Text version of the report "Actors vs CSP vs Tasks ..." with C ++ CoreHard Autumn 2018
At the beginning of November, another C ++ CoreHard Autumn 2018 conference dedicated to C ++ language was held in Minsk. The captain's report “Actors vs CSP vs Tasks ...” was made at it , where they talked about how a higher-level application than “ bare multithreading ”, competitive programming models. Under the cut is converted into an article version of this report. Brushed, in places corrected, in places supplemented.
Taking this opportunity, I would like to thank the CoreHard community for organizing the next big conference in Minsk and for the opportunity to speak. And also for the rapid publication of video reports on YouTube .
So let's move on to the main topic of conversation. Namely, we can use what approaches to simplify multithreaded programming in C ++, how the code will look at using some of these approaches, what features are inherent to specific approaches, what is common between them, etc.
Note: in the original presentation of the report errors and typos were found, so the article will use slides from the updated and edited version, which can be found in Google Slides or on SlideShare .
We need to start with the repeated banality, which, nevertheless, still remains relevant:
A good example was recently described here in this article here on Habré: "The architecture of the meta-server mobile online shooter Tacticool ." In it, the guys talked about how they managed to collect, apparently, the full range of rakes associated with the development of multi-threaded code in C and C ++. There were “passages” from memory as a result of races, and low productivity due to unsuccessful parallelization.
As a result, it all ended quite naturally:
People ate C / C ++ while working on the first version of their server and rewrote the server in another language.
A great demonstration of how in the real world, outside of our cozy C ++ community, developers refuse to use C ++ even where the use of C ++ is still appropriate and justified.
But why, if it has been said many times that “bare multithreading” in C ++ is evil, people continue to use it with a stubbornness worthy of better use? What is to blame:
After all, there is not a single time-tested approach and many projects. In particular:
It is hoped that the main reason is still ignorance. This is hardly taught in universities. So young professionals, coming into the profession, use the little that they already know. And if then the knowledge base is then not replenished, then people continue to use bare threads, mutexes, and condition_variables.
Today we will talk about the first three approaches from this list. And let's talk not abstract, but on the example of one simple little problem. Let's try to show how the code solving this problem will look using Actors, CSP processes and channels, as well as using Tasks.
It is required to implement an HTTP server that:
For example, such a server may require some paid service, distributing content by subscription. If a picture from this service then “pops up” somewhere, then by “watermarks” on it it will be possible to understand who needs to “turn off the oxygen”.
The task is abstract, it was formulated specifically for this report under the influence of our demo project Shrimp (we already told about it: №1 , №2 , №3 ).
This our HTTP server will work as follows:
Having received a request from a client, we turn to two external services:
Both of these services operate independently and we can access them both at the same time.
Since the processing of requests can be done independently of each other, and even some actions when processing a single request can be done in parallel, the use of contention arises. The simplest thing that comes to mind is to create a separate thread for each incoming request:
But the “one-request = one-work-flow” model is too expensive and it doesn’t scale well. We do not need it.
Even if it is wasteful to approach the number of workflows, we still need a small number of them:
Here we need a separate stream for receiving incoming HTTP requests, a separate stream for our own outgoing HTTP requests, a separate stream for coordinating the processing of received HTTP requests. As well as a pool of workflows for performing operations on images (since the manipulation of images is well parallel, then processing the image is not just a few streams, we reduce the time it is processed).
Therefore, our goal is to process a large number of concurrent incoming requests on a small number of worker threads. Let's take a look at how we will achieve this through various approaches.
Before moving on to the main story and parsing code examples, you need to make a few notes.
Firstly, all the following examples are not tied to any particular framework or library. Any matches in API call names are random and unintended.
Secondly, in the examples below, there is no error handling. This was done deliberately, so that the slides turned out to be compact and visible. And also to fit the material in the time allotted for the report.
Thirdly, the examples use a certain entity, execution_context, which contains information about what else exists inside the program. The content of this entity depends on the approach. With the case of the actors in the execution_context there will be links to other actors. In the case of CSP, in the execution_context there will be CSP-channels for communication with other CSP-processes. Etc.
When using the Model of Actors, the solution will be built from separate objects-actors, each of which has its own private state and this state is inaccessible to anyone except the actor.
Actors interact with each other through asynchronous messages. Each actor has its own unique mailbox (message queue) in which messages sent to the actor are saved and from where they are retrieved for further processing.
Actors work on very simple principles:
Inside the application, actors can be implemented in different ways:
In our decision, we will use the actors as objects with callbacks, and leave the coroutines for the CSP approach.
On the basis of the actors, the general scheme for solving our problem will be as follows:
We will have actors that are created at the start of the HTTP server and exist as long as the HTTP server is running. These are such actors as: HttpSrv, UserChecker, ImageDownloader, ImageMixer.
When we receive a new incoming HTTP request, we create a new instance of the RequestHandler actor, which will be destroyed after issuing a response to an incoming HTTP request.
The implementation of the request_handler actor, which coordinates the processing of an incoming HTTP request, can have the following form:
Let's break this code down.
We have a class in the attributes of which we store or are going to store what we need to process the request. Also in this class there is a set of callbacks that will be called at one time or another.
First, when the actor is just created, the on_start () callback is called. In it, we send two messages to other actors. The first is the check_user message to verify the client ID. Secondly, this is the download_image message for downloading the original image.
In each of the sent messages, we pass a link to ourselves (calling the self () method returns a link to the actor for which you called self ()). This is necessary so that our actor can send a message in response. If we do not send the link to our actor, for example, in the check_user message, the UserChecker actor will not know who to send information about the user to.
When a user_info message is sent to us with information about the user, the on_user_info () callback is called. And when an image_loaded message is sent to us, our actor is called by the on_image_loaded () callback. And inside these two callbacks we see a feature inherent in the Model Actors: we do not know exactly in which order the response messages will come to us. Therefore, we must write our code so as not to depend on the order of receipt of messages. Therefore, in each of the processors, we first store the received information in the appropriate attribute, and then we check, can we already have all the information we need? If so, then we can move on. If not, we will wait further.
That is why we have if-s in on_user_info () and on_image_loaded (), which, when executed, call send_mix_images_request ().
So, if all the information we need from UserChecker and ImageDownloader is received, the send_mix_images_request () method is called, in which the mix_images message is sent to the ImageMixer actor. The on_mixed_image () callback is called when we receive a response message with the resulting image. Here we send this image to the HttpSrv actor and wait for HttpSrv to generate the HTTP response and destroy the RequestHandler that became unnecessary (although, in principle, nothing prevents the RequestHandler actor from destroying itself in the on_mixed_image () callback.
That's all.
The implementation of the RequestHandler actor is quite voluminous. But this is due to the fact that we needed to describe a class with attributes and callbacks, and then also implement callbacks. But the logic of RequestHandler’s operation is rather trivial and it’s easy to understand it, despite the amount of code in the request_handler class.
Now we can say a few words about the features of the Model Actors.
As a rule, actors respond only to incoming messages. There are messages - the actor handles them. No messages - the actor does nothing.
This is especially true for those implementations of the Actor Model, in which actors are represented as objects with callbacks. The framework pulls the callback from the actor and if the actor does not return control from the callback, then the framework cannot serve other actors in the same context.
