Search Evolution - how to buy a piano in three clicks
Previously, Avito could find the right product using keyword filtering or navigating through the category tree. This method, although it seemed familiar, was not always convenient - to find a product or service, you had to make a large number of clicks. More than a year ago, we had a relevance, thanks to which the search became better, and now it is easier and more convenient to find a product or service even on the main page. With this innovation, unsuitable, openly "junk" goods no longer fall into the issue. And this is just one of the steps to make the search better. We are gradually changing the infrastructure, which allows us to work on the quality of the search more intensively, quickly improve it and roll out new features that benefit sellers and buyers on Avito.
In the article I will tell you how the search on Avito changed: how we started and how we are now moving towards improving the lives of our users, sharing our innovations both in the product and in its stuffing - the technical part. Most hardcore meat will not be here, but I hope you enjoy it.

Some introductory: Avito is the most popular ad service in Russia. We have more than 450 thousand ads posted every day, and the monthly number of unique visitors reaches 35 million, which make more than 140 million search queries every day.
Typical search script before
Consider a simple example of how the search worked over a year ago. Suppose you need a piano (well, why not?). We go to the main page, we type "piano".
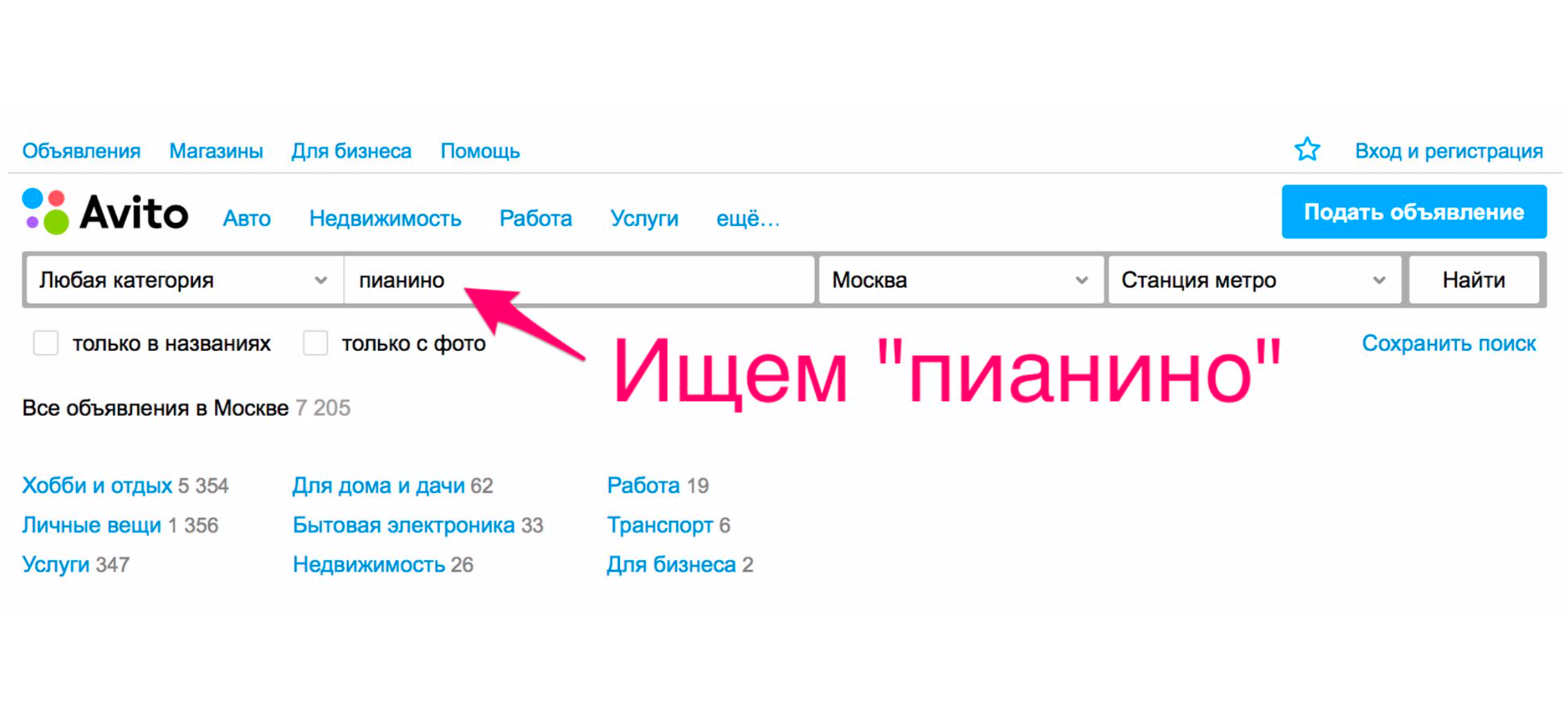
In issuing, you will most likely get movers, piano transportation services or something similar, but not a musical instrument.

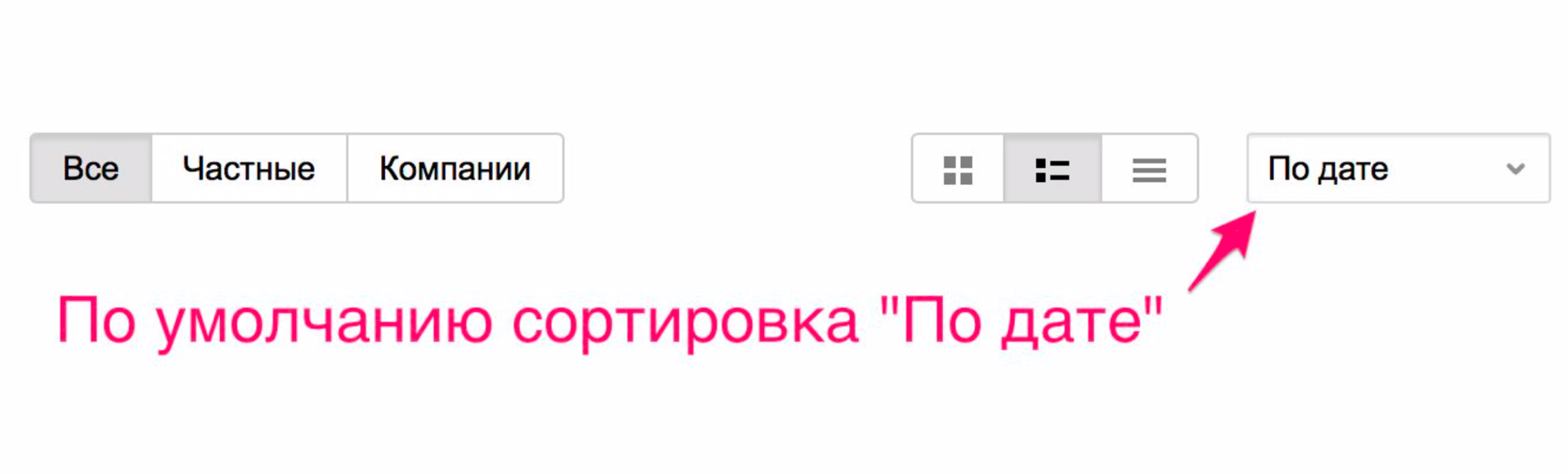
This happens because we will have sorting by date of placement - and these services are placed most often.
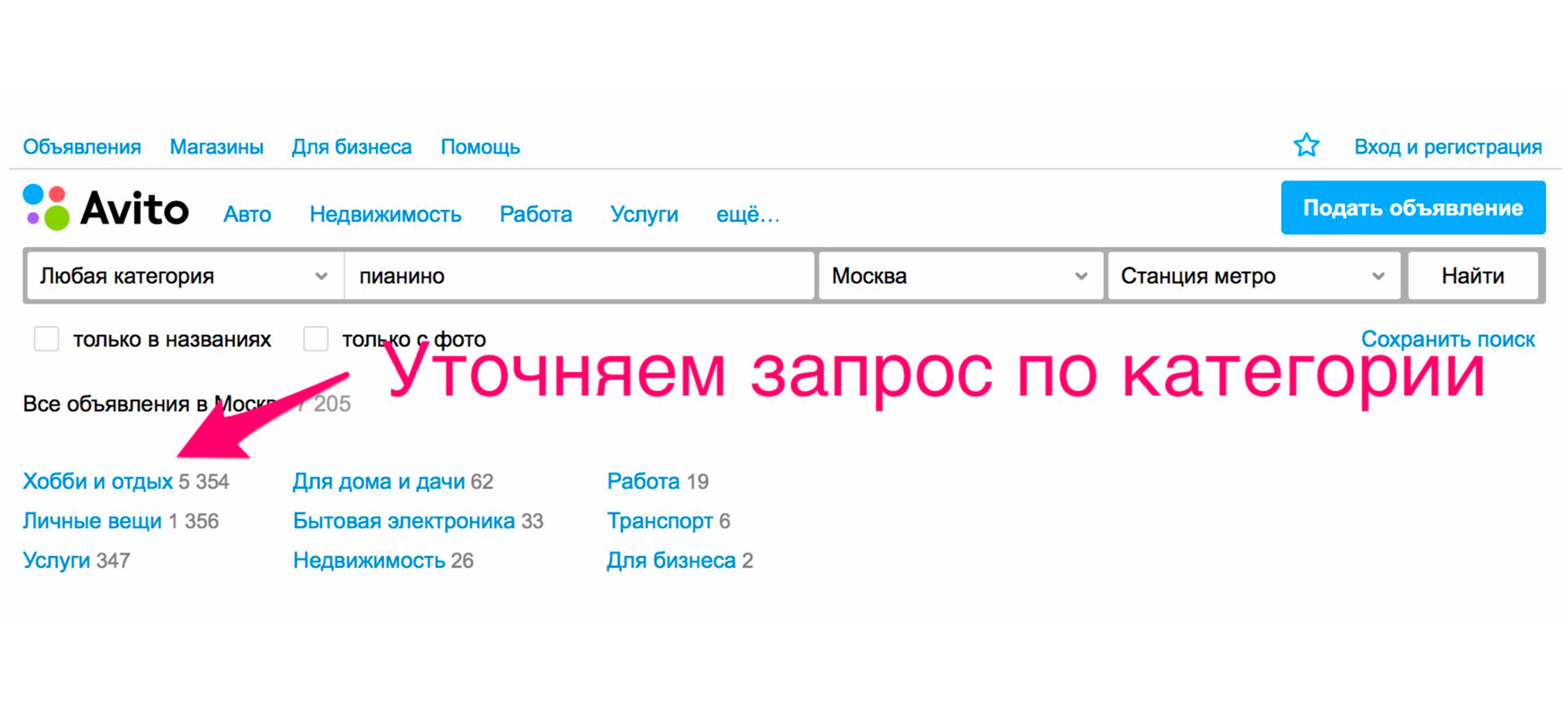
To see the piano, you need to clarify the category. Click on the "Hobbies and Recreation" rubricator, go down the category tree to "Musical Instruments", then "Keyboard Instruments".
