Network Security Model” Part 1 / Part 2 / Part 3
Lecture 9: “Web Application Security” Part 1 / Part 2/ Part 3 Part 2
Lecture 10: “Symbolic execution” Part 1 / Part 2 / Part 3
Lecture 11: “Ur / Web programming language” Part 1 / Part 2 / Part 3
Lecture 12: “Network security” Part 1 / Part 2 / Part 3
Lecture 13 : “Network Protocols” Part 1 / Part 2 / Part 3
Lecture 14: “SSL and HTTPS” Part 1 / Part 2 / Part 3
Lecture 15: “Medical Software” Part 1 / / Part 3
Lecture 16: “Attacks through the side channel” Part 1 / Part 2 / Part 3
Lecture 17: “User authentication” Part 1 / Part 2 / Part 3
Lecture 18: “Private Internet viewing” Part 1 / Part 2 / Part 3
Lecture 19 : “Anonymous Networks” Part 1 / Part 2 / Part 3
Lecture 20: “Mobile Phone Security” Part 1 / Part 2 / Part 3
Today we will talk about the security of Android. You can think of this as an interesting example of a system that was primarily designed with security in mind. It is possible that, unlike many systems that we have considered so far, such as Unix or web browsers, where security was mostly “screwed” after creating the system and its design did not focus on these issues, Android developers were initially very worried about specific classes of attacks and constructive mechanisms of applications.

They came up with the best way to structure Android apps that will allow us to better enforce security policies. The great thing is that this is a fairly widely used system, unlike some research work that can only offer a new architecture, this system is actually used in practice, and devices using the Android OS are becoming more and more.
Today we will talk about how well some developers have succeeded or failed. We consider what parts of the design they considered important and what they missed, and what the result is in practice. This is quite interesting. In a sense, the developers used the existing systems that we talked about, so the “Android” is based on UNIX, in fact, it’s just the Linux kernel that runs on the whole phone.
So in many ways they use some of the familiar mechanisms that you remember from lab # 2, where you used user IDs and Unix groups and other things to separate applications from each other. But in the case of Android, they have a completely different way of setting user IDs and file permissions than a typical Linux system.
Let's start by discussing what is the level of threat here? What worries these guys on the phone? What's going on here? What are they trying to protect against? What is a threat model in a mobile device?

Student: applications that can cause harm?
Professor:Yes, they are concerned that applications that can be installed on the phone may be malicious. I think that there are frankly malicious applications created to gain control over you or to steal your personal data. So you should worry about your data and things that cost money - SMS messages, phone calls, Internet connection and so on.
Thus, on the right - those things that you want to protect in your phone, and on the left - what can make them not work as they should. Since there are malicious apps, Android guys don't want users to install apps written by developers that Google has never heard of. In addition, such applications may cause harm, not because the developer wanted it so, but because he simply forgot to do something. And it would be nice to help these guys create applications that are safe, because often the application developer is not an expert in the field of vulnerabilities, which can then be used by an attacker in his application.

Since the Android OS is widespread, we can view vulnerability reports. There is a CVE database that catalogs many operating system vulnerabilities, and this is actually interesting. Of course, there are also Android error messages, many of which you encountered in lectures. In some parts of Android, buffer overflow is still possible, there is a poor choice of default cryptosystems, people forget to initialize the random number generator and create predictable keys. All this is still happening, because the software is not insured from any of the known problems.
Interestingly, these problems seem to be sporadic and occur from time to time. By and large, they can be eliminated, and the system remains fairly safe after correcting these errors. So in many ways, the Android design works quite well. Therefore, we will consider in more detail later which parts of the design work better and which parts are worse. But overall, this is a fairly well thought out software solution, or at least more thoughtful than the desktop Unix applications that you have encountered so far.
Thus, one of the ways to figure out how to protect data and various services that could cost you money from malicious applications is first of all to understand what an Android application looks like. Then we will talk about how various permissions or privileges are configured and applied in this application. Android applications are very different from what you have seen so far in desktop applications or in Internet applications.
Instead of making up the indivisible part of the code with the main function that you start to perform, Android applications are more modular. In the case of using Android, you can think of one application as a set of components. The lecture article describes 4 types of components that the Android framework provides to the developer. The first component is Activity, or Activity. This is the thing that represents the user interface and allows the user to interact with the application, displays information and accepts keystrokes from it, and so on.
From a security point of view, activity has an interesting property — user input is reduced to one action at a time. The Android framework in fact guarantees that only one type of activity is possible at the same time, that is, if you start a banking application, no application will run in the background to intercept the banking application PIN-code through touch presses. So the framework provides for the use of some security properties with respect to user input. Thus, the activity is a component of the user interface.
Three other types of components help the application's own structure logic to interact with other components. So, the second component is called Service, or service. These things work in the background. For example, you may have a service that tracks your location, as in the application that these guys describe in the article. You may have services that retrieve information from the network in the background and so on.
The third component is the content provider component, the Content provider. It can be thought of as a SQL database in which you can define several tables with a schema, and so on. You can call SQL queries to all data stored in this application. This component allows you to control access to the database, telling who is allowed to access it.
In "Android" there is still something unusual, which is not in other systems. This is the fourth component - Broadcast receiver, or broadcast receiver. It is used to receive messages from other parts of the system. Therefore, we will talk about how applications interact with each other in terms of messages.