On actors, we can very easily make the actor-producer generate messages for the actor-consumer with a much higher rate than the actor-consumer will be able to process.
This will lead to the fact that the queue of incoming messages for the consumer actor will constantly grow. Queue growth, i.e. the increase in memory consumption in the application will reduce the speed of the application. This will lead to an even faster growth of the queue and, as a result, the application may degrade to complete inoperability.
All this is a direct consequence of the asynchronous interaction of actors. Since the send operation is usually non-blocking. And to make it blocking is not easy, because an actor can send to itself. And if the queue for the actor is full, then the actor will be blocked on the send to himself and this will stop his work.
So when working with actors you need to pay serious attention to the problem of overload.
As a rule, actors are lightweight entities and there is a temptation to create them in your application in large numbers. You can create ten thousand actors, one hundred thousand and a million. And even one hundred million actors, if iron allows you.
But the problem is that the behavior of a very large number of actors is difficult to track. Those. you may have some actors that obviously work correctly. Some of the actors who either obviously work incorrectly or do not work at all and you know about it for sure. But there can be a large number of actors about whom you do not know anything: they work at all, whether they work correctly or incorrectly. And all because when you have a hundred million autonomous entities with your own logic of behavior in your program, it’s very difficult to follow all of this.
Therefore, it may happen that by creating a large number of actors in the application, we do not solve our application problem, but we get another problem. And, therefore, it may be beneficial for us to abandon the simple actors who solve a single task, in favor of more complex and heavy actors who perform several tasks. But then we will have fewer such “heavy” actors in our application and it will be easier for us to follow them.
If someone wants to try to work with actors in C ++, then it makes no sense to build your own bikes, there are several ready-made solutions, in particular:
These three options are live, developing, cross-platform, documented. And you can try them for free. Plus a few more options of varying degrees of [not] freshness can be found on the list in Wikipedia .
SObjectizer and CAF are intended for use in sufficiently high-level tasks where exceptions and dynamic memory can be applied. And the QP / C ++ framework may be of interest to those involved in embedded development, since it is precisely under this niche that he is "sharpened."
The CSP model is very similar to the Actor Model. We also build our solution from a set of autonomous entities, each of which has its own private state and interacts with other entities only through asynchronous messages.
Only these entities in the CSP model are called “processes”.
Processes in CSP are lightweight, without any parallelization of their work inside. If we need to parallelize something, then we simply run several CSP processes, within which there is no parallelization.
CSP-shny processes interact with each other through asynchronous messages, but messages are not sent to mailboxes, as in the Actors Model, but into channels. Channels can be thought of as message queues, usually of fixed size.
Unlike the Actor Model, where a mailbox is automatically created for each actor, the channels in the CSP must be created explicitly. And if we need the two processes to interact with each other, then we have to create the channel ourselves, and then tell the first process “you will write here”, and the second process must say: “you will read here from here”.
In this case, the channels have at least two operations that need to be called explicitly. The first is the write (send) operation to write a message to the channel.
Secondly, it is the operation read (receive) to read the message from the channel. And the need to explicitly call read / receive distinguishes the CSP from the Actor Model, since in the case of actors, the read / receive operation can be generally hidden from the actor. Those. the actor framework can retrieve messages from the actor's queue and call the handler (callback) for the retrieved message.
While the CSP-shny process itself must choose the time to call read / receive, then the CSP-shny process must determine what message it received and process the extracted message.
Inside our “big” application, CSP processes can be implemented in different ways:
Further, we will assume that CSP-shny processes are presented in the form of stackful coroutines (although the code shown below may well be implemented on OS threads).
The solution scheme based on the CSP model will very strongly resemble a similar scheme for the Actor Model (and this is no accident):
There will also be entities that are started at the start of the HTTP server and run all the time - these are CSP-shny processes HttpSrv, UserChecker, ImageDownloader and ImageMixer. For each new incoming request, a new RequestHandler CSP process will be created. This process sends and receives the same messages as when using the Actor Model.
This is how the code of the function implementing the RequestHandler CSP-process may look like:
Here everything is rather trivial and the same pattern repeats regularly:
This is clearly seen in the example of communication with the ImageMixer CSP-shny process:
But separately it is worthwhile to focus attention on this fragment:
Here we see another major difference from the Model Actors. In the case of CSP, we can receive response messages in the order that suits us.
Want to wait for user_info first? No problem, we fall asleep on the read-e until user_info appears. If by this time image_loaded have already been sent to us, then it will just wait in its channel until we read it.
That is, in fact, everything that can be used to accompany the code shown above. The code based on CSP turned out to be more compact than its counterpart on the basis of actors. What is not surprising, since here we did not have to describe a separate class with callback methods. Yes, and part of the state of our RequestHandler CSP process is implicitly present in the form of the ctx and req arguments.
Unlike actors, CSP-shny processes can be both reactive and proactive, both. Let's say, the CSP-shny process checked its incoming messages, if they were, it processed them. And then, seeing that there were no incoming messages, he undertook to multiply the matrices.
After some time, the CSP-shnomu process of the matrix multiply tired and he once again checked for incoming messages. No new ones? Well, okay, let's go multiply the matrices further.
And this ability of CSP processes to perform some work, even in the absence of incoming messages, strongly distinguishes the CSP model from the Actors Model.
Since, as a rule, channels are queues of messages of a limited size and trying to write a message to a filled channel suspends the sender, we have a built-in overload protection mechanism in the CSP.
Indeed, if we have a smart process-producer and a slow consumer-process, then the producer-process will quickly fill the channel and suspend it at the next send operation. And the producer-process will sleep as long as the consumer-process does not make room in the channel for new messages. As soon as a place appears, the producer-process will wake up and add new messages to the channel.
Thus, when using CSP, we can worry less about the problem of overload than in the case of the Actor Model. The truth is that there is a pitfall, which we will talk about later.
We need to decide how our CSP processes will be implemented.
You can make it so that each CSP-shny process will be represented by a separate OS thread. It turns out expensive and not scalable solution. But on the other hand, we get preemptive multitasking: if our CSP-shny process starts multiplying matrices or makes some kind of blocking call, then the OS will eventually push it out of the computational core and allow other CSP-processes to work.
You can make each CSP-shny process be represented by a coroutine (stackful coroutine). This is a much cheaper and scalable solution. But here we will only have cooperative multitasking. Therefore, if suddenly the CSP-shny process is engaged in the multiplication of matrices, then the working thread with this CSP-shny process and other CSP-shny processes that are attached to it will be blocked.
There may be another trick. Suppose we use a third-party library, on the inside of which we can not influence. And inside the library TLS-variables are used (i.e. thread-local-storage). We make one call to the library function and the library sets the value of some TLS variable. Then our coroutine "moves" to another working thread, and this is possible, because in principle, coroutines can migrate from one working thread to another. We make the next call to the library function and the library is trying to read the value of the TLS variable. But there may already be another value! And to search for such a bug will be very difficult.
Therefore, it is necessary to carefully consider the choice of the method of implementing CSP-shnyh processes. Each option has its strengths and weaknesses.
Just as with actors, the ability to create many CSP processes in one’s own program is not always a solution to an applied problem, but the creation of additional problems for oneself.
