How does the Python parser work, and how to triple its memory consumption
Anyone who has studied the structure of programming languages can roughly imagine how they work: the parser, in accordance with the formal grammar of the JP, turns the input text into some tree view, which the next steps work with (semantic analysis, various transformations, and code generation).

In Python, things are a little more complicated: there are two parsers. The first parser is guided by the grammar specified in the file
The easiest way to illustrate the operation of the first parser is with an example. Let us have a program
(It would be convenient to follow the following description of the parser’s work on this listing — for example, by opening it in the next tab.)
The parser starts parsing from the spacecraft for
Only one arc
There is a standard module for working with KSD in Python
In its source code (
It is easy to guess that such a uniform code could be automatically generated using formal grammar. It’s a little harder to guess that such a code is already generated automatically - this is exactly how the machines used by the first parser work! Above, I then explained in detail its structure in order to explain how in March of this year I proposed replacing all these sheets of the handwritten code, which must be edited every time the grammar changes, with a run of all the same automatically generated spacecraft that it uses the parser itself. This is to talk about whether programmers need to know the algorithms.
In June, my patch was accepted, so in Python 3.6+ the above sheets in
Working with such a bulky and excessive KSD, as shown above, is quite inconvenient; and therefore, the second parser (
Instead of working with KSD using a module
As soon as the ASD is created, the KSD is no longer necessary, and all the memory occupied by it is freed; therefore, for a "long-playing" program in Python, it does not really matter how much memory the KSD takes. On the other hand, for large, but “fast-firing” scripts (for example, searching for a value in a huge
The need to pass along long "bamboo branches" makes the code
Repeatedly repeating throughout the second parser
But is it something that prevents immediately during the creation of the KSD to remove the "one-child" nodes, substituting their children for them? After all, this will save a lot of memory and simplify the second parser, allowing you to get rid of multiple repetition
In March, along with the aforementioned patch for
The compressed KSD for our sample code contains a total of 21 nodes:
With my patch, a standard set of benchmarks shows a reduction in memory consumption by a process of
But alas, for half a year since I proposed my patch, none of the maintainers dared to revise it - it is so big and scary. In September, Guido van Rossum himself answered me : “Since all this time no one has shown interest in the patch, which means that parser does not care about anyone else's memory consumption. So there is no point in wasting the maintainers' time on his review. ” I hope this article explains why my big and scary patch is really necessary and useful; and I hope that after this explanation the Python community will get their hands on it.
In Python, things are a little more complicated: there are two parsers. The first parser is guided by the grammar specified in the file
Grammar/Grammarin the form of regular expressions (with not quite the usual syntax). According to this grammar, with the help of Parser/pgencompilation time pythona whole set of finite state machines is generated that recognize the given regular expressions - one KA for each nonterminal. The format of the resulting spacecraft set is described in Include/grammar.h, and the spacecraft themselves are set in Python/graminit.c, in the form of a global structure _PyParser_Grammar. Terminal symbols are defined in Include/token.h, and they correspond to the numbers 0..56; non-terminal numbers start at 256. The easiest way to illustrate the operation of the first parser is with an example. Let us have a program