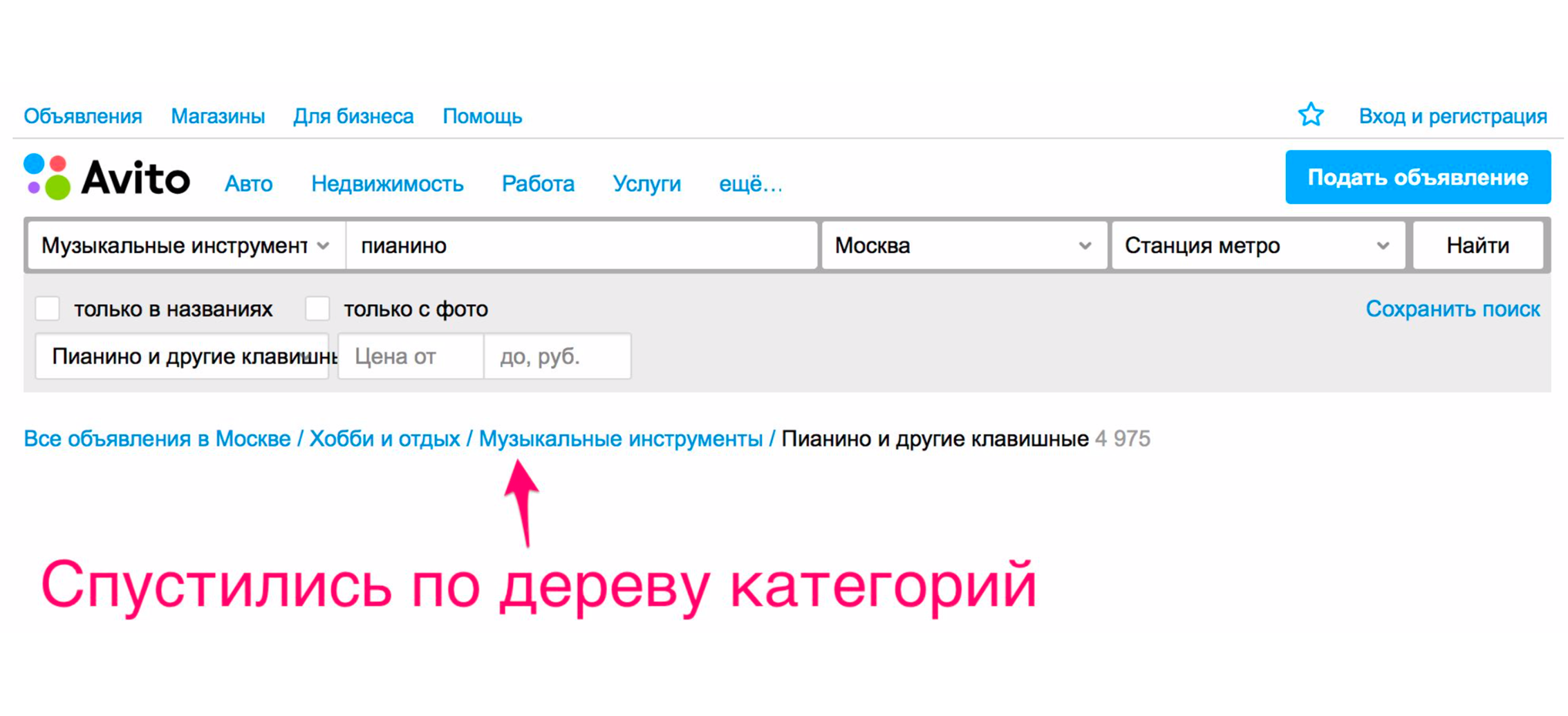
And only after that we see the piano we were looking for.
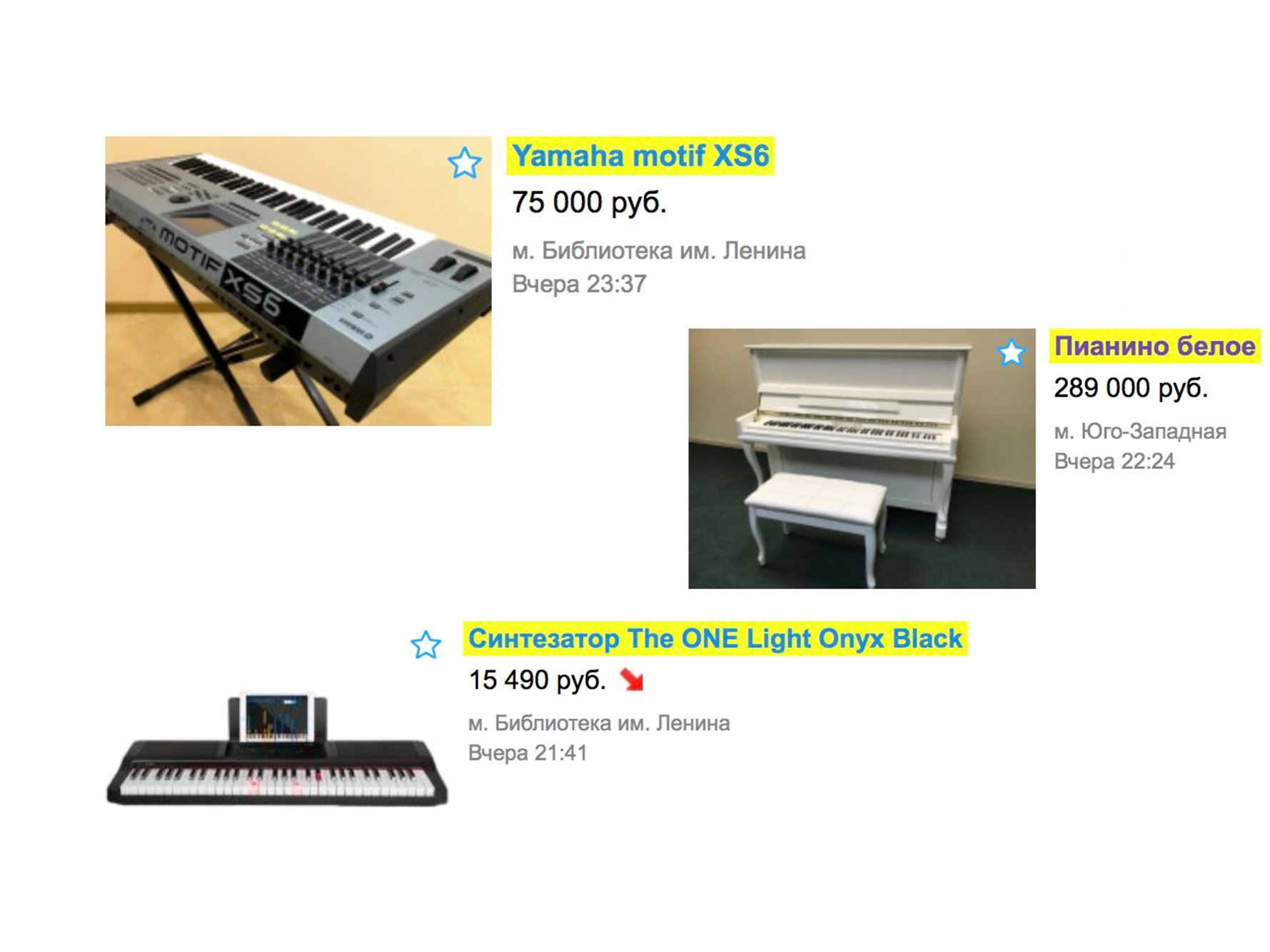
It turns out, to find the right ad, there were the following features:
- category refinement when searching by keywords,
- sorting by freshness and price,
- filters,
- search by name only.
What has changed due to relevance
Due to the relevance of the issuance of ads no longer fall, which do not fit. Now, if you are looking for a piano from the main page, you probably will not see the services of porters who help him transport it, but you will immediately see the musical instrument you want. At the same time a new sorting was added - “Default”. It is formed by two indicators: the relevance of the ad text query and freshness.

In the top you see the most recent of the relevant.
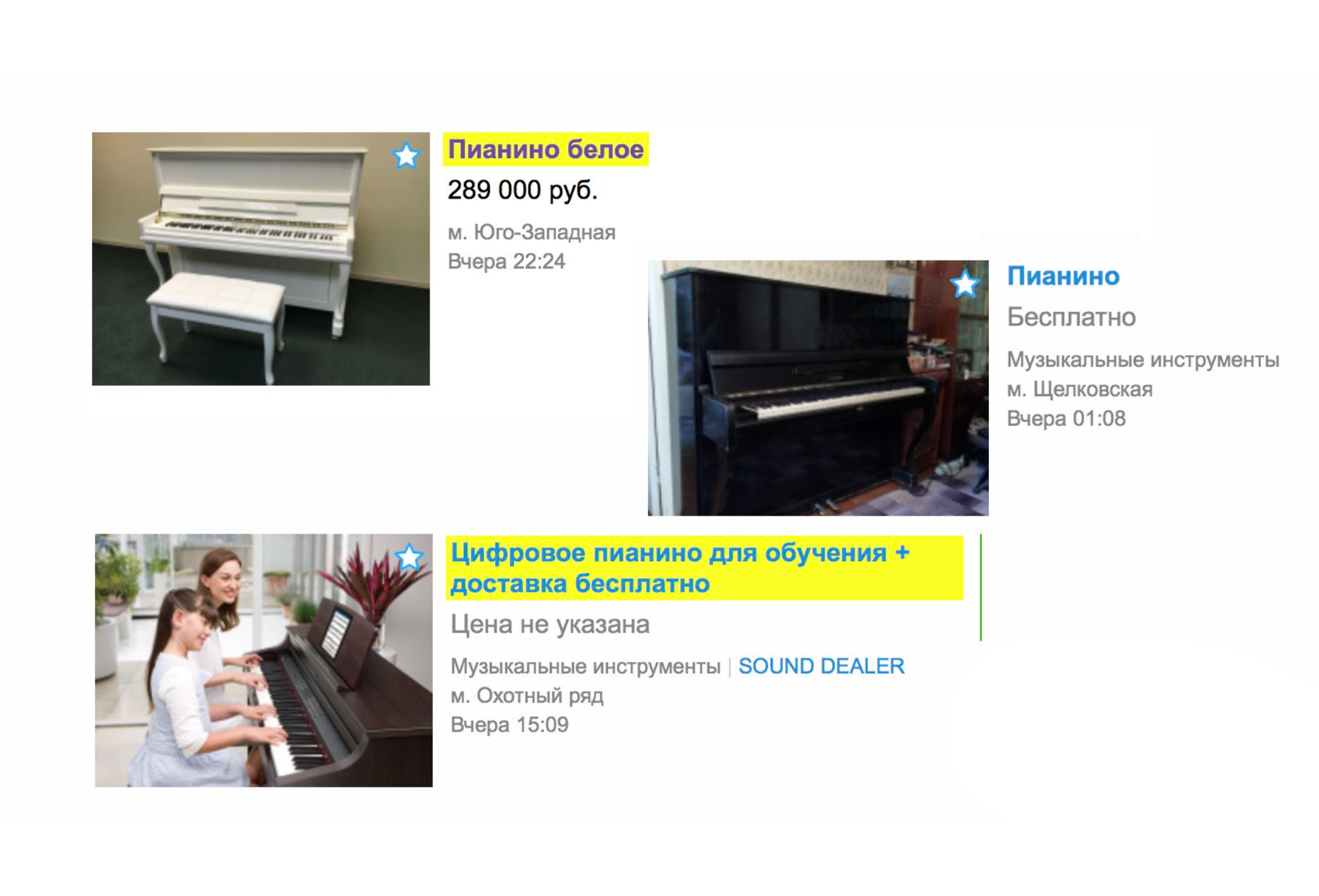
At Avito for an additional fee, you can raise your ad. And with the introduction of relevance, paid raises work more efficiently. They will work, first of all, if your ad is relevant to a text query.
The introduction of relevance does not mean that we have completely abandoned the transition to the category tree. Just for most cases, we have reduced the number of clicks to the desired ad when searching from the main page. If you still need transportation services, although you just typed a “piano” in the search, go to the category tree and you will find these ads. The search also began to work more efficiently and within the category, for example, “Personal things” and “Household appliances”.
