Tarantool Replication: Configuration and Usage

I enter the Tarantool Core Team and participate in the development of the database engine, internal communications of server components and replication. And today I will tell you how replication works.
About replication
Replication is the process of creating copies of data from one repository to another. Each copy is called a replica. Replication can be used if you need to get a backup, implement hot standby, or scale the system horizontally. And for this you need to be able to use the same data on different nodes of the cluster's computing network.
We classify replication according to two main features:
- Direction: master-master or master-slave . Master-slave replication is the easiest option. You have one node where you change data. You transmit these changes to the other nodes where they apply. With master-master replication, changes are made on several nodes at once. In this case, each node itself changes its data, and applies changes made on other nodes to itself.
- Mode of operation: asynchronous or synchronous . Synchronous replication means that the data will not be fixed and the user will not be confirmed replication until the changes propagate at least the minimum number of cluster nodes. In asynchronous replication, committing a transaction (its commit) and user interaction are two independent processes. For a data commit, all that is required is that they fall into a local log, and only then these changes are somehow transmitted to other nodes. Obviously, because of this, asynchronous replication has a number of side effects.
How does replication work in Tarantool?
Replication in Tarantool has several features:
- It is built from basic bricks, with which you can create a cluster of any topology. Each such basic configuration item is unidirectional, that is, you always have a master and a slave. The master performs some actions and generates a log of operations that is used on the replica.
- Replication in Tarantool is asynchronous. That is, the system confirms the commit to you, regardless of how many replicas of this transaction were seen, how much it was applied to itself, and whether it happened at all.
- Another replication property in Tarantool is row-based. Tarantool has an inside log of operations (WAL). The operation gets there line by line, that is, when a tapl is changed from a space, this operation is recorded in the log as one line. After that, the background process reads this line from the log and sends it to the replica. How many replicas master has, so many background processes. That is, each replication process to different nodes of the cluster is performed asynchronously from the others.
- Each node of the cluster has its own unique identifier that is generated when the node is created. In addition, the node also has an identifier in the cluster (member number). This is a numeric constant that is assigned to a replica when it is connected to a cluster, and it remains together with the replica during the entire time that it exists in the cluster.
Due to asynchrony, the data fall on the replicas with a delay. That is, you made some change, the system confirmed the commit, on the master the operation has already been applied, but on replicas it will apply with some delay, which is determined by the speed with which the background replication process reads the operation, sends it to the replica, and that .
Because of this, there is the likelihood of out of sync data. Suppose we have several master'ov, which change the interrelated data. It may happen that the operations you use are non-commutative and refer to the same data, then two different cluster members will have different versions of the data.
If replication in Tarantool is a unidirectional master-slave, then how is the master-master to be made?Very simple: create another replication channel but in the other direction. It should be understood that in Tarantool, master-master replication is just a combination of two independent data streams.
Using the same principle, we can connect a third master, and as a result, build a full mesh network in which each replica is a master and a slave for all other replicas.
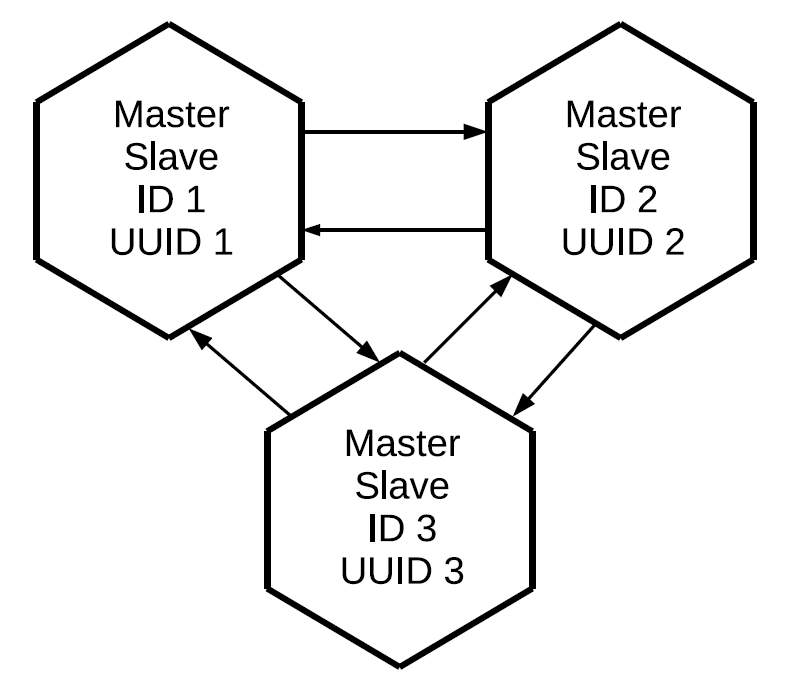
Please note that not only those operations that are initiated locally on this master, but also those that it received from outside via replication protocols are replicated. In this case, the changes created on replica No. 1 will come to replica No. 3 twice: directly and through replica No. 2. This property allows us to build more complex topologies without using full mesh. Let's say this one.