Moreover, the poor visibility of what is happening inside the program is only one part of the problem. I want to focus on another pitfall.
The fact is that on the CSP-shnyh channels you can easily get an analogue of the deadlock. Process A attempts to write the message to the full channel C1 and process A is suspended. From channel C1 must read process B, which he tried to write to channel C2, which is full and, therefore, process B was suspended. And from channel C2 I had to read process A. Everything, we got deadlock.
If we have only two CSP processes, then we can find a similar deadlock during the debugging process or even during the code review procedure. But if we have millions of processes in the program, they actively communicate with each other, then the likelihood of such deadlocks will increase significantly.
If someone wants to work with CSP in C ++, the choice here, unfortunately, is not as big as for actors. Well, or I do not know where to look and how to search. In this case, I hope, in the comments will share other links.
But, if we want to use CSP, then first of all we need to look towards Boost.Fiber . There are fiber-s (ie coroutines), channels, and even such low-level primitives as mutex, condition_variable, barrier. All this can be taken and used.
If you are satisfied with the CSP-shny processes in the form of threads, then you can look at SObjectizer . There are also analogs of CSP shny channels and complex multi-threaded applications on SObjectizer, you can write without any actors at all.
Actors and CSP processes are very similar to each other. It has been repeatedly found that the two models are equivalent to each other. Those. what can be done on actors can almost be repeated 1-in-1 on CSP processes and vice versa. They say that it is even proven mathematically. But here I do not understand anything, so I can not say anything. But from his own thoughts somewhere at the level of common sense, it all looks quite plausible. In some cases, indeed, actors can be replaced by CSP processes, and CSP processes by actors.
However, actors and CSP have several differences that can help determine where it is advantageous or unprofitable to use each of these models.
The actor has a single “channel” for receiving incoming messages - this is his mailbox, which is automatically created for each actor. And the actor retrieves messages from there sequentially, exactly in the order in which the messages got into the mailbox.
And this is quite a serious question. Suppose there are now three messages in the actor's mailbox: M1, M2 and M3. Actor is currently only interested in M3. But before you get to the M3, the actor will extract first M1, then M2. And what will he do with them?
While the CSP-shny process has the ability to select the channel from which he currently wants to read messages. So, a CSP process can have three channels: C1, C2 and C3. Currently the CSP process is only interested in messages from C3. This channel is the process of reading. And to the contents of channels C1 and C2, he will return when he is interested in this.
As a rule, actors are reactive and work only when they have incoming messages.
While CSP processes can do some work even in the absence of incoming messages. In some scenarios, this difference may play an important role.
In essence, actors are finite automata (SV). Therefore, if there are many state machines in your data domain, and even if these are complex, hierarchical state machines, then it can be much simpler to implement them on the basis of the model of actors than by adding the implementation of a spacecraft to the CSP process.
The experience of the Go language shows how easy and convenient it is to use the CSP model when its support is implemented at the level of a programming language and its standard library.
In Go, it is easy to create “CSP processes” (aka goroutines), it is easy to create and work with channels, there is a built-in syntax for working with several channels at once (Go-shny select, which works not only for reading but also for writing) The standard library knows about the Goroutines and can switch them when Goroutin makes a blocking call from stdlib.
In C ++, there is no stackful coroutines support yet (at the language level). Therefore, working with CSP in C ++ can look, in places, if not a crutch, then ... Then surely it requires much more attention to itself than in the case of the same Go.
The meaning of the Task-based approach is that if we have a complicated operation, then we divide this operation into separate steps-tasks, where each task (it’s a task) performs some one sub-operation.
We start these tasks with a special async operation. The async operation returns a future object, in which after the execution of the task the value returned by the task will be placed.
After we run N tasks and get N objects of the future, we need to somehow knit it all into a chain. It seems that when tasks No. 1 and No. 2 are completed, the values returned by them should fall into task No. 3. And when the task number 3 is completed, the returned value should be transferred to task number 4, number 5 and number 6. Etc.
For such "provings" special means are used. Such, for example, as the .then () method of the future object, as well as the wait_all (), wait_any () functions.
Such an explanation “on the fingers” may not be very clear, so let's move on to the code. Maybe in a conversation about a specific code, the situation will become clear (but not a fact).
The code for processing an incoming HTTP request based on tasks can look like this:
Let's try to figure out what's going on here.
First, we create a task that should run on the context of our own HTTP client and which requests information about the user. The returned future object is stored in the user_info_ft variable.
Next, we create a similar task, which should also run on the context of our own HTTP client and which loads the original image. The returned future object is stored in the variable original_image_ft.
Next we need to wait for the first two tasks. What we directly write: when_all (user_info_ft, original_image_ft). When both future objects get their values, then we will run another task. This task will take a bitmask with watermarks and the original image and will launch another task in the context of ImageMixer. This task mixes the images, and when it completes, another task will start in the context of the HTTP server and generate an HTTP response.
Probably this explanation of what is happening in the code is not much clarified. So let's enumerate our tasks:
And look at the dependencies between them (from which the order in which tasks are carried out):
And if we now apply this image to our source code, then I hope it will become clearer:
The first feature that should already become apparent is the visibility of the code on the Task. She's not doing well.
Here you can mention such a thing as callback hell. Node.js programmers are very familiar with it. But C ++ nicknames, which work closely with Task, also dip into this very callback hell.
Another interesting feature is error handling.
On the one hand, in the case of using async and the future, delivering information about the error to the interested party can be even easier than in the case of actors or CSP. After all, if in CSP, process A sends a request to process B and waits for a response message, then when an error occurs in B when executing the request, we need to decide how to deliver an error to process A:
And in the case of the future, everything is simpler: we extract from the future either a normal result, or an exception is thrown to us.
But, on the other hand, we can easily run into a cascade of errors. For example, an exception occurred in task # 1, this exception fell into the future object, which was passed to task # 2. In problem number 2, we tried to take the value from the future, but received an exception. And, most likely, we will throw out the same exception. Accordingly, it will fall into the next future, which will go to the task number 3. There will also be an exception, which, quite possibly, will also be released outside. Etc.
If our exceptions are logged, then in the log we will be able to see the repeated repetition of the same exception, which is transferred from one task in the chain to another task.
And another very interesting feature of the Task-based hike is the cancellation of tasks if something went wrong. In fact, let's say we created 150 tasks, completed the first 10 of them and realized that everything further work does not make sense to continue. How do we cancel 140 remaining? This is a very, very good question :)
Another similar question is how to make friends tasks with timers and timeouts. Suppose we are accessing some kind of external system and want to limit the wait time to 50 milliseconds. How do we set the timer, how to react to the timeout, how to interrupt the task chain if the timeout has expired? Again, asking is easier than answering :)
Well, more to the conversation about the features of the Task-based approach. In the example shown, a small cheating was applied:
Here I have sent two tasks to the context of our own HTTP server, each of which performs a blocking operation inside. In fact, in order to be able to process two requests to third-party services in parallel, here it was necessary to create their own chains of asynchronous tasks. But I did not do this in order to make the decision more or less observable and fit on the slide of the presentation.
We looked at three approaches and saw that if the actors and CSP processes are similar to each other, then the Task-based approach is not similar to any of them. And it may seem that Actors / CSP should be opposed to Task.
