The world's first search engine: Historical Excursion
In the early years of the Internet era, millions of files were stored on thousands of anonymous FTP sites. In this variety, it was rather difficult for users to find a program suitable for solving their problem.
Moreover, they did not know in advance whether the required instrument existed. Therefore, I had to manually browse FTP-storages, the structure of which was significantly different. It is this problem that has led to the emergence of one of the key aspects of the modern world - Internet search. / photo by mariana abasolo CC

It is believed that the creator of the first search engine was Alan Emtage. In 1989, he worked at McGill University in Montreal, where he moved from his native Barbados. One of his tasks as the administrator of the university faculty of information technology was to find programs for students and teachers. To make his job easier and save time, Alan wrote code that searched for him.
“Instead of wasting my time wandering around FTP sites and trying to figure out what they have, I wrote scripts that did it for me,” Alan says, “and they did it quickly.”
Emteij wroteA simple script that automates the task of embedding listings on FTP servers, which are then copied to local files. These files were used to quickly search for the necessary information using the standard grep Unix command. Thus, Alan created the world's first search engine, which was called Archie - this is an abbreviation for the word Archive (Archive).
Archie was able to search through 2.1 million files on more than a thousand sites around the world in a few minutes. The user was required to enter a topic, and the system provided a report on the location of files whose names coincided with keywords.
The decision turned out to be so successful that in 1990 Emteij and his partner Peter Deutsch founded Bunyip with the intention of launching a more powerful commercial version of Archie. We can say that this was the first Internet startup in history, since Bunyip sold the Internet service.
“It all started with thirty visits a day, then there were thirty requests per hour, then - in a minute,” says Peter. “Traffic continued to grow, so we started working on scaling mechanisms.”
The team decided to bring listings to a more effective presentation. The data was divided into separate databases: in one of them textual file names were stored, in the other - records with links to hierarchical host directories. There was a third base connecting the other two with each other. In this case, the search was performed element by element by file name.
Over time, other improvements were implemented. For example, the database was changed again - it was replaced by a database based on the theory of compressed trees. The new version formed a text database instead of a list of file names and worked much faster than the previous ones. Minor improvements also allowed Archie to index web pages.
Unfortunately, work on Archie was discontinued, and the revolution in the field of search engines was postponed. Emteij and his partners disagreed on future investments, and in 1996 he decided to quit. After that, the Bunyip client worked for another year, and then became part of Mediapolis, a New York web design firm. At the same time, patents for all the acquired technologies were never obtained.
“But I gained wonderful experience: I traveled the world, participated in conferences and met people who shaped the look of the modern Internet, ” Alan recalls . As a member of the Internet Society, he managed to work with people like Tim Berners-Lee, Winton Cerf, and John Postel.
And yet Archie managed to influence the development of WWW. In particular, the emergence of a standard exceptions for robots. The tool was used to inform robots about which parts of the server cannot be accessed. To do this, we used the robots.txt file, which could be accessed via HTTP.
It contained one or more lines containing information in the following format :
The record <field> could take two values: User-agent or Disallow. The user-agent specified the name of the robot for which the policy was described, and Disallow defined the sections to which access was closed.
For example, a file with such information prevents all robots from accessing any URL with / cyberworld / map / or / tmp /, or /foo.html:
This example closes access to / cyberworld / map for all robots except cybermapper:
This file will “deploy” all robots that try to access information on the site:
Created almost three decades ago, Archie has not received any updates all this time. And he offered a completely different experience with the Internet. But even today, with its help you can find the information you need. One of the places that still host the Archie search engine is the University of Warsaw. True, most of the files found by the service date back to 2001.
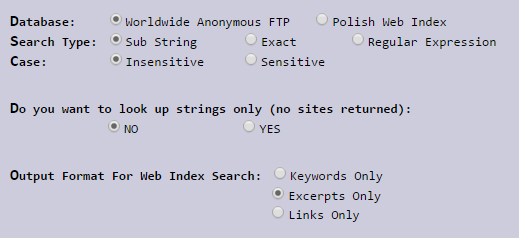
Despite the fact that Archie is a primitive search engine, it still offers several features to customize the search. In addition to the ability to specify a database (anonymous FTP or Polish web index), the system suggests choosing options for interpreting the entered string: as a substring, as a literal search or a regular expression. You even have options for choosing a register and three options for changing the options for displaying results: keywords, description or links.
