Reconciliation - checking data integrity in distributed systems
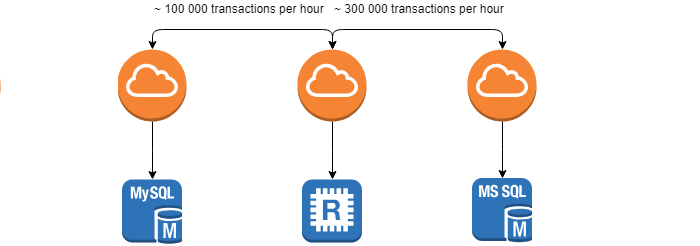
When developing and using distributed systems, we face the task of controlling the integrity and identity of data between systems - the task of reconciliation .
Requirements that the customer exposes - the minimum time of this operation, since the earlier the discrepancy is found, the easier it will be to eliminate its consequences. The task is considerably complicated by the fact that the systems are in constant motion (~ 100,000 transactions per hour) and it will not be possible to achieve 0% discrepancies.
main idea
The main idea of the solution can be described in the following diagram.
Consider each of the elements separately.
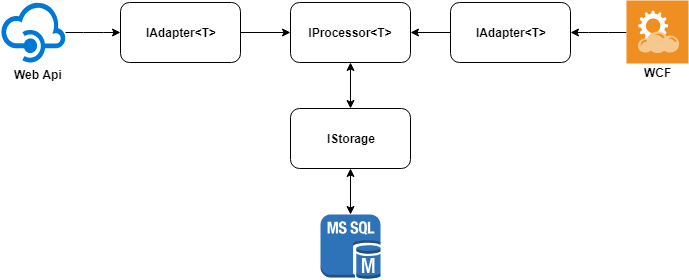
Data adapters
Each of the systems was created for its own subject area and, as a result, the descriptions of objects may vary significantly. We need to compare only a specific set of fields from these objects.
To simplify the comparison procedure, we will bring the objects into a single format, writing their own adapter for each data source. Reduction of objects to a single format allows us to significantly reduce the amount of memory used, since we will only store the compared fields.
Under the hood, the adapter can have any data source: HttpClient , SqlClient , DynamoDbClient , etc.
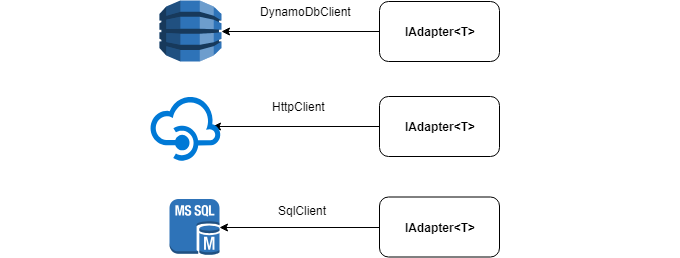
Below is the IAdapter interface that you want to implement:
publicinterfaceIAdapter<T> whereT : IModel
{
int Id { get; }
Task<IEnumerable<T>> GetItemsAsync(ISearchModel searchModel);
}
publicinterfaceIModel
{
Guid Id { get; }
intGetHash();
}Storage
Reconstruction of data can be started only after all data has been read, since adapters can return them in any order.
In this case, the amount of RAM may not be enough, especially if you run multiple reconciliations at the same time, indicating longer time intervals.
Consider the IStorage interface
publicinterfaceIStorage
{
int SourceAdapterId { get; }
int TargetAdapterId { get; }
int MaxWriteCapacity { get; }
Task InitializeAsync();
Task<int> WriteItemsAsync(IEnumerable<IModel> items, int adapterId);
Task<IEnumerable<IResultModel>> GetDifferenceAsync(ISearchDifferenceModel model);
}
publicinterfaceISearchDifferenceModel
{
int Offset { get; }
int Limit { get; }
}Storage. Implementation based on MS SQL
We implemented IStorage using MS SQL, which made it possible to perform the comparison entirely on the Db server side.
