As we Republic website on Kubernetes translated

Scandalous, important and simply very cool materials are not published in the media every day, and no editor will undertake to predict the success of a particular article with 100% accuracy. The maximum that the team has is at the level of instinct to say “strong” material or “ordinary”. Everything. Then begins the unpredictable magic of the media, due to which the article can go to the top of the search results with dozens of links from other publications or the material sinks into oblivion. And just in the case of the publication of cool articles, media sites periodically fall under the monstrous influx of users, which we modestly call “habraeffekt”.
This summer, the site of the Republic of: articles on pension reform, school education and nutrition in general gathered an audience of several million readers. The publication of each of the mentioned material led to such high loads that until the fall of the Republic site, there was absolutely “a little bit of a word”. The administration realized that it was necessary to change something: it was necessary to change the structure of the project so that it could quickly respond to changes in working conditions (mainly external load), while remaining fully functional and accessible to readers, even in moments of very sharp attendance jumps. And a great bonus would be the minimal manual intervention of the technical team of the Republic in such moments.
Following the results of a joint discussion with Republic experts on the various options for the implementation of voiced requests, we decided to transfer the website to Kubernetes *. About what it all cost us all, and will be our story today.
* No Republican technician was hurt during the move
How it looked in general
It all began, of course, from the negotiations, how everything will happen "now" and "then". Unfortunately, the modern paradigm in the IT market implies that as soon as any company goes to the side for some kind of infrastructure solution, the price list of services is “turnkey”. It would seem that the work "turnkey" - what could be nicer and nicer than the conventional director or business owner? I paid, and my head does not hurt: planning, development, support - everything is there, on the side of the contractor, the business can only earn money to pay for such a pleasant service.
However, the complete transfer of IT-infrastructure is not in all cases appropriate for the customer in the long term. It is more correct to work from all points of view as one large team, so that after the completion of the project the client understands how to live with the new infrastructure further, and the colleagues on the shop floor didn’t have the question “oh, but what did they do here?” After signing the certificate of completion and showcase the results. The same opinion was shared by the guys from the Republic. As a result, we landed a landing of four people for a client for two months, who not only realized our idea, but also technically prepared specialists on the Republic side for further work and existence in the realities of Kubernetes.