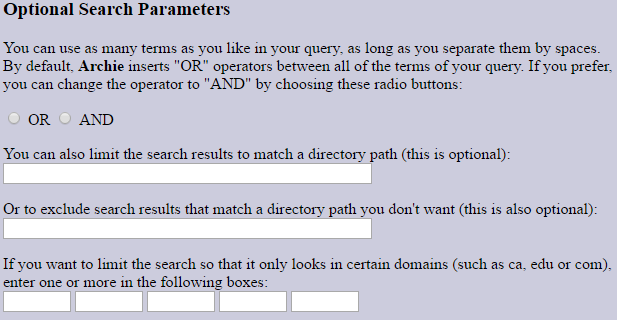
There are also several optional search parameters that allow you to more accurately determine the necessary files. There is the possibility of adding the service words OR and AND, limiting the scope of the file search by a specific path or domain (.com, .edu, .org, etc.), as well as setting the maximum number of output results.
Although Archie is a very old search engine, it still provides quite powerful functionality when searching for the file you need. However, compared to modern search engines, it is extremely primitive. "Search Engines" have gone far ahead - just start entering the desired query, as the system already offers search options. Not to mention the machine learning algorithms used.
Today, machine learning is one of the main parts of search engines such as Google or Yandex. An example of using this technology can be search ranking: contextual ranking, personalized ranking, etc. Learning to Rank ( LTR ) systems are very often used .
Machine learning also allows you to “understand” user input. The site independently corrects the spelling, processes synonyms, resolves ambiguity issues (what the user wanted to find, information about the Eagles group or about eagles). Search engines independently learn to classify sites by URL - a blog, news resource, forum, etc., as well as the users themselves to create a personalized search.
Archie spawned search engines such as Google, so to some extent it can be considered the great-grandfather of search engines. That was almost thirty years ago. Today, the search engine industry makes about $ 780 billion annually.
As for Alan Emteij, when asked about the missed opportunity to get rich, he answers with modesty. “Of course, I would like to get rich, ” he says . “However, even with patents issued, I might not have become a billionaire.” It is too easy to make inaccuracies in the description. Sometimes it’s not the one who was the first who wins, but the one who has become the best. ”
Google and other companies were not the first, but they surpassed their competitors, which allowed the founding of a multi-billion dollar industry.
PSOur digest of practical materials about work with IaaS .
Moreover, they did not know in advance whether the required instrument existed. Therefore, I had to manually browse FTP-storages, the structure of which was significantly different. It is this problem that has led to the emergence of one of the key aspects of the modern world - Internet search. / photo by mariana abasolo CC
History of creation
It is believed that the creator of the first search engine was Alan Emtage. In 1989, he worked at McGill University in Montreal, where he moved from his native Barbados. One of his tasks as the administrator of the university faculty of information technology was to find programs for students and teachers. To make his job easier and save time, Alan wrote code that searched for him.
“Instead of wasting my time wandering around FTP sites and trying to figure out what they have, I wrote scripts that did it for me,” Alan says, “and they did it quickly.”
Emteij wroteA simple script that automates the task of embedding listings on FTP servers, which are then copied to local files. These files were used to quickly search for the necessary information using the standard grep Unix command. Thus, Alan created the world's first search engine, which was called Archie - this is an abbreviation for the word Archive (Archive).
Archie was able to search through 2.1 million files on more than a thousand sites around the world in a few minutes. The user was required to enter a topic, and the system provided a report on the location of files whose names coincided with keywords.
The decision turned out to be so successful that in 1990 Emteij and his partner Peter Deutsch founded Bunyip with the intention of launching a more powerful commercial version of Archie. We can say that this was the first Internet startup in history, since Bunyip sold the Internet service.
“It all started with thirty visits a day, then there were thirty requests per hour, then - in a minute,” says Peter. “Traffic continued to grow, so we started working on scaling mechanisms.”
The team decided to bring listings to a more effective presentation. The data was divided into separate databases: in one of them textual file names were stored, in the other - records with links to hierarchical host directories. There was a third base connecting the other two with each other. In this case, the search was performed element by element by file name.
