Chain replication: building efficient KV storage (part 1/2)

In this article we will consider the architecture of simple and efficient KV-storages using chain replication (chain replication), which is actively investigated and successfully used in various systems.
This is the first half of the chain replication article. The second part is here . First there will be a little theory, then a few examples of use with various modifications.
- The goal is to set the task and compare it with the primary / backup protocol.
- Chain replication is a basic approach.
- Chain replication - distributed requests.
- FAWN: a Fast Array of Wimpy Nodes.
1. Introduction
1.1 Purpose
Suppose we want to design a simple key-value store. The storage will have a very minimal interface:
- write (key, object): save / update value by key.
- read (key): return the saved value by key.
We also know that the data size is relatively small (everything fits on one server, there is no need for sharding), but there can be very, very many write / read requests.
Our goal is to withstand a large number of requests ( high throughput, HT ), to have high availability ( high availability, HA ) and strict consistency ( strong consistency, SC ).
In many systems, SC is sacrificed for the sake of HA + HT, because the performance of all three properties is a non-trivial task. Amazon Dynamo was a huge leap forward and spawned a number of Dynamo-style databases, such as Cassandra, Riak, Voldemort, etc.
1.2 Primary / Backup
One of the most common and simple approaches to building such a data storage system is to use primary / backup replication.
We have 1 primary server, several backup servers, write / read operations go only through the primary server.
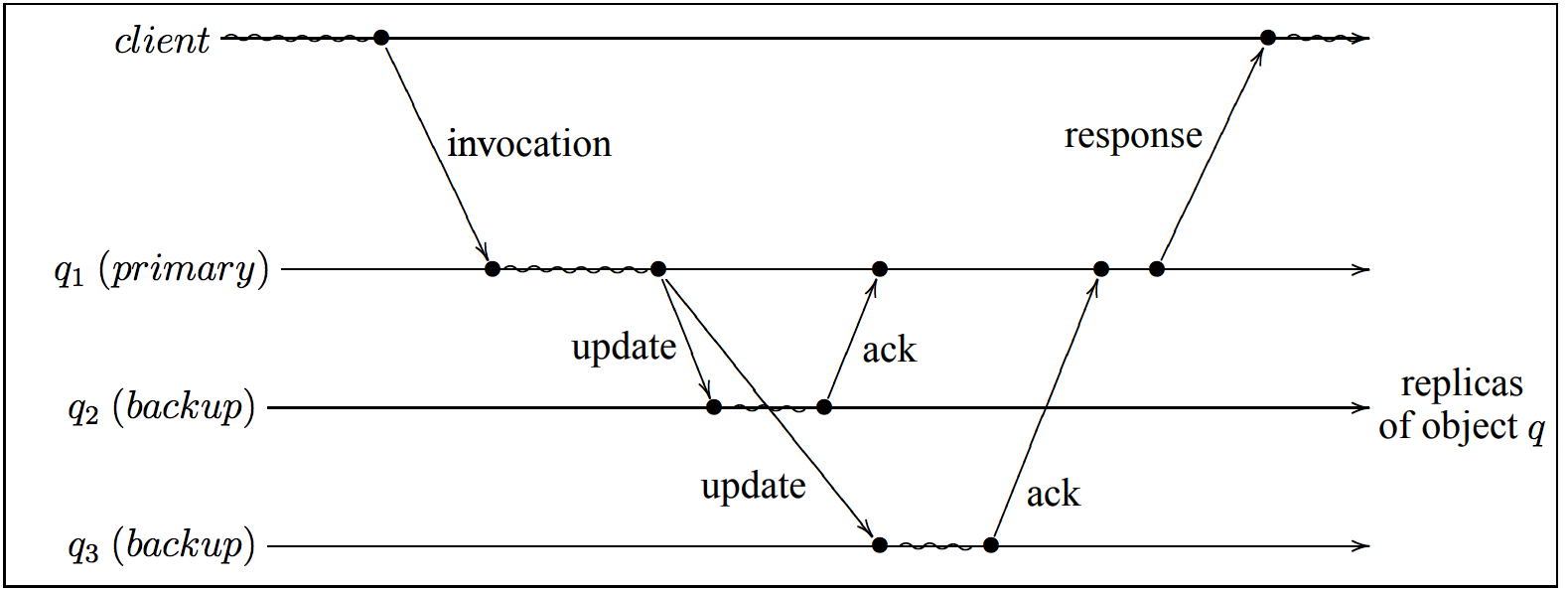
Here, the picture shows one of the possible interaction protocols (the primary waits for ack from all backups before sending the ack to the client), there are other options (not mutually exclusive), for example:
- Primary strictly orders write requests.
- Primary sends ack as soon as one of the backup replied ack.
- Sloppy quorum and hinted handoff.
- Etc.
A separate process is also needed, which monitors the state of the cluster (distributes the configuration to the participants) and when the master server drops, it makes (initiates) new elections, and also determines what to do in the case of split brain. Again, depending on the requirements, a part of this logic can be executed as part of the replication algorithm, part as a third-party application (for example, zookeeper for configuration storage), etc.