And all parties benefited from this: we quickly completed the work, kept our specialists ready for new challenges and got the Republic as a client for advisory support with our own engineers. The publication also received a new infrastructure, adapted to the “habra effects”, its own saved staff of technical specialists and the opportunity to ask for help if needed.
Cooking bridgehead
"To destroy is not to build." This saying applies to anything at all. Of course, the simplest solution seems to be the taking of the client’s infrastructure hostage earlier and chaining it, the client, to himself with a chain, or overclocking the existing staff and demanding to hire gurus in new technologies. We went the third, not the most popular way today, and started with the training of engineers of the Republic.
Approximately this solution to ensure the operation of the site we saw at the start:
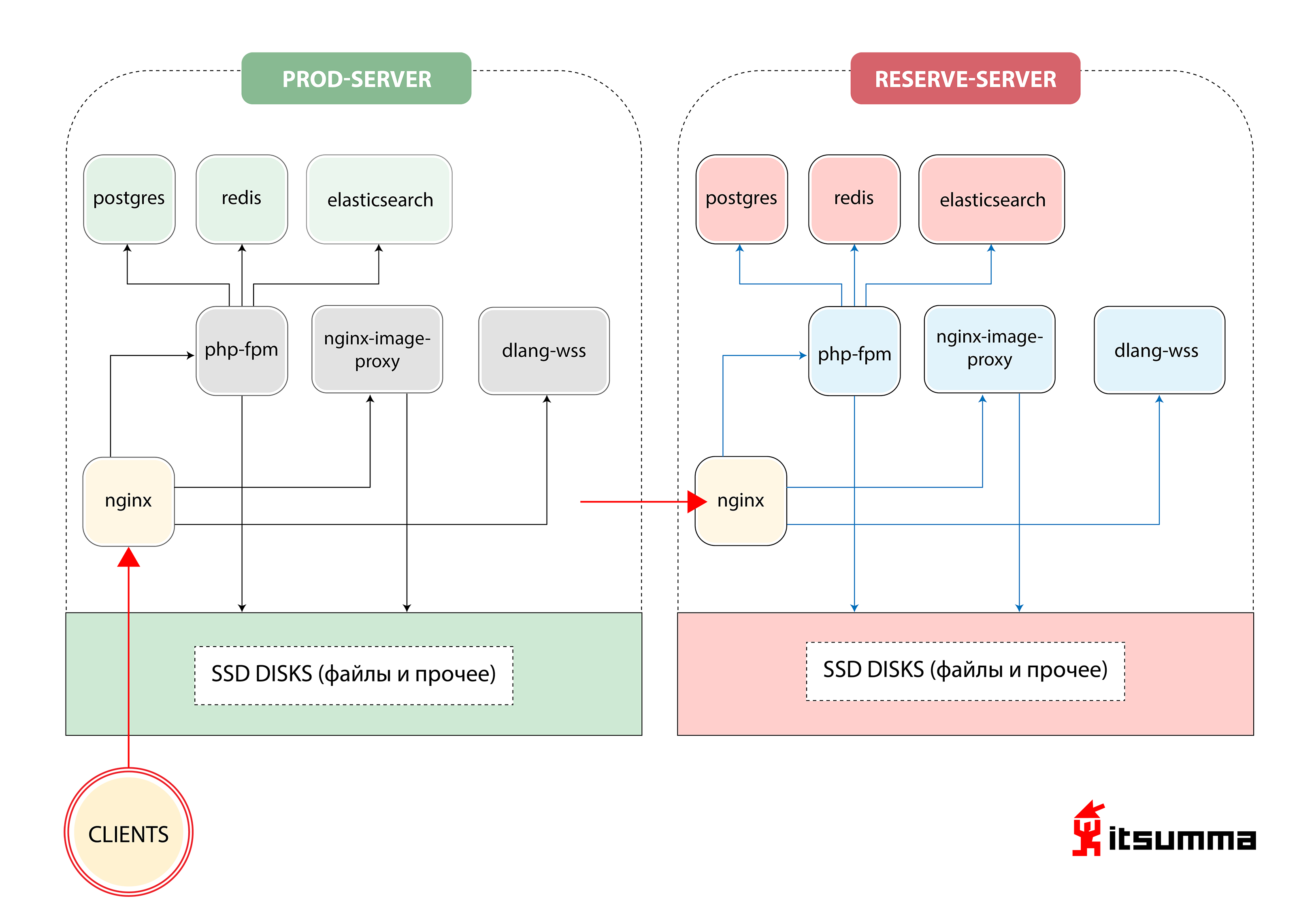
That is, Republic had just two iron servers - the main and backup, backup. The most important thing for us was to achieve a paradigm shift in the thinking of technical client technicians, because they had previously dealt with a very simple bundle of NGINX, PHP-fpm and PostgreSQL. Now they had to face the Kubernetes scalable container architecture. So first we transferred the local Republic development to the docker-compose environment. And this was only the first step.
Before the landing of our landing party, the Republic developers kept their local working environment in virtual machines configured via Vagrant, or they worked directly with the dev server via sftp. Based on the common base image of the virtual machine, each developer “pre-configured” his typewriter “for himself”, which gave rise to a whole set of different configurations. As a result of this approach, connecting new people to the team exponentially increased the time they entered the project.
In the new reality, we offered the team a more transparent structure of the working environment. It declaratively described what software and which versions are needed for the project, the order of connections and interactions between services (applications). This description was uploaded to a separate git repository, so that they can be conveniently managed centrally.
All the necessary applications started running in separate docker containers - and this is a regular php site with nginx, a lot of static, image services (resize, optimization, etc.), and ... a separate service for web sockets written in D All configuration files (nginx-conf, php-conf ...) also became part of the project codebase.
Accordingly, the local environment, completely identical to the current server infrastructure, was “recreated”. In this way, the time spent on maintaining the same environment was reduced, both on the local development machines and on the sale. That, in turn, greatly helped to avoid completely unnecessary problems caused by self-written local configurations of each developer.
As a result, the following services were raised in the docker-compose environment:
- web for php-fpm applications;
- nginx;
- impproxy and cairosvg (image services);
- postgres;
- redis;
- elastic-search;
- trumpet (the same service for web sockets on D).
