Recommender systems in online education. Adaptive learning
Less than six months later, we are completing a series of articles on adaptive learning at Stepik! Well, no, it’s passed ... But I’m finally glad to present to your attention the final article on why adaptive training is needed at all, how it is implemented at Stepik and what does chess have to do with it.

Introduction
Once we decided to tell on Habré how the system of adaptive recommendations on Stepik.org is arranged. The first two articles of this series were written back in the summer in the hot pursuit of my bachelor's diploma at the St. Petersburg State University matriculation, the first was generally about recommendation systems in online education, in the second we looked a bit under the hood and talked about the architecture of our recommendation system. The third part, in which we finally get to the actual adaptive recommendations, was poorly written, largely because this part of the platform is changing very quickly. But now I am ready to publish it.
Why adaptability?
When talking about the benefits of online learning, they are often mentioned among the masses. Indeed, it is difficult to compare the throughput of a full-time course at a university, even if a streaming one, and a massive online course that has practically no restrictions for scaling - the difference in audience size will be orders of magnitude.
But this feature is also a drawback of online education: in the case of classes in the classroom, the teacher can tailor his lectures to students: conduct a survey at the beginning of the semester, follow in the classroom, does everyone understand the material, even communicate with individual students personally if they they haven’t learned or, on the contrary, they want to delve deeper into some topics. Of course, in the case of a massive online course, the teacher’s resources for such interaction are not enough, and students find themselves in the strict framework of a linearly composed course without the ability to analyze complex tasks in more detail or skip simple ones.
However, there are ways to implement something similar in automatic (mass) mode. These methods can be divided into three main groups:
- Differentiated training. The easiest way to adjust the material to the student’s level of knowledge: the teacher creates several fixed training paths of varying complexity in advance, and the student selects the most suitable for himself and then learns from it in a regular, linear mode. For example, a series of textbooks for different levels of language proficiency.

