Disaster-proof IaaS, as well as replication and backups

We live in a time when information volumes are growing every day faster. In parallel with this, business needs are growing. The growing popularity of virtualization and cloud computing has made it possible for both small and large companies, so it has become necessary to change approaches to data security.
There is a so-called disaster recovery solution (Disaster Recovery Solution or DRS), which is often confused with a high-availability system . However, there is a difference between these concepts, and this is the acceptable scale of the accident. DRS-systems can recover from a major failure of several data centers at once, without paralyzing the work of services for a long time.
When it comes to systems of this class, people often mean a backup data center, which serves as a springboard for transferring load and data from a non-working place. There are three types of data centers: cold reserve, warm reserve and hot reserve. Cold reserve are often low-performance servers that are ordered and configured after an accident occurs, and data is transferred to them on magnetic tapes or disks. The "rise" of this infrastructure can last several days or weeks and depends on suppliers, transport and staff skills.
Warm reserve - these are weaker servers in the minimum amount necessary to run critical systems; they are connected, activated and always ready for load transfer. To start such a system requires no more than one day. Hot standby - these are servers whose performance corresponds to the servers of the main site; in this case, all data is replicated regularly and on an ongoing basis. Since there is a ready-made infrastructure, channels, software, and all this is brought together automatically, the launch of such a system takes place within one hour (often less).
It is the warm option that is now used by many companies because of the acceptable cost and good timing. But if you use a backup platform based on IaaS, you can even get a hot option without a significant budget increase. DRS in the cloud infrastructure is not particularly different from classic solutions, but it has several tangible advantages.
If earlier for the organization of the LUN replica, compatible storage systems with special licenses were required, now it’s enough to put a couple of daws in a virtual environment (the same vSphere vSAN), and the popular vector for outsourcing and cloud computing allows you to give some corporate services to third parties. This makes it possible to exclude highly specialized employees from the state and begin to build our own management and monitoring system.
Allocating a backup data center is necessary:
- To provide the opportunity for users to work not only from the main office, but also from any other place (decentralization useful in a large-scale accident)
- The backup data center should have an availability indicator close to 100% per year. In practice, this means the maximum number of nines after the decimal point (99.0%, ..., 99.999%)
- Emergency site data should be up to date
One of the most important components of a disaster-resilient solution is the preservation of relevant information on both, for example, sites. RPOs (valid recovery point ) are directly dependent on stable storage synchronization . Virtual disk replication can be performed, for example, using vSphere Replication or to shift this task to storage systems (storage-based replication).
VSphere Replica's own mechanism is replication at the ESXi hypervisor level, which does not depend on the type and identity of storage systems on all sites. A distinctive feature is the ability to transfer data between different types of storage devices: from VSAN on the main site to DAS on the backup. Storage-level replication is a more efficient mechanism whereby the entire synchronization process is transferred to storage devices. The minimum RPO of hardware replication is a couple of minutes, which fits well with the requirements of a business-critical application.
And, as often happens, in general it is recommended to choose a hybrid option. In it, you select a datastore with hardware replication of the most important virtual machines, and protect the rest with the vSphere Replica mechanism, which allows you to work with cheaper storage systems. A pleasant bonus from devices with hardware replication will be proprietary snapshot technologies, shadow volumes, and other useful features. Due to the popularity of NetApp storage systems in the domestic market, we will consider them as the main storage for DRS (by the way, we published anboxing of storage systems, which you can see here and here ).
Snapmirror
SnapMirror is known as disk-based synchronous and asynchronous replication technology that takes place using an IP network. The technology is based on the concept of using differential snapshots of the state of the corresponding volume.
Synchronous replication is characterized by the fact that the ready signal from the storage to the recording application is not transmitted until data is written to both the source volume on the client side and the replica in the cloud of the IaaS provider. In other words, the application waits until the data block is written to the local volume first and then to the remote one.
During asynchronous replication during recording, the local system immediately sends a signal to the application with the status “recorded”, after which (at a specified interval) updates are sent to the remote site.
