Caffe Neural Network Platform Optimization for Intel Architecture
- Transfer
Modern programs, claiming to be effective, must take into account the features of the hardware on which they will be executed. In particular, we are talking about multi-core processors, for example, such as Intel Xeon and Intel Xeon Phi, about large cache sizes, about instruction sets, say, Intel AVX2 and Intel AVX-512, which can improve computing performance. Barely restrained so as not to joke about Rusiano)
For example, Caffe is a popular platform for developing neural networks of deep learning. It was created at the Berkley Vision and Learning Center (BVLC), it was liked by a community of independent developers who make a contribution to its development. The platform lives and develops, the proof of this is the statistics on the project page

on github. Caffe is called "a fast open platform for deep learning." Is it possible to speed up such a “quick” set of tools? Asking this question, we decided to optimize Caffe for Intel architecture.
Looking ahead, we note that Caffe, thanks to the integration with the Intel Math Kernel Library 2017 and the set of optimizations that we performed, following the plan outlined in this article, began to work on Intel processors more than 10 times faster than the base version, which we, in hereinafter, we will call BVLC Caffe. The version optimized for Intel architecture will be called Intel Caffe for brevity. Here is its source code.
The main areas of performance improvement, details of which are read below, were code refactoring, its optimization based on the use of vector instruction sets such as Intel AVX2, fine-tuning of compilation, and increasing the efficiency of multi-threaded code execution using OpenMP. The tests were conducted on a system with two Intel Xeon processors. In particular, we investigated the speed of a neural network constructed by Caffe tools when working with images from the CIFAR-10 set. The program execution results were analyzed in Intel VTune Amplifier XE 2017 and using other tools.
A similar approach can be used to improve the performance of various programs, for example, other platforms for deep learning of neural networks.
Before moving on to optimization issues, we will talk about deep learning algorithms and the tasks that they solve with their help.
Deep learning algorithms are part of a more general class of machine learning algorithms that in recent years have shown significant results in pattern recognition in photos and videos, in speech recognition, in natural language processing, and in other areas where you have to deal with huge amounts of information and solve data analysis problems. The success of deep learning is based on the latest advances in computing and algorithms, in the ability to process large data sets. The principle of operation of such algorithms is that data is passed through network layers in which information is converted, and more and more complex features are extracted from it.
Here is an example of how each level of a deep neural network is trained to identify signs of ever greater complexity. Shown here is a small set of features recognized by a deep network, visualized as grayscale images. It also shows the original color images, the processing of which leads to the selection of these signs. Image taken from here .

Convolutional Neural Network
For the deep learning algorithms to work with the teacher, a labeled data set is required. The three popular types of deep neural networks that are taught with the teacher are Multilayer Perceptron (MLM), convolutional neural networks (CNNs), and recurrent neural networks (RNNs). In these networks, the input data, when passing through each layer of the network, is subjected to a series of linear and non-linear transformations. As a result, network output data is generated. The network response is compared with the expected result, errors are found, then, for the output layer, the error surface gradient vector is calculated, the contribution of the synaptic weights of the neurons to the network is taken into account, taking into account activation functions, and then the same procedure is performed for other layers using previously received data.
In multilayer perceptrons, the input data in each layer (represented by a vector) is first multiplied by a completely filled weight matrix unique to the layer. In recurrent networks, such a matrix (or matrices) is the same for each layer (since the layer is recurrent), and the properties of the network depend on the input signal. Convolutional networks are similar to multi-layer perceptrons, but they use sparse matrices for hidden layers called convolutional ones. In such networks, matrix multiplication is represented by the convolution of the matrix representation of the weights with the matrix representation of the input data of the layer. Convolutional networks are popular in image recognition, but they are used in speech recognition and natural language processing. Here you can read more about such networks.
As already mentioned, here we are going to optimize for the architecture of Intel BVLC Caffe - a popular platform for creating and exploring deep learning networks. We will test the initial and optimized version of the platform using the CIFAR-10 dataset , which is often used in image classification tasks, and the neural network model built in Caffe.

Example images from the CIFAR-10 set
The CIFAR-10 dataset consists of 60,000 color images 32x32 pixels in size divided into 10 classes: airplane, car, bird, cat, deer, dog, frog, horse, ship and truck. Classes do not intersect. For example, there is no overlap between the classes “car” and “truck”. "Cars" include, for example, sedans and SUVs. The “truck” class includes only heavy trucks, and, for example, pickup trucks are not in any of the image groups.
The network used during performance testing contains various types of layers. In particular, these are layers with a sigmoid activation function (such layers, in Caffe terminology, are of the Sigmoid type), convolutional layers (Convolution type), spatial union layers or, as they are also called, subsample layers (Pooling type), batch normalization layers ( BatchNorm type), fully connected layers (InnerProduct type). At the output of the network is a layer with the activation function Softmax (type SoftmaxWithLoss). We will talk more about this network and its layers below. Now let's get down to analyzing the original version of Caffe.
One method for evaluating the performance of BVLC Caffe and Intel Caffe is to use the time command , which calculates the time it takes for the signal to travel through the layers in the forward and reverse directions. This command is very useful for measuring the time spent on computing at each level, and for obtaining comparative execution time for different models:
In this case, “iteration” (that sets the iteration parameter ) is one forward and reverse pass through the image packet. The above command displays the average execution time for 1000 iterations, both for individual layers and for the entire network. Here are the results of this team for BVLC Caffe.

Time command output for BVLC Caffe
In tests, we used a system with two sockets. In each, an Intel Xeon processor E5-2699 v3 (2.3 GHz) with 18 physical cores was installed. At the same time, Intel Hyper-Threading Technology was disabled. Thus, there were only 36 physical processor cores in the system and the same number of OpenMP threads that was set using the OMP_NUM_THREADS environment variable. Unless otherwise indicated, just such a configuration was used in our experiments. Please note that we recommend allowing Intel Caffe to automatically configure OpenMP environment variables, rather than setting them yourself. In addition, the system has 64 GB of DDR4 memory, which operates at a frequency of 2.133 MHz.
Here you can see the results of the performance tests that were achieved due to the optimization of the code by Intel engineers. To measure performance, we used the following tools:
Tools from Intel VTune Amplifier XE provide the following information:
Performance analyzes can be used to find suitable candidates for optimization, such as functions that create a large load on the system, and calls to functions that take a relatively long time to complete.