How to find the right product in three clicks
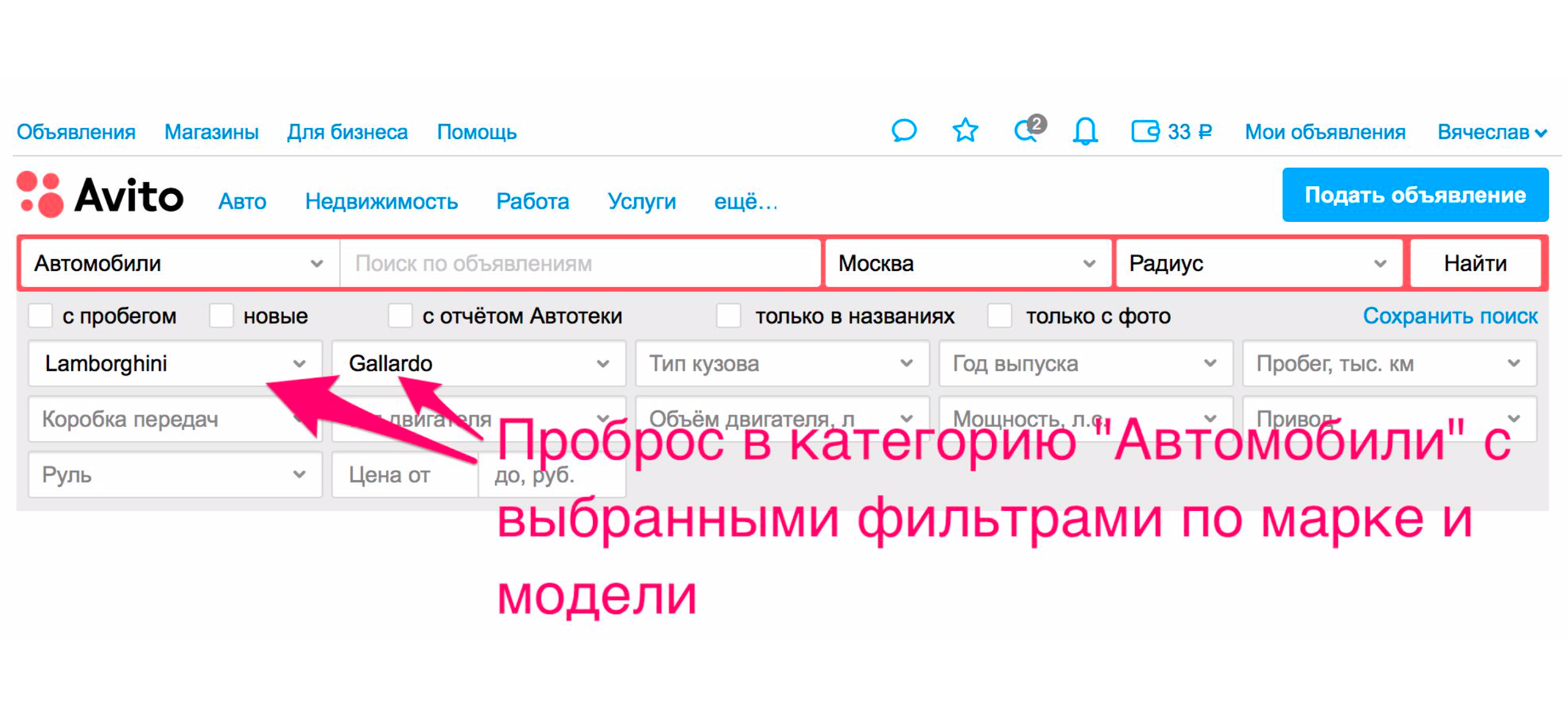
Search becomes more convenient for users not only due to the quality of the issue. There are other ways to improve it. One of them - probros in the category. For example, we are looking for Lamborghini Gaardo (yes, you like to play the piano and want to ride the Lamborghini). To get to the car category of a particular model, you need to make two extra clicks. With relevance, you will most likely get what you want.
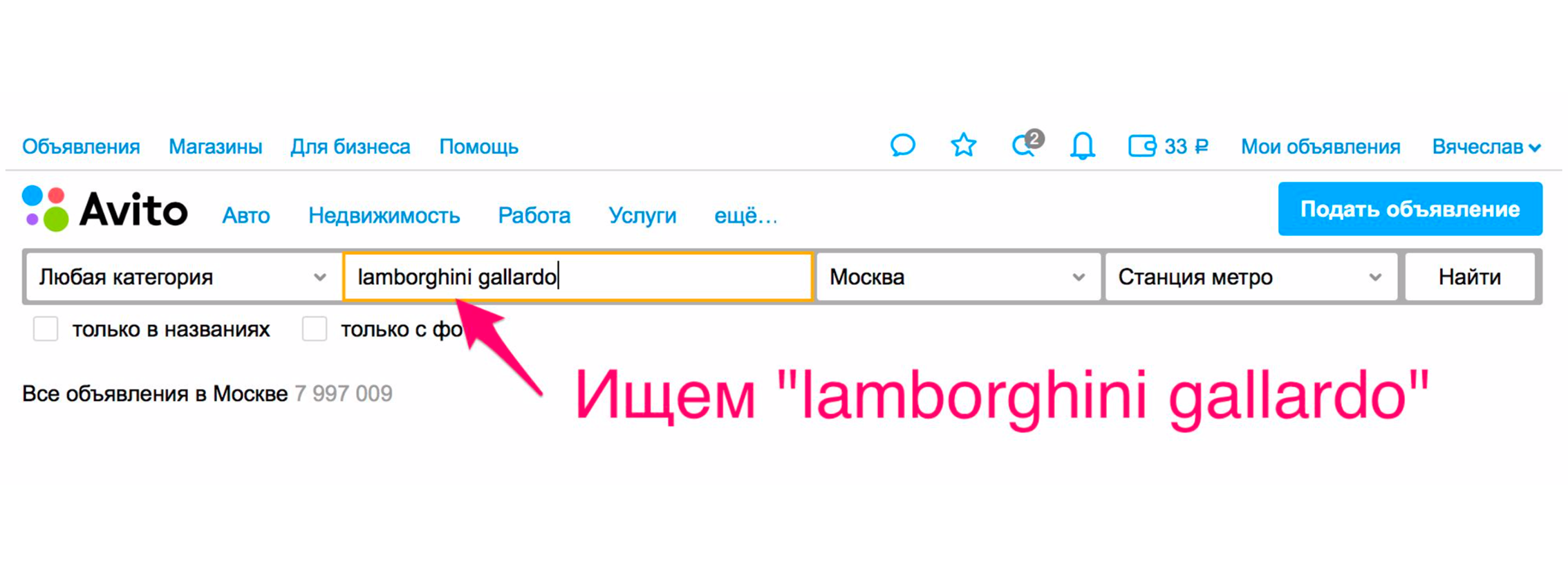
But there is an additional way that you immediately send in cars. The issue will be narrowed, the desired car will be selected in the filters, and you will get cars in the issue.

Another way is expanding tags. For example, when you enter the word "jacket", you have hints.
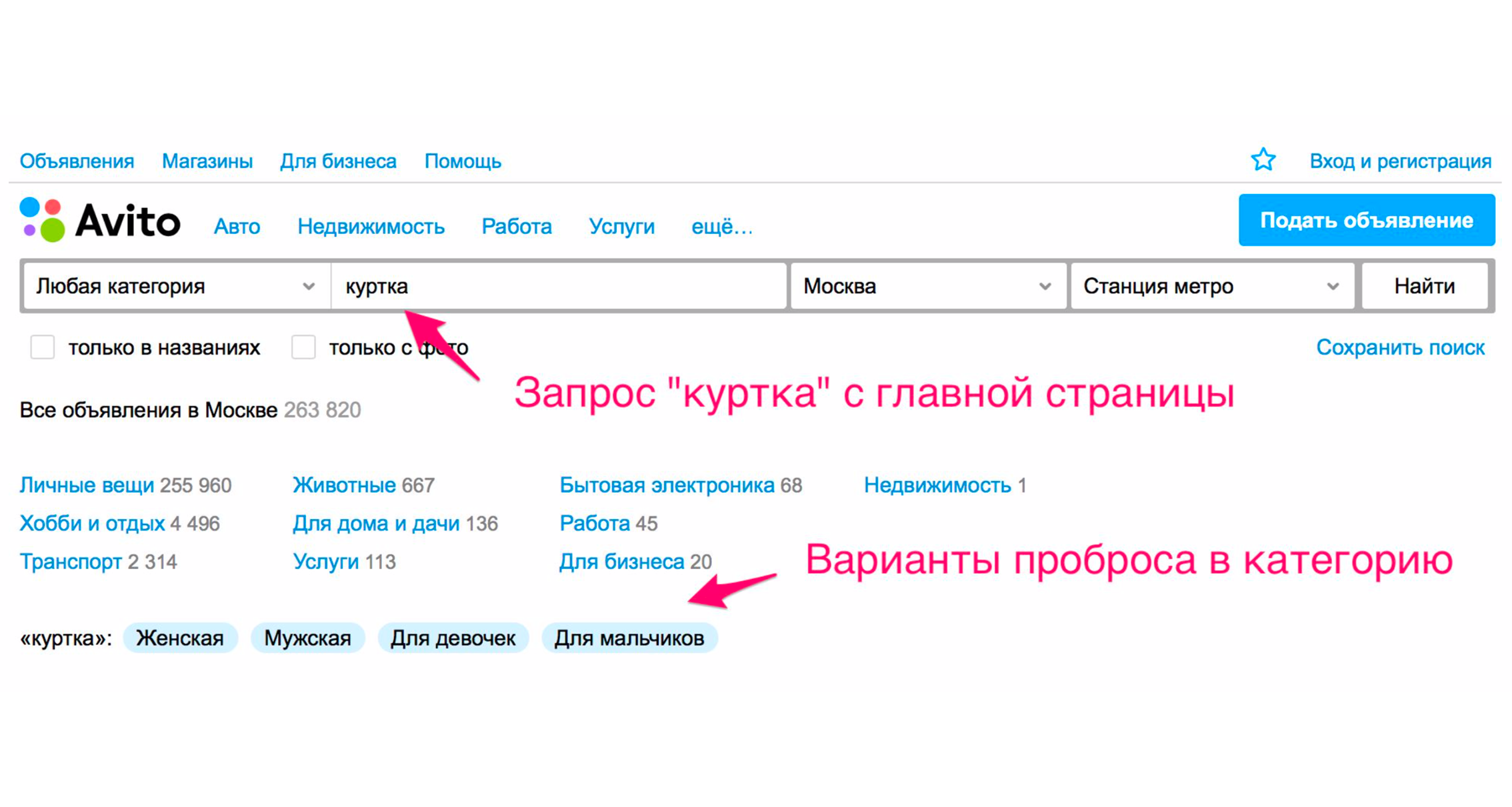
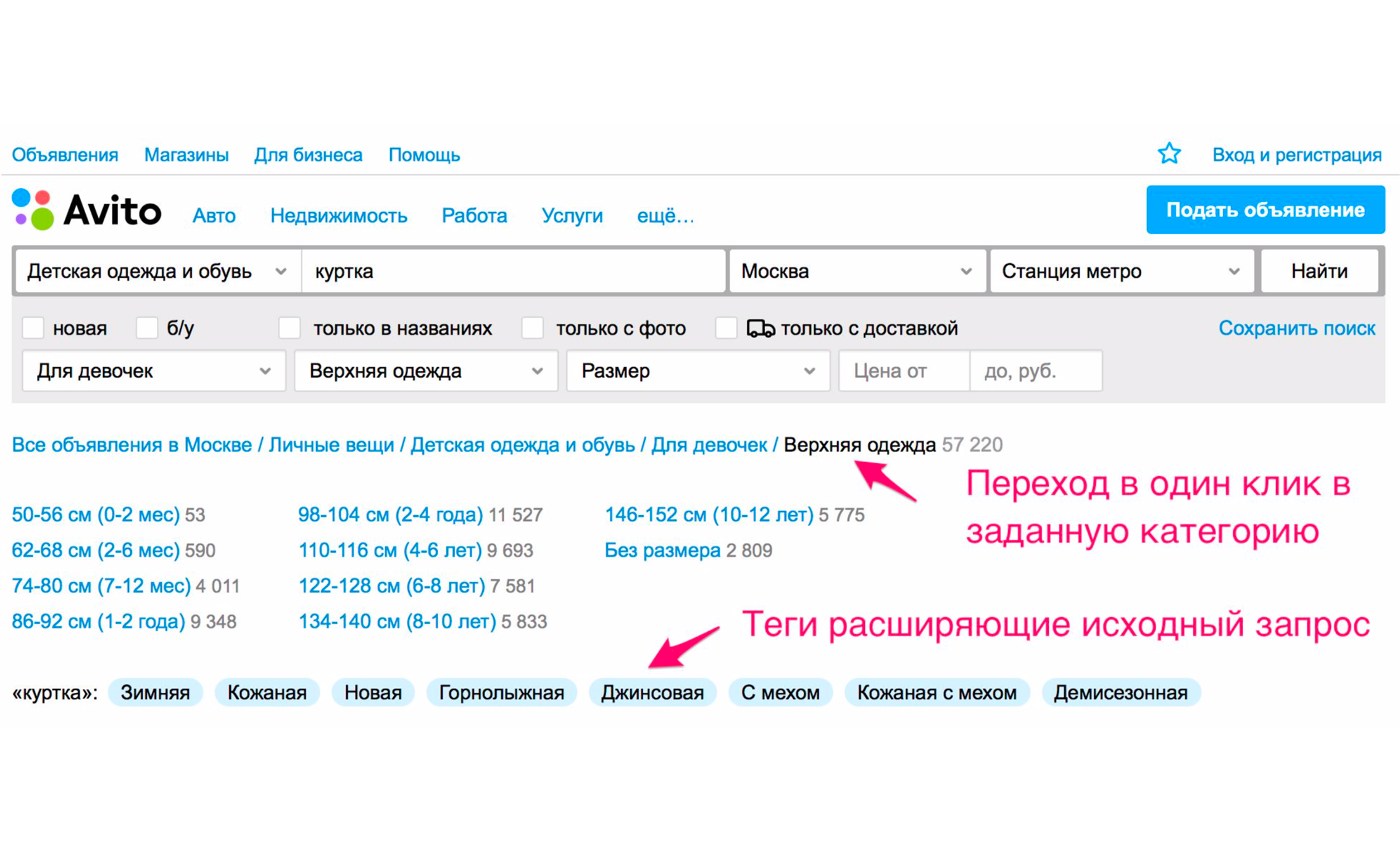
The screenshot above shows the tips: the type of jackets - women's, men's, for girls, for boys. If you click "For girls", you will immediately fall into the category where the appropriate filters will be selected. Also there will be a set of additional expanding tags: winter jacket, leather, new and so on. If you go down the category tree manually to the right product, then you need to perform more actions.