Obviously, sooner or later, the performance of primary / backup replication will be limited to two bottlenecks:
- The performance of the primary server.
- Number of backup servers.
The more reliability / consistency requirements are imposed on the cluster, the faster this moment will come.
Are there any other ways to achieve our goal?
1.3 Chain Replication
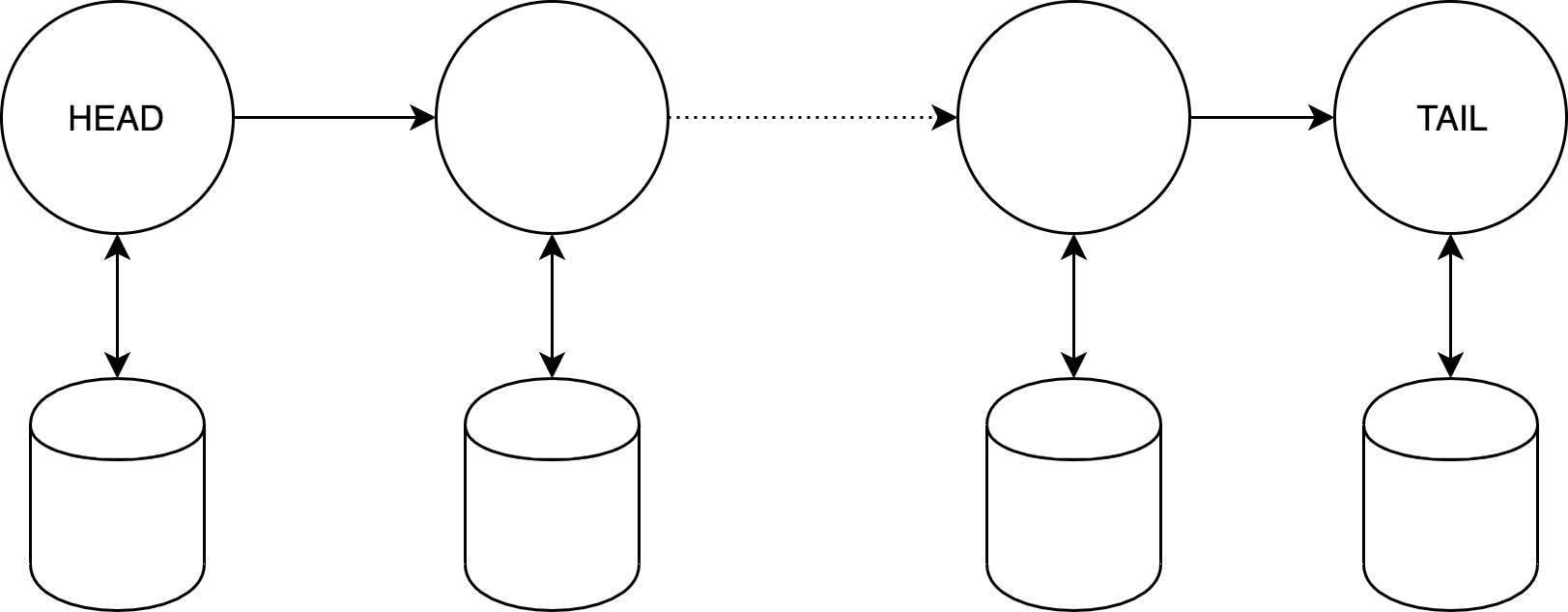
In general, chain replication consists of a sequence (chain) of servers, with special roles HEAD (the server with which the client communicates) and TAIL (chain end, SC warranty). The chain has at least the following properties:
- Withstands crashing to n - 1 servers.
- The write speed is not significantly different from the SC Primary / Backup speed.
- The cluster reconfiguration in case of a HEAD crash occurs much faster than Primary, the other servers are comparatively or faster than in Primary / Backup.
A small but significant point is that you need a reliable FIFO connection between the servers.
Let us further consider in more detail the various methods of constructing chain replication.