To store the values being reconstituted, it is enough to create the following table:
CREATETABLE [dbo].[Storage_1540747667]
(
[id] UNIQUEIDENTIFIER NOTNULL,
[adapterid] INTNOTNULL,
[qty] INTNOTNULL,
[price] INTNOTNULL,
CONSTRAINT [PK_Storage_1540747667] PRIMARY KEY ([id], [adapterid])
)Each entry contains system fields ( [id] , [adapterId] ) and fields to be compared by ( [qty] , [price] ). A few words about the system fields:
[id] - unique identifier of the record, the same in both systems
[adapterId] - adapter identifier through which the record was received
Since reconciliation processes can be started in parallel and have overlapping intervals, we create a table with a unique name for each of them. If the reconciliation was successful, this table is deleted, otherwise a report with a list of records with discrepancies is sent.
Storage. Value comparison
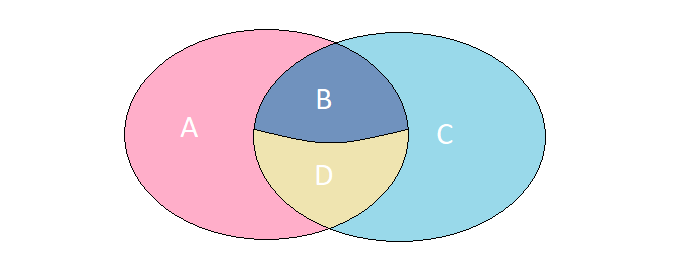
Imagine that we have 2 sets whose elements have an absolutely identical set of fields. Consider 4 possible cases of their intersection:
A . Elements are present only in the left set of
Bed and . The elements are present in both sets, but have different meanings
C . Elements are present only in the right set of
D . Elements are present in both sets and have the same values.
In particular problem we need to find the elements described in the cases A, B, C . You can get the required result in one request to MS SQL via FULL OUTER JOIN :
select
[s1].[id],
[s1].[adapterid]
from [dbo].[Storage_1540758006] as [s1]
fullouterjoin [dbo].[Storage_1540758006] as [s2]
on [s2].[id] = [s1].[id]
and [s2].[adapterid] != [s1].[adapterid]
and [s2].[qty] = [s1].[qty]
and [s2].[price] = [s1].[price]
where [s2].[id] is nulThe output of this query can contain 4 types of records that meet the original requirements.
| # | id | adapterid | comment |
|---|---|---|---|
| one | guid1 | adp1 | The record is present only in the left set. Case A |
| 2 | guid2 | adp2 | The record is present only in the right set. Case C |
| 3 | guid3 | adp1 | Records are present in both sets, but have different meanings. Case B |
| four | guid3 | adp2 | Records are present in both sets, but have different meanings. Case B |
Storage. Hashing
Using hashing on compared objects, you can significantly reduce the cost of write and compare operations. Especially when it comes to comparing dozens of fields.
The most universal was the method of hashing the serialized representation of an object.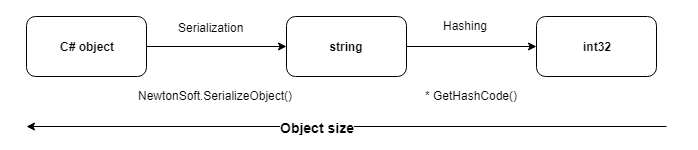
1. For hashing, we use the standard GetHashCode () method , which returns int32 and is redefined for all primitive types.
2. In this case, the probability of collisions is unlikely, since only records that have the same identifier are compared.
Consider the structure of the table used in this optimization:
CREATETABLE [dbo].[Storage_1540758006]
(
[id] UNIQUEIDENTIFIER NOTNULL,
[adapterid] INTNOTNULL,
[hash] INTNOTNULL,
CONSTRAINT [PK_Storage_1540758006] PRIMARY KEY ([id], [adapterid], [hash])
)The advantage of this structure is the constant cost of storing one record (24 bytes), which will not depend on the number of compared fields.