- Personalized training. In this case, the trajectory is built in the learning process, depending on the student's results in intermediate tests. The rules about when to test and what to advise to study further with different results are set in advance by the teacher. It turns out something similar to a decision tree, according to which students will go differently depending on their successes, but the tree itself must be thought out and created by the teacher.
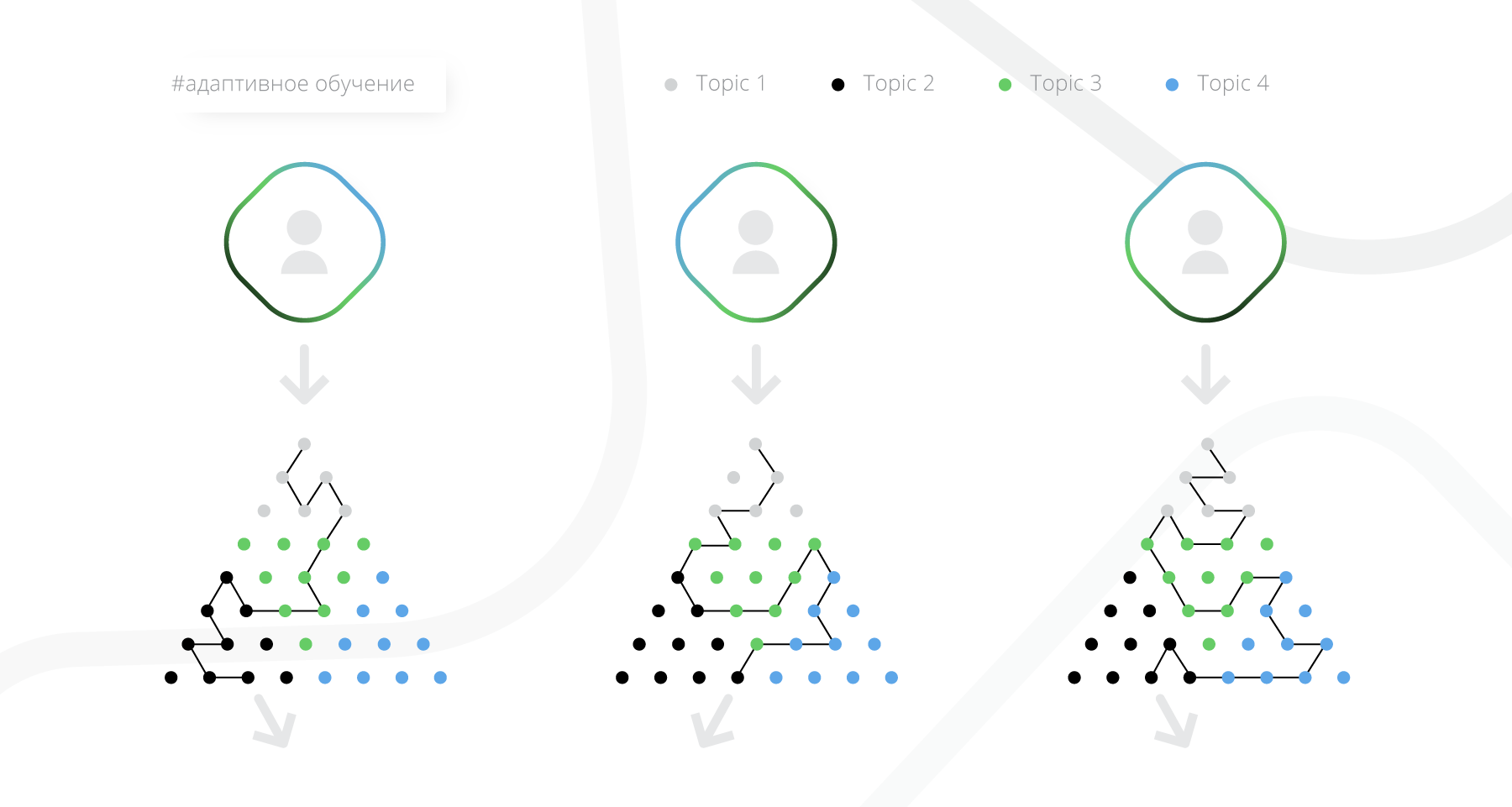
- Adaptive learning. The most interesting group from the point of view of algorithms. The trajectory is also built in the learning process, but does not require initial marking from the teacher, but uses a maximum of information about how the student studies the material and how this material was studied before him. Further in the article this will be discussed in more detail.
Adaptive learning mechanisms
The adaptive training on Stepik is made in the form of a recommendation system that advises the user which lesson he should learn next, depending on his previous actions. So far, recommendations are given as part of the materials of the chosen course (for example, a Python simulator ), but in the near future, recommendations will also be available as part of an arbitrary topic (for example, C ++ or integrals). In the future, any topic can be studied in adaptive mode.
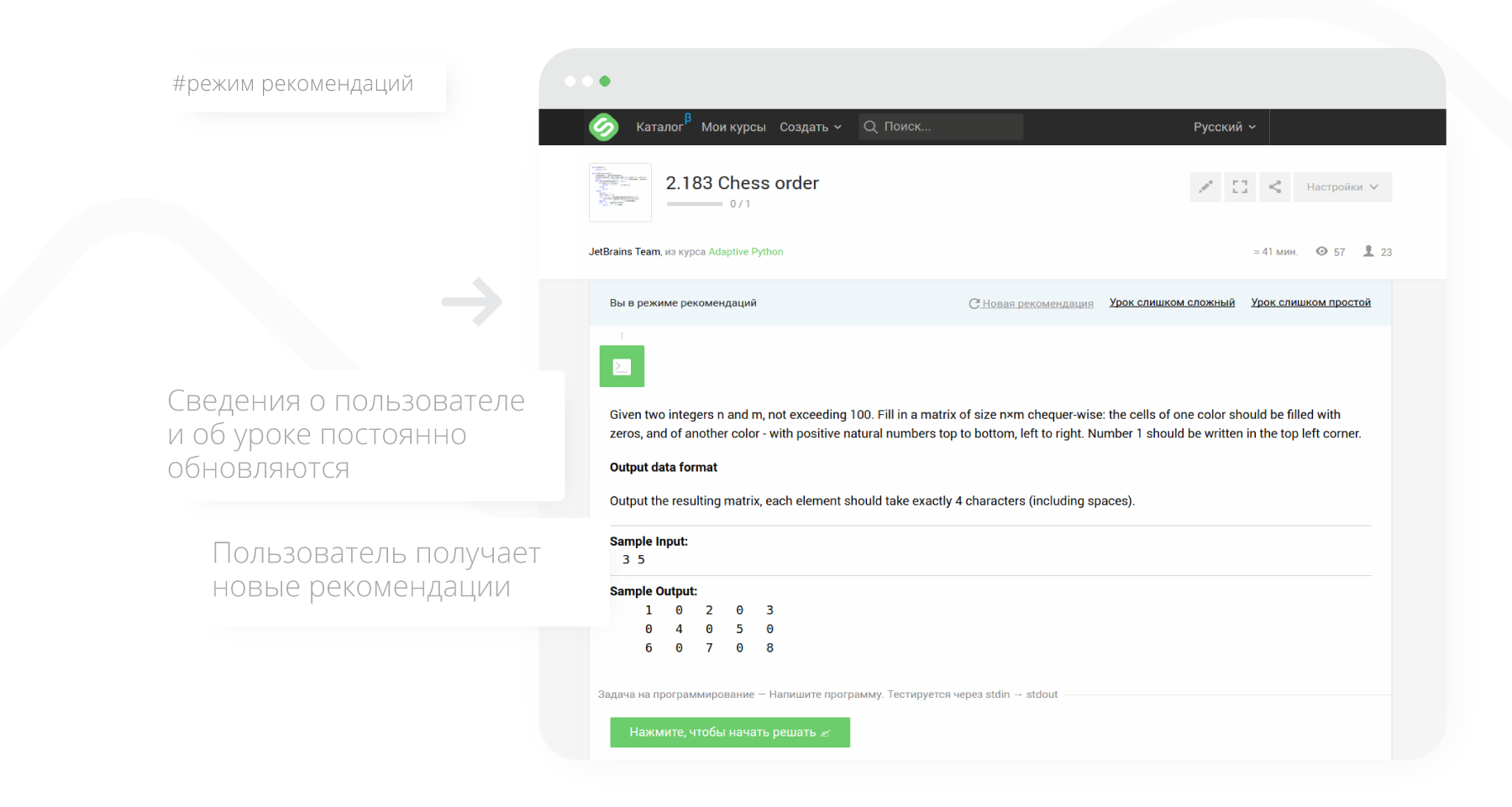
For a registered user, to start learning in adaptive mode, just click the “Learn” button in an adaptive course (it will become available after enrolling in a course).
Having received the material recommended for training (lesson), the user can respond to it in one of three ways:
- take a lesson (solve problems in it),
- mark lesson as too simple
- mark the lesson as too complicated.
After receiving the reaction, information about the user's knowledge and the complexity of the lesson is updated, and the user receives a new recommendation.
For adaptive recommendations, two methods are used (“handlers”): based on complexity and based on dependencies between topics (more about handlers can be found in the second article of the series ).
Under the hood of recommendations based on complexity lies two ideas:
- Item Response Theory . This psychometric paradigm with a name that cannot be translated into Russian can be formulated very simply: the probability that the student will solve the problem is expressed as a function of the student’s parameters and the task. As parameters, you can use, for example, somehow calculated level of user knowledge and complexity of the task, as well as how confident we are in these values.
- Chess rating Elo. The model for rating chess players, developed by Arpad Elo in the 1960s, works as follows: each new player is assigned a default rating (for example, zero), and then after each game the ratings of both players are updated. To do this, first calculate the expected result of the game for each of the players (
 in case of losing player A,
in case of losing player A,  - in case of victory,
- in case of victory,  - draws), and then the ratings are updated depending on the difference between the predicted result of the game and the actual one.
- draws), and then the ratings are updated depending on the difference between the predicted result of the game and the actual one.
Formula for predicting the result ,
,
to update the rating ,
,
where ,
,  - ratings of players A and B,
- ratings of players A and B,  - Updated player rating A,
- Updated player rating A,  - the actual result of the game for player A. Odds
- the actual result of the game for player A. Odds  characterizes our confidence in rating assessment: if we still do not know much about a player, his rating should change quickly, but when it comes to an experienced master, one game, far from being predicted, should not change the rating much.
characterizes our confidence in rating assessment: if we still do not know much about a player, his rating should change quickly, but when it comes to an experienced master, one game, far from being predicted, should not change the rating much.
As a result of the merger of these two ideas, we obtain the following model of the system. We consider users and lessons as “players,” the user's reaction to the recommendation of the lesson is the result of a “game,” and we predict this result based on some student and lesson parameters. We took the main features of this model from a scientific article about Maths Garden , a service for studying arithmetic for children. For the recommendation, we select such a lesson, the probability of deciding which for the user is close to optimal.
