Fear and Loathing in Distributed Systems

Roman Grebennikov explains the complexity of building distributed systems. This is a report of Highload ++ 2016.
Hello everyone, my name is Roman Grebennikov. I work for Findify. We do a search for online stores. But the conversation is not about that. At Findify, I deal with distributed systems.
What are distributed systems?

From the slides it is clear that “fear and hatred” is a common thing in IT, and distributed systems are not quite ordinary. First, we will try to understand what distributed systems are, why there is such pain, and why this report is needed.
Imagine that you have some kind of application that works somewhere there. Suppose it is server-side, but it differs from ordinary applications in that it has some kind of internal state. For example, you have a game, your internal state is a world where little men run along and so on. Sooner or later, you grow, and your internal state swells, it changes and ceases to fit on one server.

Here in the picture Winnie the Pooh was stuck in a hole.
If you started to grow and ceased to fit on the same server, then you need to do something.
You have several options.
You can take the server more powerful, but it can be a dead end path, because you are probably already working on the fastest server that is.
We can optimize, but it’s not clear, it’s twice as hard to click everything to accelerate.
You can stand on a very shaky track - creating distributed systems.
This track is shaky and scary.
What I will talk about today
First, we'll talk about distributed systems. A little bit of equipment, why it is important, what is integrity, how to comb this integrity, what are the approaches to designing distributed systems that don’t lose data or lose it just a little, what tools are there to check your distributed systems for what you have everything is good with data or almost everything is good.
Since one theory is boring, we will talk a little bit on the matter and a little practice. We will take this laptop and write our own small, simple distributed database. Not really a database, there will be not key value storage, but value storage. Then we will try to prove that she does not lose data, more than once and in especially terrible poses.
Next is a little philosophy of "how to live with it."
We imagine that distributed systems are things that work somewhere far away, and we are sitting here. It can be servers, it can be mobile applications that communicate with each other, they have some kind of internal state. If you are texting with your friends, then you are also part of a distributed system, you have a general condition, which you are trying to agree on. In general, a distributed system is a joke that consists of several parts, and these parts communicate with each other. But things get complicated by the fact that they communicate with delays and errors. This makes things very complicated.
A small example from life.
We once wrote a web spider that surfed the Internet, downloaded all sorts of different pages. He had a long line of tasks, we piled everything there. We have several basic operations on the queue. This is something to take from the queue, something to put in the queue. We also had the third operation for the queue: to check whether there is an object in the queue so that we don’t put the same thing there twice.
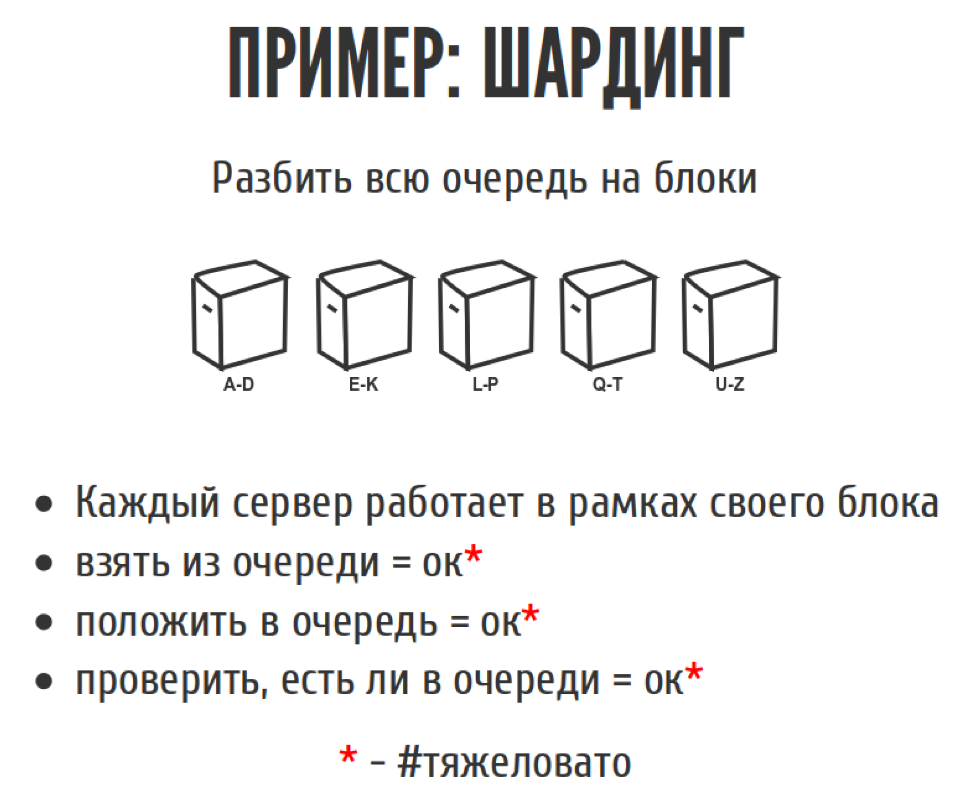
The problem was that the line was quite large, and it did not fit into the memory. We thought: what's so complicated? We are smart, we go to HighLoad. Therefore, let's cut this queue into pieces, roll it to different servers. Each server will deal with its own piece of the queue. Yes, we will lose a little integrity, in the sense that we cannot take the very first element from the queue, but we can take almost the very first. Just choosing a shard case, taking from it, and all is well. That is, if you take it from the queue, almost everything is fine, the logic has become a little more complicated. Putting it in the queue is also simple, we look into which shard to put, and put it. Check if there is a queue, also no problem. Yes, business logic has become a little more complicated, but at least it has become uncritical, and there seems to be no blood here.
What problems can be
We understand that if we have added some kind of network interaction and we have more components, then the system has less reliability. If reliability is less, then something will definitely go wrong. If with software and hardware, everything is clear. With iron, you can take the server more brand-new, with software - do not deploy drunk on Friday. And with the network, such a thing breaks regardless of what you do with it. Microsoft has a great article on network hardware failure statistics based on the type of switch in Windows Azure. The probability that the load balancer port grunts during the year is about 17%. That is, if you do not provide what to do in case of refusal, then sooner or later you will slurp someone good.
The most popular problem that happens with a network is NETSPLIT. When your network has collapsed in half, either it has constantly collapsed, or you have packet loss. As a result of this, it either fell apart, or did not fall apart.
What will happen to our queue at sharding if we have problems with the network?
If we take something from the queue, if we are ready to take not the very first element from the queue, then we can just take from those shards that are available to us and somehow live on.
If we need to check if there is a component in the queue, then everything is complicated by the fact that if we need to go to the shard that is not available to us, then we can do nothing.
But things get complicated when we need to put something in the queue, and the shard is not available. We have nowhere to put it, because that shard is somewhere far away. There is nothing left but to lose it, or to postpone it somewhere and then do something with it. Because we did not put failures in the design of the system.

The uncle is sad in the picture. Because he did not put failures in the design of the system. We are smart, we know that there are certainly other uncles who are very smart and have come up with many different options for how to live with this problem.
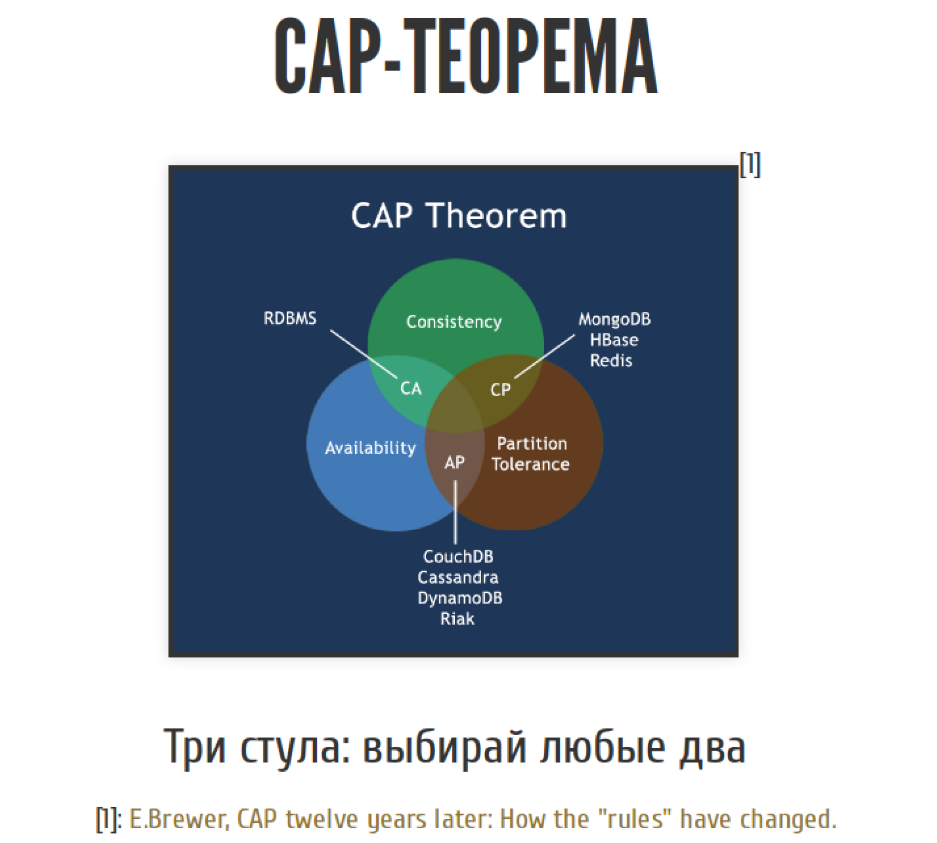
Then the CAP-theorem appears on the scene.
The CAP theorem is the cornerstone of the design of distributed systems. This is a theorem that formally is not a theorem, but an empirical rule, but everyone calls it a theorem.
It sounds as follows. We have three pillars of creating distributed systems. This is integrity, availability and resistance to network problems. We have three whales, we can choose any two. And not just any two, almost any two. We’ll talk about this a bit later.
In order - what is integrity, accessibility and sustainability. This is kind of a theorem, there must be formal descriptions.
Availability
This is availability, and it implies continuous availability. Each request to the system, any request to the system to any living node must be successfully processed. That is, if we postpone part of the requests somewhere for later, or we postpone recordings to the side, because something went wrong with us - this is inconsistent availability. If not all nodes respond to requests, or if all nodes do not answer all requests, this is also inconsistent availability from the point of view of the CAP theorem.
If it answers you like this:

This is also a variable availability.
Integrity
The next item is integrity. From the point of view of integrity, you can say that there are so many different types of integrity in distributed systems:
There are about 50 of them. Which one of them is in the CAP theorem?
The CAP theorem is the most stringent type. Linearizability is called.
Integrity, linearizability. It sounds very simple, but underneath it has great consequences. If operation B started after operation A, then B should see the system at the end of A or in a newer state. That is, if A is completed, then the next operation cannot see what happened before A. It seems that everything is logical, there is nothing complicated. To reformulate this in other words: "There is a consistent history of sequential operations."
Now we will talk more about these stories.
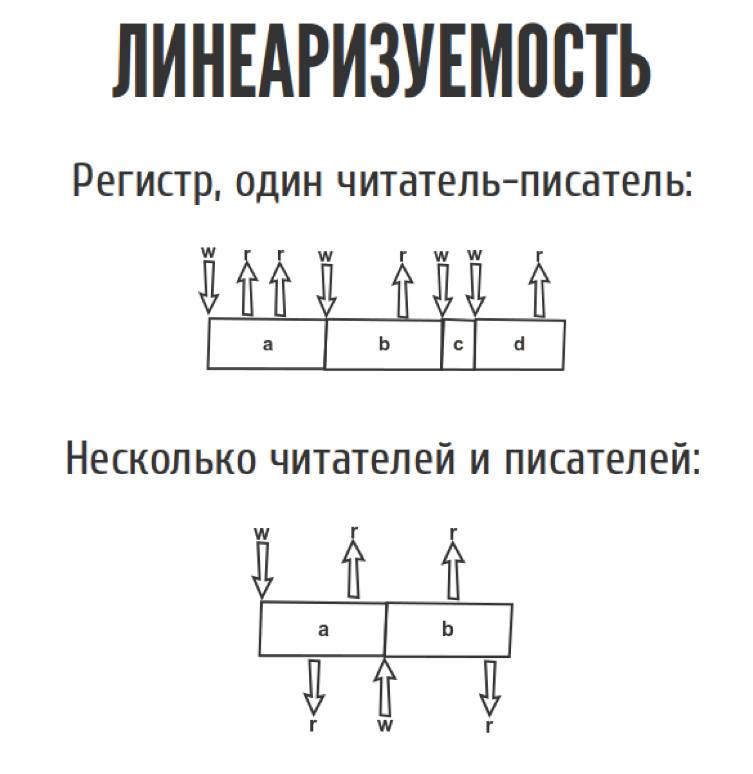
Представим, у нас есть какой-то регистр. Это то что мы можем прочитать, только то что мы до этого туда записали. Просто одна дырочка для переменной. У нас есть один читатель-писатель. Мы всё туда читаем-пишем, ничего сложного. Даже если у нас несколько читателей и писателей, тоже ничего сложного.
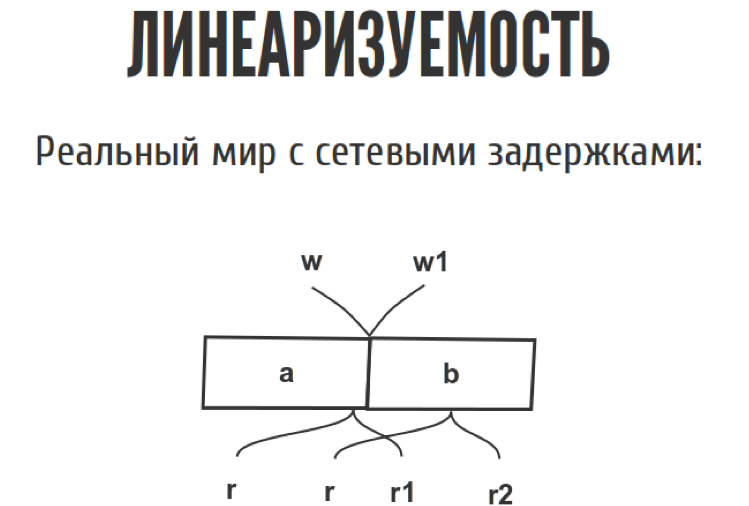
Но как только мы перемещаем из слайда в реальный мир, эта диаграмма выглядит немножко по-другому, потому что у нас появляются сетевые задержки. Мы точно не знаем, когда. Запись случилась между w и w1, где именно она случилась, мы не знаем. То же самое с чтениями. С точки зрения истории у нас, допустим, можно записать три таких простеньких истории.
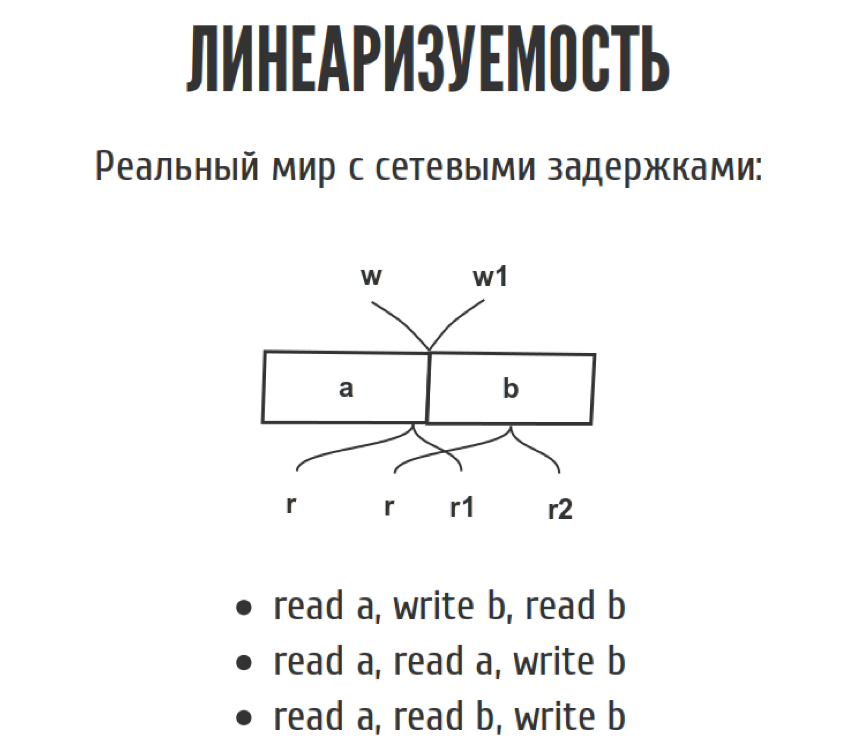
First we read a, then we wrote b, then we read b, clearly as in the picture. In principle, another story is possible, when we read a, we read a again, and then we wrote b, if we have everything as in the picture.
Third story. If we read a, and then suddenly read b, and then wrote b, it contradicts itself, because we read b before we wrote it. From the point of view of linearizability, such a story is not linearizable, but the CAP-theorem requires that there be at least one story that does not contradict itself. Then your system is linearizable. There may be several.
Sustainability
The last item is the letter P. Partition tolerance, in Russian it can be said that it is "resistance to network outages." It looks like this:

Imagine that you have several servers, and an excavator drove here early in the morning and cut the wires between them. You have two options if your cluster has fallen apart in half. The first way out: the bigger half lives, and the smaller one falls off. You have lost accessibility because the smaller one has fallen off. But the big one lives. But they did not lose their integrity. Either both halves work, we here and there we accept notes, we accept everything, everything is fine. Only then, when the wire is soldered, we will understand that we had one system, and there were two, and they live their own lives.
From the point of view of the CAP theorem, we have three possible approaches to the design of the system. These are CP / AP / AC systems depending on two combinations of the three.
There is a problem with AC systems. On the one hand, they guarantee that we have high availability and integrity. Everything is cool until we have a broken network. And since this often happens, in the real world AC-systems can be used, but only if you understand the compromises that you make when you use AC-systems.
There are two ways out in the real world. You can either shift in integrity and lose accessibility, or you can shift to accessibility, but lose integrity. There is no third.
In real life, there are many algorithms that implement various CP / AP / AC systems. Two-phase commit, Paxos, quorum and other rafts, Gossip and other heaps of algorithms.
We will now try to implement some of them and see what happens. You can say: "10 minutes have passed, our head has already exploded, and we just arrived." Therefore, we will try to do something in practice.
What we will do in practice
We will write a simple master-slave distributed system. For this we will take Scala, Docker, we will pack everything. We will have a master-slave distributed system, which with asynchronous / synchronous replication. Then we get Jepsen and show that in fact we wrote everything right or wrong. Let's try to explain the result after we start Jepsen. What is Jepsen? I’ll tell you a little later, probably many of you have heard about it, but you haven’t seen it with your eyes.
So, master-slave. In general, it looks like a basic thing. The client sends a write request to the master. The master writes to disk. The master synchronously or asynchronously scatters it all in slaves. It responds to the client synchronously or asynchronously, either before it is scattered as records, or after.
We will try to understand from the point of view of the CAP-theorem how things are with integrity, accessibility and others.
Let's try something up.
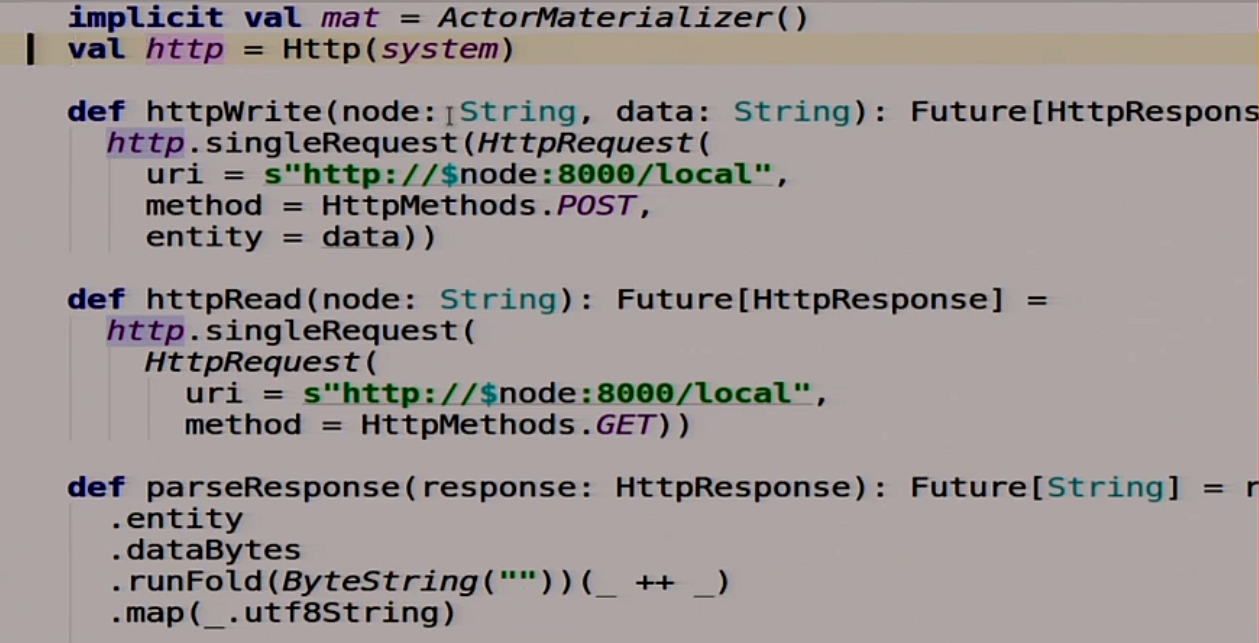
There is a small blank here, then I will write more under karaoke. We have two functions that will help us work with other servers. That is, we will use HTTP as the easiest way to communicate between nodes in a distributed system. Why not?
We have two functions. One writes this data to this node:

Another function that reads some data from this node and does it all asynchronously:

It is also a useful function that parses Response. Takes a Response, returns String:

Nothing complicated.
To begin with, we will write a simple server of our distributed system.
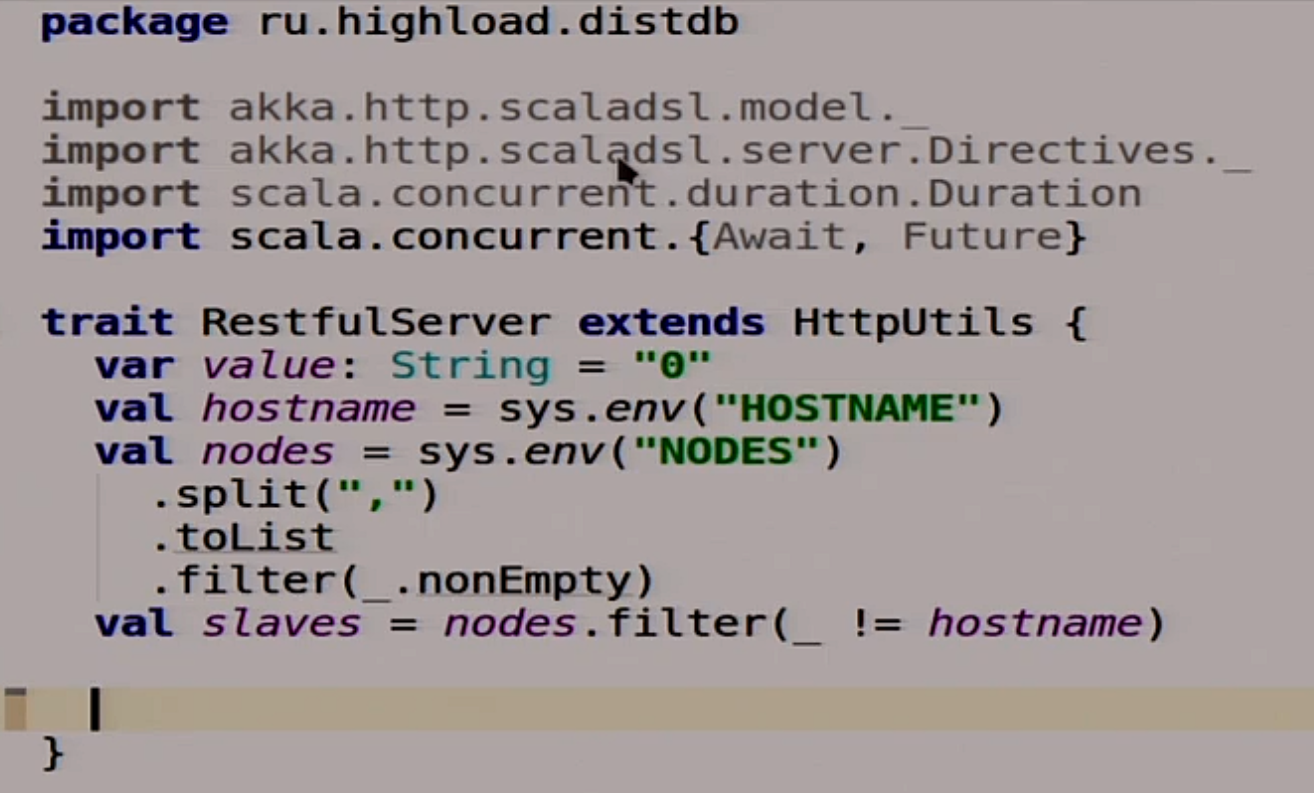
For starters, we have homework here. The data inside our system, we will store the entire stat in one variable, because we have a live demo here, and not a real database.