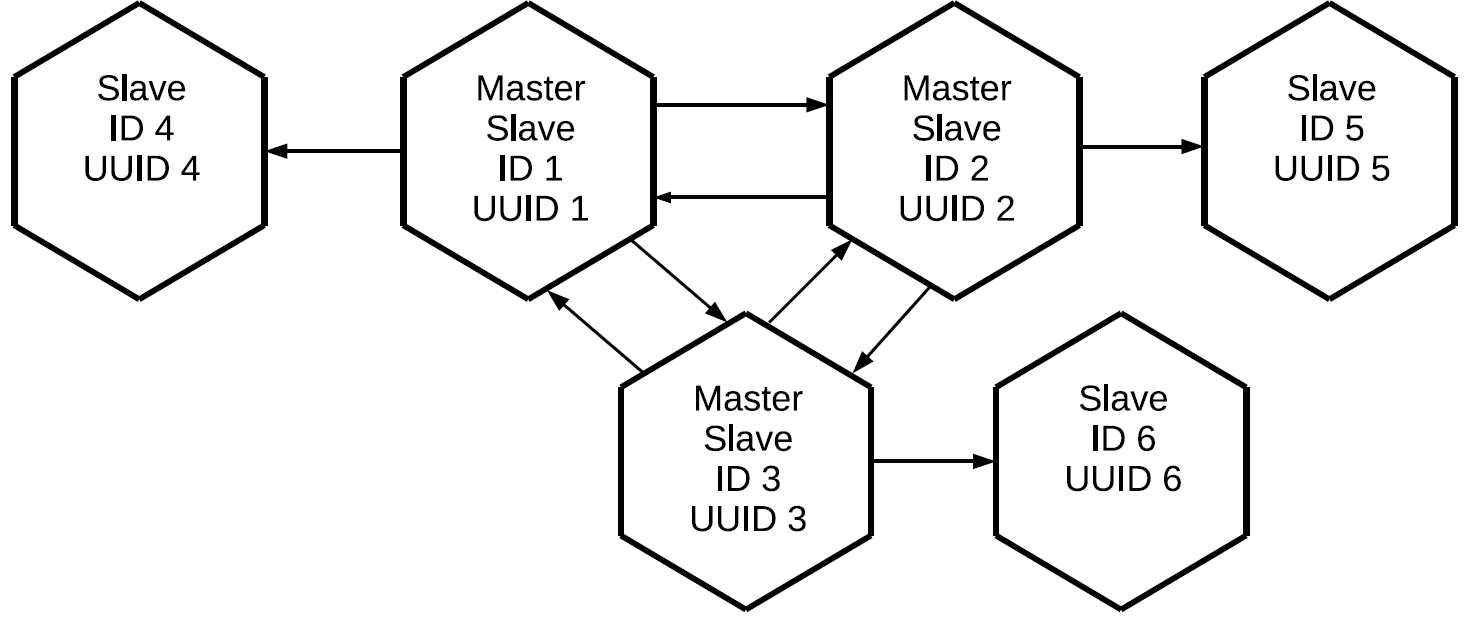
All the masters, who together make up the full mesh core of the cluster, have been assigned an individual replica. Since on each of the master logs the logging is performed, all three “clean” slaves will contain all the operations that were performed on any of the cluster nodes.
This configuration can be used for a variety of tasks. It is possible not to create redundant links between all nodes of the cluster; moreover, if replicas are placed side by side, they will have an exact copy of the master with minimal delay. And all this is done with the help of the master-slave replication element.
Marking operations in a cluster
The question arises: if operations are proxied between all members of the cluster and come to each replica several times, how do we understand which operation needs to be performed and which one does not? This requires a filtering mechanism. Each operation read from the log is assigned two attributes:
- The identifier of the server on which the operation was initiated.
- The sequence number of the operation on the server, lsn, which is its initiator. Each server, when performing an operation, assigns an incrementing number to each received log line: 1, 2, 3, 4, 5, 6, 7, 8, 9, 10 ... Thus, if we know that for a server with some identifier we applied an operation with lsn 10, then operations with lsn 9, 8, 7, 10 that came through other channels of replication are not necessary. Instead, apply the following: 11, 12, and so on.
Replica state
And how does Tarantool store information about those operations that he has already applied? For this, there is a Vclock clock - this is the vector of the last lsn applied relative to each node of the cluster. where is the number of the last known operation from the server with the identifier i. Vclock can also be called a certain known replica snapshot of the entire cluster state. Knowing the server ID of the incoming operation, we isolate the local Vclock component we need, compare the resulting lsn with the lsn operation and decide whether to apply this operation. As a result, operations initiated by a particular master will be sent and applied sequentially. In this case, workflows created on different masters can be intermixed due to asynchronous replication.
[lsn1, lsn2, lsnn]lsniCluster creation
Suppose we have a cluster consisting of two master and slave elements, and we want to connect a third instance to it. It has a unique UUID, but no cluster identifier yet. If a not yet initialized Tarantool wishes to join a cluster, it must send a JOIN operation to one of the master's that can execute it, that is, is in read-write mode. In response to the JOIN, the master sends its local snapshot to the connecting replica. The replica rolls it in, but it still does not have an identifier. Now the replica with a slight lag is synchronized with the cluster. After that, the master, on which the JOIN was executed, assigns an identifier to this replica, which is written to the log and sent to the replica. When an id is assigned to a replica,
Lines from the log are sent starting from the state of this replica at the time of the replication log request from the master — that is, from the vclock it received during the JOIN process, or from the point where the replica stopped earlier. If the replica for some reason has fallen off, then the next time it is connected to the cluster, it does not perform the JOIN, because it already has a local snapshot. It simply requests all operations that occurred during its absence in the cluster.