2. Basic approach
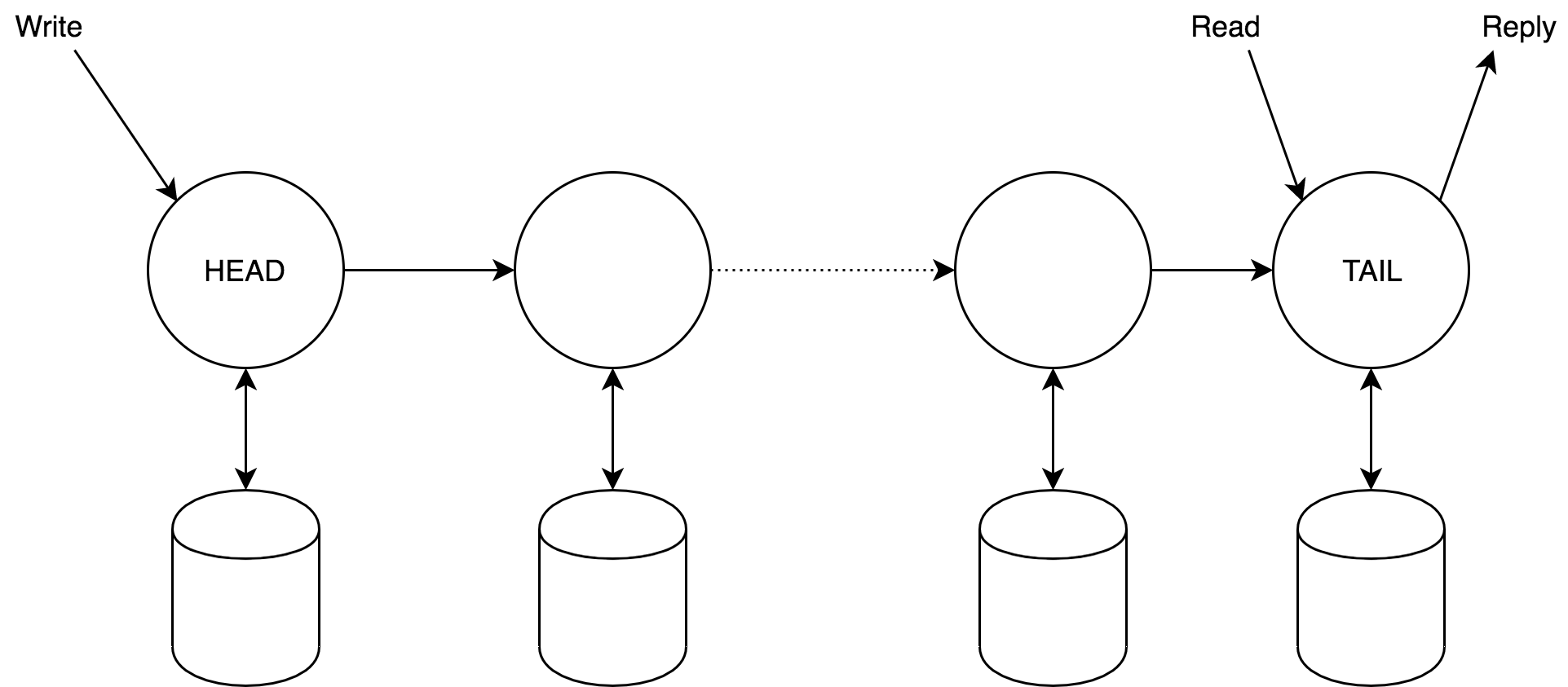
2.1 Algorithm of work
Clients send write requests to the head node, and read requests to the tail node. The answer always comes from tail. Head, upon receiving a change request, calculates the required state change, applies it, and sends it to the next node. As soon as tail processes it, an ACK response is sent back through the chain. Obviously, if the read request returns a certain x value, then it is stored on all nodes.
2.2 Replication Protocol
Let's number servers from head to tail, then on each node
 we will additionally store:
we will additionally store: - a list of received requests by the node that have not yet been processed tail.
- a list of received requests by the node that have not yet been processed tail.  - a list of requests sent by the server to its successor that have not yet been processed by tail.
- a list of requests sent by the server to its successor that have not yet been processed by tail. - history of changes in the key value (you can store both history and just the total value). Notice, that:
- history of changes in the key value (you can store both history and just the total value). Notice, that:
- And:

2.3 Handling server failures
As stated in the introduction, we need a master process that:
- Identifies the failed server.
- Alerts his predecessor and successor about changes in the circuit.
- If the server is tail or head, it notifies clients of their change.
We believe that the master process is stable and never falls. The choice of such a process is beyond the scope of this article.
The second very important assumption is that we assume that the servers are fail-stop:
- In case of any (internal) failure, the server stops working, but does not give an incorrect result.
- Server failure is always determined by the master process.
Consider how a new server is added:
Theoretically, a new server can be added to any place in the chain; requests now need to be sent further.
Finally, consider three possible failure scenarios:
2.3.1. Drop head
Just remove the server from the chain and assign the next new head. There will only be a loss of those requests from
 which were not sent further -
which were not sent further - 
2.3.2 Drop tail
Remove the server from the chain and assign the previous new tail, before
 cleared (all these operations are marked as processed tail), respectively
cleared (all these operations are marked as processed tail), respectively  decreases.
decreases. 2.3.3 Drop intermediate node

Wizard informs nodes
 and
and  about changing the order in the chain.
about changing the order in the chain. Possible loss
 if the node I did not have time to send them further to my successor, so after removing the node from the chain of the first thing re-sent and only after that the node continues to process new requests.
if the node I did not have time to send them further to my successor, so after removing the node from the chain of the first thing re-sent and only after that the node continues to process new requests.2.4 Comparison with backup / primary protocol
- In chain replication, only one server (tail) participates in the execution of read requests, and it issues a response immediately, whereas in the P / B primary it can wait for confirmation of the execution of write requests.