Thus, this is a very logical idea of what Android applications are. But in fact, everything is just Java classes or Java code written by a developer.
There is only a certain standard interface that you implement for activity, for services, for a broadcast receiver, and for a content provider, and it is clear that this is just Java code. And all the components placed in the rectangle are simply the Java runtime that runs on your phone, it's just a single process on the Linux kernel that runs on your phone. And all of these components are different classes or parts of code that work in the Java runtime process. Here's how it can be reduced to traditional, more understandable to you processes.
Another thing that interacts with an application is called a manifest. The code for all components is written or compiled by the application developer, but beyond that, there is also a manifest in the system, which is outside the application components. It is a text or an XML file that describes all of these components and how other parts of the system should interact with the components of this application.

In particular, this manifesto talks about the so-called Lables tags, which we will talk about in a second, which determine the privileges of this application in terms of what it is allowed to do, and also define restrictions on who else can interact with the various components of this applications. You want to ask how it works?
Student:Is the label something that defines “this application cannot make a phone call”, or “can this application send a message”?
Professor: Yes, these labels set whether this application can make a call, send an SMS or use the Internet. There are two types of tags, I'll draw them here. Each application has a list of tags describing the privileges that the application has. This is something like permissions to dial a phone number, turn on the connection to the Internet, and so on. Later I will tell you how they work.
Thus, these are the privileges that the application has. In addition, you can also attach tags to individual components, and there they acquire a different meaning — these are privileges for a particular application. If you have a component with a label, then to interact with it, any other component must also have a corresponding label.
For example, you might have a label with the “View Friends” privilege, which you can use to view the location of your friends. This is a privilege that an application can have. But in order to secure this privilege, you must attach this label to a specific component, in this case to the Content Provider component, to its database, which contains information about the location of your friends. And now anyone who wants to access this database needs to have the same label in their privileges.