Register a replica in a cluster
To store the state of the cluster structure, a special space is used - cluster. It contains server identifiers in the cluster, their sequence numbers and unique identifiers.
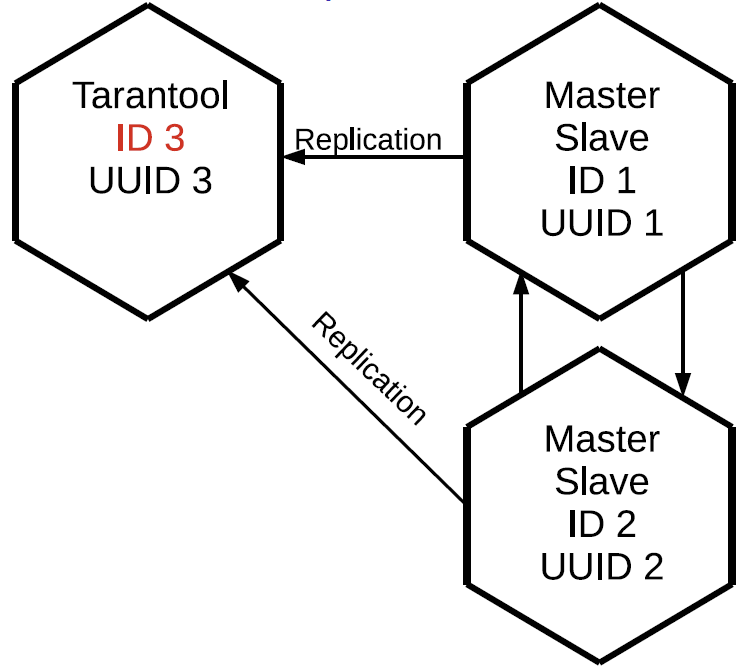
[1, ’c35b285c-c5b1-4bbe-83b1-b825eb594aa4’]
[2, ’37b12cb7-d324-4d75-b428-cde92c18e708’]
[3, ’b72b1aa6-42a0-4d73-a611-900e44cdd465’]Identifiers are not required to go in order, because the nodes can be dropped and added.
Here is the first underwater stone. As a rule, clusters are not assembled one by one: you start some application and it deploys an entire cluster at once. But replication in Tarantool is asynchronous. What if two masters simultaneously connect new nodes and assign them the same identifiers? There will be a conflict.
Here is an example of a wrong and correct JOIN:

We have two masters and two replicas that want to connect. They do JOIN on different master'ah. Suppose replicas get the same identifier. Then the replication between the masters and those who have time to replicate their journals will fall apart, the cluster will fall apart.
To prevent this from happening, you need to initiate replicas strictly on the same master at each time point. To do this, Tarantool introduced such a concept as the initialization leader, and implemented the algorithm for selecting this leader. A replica wishing to connect to a cluster first establishes a connection with all the masters known to it from the transferred configuration. Then the replica selects those that have already been initiated (when a cluster is deployed, not all nodes have time to fully earn). And from them are selected master'y that are available for writing. In Tarantool, read-write and read only happen; we cannot register on the read-only node. After that, from the list of filtered nodes, we select the one that has the smallest UUID.
If we use the same configuration and one server list on the non-initialized instances connecting to the cluster, they will choose the same master, which means the JOIN will most likely be successful.
From here we derive the rule: when replicas are connected in parallel to the cluster, all these replicas should have the same replication configuration. If we omit something somewhere, then there is a possibility that instances with different configurations will be initiated on different masters and the cluster will not be able to assemble.
Suppose that we were mistaken, or the admin forgot to fix the config, or Ansible broke, and the cluster still fell apart. What can this indicate? First, pluggable replicas will not be able to create their local snapshots: replicas do not start and report errors. Secondly, on master logs we will see errors related to conflicts in the space cluster.
How do we resolve this situation? It's simple:
- First of all, you need to validate the configuration that we asked the connecting replicas, because if we do not fix it, then everything else will be useless.
- After this, we clean the conflicts in the cluster and take a snapshot.
Now you can try to initialize the replicas again.
Conflict resolution
So, we created a cluster and connected it. All nodes work in the subscription mode, that is, they receive changes generated by different master'ami. Since replication is asynchronous, conflicts are possible. When you simultaneously change data on different masters, different replicas get different copies of the data, because operations can be applied in a different order.
Here is an example of a cluster after performing a JOIN:

We have three master-slaves, logs are transferred between them, which are proxied in different directions and are used on slaves. Desynchronization of data means that each replica will have its own vclock history of changes, because streams from different master'ov can intermingle with each other. But then the order of application of operations on the instances may differ. If our operations are not commutative, as, for example, the REPLACE operation, then the data that we get on these replicas will be different.
A small example. Suppose we have two masters with vclock = {0,0}. And both will perform two operations, designated as op1,1, op1,2, op2,1, op2,2. This is how the second time quantum looks like when each of the masters performed one local operation:

Green indicates the change to the corresponding vclock component. First, both master'a change their vclock, and then the second master performs another local operation and again increases vclock. The first master receives replication operation from the second master, this is indicated by the red number 1 in the vclock of the first node of the cluster.

Then the second master receives the operation from the first, and the first the second operation from the second. And at the end the first master performs its last operation, and the second master receives it.