The figure below shows a summary of the Intel VTune BVLC Caffe performance analysis data obtained after 100 iterations. The Elapsed Time indicator, located at the top of the figure, is 37 seconds. This is the time it took to execute the code on the test system. The CPU Time indicator, the processor time, is 1306 seconds. This is slightly less than 37 seconds times 36 cores (1332 seconds). This indicator represents the total duration of code execution in all threads (or on all cores, since in our case Intel HT technology was disabled), which are used in the calculations.

General results of the analysis of BVLC Caffe performance on the CIFAR-10 dataset in Intel VTune Amplifier XE 2017 beta
The histogram of processor usage, which is located at the bottom of the figure, indicates how often during the test a certain number of threads are involved simultaneously. In this case, out of 37 seconds, 14 falls on one thread (that is, on one core). The rest of the time, we see very inefficient multithreaded processing, while, basically, less than 20 threads participate in the work.
The Top Hotspots section, located in the middle of the figure, indicates which features account for the most work. Function calls and the contribution of each of them to the total processor time are listed here. Kmp_fork_barrier function- This is an external OpenMP-function, the execution of the code which takes 1130 seconds of processor time. This means that about 87% of the processor’s working time is spent on threads idling in this barrier function without doing anything useful.
BVLC Caffe source code has #pragma omp parallel line. However, the code itself does not explicitly use the OpenMP library to organize multi-threaded data processing. At the same time, inside Intel MKL, OpenMP streams are used to parallelize the execution of some basic mathematical calculations. In order to confirm this parallelization, we can use the Bottom-up tab in Intel VTune XE, the contents of which, after testing the BVLC Caffe on the CIFAR-10 dataset, are shown in the figure below. Here you can find a list of function calls and additional information about them. In particular, we are interested in the Effective Time by Utilization indicators (upper part of the tab) and the indicators of the distribution of the load created by the functions by flows (lower part).

Visualization of time parameters for executing functions and a list of functions that load the system the most when executing BVLC Caffe on the CIFAR-10 dataset
The gemm_omp_driver_v2 function is part of the libmkl_intel_thread.so- A generalized implementation of matrix multiplication (GEMM) from Intel MKL. The internal mechanisms of this function involve OpenMP multithreading. The matrix multiplication function from Intel MKL is the main function used in forward and backward propagation procedures, that is, in operations for receiving a network response and training it. Intel MKL uses multi-threaded execution, which usually reduces the execution time of GEMM calculations. However, in this particular case, the convolution operation for 32x32 images does not create too much load on the system, which does not allow efficient use of all 36 OpenMP streams on 36 cores in one GEMM operation. Therefore, as will be shown below, the use of various multithreading and parallelization schemes is required.
In order to demonstrate the additional load on the system, which creates the need to work with multiple OpenMP streams, we ran the same code with the environment variable OMP_NUM_THREADS = 1 , and then compared the execution time with the previous result. What we have is presented in the figure below. Here we see an Elapsed Time value of 31.1 seconds, instead of 37 seconds from the previous test. By writing one to the environment variable, we forced OpenMP to create only one stream and use it to execute code. The resulting difference of almost six seconds indicates an additional load on the system, which is caused by the initialization and synchronization of OpenMP streams.

General results of the analysis of the performance of the BVLC Caffe on the CIFAR-10 dataset in Intel VTune Amplifier XE 2017 beta using a single stream
In the central part of the above figure there is a list of functions that load the system most heavily. Among them, we found three main candidates for optimization. Namely, these are the functions im2col_cpu , col2im_cpu , and PoolingLayer :: Forward_cpu .
Using the CIFAR-10 c dataset in a Caffe environment optimized for Intel architecture is approximately 13.5 times faster than using the Caffe BVLC. The figure below shows the average results after 1000 iterations. On the left are BVLC Caffe data, on the right is Intel Caffe. It can be seen that in the first case, the total execution time was 270 ms., And in the second, 20 ms.

Performance Comparison of BVLC Caffe and Intel Caffe
Details on how to set calculation parameters for layers can be found here .
The next section will describe the optimizations used to improve the performance of the calculations used in different layers. We followed the guidelinesfrom the Intel Modern Code program. Some of the optimizations are based on basic math functions from Intel MKL 2017.
After profiling the BVLC Caffe code and identifying the most loaded functions that consume the most CPU time, we began work on vectorizing the code. Among the changes were the following:
BVLC Caffe has the ability to use Intel MKL BLAS function calls or other implementations of the same mechanisms. For example, the GEMM function is optimized for vectorization, multi-threaded execution and efficient use of cache memory. To improve vectorization, we also used Xbyak, a JIT assembler for x86 (IA-32) and x64 (AMD64 or x86-64) architectures. Xbyak supports the following vector instruction sets: MMX, Intel Streaming SIMD Extensions (Intel SSE), Intel SSE2, Intel SSE3, Intel SSE4, floating point module, Intel AVX, Intel AVX2, and Intel AVX-512.
Xbyak is an x86 / x64 assembler for C ++, a library specifically designed to improve code execution efficiency. Xbyak is provided as a header file. It can dynamically compile mnemonic instructions for x86 and x64 architectures. JIT binary generation during execution provides additional optimization options. For example, it is the optimization of quantization, the operation of elementwise division of one array by another, or the optimization of polynomial calculations due to the automatic creation of the necessary functions during program execution. With support for Intel AVX and Intel AVX2 vector instruction sets, with Xbyak you can achieve the best level of code vectorization in Caffe, optimized for Intel architecture. The latest version of Xbyak has support for the Intel AVX-512 vector instruction set.
Improving vectorization performance enables Xbyak, with the help of SIMD instructions, to process more data at the same time, which allows more efficient use of parallel data processing. We used Xbyak to optimize the code, which significantly improved the performance of calculations in the layers of spatial union. If the parameters of spatial joining are known, you can generate assembler code for specific joining models that use a specific data processing window or algorithm. The result is a completely normal-looking assembly, which, as proved, works more efficiently than C ++ code compiled without using Xbyak.
Other consecutive optimizations included the following:
Getting rid of repeated code execution, the results of which do not change, is one of the scalar optimization techniques that we have applied. This was done in order to pre-calculate what would otherwise be calculated inside the loop with maximum nesting depth.
Consider, for example, the following code fragment:
The third line of this fragment, to calculate the variable h_im , no index is used the inner loop w_col . But, despite this, the calculation of this variable is performed at each iteration of the nested loop. Alternatively, we can move this line outside the inner loop, bringing the code to this form:
Here are some additional general code optimizations that have been applied:
Intel VTune Amplifier XE found out that im2col_cpu is one of the most heavily loaded systems. This means that she is a good candidate for performance optimization. The im2col_cpu function is an implementation of the standard step in a direct convolution operation. Each local fragment is expanded into a separate vector, the entire image is converted into a larger matrix (which increases the intensity of working with memory), the rows of which correspond to many places where the filters were applied.