This is how you set permissions. You can think of it as user IDs or group IDs in Unix, with the exception of arbitrary strings, which make them a bit more flexible. That is, you will never run out of these IDs and you are not worried that someone will not have enough of them.
It turns out that the developers of "Android" were not particularly careful in determining the scope of these labels. You can have two applications that decide to provide the same label. Thus, these labels are partially defined by the application. Suppose you have two applications on your phone - Facebook and Google+, and they both declare that they would like a new line of permissions for the “View Friends” feature on the social network. You say, "no problem, it's the same string."
Of course, in reality, this line with the Labels list is much longer than I drew. There is a domain in the style of Java applications that defines the string label name. For example, the permission I have drawn for a DIALPERM call actually looks like com.google.android.dialperm. But roughly speaking, these are the lines that appear in the permissions. Therefore, if you have well-intentioned applications, they will not conflict with these permission lines.
But it turns out that, unfortunately, in the Android operating system, nothing forces the application to such behavior, and this creates potential problems. I do not know why they were not corrected. We will see what happens if we have two applications that conflict with tag names.
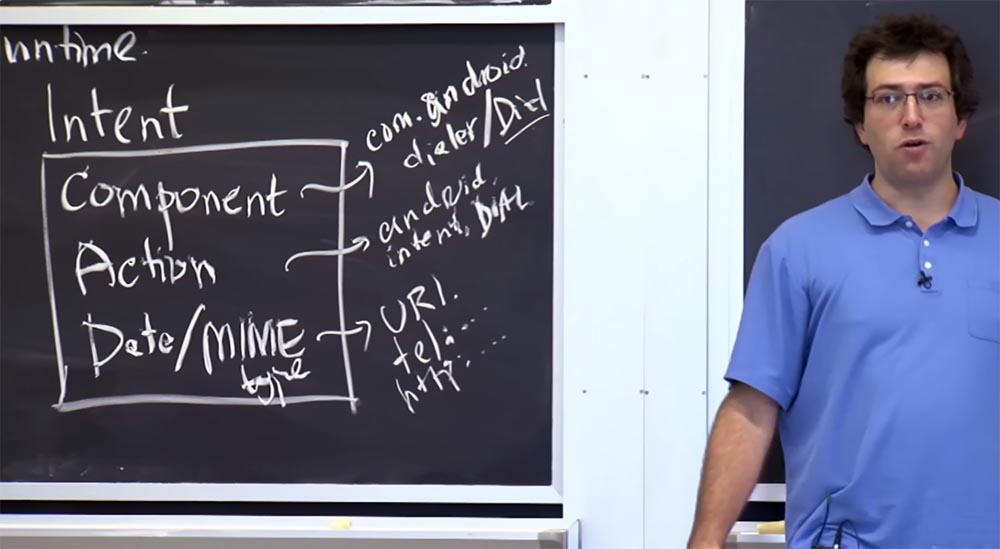
So, this is what an application looks like: it is a set of Java programs that form components, a manifest that describes permissions for applications, and the necessary restrictions for all components. The interaction between the application is carried out with the help of a thing that was invented by the developers of “Android” and is called the Intent - Intention. Intention is a structured message, and in a second we will see how it is used. For now, I’ll say that Intent has three key things. Of course, the intent contains other fields, but the most important is the name of the Component component to which you want to send a message. Then comes the Action action that the component needs to perform, and the Data data along with the MIME type that you want to send to the other component.

As an abstract example, you can imagine that this component is com.android.dialer / Dial - this is how the component name is indicated in Android, this is a kind of Java domain name. So, com.android.dialer is the name of the application as a whole, which needs to be sent intent, and you use a slash to write the name of the component of the target application to which you are sending the message - / Dial. Thus you name the specific component to which the message is addressed. An action represents a specific set of actions that may look like android.intend.Dial.
This is the predefined string that applications place in the Action field if they want the phone's dialer to call a specific number. For example, if you want to view a document on your phone, then in the Action field you insert an action line of the type android.intend.ViewDoc. This will tell the receiving component that you just want to look at the called contact before dialing its phone number.
Finally, Data data is basically an arbitrary URL or URL of the data you want to send along with this message. It can be something like a phone number or an HTTP URL that you want to view or open, or any other applications that are indicated in the system by the URL address.
This is how you send messages that are sent through the system using the Android runtime itself, which is under all these applications. Thus, Android runtime can be perceived as a cross between applications and the kernel. This is not entirely correct, but we will try to draw some kind of picture to clarify what the architecture of this thing looks like.
Let's say we have one application that runs on Android, and another application. These rectangles App1 and App 2, and each represents what is shown in the upper picture - components, manifest, labels.

These are all processes running on top of the Linux kernel, which provides some degree of isolation between applications. There is also what the lecture article calls Reference Monitor. It will mediate all interactions at the level of intentions between different applications. Therefore, if Appendix 1 wants to send a message to Appendix 2, it first sends a message to the link monitor.
So, the way you send all Intend intentions to Android, is that you create one of these messages of intent and send it via some channel to this Reference Monitor.

The Android system has its own channel implementation for sending such intentions, which is called Binder, or Bundle. Each Android application, by agreement, is going to open Binder - connect to the reference monitor so that it can receive intentions from this application, as well as send messages to this application.
In our case, if Appendix 1 writes an Intent for Appendix 2 to the link monitor, the link monitor will first find out where this intention should go, and then pass it on to Appendix 2. Then Appendix 2 can trigger some action, receive a message or execute a request SQL for Applications 1.