But personally, I like a different point of view.
When we talk about the Model Actors and CSP, we are talking about the decomposition of its task. In our task we single out separate independent entities and describe the interfaces of these entities: which messages they send, which ones receive, through which channels the messages go.
Those. working with actors and CSP we are talking about interfaces.
But, let's say, we broke the task down into separate actors and CSP-processes. How exactly do they do their work?
When we take on the Task-based approach, we start talking about implementation. How the concrete work is performed, what sub-operations are performed, in what order, how these sub-operations are connected by data, etc.
Those. working with Task we are talking about implementation.
Consequently, Actors / CSP and Tasks do not so much confront each other as complement each other. Actors / CSPs can be used to decompose a task and define interfaces between components. And Tasks can then be used to implement specific components.
For example, when using Actors, we have an entity such as ImageMixer, which needs to be manipulated with images on a pool of worker threads. In general, nothing prevents us from implementing the TaskMixer actor to use the Task-based approach.
If you wanted to work with Task-s in C ++, then you can look towards the standard library of the upcoming C ++ 20. There, the .then () method has already been added to the future, as well as the free wait_all () and wait_any functions. For details, refer to cppreference .
Also, there is no longer a new async ++ library . In which, in principle, has everything you need, just a little under a different sauce.
And there is another older Microsoft PPL library . Which also gives everything that is needed, but under its own sauce.
Recently here, on Habré, there was an article by Anton Polukhin: " Preparing for C ++ 20. Coroutines TS with a real example ."
It talks about combining the Task-based approach with stackless coroutines from C ++ 20. And it turned out that the code on the basis of Task readability approached the readability of the code on CSP processes.
So if someone is interested in the Task-based approach, then it makes sense to read this article.
Well, it's time to move on to the results, the benefit of them is not so much.
The main thing that I want to say is that in the modern world bare multithreading you may need it unless you are developing some kind of framework or solving some specific and low-level task.
And if you are writing application code, then you hardly need bare threads, low-level synchronization primitives, or some lock-free algorithms along with lock-free containers. For a long time there are approaches that have been tested by time and have proven themselves well:
And the main thing is that for them in C ++ there are ready-made tools. You do not need to ride a bike, you can take it, try it and, if you like it, start it up.
So simple: take, try and start up in operation.
Taking this opportunity, I would like to thank the CoreHard community for organizing the next big conference in Minsk and for the opportunity to speak. And also for the rapid publication of video reports on YouTube .
So let's move on to the main topic of conversation. Namely, we can use what approaches to simplify multithreaded programming in C ++, how the code will look at using some of these approaches, what features are inherent to specific approaches, what is common between them, etc.
Note: in the original presentation of the report errors and typos were found, so the article will use slides from the updated and edited version, which can be found in Google Slides or on SlideShare .
“Naked multi-threading” is evil!
We need to start with the repeated banality, which, nevertheless, still remains relevant:
Multithreaded programming in C ++ by means of bare threads, mutexes, and condition variables are sweat , pain, and blood .
A good example was recently described here in this article here on Habré: "The architecture of the meta-server mobile online shooter Tacticool ." In it, the guys talked about how they managed to collect, apparently, the full range of rakes associated with the development of multi-threaded code in C and C ++. There were “passages” from memory as a result of races, and low productivity due to unsuccessful parallelization.
As a result, it all ended quite naturally:
After a couple of weeks spent searching for and fixing the most critical bugs, we decided that it was easier to rewrite everything from scratch than to try to correct all the shortcomings of the current solution.
People ate C / C ++ while working on the first version of their server and rewrote the server in another language.
A great demonstration of how in the real world, outside of our cozy C ++ community, developers refuse to use C ++ even where the use of C ++ is still appropriate and justified.
But why?
But why, if it has been said many times that “bare multithreading” in C ++ is evil, people continue to use it with a stubbornness worthy of better use? What is to blame:
- ignorance?
- laziness?
- NIH syndrome?
After all, there is not a single time-tested approach and many projects. In particular:
- actors
- communicating sequential processes (CSP)
- tasks (async, promises, futures, ...)
- data flows
- reactive programming
- ...
It is hoped that the main reason is still ignorance. This is hardly taught in universities. So young professionals, coming into the profession, use the little that they already know. And if then the knowledge base is then not replenished, then people continue to use bare threads, mutexes, and condition_variables.
Today we will talk about the first three approaches from this list. And let's talk not abstract, but on the example of one simple little problem. Let's try to show how the code solving this problem will look using Actors, CSP processes and channels, as well as using Tasks.
Task for experiments
It is required to implement an HTTP server that:
- accepts a request (picture ID, user ID);
- gives a picture with watermarks unique to this user.
For example, such a server may require some paid service, distributing content by subscription. If a picture from this service then “pops up” somewhere, then by “watermarks” on it it will be possible to understand who needs to “turn off the oxygen”.
The task is abstract, it was formulated specifically for this report under the influence of our demo project Shrimp (we already told about it: №1 , №2 , №3 ).
This our HTTP server will work as follows:
 |
Having received a request from a client, we turn to two external services:
- The first returns us information about the user. Including from there we get a picture with "watermarks";
- the second returns us the original image
Both of these services operate independently and we can access them both at the same time.
Since the processing of requests can be done independently of each other, and even some actions when processing a single request can be done in parallel, the use of contention arises. The simplest thing that comes to mind is to create a separate thread for each incoming request:
 |
But the “one-request = one-work-flow” model is too expensive and it doesn’t scale well. We do not need it.
Even if it is wasteful to approach the number of workflows, we still need a small number of them:
 |
Here we need a separate stream for receiving incoming HTTP requests, a separate stream for our own outgoing HTTP requests, a separate stream for coordinating the processing of received HTTP requests. As well as a pool of workflows for performing operations on images (since the manipulation of images is well parallel, then processing the image is not just a few streams, we reduce the time it is processed).
Therefore, our goal is to process a large number of concurrent incoming requests on a small number of worker threads. Let's take a look at how we will achieve this through various approaches.
Several important disclaimers
Before moving on to the main story and parsing code examples, you need to make a few notes.
Firstly, all the following examples are not tied to any particular framework or library. Any matches in API call names are random and unintended.
Secondly, in the examples below, there is no error handling. This was done deliberately, so that the slides turned out to be compact and visible. And also to fit the material in the time allotted for the report.
Thirdly, the examples use a certain entity, execution_context, which contains information about what else exists inside the program. The content of this entity depends on the approach. With the case of the actors in the execution_context there will be links to other actors. In the case of CSP, in the execution_context there will be CSP-channels for communication with other CSP-processes. Etc.
Approach # 1: Actors
Pro Model Actors in a nutshell
When using the Model of Actors, the solution will be built from separate objects-actors, each of which has its own private state and this state is inaccessible to anyone except the actor.
Actors interact with each other through asynchronous messages. Each actor has its own unique mailbox (message queue) in which messages sent to the actor are saved and from where they are retrieved for further processing.
Actors work on very simple principles:
- an actor is an entity with behavior;
- actors respond to incoming messages;
- having received the message the actor can:
- send some (finite) number of messages to other actors;
- create a certain (final) number of new actors;
- define for yourself a new behavior for handling subsequent messages.