One optimization technique for im2col_cpu is to reduce the number of operations required to access data. In the BVLC Caffe code, there are three nested loops in which iterates through the pixels of the image:
In this code snippet, BVLC Caffe initially calculated the corresponding indexes of the data_col element array , although the indexes of this array are simply processed sequentially. Thus, four arithmetic operations (two additions and two multiplications) can be replaced with one index increment operation. In addition, the complexity of checking conditions can be reduced based on the following:
In the BVLC Caffe code, we checked a condition of the form if (x> = 0 && x <N) , where x and N are signed integers, and N is always a positive number. Converting these integers to unsigned integers allows you to change the comparison interval. Instead of performing two operations of comparison and calculation of logical AND , after type conversion, one comparison is enough:
In order to avoid movement of threads by the operating system between the computing cores, we used the OpenMP environment variable: KMP_AFFINITY = compact, granularity = fine . The compact arrangement of neighboring threads can improve the performance of GEMM operations, since threads that work together with the same last-level cache (LLC) can reuse data previously written to cache lines.
Here is the material where you can find details about the optimization associated with blocking the cache, about the features of optimal data composition and vectorization.
During the application of OpenMP-parallelization, the following neural network mechanisms were optimized:
The convolution layer, which is quite consistent with its name, convolves the input data using a set of weights modified in the course of training the network, or filters, each of which allows you to get one feature map in the output image. This optimization prevents the underutilization of hardware resources for a single set of input feature maps.
We handle k = min (num_threads, batch_size) sets of input_feature map sets . For example, k im2col operations occur in parallel and k calls to Intel MKL are performed . Intel MKL switches to single-threaded execution mode automatically and overall performance is better than before when Intel MKL processed one packet. This behavior is specified in the src / caffe / layers / base_conv_layer.cpp source file. This is an implementation of optimized multi-threaded processing using OpenMP from the src / caffe / layers / conv_layer.cpp source file.
Max-pooling, average-pooling, and stochastic-pooling (not yet implemented) are different downsampling methods, with max-pooling being the most popular method. The subsampling layer splits the result obtained from the previous layer into a set of usually non-overlapping rectangular fragments. For each such fragment, the layer then displays the maximum (max-pooling), arithmetic mean (average-pooling), or (in the future) stochastic value (stochastic-pooling) obtained from the multinomial distribution formed from the activation functions of each fragment.
Subsampling layers are useful in convolutional networks for three main reasons:
A subsample works on a single feature map, so we used Xbyak to perform an efficient build procedure that would help us create the selection we need for one or more input feature maps. This technique can be implemented for a packet of input feature maps when the procedure is executed in parallel in OpenMP.
Subsampling layer calculations are performed in parallel using OpenMP multithreading. This is possible due to the fact that the images are independent:
Thanks to the expression collapse (2), the OpenMP #pragma omp parallel directive extends to both nested for loops, which loop through the images in the packet and image channels, combining the loops into one and executing what happened in parallel.
The loss function is a key component in machine learning. It is this function that is used when comparing the network output with the target, to search for errors. After that, the network weights are adjusted to reduce the value of this function, that is, to reduce the error, to deviate what the network produces from the desired output. In our model, softmax is used as a loss function (layer type is SoftmaxWithLoss).
Such an activation function is used when the network outputs symbolize the probability of certain events, or, as in our case, the probability of images belonging to different classes. In particular, in multinomial logistic regression (the problem of classification into many classes), the input for this function is the result of Kdifferent linear functions, and the predicted probability of the j- th class for the vector x is calculated by the following formula:
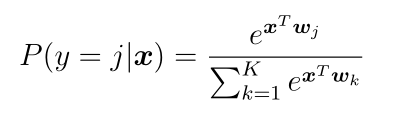
In multithreaded execution of these calculations, an approach is applied using the main and subordinate threads. So, the main thread starts a certain number of subordinates, distributing tasks between them. Slave threads are then executed in parallel, as they are assigned to different cores.
For example, in the following code, the parallel execution of individual arithmetic operations with independent access to data is implemented by separating the calculations for different image channels:
ReLU is today the most popular class of nonlinear functions used in deep learning algorithms. Fully connected layers are element-wise operators that take a binary object (blob in Caffe terminology) produced by the underlying layer and feed the transformed dataset of the same size onto the overlying layer. (Such a data set is a regular array representing the unified interface of the Caffe platform. When data and errors found are distributed over the network, Caffe works with information in the form of such objects).
The layer with the activation function ReLU takes the input value x and outputs the same x if it is greater than zero, and multiplies negative values by the negative_slope parameter using the following formula:
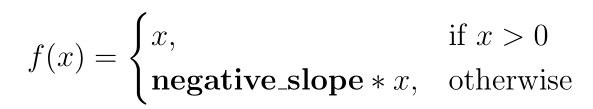
By default, the value of the negative_slope parameter is zero, which is equivalent to the standard ReLU function, which returns the maximum value after comparing the value passed to it with zero: max (x, 0) . Due to the independence of the activation process from the data, each data set can be processed in parallel:
Similar parallel computing can also be used in the error back propagation procedure:
In the same way, we can parallelize the calculation of the sigmoid function S (x) = 1 / (1 + exp (-x)):
Since MKL does not provide basic mathematical operations for implementing ReLU functions, in order to add this functionality to the system, we tried to implement an optimized assembler version of the ReLU layer (using Xbyak). However, after testing, we did not find a noticeable increase in performance on Intel Xeon processors. Perhaps this is because of the limited memory bandwidth. The parallelization of existing C ++ code was good enough to improve overall performance.
In the previous section, we examined the various components and layers of neural networks, and how the data processed in these layers are distributed among OpenMP and Intel MKL streams. The processor usage histogram below shows how often a certain number of threads are executed in parallel after code optimization.