if 42: print("Hello world").Here is the part of the grammar corresponding to the analysis of our program
single_input: NEWLINE | simple_stmt | compound_stmt NEWLINE
compound_stmt: if_stmt | while_stmt | for_stmt | try_stmt | with_stmt | funcdef | classdef | decorated | async_stmt
if_stmt: 'if' test ':' suite ('elif' test ':' suite) * ['else' ':' suite]
suite: simple_stmt | NEWLINE INDENT stmt + DEDENT
simple_stmt: small_stmt (';' small_stmt) * [';'] NEWLINE
small_stmt: expr_stmt | del_stmt | pass_stmt | flow_stmt | import_stmt | global_stmt | nonlocal_stmt | assert_stmt
expr_stmt: testlist_star_expr (annassign | augassign (yield_expr | testlist) | ('=' (yield_expr | testlist_star_expr)) *)
testlist_star_expr: (test | star_expr) (',' (test | star_expr)) * [',']
test: or_test ['if' or_test 'else' test] | lambdef
or_test: and_test ('or' and_test) *
and_test: not_test ('and' not_test) *
not_test: 'not' not_test | comparison
comparison: expr (comp_op expr) *
expr: xor_expr ('|' xor_expr) *
xor_expr: and_expr ('^' and_expr) *
and_expr: shift_expr ('&' shift_expr) *
shift_expr: arith_expr (('<<' | '>>') arith_expr) *
arith_expr: term (('+' | '-') term) *
term: factor (('*' | '@' | '/' | '%' | '//') factor) *
factor: ('+' | '-' | '~') factor | power
power: atom_expr ['**' factor]
atom_expr: [AWAIT] atom trailer *
atom: '(' [yield_expr | testlist_comp] ')' | '[' [testlist_comp] ']' | '{' [dictorsetmaker] '}' |
NAME | NUMBER | STRING + | '...' | 'None' | 'True' | 'False'
trailer: '(' [arglist] ')' | '[' subscriptlist ']' | '.' NAME
arglist: argument (',' argument) * [',']
argument: test [comp_for] | test '=' test | '**' test | '*' test
And here are the parts of the _PyParser_Grammar structure interesting to us in Python / graminit.c
static arc arcs_0_0[3] = {
{2, 1},
{3, 1},
{4, 2},
};
static arc arcs_0_1[1] = {
{0, 1},
};
static arc arcs_0_2[1] = {
{2, 1},
};
static state states_0[3] = {
{3, arcs_0_0},
{1, arcs_0_1},
{1, arcs_0_2},
};
//...
static arc arcs_39_0[9] = {
{91, 1},
{92, 1},
{93, 1},
{94, 1},
{95, 1},
{19, 1},
{18, 1},
{17, 1},
{96, 1},
};
static arc arcs_39_1[1] = {
{0, 1},
};
static state states_39[2] = {
{9, arcs_39_0},
{1, arcs_39_1},
};
//...
static arc arcs_41_0[1] = {
{97, 1},
};
static arc arcs_41_1[1] = {
{26, 2},
};
static arc arcs_41_2[1] = {
{27, 3},
};
static arc arcs_41_3[1] = {
{28, 4},
};
static arc arcs_41_4[3] = {
{98, 1},
{99, 5},
{0, 4},
};
static arc arcs_41_5[1] = {
{27, 6},
};
static arc arcs_41_6[1] = {
{28, 7},
};
static arc arcs_41_7[1] = {
{0, 7},
};
static state states_41[8] = {
{1, arcs_41_0},
{1, arcs_41_1},
{1, arcs_41_2},
{1, arcs_41_3},
{3, arcs_41_4},
{1, arcs_41_5},
{1, arcs_41_6},
{1, arcs_41_7},
};
//...
static dfa dfas[85] = {
{256, "single_input", 0, 3, states_0,
"\004\050\340\000\002\000\000\000\012\076\011\007\262\004\020\002\000\300\220\050\037\102"},
//...
{270, "simple_stmt", 0, 4, states_14,
"\000\040\200\000\002\000\000\000\012\076\011\007\000\000\020\002\000\300\220\050\037\100"},
//...
{295, "compound_stmt", 0, 2, states_39,
"\000\010\140\000\000\000\000\000\000\000\000\000\262\004\000\000\000\000\000\000\000\002"},
{296, "async_stmt", 0, 3, states_40,
"\000\000\040\000\000\000\000\000\000\000\000\000\000\000\000\000\000\000\000\000\000\000"},
{297, "if_stmt", 0, 8, states_41,
"\000\000\000\000\000\000\000\000\000\000\000\000\002\000\000\000\000\000\000\000\000\000"},
// ^^^
//...
};
static label labels[176] = {
{0, "EMPTY"},
{256, 0},
{4, 0}, // №2
{270, 0}, // №3
{295, 0}, // №4
//...
{305, 0}, // №26
{11, 0}, // №27
//...
{297, 0}, // №91
{298, 0},
{299, 0},
{300, 0},
{301, 0},
{296, 0},
{1, "if"}, // №97
//...
};
grammar _PyParser_Grammar = {
86,
dfas,
{176, labels},
256
};
(It would be convenient to follow the following description of the parser’s work on this listing — for example, by opening it in the next tab.)
