Quantum leap

The term “ quantum jump ”, aka “quantum transition”, describes an abrupt change in the state of a quantum system. And it is this physical term that is associated with the current situation in which the cheapening of flash-memory made it possible to create super-productive storage systems that are not inferior in capacity to systems on hard disks and compete with them in the total cost of one terabyte. This year, the total cost of one terabyte for the first time will make flash-systems more profitable.
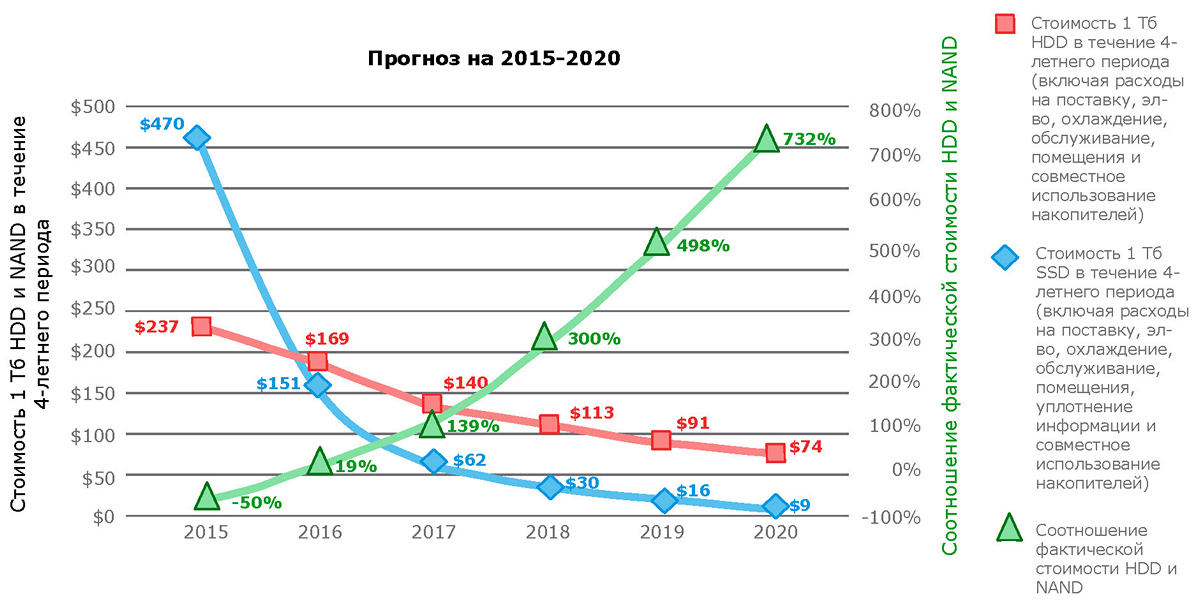
Source: http://wikibon.org/wiki/v/Evolution_of_All-Flash_Array_Architectures
The importance of this moment can hardly be overestimated; it can be compared with the rapid change of the historical formation. The era of HDD dominance is fast becoming a thing of the past. And one of the messengers of this process was DSSD D5 - high-performance rack-class storage on flash-drives (RSF, Rack-Scale Flash).
The RSF system is a shared repository designed to solve tasks that require the highest performance and processing huge amounts of data. Solutions of this class became popular because, despite the rapid development of traditional storage systems, they did not have time to keep up with the requirements for the performance of new types of workloads. The world of software-defined infrastructures now needs the fastest electronic storage that a modern process can afford. DSSD D5, in fact, is a system designed to solve this problem.
In the maximum configuration, the DSSD D5 performance is as follows:
- Bandwidth up to 100 Gb / s.
- Up to 10 million IOPS.
- Delay ~ 100 microseconds (for applications with integrated native API).
- Full capacity up to 144 TB, used - 100 TB.
Fields of application
In high-performance computing systems, the bottlenecks of storage are the number of operations / input / output, bandwidth and capacity. The main task of RSF-systems is to level these limitations.
From the point of view of the nature of workloads, there are three areas of application of D5:
- High performance storages / databases . These include traditional databases like Oracle, as well as databases with mass-parallel processing. Such systems are used to service financial transactions, manage risks, prevent fraud, manage supplies, etc.
- For transaction processing applications, ultra-low latency means more transactions per second, and therefore more profit.
- The high level of IOPS and bandwidth allows you to quickly develop business solutions or analyze more data, which means to be more competitive.
- Performing all analytics on one D5 can significantly save time on moving data.
- High performance applications on Hadoop . Unlike traditional Hadoop batch processing, this requires a high speed of receiving and processing data. In particular, for the analysis of real-time streaming information in the areas of exchange trading, advertising systems, business reporting and predictive modeling based on extensive data sets.
- Independent scaling of computing power and storage in the Hadoop infrastructure.
- High performance user applications . Workloads involving high storage performance and data processing through a fast API. In such cases, traditional file systems like XFS or parallel clustered file systems are used. Areas of application: trade modeling, weather prediction, mechanical engineering, medical research, pharmacology, climate analysis, etc.
- High throughput and a large number of IOPS allow us to draw conclusions based on data processing within minutes after they are received, and not hours or days.
- When using parallel file systems, you can reduce the amount of infrastructure by 20 or more times.
- Real-time analytics allows you to quickly market new products.
On the other hand, DSSD D5 in its current release is not designed to work with SAP HANA, since it requires appropriate technological integration at the RAM level and subsequent certification with SAP.
Architecture