Over time, other improvements were implemented. For example, the database was changed again - it was replaced by a database based on the theory of compressed trees. The new version formed a text database instead of a list of file names and worked much faster than the previous ones. Minor improvements also allowed Archie to index web pages.
Unfortunately, work on Archie was discontinued, and the revolution in the field of search engines was postponed. Emteij and his partners disagreed on future investments, and in 1996 he decided to quit. After that, the Bunyip client worked for another year, and then became part of Mediapolis, a New York web design firm. At the same time, patents for all the acquired technologies were never obtained.
“But I gained wonderful experience: I traveled the world, participated in conferences and met people who shaped the look of the modern Internet, ” Alan recalls . As a member of the Internet Society, he managed to work with people like Tim Berners-Lee, Winton Cerf, and John Postel.
Left a mark
And yet Archie managed to influence the development of WWW. In particular, the emergence of a standard exceptions for robots. The tool was used to inform robots about which parts of the server cannot be accessed. To do this, we used the robots.txt file, which could be accessed via HTTP.
It contained one or more lines containing information in the following format :
<поле>:<необязательный пробел><значение><необязательный пробел>The record <field> could take two values: User-agent or Disallow. The user-agent specified the name of the robot for which the policy was described, and Disallow defined the sections to which access was closed.
For example, a file with such information prevents all robots from accessing any URL with / cyberworld / map / or / tmp /, or /foo.html:
# robots.txt for http://www.example.com/
User-agent: *
Disallow: /cyberworld/map/ # This is an infinite virtual URL space
Disallow: /tmp/ # these will soon disappear
Disallow: /foo.htmlThis example closes access to / cyberworld / map for all robots except cybermapper:
# robots.txt for http://www.example.com/
User-agent: *
Disallow: /cyberworld/map/ # This is an infinite virtual URL space
# Cybermapper knows where to go.
User-agent: cybermapper
Disallow: This file will “deploy” all robots that try to access information on the site:
# go away
User-agent: *
Disallow: /Immortal Archie
Created almost three decades ago, Archie has not received any updates all this time. And he offered a completely different experience with the Internet. But even today, with its help you can find the information you need. One of the places that still host the Archie search engine is the University of Warsaw. True, most of the files found by the service date back to 2001.
Despite the fact that Archie is a primitive search engine, it still offers several features to customize the search. In addition to the ability to specify a database (anonymous FTP or Polish web index), the system suggests choosing options for interpreting the entered string: as a substring, as a literal search or a regular expression. You even have options for choosing a register and three options for changing the options for displaying results: keywords, description or links.
There are also several optional search parameters that allow you to more accurately determine the necessary files. There is the possibility of adding the service words OR and AND, limiting the scope of the file search by a specific path or domain (.com, .edu, .org, etc.), as well as setting the maximum number of output results.
Although Archie is a very old search engine, it still provides quite powerful functionality when searching for the file you need. However, compared to modern search engines, it is extremely primitive. "Search Engines" have gone far ahead - just start entering the desired query, as the system already offers search options. Not to mention the machine learning algorithms used.
Our posts: Machine Learning



Today, machine learning is one of the main parts of search engines such as Google or Yandex. An example of using this technology can be search ranking: contextual ranking, personalized ranking, etc. Learning to Rank ( LTR ) systems are very often used .
Machine learning also allows you to “understand” user input. The site independently corrects the spelling, processes synonyms, resolves ambiguity issues (what the user wanted to find, information about the Eagles group or about eagles). Search engines independently learn to classify sites by URL - a blog, news resource, forum, etc., as well as the users themselves to create a personalized search.
Great-grandfather of search engines
Archie spawned search engines such as Google, so to some extent it can be considered the great-grandfather of search engines. That was almost thirty years ago. Today, the search engine industry makes about $ 780 billion annually.
As for Alan Emteij, when asked about the missed opportunity to get rich, he answers with modesty. “Of course, I would like to get rich, ” he says . “However, even with patents issued, I might not have become a billionaire.” It is too easy to make inaccuracies in the description. Sometimes it’s not the one who was the first who wins, but the one who has become the best. ”
Google and other companies were not the first, but they surpassed their competitors, which allowed the founding of a multi-billion dollar industry.
PSOur digest of practical materials about work with IaaS .