Therefore, we simply store the string, we will replicate it and so on. There are all sorts of useful jokes, such as reading from the variable environment HOSTNAME, NODES neighboring ones and so on.

We will write plugs for two functions here.

Reading from our distributed system and writing from our distributed system. We, of course, will not implement them now, but will move on.
Here we launch our balalaika:

Everything is very simple. We have a route function that has not yet been implemented, but it does something. It describes the rest route that we will use.

We are pulling all this on the 8000th port:

What routes will we have? We will have two routes. The first is db.
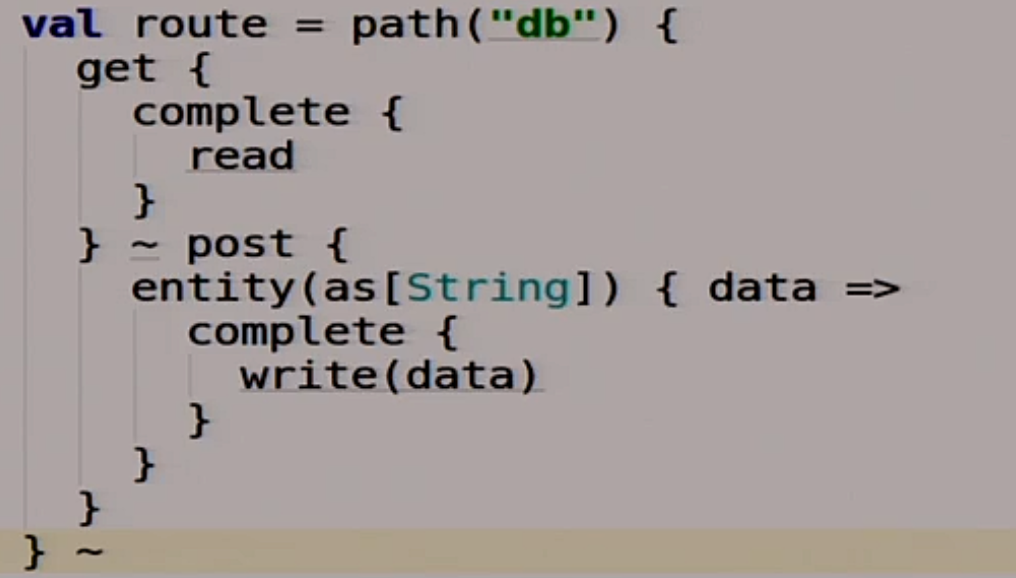
This route is for us, for database clients. We are working with him, and she is doing something under the hood.
If we get there, then we call our magic function read, which we have not yet implemented.

If we post some data there, then we call our write function. It seems nothing complicated.
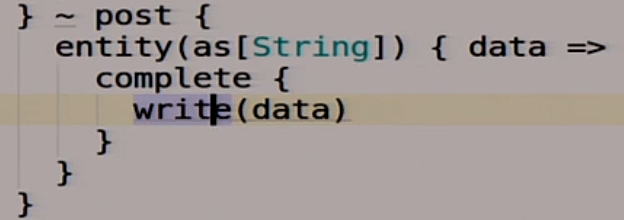
In addition to this, we will have another route called local.
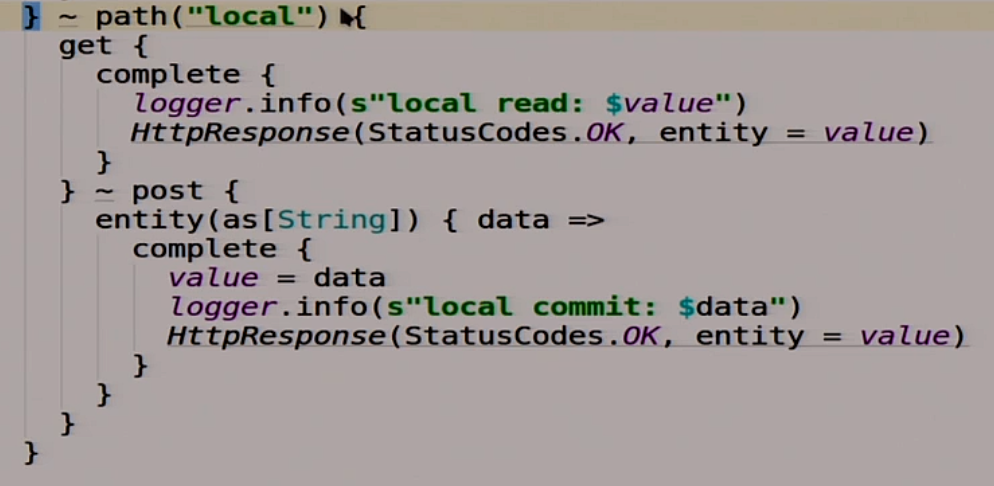
It is not made for us, but so that the members of a distributed system, different nodes can communicate with each other. One from the other could read what was written there.
If we get there, then we read our magic variable value.

If we do a post there, then we are writing to this variable what we posted there.

Nothing complicated. A little brain explodes from Scala, probably, but that's okay.
We kind of wrote our server. It remains to make logic for our MasterSlave. We will now make a separate class that MasterSlave will implement. Reading from an asynchronous MasterSlave, in fact, is just a local reading of what we have written to our variable there.

Recording is a bit more complicated.

We write to ourselves first.

Then we go over all the slaves that we have and write to all the slaves.

But this function has a feature, it returns Future.

Here we blur out asynchronously all write requests to slaves, and we say to the client: “Everything is OK, we recorded, we can go further.” Typical asynchronous replication, possibly with pitfalls, now we'll see it all.
Now we will try to compile all this. This is Scala, she does it for a long time. Generally should compile, I rehearsed. Compiled.
What to do next
We wrote, but we need to run it all, and I have one laptop. But we are making a distributed system. A distributed system with a single node is not a completely distributed system. Therefore, we will use Docker.

Docker is a system for containerizing applications, everyone has probably heard about it. Not all were probably used in production. We will try to use it. This is a light virtualization system, to simplify everything. Docker has a rich ecosystem around, we will not use all of this ecosystem. But since we need to run not just one container, but a group at once, we will use Docker Compose to roll them all at once.
We have a simple Dockerfile, but it's not quite simple.
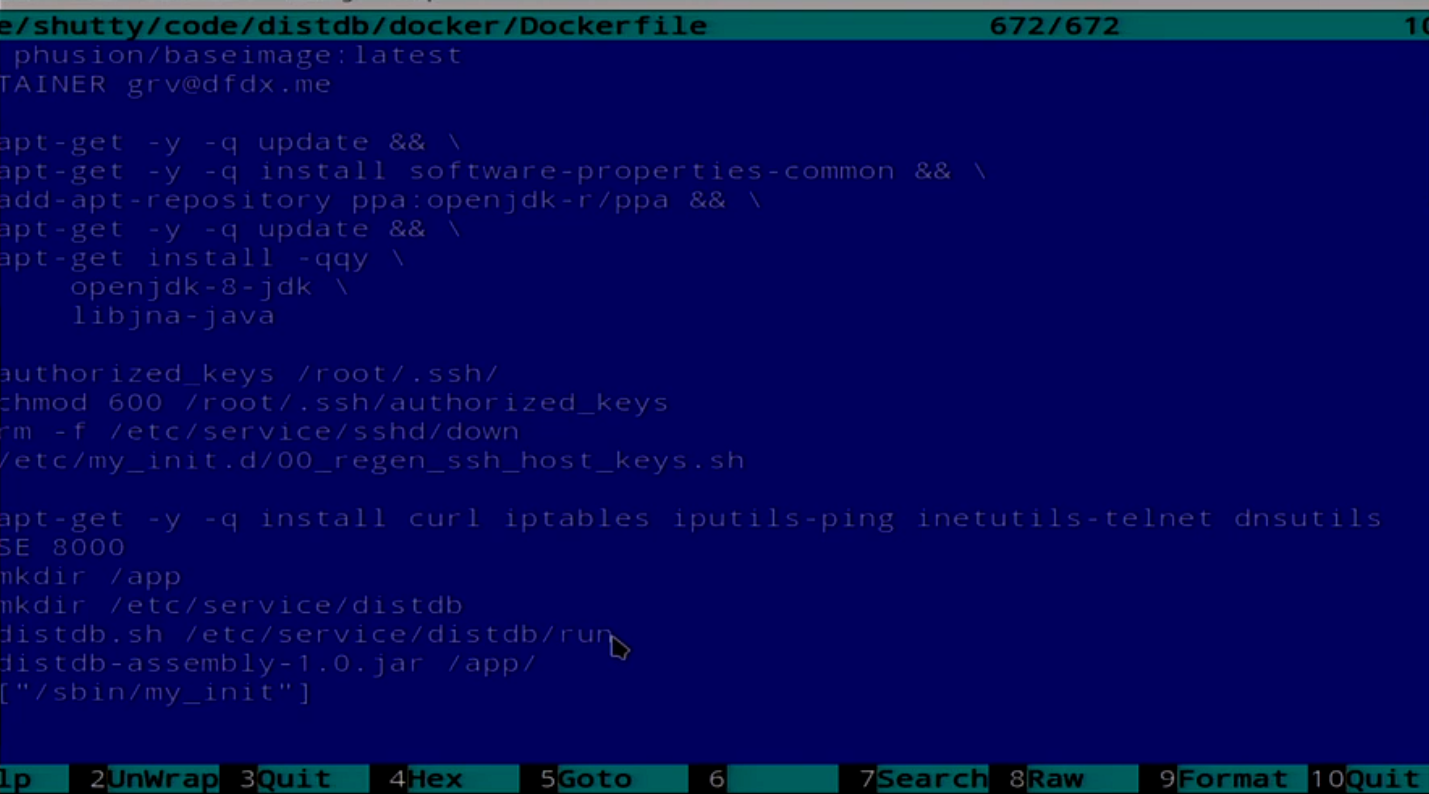
Then the Dockerfile, which installs Java, pushes SSH there. Do not ask why you need it. Our application launches it all.
And we have a Compose file that describes all 5 nodes.
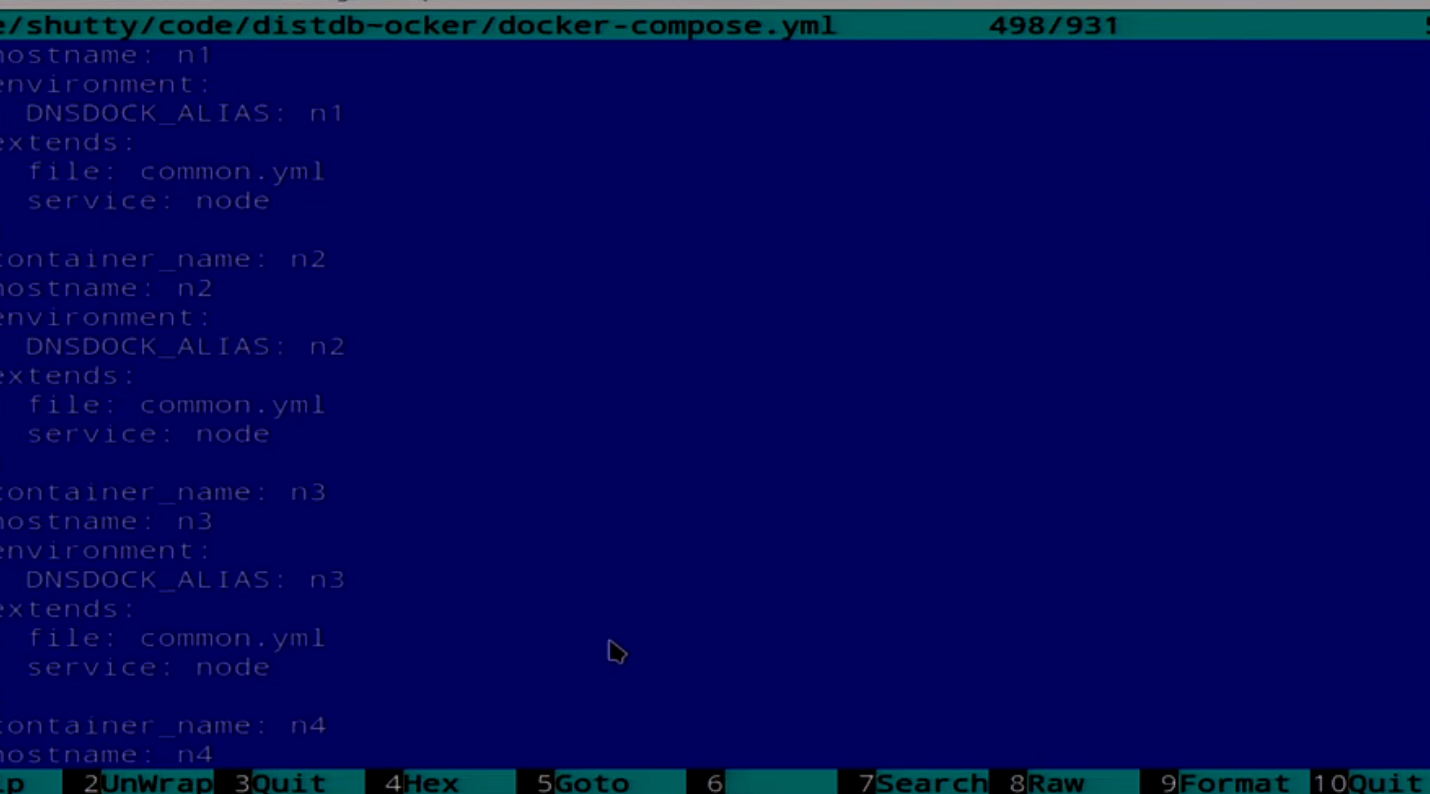
Here we have a description of several nodes. We’ll try to consolidate it now. I have a script for this.