Vclock in zero time slot we have the same - {0,0}. On the last quantum of time, we also have the same vclock {2,2}, it would seem, the data should be the same. But the order of operations performed on each master is different. And if this is a REPLACE operation with different values for identical keys? Then, despite the same vclock in the end, we get different versions of the data on both replicas.
We are also able to resolve such a situation.
- Sharding the record . Firstly, we can perform write operations not on randomly selected replicas, but in some way shard them. Just smashed write operations on different masters and get an eventual consistence-system. For example, keys from 1 to 10 on one master and from 11 to 20 on the other have changed - the nodes will exchange their logs and receive absolutely identical data.
Sharding means that we have a router. It does not necessarily have to be a separate entity, the router can be part of the application. This may be a shard that applies to itself operations to write or in one way or another transfers them to another master. But it transmits in such a way that the changes on the associated values go to a particular master: one block of value goes to one master, the other block goes to another master. In this case, read operations can be directed to any node in the cluster. And do not forget about asynchronous replication: if you write it on one master, you may also need to read it from it.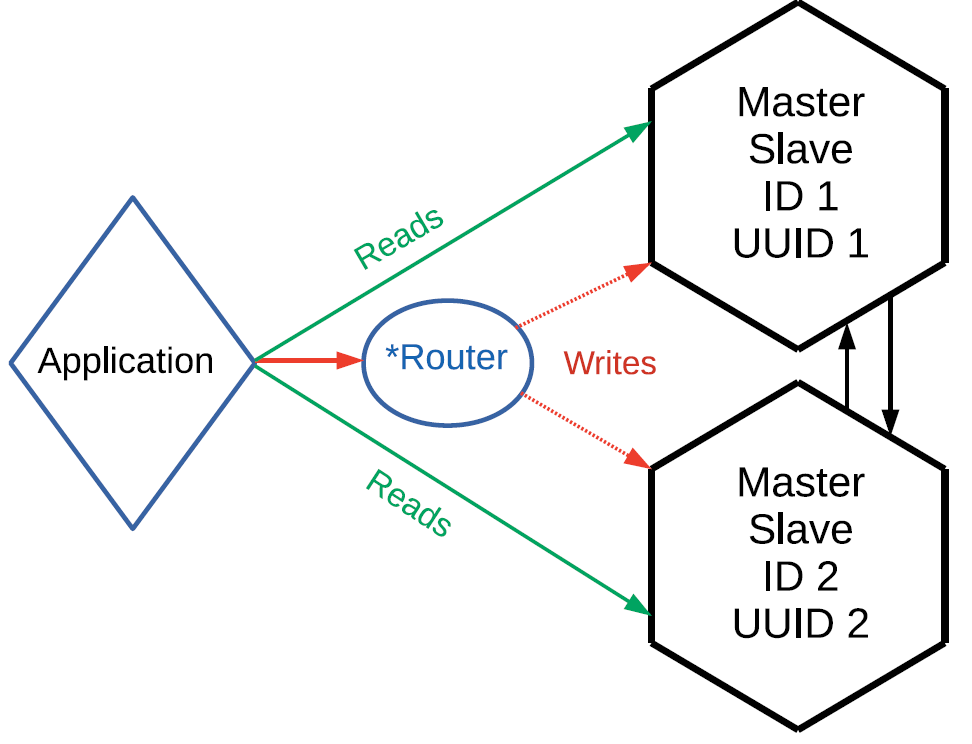
- Logical ordering operations . Suppose that the task conditions can somehow determine the priority of an operation. Say, put the timestamp, or version, or another label that will allow us to understand which operation physically occurred before. That is, we are talking about an external source of ordering.
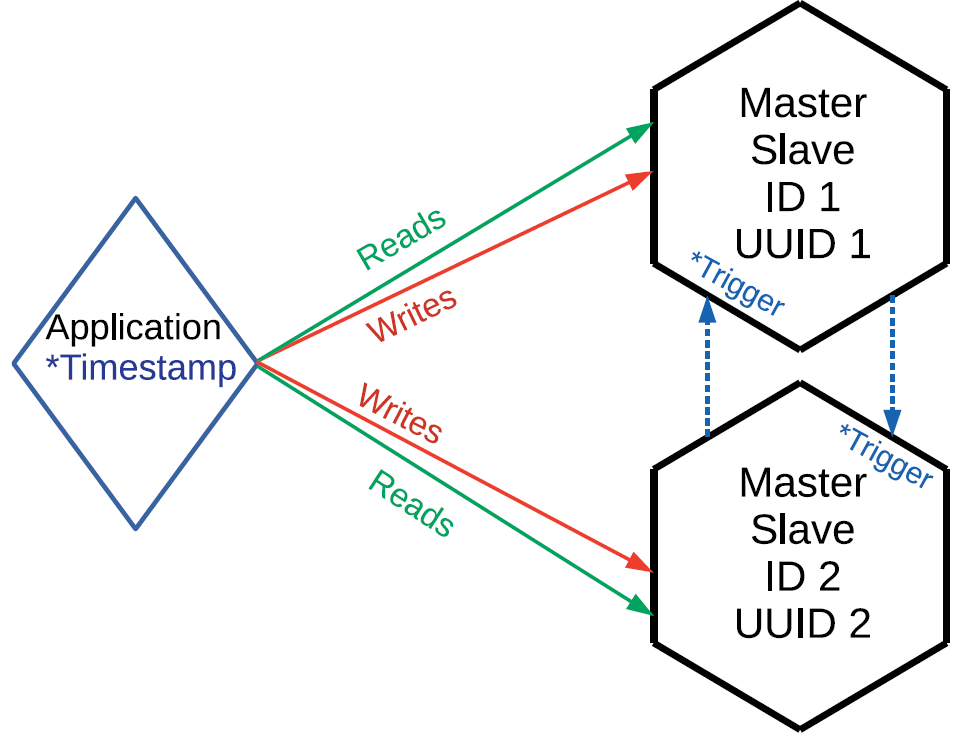
In Tarantool there is a triggerbefore_replacethat can be run during replication. In this case, you and I are not limited by the need to route requests, we can send them where we want. But when replicating at the input of a data stream, we have a trigger. He reads the sent line, compares it with the line that is already stored, and decides which of the lines has a higher priority. That is, the trigger either ignores the request for replication, or applies it, possibly with the required modifications. We are already using this approach, although it also has its drawbacks. First, you need an external synchronization source. For example, an operator in a cellular communication salon makes changes to some subscriber. For such operations, you can use the time on the computer operator, because it is unlikely to make changes to one subscriber will be several operators at the same time.
