How much time did you spend on movies?
The emergence of ideas
Recently I was visiting friends and we were choosing a movie, and I, as a burned film fan, (in fact, not so much as burned) rejected everything as viewed. And I was asked a logical question, but what did you not look at all? To which I said that I am conducting a film search and every film that I watched, I mark either with a rating, or just a tick that the viewing took place. And here in my head I had a question, but how much time did I spend on films? Steam has convenient statistics on the game, but there is nothing like that in the movies. So I decided to take up this idea.
What is there with the implementation?
I’ve been developing on ASP.NET for several years now and I got used to C #, I first wanted to write this utility on it, but then there was a problem with a heavy environment and, since I am a little familiar with Python, I resorted to his help.
And where to get the data?
And here I faced the first problem. I naively assumed that the movie search has an official public API and some free version. But I did not find anything like that. It is possible to request through technical support, but even there they are given out only for the n-th sum, and I wrote it for myself and did not want to pay for it.
Naturally, I had to consider the option of parsing pages and it was there that I stopped.
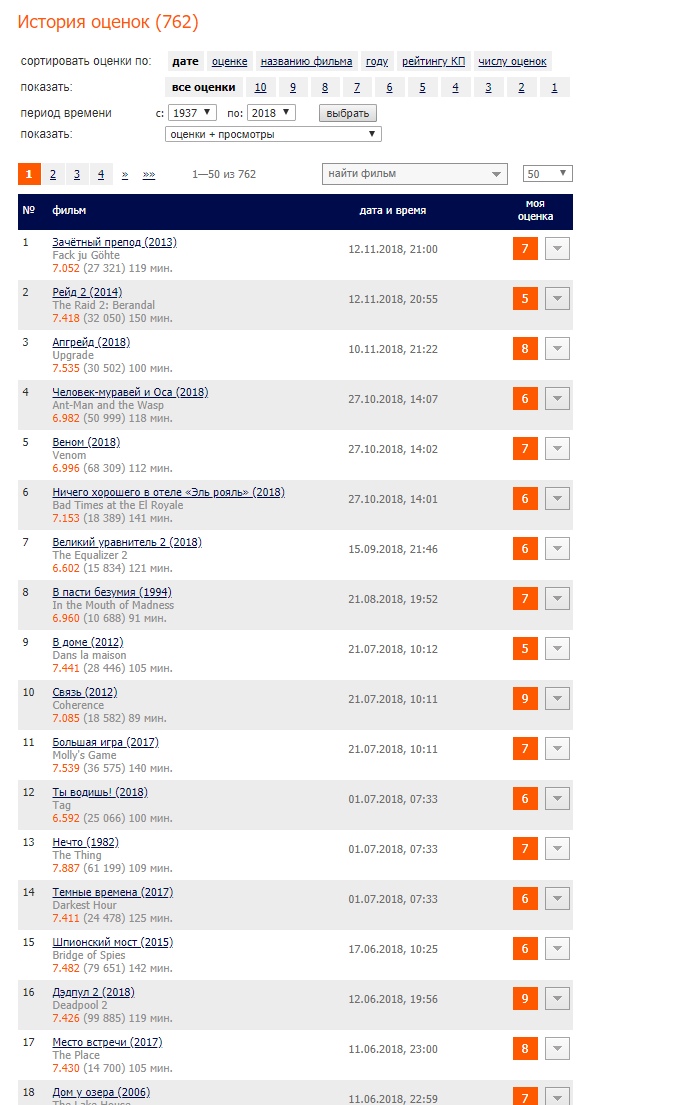
Everyone in the profile has a list of viewed film with a small description, which includes the duration of the picture. Thus, I can get only a few pages (I have 762 films and it was necessary to get only 17 pages) and calculate the time spent.