At the heart of the DSSD D5 is a new architecture that provides an order of magnitude higher performance, minimal latency and extremely high memory density. At the same time, the level of reliability and accessibility characteristic of corporate systems is provided.
What are the features of the D5 architecture?
- For the first time in the industry, direct access to flash-memory (DMA) with segmented levels of control and data is applied.
- Flexible access to data (block, object, key-value).
- Built-in switches (PCIe Mesh Fabric) provide extremely low latency.
- The system can be used simultaneously by several computing nodes.
- There is no single point of failure.
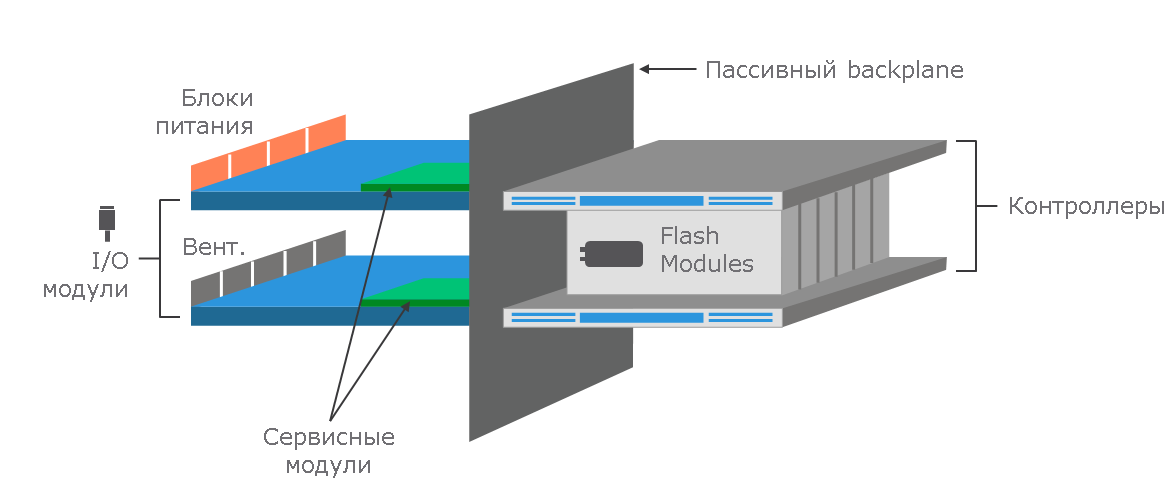
Block diagram DSSD D5.
Ability to integrate direct memory access APIs into user applications. High system performance is achieved through:
- API with asynchronous architecture without locks,
- lack of software intermediaries in the data transmission path,
- lack of kernel interaction with the APIs and plugins used,
- and intensive parallelization of processes.

