Prediction of the probability of transition of each client of the company to the status of a former member of the club
The authors of the publication are Dmitry Sergeev and Julia Petropavlovskaya .
Recently, Russia's first Virtual Hackathon from Microsoft with the support of Forbes has ended . Our two-person team managed to take first place in the WorldClass nomination, in which it was necessary to predict the likelihood of each client transferring to the status of a former club member. In this article we would like to share our decision and talk about its main stages.
Data preparation
Most of the time was spent in cleaning, restoring and combining data, since datasets were heavily polluted and grouped into four separate categories:
- Customer contracts
- Attendance
- Frost
- Communication between customers and the club
Test and training data sets were broken down by month. Train contained customer information for December 2015, and Test for March 2016. For each of the categories, we combined Train and Test parts for further processing.
Customer contracts
Contracts were the first data set that we took up, since it was there that the target variable was “whether the customer extended his contract”, as well as the contract and customer codes in the amount of 17,631 pieces, which served as keys for combining all the other datasets. A small number of missing values in variables were restored by mods. Then we created features for the season (winter, spring ...), the month and day on which the contract was signed with the club, and the variables "contract duration", "remainder of the days of freezing" and "balance of bonus on the account". Various categorical variables such as age group, club segment, etc. left unchanged.
Attendance
We started by creating a variable - the duration of a one-time trip to a fitness club. 
It turned out that particularly diligent clients can spend almost 9 hours in the club, possibly due to the passage of complex procedures.
Also in the dataset there were categorical variables, the gradations of which we decided to group into more general categories. For example, "Trainer Category":
additional = ['Сотрудник СПА', 'Врач']
coach = ['Тренер мастер', "Тренер фитнес"]
coach_vip = ["Тренер персональный", "Тренер элит"]
other = ['Другое']Similarly - "Service Direction":
sport = ["Тренажерный зал", "Водные программы", "Аэробика", "Боевые искусства", "Mind Body",
"Танцевальные программы", "Игровые программы", "Йога", "Групповые программы"]
health_beauty = ["Солярий", "Парикмахерские услуги", "Лечебный массаж", "Маникюр, педикюр", "Массаж_SF",
"Терапевтические процедуры", "Физиотерапевтические процедуры", "Косметические услуги",
"Аппаратная косметология", "Окрашивание", "Аппаратная косметология_SF", "Врачи", "Врачи_SF",
"Продажа косметических товаров", "Инъекции", "Прочие услуги SPA", "Лечебное питание", "Инъекции_SF", "SPA"]Finally, we added a variable with the frequency of visits to the club per month and the total number of visits in different seasons (winter, spring ..) and grouped the data according to the codes of the clients contained in the dataset under the contracts. In total, out of 3,700,000 records, ~ 15,000 observations remained.
Frost
Initially, we found out that there are duplicates in the dataset. After a little research, it turned out that the same contract number with the same freezing operations is contained in both Train and Test, as the client’s history of frosts was transferred to the test suite. To avoid retraining models in the future, we threw out repeated values from the test.
During the year, each client could freeze his card several times, and it seemed to us useful in some form to preserve the temporary structure of his freeze. To do this, we created four variables for each season of the year, in which we recorded the total number of freezing days spent for a given season. As a result, we got the following data structure:
Communications
There were three main columns in the raw data: Date , View, and Status of the interaction. Such options as “phone call” , “meeting” , “SMS” , etc. were hidden under the “view” , while the “state” was characterized by three levels: “held” , “canceled” , “planned” . As in frosts, we first removed duplicates from the test data to clear them of the client history, and then proceeded to create the variables.
Almost every client had several dozen communications of one kind or another. To compress this information into a single line for later combining using a unique contract code, we created several new features.
First, we broke the variable “Type of interaction” into 3 dummies:
- a personal meeting
- telephone
- other
Then we calculated for each client the total and successful ( "held" ) number of communications. Dividing one into the other received the variable "share of successful communications."