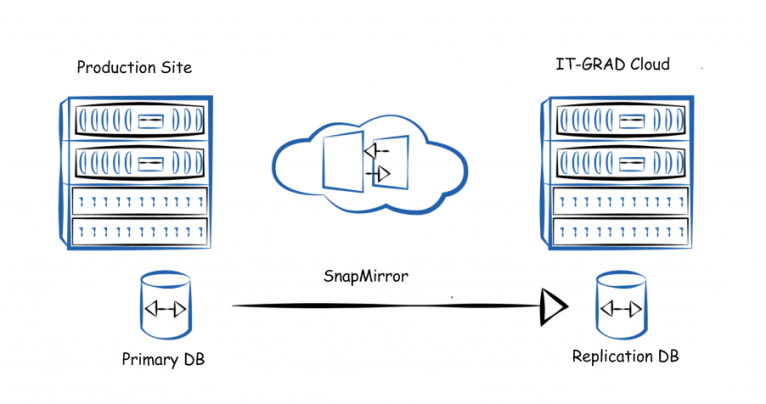
Synchronous / asynchronous replication technology SnapMirror
In the event of a break in the replica, the receiving side transfers the replicated mirror to read-write mode, which remains active until the equipment on the customer side is restored. After everything has returned to normal, SnapMirror enters into operation in reverse replication mode and restores the database on the client side.
Snapvault
Replication is good in itself, but it is unlikely to help in case of data corruption. During replication, “corrupted” fragments fall into the backup system, which leads to the appearance of two damaged data sets. SnapVault backup technology allows you to avoid such unpleasant situations, which solves the problems of long-term storage and protection of data from changes for their subsequent recovery.

SnapVault backup technology
In the case of the client and the cloud provider, the essence of using SnapVault is that customer data located on the source volume is copied to the destination volume in the cloud of the hosting provider according to the schedule. Such a copy is created in read-only mode, which is accessed as necessary.
In general, the topic of backup has always been relevant. A study by analytic company Gartner showed that data growth is the biggest data center infrastructure problem in large organizations. All data must be protected from various threats, as well as methods to reduce the amount of data and restore them.
The very idea of cloud backup is to automatically transfer client backups to the data center of the cloud service provider. Of course, in order to create a service, it is not enough just to allocate storage space and give the client access, it is necessary to ensure safe storage of information and access to it, as well as correctly formulate a tariff policy and provide a certain level of service with a fixed response time.
The main task of any cloud backup is to save a data reserve in case of an unforeseen situation. The availability of these backups depends on the level of reliability (Tier) of the provider. For example, Tier-1 assumes availability of 99.671% per year, and Tier-4 - already 99.995%.
Data center providers can declare a variety of availability values, but the reality is that any unforeseen events (hacker attack, natural disasters) can withdraw equipment and make your data inaccessible. As an example, we can recall a large-scale accident in the Amazon data center, when whole services were disconnected due to a thunderstorm: Netflix, Instagram and Pinterest. Since disasters are not always possible to prevent, it is worth choosing a provider with a well-developed disaster recovery plan. Then you will at least get your data back within a reasonable time.
Also, for any business, one of the most important priorities is the confidentiality of user data. To reduce the chance of information being compromised, it’s important to choose a supplier with proven compliance with local and international security standards. For example, one of the most stringent modern standards is the PCI (Payment Card Industry Standard), which protects financial information. If you work with other specific information (medicine, industry, etc.), then the provider will be required to comply with the standards of this industry.
Any company that has existed long enough knows that it is impossible to completely eliminate the likelihood of data loss. But whether this will simply be an inconvenience or a situation that puts the entire business on the shoulder depends on the quality of the preliminary training. The rules of the game in the business environment are regularly changing, and cloud services allow organizations to insure themselves against serious losses.
PS Interesting materials on the topic from our blog on Habré:
- Briefly about IaaS Trends
- Experience and problems of the data center: How to check the reliability of the data center
- How IaaS provider choose a data center to host the cloud: Experience IT-GRAD
- How we implemented Disaster Recovery