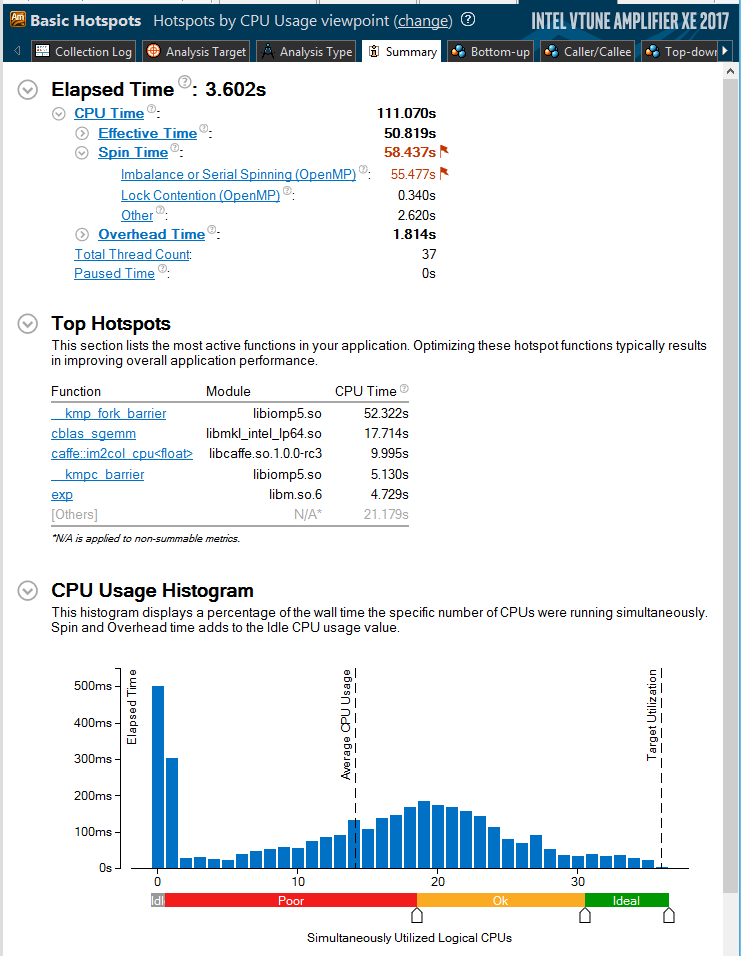
General results of the analysis of the execution of the implementation of Caffe, optimized for Intel architecture, on the CIFAR-10 task in Intel VTune Amplifier XE 2017 beta
Using Caffe, optimized for Intel architecture, the number of simultaneously running threads has increased significantly. The runtime on our test system fell from 37 seconds for the non-optimized BVLC Caffe code to just 3.6 seconds for the optimized version. Overall productivity has grown more than 10 times.
As shown in the Elapsed Time section, at the top of the figure, part of the execution time refers to the Spin Time indicator, which indicates the time spent on waiting, and not on useful work. As a result, productivity does not grow linearly with increasing number of threads (in accordance with Amdal's law). In addition, there are still portions running sequentially that are not parallelized using OpenMP. The reinitialization of parallel sections of OpenMP has been significantly optimized for recent implementations of the OpenMP library, but it still poses a rather noticeable additional load on the system. Moving parallel sections to the main function can potentially improve performance even more, but this will require significant code refactoring.
The figure below summarizes the optimization techniques described and the code processing principles that we followed while optimizing Caffe for Intel architecture.
Step-by-step approach of the Intel Modern Code program
During the tests, we used the Intel VTune Amplifier XE 2017 beta to find the code sections that create the greatest load on the system, and the optimization of which can bring a noticeable performance gain. We have implemented scalar and sequential optimizations, including eliminating code whose execution results turn out to be the same with repeated calls. We also reduced or simplified arithmetic operations, optimizing cycles and checking conditions. Next, we improved the code based on its vectorization, following the general principles outlined in the materialabout automatic vectorization in GCC. Using the Xbyak JIT assembler allowed us to use SIMD instructions more efficiently.
We implemented multithreading for calculations performed inside layers of a neural network using the OpenMP library, where operations on images or channels were independent of data. The final step in applying the approach of the Intel Modern Code program included scaling the application, which was originally executed on one node, to a multi-core architecture, and to a cluster environment with many nodes. This, at the moment, is the main subject of our study. In addition, we applied cache-oriented reuse optimizations to improve computational performance. Details about such optimizations can be found here.. Code optimization for the Intel Xeon Phi x200 family of processors included the use of high bandwidth MCDRAM and NUMA operation.
Optimizing Caffe for Intel architecture not only significantly improved computing performance, but also enabled the extraction of much more complex feature sets from graphic data. If you use Caffe in your own neural network research, running the code on systems with Intel processors, an optimized version of this platform will significantly expand your capabilities.
In addition, we hope that our story about improving the code, about tools for analyzing the speed of work and optimizing programs, will help you in improving the performance of your applications, both in the field of deep learning of neural networks, and any others.
Intel would like to thank Boris Ginzburg for his ideas and initial contribution to the development of the multi-threaded OpenMP version of Caffe, optimized for Intel architecture.
Details about the Intel Modern Code program can be found here and here .
on github. Caffe is called "a fast open platform for deep learning." Is it possible to speed up such a “quick” set of tools? Asking this question, we decided to optimize Caffe for Intel architecture.
Looking ahead, we note that Caffe, thanks to the integration with the Intel Math Kernel Library 2017 and the set of optimizations that we performed, following the plan outlined in this article, began to work on Intel processors more than 10 times faster than the base version, which we, in hereinafter, we will call BVLC Caffe. The version optimized for Intel architecture will be called Intel Caffe for brevity. Here is its source code.
The main areas of performance improvement, details of which are read below, were code refactoring, its optimization based on the use of vector instruction sets such as Intel AVX2, fine-tuning of compilation, and increasing the efficiency of multi-threaded code execution using OpenMP. The tests were conducted on a system with two Intel Xeon processors. In particular, we investigated the speed of a neural network constructed by Caffe tools when working with images from the CIFAR-10 set. The program execution results were analyzed in Intel VTune Amplifier XE 2017 and using other tools.
A similar approach can be used to improve the performance of various programs, for example, other platforms for deep learning of neural networks.
Before moving on to optimization issues, we will talk about deep learning algorithms and the tasks that they solve with their help.
About deep learning algorithms
Deep learning algorithms are part of a more general class of machine learning algorithms that in recent years have shown significant results in pattern recognition in photos and videos, in speech recognition, in natural language processing, and in other areas where you have to deal with huge amounts of information and solve data analysis problems. The success of deep learning is based on the latest advances in computing and algorithms, in the ability to process large data sets. The principle of operation of such algorithms is that data is passed through network layers in which information is converted, and more and more complex features are extracted from it.
Here is an example of how each level of a deep neural network is trained to identify signs of ever greater complexity. Shown here is a small set of features recognized by a deep network, visualized as grayscale images. It also shows the original color images, the processing of which leads to the selection of these signs. Image taken from here .
