We study ActionBlock: or a short story about another deadlock
- Transfer
I think that almost every real project uses some form of implementation of the producer-consumer queue . The idea behind the problem is pretty simple. An application needs to decouple the production of some data from its processing. Take, for example, the thread pool in the CLR: we add an element for processing by calling ThreadPool.QueueUserWorkItem , and the thread pool itself understands how many workflows are most optimal and calls methods for processing elements with the necessary degree of parallelism.
But using a standard thread pool is not always possible and / or reasonable. Despite the possibility of specifying the minimum and maximum number of threads, this configuration is global and will affect the entire application, and not the necessary parts. There are many other ways to solve the problem of the consumer supplier. It can be a “head-on” solution when the application logic is mixed with aspects of multithreading, queues, and synchronization. This can be a wrapper over a BlockingCollection with manual control of the number of workflows or tasks. Or it could be a solution based on a complete solution, such as the ActionBlock <T> from the TPL DataFlow.
Today we look at the internal structure of the ActionBlock class, we will discuss the design decisions that were made by its authors and find out why we need to know all this in order to get around some problems when using it. Ready? Well then let's go!
On my current project, we have a number of cases where we need to solve the problem of the supplier-consumer. One of them looks like this: we have a custom parser and interpreter for a language very similar to TypeScript. Without going deep into details, we can say that we need to parse a set of files and get the so-called “transitive closure" of all the dependencies. Then they need to be transformed into a presentation suitable for execution and executed.
The parsing logic looks something like this:
Pretty simple, right? And there is. Here's what a slightly simplified implementation based on the TPL Dataflow and ActionBlock <T> class will look like :
Let's see what happens here. For simplicity, all the core logic is in the Main method . The variable numberOfProcessedFiles is used to verify the logic is correct and contains the total number of processed files. The main work is done in the processFile delegate , which is then passed to the ActionBlock constructor . This delegate plays both the role of “consumer” and “provider”: it takes the file path through the path argument , parses the file, finds its dependencies and sends new files to the queue by calling the actionBlock.SendAsync method . Then there is a check of the number of elements in the processing queue, and if there are no new elements, then the whole operation is completed by callingactionBlock.Complete () (*). Then, the Main method creates an ActionBlock instance , starts processing the first file and waits for the end of the whole process.
The ParseFileAsync method emulates a file parsing process and calculates dependencies using the following primitive logic: the file 'foo.ts' depends on 'fo.ts', which depends on 'f.ts'. Those. each file depends on a file with a shorter name. This is unrealistic logic, but it allows us to show the basic idea of calculating the transitive closure of files.
Class actionblockmanages concurrency for you. True, you need to consider that the default degree of parallelism is 1, and to change this, you need to pass an instance of the ExecutionDataflowBlockOptions class in the ActionBlock constructor . If the MaxDegreeOfParallelism property is greater than 1, then the ActionBlock will call a callback delegate from different threads (actually, from different tasks) to process queue elements in parallel.
Everyone who at least once tried to independently solve the problem of the supplier-consumer faced a problem: what to do when the input data stream exceeds the capabilities of consumers in processing? How to “throttle” the input stream? Just store all input elements in memory? Throw an exception? Return false in add item method? Use a circular buffer and discard old elements? Or block the execution of this method until a place appears in the queue?
To solve this problem, the authors of ActionBlock decided to use the following generally accepted approach:
In our previous example, we did not set the size of the queue. And this means that if new elements are added faster than processed, then the application will sooner or later crash with an OutOfMemoryException . But let's try to fix this situation. And we set the queues to a very small size, for example, 1 element.
Now, if we run this code, we get ... deadlock!

Let’s think about the problem of the consumer-supplier in terms of design. We write our own queue, which accepts a callback method to process the elements. We need to decide whether it should support the limitation of the number of elements or not. If we need a “bounded” queue, then we will surely come to a design very similar to the design of the ActionBlock class : we will add a synchronous method to add elements that will return falseif the queue is full, and an asynchronous method that will return the task. In the case of a full queue, a client of our class will have the opportunity to decide what to do: handle the "overflow" on their own by calling the synchronous version of adding elements or "await" the appearance of free space in the queue using the asynchronous version.
Then you will need to decide when to call the callback method. As a result, you can come to the following logic: if the queue is not empty, then the first element is taken, the callback method is called, processing is expected to complete, after which the element is removed from the queue. (The actual implementation will be significantly more complicated than it seems, simply because it must take into account all sorts of races). The queue may decide to delete the item before calling the callback method, but, as we will soon see, this will not affect the possibility of receiving deadlock.