Initially, the D5 will be available in four configurations: with 18 or 36 flash modules of 2 or 4 TB (thousands of NAND memory chips). Thus, the total storage capacity can be 36, 72 or 144 TB. All modules are combined into a RAID array. The capacity available for use will be approximately 25, 50, or 100 TB for a "typical workload." The exact amount of memory will be determined by the size of FLEN: the smaller it is, the more metadata will be in the storage. According to our measurements, the highest level of IOPS is achieved with 4 Kb FLEN objects, and the best throughput is achieved with 32 Kb FLEN.
All flash modules are non-volatile and protected against power failures. Each module is connected to the PCIe network via two separate lane-connections PCIe Gen3 x4, which allows to achieve throughput up to 8 Gb / s.

Flash module DSSD D5.
Thanks to the multi-link PCIe network, each client has direct access to each of the NAND chips. This allowed us to abandon excessive copying when writing data to the final part of the memory. And the use of the NVMe protocol provides parallel access to any parts of the D5 memory.
Unlike traditional architectures in which the processor controls the system, in DSSD D5 the control and data transmission paths are separated and have their own control module. These modules control the input / output operations, but the data itself goes through the input / output modules directly between the connected servers and flash modules.

Controller module DSSD D5.
Connecting D5 to servers is carried out using I / O modules operating according to the active-active scheme. Each module allows connecting up to 48 nodes with redundancy through the PCIe Gen3 x4 lane ports (96 ports in total). Cards for connecting nodes are installed in standard PCIe Gen3 x8 slots and connected to I / O modules via dual PCIe Gen3 x4 copper cables. In the future, it is planned to introduce support for Active Optical Cable (AOC).

DSSD D5 I / O module.
Bidirectional throughput of a single port reaches 3.5 Gb / s, and dual ports - 6.5 Gb / s. So the theoretical throughput of the entire system is 6.5 * 48 = 312 Gb / s. But due to the limitations inherent in some components, 100 Gb / s is now provided.
To access DSSD D5, the client software must have the following software installed:
- client card driver
- block device driver
- Client CLI
- The libflood library used by applications to call our APIs
- API and CLI documentation.
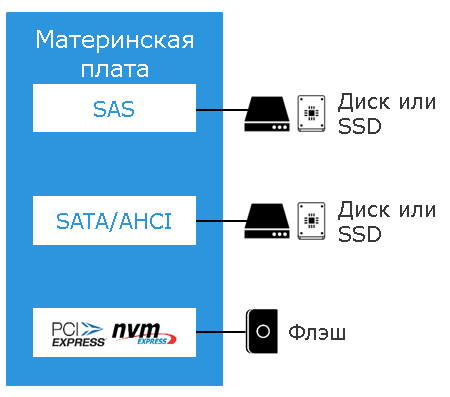
NVMe protocol.
Finally, one of the very important properties of the DSSD D5 architecture is its “maintainability”: all the main components - from cards for connecting clients (servers) to flash modules - are backed up and can be replaced by the customer independently. This provides a very high level of availability and the absence of a single point of failure.
In the dry residue
To summarize the above. DSSD D5 is the first solution in the RSF (Rack-Scale Flash) class. It is designed to solve problems that are extremely demanding on storage performance, latency and throughput. At the same time, the total cost of 1 TB of DSSD D5 memory is already comparable with HDD-based systems, and by a number of metrics the new solution surpasses the majority of all flash-systems with "traditional" architectures on the market.