What is the difference between search and filters?
When I gave a talk at RIT ++ , the listeners had a question: what is the difference between text search and filters? Everything is quite simple. You can find the right ad without a text request by going down the category tree. In this case, the search will still find products and services, but not by the specified text, but by a set of parameters transmitted from the corresponding filters of the selected category.
Each category has its own set of filters. For example, in the “Cars” category there are some filters, in the “Personal belongings” category - other filters. That is, the filters are rigidly tied to the category.
Placing ads in two minutes
For sellers there was an important innovation that they feel when submitting their ads. If your ad does not contain any "banned" or is not a duplicate - the usual good ad - you will see it in the issue almost immediately. In reality, this delay lasts about two minutes, but in rare cases it can be extended up to 30 minutes. Previously, the announcement always appeared on the site only half an hour later.
Avito Assistant
Avito Helper is an extension for Chrome that displays the price of a similar product on Avito on third-party sites. In the extension, you can compare prices in many online stores with prices for Avito or simply search for the necessary goods and services in our service, without going directly to the website or in the application. We were able to implement the “Assistant”, including through new infrastructure changes.

Architecture
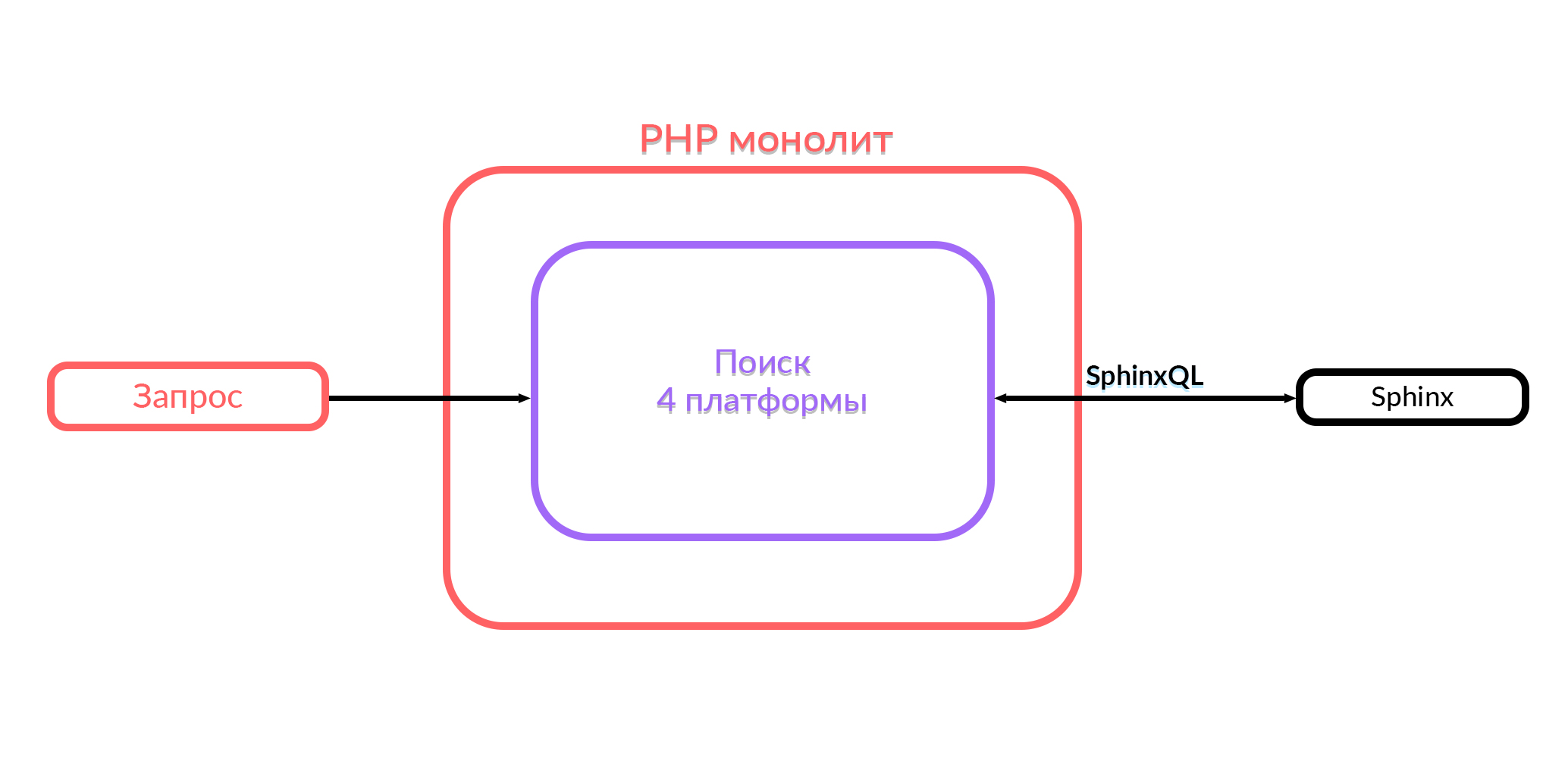
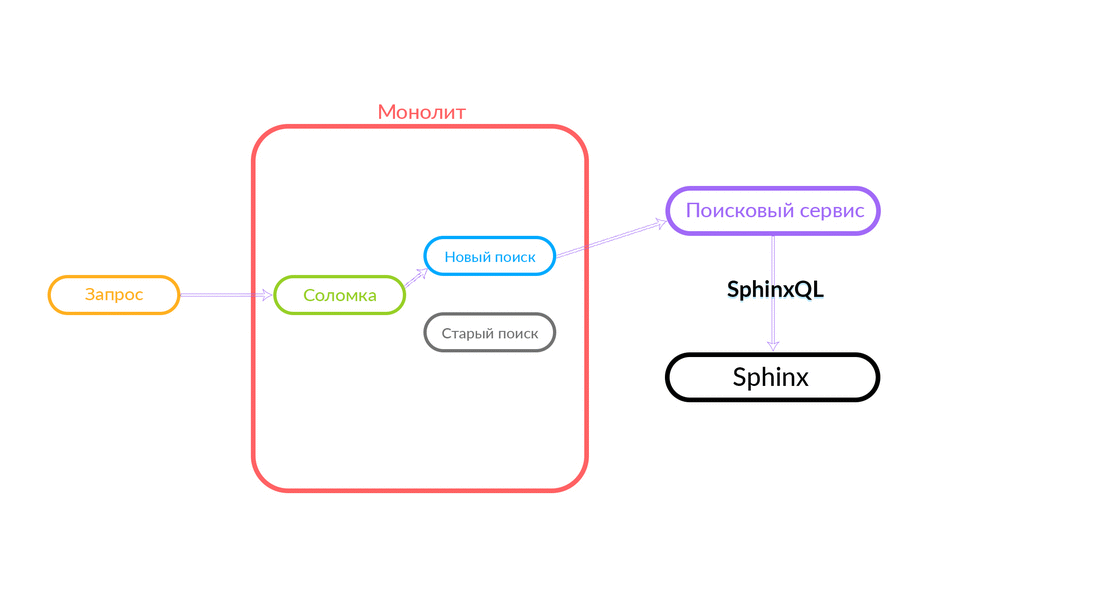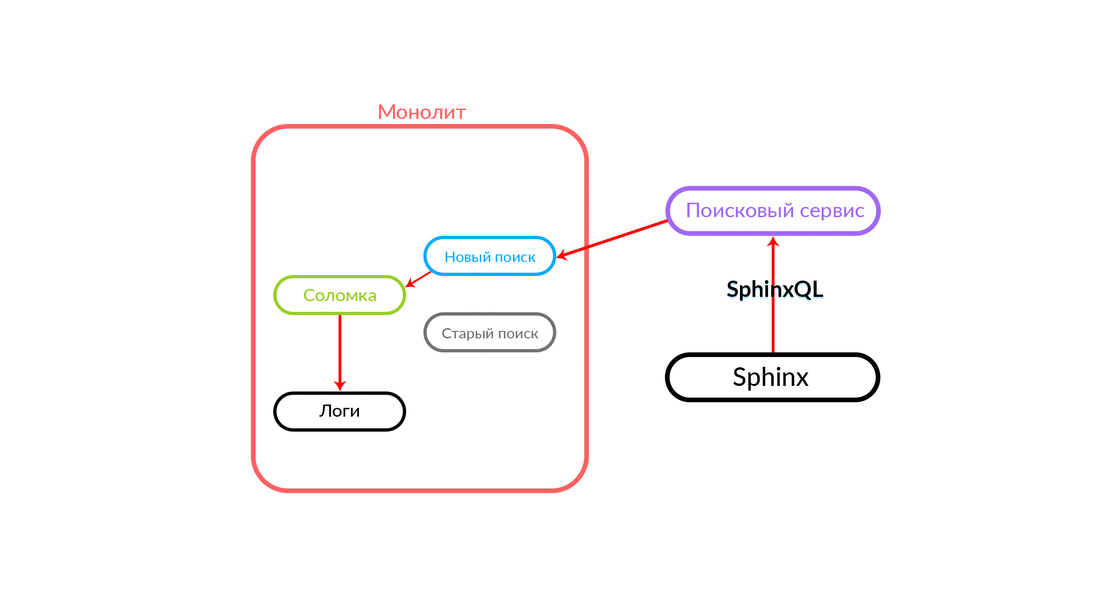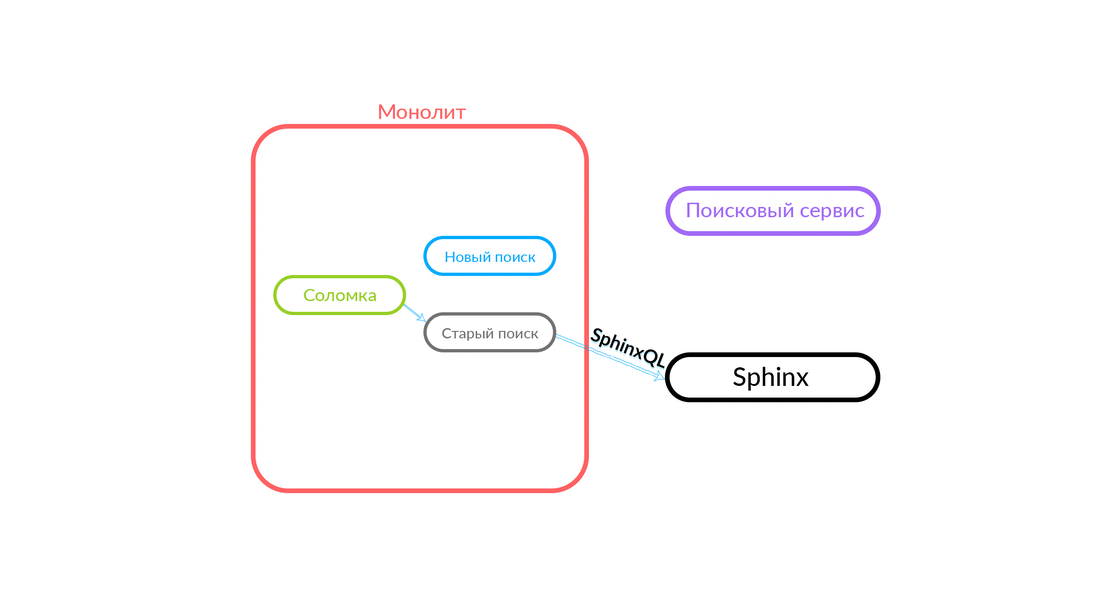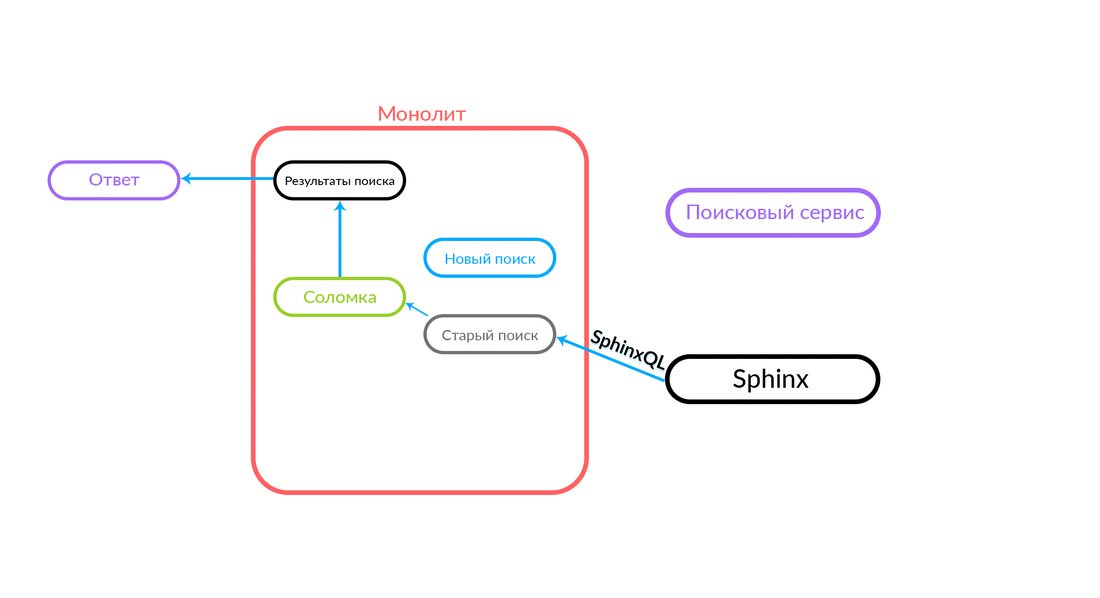
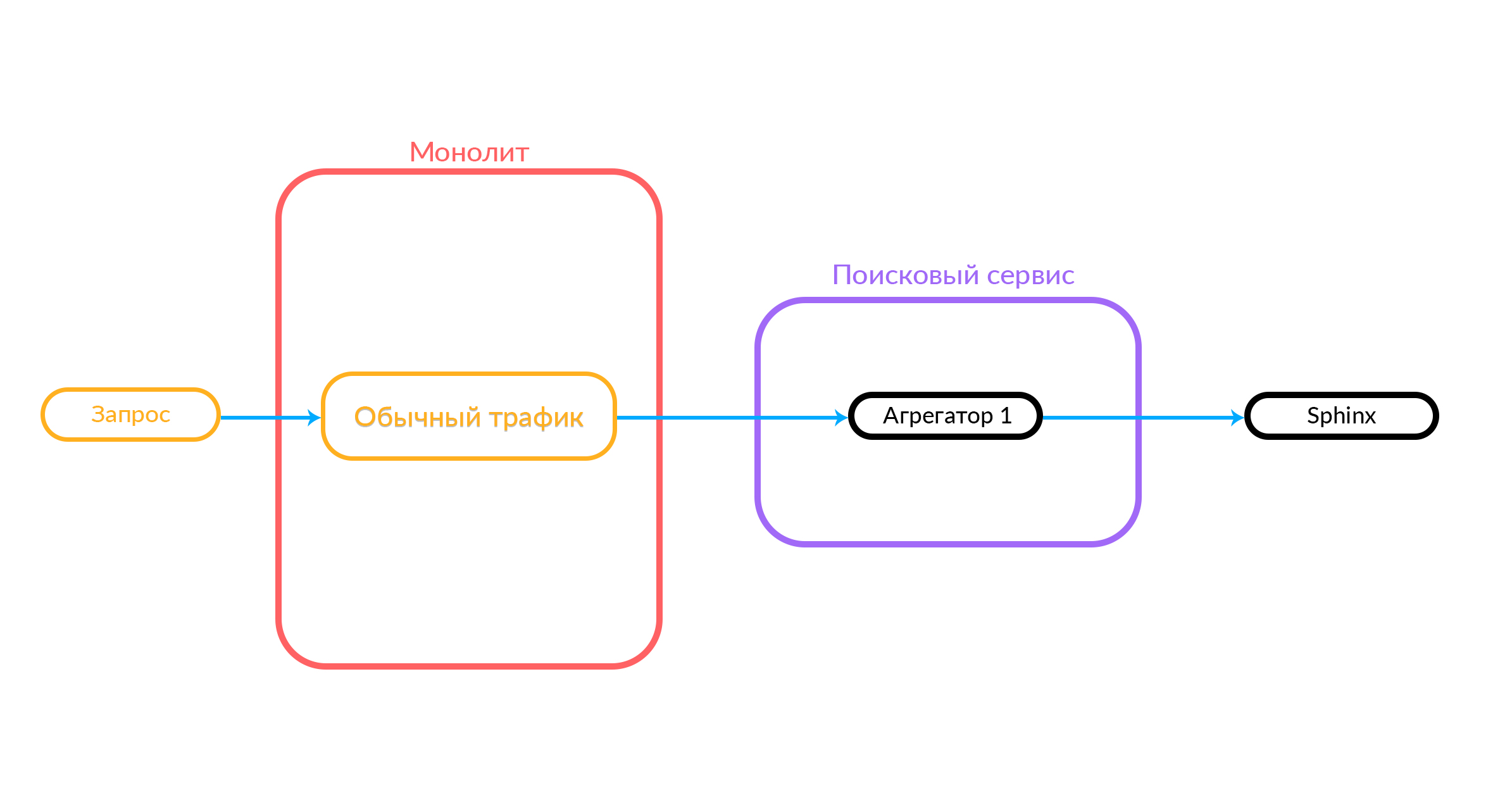
We saw monolith