The latest find was the creation of a dummy variable "were there communications over the past two months." We suggested that if a person is going to renew his contract, he will try to somehow contact the club when his current contract comes to an end.
As a result, out of 1,500,000 lines, 15,500 were received and combined with the final dataset. After converting categorical variables into dummies, the number of columns was inflated to 72 pieces.
Machine learning
So, the binary classification of customers, classes are represented approximately equally, everything is good and you can learn. The candidates for the model, in addition to the obvious , are:
- Random forest
- Neural network
- SVM
- k-nn
- Naive bayes
- Logit regression
- Decision stamps
Each of the classifiers, in general, showed very good results on validation. Random Forest for 1000 trees with 10-fold cv yielded 0.9499 AUC, a two-layer neural network was able to raise the result to 0.98, and the thunderstorm of competition on Kaggle, XGB, showed an impressive 0.982. Xgboost also helped with visualizing the importance of the signs: 
The first three are quite expected - "contract length" , "balance bonus points" and "average visit length" . Also in the top ten are “the number of successful communications” , “the rest of the days of freezing” and, suddenly, “did you attend fitness in the winter” .
The rest of the models, apart from the decisive hemp, averaged 0.92–0.94 AUC each and were added to the ensemble to reduce the correlation between different predictions.
The ensemble was conceived in the form of two levels - on the first hundred decision stumps, predictions on which were combined using the principle of majority vote, i.e. if 51 stumps were “for” and 49 “against”, then the unit was placed. On the second, predictions for other classifiers were connected for subsequent unification. 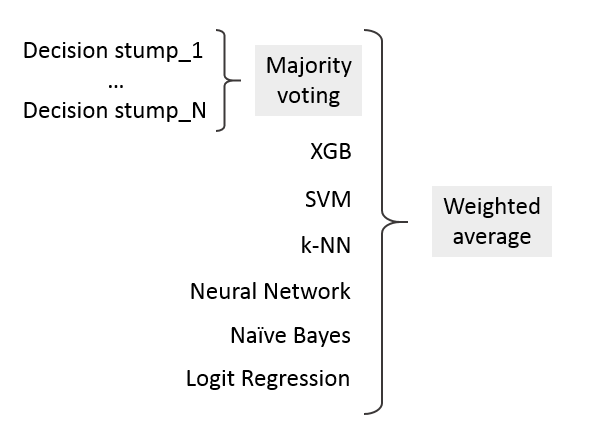
To create the ensemble, the method of weighted averages was used , each classifier is trained separately, and then a linear combination is created from their predictions: 
aj are the weights with which the predictions enter the ensemble
yj (x) - individual predictions of the classifiers
p - the number of
weight models used was determined by minimizing the ensemble logloss using the wonderful minimize function that returns the optimal values of the weight vector x0.
from scipy.optimize import minimize
opt = minimize(ensemble_logloss, x0=[1, 1, 1, 1, 1, 1, 1])Models that were given negative weight were thrown out of the ensemble to avoid fitting to training data, although there is an interesting opinion that this is not necessary in the case of negatively correlated model errors.
As a result of this selection, logistic regression fell away and, unfortunately, all the stumps, but the AUC grew by a couple of thousandths of a percent and amounted to 0.98486. Totally worth it.
Finally, predictions were made on the test dataset, and in order to have at least some idea of their quality, two histograms were built: the first for the ensemble predicted probabilities of the client renewing the contract on the validation sample, the second on the test sample.
If we assume that the Train and Test samples were more or less homogeneous, and the number of renewals should be approximately equal to the number of rejected, then there is more than a double overestimation by the models of the probability of extension of the contract. However, we decided to trust the decision of the ensemble and did not punish him for unnecessaryimpudenceoptimistic forecast. And as it turned out - not in vain.
In conclusion, I would like to say many thanks to the organizers of the hackathon for a very interesting practical task and an unforgettable experience.
Link to the repository.