The second drawback of the method is: since the trigger is applied to every delta that came through replication for each request, this creates an extra computational burden. But then we will have a consistent copy of the data across the cluster.
Synchronization
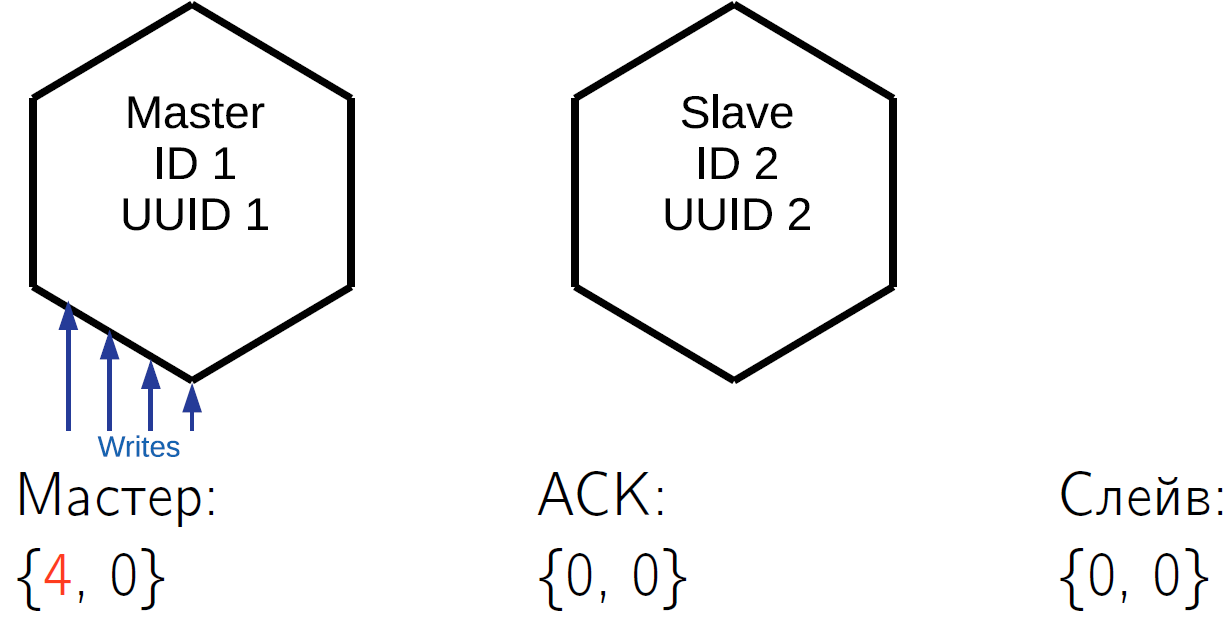
Our replication is asynchronous, that is, when you execute a commit, you don’t know if this data already exists on some other cluster node. If you have performed a commit on master, you have confirmed it, and master for some reason immediately stopped working, then you cannot be sure that the data is somewhere else. To solve this problem, the Tarantool replication protocol has an ACK packet. Each master keeps knowledge of what the latest ACK came from each slave.
What is an ACK? When a slave receives a delta, which is labeled with the master's lsn and its identifier, then in response, it sends a special ACK packet to which it packs its local vclock after applying this operation. Let's see how this can work.
We have a master who has performed 4 operations in himself. Suppose that in some time slot the slave received the first three lines and its vclock increased to {3.0}.