While it is deployed, I will change colors.
Now it is creating a docker container. Now it will launch it. All our 5 nodes started up.

Now we wait until our distributed system knocks that it is alive. It takes some time, it's Java. Our MasterSlave said it started up.

In addition to this, in all we have unpretentious scripts that will allow us to read something from this distributed system.
Let's see what we have in the node n1.
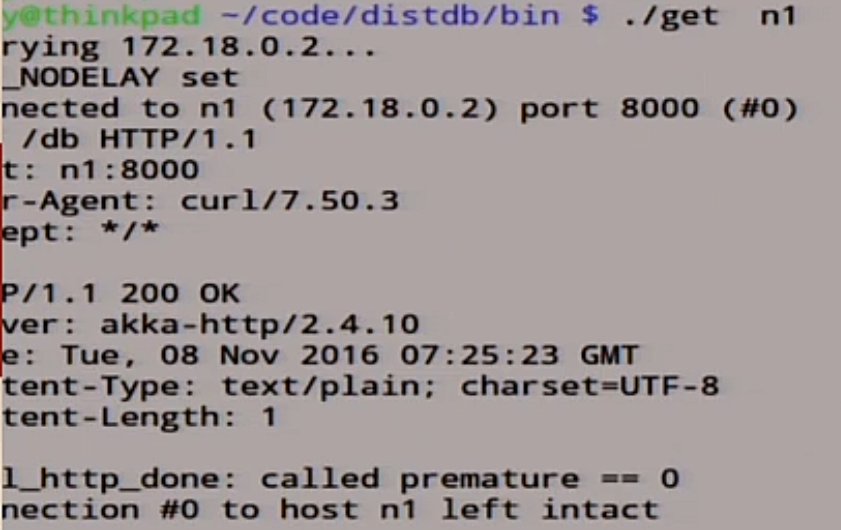
It says 0.
Since there was no protection from who is master, who is slave, we will take it on faith that n1 is always master. We will only always write in it in order to simplify everything.
Let's try to write something in this master.
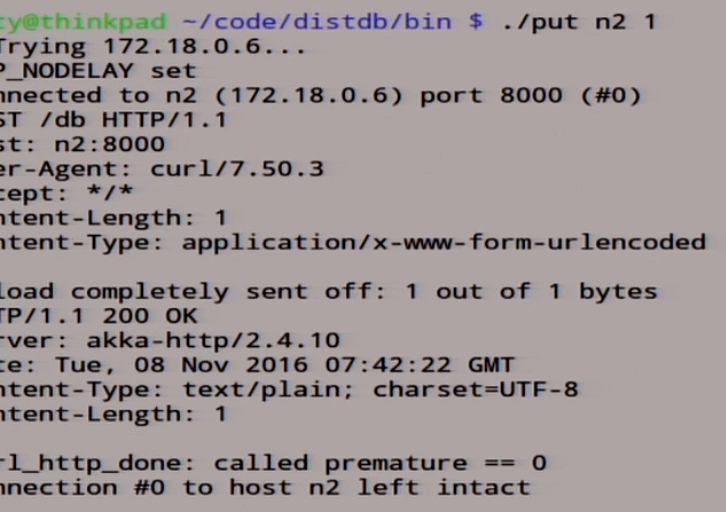
put n1 1 The
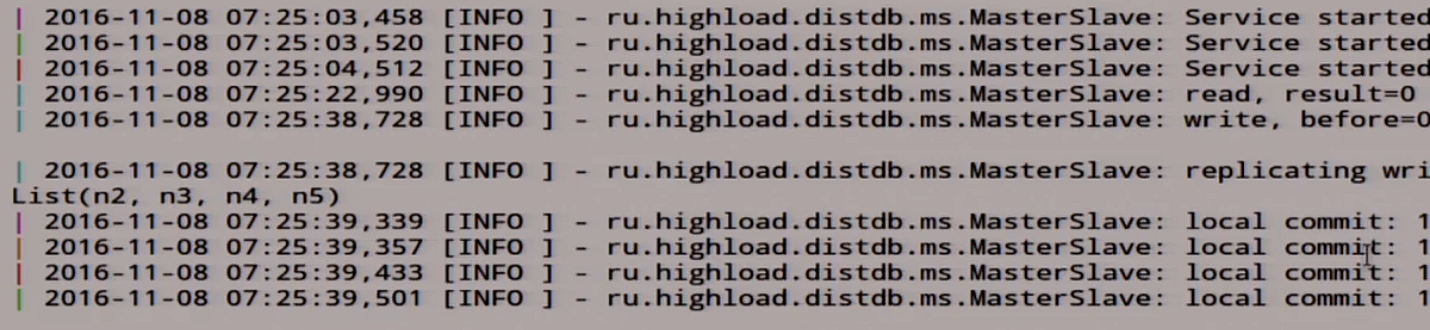
unit was written there. Let's see what we have here in the logs.
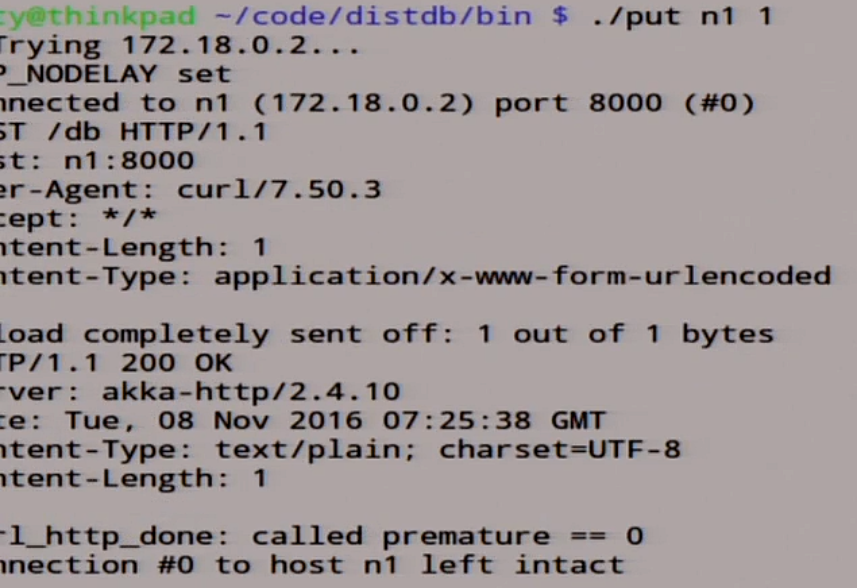
Here we have our unity here in the record, we rolled out this record for all slaves, here it was recorded.
We can even go to node n3, see what is there.
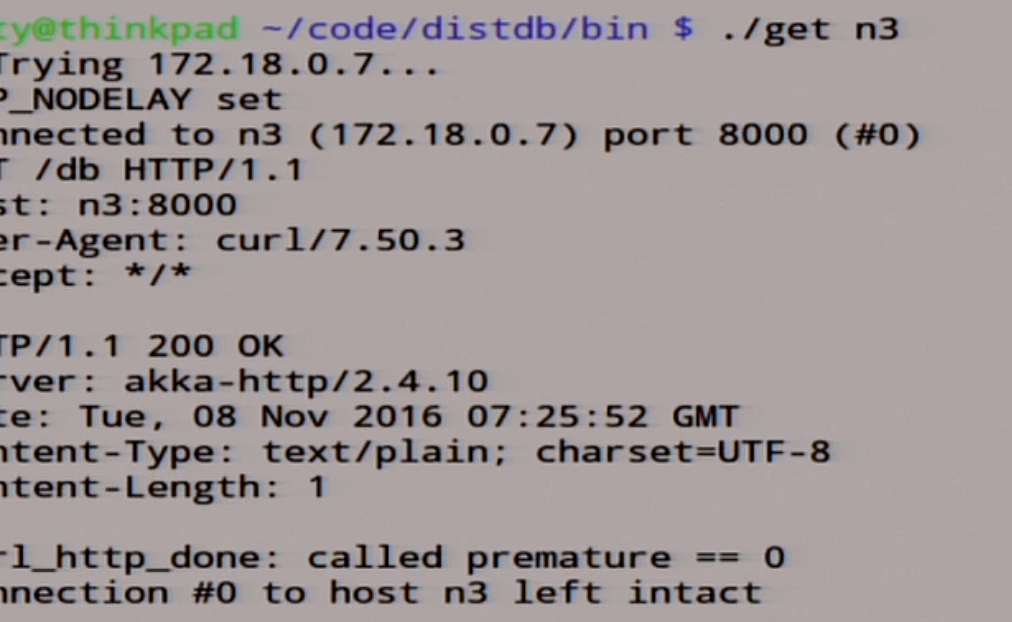
There is a single written down.
We can go for a bonus, we wrote our distributed system on the knee, which even works. But it works, so far so good.
Now we will try to make her ill. In order to make her feel bad, we will take such a framework called Jepsen. Jepsen is the first framework for testing distributed systems, with one subtlety: it is written in Clojure. Clojure is a lisp who doesn't know. This is a set of ready-made tests for existing databases, queues, and more. You can always write your own. In addition, there is a bunch of articles about the problems found, probably in all databases except exotic. Perhaps only ZooKeeper and RethinkDB did not get it. They got it, but a little bit compared to the rest. You can read about it.
How Jepsen Works
It simulates network errors, then generates random operations on your distributed system. Then he looks at how these operations were applied to your distributed system and to the reference behavior, to the model of this distributed system, and whether there are problems with this.
If Jepsen found such a problem with you:
I just wanted to joke here.
If Jepsen found some kind of problem with you, then he found counterexamples for your distributed system, and there really is some kind of cant. But since Jepsen tests are probabilistic in nature, if he did not find anything, he might not have been looking well enough. But if he searches well, he will find something. In the case of, for example, RethinkDB, they ran tests for about two weeks before the release, to prove that more or less somehow it worked.
We’ll not run tests here for two weeks, we’ll take five seconds. Our task with the Jepsen test is to write to master, read from MasterSlave and understand how things are with integrity and whether we wrote our master / slave replication correctly or maybe not.
The Jepsen test consists of several important parts.
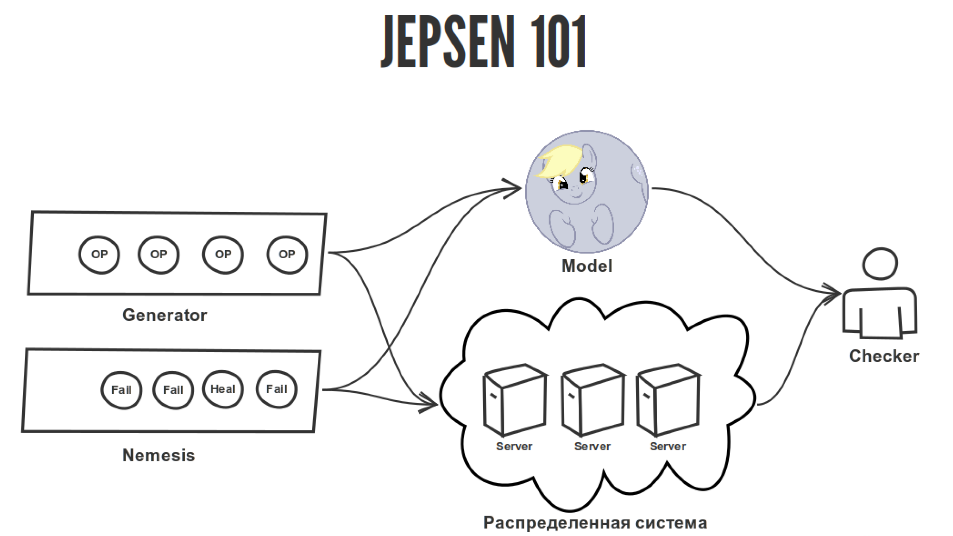
We have a generator that generates random operations that we apply to our distributed system. The distributed system itself, which we launched somewhere there. It can be in Docker, it can be on real iron servers, why not. And we have a reference model that describes the behavior of a distributed system. In our case, this is a register, what we wrote there, we must read this. There is nothing complicated. Jepsen has a huge number of models for all occasions, but we will use only the register and Checker, which checks the correspondence of the history of the operation applied to the distributed system for their correspondence to the model.
The problem is that Jepsen is written in Clojure, and tests need to be written in Clojure too. If it were possible to write them on something else, it would be cool. But trouble, trouble. Clojure is a language where there is always a list. If, for example, you want to add two numbers, then you make a list in which the first element is addition, and then two numbers, in the end you get three.
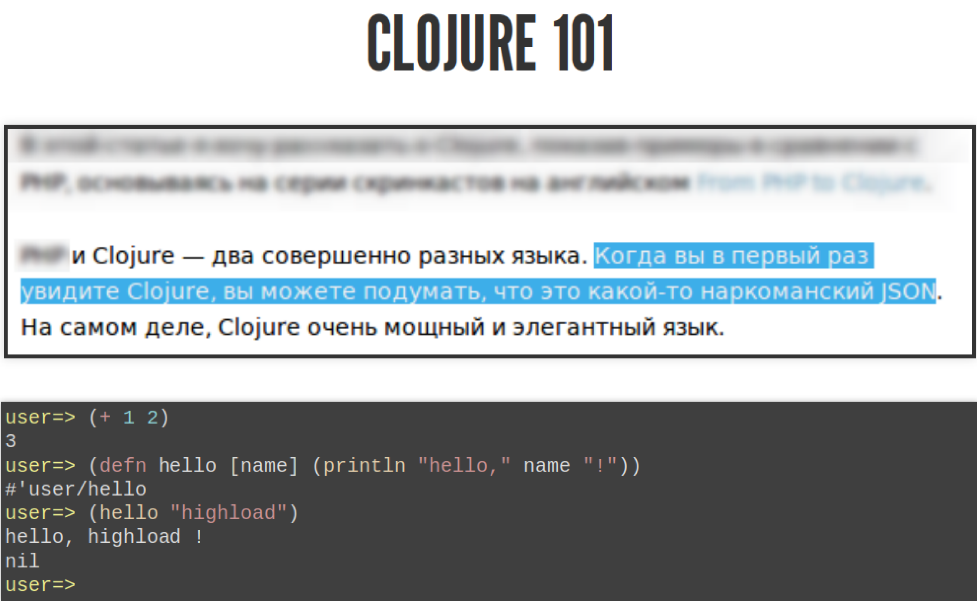
You can set your call function to another function called defn and say that the first argument is the name of the function, then the argument is the function, then the body of the function. If you call her this way, she will say “hello, highload!”. This is such a Clojure course for beginners.
You can say that this Clojure course looks like this:

And now it will surely be what’s on the right. In fact, yes. But I told you, it’s enough for you to at least roughly understand what will take place on frames now, because Clojure is a little specific.
So, Jepsen. First, we will describe our test.

This footcloth is not correct to read from left to right, from top to bottom, because it is a lisp, it is better to read from the inside and out. We have some kind of function that returns a description of our test, which we have not yet implemented. We put this description in another function that runs this test, and it returns a directory. In this directory, we pick out something using the results key and see if there is a key in this directory called valid. If it is there, then the test is passed. Clojure reads like this. First you need to break the brain, but then everything becomes clear.
Now we will describe our test.
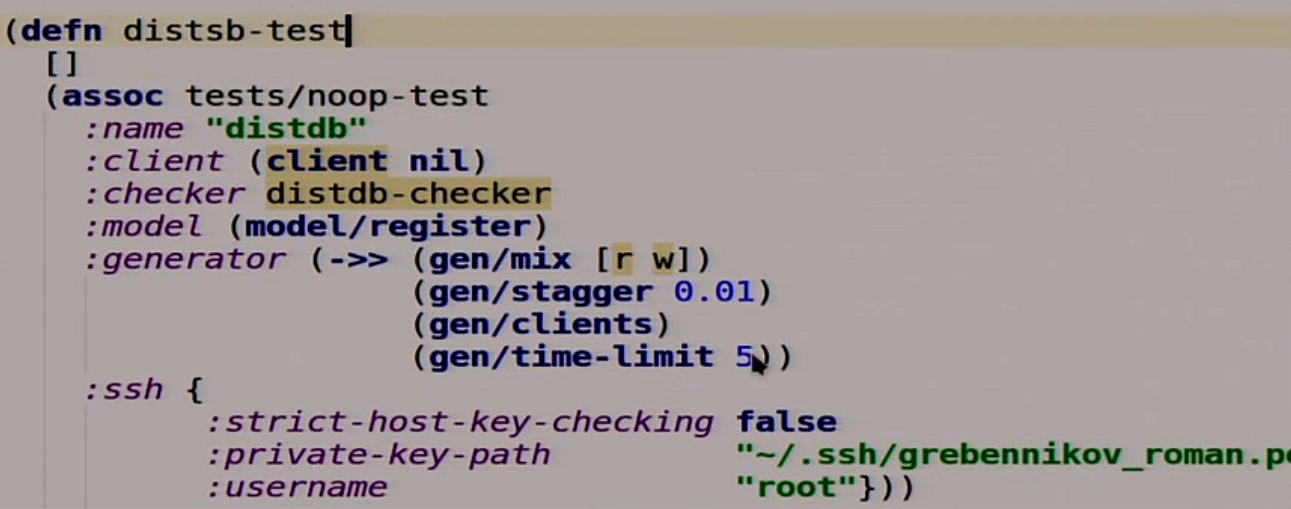
Our test is also a function in which there are no arguments. She extends another test, which does nothing at all, and adds some things to it. For example, the name, the client, which he will use to communicate with our database, because Jepsen does not know about anything, about any HTTP. Checker, which we have not written yet, but will write. The model that we will use as the standard of our distributed system. The generator, which takes random read and write operations, inserts a 10 millisecond delay between them, starts them with the client and starts it all for 5 seconds. Further there for work with SSH.
Now we will describe our reading and writing. These are also functions. This is Clojure, there are all the functions, there is nothing else.
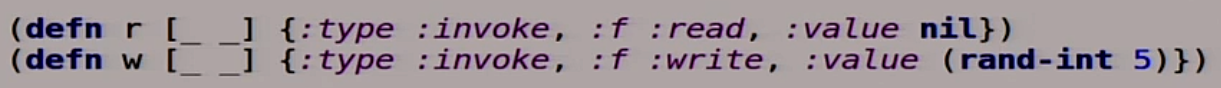
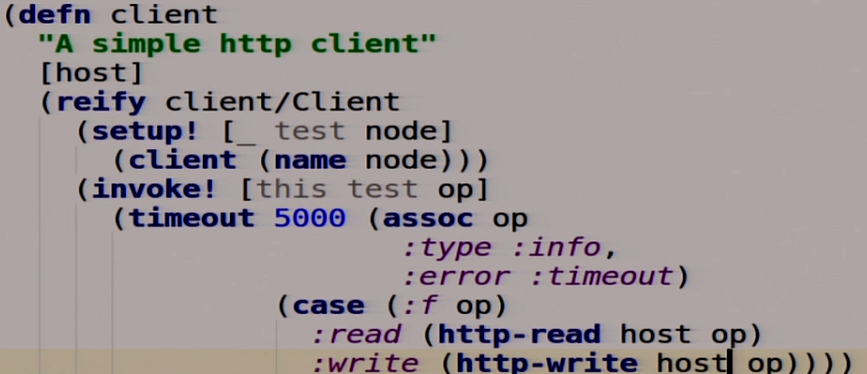
We will also describe our client, but first an HTTP client.

Here we have several functions for writing to HTTP, for reading in HTTP. We will not go into how this is all done. But in fact, if 200 returned to us, then everything is OK. If 409 is HTTP 409 Conflict, a very useful code, then something is wrong. We will use it a little further.
Further we will describe our client.
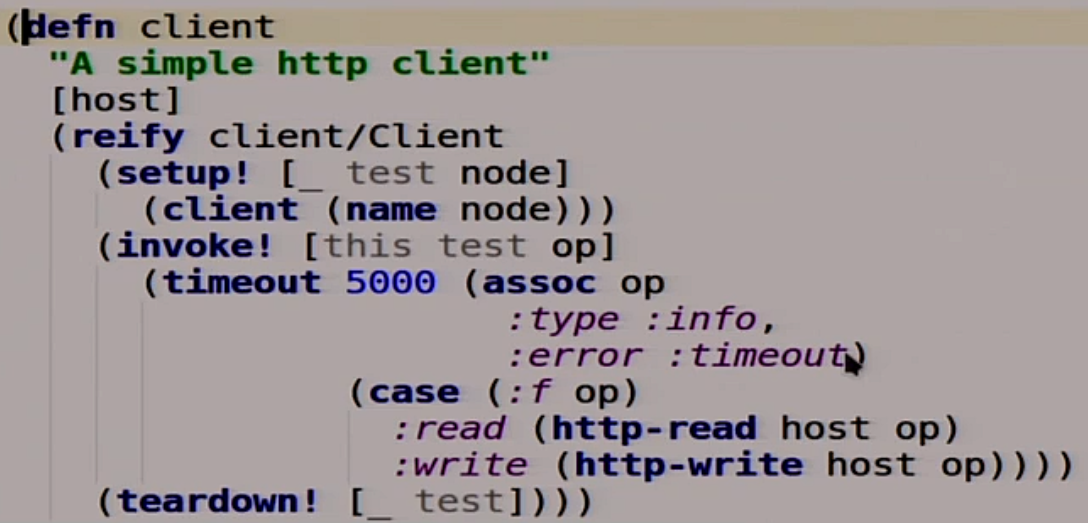
Also a function that takes the host, which we will write now, and extends the interface called client. It has three functions. Setup which returns itself. Teardown which does not need to remove the client, there is nothing inside. invoke which applies our operation that we transfer there to this host. We have a five-second timeout here, that is, if in 5 seconds our distributed system did not work, then we can say that it does not work. If we have this reading, we perform HTTP-read, make a GET request. If the record, then we do HTTP-write, that is, a POST request. Since we have MasterSlave and we have only one Master, we will change a little here, we write all the time in Master.

