Using UTF-8 in HTTP headers

As you know, HTTP 1.1 is a text-based data transfer protocol. HTTP messages are encoded using ISO-8859-1 (which can be conventionally considered an extended version of ASCII containing umlauts, diacritics, and other characters used in Western European languages). In this case, the message body can use a different encoding, which should be indicated in the header "Content-Type". But what if we need to specify non-ASCII characters not in the body of the message, but in the headers themselves? Probably the most common case is putting a file name in the “Content-Disposition” header. This would seem to be a fairly common task, but its implementation is not so obvious.
TL; DR: Use the encoding described in RFC 6266, for "Content-Disposition" and convert the text to Latin (transliteration) in other cases.
A little intro to encodings
The article mentions and uses US-ASCII encodings (often simply referred to as ASCII), ISO-8859-1, and UTF-8. This is a small introduction to these encodings. The section is intended for developers who rarely or do not work at all with encodings and have forgotten them. If you do not belong to them, feel free to skip the section.
ASCII is a simple encoding that contains 128 characters and includes the entire English alphabet, numbers, punctuation marks, and service characters.
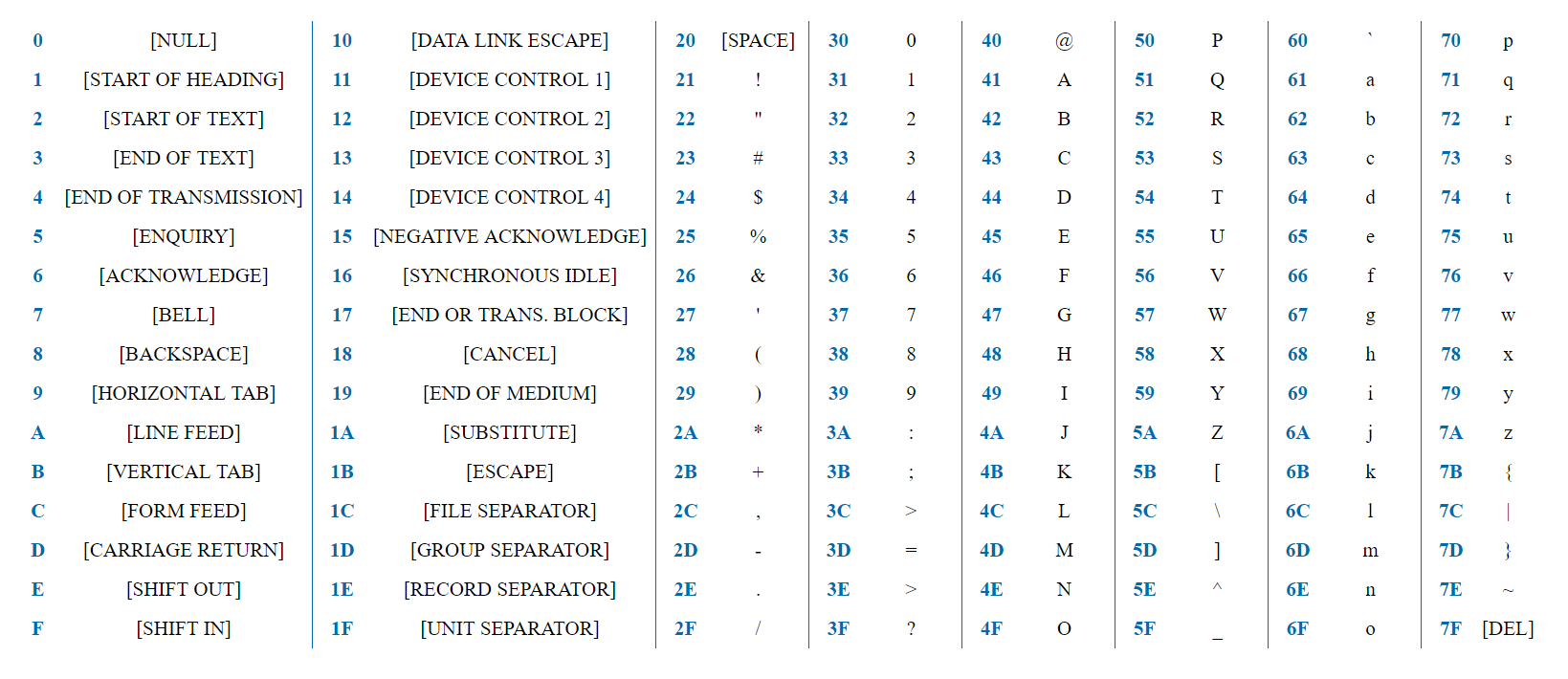
7 bits is enough to represent any ASCII character. The word “test” will be represented in the HEX view as 0x74 0x65 0x73 0x74. The first bit of all characters is always 0, because the characters are encoded in 128, and the byte provides 2 ^ 8 = 256 options.
ISO-8859-1- encoding intended for Western European languages. Contains French diacritics, German umlauts, etc.
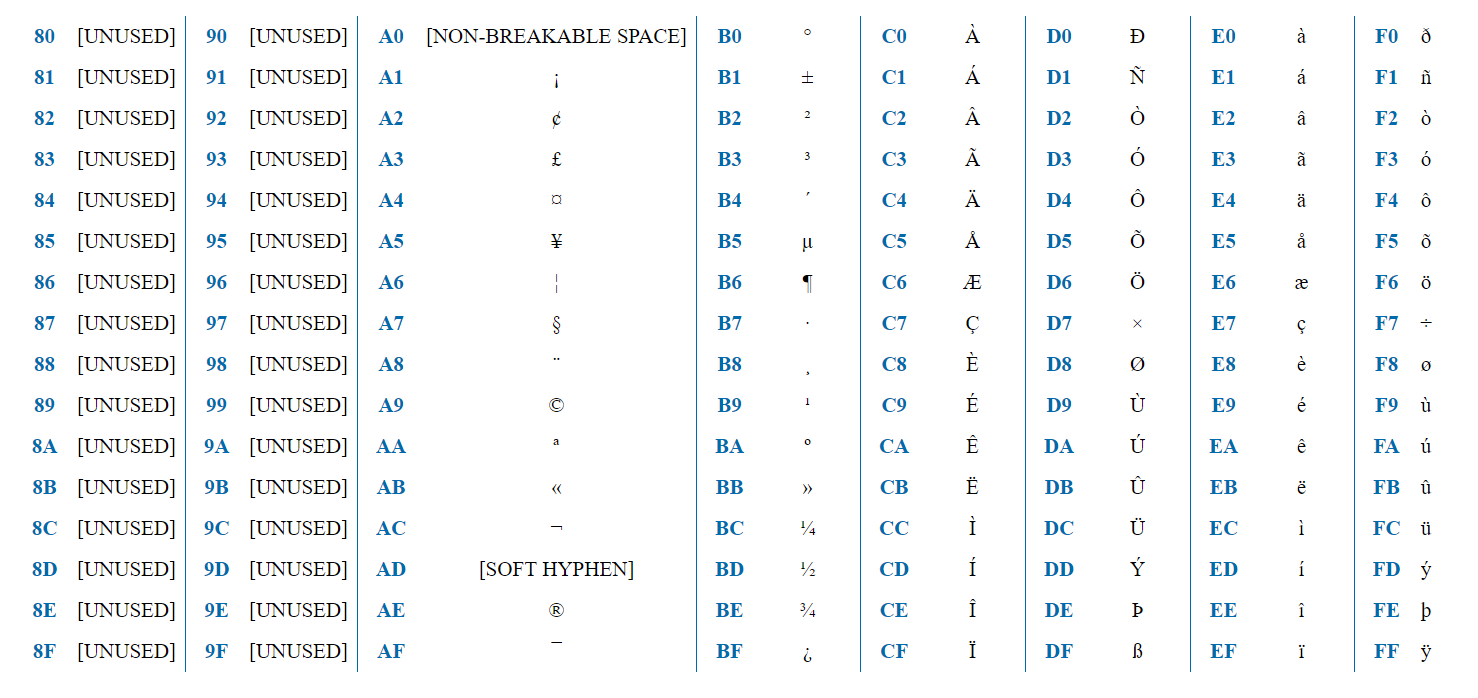
The encoding contains 256 characters and, thus, can be represented by a single byte. The first half (128 characters) is exactly the same as ASCII. Thus, if the first bit = 0, then this is a regular ASCII character. If 1, then this is an ISO-8859-1 specific character.
UTF-8 is one of the most well-known encodings along with ASCII. Able to encode 1.112.064 characters. The size of each character varies from 1 to 4 bytes ( values up to 6 bytes were previously allowed).