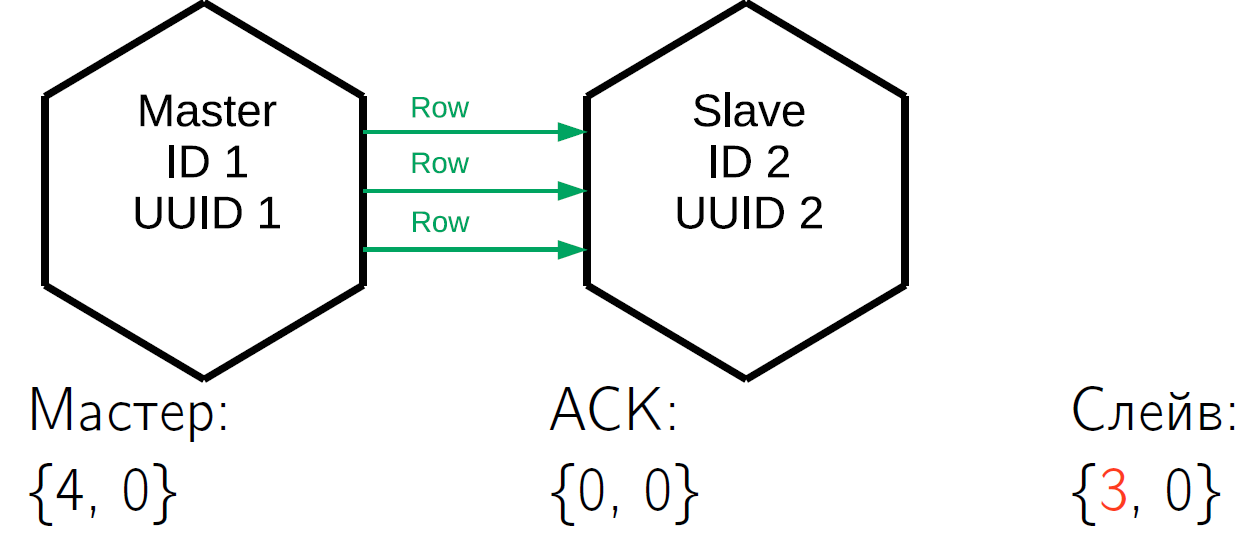
ACK has not come yet. Having received these three lines, the slave sends an ACK packet to which it has stitched up its vclock as of the moment of sending the packet. Let the slave-master send another line to the same time quantum, that is, the slave's vclock has increased. Based on this, master No. 1 knows for sure that the first three operations that he performed have already been applied on this slave. These states are stored for all slaves that the master works with, they are completely independent.

And at the end the slave responds with a fourth ACK packet. After this, the master knows that the slave is synchronized with it.
This mechanism can be used in application code. When you commit the operation, you do not immediately acknowledge the user, but first call the special function. She is waiting for the lsn slave, known to the master, to be equal to your master's lsn at the time of the completion of the commit. So you do not need to wait for complete synchronization, it is enough to wait for the mentioned moment.
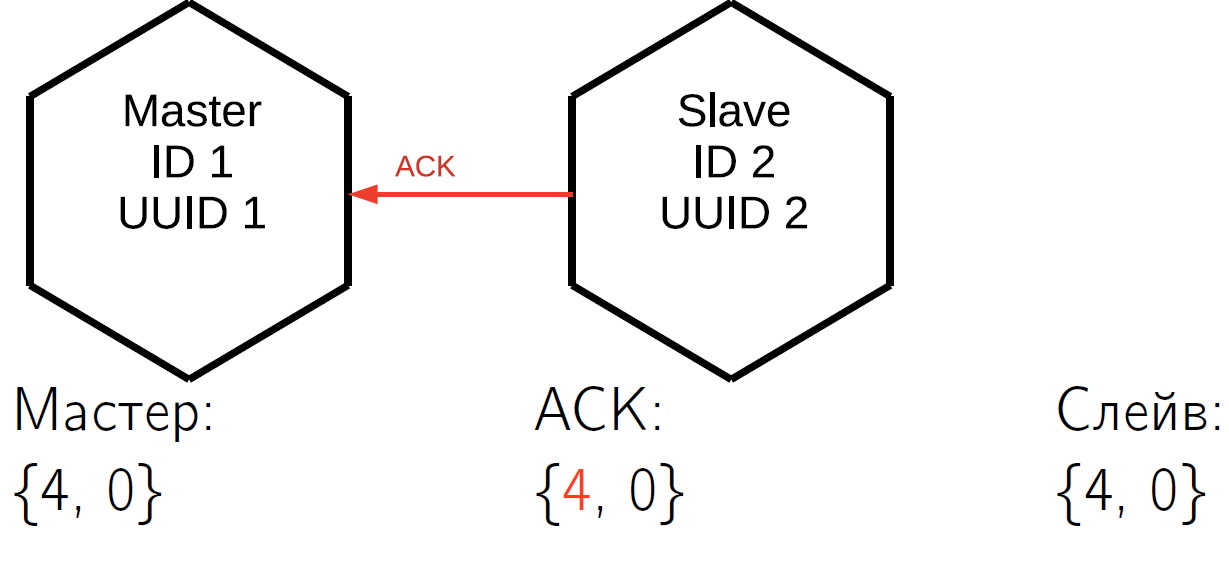
Suppose that our first call changed three lines, and the second call changed one. After the first call, you want to make sure that the data is synchronized. The state shown above already means that the first call was synchronized on at least one slave.
Where exactly to look for information about this, we will look at the next section.
Monitoring
When replication is synchronous, monitoring is very simple: once it falls apart, errors are generated for your operations. And if replication is asynchronous, the situation becomes confusing. The master answers you that everything is fine, it works, accepted, recorded. But at the same time, all the replicas are dead, the data does not have redundancy, and if you lose the master, you will also lose data. Therefore, I really want to monitor the cluster, to understand what is happening with asynchronous replication, where the replicas are, what state they are in.