Student: when does a label check occur - right in the applications or when they access the Reference Monitor?
Professor:the link monitor is of paramount importance, as its duty is to check all the permissions granted by these tags. So that you can imagine what is happening in terms of checking the permissions in the applications themselves, let's try to figure out why the developers decided to check the tags in RM, and not in the applications? Does it make sense to make a check in the application? Suppose we inserted a verification tag in Appendix 1. Is this reasonable?
Student: this seems like a bad idea, because if someone hacks the application, it can change the label so that the application can pass a trust test.
Professor:Yes it is. Therefore, you probably do not want to insert a label in the sender, because you are not going to trust him unconditionally. If you installed a malicious application, there are no guarantees that it will correctly check the tags. Therefore, we are not allowed to do checks on the sender side. What about performing checks on the recipient side, in Appendix 2?
Student: this is possible, but then you will need encryption and a PKI key. This will require more effort.
Professor:then you think you need cryptography and a key for encryption and decryption. But I'm not sure that cryptography is needed here, because the kernel can tell exactly who the message comes from, that is, RM can say that this message came from App 1. So in this sense, PKI is not needed. This does not have to be related to cryptography. I think you need encryption when you talk on the network and when there is nothing in common that you could trust. Here, I think, it's not about cryptography. Try to name any other reasons why the reference monitor should check the tag.
Student: you may want to avoid developer errors that may concern tags as well.
Professor:exactly. I think that the developers of "Android" decided to protect the system from the many annoying errors that are made by the creators of applications. Therefore, as far as possible, you will want to expand the overall functionality into code that the developer has nothing to do with and that he doesn’t need to worry about. So this seems like a good reason to give the link monitor a Labels check function. What else?
Student: perhaps this is due to the fact that you want to minimize the area of trust in the system. You can make a reference monitor that will act independently, without affecting other areas of the system, or have some component that personally checks the label on “its territory”.
Professor: yes, this seems to be a potentially reasonable plan, because the security of the system depends on the proper operation of the link monitor. In fact, putting a link in a monitor makes it bigger, so you could make RM smaller by delegating its work to applications. However, in this case, we would need to add some library to the applications. So there are controversial issues.
I think that there are 2 more reasons why tags are checked by the link monitor. The first is simplicity, because in many ways it's easier to do all the checks in one place. As you yourself said, it is convenient to look and see that the check has been carried out, and a corresponding message is issued. So this is convincing or good in terms of software engineering.
In addition, these intentions have two addressing modes. In particular, the article describes the so-called implicit and explicit intentions. Explicit intentions are those where you indicate a specific component and say that it should refer to that particular component. It is perfectly normal that verification of explicit intentions is carried out on the recipient side, because usually you know where you want to send this component. You can send the intent there, and if it does not want to allow you to send a message, it will not work or in some way reject the request.
There are also implicit intentions in Android, when you, as the sender, do not know exactly which application should receive your message. This can happen if you just want to view images or dial a phone number, but do not know which “dialer” is installed on the user's phone. Maybe he has Google Voice, VoIP, Skype and who knows what else. In this case, the implicit intentions actually skip the name of the component and simply say: “I want this action to be processed with this data by some suitable application for this”. In this case, the job of the link monitor is to find an application that is suitable for processing this type of message — dialing a phone number, viewing a PDF or JPEG image, and so on.