- In both approaches, the write request is executed on all servers, P / B performs it faster due to parallel execution.
Chain replication delays on failures:
- Head: read requests are not interrupted; write requests are delayed by 2 messages — from the wizard to all servers about the new head and from the wizard to all clients about the new head.
- Intermediate server: read requests are not interrupted. Write requests may be delayed for the duration of execution.No loss of updates.
- Tail: Delayed read and write requests for two messages - alert
 about the new tail and notifying customers about the new tail.
about the new tail and notifying customers about the new tail.
P / B delays on failures:
- Primary: a delay of 5 messages to select a new primary and synchronize the state.
- Backup: no delays for reading, provided there are no write requests. When a write request appears, there may be a delay of 1 message.
As you can see, the worst failure (tail) for chain replication is faster than the worst one for P / B (Primary).
The authors of this approach performed load tests that showed comparable performance with the P / B protocol.
3. Distributed Queries (Chain Replication with Apportioned Queries - CRAQ)
The basic approach has an obvious weak point - tail, which handles all read requests. This can lead to two problems:
- Tail becomes a hotspot, i.e. a server that processes much more requests than any other node.
- When placing the chain in several data centers, tail can be very “far” that will slow down write requests.
The idea of CRAQ is quite simple - allow read requests to come to all servers except tail, and to ensure consistency we will store the object version vector for write requests, and in case of ambiguity, the nodes will make a request in tail to get the latest fixed version.
3.1 CRAQ
We formalize the CRAQ architecture:
Each node, except tail, processes read requests and returns a response, and head returns a response from write requests (compare with the basic approach).
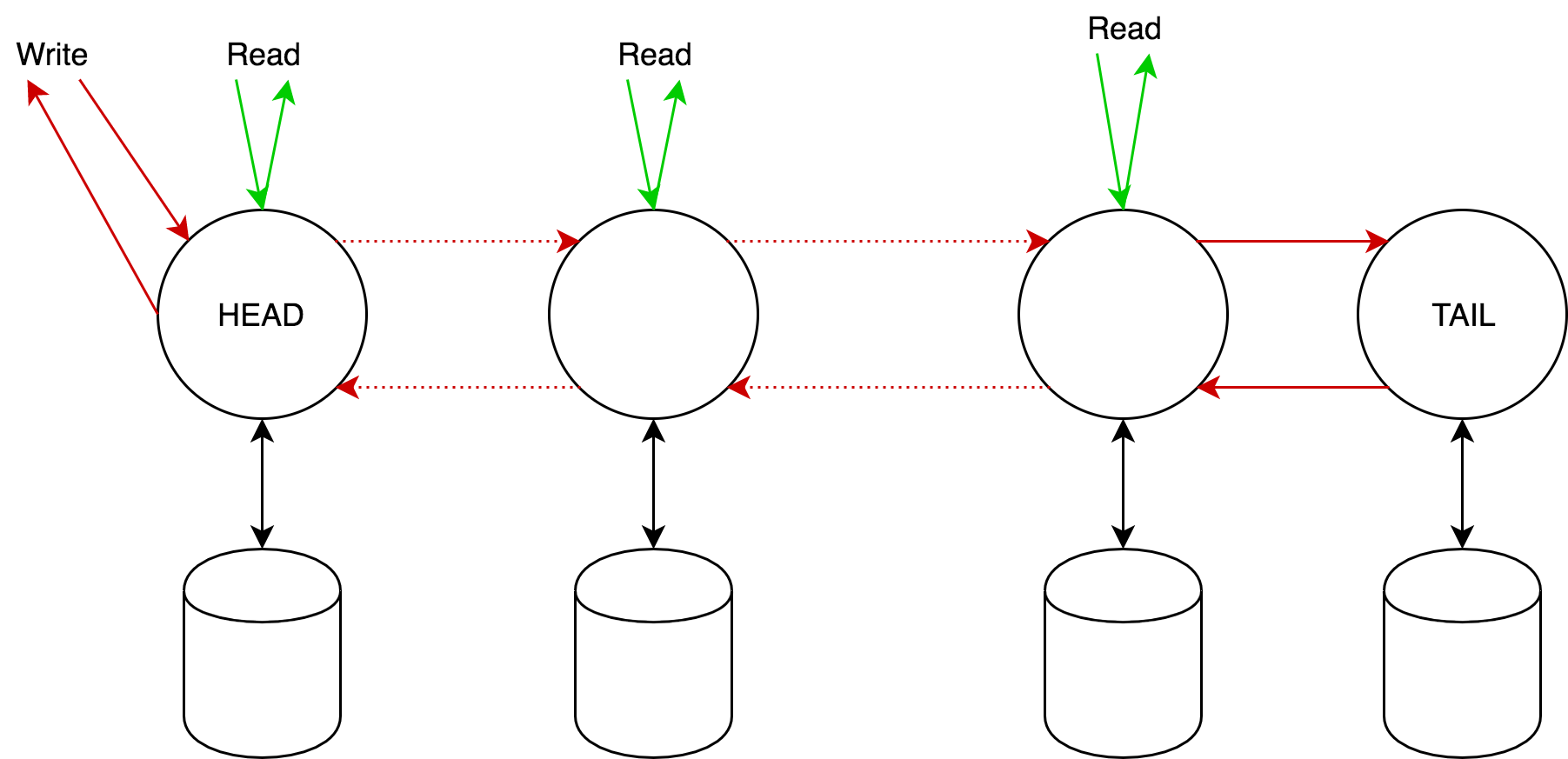
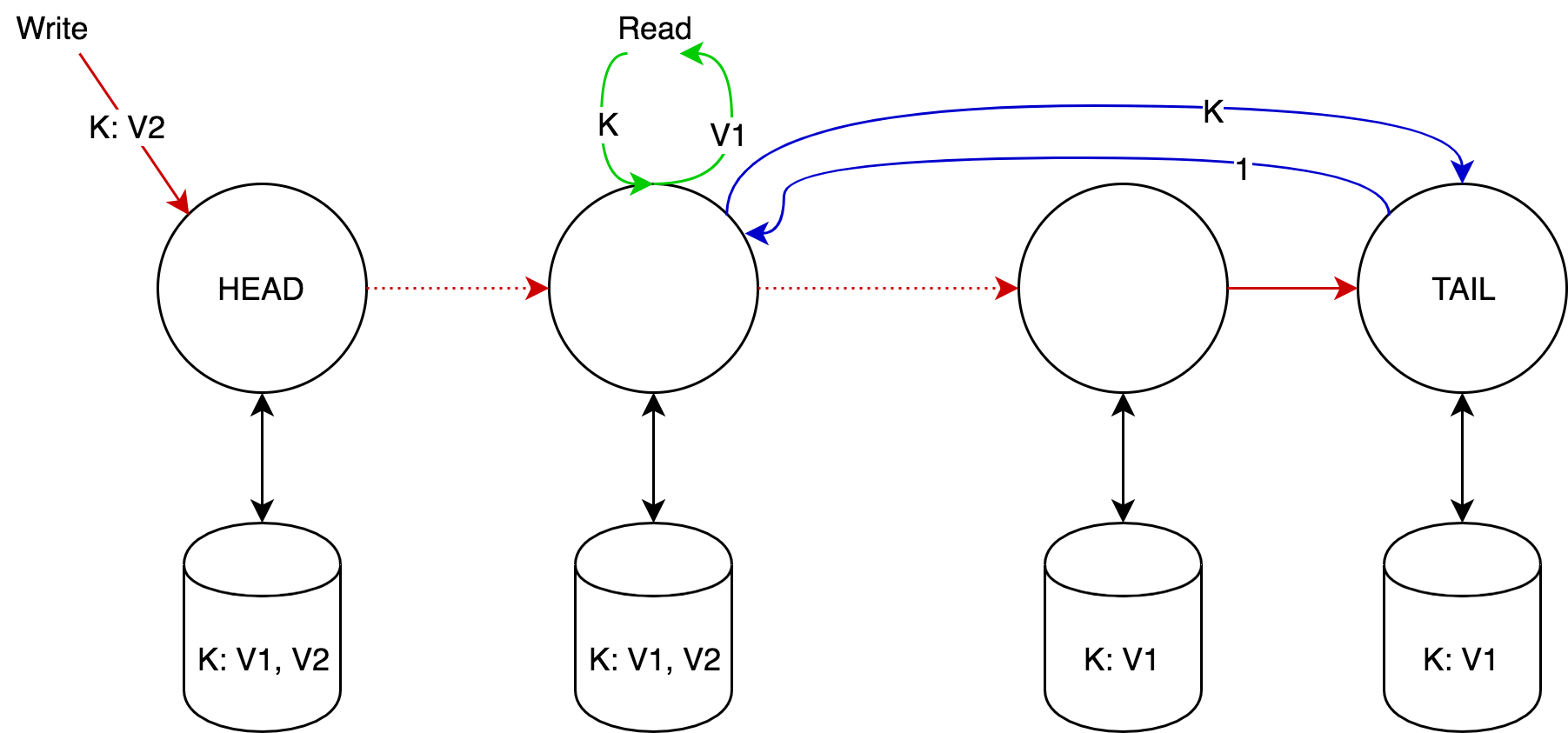
On each non-tail node several versions of the same object can be stored, and the versions form a strictly monotonically increasing sequence. For each version is added an additional attribute "clean" or "dirty." Initially all versions are clean.
As soon as the node receives the write request, it adds the received version to the list of versions, and then:
- If the node is tail, then it marks the version as clean, at this point the version is considered fixed, and sends a confirmation back through the chain.
- Otherwise, it marks the version as dirty and sends the request further down the chain.
As soon as the node receives confirmation from the successor, it marks the version as clean and removes all previous versions.
As soon as the node receives a read request:
- If the last known node version of the object is clean, then it returns it.