Inside the application, actors can be implemented in different ways:
- Each actor can be represented as a separate OS thread (this happens, for example, in C ++ library Just :: Thread Pro Actor Edition);
- each actor can be represented as a stackful coroutine;
- Each actor can be represented as an object to which someone calls callback methods.
In our decision, we will use the actors as objects with callbacks, and leave the coroutines for the CSP approach.
Solution scheme based on Model Actors
On the basis of the actors, the general scheme for solving our problem will be as follows:
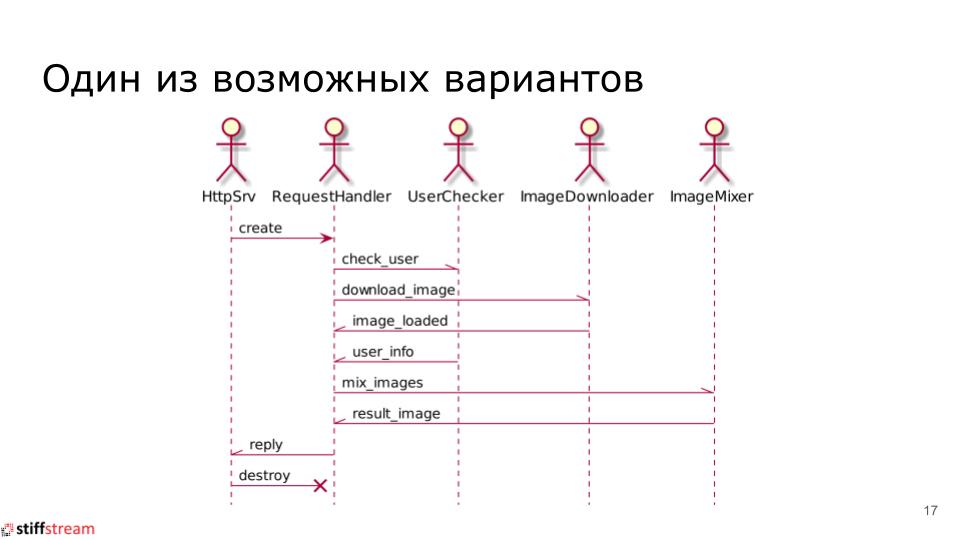 |
We will have actors that are created at the start of the HTTP server and exist as long as the HTTP server is running. These are such actors as: HttpSrv, UserChecker, ImageDownloader, ImageMixer.
When we receive a new incoming HTTP request, we create a new instance of the RequestHandler actor, which will be destroyed after issuing a response to an incoming HTTP request.
Actor code RequestHandler
The implementation of the request_handler actor, which coordinates the processing of an incoming HTTP request, can have the following form:
classrequest_handlerfinal :public some_basic_type {
const execution_context context_;
const request request_;
optional<user_info> user_info_;
optional<image_loaded> image_;
voidon_start();
voidon_user_info(user_info info);
voidon_image_loaded(image_loaded image);
voidon_mixed_image(mixed_image image);
voidsend_mix_images_request();
... // вся специфическая для фреймворка обвязка.
};
void request_handler::on_start() {
send(context_.user_checker(), check_user{request_.user_id(), self()});
send(context_.image_downloader(), download_image{request_.image_id(), self()});
}
void request_handler::on_user_info(user_info info) {
user_info_ = std::move(info);
if(image_)
send_mix_images_request();
}
void request_handler::on_image_loaded(image_loaded image) {
image_ = std::move(image);
if(user_info_)
send_mix_images_request();
}
void request_handler::send_mix_images_request() {
send(context_.image_mixer(),
mix_images{user_info->watermark_image(), *image_, self()});
}
void request_handler::on_mixed_image(mixed_image image) {
send(context_.http_srv(), reply{..., std::move(image), ...});
}Let's break this code down.
We have a class in the attributes of which we store or are going to store what we need to process the request. Also in this class there is a set of callbacks that will be called at one time or another.
First, when the actor is just created, the on_start () callback is called. In it, we send two messages to other actors. The first is the check_user message to verify the client ID. Secondly, this is the download_image message for downloading the original image.
In each of the sent messages, we pass a link to ourselves (calling the self () method returns a link to the actor for which you called self ()). This is necessary so that our actor can send a message in response. If we do not send the link to our actor, for example, in the check_user message, the UserChecker actor will not know who to send information about the user to.
When a user_info message is sent to us with information about the user, the on_user_info () callback is called. And when an image_loaded message is sent to us, our actor is called by the on_image_loaded () callback. And inside these two callbacks we see a feature inherent in the Model Actors: we do not know exactly in which order the response messages will come to us. Therefore, we must write our code so as not to depend on the order of receipt of messages. Therefore, in each of the processors, we first store the received information in the appropriate attribute, and then we check, can we already have all the information we need? If so, then we can move on. If not, we will wait further.
That is why we have if-s in on_user_info () and on_image_loaded (), which, when executed, call send_mix_images_request ().
In principle, in implementations of the Model Actors there can be mechanisms like selective receive from Erlang or stashing from Akka, by means of which you can manipulate the order of processing incoming messages, but we will not talk about this today, so as not to go deep into the jungle of details of various implementations Actors.
So, if all the information we need from UserChecker and ImageDownloader is received, the send_mix_images_request () method is called, in which the mix_images message is sent to the ImageMixer actor. The on_mixed_image () callback is called when we receive a response message with the resulting image. Here we send this image to the HttpSrv actor and wait for HttpSrv to generate the HTTP response and destroy the RequestHandler that became unnecessary (although, in principle, nothing prevents the RequestHandler actor from destroying itself in the on_mixed_image () callback.
That's all.
The implementation of the RequestHandler actor is quite voluminous. But this is due to the fact that we needed to describe a class with attributes and callbacks, and then also implement callbacks. But the logic of RequestHandler’s operation is rather trivial and it’s easy to understand it, despite the amount of code in the request_handler class.
Features inherent in actors
Now we can say a few words about the features of the Model Actors.
Actors are reactive
As a rule, actors respond only to incoming messages. There are messages - the actor handles them. No messages - the actor does nothing.
This is especially true for those implementations of the Actor Model, in which actors are represented as objects with callbacks. The framework pulls the callback from the actor and if the actor does not return control from the callback, then the framework cannot serve other actors in the same context.
Actors are subject to overloads
On actors, we can very easily make the actor-producer generate messages for the actor-consumer with a much higher rate than the actor-consumer will be able to process.
This will lead to the fact that the queue of incoming messages for the consumer actor will constantly grow. Queue growth, i.e. the increase in memory consumption in the application will reduce the speed of the application. This will lead to an even faster growth of the queue and, as a result, the application may degrade to complete inoperability.
All this is a direct consequence of the asynchronous interaction of actors. Since the send operation is usually non-blocking. And to make it blocking is not easy, because an actor can send to itself. And if the queue for the actor is full, then the actor will be blocked on the send to himself and this will stop his work.
So when working with actors you need to pay serious attention to the problem of overload.
Many actors are not always the solution.
As a rule, actors are lightweight entities and there is a temptation to create them in your application in large numbers. You can create ten thousand actors, one hundred thousand and a million. And even one hundred million actors, if iron allows you.