At the same time, the link monitor can issue account permissions to select the appropriate application. For example, you installed a very sensitive application for viewing PDF files, but you do not want it to be available for most other applications on the phone. Therefore, RM will not give permissions to use this application to other programs installed in the system.
In this case, the monitor will look at it and say: “you are not allowed to send your request to this application, but perhaps there is another application that is ready to process it”. So it seems like it simplifies the user interface and user interaction by comparing the capabilities of applications in the system and taking into account the permissions that are available to the sender.
Audience: Is the link monitor not a system bottleneck?
Professor: possible. Many of the messages are sent through this monitor, and I do not know if it is multi-threaded. Probably you could make it multi-threaded, it should take into account the logic of its purpose. I think that if necessary, many messages of intent can be processed in parallel, so it should not become a bottleneck of the system.
For massive things, Android has an RPC mechanism. If you want to send multiple operations to another application, you send what is called a bind intent, or intent to bind to the link monitor, saying, "I want a direct connection to this application." Thus, first you organize the channel between these two applications, and then send the amount of data through it.
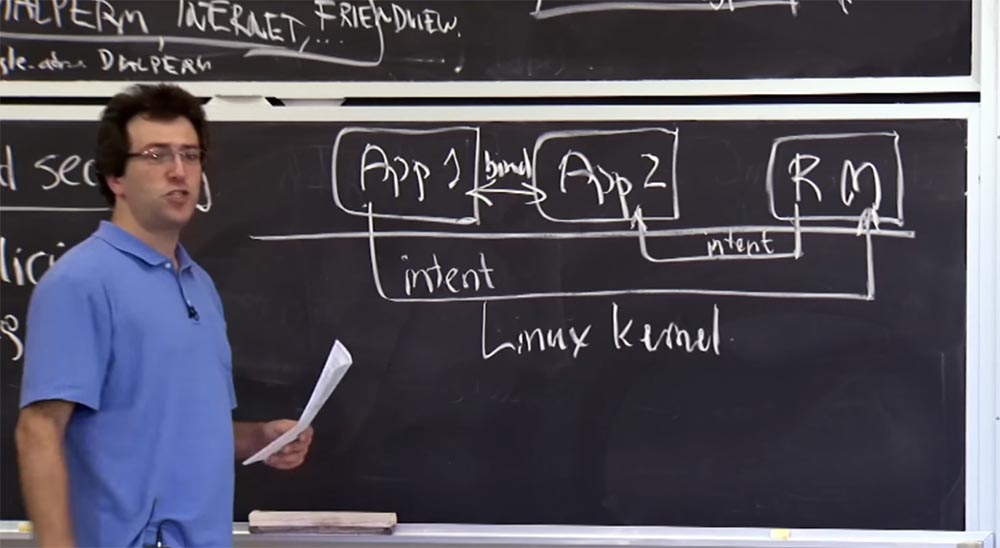
Therefore, if some application is concerned about the interface for which performance is critical, then it uses the Bind intent.
Student: applications communicate with each other by channel, because each label corresponds to a specific component?
Professor: Well, this is not the case when you get direct access inside Appendix 2. It's not that you can directly manipulate everything that is contained in the address space or all the objects in Appendix 2. You just get a channel through which other An application can view messages and do something sensible according to its content.
Thus, Appendix 2 on this diagram uses the bind channel to look at the messages of the first application and do something sensible with them, preventing arbitrary code execution or random access to the components inside. I think there are a couple of operations in this application, with which you can add a new friend or enable or disable tracking via this interface.

Thus, there are fairly clear messages about which component, for example, from the Service group, you should use. At the same time, the reference monitor is responsible both for accepting the message, for checking the reasonableness of this message, and for performing the requested operation.
Student: I think intentions are usually initiated by a person, but people are rather slow. Therefore, it is unlikely that the reference monitor will be a system bottleneck.
Professor: this is probably true, but it all depends on how you use intentions. There is a problem here. The article states that permissions are monitored by the reference monitor only during the creation of the bind binding channel. But the monitor does not check permissions for separate RPC calls between applications, since there is a direct channel between the two applications.
I don’t know exactly why they decided to do it this way. It is possible that RM does not become a bottleneck for communication. But this means that permissions for individual RPC operations between applications must be made in the software inside the application logic, which is a bit unsuccessful if we want to avoid cases where the application developer made an error and may have forgotten to check permissions for some RPC calls.
Thus, if you are solely concerned about security, it would be better to also send all RPCs through the reference monitor, because in this case, it could check permissions on each RPC call, and not only during the installation of the channel for future RPC call exchange between the two applications.
27:40
MIT course "Computer Systems Security". Lecture 20: "Mobile Phone Security", part 2
Full version of the course is available here .
Thank you for staying with us. Do you like our articles? Want to see more interesting materials? Support us by placing an order or recommending to friends, 30% discount for Habr users on a unique analogue of the entry-level servers that we invented for you: The whole truth about VPS (KVM) E5-2650 v4 (6 Cores) 10GB DDR4 240GB SSD 1Gbps from $ 20 or how to share the server? (Options are available with RAID1 and RAID10, up to 24 cores and up to 40GB DDR4).
VPS (KVM) E5-2650 v4 (6 Cores) 10GB DDR4 240GB SSD 1Gbps until January free of charge if you pay for a period of six months, you can order here .
Dell R730xd 2 times cheaper? Only here2 x Intel Dodeca-Core Xeon E5-2650v4 128GB DDR4 6x480GB SSD 1Gbps 100 TV from $ 249 in the Netherlands and the USA! Read about How to build an infrastructure building. class c using servers Dell R730xd E5-2650 v4 worth 9000 euros for a penny?