Convolutional Neural Network
For the deep learning algorithms to work with the teacher, a labeled data set is required. The three popular types of deep neural networks that are taught with the teacher are Multilayer Perceptron (MLM), convolutional neural networks (CNNs), and recurrent neural networks (RNNs). In these networks, the input data, when passing through each layer of the network, is subjected to a series of linear and non-linear transformations. As a result, network output data is generated. The network response is compared with the expected result, errors are found, then, for the output layer, the error surface gradient vector is calculated, the contribution of the synaptic weights of the neurons to the network is taken into account, taking into account activation functions, and then the same procedure is performed for other layers using previously received data.
In multilayer perceptrons, the input data in each layer (represented by a vector) is first multiplied by a completely filled weight matrix unique to the layer. In recurrent networks, such a matrix (or matrices) is the same for each layer (since the layer is recurrent), and the properties of the network depend on the input signal. Convolutional networks are similar to multi-layer perceptrons, but they use sparse matrices for hidden layers called convolutional ones. In such networks, matrix multiplication is represented by the convolution of the matrix representation of the weights with the matrix representation of the input data of the layer. Convolutional networks are popular in image recognition, but they are used in speech recognition and natural language processing. Here you can read more about such networks.
Caffe, CIFAR-10 and Image Classification
As already mentioned, here we are going to optimize for the architecture of Intel BVLC Caffe - a popular platform for creating and exploring deep learning networks. We will test the initial and optimized version of the platform using the CIFAR-10 dataset , which is often used in image classification tasks, and the neural network model built in Caffe.
Example images from the CIFAR-10 set
The CIFAR-10 dataset consists of 60,000 color images 32x32 pixels in size divided into 10 classes: airplane, car, bird, cat, deer, dog, frog, horse, ship and truck. Classes do not intersect. For example, there is no overlap between the classes “car” and “truck”. "Cars" include, for example, sedans and SUVs. The “truck” class includes only heavy trucks, and, for example, pickup trucks are not in any of the image groups.
The network used during performance testing contains various types of layers. In particular, these are layers with a sigmoid activation function (such layers, in Caffe terminology, are of the Sigmoid type), convolutional layers (Convolution type), spatial union layers or, as they are also called, subsample layers (Pooling type), batch normalization layers ( BatchNorm type), fully connected layers (InnerProduct type). At the output of the network is a layer with the activation function Softmax (type SoftmaxWithLoss). We will talk more about this network and its layers below. Now let's get down to analyzing the original version of Caffe.
Initial performance analysis
One method for evaluating the performance of BVLC Caffe and Intel Caffe is to use the time command , which calculates the time it takes for the signal to travel through the layers in the forward and reverse directions. This command is very useful for measuring the time spent on computing at each level, and for obtaining comparative execution time for different models:
./build/tools/caffe time \
--model=examples/cifar10/cifar10_full_sigmoid_train_test_bn.prototxt \
-iterations 1000In this case, “iteration” (that sets the iteration parameter ) is one forward and reverse pass through the image packet. The above command displays the average execution time for 1000 iterations, both for individual layers and for the entire network. Here are the results of this team for BVLC Caffe.
Time command output for BVLC Caffe
In tests, we used a system with two sockets. In each, an Intel Xeon processor E5-2699 v3 (2.3 GHz) with 18 physical cores was installed. At the same time, Intel Hyper-Threading Technology was disabled. Thus, there were only 36 physical processor cores in the system and the same number of OpenMP threads that was set using the OMP_NUM_THREADS environment variable. Unless otherwise indicated, just such a configuration was used in our experiments. Please note that we recommend allowing Intel Caffe to automatically configure OpenMP environment variables, rather than setting them yourself. In addition, the system has 64 GB of DDR4 memory, which operates at a frequency of 2.133 MHz.
Here you can see the results of the performance tests that were achieved due to the optimization of the code by Intel engineers. To measure performance, we used the following tools:
- Callgrind from the Valgrind toolkit.
- Intel VTune Amplifier XE 2017 beta.
Tools from Intel VTune Amplifier XE provide the following information:
- Functions that create the greatest load on the system (hotspots).
- System calls (including task switching).
- CPU and cache usage.
- Load balancing across OpenMP streams.
- Thread locks.
- Memory usage.
Performance analyzes can be used to find suitable candidates for optimization, such as functions that create a large load on the system, and calls to functions that take a relatively long time to complete.
The figure below shows a summary of the Intel VTune BVLC Caffe performance analysis data obtained after 100 iterations. The Elapsed Time indicator, located at the top of the figure, is 37 seconds. This is the time it took to execute the code on the test system. The CPU Time indicator, the processor time, is 1306 seconds. This is slightly less than 37 seconds times 36 cores (1332 seconds). This indicator represents the total duration of code execution in all threads (or on all cores, since in our case Intel HT technology was disabled), which are used in the calculations.
General results of the analysis of BVLC Caffe performance on the CIFAR-10 dataset in Intel VTune Amplifier XE 2017 beta
The histogram of processor usage, which is located at the bottom of the figure, indicates how often during the test a certain number of threads are involved simultaneously. In this case, out of 37 seconds, 14 falls on one thread (that is, on one core). The rest of the time, we see very inefficient multithreaded processing, while, basically, less than 20 threads participate in the work.
The Top Hotspots section, located in the middle of the figure, indicates which features account for the most work. Function calls and the contribution of each of them to the total processor time are listed here. Kmp_fork_barrier function- This is an external OpenMP-function, the execution of the code which takes 1130 seconds of processor time. This means that about 87% of the processor’s working time is spent on threads idling in this barrier function without doing anything useful.
BVLC Caffe source code has #pragma omp parallel line. However, the code itself does not explicitly use the OpenMP library to organize multi-threaded data processing. At the same time, inside Intel MKL, OpenMP streams are used to parallelize the execution of some basic mathematical calculations. In order to confirm this parallelization, we can use the Bottom-up tab in Intel VTune XE, the contents of which, after testing the BVLC Caffe on the CIFAR-10 dataset, are shown in the figure below. Here you can find a list of function calls and additional information about them. In particular, we are interested in the Effective Time by Utilization indicators (upper part of the tab) and the indicators of the distribution of the load created by the functions by flows (lower part).