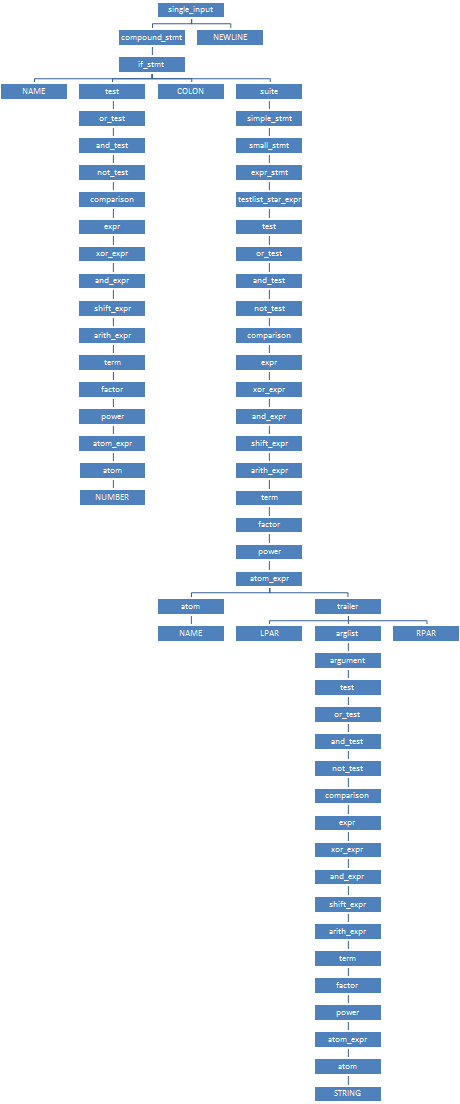
The parser starts parsing from the spacecraft for
single_input; this spacecraft is given by an array states_0of three states. Three arcs ( arcs_0_0) corresponding to the input symbols NEWLINE(label No. 2, symbol No. 4), simple_stmt(label No. 3, symbol No. 270) and compound_stmt(label No. 4, symbol No. 295) emerge from the initial state . The input terminal "if"(symbol No. 1, label No. 97) is included in the set d_firstfor compound_stmt, but not for simple_stmt, the bit \ 002 in the 13th byte of the set corresponds to it. (If during the analysis it turns out that the next terminal is included in the setsd_firstfor several outgoing arcs at once, the parser displays a message that the grammar is ambiguous, and refuses to continue parsing.) So, the parser moves along the arc {4, 2}to state No. 2, and at the same time switches to the spacecraft compound_stmtspecified by the array states_39. In this spacecraft, nine arcs ( arcs_39_0) immediately exit from the initial state ; among them we select the arc {91, 1}corresponding to the input symbol if_stmt(No. 297). The parser switches to state No. 1 and switches to the spacecraft if_stmtspecified by the array states_41.Only one arc
{97, 1} "if". On it, the parser goes into state No. 1, from where again the only arc {26, 2}corresponding to the nonterminal test(No. 305) comes out. On this arc, the parser enters state No. 2 and switches to the spacecraft test, and so on. After a long, long-lasting transformation of the number 42into a non-terminal test, the parser will return to state No. 2, from which the only arc {27, 3}corresponding to the terminal COLON(symbol No. 11) emerges , and continue parsing the non-terminal if_stmt. As a result of its analysis, the parser will create a node of a specific syntax tree (structure node), which will have node type No. 297, and four children - types No. 1 (NAME), No. 305 ( test), No. 11 ( COLON) and No. 304 ( suite). In state No. 4, the creation of the node for if_stmtcompletion will be completed, the parser will return to state No. 1 of the spacecraft compound_stmt, and the newly created node for if_stmtwill become the only child of the node corresponding to it compound_stmt. The entire KSD of our program will look like the one shown on the right. Notice how the short program of seven terminals NAME NUMBER COLON NAME LPAR STRING RPARturned into a “bamboo” - a huge, almost unbranched parse tree of as many as 64 nodes! If you count in bytes, then the original program takes 27 bytes, and its KSD is two orders of magnitude more: one and a half kilobytes on a 32-bit system, and three on a 64-bit one! (64 nodes of 24 or 48 bytes each). It is because of the unrestrained stretching KSD attempts to pass throughpythonsource files of only a few tens of megabytes in size lead to fatal MemoryError. There is a standard module for working with KSD in Python
parser:$ python
Python 3.7.0a0 (default:98c078fca8e0, Oct 31 2016, 08:33:23)
[GCC 4.7.3] on linux
Type "help", "copyright", "credits" or "license" for more information.
