Myths about / dev / urandom
- Transfer

Surely many of you have repeatedly come across the myths of / dev / urandom and / dev / random. Maybe you even believe in some of them. In this post, we will break the covers of all these myths and analyze the real strengths and weaknesses of these random number generators.
Myth 1: / dev / urandom is unsafe. For cryptography always use / dev / random
Basically, this is stated in relation to fairly "fresh" Linux-based systems, and not generally to all UNIX-like systems. In fact, / dev / urandom is the preferred random number generator for cryptographic tasks on UNIX-like systems.
Myth 2: / dev / urandom is a pseudo random number generator (PRNG), and / dev / random is a true random number generator
In fact, both of them are cryptographically robust pseudo random number generators ( CSPRNG ). The differences between them are very small and are not related to the degree of randomness.
Myth 3: for cryptographic tasks, it is definitely better to use / dev / random. There is no point in using / dev / urandom, even if it were relatively safe
Actually , / dev / random has a very nasty problem: locks.
But this is wonderful! The more entropy in the pool / dev / random, the higher the level of randomness. And / dev / urandom generates unsafe random numbers, even if the entropy is already exhausted
No . "Exhaustion of entropy" is a scarecrow, even if you do not take into account the availability and subsequent manipulations by users. The order of 256 bits of entropy is quite enough for a VERY long generation of computationally stable numbers.
Much funnier is another: how can / dev / random know how much more entropy he has left?
But cryptography experts keep talking about constantly updating the initial state (re-seeding). Does this contradict your last statement?
This is partly true. Yes, the random number generator is constantly updating its initial state using all kinds of sources of entropy that are available to it. But the reasons for this lie elsewhere (in part). I am not saying that using entropy is bad. Not at all. I am only talking about the dangers of blocking when entropy falls.
This is all fine, but even the / dev / (u) random manual contradicts your claims. In general, does anyone share your point of view?
I do not refute reference data at all. I can assume that you still do not quite understand all this cryptographic jargon, so you saw in the directory confirmation of the insecurity of / dev / urandom for cryptographic tasks. But the directory just does not recommend using / dev / urandom in some cases. In my opinion, this is not critical. At the same time, the directory recommends using / dev / urandom for "normal" cryptographic tasks.
Appeal to authorities is not a reason for pride. In cryptography, it is necessary to carefully approach the solution of issues, listening to the opinion of specialists in specific fields.
And yes, many experts share my point of view that in the context of cryptography on UNIX-like systems, the best random number generator is / dev / urandom. As you know, this combined opinion influenced me, and not vice versa.
* * *
Most of you probably have a hard time believing this. “He must be mistaken!” Well, let’s take a look at everything that has been said, and you will decide for yourself whether I am right or not. But before you start the analysis, answer yourself: what is chance? More precisely, what kind of randomness are we talking about here? I'm not trying to be lenient. This text was written in order to refer to it in the future, when again there will be a discussion about random number generators. So here I hone my arguments and arguments. In addition, I am interested in other opinions. It is not enough to simply say that "/ dev / urandom is bad." You need to find out what exactly you do not agree with and figure it out.
"He's an idiot!"
Strongly disagree! I myself once believed that / dev / urandom is not safe. Yes, we all simply had to believe it, because many of these respected programmers and developers on forums and social networks insist on it. And it seems to many that even in man says the same thing. And who are we to argue with their convincing argument about "exhaustion of entropy"?
This deeply erroneous opinion is rooted not because people are stupid, but just few people seriously understand cryptography (namely, the foggy concept of "entropy"). Therefore, authorities easily convince us. Even intuition agrees with them. Unfortunately, intuition also makes no sense in cryptography, like most of us do.
True chance
What are the criteria for "true randomness" of a number? We will not delve into the jungle, since the discussion will quickly move into the field of philosophy. In such discussions, it is quickly discovered that everyone is talking about his favorite model of chance, not listening to others and not even caring to be understood.
I believe that quantum effects are the true standard of “true randomness”. For example, those arising when photons pass through a translucent mirror, when alpha particles are emitted by radioactive material, etc. That is, ideal randomness occurs in some kind of physical phenomena. Someone may believe that they cannot be truly random. Or that in the world nothing can be accidental at all. In short, " all the letters ."
Cryptographers usually avoid participating in such philosophical debates because they do not recognize the concept of "truth." They operate with the concept of "unpredictability." If no one has any information about the next random number, then everything is in order. I believe that this is what you need to focus on when using random numbers in cryptography.