Visualization of time parameters for executing functions and a list of functions that load the system the most when executing BVLC Caffe on the CIFAR-10 dataset
The gemm_omp_driver_v2 function is part of the libmkl_intel_thread.so- A generalized implementation of matrix multiplication (GEMM) from Intel MKL. The internal mechanisms of this function involve OpenMP multithreading. The matrix multiplication function from Intel MKL is the main function used in forward and backward propagation procedures, that is, in operations for receiving a network response and training it. Intel MKL uses multi-threaded execution, which usually reduces the execution time of GEMM calculations. However, in this particular case, the convolution operation for 32x32 images does not create too much load on the system, which does not allow efficient use of all 36 OpenMP streams on 36 cores in one GEMM operation. Therefore, as will be shown below, the use of various multithreading and parallelization schemes is required.
In order to demonstrate the additional load on the system, which creates the need to work with multiple OpenMP streams, we ran the same code with the environment variable OMP_NUM_THREADS = 1 , and then compared the execution time with the previous result. What we have is presented in the figure below. Here we see an Elapsed Time value of 31.1 seconds, instead of 37 seconds from the previous test. By writing one to the environment variable, we forced OpenMP to create only one stream and use it to execute code. The resulting difference of almost six seconds indicates an additional load on the system, which is caused by the initialization and synchronization of OpenMP streams.
General results of the analysis of the performance of the BVLC Caffe on the CIFAR-10 dataset in Intel VTune Amplifier XE 2017 beta using a single stream
In the central part of the above figure there is a list of functions that load the system most heavily. Among them, we found three main candidates for optimization. Namely, these are the functions im2col_cpu , col2im_cpu , and PoolingLayer :: Forward_cpu .
Code optimization
Using the CIFAR-10 c dataset in a Caffe environment optimized for Intel architecture is approximately 13.5 times faster than using the Caffe BVLC. The figure below shows the average results after 1000 iterations. On the left are BVLC Caffe data, on the right is Intel Caffe. It can be seen that in the first case, the total execution time was 270 ms., And in the second, 20 ms.
Performance Comparison of BVLC Caffe and Intel Caffe
Details on how to set calculation parameters for layers can be found here .
The next section will describe the optimizations used to improve the performance of the calculations used in different layers. We followed the guidelinesfrom the Intel Modern Code program. Some of the optimizations are based on basic math functions from Intel MKL 2017.
Scalar and sequential optimization
▍Vectorization code
After profiling the BVLC Caffe code and identifying the most loaded functions that consume the most CPU time, we began work on vectorizing the code. Among the changes were the following:
- Improving the work with the Basic Linear Algebra Subprograms (BLAS) libraries, namely, the transition from the Automatically Tuned Linear Algebra System (ATLAS) to Intel MKL.
- Optimization in the process of building code (using the Xbyak JIT assembler).
- Vectoring code using the GNU Compiler Collection (GCC) and OpenMP.
BVLC Caffe has the ability to use Intel MKL BLAS function calls or other implementations of the same mechanisms. For example, the GEMM function is optimized for vectorization, multi-threaded execution and efficient use of cache memory. To improve vectorization, we also used Xbyak, a JIT assembler for x86 (IA-32) and x64 (AMD64 or x86-64) architectures. Xbyak supports the following vector instruction sets: MMX, Intel Streaming SIMD Extensions (Intel SSE), Intel SSE2, Intel SSE3, Intel SSE4, floating point module, Intel AVX, Intel AVX2, and Intel AVX-512.
Xbyak is an x86 / x64 assembler for C ++, a library specifically designed to improve code execution efficiency. Xbyak is provided as a header file. It can dynamically compile mnemonic instructions for x86 and x64 architectures. JIT binary generation during execution provides additional optimization options. For example, it is the optimization of quantization, the operation of elementwise division of one array by another, or the optimization of polynomial calculations due to the automatic creation of the necessary functions during program execution. With support for Intel AVX and Intel AVX2 vector instruction sets, with Xbyak you can achieve the best level of code vectorization in Caffe, optimized for Intel architecture. The latest version of Xbyak has support for the Intel AVX-512 vector instruction set.
Improving vectorization performance enables Xbyak, with the help of SIMD instructions, to process more data at the same time, which allows more efficient use of parallel data processing. We used Xbyak to optimize the code, which significantly improved the performance of calculations in the layers of spatial union. If the parameters of spatial joining are known, you can generate assembler code for specific joining models that use a specific data processing window or algorithm. The result is a completely normal-looking assembly, which, as proved, works more efficiently than C ++ code compiled without using Xbyak.
▍ General code optimizations
Other consecutive optimizations included the following:
- Reducing the complexity of the algorithms.
- Decrease in volume of calculations.
- Unfolding cycles.
Getting rid of repeated code execution, the results of which do not change, is one of the scalar optimization techniques that we have applied. This was done in order to pre-calculate what would otherwise be calculated inside the loop with maximum nesting depth.
Consider, for example, the following code fragment:
for (int h_col = 0; h_col < height_col; ++h_col) {
for (int w_col = 0; w_col < width_col; ++w_col) {
int h_im = h_col * stride_h - pad_h + h_offset;
int w_im = w_col * stride_w - pad_w + w_offset;The third line of this fragment, to calculate the variable h_im , no index is used the inner loop w_col . But, despite this, the calculation of this variable is performed at each iteration of the nested loop. Alternatively, we can move this line outside the inner loop, bringing the code to this form:
for (int h_col = 0; h_col < height_col; ++h_col) {
int h_im = h_col * stride_h - pad_h + h_offset;
for (int w_col = 0; w_col < width_col; ++w_col) {
int w_im = w_col * stride_w - pad_w + w_offset;Processor, system-specific optimizations, and other general code improvement approaches
Here are some additional general code optimizations that have been applied:
- Improved im2col_cpu and col2im_cpu functions implementation .
- Reducing the complexity of the batch normalization operation.
- Optimizations specific to the processor and system.
- Using one core per compute stream.
- Elimination of movement of flows between computing cores.
Intel VTune Amplifier XE found out that im2col_cpu is one of the most heavily loaded systems. This means that she is a good candidate for performance optimization. The im2col_cpu function is an implementation of the standard step in a direct convolution operation. Each local fragment is expanded into a separate vector, the entire image is converted into a larger matrix (which increases the intensity of working with memory), the rows of which correspond to many places where the filters were applied.