We came up with a simple and elegant design, but it can easily lead to a problem. Suppose the queue is full and a callback is being called to process one of the elements. But what if, instead of quickly “returning” the management queue, the handler tries to add another element by calling await SendAsync :
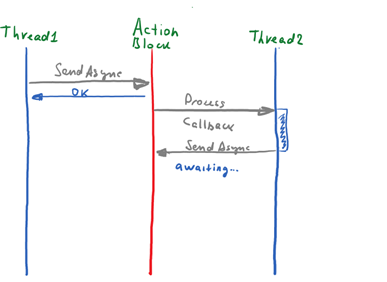
The queue is full and cannot accept new items because the callback method is not yet complete. But this method, too, was stuck waiting for await SendAsync to complete and could not move on until a place was queued up. Classic deadlock!
Ok, we get a deadlock because ActionBlock removes an item from the queue * after * the callback method completes. But let's look at an alternative scenario: what happens if the ActionBlock removes the element * before * calling the callback method? In fact, nothing will change. Deadlock will still be possible.
Imagine that the queue size is one, and the degree of parallelism is two.

It turns out that removing an item from the queue before processing does not help. Moreover, this will only exacerbate the problem, since the probability of deadlock will significantly decrease (it is necessary that, with a degree of parallelism equal to N, all N callback methods try to simultaneously add new elements to the queue).
Another drawback is less obvious. ActionBlock is still not a general-purpose solution. This class implements the ITargetSource interface and can be used to process elements in complex dataflow scripts. For example, we may have a BufferBlock with several “target” blocks for parallel processing of elements. In the current implementation, balancing handlers is implemented in a trivial way. As soon as the receiver (in our caseActionBlock ) is full, it stops accepting new elements for input. And this allows other blocks in the chain to process the element instead.
If an element is deleted only after it has been processed, then the ActionBlock will become more greedy and will accept more elements than it can handle at the moment. In this case, the bounded capacity of each block becomes equal to 'BoundedCapaciy' + 'MaxDegreeOfParallelism'.
I'm afraid that nothing. If at the same time you need to limit the number of elements in the queue and the callback method can add new elements, then you will have to abandon ActionBlock . An alternative could be a solution based on BlockingCollection and “manual” control of the number of workflows, for example, using a task pool or Parallel.Invoke.
Unlike primitives from TPL, all blocks from TPL Dataflow are single-threaded by default. Those. ActionBlock , TransformerBlock, and others, call the callback method one at a time. The authors of TPL Dataflow felt that simplicity is more important than possible performance gains. It’s quite difficult to think about data flow graphs, and parallel processing of data by all blocks will make this process even more difficult.
To change the degree of parallelism, the block must be passed ExecutionDataflowBlockOptions and set to the MaxDegreeOfParallelism propertythe value is greater than 1. By the way, if this property is set to -1, then all incoming elements will be processed by the new task and parallelism will be limited only by the capabilities of the used task scheduler ( TaskScheduler object ), which can also be passed through ExecutionDataflowBlockOptions .
Designing easy-to-use components is challenging. Designing easy-to-use components that solve concurrency issues is doubly more difficult. To use these components correctly, you need to know how they are implemented and what limitations their developers had in mind.
The ActionBlock <T> class is a great thing, which greatly simplifies the implementation of the supplier-consumer pattern. But even in this case, you should know about some aspects of TPL Dataflow, such as the degree of parallelism and the behavior of blocks in case of overflow.
- (*) This example is not thread safe and a full implementation should not use actionBlock.InputCount . Do you see a problem?
(**) Post methodreturns false in one of two cases: the queue is full or already completed (the Complete method is called ). This aspect may complicate the use of this method, since these two cases cannot be distinguished. The SendAsync method , on the other hand, behaves somewhat differently: the method returns a Task <bool> object that will be in an unfinished state while the queue is full, but if the queue is already completed and unable to accept new elements, then task.Result will be false .
But using a standard thread pool is not always possible and / or reasonable. Despite the possibility of specifying the minimum and maximum number of threads, this configuration is global and will affect the entire application, and not the necessary parts. There are many other ways to solve the problem of the consumer supplier. It can be a “head-on” solution when the application logic is mixed with aspects of multithreading, queues, and synchronization. This can be a wrapper over a BlockingCollection with manual control of the number of workflows or tasks. Or it could be a solution based on a complete solution, such as the ActionBlock <T> from the TPL DataFlow.
Today we look at the internal structure of the ActionBlock class, we will discuss the design decisions that were made by its authors and find out why we need to know all this in order to get around some problems when using it. Ready? Well then let's go!
On my current project, we have a number of cases where we need to solve the problem of the supplier-consumer. One of them looks like this: we have a custom parser and interpreter for a language very similar to TypeScript. Without going deep into details, we can say that we need to parse a set of files and get the so-called “transitive closure" of all the dependencies. Then they need to be transformed into a presentation suitable for execution and executed.