>>> import parser
>>> parser.suite('if 42: print("Hello world")').tolist()
[257, [269, [295, [297, [1, 'if'], [305, [309, [310, [311, [312, [315, [316, [317, [318, [319, [320, [321, [322, [323, [324, [2, '42']]]]]]]]]]]]]]]], [11, ':'], [304, [270, [271, [272, [274, [305, [309, [310, [311, [312, [315, [316, [317, [318, [319, [320, [321, [322, [323, [324, [1, 'print']], [326, [7, '('], [334, [335, [305, [309, [310, [311, [312, [315, [316, [317, [318, [319, [320, [321, [322, [323, [324, [3, '"Hello world"']]]]]]]]]]]]]]]]]], [8, ')']]]]]]]]]]]]]]]]]]], [4, '']]]]]], [4, ''], [0, '']]
>>>
In its source code (
Modules/parsermodule.c), to check the CSD for compliance with the Python grammar, there were> 2000 handwritten lines that looked something like this://...
/* simple_stmt | compound_stmt
*
*/
static int
validate_stmt(node *tree)
{
int res = (validate_ntype(tree, stmt)
&& validate_numnodes(tree, 1, "stmt"));
if (res) {
tree = CHILD(tree, 0);
if (TYPE(tree) == simple_stmt)
res = validate_simple_stmt(tree);
else
res = validate_compound_stmt(tree);
}
return (res);
}
static int
validate_small_stmt(node *tree)
{
int nch = NCH(tree);
int res = validate_numnodes(tree, 1, "small_stmt");
if (res) {
int ntype = TYPE(CHILD(tree, 0));
if ( (ntype == expr_stmt)
|| (ntype == del_stmt)
|| (ntype == pass_stmt)
|| (ntype == flow_stmt)
|| (ntype == import_stmt)
|| (ntype == global_stmt)
|| (ntype == nonlocal_stmt)
|| (ntype == assert_stmt))
res = validate_node(CHILD(tree, 0));
else {
res = 0;
err_string("illegal small_stmt child type");
}
}
else if (nch == 1) {
res = 0;
PyErr_Format(parser_error,
"Unrecognized child node of small_stmt: %d.",
TYPE(CHILD(tree, 0)));
}
return (res);
}
/* compound_stmt:
* if_stmt | while_stmt | for_stmt | try_stmt | with_stmt | funcdef | classdef | decorated
*/
static int
validate_compound_stmt(node *tree)
{
int res = (validate_ntype(tree, compound_stmt)
&& validate_numnodes(tree, 1, "compound_stmt"));
int ntype;
if (!res)
return (0);
tree = CHILD(tree, 0);
ntype = TYPE(tree);
if ( (ntype == if_stmt)
|| (ntype == while_stmt)
|| (ntype == for_stmt)
|| (ntype == try_stmt)
|| (ntype == with_stmt)
|| (ntype == funcdef)
|| (ntype == async_stmt)
|| (ntype == classdef)
|| (ntype == decorated))
res = validate_node(tree);
else {
res = 0;
PyErr_Format(parser_error,
"Illegal compound statement type: %d.", TYPE(tree));
}
return (res);
}
//...
It is easy to guess that such a uniform code could be automatically generated using formal grammar. It’s a little harder to guess that such a code is already generated automatically - this is exactly how the machines used by the first parser work! Above, I then explained in detail its structure in order to explain how in March of this year I proposed replacing all these sheets of the handwritten code, which must be edited every time the grammar changes, with a run of all the same automatically generated spacecraft that it uses the parser itself. This is to talk about whether programmers need to know the algorithms.
In June, my patch was accepted, so in Python 3.6+ the above sheets in
Modules/parsermodule.c already, but there are several dozen lines of my code.Working with such a bulky and excessive KSD, as shown above, is quite inconvenient; and therefore, the second parser (
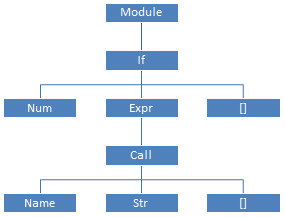
Python/ast.c), written entirely by hand, bypasses the KSD and creates an abstract syntax tree from it . ASD grammar is described in the file Parser/Python.asdl; for our program, the SDA will be as shown on the right.Instead of working with KSD using a module
parser, the documentation recommends using a module astand working with an abstract tree:$ python
Python 3.7.0a0 (default:98c078fca8e0, Oct 31 2016, 08:33:23)
[GCC 4.7.3] on linux
Type "help", "copyright", "credits" or "license" for more information.