One optimization technique for im2col_cpu is to reduce the number of operations required to access data. In the BVLC Caffe code, there are three nested loops in which iterates through the pixels of the image:
for (int c_col = 0; c_col < channels_col; ++c_col)
for (int h_col = 0; h_col < height_col; ++h_col)
for (int w_col = 0; w_col < width_col; ++w_col)
data_col[(c_col*height_col+h_col)*width_col+w_col] = // ...In this code snippet, BVLC Caffe initially calculated the corresponding indexes of the data_col element array , although the indexes of this array are simply processed sequentially. Thus, four arithmetic operations (two additions and two multiplications) can be replaced with one index increment operation. In addition, the complexity of checking conditions can be reduced based on the following:
/* Функция использует приведение типа int к unsigned для проверки
того, является ли значение параметра a большим или равным нулю,
и меньшим, чем значение параметра b. Тип параметра b – unsigned,
он всегда положителен, таким образом, его значение всегда меньше,
чем 0x800…, при этом преобразование типа параметра с отрицательным
значением всегда приводит его к числу, которое больше, чем 0x800…
Приведение типов позволяет использовать одно условие вместо двух. */
inline bool is_a_ge_zero_and_a_lt_b(int a, int b) {
return static_cast(a) < static_cast(b);
} In the BVLC Caffe code, we checked a condition of the form if (x> = 0 && x <N) , where x and N are signed integers, and N is always a positive number. Converting these integers to unsigned integers allows you to change the comparison interval. Instead of performing two operations of comparison and calculation of logical AND , after type conversion, one comparison is enough:
if (((unsigned) x) < ((unsigned) N))In order to avoid movement of threads by the operating system between the computing cores, we used the OpenMP environment variable: KMP_AFFINITY = compact, granularity = fine . The compact arrangement of neighboring threads can improve the performance of GEMM operations, since threads that work together with the same last-level cache (LLC) can reuse data previously written to cache lines.
Here is the material where you can find details about the optimization associated with blocking the cache, about the features of optimal data composition and vectorization.
Code parallelization using OpenMP
▍ Neural network layers
During the application of OpenMP-parallelization, the following neural network mechanisms were optimized:
- Convolution Layer.
- The layer of the inverse convolution (Deconvolution).
- Layer of local normalization (Local response normalization, LRN).
- Layer with semi-linear activation function (Rectified-Linear Unit, ReLU)
- Layer with Softmax activation function.
- Concatenation Layer
- Utilities for OpenBLAS optimization, such as the vPowx operation - y [i] = x [i] β, the operations caffe_set , caffe_copy , and caffe_rng_bernoulli .
- A layer of spatial union, or subsampling (Pooling).
- Layer “thinning” the network to prevent the effect of retraining (Dropout).
- Batch normalization layer.
- Data Layer
- Layer for performing elementwise operations (Eltwise).
▍ Layer convolution
The convolution layer, which is quite consistent with its name, convolves the input data using a set of weights modified in the course of training the network, or filters, each of which allows you to get one feature map in the output image. This optimization prevents the underutilization of hardware resources for a single set of input feature maps.
template
void ConvolutionLayer::Forward_cpu(const vector*>& \
bottom, const vector*>& top) {
const Dtype* weight = this->blobs_[0]->cpu_data();
// Если имеется больше доступных потоков, чем пакетов для обработки, значит
// мы впустую используем ресурсы (меньше пакетов, чем 36
// на нашей тестовой системе).
// Сообщим об этом MKL.
for (int i = 0; i < bottom.size(); ++i) {
const Dtype* bottom_data = bottom[i]->cpu_data();
Dtype* top_data = top[i]->mutable_cpu_data();
#ifdef _OPENMP
#pragma omp parallel for num_threads(this->num_of_threads_)
#endif
for (int n = 0; n < this->num_; ++n) {
this->forward_cpu_gemm(bottom_data + n*this->bottom_dim_,
weight,
top_data + n*this->top_dim_);
if (this->bias_term_) {
const Dtype* bias = this->blobs_[1]->cpu_data();
this->forward_cpu_bias(top_data + n * this->top_dim_, bias);
}
}
}
} We handle k = min (num_threads, batch_size) sets of input_feature map sets . For example, k im2col operations occur in parallel and k calls to Intel MKL are performed . Intel MKL switches to single-threaded execution mode automatically and overall performance is better than before when Intel MKL processed one packet. This behavior is specified in the src / caffe / layers / base_conv_layer.cpp source file. This is an implementation of optimized multi-threaded processing using OpenMP from the src / caffe / layers / conv_layer.cpp source file.
▍ Layer subsampling
Max-pooling, average-pooling, and stochastic-pooling (not yet implemented) are different downsampling methods, with max-pooling being the most popular method. The subsampling layer splits the result obtained from the previous layer into a set of usually non-overlapping rectangular fragments. For each such fragment, the layer then displays the maximum (max-pooling), arithmetic mean (average-pooling), or (in the future) stochastic value (stochastic-pooling) obtained from the multinomial distribution formed from the activation functions of each fragment.
Subsampling layers are useful in convolutional networks for three main reasons:
- Subsampling reduces the dimension of the task and the computational load on the overlying layers.
- The subsample for the underlying layers allows convolution kernels in the layers above to cover large areas of input data, and thus learn more complex attributes. For example, the core of a layer below is usually trained to recognize small image elements, while the core of a layer above can learn to recognize more complex structures, such as images of forests or beaches.
- The max-pooling method increases network resilience to image shift. Of the eight possible directions in which a 2x2 fragment (the normal size of the sub-sampling window) can be shifted by one pixel, three will give the same maximum value. For a 3x3 window, already five directions will give the same maximum value.
A subsample works on a single feature map, so we used Xbyak to perform an efficient build procedure that would help us create the selection we need for one or more input feature maps. This technique can be implemented for a packet of input feature maps when the procedure is executed in parallel in OpenMP.
Subsampling layer calculations are performed in parallel using OpenMP multithreading. This is possible due to the fact that the images are independent:
#ifdef _OPENMP
#pragma omp parallel for collapse(2)
#endif
for (int image = 0; image < num_batches; ++image)
for (int channel = 0; channel < num_channels; ++channel)
generator_func(bottom_data, top_data, top_count, image, image+1,
mask, channel, channel+1, this, use_top_mask);
}Thanks to the expression collapse (2), the OpenMP #pragma omp parallel directive extends to both nested for loops, which loop through the images in the packet and image channels, combining the loops into one and executing what happened in parallel.
▍ Softmax layer and loss function
The loss function is a key component in machine learning. It is this function that is used when comparing the network output with the target, to search for errors. After that, the network weights are adjusted to reduce the value of this function, that is, to reduce the error, to deviate what the network produces from the desired output. In our model, softmax is used as a loss function (layer type is SoftmaxWithLoss).