The parsing logic looks something like this:
- Parsim file.
- We analyze its contents and look for its dependencies (by analyzing all the 'import * from', 'require' and similar constructions).
- We calculate the dependencies (i.e., we find the set of files that the current file requires for normal operation).
- Add the received dependency files to the list for parsing.
Pretty simple, right? And there is. Here's what a slightly simplified implementation based on the TPL Dataflow and ActionBlock <T> class will look like :
privatestatic Task<ParsedFile> ParseFileAsync(string path)
{
Console.WriteLine($"Parsing '{path}'. {{0}}",
$"Thread Id - {Thread.CurrentThread.ManagedThreadId}");
Thread.Sleep(10);
return Task.FromResult(
new ParsedFile()
{
FileName = path,
Dependencies = GetFileDependencies(path),
});
}
staticvoidMain(string[] args)
{
long numberOfProcessedFiles = 0;
ActionBlock<string> actionBlock = null;
Func<string, Task> processFile = async path =>
{
Interlocked.Increment(ref numberOfProcessedFiles);
ParsedFile parsedFile = await ParseFileAsync(path);
foreach (var dependency in parsedFile.Dependencies)
{
Console.WriteLine($"Sending '{dependency}' to the queue... {{0}}",
$"Thread Id - {Thread.CurrentThread.ManagedThreadId}");
await actionBlock.SendAsync(dependency);
}
if (actionBlock.InputCount == 0)
{
// This is a marker that this is a last file and there // is nothing to process
actionBlock.Complete();
}
};
actionBlock = new ActionBlock<string>(processFile);
actionBlock.SendAsync("FooBar.ts").GetAwaiter().GetResult();
Console.WriteLine("Waiting for an action block to finish...");
actionBlock.Completion.GetAwaiter().GetResult();
Console.WriteLine($"Done. Processed {numberOfProcessedFiles}");
Console.ReadLine();
}Let's see what happens here. For simplicity, all the core logic is in the Main method . The variable numberOfProcessedFiles is used to verify the logic is correct and contains the total number of processed files. The main work is done in the processFile delegate , which is then passed to the ActionBlock constructor . This delegate plays both the role of “consumer” and “provider”: it takes the file path through the path argument , parses the file, finds its dependencies and sends new files to the queue by calling the actionBlock.SendAsync method . Then there is a check of the number of elements in the processing queue, and if there are no new elements, then the whole operation is completed by callingactionBlock.Complete () (*). Then, the Main method creates an ActionBlock instance , starts processing the first file and waits for the end of the whole process.
The ParseFileAsync method emulates a file parsing process and calculates dependencies using the following primitive logic: the file 'foo.ts' depends on 'fo.ts', which depends on 'f.ts'. Those. each file depends on a file with a shorter name. This is unrealistic logic, but it allows us to show the basic idea of calculating the transitive closure of files.
Class actionblockmanages concurrency for you. True, you need to consider that the default degree of parallelism is 1, and to change this, you need to pass an instance of the ExecutionDataflowBlockOptions class in the ActionBlock constructor . If the MaxDegreeOfParallelism property is greater than 1, then the ActionBlock will call a callback delegate from different threads (actually, from different tasks) to process queue elements in parallel.
Post vs. SendAsync: what and when to use
Everyone who at least once tried to independently solve the problem of the supplier-consumer faced a problem: what to do when the input data stream exceeds the capabilities of consumers in processing? How to “throttle” the input stream? Just store all input elements in memory? Throw an exception? Return false in add item method? Use a circular buffer and discard old elements? Or block the execution of this method until a place appears in the queue?
To solve this problem, the authors of ActionBlock decided to use the following generally accepted approach:
- The client can specify the size of the queue when creating the ActionBlock object .
- If the queue is full, the Post method returns false , and the SendAsync extension method returns a task that will be completed when there is free space in the queue.
In our previous example, we did not set the size of the queue. And this means that if new elements are added faster than processed, then the application will sooner or later crash with an OutOfMemoryException . But let's try to fix this situation. And we set the queues to a very small size, for example, 1 element.
actionBlock = new ActionBlock<string>(processFile,
new ExecutionDataflowBlockOptions() {BoundedCapacity = 1});Now, if we run this code, we get ... deadlock!
Deadlock
Let’s think about the problem of the consumer-supplier in terms of design. We write our own queue, which accepts a callback method to process the elements. We need to decide whether it should support the limitation of the number of elements or not. If we need a “bounded” queue, then we will surely come to a design very similar to the design of the ActionBlock class : we will add a synchronous method to add elements that will return falseif the queue is full, and an asynchronous method that will return the task. In the case of a full queue, a client of our class will have the opportunity to decide what to do: handle the "overflow" on their own by calling the synchronous version of adding elements or "await" the appearance of free space in the queue using the asynchronous version.