But the problem is that the behavior of a very large number of actors is difficult to track. Those. you may have some actors that obviously work correctly. Some of the actors who either obviously work incorrectly or do not work at all and you know about it for sure. But there can be a large number of actors about whom you do not know anything: they work at all, whether they work correctly or incorrectly. And all because when you have a hundred million autonomous entities with your own logic of behavior in your program, it’s very difficult to follow all of this.
Therefore, it may happen that by creating a large number of actors in the application, we do not solve our application problem, but we get another problem. And, therefore, it may be beneficial for us to abandon the simple actors who solve a single task, in favor of more complex and heavy actors who perform several tasks. But then we will have fewer such “heavy” actors in our application and it will be easier for us to follow them.
Where to look, what to take?
If someone wants to try to work with actors in C ++, then it makes no sense to build your own bikes, there are several ready-made solutions, in particular:
- SObjectizer (support domestic producer!)
- C ++ Actor Framework (CAF)
- QP / C ++
These three options are live, developing, cross-platform, documented. And you can try them for free. Plus a few more options of varying degrees of [not] freshness can be found on the list in Wikipedia .
SObjectizer and CAF are intended for use in sufficiently high-level tasks where exceptions and dynamic memory can be applied. And the QP / C ++ framework may be of interest to those involved in embedded development, since it is precisely under this niche that he is "sharpened."
Approach # 2: CSP (communicating sequential processes)
CSP on fingers and no matane
The CSP model is very similar to the Actor Model. We also build our solution from a set of autonomous entities, each of which has its own private state and interacts with other entities only through asynchronous messages.
Only these entities in the CSP model are called “processes”.
Processes in CSP are lightweight, without any parallelization of their work inside. If we need to parallelize something, then we simply run several CSP processes, within which there is no parallelization.
CSP-shny processes interact with each other through asynchronous messages, but messages are not sent to mailboxes, as in the Actors Model, but into channels. Channels can be thought of as message queues, usually of fixed size.
Unlike the Actor Model, where a mailbox is automatically created for each actor, the channels in the CSP must be created explicitly. And if we need the two processes to interact with each other, then we have to create the channel ourselves, and then tell the first process “you will write here”, and the second process must say: “you will read here from here”.
In this case, the channels have at least two operations that need to be called explicitly. The first is the write (send) operation to write a message to the channel.
Secondly, it is the operation read (receive) to read the message from the channel. And the need to explicitly call read / receive distinguishes the CSP from the Actor Model, since in the case of actors, the read / receive operation can be generally hidden from the actor. Those. the actor framework can retrieve messages from the actor's queue and call the handler (callback) for the retrieved message.
While the CSP-shny process itself must choose the time to call read / receive, then the CSP-shny process must determine what message it received and process the extracted message.
Inside our “big” application, CSP processes can be implemented in different ways:
- CSP-shny process can be implemented as a separate OS thread. It turns out an expensive solution, but with preemptive multitasking;
- CSP-shny process can be implemented coroutine (stackful coroutine, fiber, green thread, ...). It is much cheaper, but multitasking is only cooperative.
Further, we will assume that CSP-shny processes are presented in the form of stackful coroutines (although the code shown below may well be implemented on OS threads).
CSP based solution
The solution scheme based on the CSP model will very strongly resemble a similar scheme for the Actor Model (and this is no accident):
 |
There will also be entities that are started at the start of the HTTP server and run all the time - these are CSP-shny processes HttpSrv, UserChecker, ImageDownloader and ImageMixer. For each new incoming request, a new RequestHandler CSP process will be created. This process sends and receives the same messages as when using the Actor Model.
CSP-shny process code RequestHandler
This is how the code of the function implementing the RequestHandler CSP-process may look like:
voidrequest_handler(const execution_context ctx, const request req){
auto user_info_ch = make_chain<user_info>();
auto image_loaded_ch = make_chain<image_loaded>();
ctx.user_checker_ch().write(check_user{req.user_id(), user_info_ch});
ctx.image_downloader_ch().write(download_image{req.image_id(), image_loaded_ch});
auto user = user_info_ch.read();
auto original_image = image_loaded_ch.read();
auto image_mix_ch = make_chain<mixed_image>();
ctx.image_mixer_ch().write(
mix_image{user.watermark_image(), std::move(original_image), image_mix_ch});
auto result_image = image_mix_ch.read();
ctx.http_srv_ch().write(reply{..., std::move(result_image), ...});
}Here everything is rather trivial and the same pattern repeats regularly:
- First we create a channel for receiving response messages. This is necessary because a CSP process has no mailbox by default, like actors. Therefore, if the CSP-shny process wants to get something, then it should be puzzled by the creation of a channel where this “something” will be recorded;
- then we send our message to the CSP process executable. And in this message we indicate the channel for the response message;
- then we perform a read operation from the channel to which we must send a response message.
This is clearly seen in the example of communication with the ImageMixer CSP-shny process:
auto image_mix_ch = make_chain<mixed_image>(); // Создали канал.
ctx.image_mixer_ch().write( // Отослали сообщение.
mix_image{..., image_mix_ch}); // В сообщении передали ответный канал.auto result_image = image_mix_ch.read(); // Дождались ответа.But separately it is worthwhile to focus attention on this fragment:
auto user = user_info_ch.read();
auto original_image = image_loaded_ch.read();Here we see another major difference from the Model Actors. In the case of CSP, we can receive response messages in the order that suits us.
Want to wait for user_info first? No problem, we fall asleep on the read-e until user_info appears. If by this time image_loaded have already been sent to us, then it will just wait in its channel until we read it.
That is, in fact, everything that can be used to accompany the code shown above. The code based on CSP turned out to be more compact than its counterpart on the basis of actors. What is not surprising, since here we did not have to describe a separate class with callback methods. Yes, and part of the state of our RequestHandler CSP process is implicitly present in the form of the ctx and req arguments.
CSP Features
Reactivity and proactivity of CSP processes
Unlike actors, CSP-shny processes can be both reactive and proactive, both. Let's say, the CSP-shny process checked its incoming messages, if they were, it processed them. And then, seeing that there were no incoming messages, he undertook to multiply the matrices.
After some time, the CSP-shnomu process of the matrix multiply tired and he once again checked for incoming messages. No new ones? Well, okay, let's go multiply the matrices further.
And this ability of CSP processes to perform some work, even in the absence of incoming messages, strongly distinguishes the CSP model from the Actors Model.
Native overload protection mechanisms
Since, as a rule, channels are queues of messages of a limited size and trying to write a message to a filled channel suspends the sender, we have a built-in overload protection mechanism in the CSP.
Indeed, if we have a smart process-producer and a slow consumer-process, then the producer-process will quickly fill the channel and suspend it at the next send operation. And the producer-process will sleep as long as the consumer-process does not make room in the channel for new messages. As soon as a place appears, the producer-process will wake up and add new messages to the channel.
Thus, when using CSP, we can worry less about the problem of overload than in the case of the Actor Model. The truth is that there is a pitfall, which we will talk about later.
How are CSP processes implemented?
We need to decide how our CSP processes will be implemented.
You can make it so that each CSP-shny process will be represented by a separate OS thread. It turns out expensive and not scalable solution. But on the other hand, we get preemptive multitasking: if our CSP-shny process starts multiplying matrices or makes some kind of blocking call, then the OS will eventually push it out of the computational core and allow other CSP-processes to work.