The last item that we have left is Checker. One could use that inside Jepsen called linearizability checker, but we will not use it because I stepped on it.
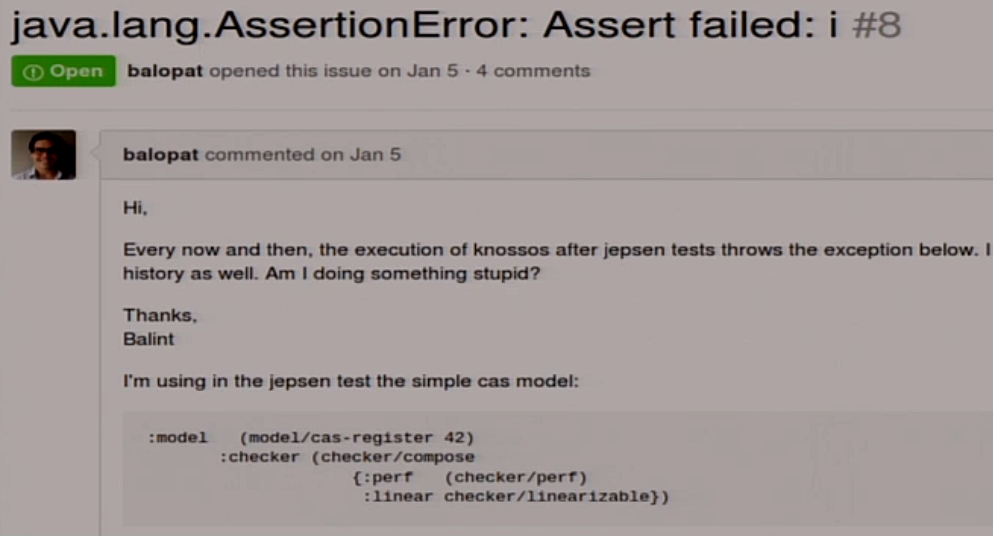
I don’t know what to do with it. Therefore, I wrote my own, which does not fall. In fact, he uses the same thing, but does not try to generate a beautiful picture in the end, where he usually falls.
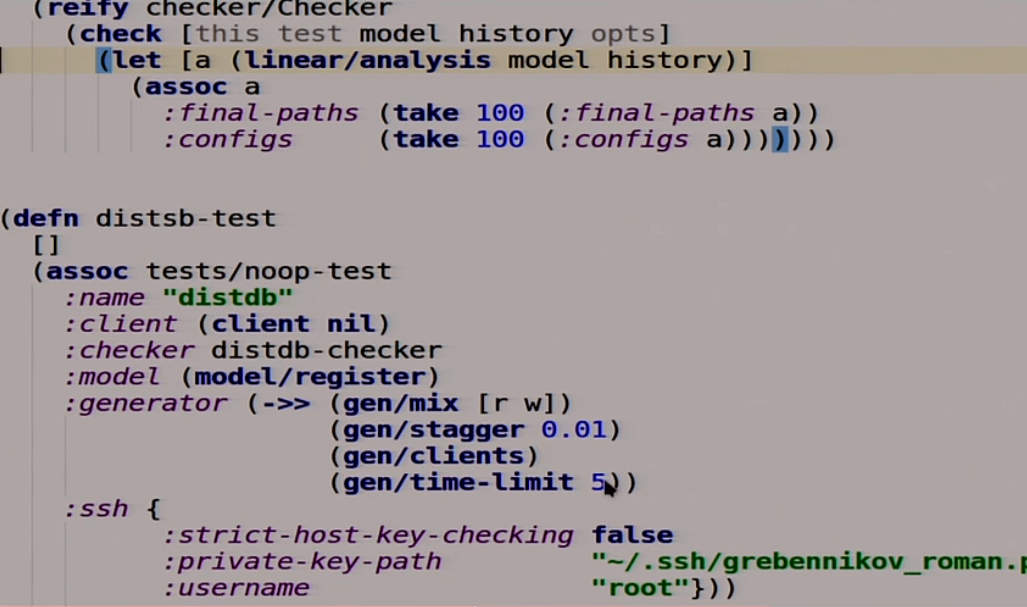
We wrote our mega test, let's try to run it.

We have our distributed system, the test, we are waiting for it to start.
lein is such a build system for Clojure.
It began to write different hosts, different read / write, in the logs the magic also happens - read / write, replication. At the end, it tells us “fail”. You forgot something here. There is a list of stories that is not linearizable, and something is clearly confused here.
Let's look at this situation:
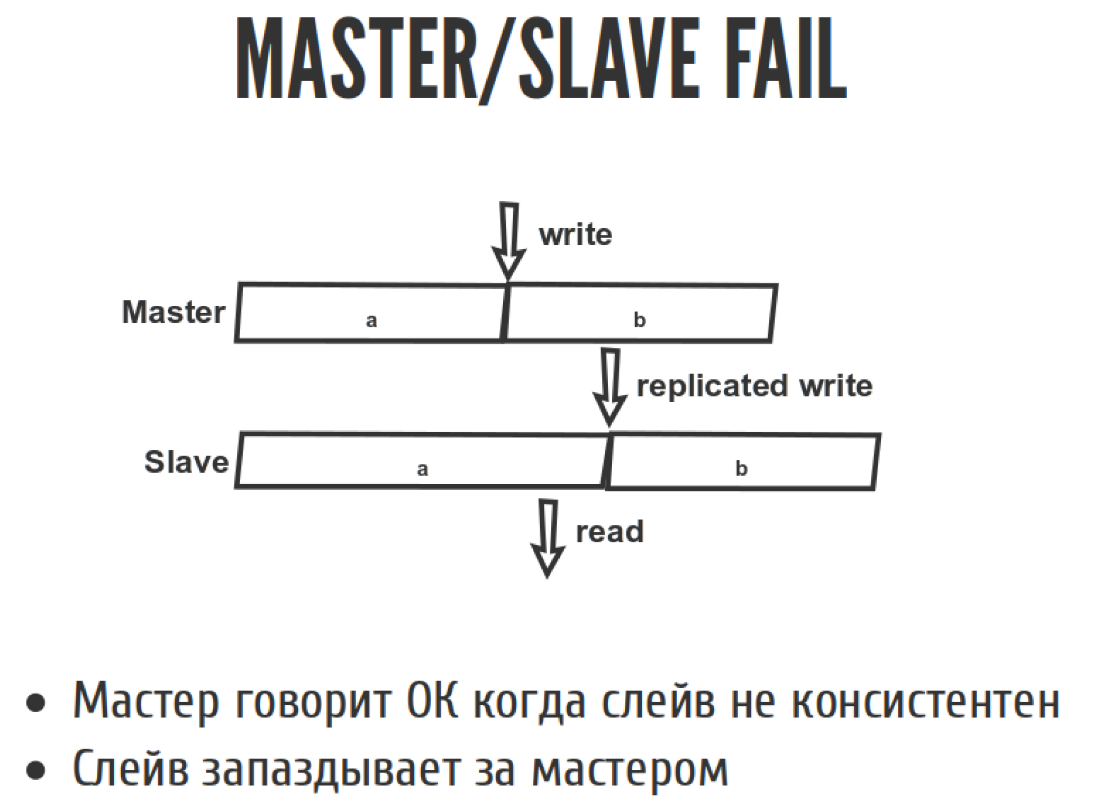
Everyone knows that if we do asynchronous replication in Master / slave, then slave always lags behind. What does slave delay mean in terms of linearizability? This means that a recording happened here, after some time the recording was replicated, and reading happened here. As a result, we read what we should not have read. We had to read B, and read A. That is, we went back in time when the operation seemed to be already over, and we went back and read what was from it. Because Master during asynchronous replication says “ok” too early, because not all slaves have yet caught up with the replication flow. Therefore, slave always lags behind master.
You will certainly say that this is a kindergarten, let's do everything in an adult way. Let's write synchronous replication, we are smart. It will be almost the same as asynchronous, only synchronous.
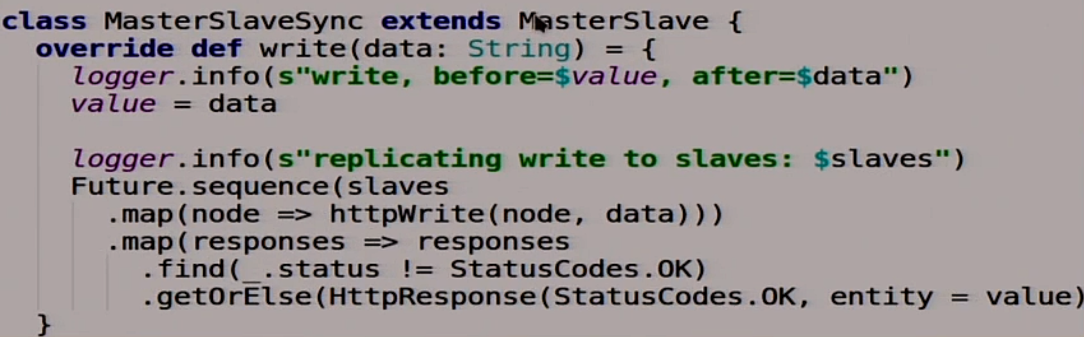
We will redefine one function that writes to our distributed system. She now does it in a smart way: she waits for the moment when all the slaves say "ok." Only then she says that well, everything was recorded. If one of the slaves said that it wasn’t “ok,” then it means we got into trouble and we don’t go there.
Now try to run all this balalaika. You probably feel that now there will be some kind of setup, everything cannot be so good. 25 minutes passed, and then the man downloaded everything and it worked, so we will now wait until it compiles. Now it collects everything, it’s not dynamically languages for you, when everything works right away, everything is long and painful here. There is time to think whether you wrote, or wrote, to rewrite everything until it is deployed.
Master / slave sync started up, great. Let us now run the Jepsen test again in the hope that everything will be fine. We did synchronous replication, what could go wrong. It starts, began to write, but not so fast. He writes again, reads again, something is happening there. As a result, something bad is happening again.
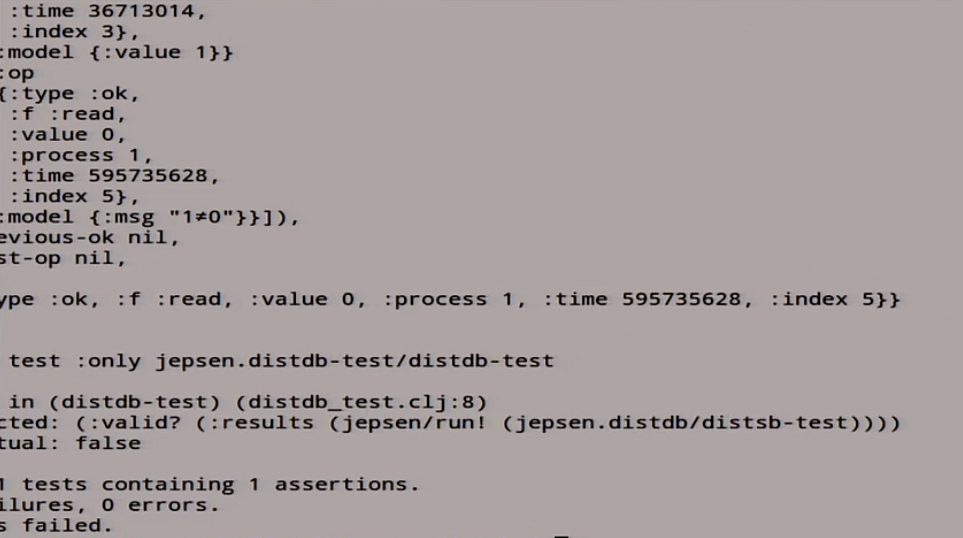
We again failed: it gave us a huge number of stories that are not linearizable in terms of linearizability.
What is the problem?
We thought we did everything right. Somehow everything turned out badly.