In addition to the complexity of the lessons, we also want to take into account the layout of content with topics. We use the knowledge graph from Wikidata , and enable lesson authors to tag them with two types of topics:
- topics to which this lesson relates (which are explained in it),
- topics you need to understand to learn this lesson.
For example, if the user has marked the lesson as too complicated, we can advise him to study the topics that are necessary for this lesson.
Metrics
The main metrics for assessing the quality of adaptive recommendations are, firstly, the share of solved lessons from the number of recommended ones (essentially retention), and secondly, the difference between the predicted outcome of the decision and the real one (from a model based on a chess rating).
The share of the lessons learned speaks more about how useful and suitable in terms of complexity the users consider the recommendations. We calculate this metric regularly based on the results of the last 7 days, and since the end of last year it has grown from 60 to 80 percent.
The second metric, the prediction error, rather characterizes the accuracy of the internal machinery of the adaptive system. At the same time, it is more difficult to interpret, because changing models to predict user response and to evaluate the actual behavior of users, we can get significant changes in this metric that are unlikely to show whether the model has become better or worse compared to the previous version. Because we evaluate the error, we are now also in a different way.
For example, if earlier the values of predicted_score and real_score were in the range ![$ [- 1, 1] $](https://habrastorage.org/getpro/habr/post_images/7b7/67e/bf1/7b767ebf15c29b116d9e6ca05734c433.svg) , and in the new version - in
, and in the new version - in ![$ [- 100, 100] $](https://habrastorage.org/getpro/habr/post_images/f8b/6ea/756/f8b6ea756f71ce77cee66868e2dd6212.svg) , the absolute values of the error will dramatically increase, but this will not mean that you need to urgently roll back. Of course, the example is exaggerated, but similar reasons for changing the error must be taken into account when analyzing metrics.
, the absolute values of the error will dramatically increase, but this will not mean that you need to urgently roll back. Of course, the example is exaggerated, but similar reasons for changing the error must be taken into account when analyzing metrics.
As I wrote, these two metrics are basic, but not exhaustive. We also monitor the state of the system by the number of recommendation requests (of the order of several thousand per week), by the moving average of the prediction errors for several days (helps to identify a tendency to improve or worsen by smoothing the peaks), by the processing time of the request for a new recommendation (well, this parameter always there is something to strive for :) ).
We also conduct A / B testing to compare the performance of different models. Then, in addition to the above metrics for daily monitoring, the dashboard can be expanded with specific metrics for a specific experiment. However, the decision about which model to leave is usually made based on basic metrics.
Adaptive Project History
- March 1, 2016 - the first prototype of adaptive recommendations appeared in Stepik (which at that time was also called Stepic)
- March 21, 2016 - the beginning of beta testing (Russian-language taskbook in Python)
- August 11, 2016 - Adaptive system integration in PyCharm Edu 3 , a JetBrains Python learning tool
- September 2016 is the peak of user activity due to the fact that for attaining a certain level of “adaptive” knowledge of Python, a discount was given for teaching programming in the online program Computer Science Center and the Academic University. Fixed some funny bugs.
- December 2016 - March 2017 - a competition for the creation of adaptive content , about which we already wrote in detail on Habré .
The table below lists the main adaptive courses on Stepik and some information about their use.
| Course | The lessons | Students | Lesson reactions |
|---|---|---|---|
| Adaptive python | 382 | 1874 | 22904 |
| Python adaptive simulator | 55 | 2298 | 20546 |
| Pokemon! Gotta catch 'em all | 101 | 243 | 7661 |
| Adaptive GMAT Data Sufficiency Problems | 265 | 29th | 94 |
| SDA 2017 | 800 | 560 | 17649 |
Conclusion
In this article, I talked about the general features of the adaptive recommendations system on the Stepik platform. Much remains behind the scenes: how we predict the outcome of a student's decision to material, how we evaluate real behavior, and how we update assessments of user knowledge and the complexity of the lesson. Perhaps someday articles will also appear on Habrahabr about this, but now these parts of the system are changing faster than they can be described.
Nevertheless, I hope you were interested in reading this article. I will be glad to answer your questions in the comments or in private messages.