In Avito there is a monolith for PHP. A year ago, the entire search functionality that works in Avito was in this monolith. The monolith search worked with four platforms: Android, iOS, mobile version in the browser and desktop. In order to give the output, inside this code the corresponding SQL queries were formed in Sphinx, processing was performed, and the output was sent in JSON or HTML format. Then users saw what they were looking for.
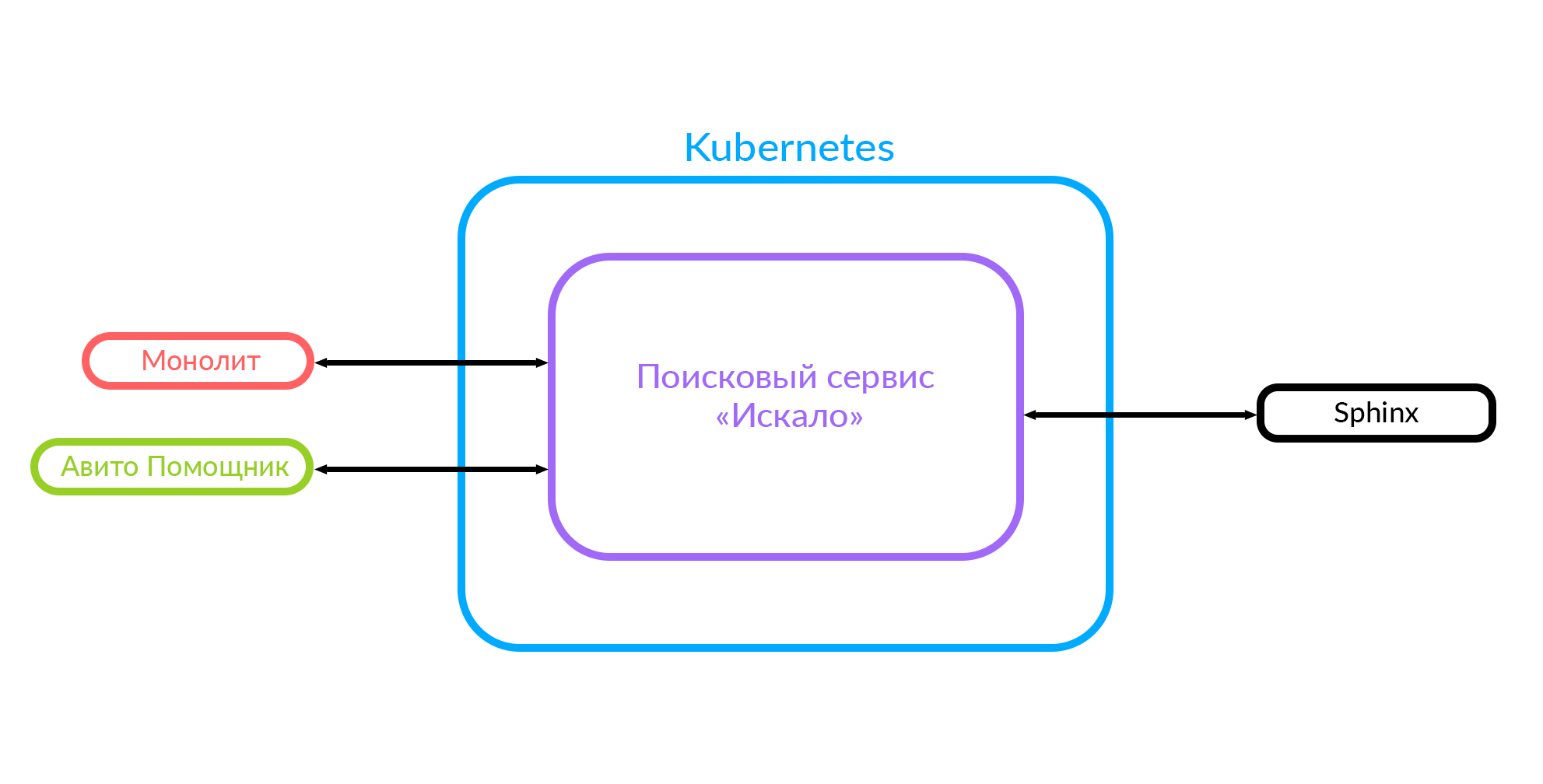
What we have now
If you implement new features, it is very difficult to integrate with this monolith. Therefore, we decided to develop a search service, which they called Iskalo among themselves. Now the monolith goes to this search service, and the service goes to Sphinx.

The reasons for creating a search service
When developing services you should always understand why you are doing this. The first obvious advantage is the removal of low-level logic. In our case, this is hiding the kitchen for processing SphinxQL queries. In addition, we can more easily provide search functionality to third-party systems.
Asynchronous query execution. This advantage is quite obvious and depending on the implementation one can achieve some success. Our service is implemented on Golang, and there was a functional that could be parallelized - three queries in Sphinx, which resulted in good results.
Quick Deploy We have identified a separate functionality with a smaller amount of code, unnecessary tests (there are many tests in the monolith, not only for the search functionality), and it is easier to roll out. The most important thing is that due to the successful approach to the implementation of this service, we were able to file down interesting pieces and implement advanced ranking algorithms - to do quite complex processing that we could not do in the monolith. This provides us with a very good foundation for conducting experiments with search quality.
As a bonus, we have the opportunity to switch from Sphinx to Elastic, because the low-level logic is now hidden.
This diagram already shows the case when there is a monolith, the Iskalo service and the third-party Avito Assistant service.