No sooner said than done.
classKinopoiskParser:def__init__(self, user_id, current_page=1):
self._user_id = user_id
self._current_page = current_page
self._wasted_time_in_minutes = 0defcalculate_wasted_time(self):whileTrue:
film_list_url = f'https://www.kinopoisk.ru/user/{self._user_id}' \
f'/votes/list/ord/date/genre/films/page/{self._current_page}/#list'try:
film_response = requests.get(film_list_url).text
except BaseException:
proxy_manager.update_proxy()
continue
user_page = BeautifulSoup(film_response, "html.parser")
is_end = kinopoisk_parser._check_that_is_end_of_film_list(user_page)
if is_end:
break
wasted_time = self._get_film_duration_on_page(user_page)
self._wasted_time_in_minutes += wasted_time
print(f'Page {self._current_page}, wasted time {self._wasted_time_in_minutes}')
self._move_next_page()
defget_wasted_time(self):return self._wasted_time_in_minutes
def_move_next_page(self):
self._current_page += 1 @staticmethoddef_get_film_duration_on_page(user_page):try:
wasted_time = 0
film_list = user_page.findAll("div", {"class": "profileFilmsList"})[0].findAll("div", {"class": "item"})
for film in film_list:
film_description = film.findAll("span")
if len(film_description) <= 1:
continue
film_duration_in_minutes = int(film_description[1].string.split(" ")[0])
wasted_time = wasted_time + film_duration_in_minutes
return wasted_time
except BaseException:
print("Something went wrong.")
return0 @staticmethoddef_check_that_is_captcha(html):
captcha_element = html.find_all("a", {"href": "//yandex.ru/support/captcha/"})
return len(captcha_element) > 0 @staticmethoddef_check_that_is_end_of_film_list(html):
error_element = html.find_all("div", {"class": "error-page__container-left"})
return len(error_element) > 0But already at the debugging stage, I ran into the problem that film search blocks requests (approximately, at 4 iterations) and considers them suspicious. And he's right! But I also assumed this option and went over to plan B.
Plan B - change proxies like gloves
Having taken the first available server, which provides an API for receiving ip proxy (I do not advertise any services, I took the first two links from Google), crooked it screwed and continued to write the main code. And an hour later, when I was close to completion, I was blocked by the server, which the API provides! I had to change it to another one, which gives a fixed list, every half hour, for my task it is enough. But if the list suddenly ends, you can go back to the previous version (they give out about 24-20 proxy every 24 hours).
classProxyManager:def__init__(self):
self._current_proxy = ""
self._current_proxy_index = -1
self._proxy_list = []
self._get_proxy_list()
defget_proxies(self):
proxies = {
"http": self._current_proxy,
"https": self._current_proxy
}
return proxies
defupdate_proxy(self):
self._current_proxy_index += 1if self._current_proxy_index == len(self._proxy_list):
print("Proxies are ended")
print("Try get alternative proxy")
proxy_ip_with_port = self._get_another_proxy()
print("Proxy updated to " + proxy_ip_with_port)
self._current_proxy = f'http://{proxy_ip_with_port}'return self._current_proxy
proxy_ip_with_port = self._proxy_list[self._current_proxy_index]
print("Proxy updated to " + proxy_ip_with_port)
self._current_proxy = f'http://{proxy_ip_with_port}'return self._current_proxy
@staticmethoddef_get_another_proxy():
proxy_response = requests.get("https://api.getproxylist.com/proxy?protocol[]=http", headers={
'Content-Type': 'application/json'
}).json()
ip = proxy_response['ip']
port = proxy_response['port']
proxy = f'{ip}:{port}'return proxy
def_get_proxy_list(self):
proxy_response = requests.get("http://www.freeproxy-list.ru/api/proxy?anonymity=false&token=demo")
self._proxy_list = proxy_response.text.split("\n")
Combining all this together (at the end I will provide a link to the githab with the final version), I got an excellent piece for calculating the time spent on movies. And he received the cherished number, tadam: "You wasted 84542 minutes or 1409.03 hours or 58.71 day."
Wasted time wasting time wasted
In fact, for good reason. The task was interesting, though hardly necessary at least to someone.
And now I can tell everyone that for almost two months of my life I have been watching a movie!
If it is also interesting for someone to get such "important" statistics for yourself, just copy the id of your profile and run the project with this parameter, and if it’s easy to discard the result in the comments, I’m interested in the movie fan or amateur beginner.
Link to the source code
PS I will also be happy to hear tips on improving the code, since I wrote very little on python and I don’t even fully understand the syntax.