You can make each CSP-shny process be represented by a coroutine (stackful coroutine). This is a much cheaper and scalable solution. But here we will only have cooperative multitasking. Therefore, if suddenly the CSP-shny process is engaged in the multiplication of matrices, then the working thread with this CSP-shny process and other CSP-shny processes that are attached to it will be blocked.
There may be another trick. Suppose we use a third-party library, on the inside of which we can not influence. And inside the library TLS-variables are used (i.e. thread-local-storage). We make one call to the library function and the library sets the value of some TLS variable. Then our coroutine "moves" to another working thread, and this is possible, because in principle, coroutines can migrate from one working thread to another. We make the next call to the library function and the library is trying to read the value of the TLS variable. But there may already be another value! And to search for such a bug will be very difficult.
Therefore, it is necessary to carefully consider the choice of the method of implementing CSP-shnyh processes. Each option has its strengths and weaknesses.
Many processes are not always a solution.
Just as with actors, the ability to create many CSP processes in one’s own program is not always a solution to an applied problem, but the creation of additional problems for oneself.
Moreover, the poor visibility of what is happening inside the program is only one part of the problem. I want to focus on another pitfall.
The fact is that on the CSP-shnyh channels you can easily get an analogue of the deadlock. Process A attempts to write the message to the full channel C1 and process A is suspended. From channel C1 must read process B, which he tried to write to channel C2, which is full and, therefore, process B was suspended. And from channel C2 I had to read process A. Everything, we got deadlock.
If we have only two CSP processes, then we can find a similar deadlock during the debugging process or even during the code review procedure. But if we have millions of processes in the program, they actively communicate with each other, then the likelihood of such deadlocks will increase significantly.
Where to look, what to take?
If someone wants to work with CSP in C ++, the choice here, unfortunately, is not as big as for actors. Well, or I do not know where to look and how to search. In this case, I hope, in the comments will share other links.
But, if we want to use CSP, then first of all we need to look towards Boost.Fiber . There are fiber-s (ie coroutines), channels, and even such low-level primitives as mutex, condition_variable, barrier. All this can be taken and used.
If you are satisfied with the CSP-shny processes in the form of threads, then you can look at SObjectizer . There are also analogs of CSP shny channels and complex multi-threaded applications on SObjectizer, you can write without any actors at all.
Actors vs CSP
Actors and CSP processes are very similar to each other. It has been repeatedly found that the two models are equivalent to each other. Those. what can be done on actors can almost be repeated 1-in-1 on CSP processes and vice versa. They say that it is even proven mathematically. But here I do not understand anything, so I can not say anything. But from his own thoughts somewhere at the level of common sense, it all looks quite plausible. In some cases, indeed, actors can be replaced by CSP processes, and CSP processes by actors.
However, actors and CSP have several differences that can help determine where it is advantageous or unprofitable to use each of these models.
Channels vs mailbox
The actor has a single “channel” for receiving incoming messages - this is his mailbox, which is automatically created for each actor. And the actor retrieves messages from there sequentially, exactly in the order in which the messages got into the mailbox.
And this is quite a serious question. Suppose there are now three messages in the actor's mailbox: M1, M2 and M3. Actor is currently only interested in M3. But before you get to the M3, the actor will extract first M1, then M2. And what will he do with them?
Again, within the framework of this conversation, we will not touch upon selective receive mechanisms from Erlang and stashing from Akka.
While the CSP-shny process has the ability to select the channel from which he currently wants to read messages. So, a CSP process can have three channels: C1, C2 and C3. Currently the CSP process is only interested in messages from C3. This channel is the process of reading. And to the contents of channels C1 and C2, he will return when he is interested in this.
Reactivity and proactivity
As a rule, actors are reactive and work only when they have incoming messages.
While CSP processes can do some work even in the absence of incoming messages. In some scenarios, this difference may play an important role.
State machines
In essence, actors are finite automata (SV). Therefore, if there are many state machines in your data domain, and even if these are complex, hierarchical state machines, then it can be much simpler to implement them on the basis of the model of actors than by adding the implementation of a spacecraft to the CSP process.
In C ++, there is no native CSP support yet.
The experience of the Go language shows how easy and convenient it is to use the CSP model when its support is implemented at the level of a programming language and its standard library.
In Go, it is easy to create “CSP processes” (aka goroutines), it is easy to create and work with channels, there is a built-in syntax for working with several channels at once (Go-shny select, which works not only for reading but also for writing) The standard library knows about the Goroutines and can switch them when Goroutin makes a blocking call from stdlib.
In C ++, there is no stackful coroutines support yet (at the language level). Therefore, working with CSP in C ++ can look, in places, if not a crutch, then ... Then surely it requires much more attention to itself than in the case of the same Go.
Approach # 3: Tasks (async, future, wait_all, ...)
About Task-based approach with the most common words
The meaning of the Task-based approach is that if we have a complicated operation, then we divide this operation into separate steps-tasks, where each task (it’s a task) performs some one sub-operation.
We start these tasks with a special async operation. The async operation returns a future object, in which after the execution of the task the value returned by the task will be placed.
After we run N tasks and get N objects of the future, we need to somehow knit it all into a chain. It seems that when tasks No. 1 and No. 2 are completed, the values returned by them should fall into task No. 3. And when the task number 3 is completed, the returned value should be transferred to task number 4, number 5 and number 6. Etc.
For such "provings" special means are used. Such, for example, as the .then () method of the future object, as well as the wait_all (), wait_any () functions.
Such an explanation “on the fingers” may not be very clear, so let's move on to the code. Maybe in a conversation about a specific code, the situation will become clear (but not a fact).
Request_handler code for the Task-based approach
The code for processing an incoming HTTP request based on tasks can look like this:
voidhandle_request(const execution_context & ctx, request req){
auto user_info_ft = async(ctx.http_client_ctx(),
[req] { return retrieve_user_info(req.user_id()); });
auto original_image_ft = async(ctx.http_client_ctx(),
[req] { return download_image(req.image_id()); });
when_all(user_info_ft, original_image_ft).then(
[&ctx, req](tuple<future<user_info>, future<image_loaded>> data) {
async(ctx.image_mixer_ctx(), [&ctx, req, d=std::move(data)] {
return mix_image(get<0>(d).get().watermark_image(), get<1>(d).get());
})
.then([req](future<mixed_image> mixed) {
async(ctx.http_srv_ctx(), [req, im=std::move(mixed)] {
make_reply(...);
});
});
});
}Let's try to figure out what's going on here.
First, we create a task that should run on the context of our own HTTP client and which requests information about the user. The returned future object is stored in the user_info_ft variable.
Next, we create a similar task, which should also run on the context of our own HTTP client and which loads the original image. The returned future object is stored in the variable original_image_ft.
Next we need to wait for the first two tasks. What we directly write: when_all (user_info_ft, original_image_ft). When both future objects get their values, then we will run another task. This task will take a bitmask with watermarks and the original image and will launch another task in the context of ImageMixer. This task mixes the images, and when it completes, another task will start in the context of the HTTP server and generate an HTTP response.