How does the search service
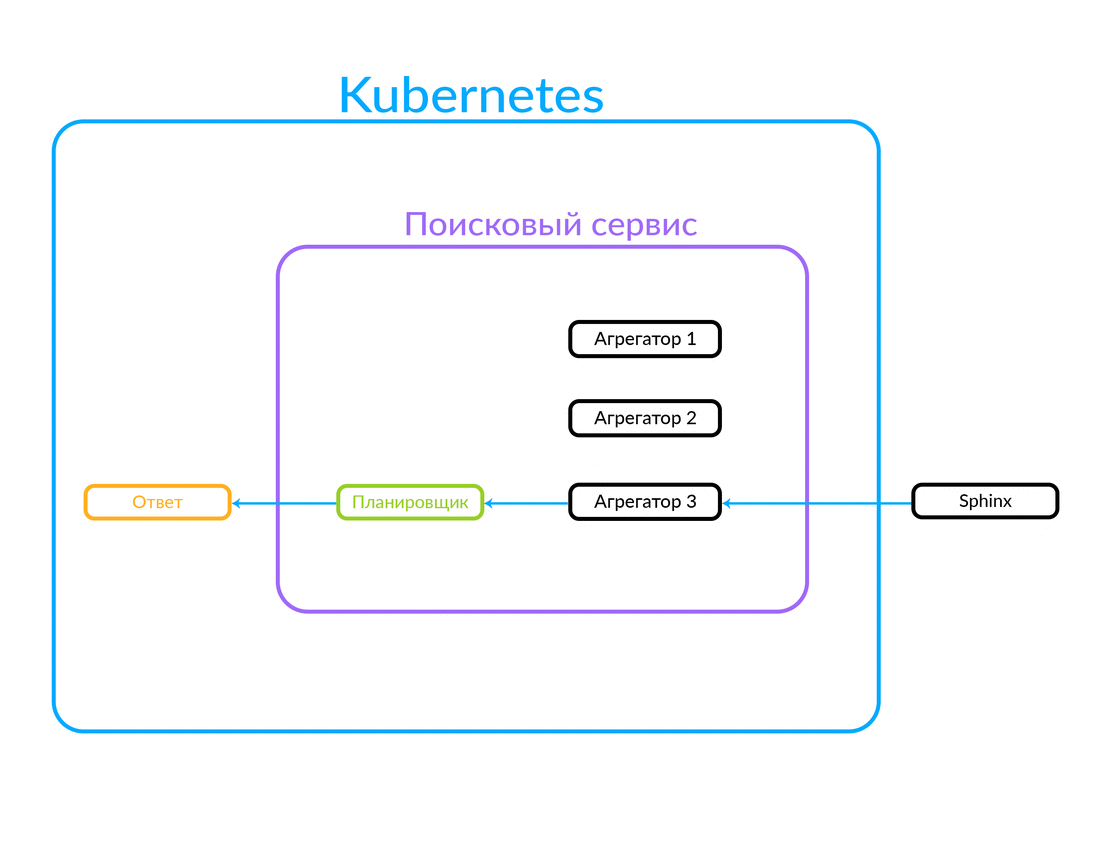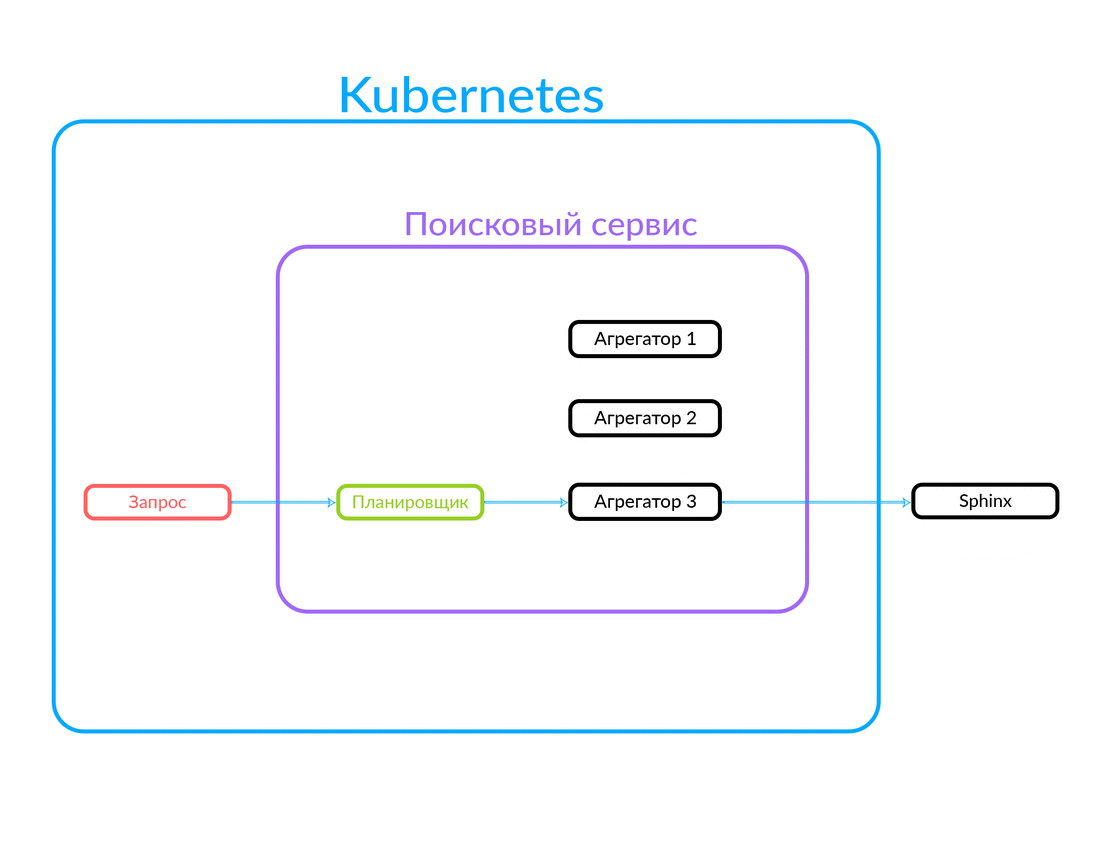
It has a set of aggregators. Each aggregator performs some business logic related to the processing of the issue. It can form this issue in a certain way.
The request goes to the scheduler. According to the query criteria, the scheduler selects the aggregator from the point of view of its parameters (or if the required aggregator is specified in the query itself). The aggregator goes to Sphinx. After receiving a response from Sphinx, he generates the issue and gives the answer to the client.

In this case, the request was outside, not from the cloud in which our search service operates. But another option is also possible: some other service of ours, inside the cloud, for example, Avito Helper, contacts the search service. This request goes to another aggregator - there is another business logic. Here's how it works:
How does asynchronous execution of requests on the aggregator
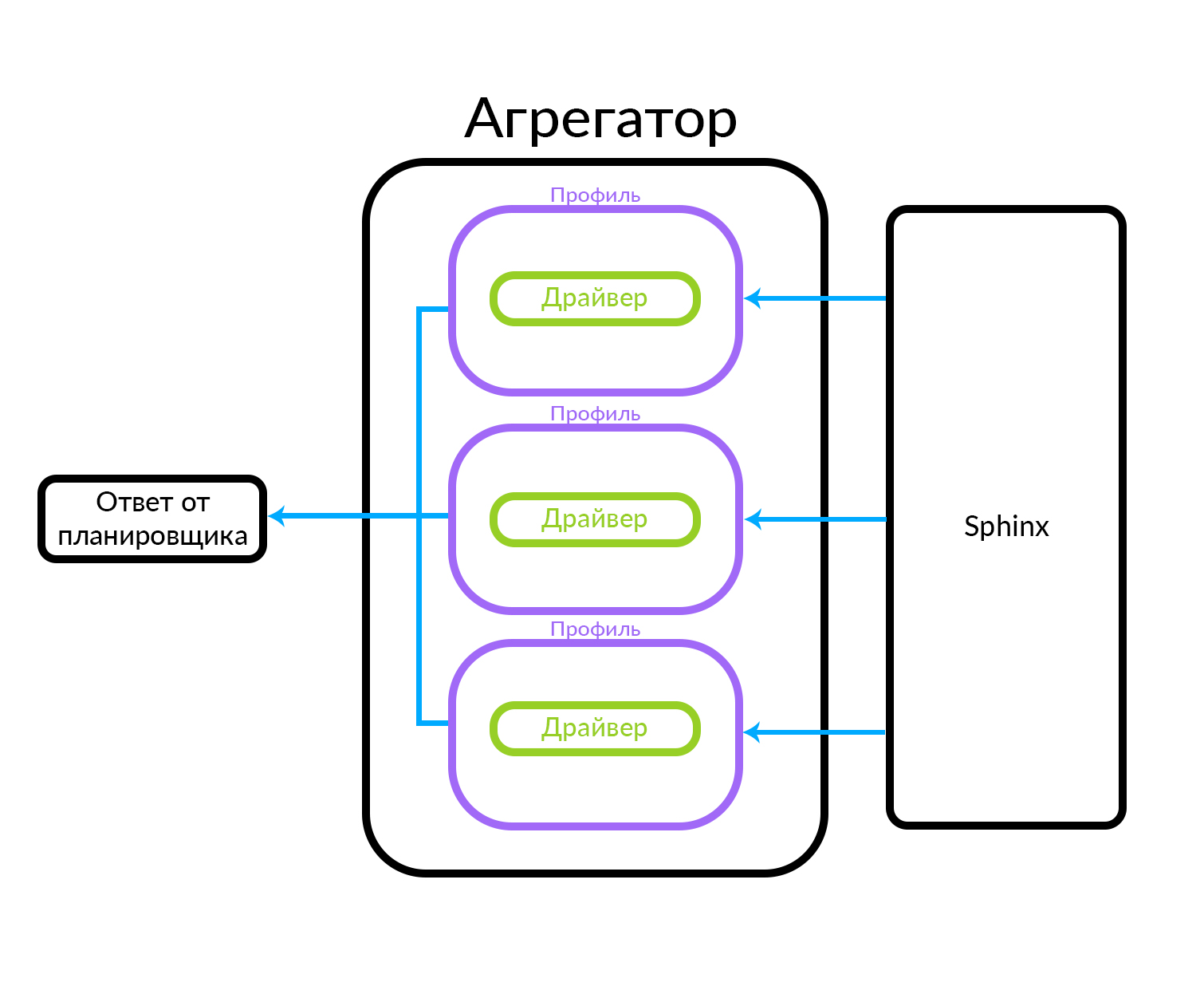
The aggregator consists of several profiles. A profile is, roughly speaking, an entity in which you can receive an ad of some type or in some particular way. For example, this can be explained through an analogy: Avito has Premium, VIP and regular announcements. The aggregator receives a request from the scheduler, while parallel queries are executed for the set of profiles known in the aggregator. The profile has a driver inside it that physically turns to the underlying level, in this case in Sphinx, but it can be any other data source.
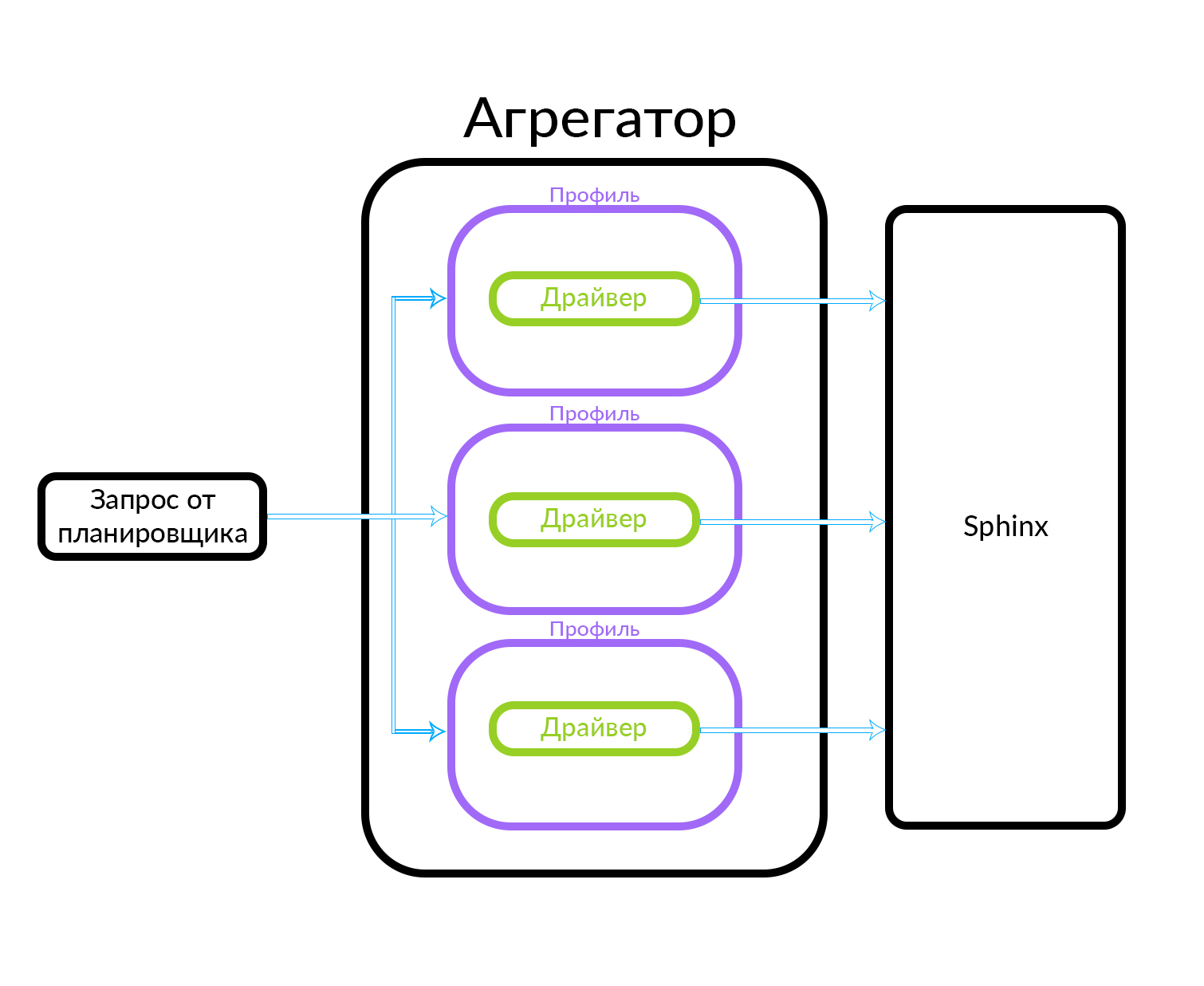
The aggregator can simply give the scheduler the results of requests for profiles, and it can also perform more complex actions, for example, to mix these results using one or another algorithm.