For basic monitoring in Tarantool is the essence of box.info. It is necessary to call it in the console, as you will see interesting data.
id: 1
uuid: c35b285c-c5b1-4bbe-83b1-b825eb594aa4
lsn : 5
vclock : {2: 1, 1: 5}
replication :
1: id: 1
uuid : c35b285c -c5b1 -4 bbe -83b1 - b825eb594aa4
lsn : 5
2: id: 2
uuid : 37 b12cb7 -d324 -4 d75 -b428 - cde92c18e708
lsn : 1
upstream : status : follow
idle : 0.30358312401222
peer : lag: 3.6001205444336 e -05
downstream : vclock : {2: 1, 1: 5}The most important indicator is the identifier
id. In this case, 1 means that the lsn of this master will be stored in the first position in all vclock. Very useful thing. If you have a conflict with JOIN, then you can distinguish one master from another only by unique identifiers. Also to the local state are values such as lsn. This is the number of the last line that this master has executed and recorded to its journal. In our example, the first master performed five operations. Vclock is the state of those operations that he knows about that he has applied to himself. Finally, for master number 2, he performed one of his replication operations. After indicators of the local state, you can see that this instance knows about the cluster replication status, for this there is a section
replication. It lists all the known nodes in the cluster instance, including itself. The first node has id 1, id corresponds to the current instance. The second node has identifier 2, its lsn 1 corresponds to that lsn, which is recorded in vclock. In this case, we consider master-master replication, when master No. 1 is simultaneously the master for the second node of the cluster, and its slave, that is, follows it.- ESSENCE
upstream. The attributestatus followmeans that master 1 follows master 2. Idle is the time that has passed locally since the last interaction with this master. We do not send the stream continuously, the master sends the delta only when changes occur on it. When we send some ACK, we also interact. Obviously, if idle becomes large (seconds, minutes, hours), then something is wrong. - Attribute
lag. We talked about the delay. In addition to lsn,server ideach operation in the log is also marked by the timestamp, the local time during which this operation was recorded in the vclock on the master that executed it. Slave compares its local timestamp with the delta timestamp it received. The last current timestamp received for the last line, the slave displays in monitoring. - Attribute
downstream. It shows what master knows about its particular slave. This is the ACK that the slave sends to it. Presented abovedownstreammeans that the last time his slave, he master under number 2, sent him his vclock, which was equal to 5.1. This master knows that all five of his lines that he has completed have gone to another node.
XLOG loss
Consider the situation with the fall of the master.
lsn : 0
id: 3
replication :
1: <...>
upstream : status: disconnected
peer : lag: 3.9100646972656 e -05
idle: 1602.836148153
message: connect, called on fd 13, aka [::1]:37960
2: <...>
upstream : status : follow
idle : 0.65611373598222
peer : lag: 1.9550323486328 e -05
3: <...>
vclock : {2: 2, 1: 5}The first thing to change is status.
Lag It does not change because the line we have applied remains and we did not receive new ones. In this case, we are growing idle, in this case it is already equal to 1602 seconds, so much time the master was dead. And we see some kind of error message: there is no network connection. What to do in a similar situation? Understand what happened to our master, attract the administrator, restart the server, raise the node. Repeated replication is performed, and when the master comes into operation, we connect to it, subscribe to its XLOG, get it ourselves and the cluster stabilizes.
But there is one small problem. Imagine that we had a slave, which for some reason turned off and was out for a long time. During this time, the master, who served him, deleted XLOG from himself. For example, the disk is full, the garbage collector has collected logs. How can a returned slave continue working? No Because the logs that he needs to apply in order to become synchronized with the cluster are already gone and there is no place to take them. In this case, we will see an interesting error: the status is no longer
disconnectedas well stopped. And a specific message: there is no log file corresponding to such an lsn.id: 3
replication :
1: <...>
upstream :
peer : status: stopped
lag : 0.0001683235168457
idle : 9.4331328970147
message: ’Missing .xlog file between LSN 7 1: 5, 2: 2 and 8 1: 6, 2: 2’
2: <...>
3: <...>
vclock : {2: 2, 1: 5}In fact, the situation is not always fatal. Suppose that we have more than two master'ov, and on some of them these logs are still preserved. We pour them all masters at once, and do not store only on one. Then it turns out that this replica, connecting to all the masters known to her, will find the necessary logs on one of them. She will perform all these operations, her vclock will increase, and she will reach the current status of the cluster. After that, you can try to reconnect.
If there are no logs left, we cannot continue the replica work. It remains only to reinitialize it. Let's remember its unique identifier, you can write it down on a piece of paper or in a file. Then we clean the replica locally: delete its snapshots, logs, and so on. After that, we re-attach the replica with the same UUID that it had.
Clean up the cluster or reuse UUID for the new replica:
box.cfg{instance_uuid = старый uuid}. This line shows how to re-initialize the replica. The identifiers and UUIDs we store in the space cluster, and the identifier space is limited. If you lose the replica should not throw out the identifier, it is best to use again. If you use the old UUID, then the master, on which we do the JOIN, finds it already as registered, assigns the same UUID to this replica, sends it a snapshot, and the story begins anew.
If we assume that it is impossible to figure out the UUID, then we will have to go to the space cluster and find in it the record that corresponds to the lost replica. After that, we catch the replica as a completely new one. It registers, gets a snapshot, subscribes to a delta, and the cluster becomes consistent and consistent.