The picture shows that everything was even worse than it was.
Imagine this situation.
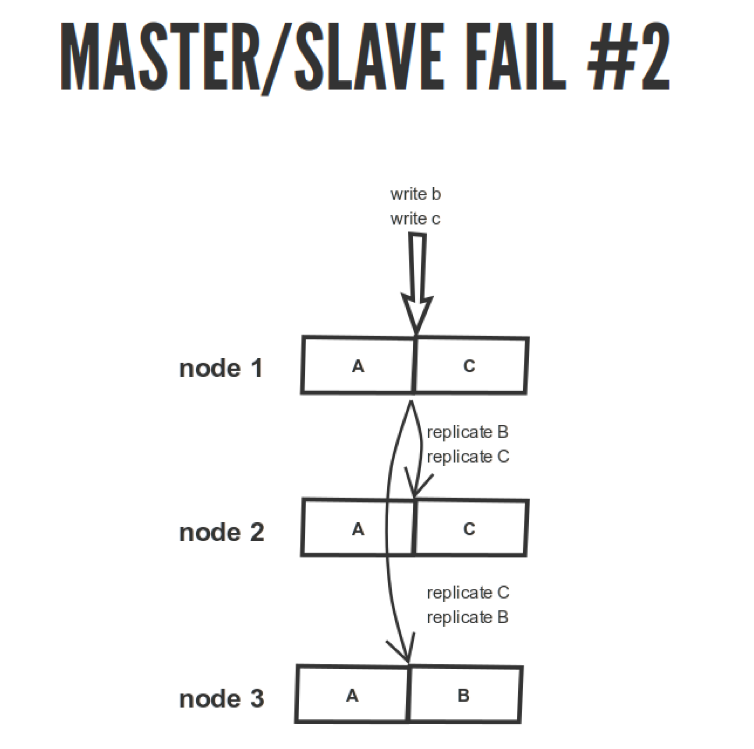
We have our master node 1. We recorded operations B and C there. We have C here, we replicated here. We do everything via HTTP asynchronously, which may go wrong. In note 2, they signed up in that sequence. But on node 3, they messed up, but we accidentally sent them. We forgot that there are magazines and other things. They did not apply in the order in which they were to be applied. As a result, instead of C we got B, and here we read it is not clear what. Either B, or C, although they should read C. Therefore, this is such a disaster.
From the point of view of the master / slave CAP theorem and integrity, replication depends on whether synchronous replication or not. If it is asynchronous, then it is clear that there is no linearizability, because slaves are late. From the point of view of synchronization, it depends on how much you are crooked and correctly implement everything. If you're lucky, good. If the same as me, then bad. From the point of view of accessibility, the problem is that with us slave cannot write, it can only read. In terms of high availability, we cannot fulfill all the requests that come to us. We can only do reading. Therefore, we are not available.
Therefore, the CAP theorem is a very specific thing.It is necessary to apply it to databases very carefully, because its definitions are strict, they do not always describe what is in real databases. Because it describes 1 register. If you can reduce all your transactions and so on to operations on one register, then this is good. But usually this is difficult or even impossible. Availability it is such accessibility, but latency says nothing. If your distributed system is awesomely consistent, but answers the request once a day, then this is also very difficult to use in production. There are a bunch of different practical aspects that are not considered in the CAP theorem. The same loss of partitions packets, that is, if we have a network partition that is unstable, and a variable, several packets are lost every 5 seconds.
Therefore, according to personal experience, when people begin to write distributed systems with a fragile mind, sooner or later their knowledge crystallizes, all crutches fill up new bumps, and it looks something like a curve-slanting consensus algorithm. When all your nodes try to agree on a general state, but this algorithm is not very tested in extreme cases, they are rare, why worry about it. But consensus in the general case is an agreement on the general condition with the possibility of somehow surviving the failures if they happened.
Such an example:
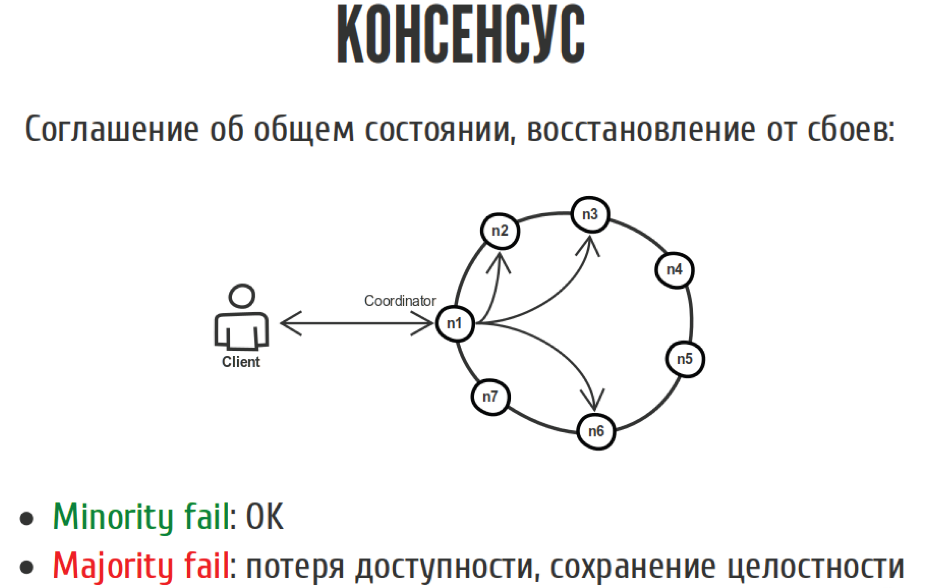
We have a client who writes to our distributed system, in which there are seven nodes. We are voting here. If most nodes agreed that we should write it all down, then everything seems to be fine. The same thing with reading. If we have a minority of nodes fell off, 1-2-3, then that's okay. We have not lost accessibility or integrity, because everything is fine. If the majority fell off, then we lost accessibility, because we can no longer record, but have not yet lost integrity.
Let's do a live demo on the knee.
We will try to make a quorum. Let's try to get Jepsen again and try to explain what we get.
Everything will be a little more complicated here, because we are kind of already smart. First, we will make a function that will describe the size of the quorum.

For three nodes, these are two, for five nodes, three, etc. Just a banal majority.
Next, we describe our magic read and write functions.

If we read from our distributed system with a quorum, then we ask all the nodes for HTTP what you have there:

Then we call our function, which will work with the quorum, which we will write now:

In the end, we say what we have in the end it should turn out:

About the same with the record. We write to all the nodes, see what is written: A

quorum has been gathered at our place or not:

Next, we form some kind of response to the user:

How will we live with the quorum?

This is a little Scala, more canonical. Here we have a sequence of answers that have arrived to us from different servers, from different nodes of our distributed system. This is almost just a sequence of lines that we will read, for example, 0000.

We group them by ourselves:

We look at how often which groups meet:

Sort by popularity:

We take the most popular answer:

It seems like everything is right.
Next is the function that forms the answer:
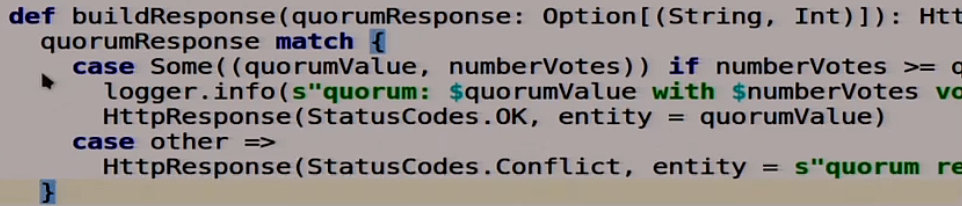
It is also very canonical on Scala, it is not entirely clear what is happening.
We take a couple: the most popular answer and the number of votes:

And look, if the number of votes is more than our quorum or equal to this quorum, then everything is ok, we wrote down. We say that it’s normal, the recording was successful, the quorum has gathered.

What could go wrong?
If something is not right, then we say our magic HTTP 409 Conflict:

Now we will try to screw it all:
And re-fix.
We will now try again our magic scripts that do. Let's see what we have in node n2.

Now it is sinking, such a meditative process. Almost. We are waiting for her to tap. Knocked out.
Let's see what we have in node n2.
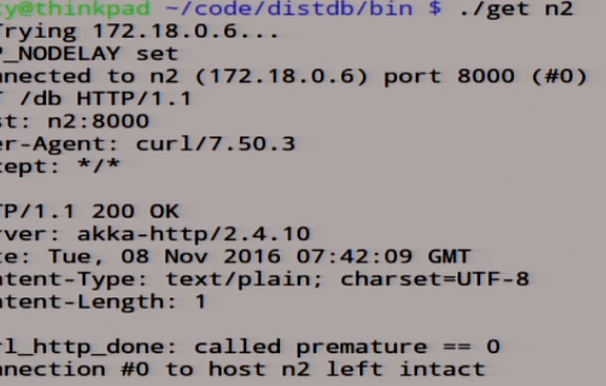
There lies 0. We look at what happened here:
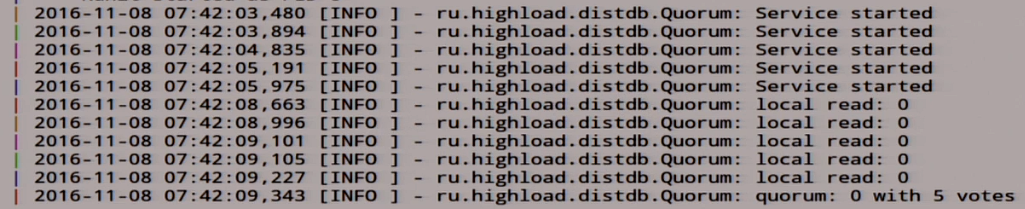
Local read, we read 0 with five votes, generally cool. A true distributed system.
Let's write something
down there : We wrote a little one there. She signed up:

We have rolled out this unit on other nodes. We have a quorum here, one with five votes. It seems like everything is fine.
Back to our Jepsen. Because we have a quorum, and a quorum can have many masters. In general, there is no such thing as a quorum.
Here we remove our crutch in the client:
And we will try to restart it all and see what will happen to our quorum when we run our integrity test again. If you abuse the code, then with all the force.
It began to write, a lot of things are happening here.
In the end, it told us true:
It seems like everything is fine. But I told you about this, that Jepsen is such a probabilistic nature of the tests. Therefore, we will turn on 15 instead of 5 seconds here:

And for reliability, we will run this test again. In the hope that he might bring something else to us, the catching of bugs is probabilistic. A very interesting and relaxing process. Let's hope that on the second attempt, it will find something for us. Now we are driving her longer, 15 seconds, in the hope that our quorum will grunt somewhere. Almost. Everyone is looking forward to what he will tell us. It told us fail:
What did we expect. What happened to fail here?
Let's look at these two functions abnormally:
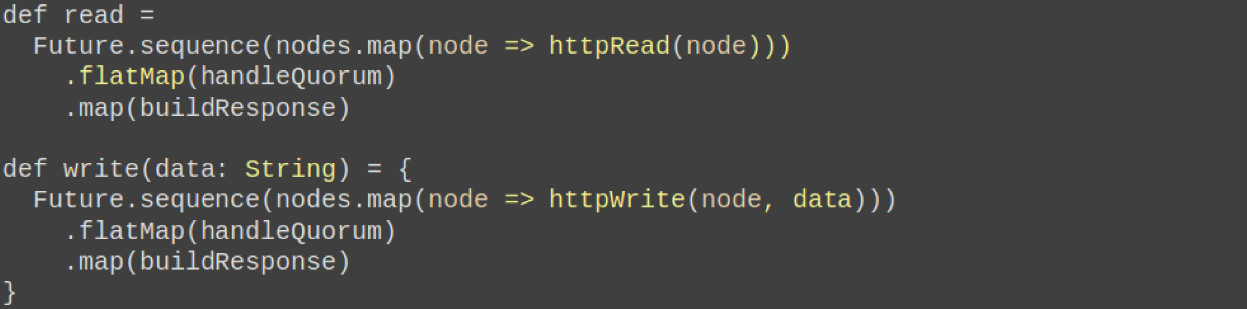
Something is wrong here. Firstly, because it is Scala, there can always be something wrong there. Secondly, there is some kind of problem in the logic.
Let's look at this sequence of records:
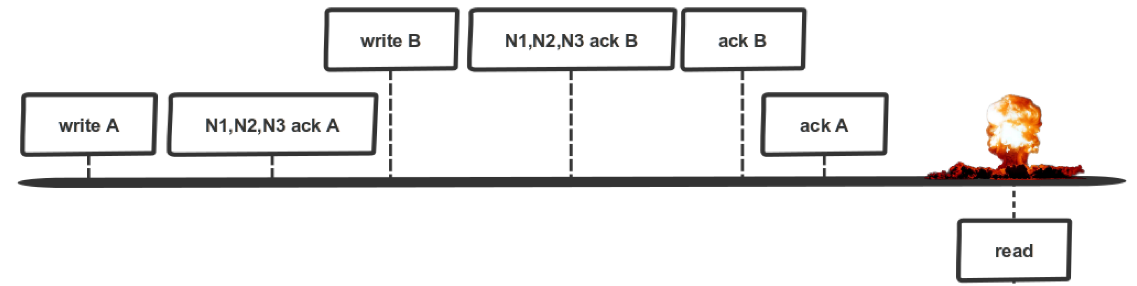
We have two clients. Here we recorded operation A, then the nodes said “ok”, we wrote down, we got a quorum here. But until we told the client that we recorded A, here a faster client ran, who managed to record B, the nodes told him that the quorum came together, and we also managed to say that everything was fine. We told this client that we recorded B, to this we said that we recorded A. Then we read something, what did we read here?
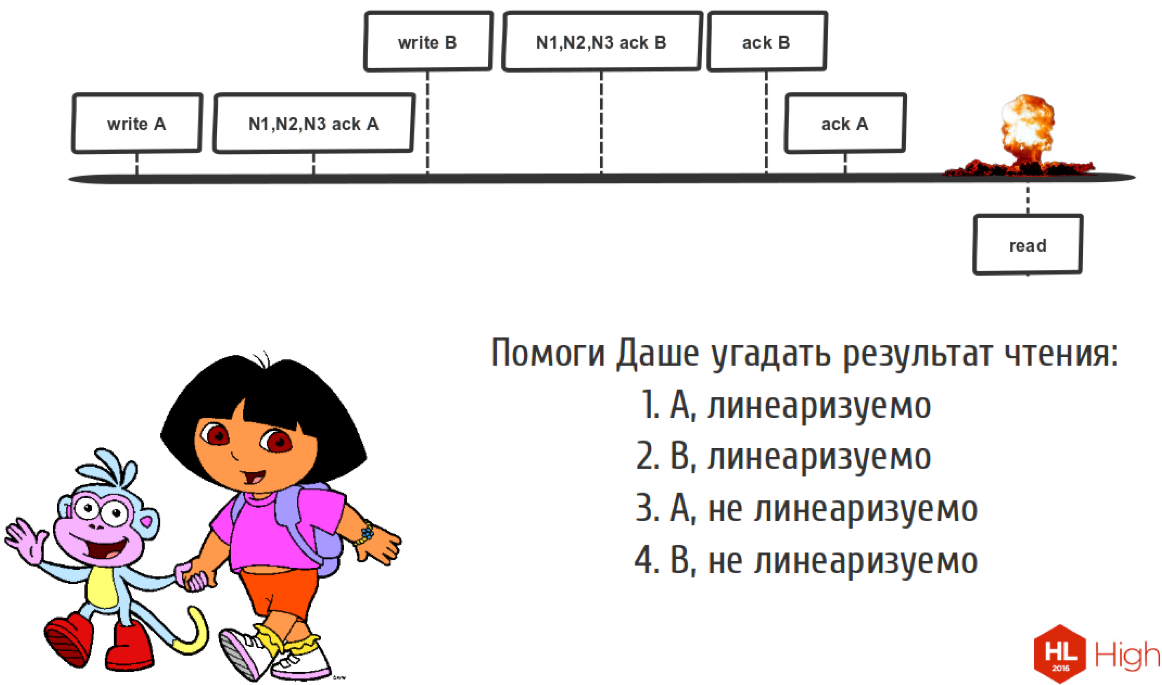
Since time is short, I will suggest that we read B here, and this is all non-linearizable. Because we had to read A, because there should not be such a situation. Because we must resolve conflicts in our system.
To avoid this, you do not need to reinvent the wheel and write a quorum yourself, unless you are the author of the RAFT or PAXOS algorithm. This algorithm helps us all to make normal distributed systems.
The PAXOS & RAFT quorum algorithms describe a state machine, and your state machine goes between states. All these transitions are logged.
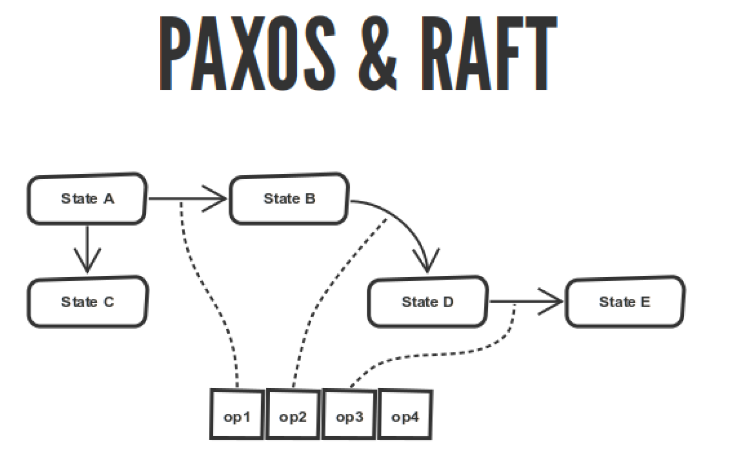
These algorithms describe the order of operations agreement in this log. They describe the choice of the wizard, the application of the operation, how to sort this journal according to your nodes. But if you have the same journal on all nodes, then your finite state machine, executing this journal from beginning to end, will come to the same state on all nodes. It seems so good.
The problem is that PAXOS is quite complex. It is written by a mathematician for mathematicians. If you try to implement it, you will have another variation of the PAXOS implementation, of which there are a lot, it's even scary to think how many. It is not really for people, it is not broken into phases. This is just a huge footcloth describing mathematical constructions. You have to think a lot. All these variations of PAXOS and the PAXOS implementation are about how to think of what is written in this paper, towards the real implementation that can be used in production.
To prevent this, there is such an RAFT algorithm. It is newer, all problems are taken into account there, all those steps that need to be taken to implement a good consensus algorithm are described there. Everything is cool there. There are a huge number of different implementations:
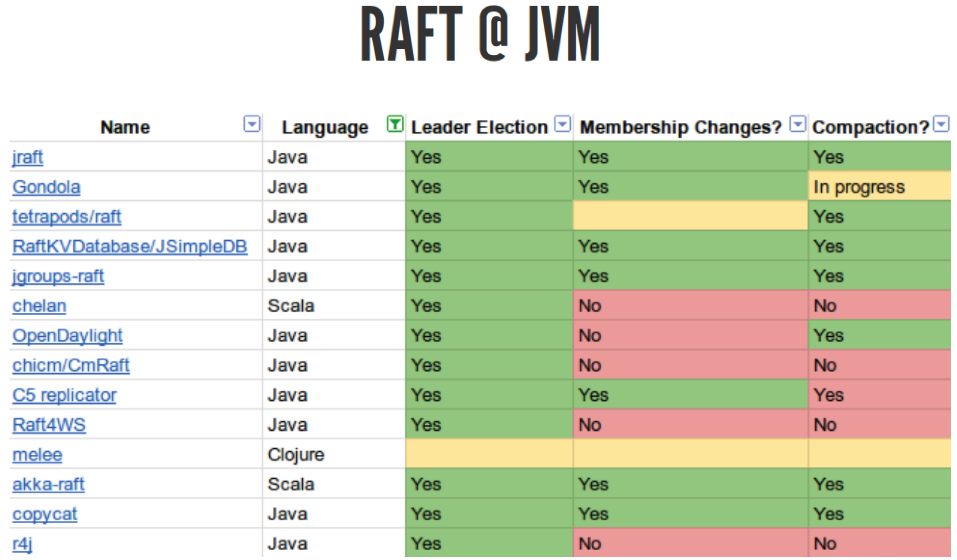
It is only for Java, but there are implementations for all languages, even in PHP, I think there is, although it is not clear why. You can take this library and try to test it for yourself. Not all of them implement the correct RAFT. I tried to use akka-raft, which should seem to work, but for some reason it didn’t pass the Jepsen tests, although it seems to be written that sometimes it should.
Consensus algorithms are used a lot where, even in the third version of MongoDB, RAFT appeared. At Cassandra, PAXOS has been his whole life. In many databases, queue systems, when they grow to maturity, sooner or later a consensus algorithm appears.
In general, when you write your distributed system, you should understand that you have many ways that you can go. You should know that these paths exist and do not do another one of your own. When you choose a path, you must understand that every path you have is a compromise between integrity, latency, bandwidth, and other different things. If you understand this compromise and can apply it to your subject area, then everything is fine.
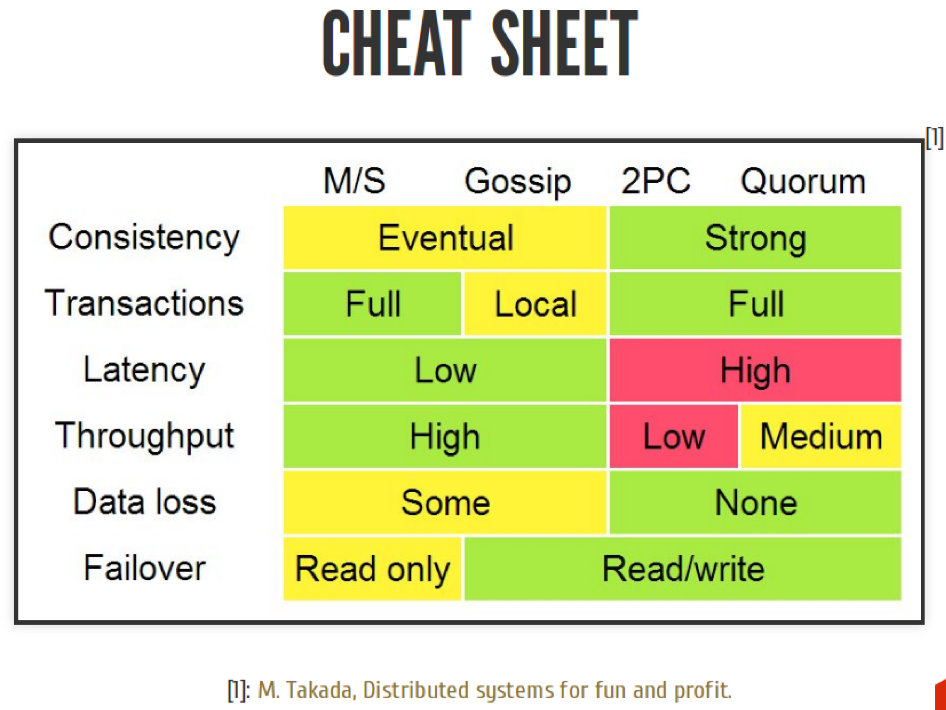
You cannot say which of these approaches is better. It all depends on you. It all depends on your business task. These are just tools.
Report: Fear and Loathing in Distributed Systems.