Search index storage
Due to the fact that we use Kubernetes in the architecture, at RIT ++ I was asked a question about storing the search index - is it stored in Kubernetes? No, we have Sphinx lives on physical machines. In Kubernetes, we have a search service that processes search logic. In the cloud also lies the search index sample for the development environment on which tests are run, but it’s undesirable to put a combat index there, because the services that work in Kubernetes are, first of all, stateless-services.
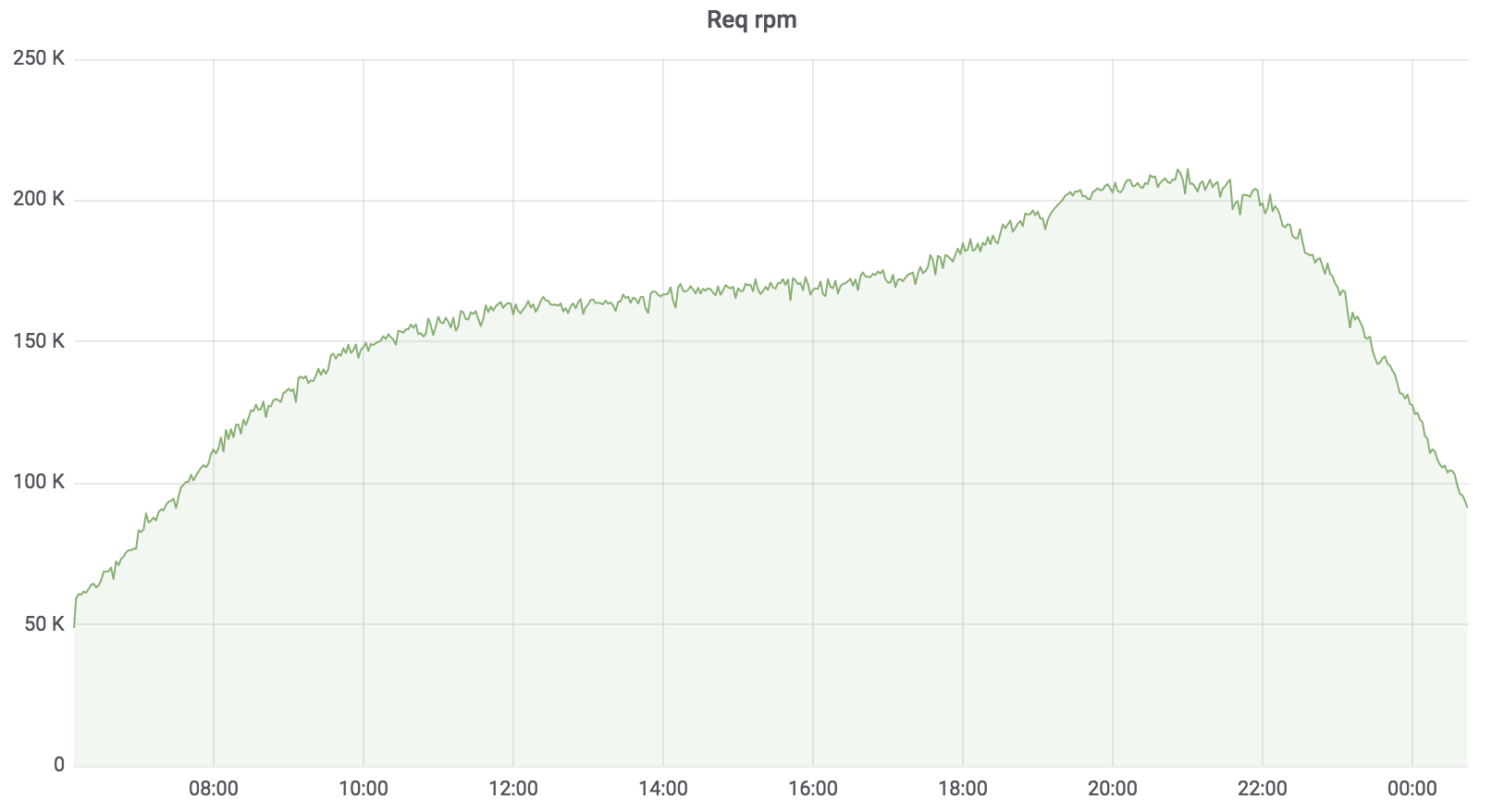
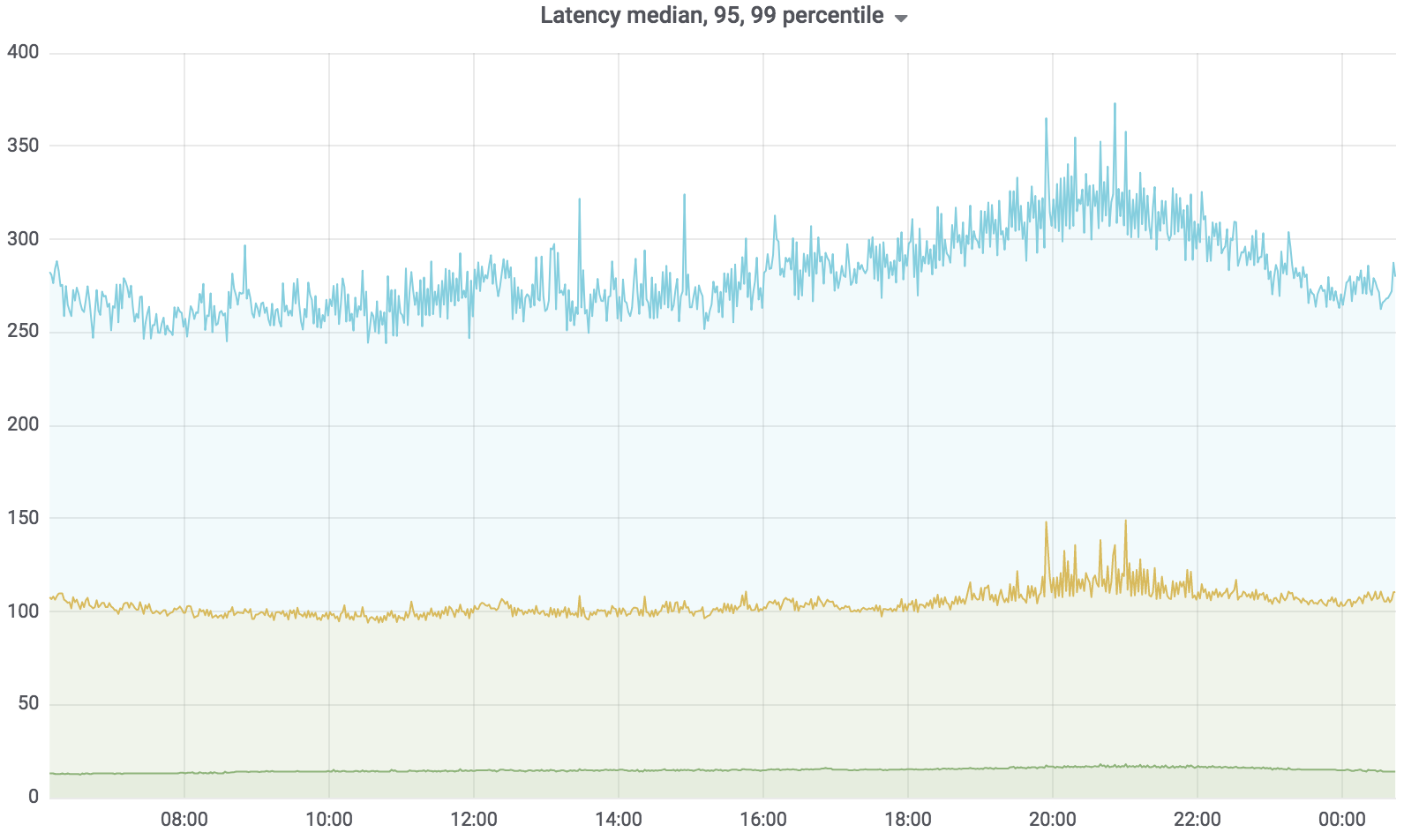
Load Search Service
Now this service is in combat, it serves 100% of the load with a few exceptions. The load he holds is about 200 krpm. Delay: Median - up to 17 ms, 95 percentile - up to 120 ms, 99 percentile - up to 320 ms.
Search service total
The search service is written in Golang, deployed in Kubernetes, the aggregator works asynchronously with several profiles. The profile works with the specified driver, the driver accesses the specified data source, for example, Sphinx. The number of requests that our service serves is up to 200 krpm at the moment. Delay: Median - up to 17 ms, 95 percentile - up to 120 ms, 99 percentile - up to 320 ms.
Introduction of service in the working system
The problem of double functionality is fairly obvious, we have to maintain two code bases that must perform the same task. We need a fallback. We called it “Straws” - we remembered about “spreading straw”. In addition, we need traffic management, it is desirable that it be fast, through dashboards.
How does the "Straw"
The search query comes to Straws, which runs inside the monolith and can make a further call to either the new search or the old one. She makes a call to a new search, that works it out, and if successful, we just get the output from the new search.
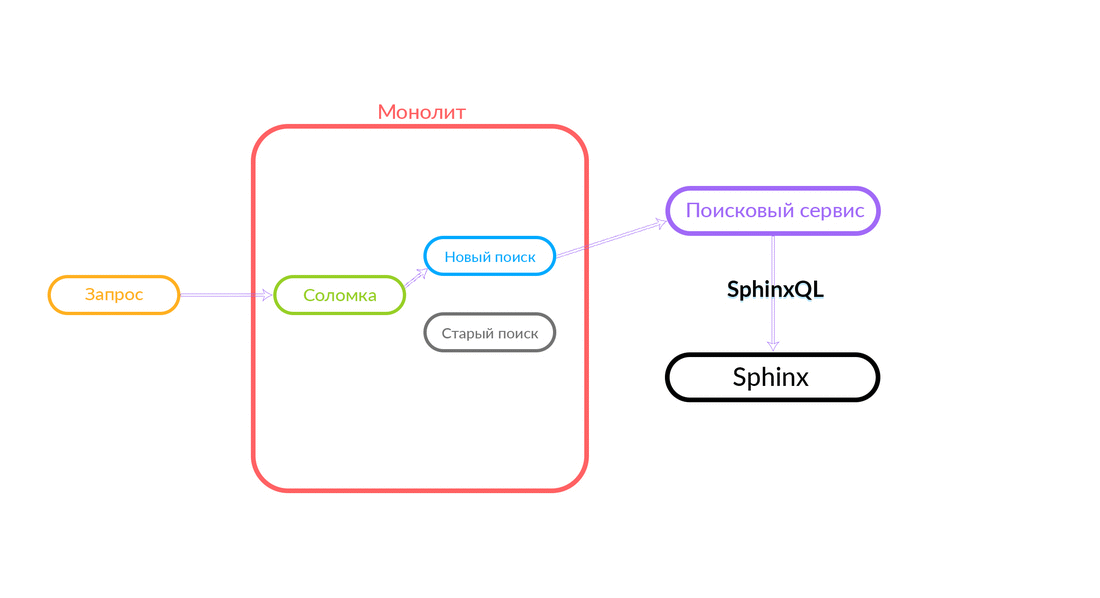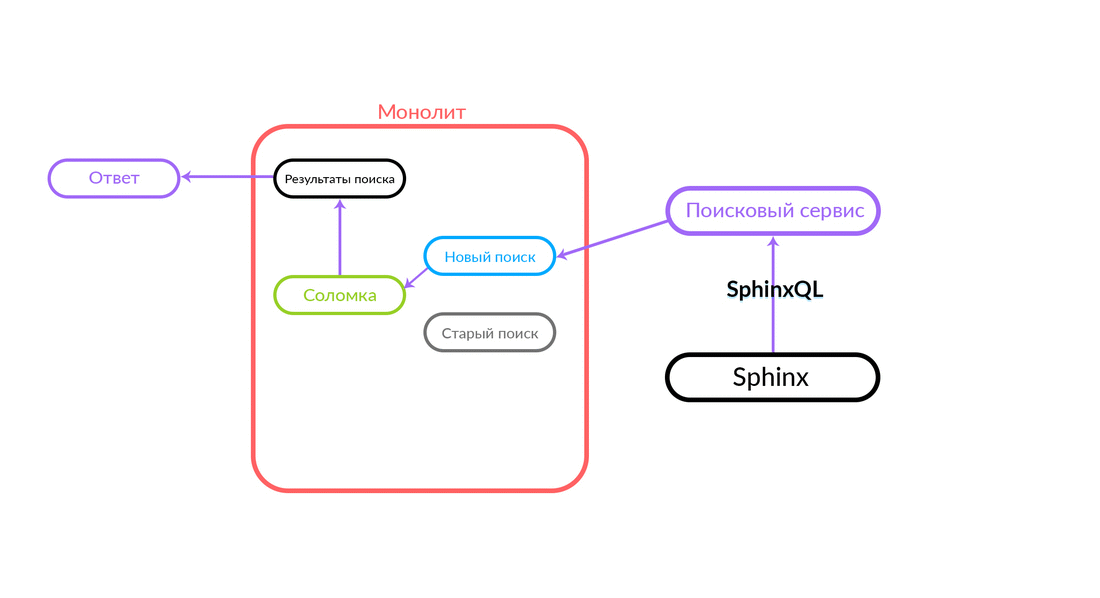
There are situations when some query to the search service has been spilled: for example, and until some functionality has been implemented inside the search service. Then we will surely pledge such a request - “Straws” will fulfill it in the old search. The old search from the monolith will turn to Sphinx, and the answer will go to the client. The client will not feel anything.