Then you will need to decide when to call the callback method. As a result, you can come to the following logic: if the queue is not empty, then the first element is taken, the callback method is called, processing is expected to complete, after which the element is removed from the queue. (The actual implementation will be significantly more complicated than it seems, simply because it must take into account all sorts of races). The queue may decide to delete the item before calling the callback method, but, as we will soon see, this will not affect the possibility of receiving deadlock.
We came up with a simple and elegant design, but it can easily lead to a problem. Suppose the queue is full and a callback is being called to process one of the elements. But what if, instead of quickly “returning” the management queue, the handler tries to add another element by calling await SendAsync :
The queue is full and cannot accept new items because the callback method is not yet complete. But this method, too, was stuck waiting for await SendAsync to complete and could not move on until a place was queued up. Classic deadlock!
Ok, we get a deadlock because ActionBlock removes an item from the queue * after * the callback method completes. But let's look at an alternative scenario: what happens if the ActionBlock removes the element * before * calling the callback method? In fact, nothing will change. Deadlock will still be possible.
Imagine that the queue size is one, and the degree of parallelism is two.
- Thread T1 adds an item to the queue. ActionBlock removes an element from the queue (decreasing the number of elements in the queue to 0) and calls the callback method.
- Thread T2 adds an item to the queue. ActionBlock removes an element from the queue (decreasing the number of elements in the queue to 0) and calls the callback method.
- Thread T1 adds an item to the queue. ActionBlock cannot call the handler of the new element, because the level of parallelism is 2, and we already have two handlers. The queue is full.
- The first handler during processing tries to add a new element to the queue, but sticks to the call to ' await SendAsync ', because the queue is full.
- The second handler during processing tries to add a new element to the queue, but sticks to the call to ' await SendAsync ', because the queue is full.
It turns out that removing an item from the queue before processing does not help. Moreover, this will only exacerbate the problem, since the probability of deadlock will significantly decrease (it is necessary that, with a degree of parallelism equal to N, all N callback methods try to simultaneously add new elements to the queue).
Another drawback is less obvious. ActionBlock is still not a general-purpose solution. This class implements the ITargetSource interface and can be used to process elements in complex dataflow scripts. For example, we may have a BufferBlock with several “target” blocks for parallel processing of elements. In the current implementation, balancing handlers is implemented in a trivial way. As soon as the receiver (in our caseActionBlock ) is full, it stops accepting new elements for input. And this allows other blocks in the chain to process the element instead.
If an element is deleted only after it has been processed, then the ActionBlock will become more greedy and will accept more elements than it can handle at the moment. In this case, the bounded capacity of each block becomes equal to 'BoundedCapaciy' + 'MaxDegreeOfParallelism'.
How to solve the problem with deadlock?
I'm afraid that nothing. If at the same time you need to limit the number of elements in the queue and the callback method can add new elements, then you will have to abandon ActionBlock . An alternative could be a solution based on BlockingCollection and “manual” control of the number of workflows, for example, using a task pool or Parallel.Invoke.
Degree of Parallelism
Unlike primitives from TPL, all blocks from TPL Dataflow are single-threaded by default. Those. ActionBlock , TransformerBlock, and others, call the callback method one at a time. The authors of TPL Dataflow felt that simplicity is more important than possible performance gains. It’s quite difficult to think about data flow graphs, and parallel processing of data by all blocks will make this process even more difficult.
To change the degree of parallelism, the block must be passed ExecutionDataflowBlockOptions and set to the MaxDegreeOfParallelism propertythe value is greater than 1. By the way, if this property is set to -1, then all incoming elements will be processed by the new task and parallelism will be limited only by the capabilities of the used task scheduler ( TaskScheduler object ), which can also be passed through ExecutionDataflowBlockOptions .
Conclusion
Designing easy-to-use components is challenging. Designing easy-to-use components that solve concurrency issues is doubly more difficult. To use these components correctly, you need to know how they are implemented and what limitations their developers had in mind.
The ActionBlock <T> class is a great thing, which greatly simplifies the implementation of the supplier-consumer pattern. But even in this case, you should know about some aspects of TPL Dataflow, such as the degree of parallelism and the behavior of blocks in case of overflow.
- (*) This example is not thread safe and a full implementation should not use actionBlock.InputCount . Do you see a problem?
(**) Post methodreturns false in one of two cases: the queue is full or already completed (the Complete method is called ). This aspect may complicate the use of this method, since these two cases cannot be distinguished. The SendAsync method , on the other hand, behaves somewhat differently: the method returns a Task <bool> object that will be in an unfinished state while the queue is full, but if the queue is already completed and unable to accept new elements, then task.Result will be false .