The program working with this encoding determines by the first bits how many bytes are included in the character. If the octet starts with 0, then the character is represented by one byte. 110 is two bytes, 1110 is three bytes, 11110 is 4 bytes.
As with ISO-8859-1, the first 128 characters are fully ASCII. Therefore, texts that use only ASCII characters will be absolutely identical in binary representation, regardless of whether US-ASCII, ISO-8859-1, or UTF-8 was used for encoding.
Using UTF-8 in the message body
Before moving on to the headers, let's quickly take a look at how to use UTF-8 in the body of messages. For this, use the "Content-Type" header .

If the “Content-Type” is not specified, the browser should process the messages as if they were written in ISO-8859-1. The browser should nottry to guess the encoding and, especially, ignore the "Content-Type". But what is actually displayed in a situation where the "Content-Type" is not transmitted depends on the implementation of the browser. For example, Firefox will make according to the specification and read the message as if it were encoded in ISO-8859-1. Google Chrome, in contrast, will use the encoding of the operating system, which for many Russian users is equal to Windows-1251. In any case, if the message was in UTF-8, then it will be displayed incorrectly.

We put a UTF-8 message in the header value
With the body of the message is simple enough. The message body always follows the headers, so there are no technical problems. But what about the headlines? The specification states unequivocally that the order of the headers in the message does not matter. Those. set the encoding in one header through another header is not possible.
What happens if you just take and write the UTF-8 value to the header value? We have seen that such a trick with the message body will result in the value being simply read in ISO-8859-1. It would be logical to assume that the same thing will happen with the title. But it is not. In fact, in many, if not most cases, this solution will work. This includes the old iPhones, IE11, Firefox, Google Chrome. The only browser I have at hand when I wrote this article that did not want to work with such a headline is Edge.

This behavior is not fixed in the specifications. It is possible that browser developers decided to make life easier for developers and automatically determine that the message is encoded in UTF-8 in the headers. In general, this is not such a difficult task. We look at the first bit: if 0, then ASCII, if 1 - then, perhaps, UTF-8.
Is there no intersection with ISO-8859-1 in this case? In fact, almost none. Take for example the UTF-8 character of 2 octets (Russian letters are represented by two octets). The symbol in binary will be: 110xxxxx 10xxxxxx . In the HEX view: [0xC0-0x6F] [0x80-0xBF] . In ISO-8859-1, these characters can hardly encode something that carries meaning. Therefore, the risk that the browser incorrectly decrypts the message is very small.
However, when trying to use this method, you may encounter technical problems: your web server or framework may simply not allow writing UTF-8 characters to the header value. For example, Apache Tomcat replaces all UTF-8 characters with 0x3F (question mark). Of course, this restriction can be circumvented, but if the application itself beats hands and does not allow to do something, then perhaps you don’t need to do it.
But, regardless of whether your framework allows you or the server to write UTF-8 messages to the header or not, I do not recommend this. This is not a documented solution that can stop working in browsers at any time.
Translit
I think that to use translit - eto bolee horoshee reshenie. Many large popular Russian resources do not disdain to use translit in file names. This is a guaranteed solution that will not break with the release of new browsers and which should not be tested separately on each platform. Although, of course, you need to think about how to transform the whole range of possible characters, which may not be entirely trivial. For example, if an application is designed for a Russian audience, then the Tatar letters ә and ң may fall into the file name, which must be somehow processed, and not simply replaced with "?".
RFC 2047
As I have already mentioned, Tomkat did not allow me to put UTF-8 in the message header. Is this behavior feature reflected in the Java docs for servlets? Yes, echo:
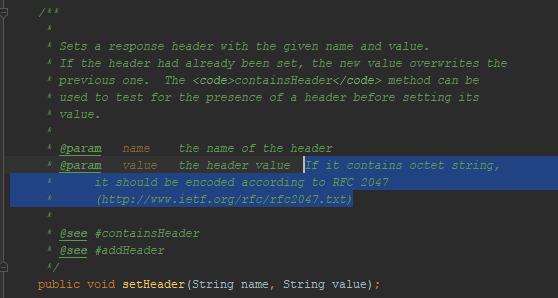
Refers to RFC 2047 . I tried to encode messages using this format - the browser did not understand me. This encoding method does not work in HTTP. Although worked before. Here, for example, a ticket to remove support for this encoding from Firefox.
RFC 6266
The ticket, referenced in the previous section, mentions that even after RFC 2047 support is discontinued, there is still a way to transmit UTF-8 values in the title of the downloaded files: RFC 6266 . In my opinion, this is the most correct decision for today. Many popular online resources use it. We in the CUBA Platform also use this particular RFC to generate the “Content-Disposition”.
RFC 6266 is a specification that describes the use of the “Content-Disposition” header. The encoding method itself is described in detail in another specification, RFC 8187 .

The “filename” parameter contains the name of the file in ASCII, “filename *” in any necessary encoding. With both attributes, “filename” is ignored in all modern browsers (including IE11 and older versions of Safari). Older browsers, by contrast, ignore “filename *”.
When using this encoding method, in the parameter, the encoding is first specified, followed by the encoded value. Visible characters from ASCII coding do not require. The remaining characters are simply written in a hex representation, with a "%" in front of each octet.
What to do with other headers?
The coding described in RFC 8187 is not universal. Yes, you can put a parameter with a * prefix in the header, and this may even work for some browsers, but the specification instructs not to do so.
In each case, where UTF-8 is supported in the headers, there is currently an explicit mention of this in the relevant RFC. In addition to “Content-Disposition,” this encoding is used, for example, in Web Linking and Digest Access Authentication .
It should be noted that the standards in this area are constantly changing. The use of the above encoding in HTTP was proposed only in 2010 . The use of this encoding in “Content-Disposition” wasfixed in standard in 2011 . Despite the fact that these standards are only at the “Proposed Standard” stage , they are supported everywhere. The option that in the future we are expected by new standards that will allow us to work more uniformly with different encodings in the headers is not excluded. Therefore, it remains only to follow the news in the world of HTTP standards and the level of their support on the side of browsers.