- Otherwise - he makes a request to tail for the latest fixed version of the object, which he returns to the client. (By construction, this version will always be on the site).
For applications with a predominance of read requests, the performance of CRAQ grows linearly with the growth of nodes ; in the case of a predominance of write requests, the performance will be no worse than the basic approach.
CRAQ can be located in one or in several data centers. This allows customers to select the nearest nodes to increase the speed of read requests.

3.2 Consistency in the CRAQ
CRAQ provides strong consistency, except in one case: when a node receives the latest fixed version from the tail, the tail can fix a new version before the node responds to the client. In this situation, CRAQ provides monotonous reading (successive read requests will not be a thing of the past, but may return old data) throughout the chain .
Weaker consistency is also possible:
- Eventual Consistency: the node will not request the last fixed version from tail. This will break the monotonous reading on the entire circuit, but will keep the monotonous reading on one node . In addition, it allows you to withstand network separation (partitioning tolerance) .
- Bounded Eventual Consistency: return a dirty version only until a certain moment. For example, the difference between dirty and clean versions should not exceed N revisions. Or time limit.
3.3 Handling server failures
Similar to the basic approach.
3.4 More
CRAQ has one interesting feature - you can use multicast for a write operation. Suppose the head sends a multicast change and sends only a certain identifier of this event further along the chain. If the update itself has not arrived before the node, then it can wait and receive it from the next node when Tail sends a confirmation of the change commit. Similarly, the tail can send a multicast confirmation of fixation.
4. FAWN: a Fast Array of Wimpy Nodes
A very interesting study, not directly related to the topic of this article, but serves as an example of the use of chain replication.
High-performance key-value storage (Dynamo, memcached, Voldemort) have common characteristics - I / O demands, minimal computing, concurrent independent access to random keys in large quantities, small key values - up to 1Kb.
Servers with HDDs are not suitable for such clusters due to the long seek operation (random access time), and servers with a lot of DRAM consume a surprisingly large amount of power — 2GB DRAM is equivalent to 1Tb HDD.
Building an effective (throughput) cluster with minimal power consumption is the goal of the original study. 50% of the cost of the server for three years is the cost of electricity, and modern power saving modes are not as effective as they are advertised - in tests at 20% load, CPU consumption remained at 50%, plus the rest of the server components do not have power saving modes ( DRAM, for example, and so works at a minimum). It is important to note that in such clusters the gap between the CPU and I / O is increasing - a powerful CPU is forced to wait for the I / O operation to complete.
4.1 Architecture