Such an activation function is used when the network outputs symbolize the probability of certain events, or, as in our case, the probability of images belonging to different classes. In particular, in multinomial logistic regression (the problem of classification into many classes), the input for this function is the result of Kdifferent linear functions, and the predicted probability of the j- th class for the vector x is calculated by the following formula:
In multithreaded execution of these calculations, an approach is applied using the main and subordinate threads. So, the main thread starts a certain number of subordinates, distributing tasks between them. Slave threads are then executed in parallel, as they are assigned to different cores.
For example, in the following code, the parallel execution of individual arithmetic operations with independent access to data is implemented by separating the calculations for different image channels:
// разделение
#ifdef _OPENMP
#pragma omp parallel for
#endif
for (int j = 0; j < channels; j++) {
caffe_div(inner_num_, top_data + j*inner_num_, scale_data,
top_data + j*inner_num_);
}▍ReLU and sigmoidal activation functions in fully connected layers
ReLU is today the most popular class of nonlinear functions used in deep learning algorithms. Fully connected layers are element-wise operators that take a binary object (blob in Caffe terminology) produced by the underlying layer and feed the transformed dataset of the same size onto the overlying layer. (Such a data set is a regular array representing the unified interface of the Caffe platform. When data and errors found are distributed over the network, Caffe works with information in the form of such objects).
The layer with the activation function ReLU takes the input value x and outputs the same x if it is greater than zero, and multiplies negative values by the negative_slope parameter using the following formula:
By default, the value of the negative_slope parameter is zero, which is equivalent to the standard ReLU function, which returns the maximum value after comparing the value passed to it with zero: max (x, 0) . Due to the independence of the activation process from the data, each data set can be processed in parallel:
template
void ReLULayer::Forward_cpu(const vector*>& bottom,
const vector*>& top) {
const Dtype* bottom_data = bottom[0]->cpu_data();
Dtype* top_data = top[0]->mutable_cpu_data();
const int count = bottom[0]->count();
Dtype negative_slope=this->layer_param_.relu_param().negative_slope();
#ifdef _OPENMP
#pragma omp parallel for
#endif
for (int i = 0; i < count; ++i) {
top_data[i] = std::max(bottom_data[i], Dtype(0))
+ negative_slope * std::min(bottom_data[i], Dtype(0));
}
} Similar parallel computing can also be used in the error back propagation procedure:
template
void ReLULayer::Backward_cpu(const vector*>& top,
const vector& propagate_down,
const vector*>& bottom) {
if (propagate_down[0]) {
const Dtype* bottom_data = bottom[0]->cpu_data();
const Dtype* top_diff = top[0]->cpu_diff();
Dtype* bottom_diff = bottom[0]->mutable_cpu_diff();
const int count = bottom[0]->count();
Dtype negative_slope=this->layer_param_.relu_param().negative_slope();
#ifdef _OPENMP
#pragma omp parallel for
#endif
for (int i = 0; i < count; ++i) {
bottom_diff[i] = top_diff[i] * ((bottom_data[i] > 0)
+ negative_slope * (bottom_data[i] <= 0));
}
}
} In the same way, we can parallelize the calculation of the sigmoid function S (x) = 1 / (1 + exp (-x)):
#ifdef _OPENMP
#pragma omp parallel for
#endif
for (int i = 0; i < count; ++i) {
top_data[i] = sigmoid(bottom_data[i]);
}Since MKL does not provide basic mathematical operations for implementing ReLU functions, in order to add this functionality to the system, we tried to implement an optimized assembler version of the ReLU layer (using Xbyak). However, after testing, we did not find a noticeable increase in performance on Intel Xeon processors. Perhaps this is because of the limited memory bandwidth. The parallelization of existing C ++ code was good enough to improve overall performance.
conclusions
In the previous section, we examined the various components and layers of neural networks, and how the data processed in these layers are distributed among OpenMP and Intel MKL streams. The processor usage histogram below shows how often a certain number of threads are executed in parallel after code optimization.
General results of the analysis of the execution of the implementation of Caffe, optimized for Intel architecture, on the CIFAR-10 task in Intel VTune Amplifier XE 2017 beta
Using Caffe, optimized for Intel architecture, the number of simultaneously running threads has increased significantly. The runtime on our test system fell from 37 seconds for the non-optimized BVLC Caffe code to just 3.6 seconds for the optimized version. Overall productivity has grown more than 10 times.
As shown in the Elapsed Time section, at the top of the figure, part of the execution time refers to the Spin Time indicator, which indicates the time spent on waiting, and not on useful work. As a result, productivity does not grow linearly with increasing number of threads (in accordance with Amdal's law). In addition, there are still portions running sequentially that are not parallelized using OpenMP. The reinitialization of parallel sections of OpenMP has been significantly optimized for recent implementations of the OpenMP library, but it still poses a rather noticeable additional load on the system. Moving parallel sections to the main function can potentially improve performance even more, but this will require significant code refactoring.
The figure below summarizes the optimization techniques described and the code processing principles that we followed while optimizing Caffe for Intel architecture.
Step-by-step approach of the Intel Modern Code program
During the tests, we used the Intel VTune Amplifier XE 2017 beta to find the code sections that create the greatest load on the system, and the optimization of which can bring a noticeable performance gain. We have implemented scalar and sequential optimizations, including eliminating code whose execution results turn out to be the same with repeated calls. We also reduced or simplified arithmetic operations, optimizing cycles and checking conditions. Next, we improved the code based on its vectorization, following the general principles outlined in the materialabout automatic vectorization in GCC. Using the Xbyak JIT assembler allowed us to use SIMD instructions more efficiently.
We implemented multithreading for calculations performed inside layers of a neural network using the OpenMP library, where operations on images or channels were independent of data. The final step in applying the approach of the Intel Modern Code program included scaling the application, which was originally executed on one node, to a multi-core architecture, and to a cluster environment with many nodes. This, at the moment, is the main subject of our study. In addition, we applied cache-oriented reuse optimizations to improve computational performance. Details about such optimizations can be found here.. Code optimization for the Intel Xeon Phi x200 family of processors included the use of high bandwidth MCDRAM and NUMA operation.
Optimizing Caffe for Intel architecture not only significantly improved computing performance, but also enabled the extraction of much more complex feature sets from graphic data. If you use Caffe in your own neural network research, running the code on systems with Intel processors, an optimized version of this platform will significantly expand your capabilities.
In addition, we hope that our story about improving the code, about tools for analyzing the speed of work and optimizing programs, will help you in improving the performance of your applications, both in the field of deep learning of neural networks, and any others.
Intel would like to thank Boris Ginzburg for his ideas and initial contribution to the development of the multi-threaded OpenMP version of Caffe, optimized for Intel architecture.
Details about the Intel Modern Code program can be found here and here .