Naturally, the comparison procedure undergoes its changes and becomes much easier.
select
[s1].[id],
[s1].[adapterid]
from [dbo].[Storage_1540758006] as [s1]
fullouterjoin [dbo].[Storage_1540758006] as [s2]
on [s2].[id] = [s1].[id]
and [s2].[adapterid] != [s1].[adapterid]
and [s2].[hash] = [s1].[hash]
where [s2].[id] isnullCPU
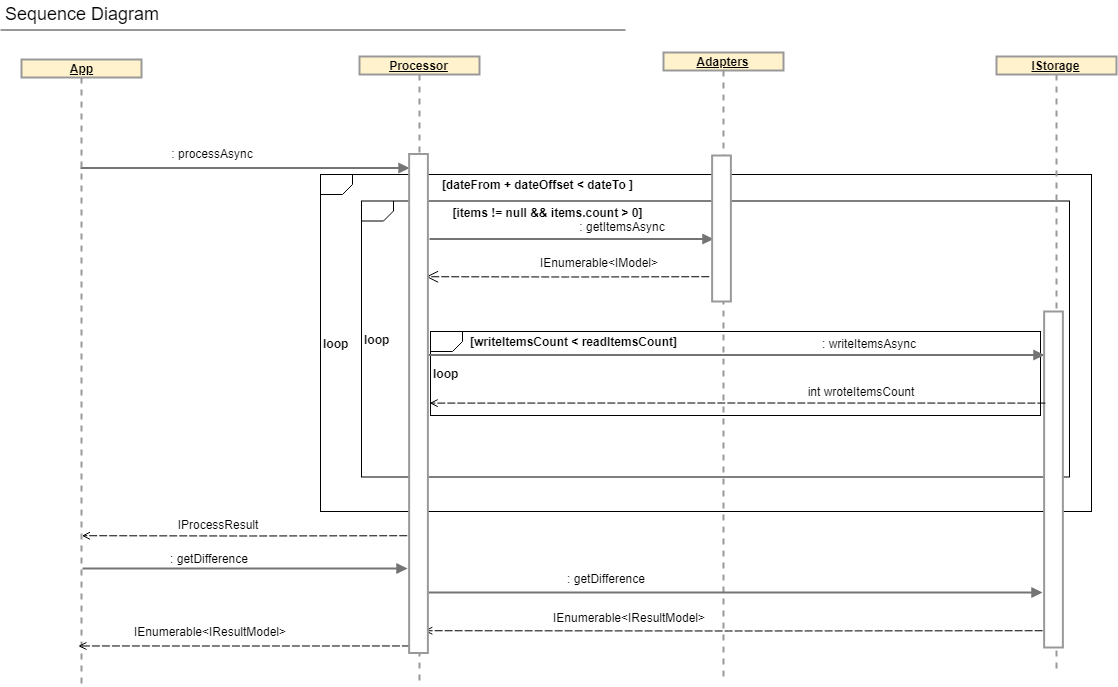
In this section we will talk about the class containing the entire business logic of reconciliation, namely:
1. parallel reading of data from adapters
2. data hashing
3. buffered writing of values in a database
4. outputting results
A more comprehensive description of the reconciliation process can be obtained by looking at the sequence diagram and the IProcessor interface .
publicinterfaceIProcessor<T> whereT : IModel
{
IAdapter<T> SourceAdapter { get; }
IAdapter<T> TargetAdapter { get; }
IStorage Storage { get; }
Task<IProcessResult> ProcessAsync();
Task<IEnumerable<IResultModel>> GetDifferenceAsync(ISearchDifferenceModel model);
}
Acknowledgments
Many thanks to my colleagues from the MySale Group for feedback: AntonStrakhov , Nesstory , Barlog_5 , Costa Krivtsun and VeterManve - to the author of the idea.