The FAWN cluster is built on old servers for $ 250 (Prices 2009), with built-in CPU 500MHz, 512Mb RAM, 32Gb SSD. If you are familiar with Amazon Dynamo architecture or consistent hashing, then you will be familiar with the FAWN architecture:
- Each physical server contains several virtual nodes, each has its own VID.
- VIDs form a ring, each VID is responsible for the range “behind itself” (for example, A1 is responsible for keys in the R1 range).
- To increase reliability, data is replicated to the following R nodes in a clockwise direction. (for example, when R = 2, the key on A1 is replicated on B1 and C1), so we get chain replication (basic approach).
- Reading requests go to the tail of the chain, i.e. Reading the key with A1 will go to C1.
- Write requests go to the head of the chain and go to the end.
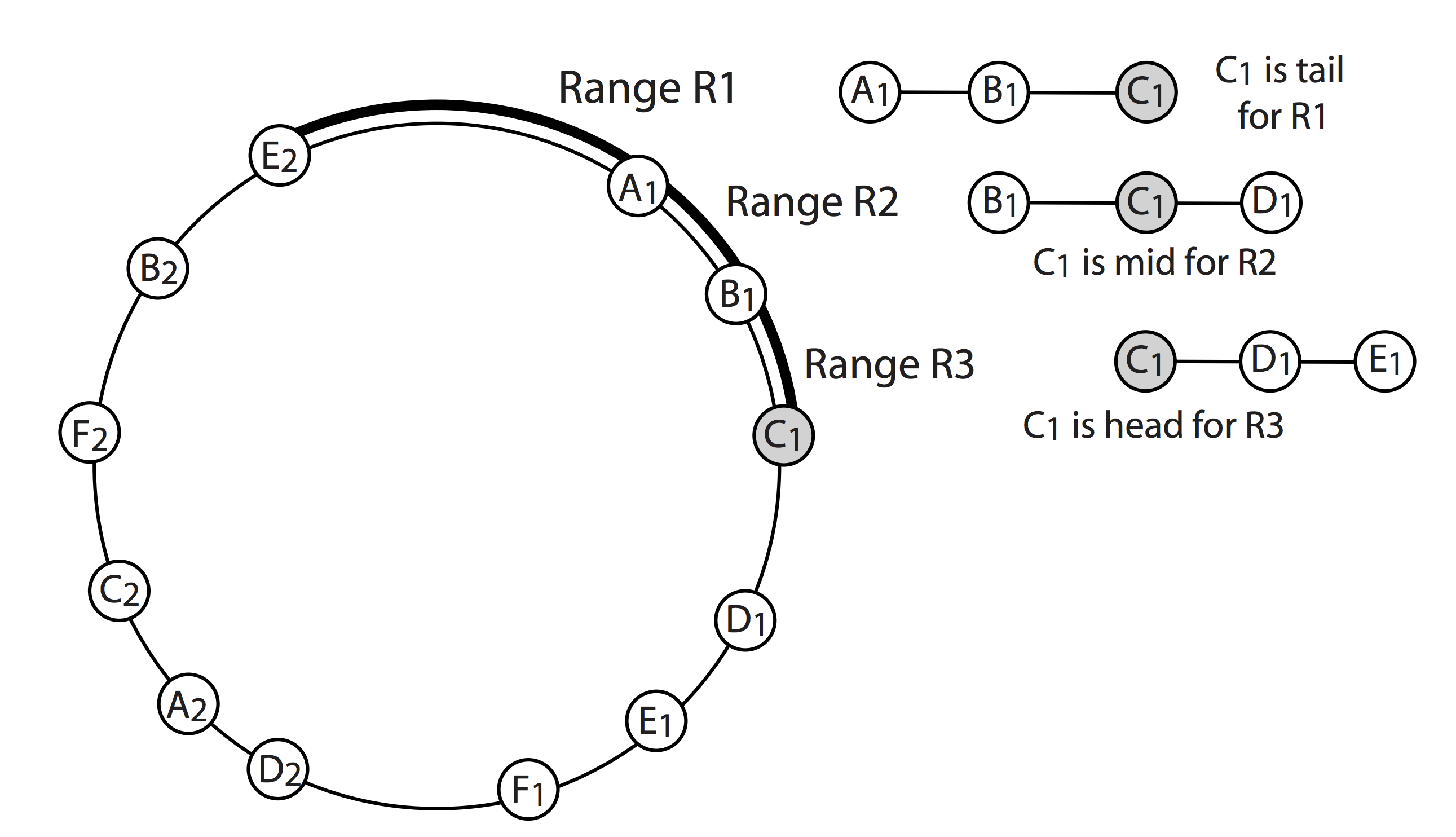
The server map is stored on a cluster of frontend servers, each of which is responsible for its specific VID list, and can redirect the request to a different frontend server.
4.2 Test Results
In FAWN load testing, it reaches QPS (Queries per second) equal to 90% of QPS on a random read flash disk.
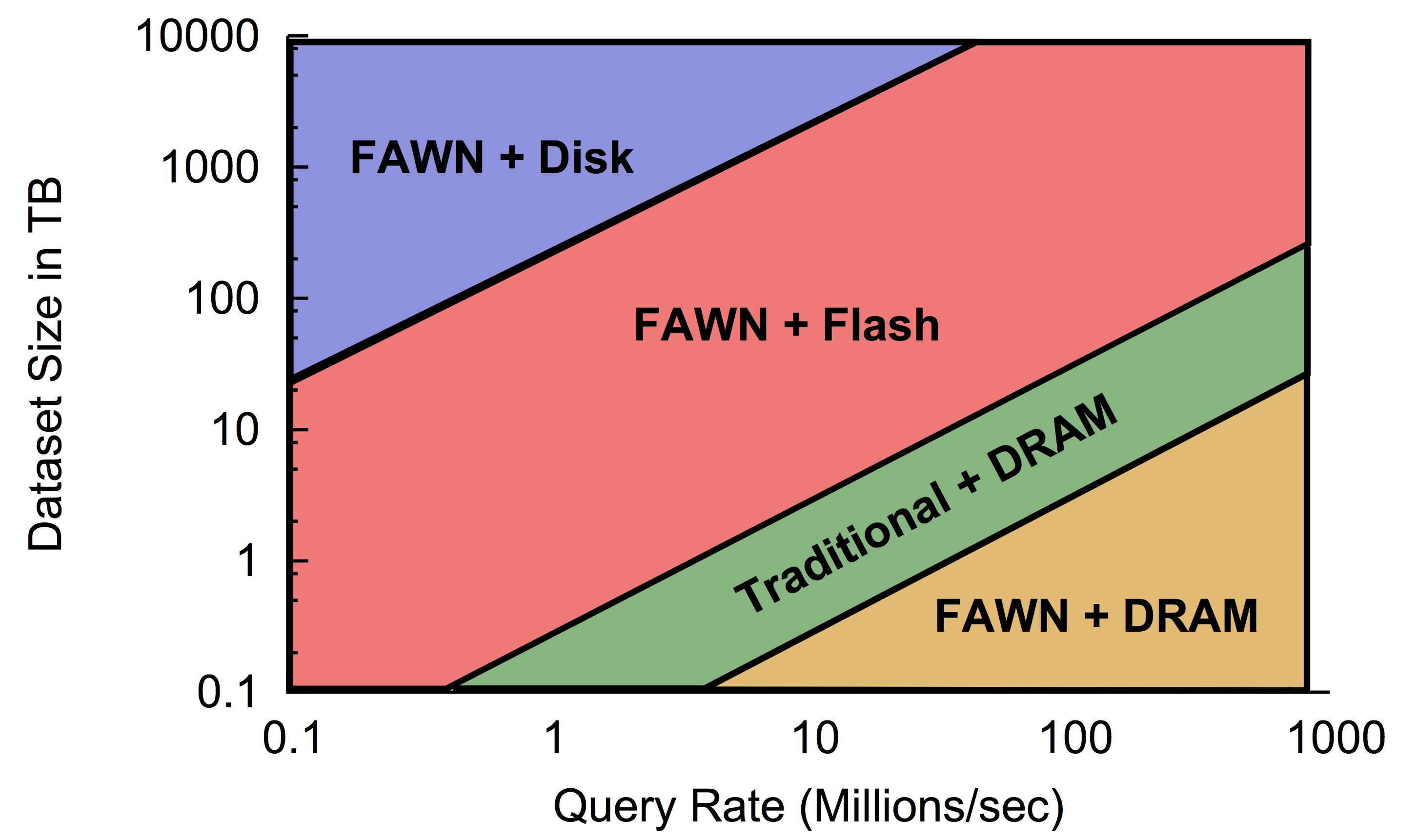
The following table compares the Total Cost of Ownership (TCO) of various configurations, where the basis for Traditional is a $ 1000 server with a consumption of 200W (2009 Prices):
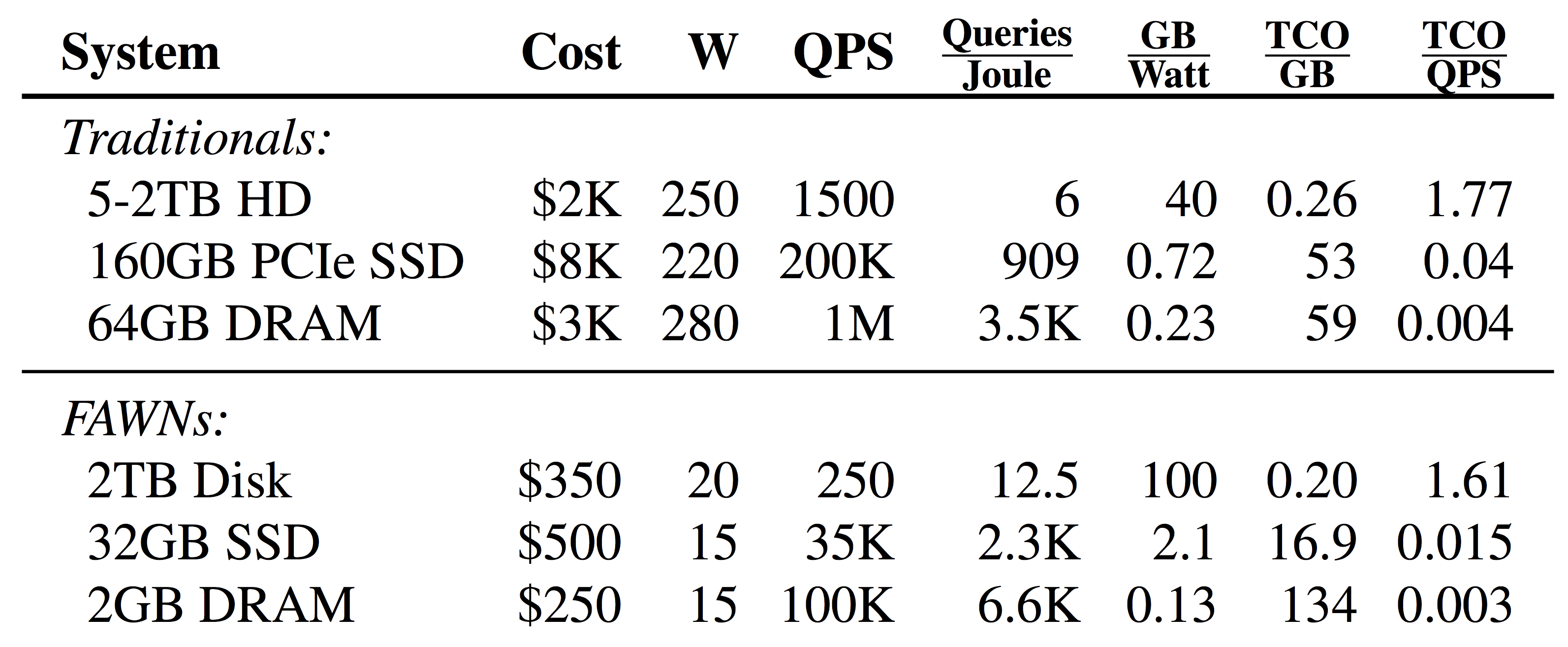
Thus, if:
- Large amount of data, few requests: FAWN + 2Tb 7200 RPM
- A small amount of data, a lot of requests: FAWN + 2GB DRAM
- Average values: FAWN + 32GB SSD