Quorum
Suppose that some of the replicas did not work for a long time and lagged behind the cluster for a day. On the one hand, we do not want to lose it and reinitialize it. But on the other hand, we don’t want to risk users reading heavily outdated data.
Tarantool implements a quorum algorithm. The scheme specified in the configuration means that this replica will not return control from the configuration to you until it reaches at least two masters with a lag of not more than 0.1 sec. If within 30 seconds. this replica will not be able to catch up, it will give an error. Lag in 0.1 seconds. is considered synchronization, but you can specify other values.
replication_connect_quorum: 2
replication_connect_timeout: 30
replication_sync_lag: 0.1Keep alive
There are situations when an inaccurate admin put in ip tables drop. You will see that the connection has collapsed somewhere in 30 minutes or 30 seconds, depending on what timeout is on your system. To deal with such situations, we implemented keep alive packages.
We keep alive-package has the timeout:
box.cfg.replication_timeout. If the replica does not see any changes from the master during this timeout, she sends him keep alive packets, saying that she is alive. If during 4 timeouts, master and slave do not see keep alive packets from each other, then they break the connection and try to establish it again. This turned out to be a very convenient means of monitoring the status of the channel between the replica and the master.
Network traffic redundancy
We said that all changes go in a circle. If we have 6 replicas, then each will receive all the deltas 5 times. And if we have 10 replicas, then each will receive 9 times. This situation can also be solved.
When the cluster is initialized, you can slightly change the topology to reduce the redundancy of network traffic. In addition to the need for initialization, we must be sure that there is a route from any master that makes changes to any replica. And in some way purely logically to ensure a balance between channel redundancy and reliability. Here is an example topology.
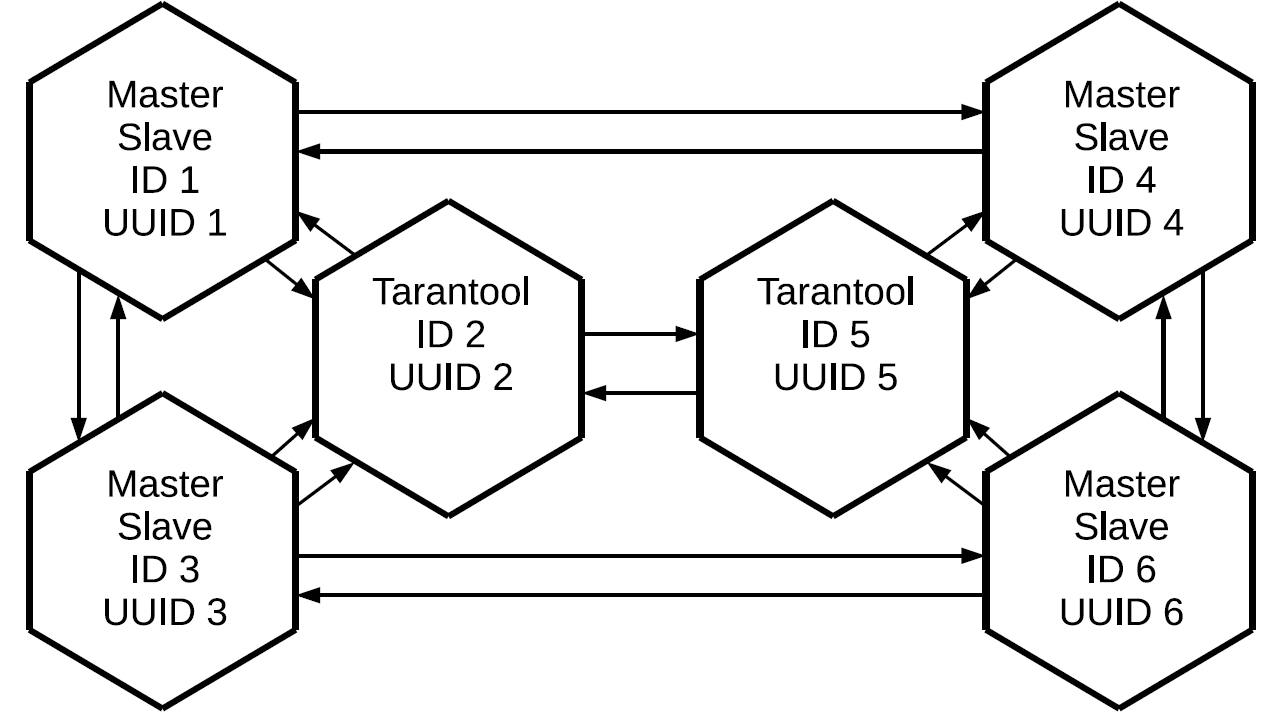
We have 6 replicas here, but the redundancy is only 3. You can lose any two replicas, and the cluster will remain intact. Instead of transmitting each delta 5 times, we will transmit it only 3 times.
Other replication issues
What you need to do if you have problems with replication:
- Check configuration.
- Make a backup, because when you start cleaning the space cluster, it is very interesting to do various operations and try to figure it out. Thus, you risk very easily and quickly losing data.
If it did not work out, write to us in the Telegram-chat, we will try to help. If we could not solve your problem in the chat, then write a ticket on GitHub, we will definitely do it.