From the developers' point of view, the work with the code base remained unchanged - it was mounted into the necessary services from a separate directory (basic repository with the site code) into the necessary services: public directory into the nginx service, all the php application code into the php-fpm service. From the separate directory (which contains all configs of the compose environment) in the nginx and php-fpm services, the corresponding configuration files are mounted. The directories with the postgres, elasticsearch and redis data are also mounted on the developer’s local machine, so that if all the containers have to be rebuilt / deleted, the data in these services will not be lost.
To work with application logs — also in the docker-compose environment — the services of the ELK stack were raised. Previously, some application logs were written to standard / var / log / ..., php-application logs and exceptions were written to Sentry, and such a variant of “decentralized” log storage was extremely inconvenient in operation. Now, applications and services have been configured and refined to interact with the ELK stack. It has become much easier to operate with logs, the developers have a convenient interface for searching, filtering logs. In the future (already in the cube) - you can watch the logs of a specific version of the application (for example, the crones running the day before yesterday).
Then the Republic team began a short period of adaptation. The team needed to understand and learn how to work in the new development paradigm, in which the following should be considered:
- Applications become stateless, and they can lose data at any time, so working with databases, sessions, static files should be built differently. PHP sessions should be stored centrally and flipped between all instances of the application. It may continue to be files, but more often redis is taken for this purpose due to greater ease of management. Database containers must either “mount into themselves” a datadir, or the database must be running outside the container infrastructure.
- File storage from about 50-60 GB of images should not be "inside the web application." For such purposes it is necessary to use any external storage, cdn-systems, etc.
- All applications (databases, application servers ...) are now separate “services”, and the interaction between them must be configured with respect to the new namespace.
After the Republic development team mastered the innovations, we began to transfer the distribution infrastructure of the publication to Kubernetes.
And here is Kubernetes
Based on the environment built for local development of docker-compose, we began to translate the project into a “cube”. All the services on which the project is built locally, we “packed into containers”: we organized a linear and understandable procedure for building applications, storing configurations, compiling statics. From the point of view of development, we carried the configuration parameters we needed into environment variables, began to store sessions not in files, but in radish. They picked up a test environment where they deployed a workable version of the site.
Since this is a former monolithic project, it is obvious that there was a strong relationship between the frontend and backend versions, respectively, and these two components deplored simultaneously. Therefore, we decided to build web applications in such a way that two containers spun at once in one file: php-fpm and nginx.
We also built autoscaling to allow web applications to scale to a maximum of 12 at the peak of the traffic, set some liveness / readiness of the sample, because the application requires at least 2 minutes to start (because you need to warm up the cache, generate configs ...)
Immediately, of course, there were all sorts of shoals and nuances. For example: compiled statics was needed both by the web server that distributed it, and by the application server on fpm, which generated some pictures on the fly, somewhere by code gave it to svg. We understood that in order not to get up twice, we need to create an intermediate build-container and final assembly to containerize through a multi-stage. To do this, we created several intermediate containers, in each of which the dependencies are tightened separately, then the statics (css and js) are collected separately, and then in two containers — in nginx and in fpm — they are copied from the intermediate build container.
We start
To work with the files of the first iteration, we made a common directory that was synchronized to all the working machines. By the word "synchronized" I mean here exactly what you can think of with horror first of all - rsync in a circle. Obviously a bad decision. As a result, we got all the disk space on GlusterFS, set up work with pictures so that they were always accessible from any machine and did not slow down. For the interaction of our applications with data storage systems (postgres, elasticsearch, redis), externalName services were created in k8s to update connection parameters in one place in the case of, for example, an emergency switch to the backup database.
All work with crones was brought to the new entities k8s - cronjob, which can run on a specific schedule.
As a result, we got the following architecture: Clickable

About difficult
It was the launch of the first version, because in parallel with the complete rebuilding of the infrastructure, the site was still undergoing redesign. Part of the site was going with the same parameters - for statics and everything else, and some - with others. There it was necessary ... as if to say more ... to be perverted with all these multistage containers, to copy data from them in a different order, etc.