>>> import ast
>>> ast.dump(ast.parse('if 42: print("Hello world")'))
"Module(body=[If(test=Num(n=42), body=[Expr(value=Call(func=Name(id='print', ctx=Load()), args=[Str(s='Hello world')], keywords=[]))], orelse=[])])"
>>>
As soon as the ASD is created, the KSD is no longer necessary, and all the memory occupied by it is freed; therefore, for a "long-playing" program in Python, it does not really matter how much memory the KSD takes. On the other hand, for large, but “fast-firing” scripts (for example, searching for a value in a huge
dict-literal), the size of the RDC will determine the memory consumption of the script. All this, in addition to the fact that the size of the KSD determines whether there is enough memory in order to download and run the program. The need to pass along long "bamboo branches" makes the code
Python/ast.csimply disgusting:static expr_ty
ast_for_expr(struct compiling *c, const node *n)
{
//...
loop:
switch (TYPE(n)) {
case test:
case test_nocond:
if (TYPE(CHILD(n, 0)) == lambdef ||
TYPE(CHILD(n, 0)) == lambdef_nocond)
return ast_for_lambdef(c, CHILD(n, 0));
else if (NCH(n) > 1)
return ast_for_ifexpr(c, n);
/* Fallthrough */
case or_test:
case and_test:
if (NCH(n) == 1) {
n = CHILD(n, 0);
goto loop;
}
// обработка булевых операций
case not_test:
if (NCH(n) == 1) {
n = CHILD(n, 0);
goto loop;
}
// обработка not_test
case comparison:
if (NCH(n) == 1) {
n = CHILD(n, 0);
goto loop;
}
// обработка comparison
case star_expr:
return ast_for_starred(c, n);
/* The next five cases all handle BinOps. The main body of code
is the same in each case, but the switch turned inside out to
reuse the code for each type of operator.
*/
case expr:
case xor_expr:
case and_expr:
case shift_expr:
case arith_expr:
case term:
if (NCH(n) == 1) {
n = CHILD(n, 0);
goto loop;
}
return ast_for_binop(c, n);
// case yield_expr: и его обработка
case factor:
if (NCH(n) == 1) {
n = CHILD(n, 0);
goto loop;
}
return ast_for_factor(c, n);
case power:
return ast_for_power(c, n);
default:
PyErr_Format(PyExc_SystemError, "unhandled expr: %d", TYPE(n));
return NULL;
}
/* should never get here unless if error is set */
return NULL;
}
Repeatedly repeating throughout the second parser
if (NCH(n) == 1) n = CHILD(n, 0);- sometimes, as in this function, inside the cycle - mean "if the current node of the KSD has only one child, then instead of the current node it is necessary to consider its child." But is it something that prevents immediately during the creation of the KSD to remove the "one-child" nodes, substituting their children for them? After all, this will save a lot of memory and simplify the second parser, allowing you to get rid of multiple repetition
goto loop;throughout the code, from the look of which Dijkstra would turn around with a top in his coffin! In March, along with the aforementioned patch for
Modules/parsermodule.c, I proposed another patch , which:- Adds the automatic “compression” of non-branching subtrees to the first parser - at the time of folding (creating the KSD node and returning from the current spacecraft to the previous one), the “one-child” node of the appropriate type is replaced by its child:
diff -r ffc915a55a72 Parser/parser.c --- a/Parser/parser.c Mon Sep 05 00:01:47 2016 -0400 +++ b/Parser/parser.c Mon Sep 05 08:30:19 2016 +0100 @@ -52,16 +52,16 @@ #ifdef Py_DEBUG static void s_pop(stack *s) { if (s_empty(s)) Py_FatalError("s_pop: parser stack underflow -- FATAL"); - s->s_top++; + PyNode_Compress(s->s_top++->s_parent); } #else /* !Py_DEBUG */ -#define s_pop(s) (s)->s_top++ +#define s_pop(s) PyNode_Compress((s)->s_top++->s_parent) #endif diff -r ffc915a55a72 Python/ast.c --- a/Python/ast.c Mon Sep 05 00:01:47 2016 -0400 +++ b/Python/ast.c Mon Sep 05 08:30:19 2016 +0100 @@ -5070,3 +5056,24 @@ FstringParser_Dealloc(&state); return NULL; } + +void PyNode_Compress(node* n) { + if (NCH(n) == 1) { + node* ch; + switch (TYPE(n)) { + case suite: case comp_op: case subscript: case atom_expr: + case power: case factor: case expr: case xor_expr: + case and_expr: case shift_expr: case arith_expr: case term: + case comparison: case testlist_star_expr: case testlist: + case test: case test_nocond: case or_test: case and_test: + case not_test: case stmt: case dotted_as_name: + if (STR(n) != NULL) + PyObject_FREE(STR(n)); + ch = CHILD(n, 0); + *n = *ch; + // All grandchildren are now adopted; don't need to free them, + // so no need for PyNode_Free + PyObject_FREE(ch); + } + } +} - Correctly corrects the second parser, excluding from it bypassing the "bamboo branches": for example, the above function
ast_for_expris replaced by:static expr_ty ast_for_expr(struct compiling *c, const node *n) { //... switch (TYPE(n)) { case lambdef: case lambdef_nocond: return ast_for_lambdef(c, n); case test: case test_nocond: assert(NCH(n) > 1); return ast_for_ifexpr(c, n); case or_test: case and_test: assert(NCH(n) > 1); // обработка булевых операций case not_test: assert(NCH(n) > 1); // обработка not_test case comparison: assert(NCH(n) > 1); // обработка comparison case star_expr: return ast_for_starred(c, n); /* The next five cases all handle BinOps. The main body of code is the same in each case, but the switch turned inside out to reuse the code for each type of operator. */ case expr: case xor_expr: case and_expr: case shift_expr: case arith_expr: case term: assert(NCH(n) > 1); return ast_for_binop(c, n); // case yield_expr: и его обработка case factor: assert(NCH(n) > 1); return ast_for_factor(c, n); case power: return ast_for_power(c, n); case atom: return ast_for_atom(c, n); case atom_expr: return ast_for_atom_expr(c, n); default: PyErr_Format(PyExc_SystemError, "unhandled expr: %d", TYPE(n)); return NULL; } /* should never get here unless if error is set */ return NULL; }
On the other hand, for many nodes, as a result of “branch compression," children can now be of new types, and therefore, in many places in the code you have to add new conditions. - Since the “squeezed KSD” no longer corresponds to the Python grammar, then to check its correctness,
Modules/parsermodule.cinstead of the “raw”_PyParser_Grammarone, we now need to use automata corresponding to the “transitive closure” of the grammar: for example, for a pair of productions
—The following “transitive” products are added:or_test :: = and_test test :: = or_test 'if' or_test 'else' test
test :: = or_test 'if' and_test 'else' test test :: = and_test 'if' or_test 'else' test test :: = and_test 'if' and_test 'else' test
During module initializationparser, the functionInit_ValidationGrammarbypasses the auto-generated spacecraft in_PyParser_Grammar, on the basis of them creates “transitively closed” spacecraft, and saves them in the structureValidationGrammar. To verify the correctness of the KSD is used preciselyValidationGrammar.