Probably this explanation of what is happening in the code is not much clarified. So let's enumerate our tasks:
 |
And look at the dependencies between them (from which the order in which tasks are carried out):
 |
And if we now apply this image to our source code, then I hope it will become clearer:
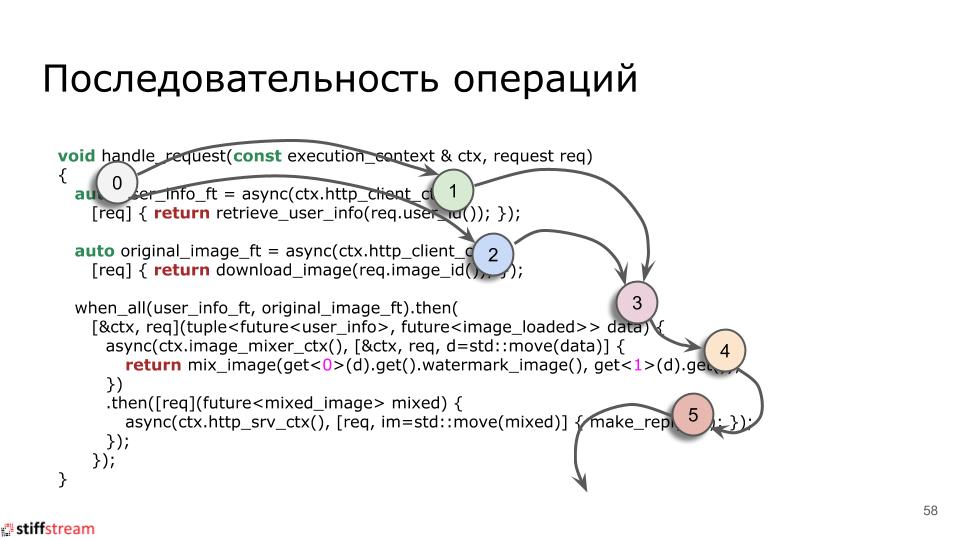 |
Features of the task-based approach
Visibility
The first feature that should already become apparent is the visibility of the code on the Task. She's not doing well.
Here you can mention such a thing as callback hell. Node.js programmers are very familiar with it. But C ++ nicknames, which work closely with Task, also dip into this very callback hell.
Error processing
Another interesting feature is error handling.
On the one hand, in the case of using async and the future, delivering information about the error to the interested party can be even easier than in the case of actors or CSP. After all, if in CSP, process A sends a request to process B and waits for a response message, then when an error occurs in B when executing the request, we need to decide how to deliver an error to process A:
- or we will make a separate message type and channel to receive it;
- or we give the result in a single message, in which there will be a std :: variant for a normal and erroneous result.
And in the case of the future, everything is simpler: we extract from the future either a normal result, or an exception is thrown to us.
But, on the other hand, we can easily run into a cascade of errors. For example, an exception occurred in task # 1, this exception fell into the future object, which was passed to task # 2. In problem number 2, we tried to take the value from the future, but received an exception. And, most likely, we will throw out the same exception. Accordingly, it will fall into the next future, which will go to the task number 3. There will also be an exception, which, quite possibly, will also be released outside. Etc.
If our exceptions are logged, then in the log we will be able to see the repeated repetition of the same exception, which is transferred from one task in the chain to another task.
Cancel Task and Timers / Timeouts
And another very interesting feature of the Task-based hike is the cancellation of tasks if something went wrong. In fact, let's say we created 150 tasks, completed the first 10 of them and realized that everything further work does not make sense to continue. How do we cancel 140 remaining? This is a very, very good question :)
Another similar question is how to make friends tasks with timers and timeouts. Suppose we are accessing some kind of external system and want to limit the wait time to 50 milliseconds. How do we set the timer, how to react to the timeout, how to interrupt the task chain if the timeout has expired? Again, asking is easier than answering :)
Cheating
Well, more to the conversation about the features of the Task-based approach. In the example shown, a small cheating was applied:
auto user_info_ft = async(ctx.http_client_ctx(),
[req] { return retrieve_user_info(req.user_id()); });
auto original_image_ft = async(ctx.http_client_ctx(),
[req] { return download_image(req.image_id()); });Here I have sent two tasks to the context of our own HTTP server, each of which performs a blocking operation inside. In fact, in order to be able to process two requests to third-party services in parallel, here it was necessary to create their own chains of asynchronous tasks. But I did not do this in order to make the decision more or less observable and fit on the slide of the presentation.
Actors / CSP vs Tasks
We looked at three approaches and saw that if the actors and CSP processes are similar to each other, then the Task-based approach is not similar to any of them. And it may seem that Actors / CSP should be opposed to Task.
But personally, I like a different point of view.
When we talk about the Model Actors and CSP, we are talking about the decomposition of its task. In our task we single out separate independent entities and describe the interfaces of these entities: which messages they send, which ones receive, through which channels the messages go.
Those. working with actors and CSP we are talking about interfaces.
But, let's say, we broke the task down into separate actors and CSP-processes. How exactly do they do their work?
When we take on the Task-based approach, we start talking about implementation. How the concrete work is performed, what sub-operations are performed, in what order, how these sub-operations are connected by data, etc.
Those. working with Task we are talking about implementation.
Consequently, Actors / CSP and Tasks do not so much confront each other as complement each other. Actors / CSPs can be used to decompose a task and define interfaces between components. And Tasks can then be used to implement specific components.
For example, when using Actors, we have an entity such as ImageMixer, which needs to be manipulated with images on a pool of worker threads. In general, nothing prevents us from implementing the TaskMixer actor to use the Task-based approach.
Where to look, what to take?
If you wanted to work with Task-s in C ++, then you can look towards the standard library of the upcoming C ++ 20. There, the .then () method has already been added to the future, as well as the free wait_all () and wait_any functions. For details, refer to cppreference .
Also, there is no longer a new async ++ library . In which, in principle, has everything you need, just a little under a different sauce.
And there is another older Microsoft PPL library . Which also gives everything that is needed, but under its own sauce.
Separate addition about the Intel TBB library. It was not mentioned in the story about the Task-based approach because, in my opinion, task graphs from TBB are already a data flow approach. And, if this report gets its continuation, then the speech about Intel TBB will definitely go, but in the context of the story about data flow.
Another interesting
Recently here, on Habré, there was an article by Anton Polukhin: " Preparing for C ++ 20. Coroutines TS with a real example ."
It talks about combining the Task-based approach with stackless coroutines from C ++ 20. And it turned out that the code on the basis of Task readability approached the readability of the code on CSP processes.
So if someone is interested in the Task-based approach, then it makes sense to read this article.
Conclusion
Well, it's time to move on to the results, the benefit of them is not so much.
The main thing that I want to say is that in the modern world bare multithreading you may need it unless you are developing some kind of framework or solving some specific and low-level task.
And if you are writing application code, then you hardly need bare threads, low-level synchronization primitives, or some lock-free algorithms along with lock-free containers. For a long time there are approaches that have been tested by time and have proven themselves well:
- actors
- communicating sequential processes (CSP)
- tasks (async, promises, futures, ...)
- data flows
- reactive programming
- ...
And the main thing is that for them in C ++ there are ready-made tools. You do not need to ride a bike, you can take it, try it and, if you like it, start it up.
So simple: take, try and start up in operation.