We also had to dance with tambourines around the CI \ CD system in order to teach all of this to deploy and control from different repositories and from different environments. After all, you need constant control over the versions of the applications so that you can understand when the application of this or that service occurred and with which version of the application certain errors began. To do this, we have established the correct logging system (as well as the very culture of logging) and implemented ELK. Colleagues have learned how to set certain selectors, look at which cron generates which errors, how it is executed at all, because in the "cube" after the cron-container is executed, you will not get into it anymore.
But the most difficult for us was to rework and revise the entire code base.
Let me remind you, Republic is a project that is now turning 10 years old. It began with one team, another is developing now, and it is really difficult to shovel all the source codes for possible bugs and errors. Of course, at this moment our landing party of four people connected the resources of the rest of the team: we clicked and drove the entire site with tests, even in those sections that real people have not visited since 2016.
No files anywhere
On Monday, in the early morning, when people sent a mass mailing with a digest, we all got a stake. The culprit was found rather quickly: a cronjob was launched and began fiercely furious to send letters to everyone who wanted to receive a selection of news over the past week, devouring the resources of the entire cluster. With such behavior, we could not come to terms, so that we quickly put down strict limits on the resources: how much CPU and memory can
How did the team of developers Republic
Our activity brought a lot of changes, and we understood that. In fact, we have not only redrawn the infrastructure of the publication, instead of the usual bundle of “primary-backup server” by introducing a container solution, which, as necessary, adds additional resources, but also completely changed the approach to further development.
After some time, the guys began to realize that it was not directly working with the code, but working with an abstract application. Considering the CI \ CD processes (built on Jenkins), they started writing tests, they had full dev-stage-prod environments, where they can test new versions of their application in real time, watch where things fall off, and learn to live in new perfect world.
What the customer received
First of all, Republic finally got a controlled process of deployment! Previously, how it happened: in the Republic there was a responsible person who went to the server, started everything manually, then collected the statics, checked with his hands that nothing had fallen off ... Now the deployment process is built in such a way that the developers are engaged in the development and do not spend time on anything else . Yes, and the person in charge now has one task - to monitor how the release went in general.
After the push to the master branch occurs, either automatically or by “clicking on the button” (periodically due to certain business requirements, the automatic deployment is disabled), Jenkins enters the battle: the assembly of the project begins. First of all, all the docker-containers are assembled: dependencies are set in the preparatory containers (composer, yarn, npm), which allows speeding up the build process, if the complete list of necessary libraries has not changed; then the containers for php-fpm, nginx, and other services are collected, into which, by analogy with the docker-compose environment, only the necessary parts of the code base are copied. After that, tests are run and, in case of successful passing of tests, there is a push of images to a private repository and, in fact, rolling out deployments in a cuber.
Thanks to the translation of the Republic into k8s, we got an architecture that uses a cluster of three real machines that can simultaneously spin up to twelve copies of the web application. At the same time, the system itself, based on current loads, decides how many copies it needs right now. We took Republic from the lottery "works - does not work" with static primary and backup servers and built for them a flexible system, ready for an avalanche-like increase in the load on the site.
At this point, the question may arise: “guys, you changed two pieces of iron for the same pieces of hardware, but with virtualization, what kind of gain, are you all right there?” And, of course, it will be logical. But only in part. As a result, we got not just hardware with virtualization. We received a stabilized working environment, the same in both sales and maidens. The environment that is managed centrally for all project participants. We got a mechanism for assembling the entire project and rolling out releases, again, one for all. We got a convenient project orchestration system. As soon as the Republic team will notice that they generally cease to have enough current resources and risks of ultrahigh loads (or when it’s already done and everything is laid down), they just take another server, in 10 minutes they roll out the role of a cluster node, and op-op - everything is beautiful and good again.
Secondly, a seamless deployment appeared: the visitor either gets to the old version of the application, or to the new one. And not like before, when the content could be new, and the styles are old.
As a result, the business is satisfied: now you can do all sorts of new things faster and more often.
Totally from “let's try” to “done”, the work on the project took 2 months. The team on our side is a heroic landing of four people + support of the “base” for the duration of the code and test checks.
What users got
And visitors, in principle, did not see the changes. The deployment process on the RollingUpdate strategy is built seamless. Rolling out a new version of the site does not affect users, the new version of the site, until the tests pass and the liveness / readiness of the sample, will not be available. They just see that the site is working and doesn’t seem to be going down after posting cool articles. That, in general, is what any project needs.