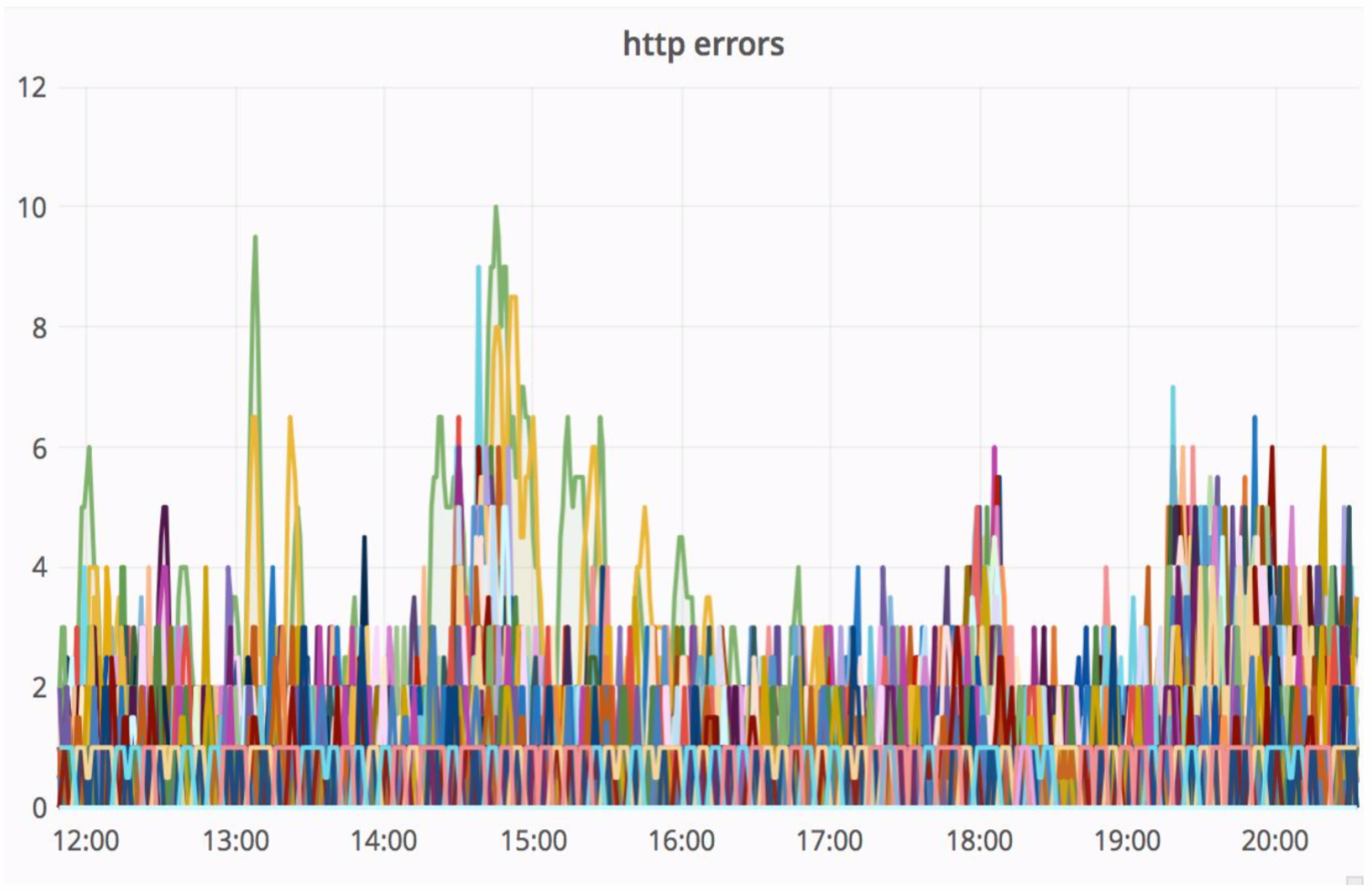
Rather reliable scheme, and it is always interesting to see what happens in practice. The Avito architecture department constantly improves our cloud, tyunit, makes it more reliable and productive. At some stage there were problems, that when servicing one of the nodes, errors with sufficiently high intensity from the monolith went (100 errors per second).

At the same time, the delay in the service has sharply increased - we can see the peaks in the picture below.
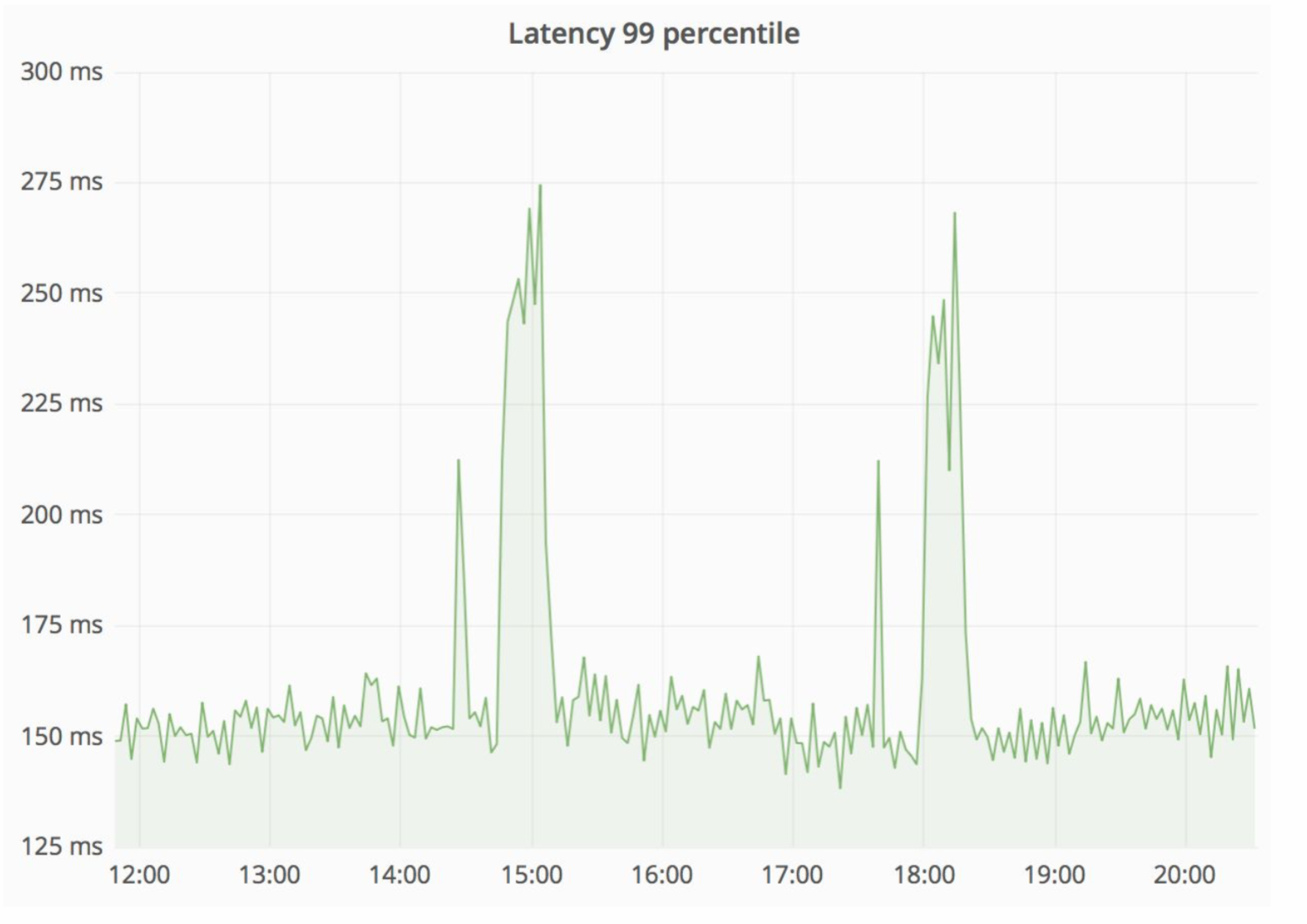
“Straw” wonderfully handled this situation, and the resulting HTTP errors were at the same level - a unit of errors for the whole Avito. Our visitors did not notice anything.
Automation of experiments
We want the search to develop quickly, and it was easier to roll out new features into it. For this you need the appropriate infrastructure. We have set up automation of A / V tests. With the help of dashboards, we can start new experiments, configure them based on the added innovations, and, accordingly, run experiments without rolling out the monolith.
In the initial state, when not a single experiment was launched, all visitors see the usual search functionality.
In a typical experiment, users are divided into groups. The control group - with the usual functionality for our visitors. There are several test groups - with innovations. When we need to create a new experiment, in the search service we implement a new search functionality (add new aggregators) and set up an experiment with the necessary groups through the dashboards, connecting them with new aggregators.
When analyzing the experiments, we compare the behavior of visitors in the control group with the test ones and on the basis of this we draw conclusions about the success of the experiment.

Suppose we have developed a new ranking formula. What do we need to do to experiment with it?
- In the search service, roll out the corresponding aggregator (let it be “Aggregator 2”).
- Through the dashboards create an experiment and link one of the groups in this experiment with this aggregator.
- Now, if a search request arrives that falls into the test group, it goes to the search service on Aggregator 2.
We can continue to create new experiments and link their test groups with new aggregators.
Search infrastructure total
There is a cluster of servers Sphinx 3. It holds 13 krps SphinxQL queries, and there are more than 45 million active ads on it.
Sphinx 3.0 is stable and pleased with its performance. By the way, open source binaries . In addition, thanks to Avito, in Sphinx 3, new features have been filed, for example, the operation of the scalar product of vectors, and the found bugs are fixed.
We use the service architecture. We have a search service "Iskalo" and the service "Avito Assistant". Some of the functionality is still in the monolith, but we are continuing to cut it.
findings
Over the past year, an advanced search engine development system has been received. We got the opportunity to conduct fast and flexible experiments. And now the search for users has become more convenient, helps to solve their problems faster and better.
What's next
Then we will continue to carry out from the monolith what is left: rendering, filters. We will work to improve the quality of the search, continue to delight our visitors. I hope you too.
If you have questions about the work of our search, would like to know more technical details, write in the comments. I will answer with pleasure. By the way, Andrei Drozdov recently spoke at Highload ++ 2018 with a report about multi-criteria optimization of search results , here is his presentation .