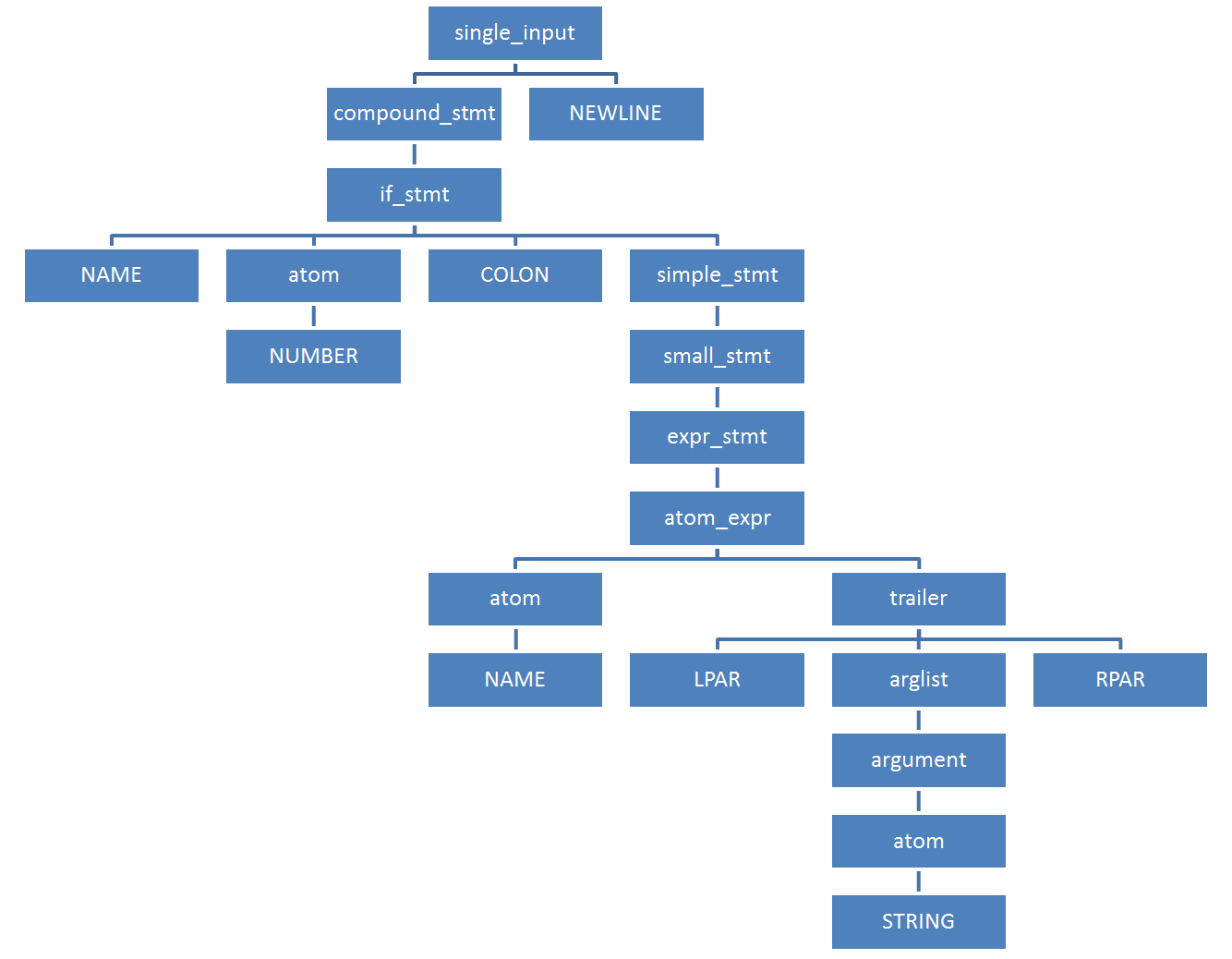
The compressed KSD for our sample code contains a total of 21 nodes:
$ python
Python 3.7.0a0 (default:98c078fca8e0+, Oct 31 2016, 09:00:27)
[GCC 4.7.3] on linux
Type "help", "copyright", "credits" or "license" for more information.
>>> import parser
>>> parser.suite('if 42: print("Hello world")').tolist()
[257, [295, [297, [1, 'if'], [324, [2, '42']], [11, ':'], [270, [271, [272, [323, [324, [1, 'print']], [326, [7, '('], [334, [335, [324, [3, '"Hello world"']]]], [8, ')']]]]], [4, '']]]], [4, ''], [0, '']]
>>>
With my patch, a standard set of benchmarks shows a reduction in memory consumption by a process of
pythonup to 30% , with unchanged operating time. On degenerate examples, the reduction in memory consumption reaches threefold !But alas, for half a year since I proposed my patch, none of the maintainers dared to revise it - it is so big and scary. In September, Guido van Rossum himself answered me : “Since all this time no one has shown interest in the patch, which means that parser does not care about anyone else's memory consumption. So there is no point in wasting the maintainers' time on his review. ” I hope this article explains why my big and scary patch is really necessary and useful; and I hope that after this explanation the Python community will get their hands on it.