In general, I am not much concerned about all these "philosophically safe" random numbers, as I call myself "truly" random.
Of the two types of security, only one matters.
But let's assume that you were able to get "truly" random numbers. What will you do with them? Print and hang on the walls in the bedroom, enjoying the beauty of the quantum universe? Why not, I can understand that attitude.
But you probably use them, and for cryptographic needs? And this already does not look so positive. You see, your truly random numbers overshadowed by the goodness of the quantum effect fall into mundane real-world algorithms. And the problem is that almost all of the cryptographic algorithms used do not correspond to information-theoretic security. They provide "only" computational security. Only two exceptions come to mind: the Shamir secret sharing scheme and the Vernam cipher. And if the first can act as a counterpoint (if you are really going to use it), then the second is extremely impractical. Still, the rest of the algorithms: AES, RSA, Diffie-Hellman, elliptic curves, cryptographic packages such as OpenSSL, GnuTLS, Keyczar, and cryptographic APIs are computationally secure.
What is the difference? Information-theoretically safe algorithms provide security for some period, and all other algorithms do not guarantee security in the face of an attacker who has unlimited computing power and enumerates all possible key values. We use these algorithms only because if we collect all the computers in the world, they will solve the problem of enumeration longer than the universe exists. This is what level of "insecurity" we are talking about.
But this is only as long as some very smart guy does not crack the next algorithm with the help of much more modest computing power. Any cryptanalyst dreams of such success: gaining fame by hacking AES, RSA, etc. And when they crack “ideal” hashing algorithms or “ideal” block ciphers, it’s completely unimportant that you have your “philosophically safe” random numbers. You simply have nowhere to use them safely. So it’s better to use computationally safe random numbers in computationally secure algorithms. In other words, use / dev / urandom.
Linux Random Number Generator Structure: Misconception
Most likely, you have something like this about the work of a random number generator built into the kernel:
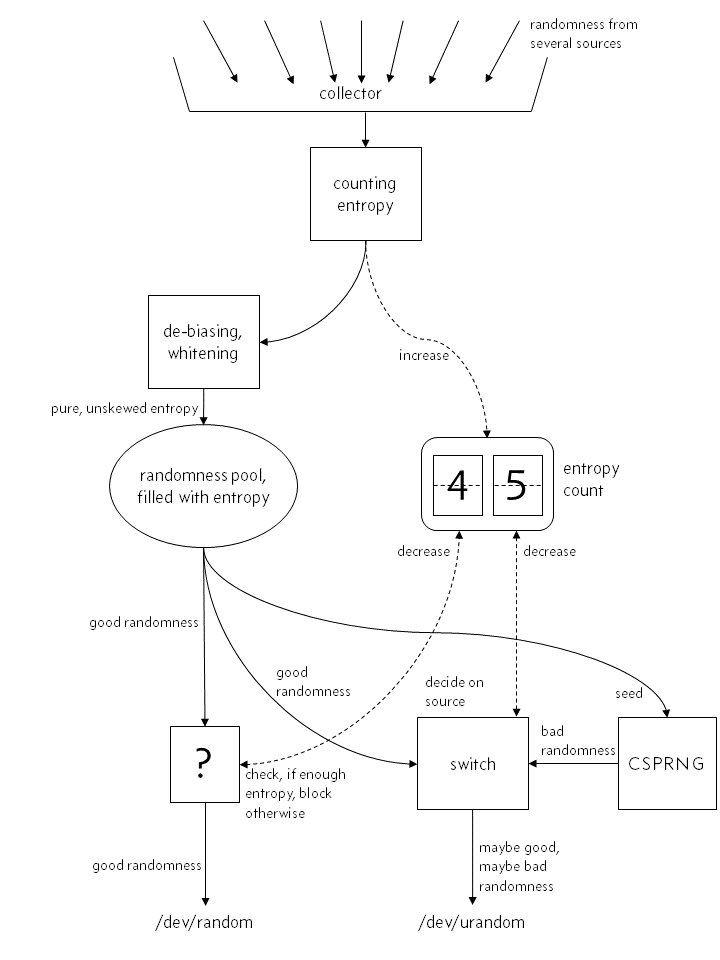
“True” randomness, although probably distorted, gets into the system. Its entropy is calculated and immediately added to the value of the internal entropy of the counter. After correcting and introducing white noise (whitening), the resulting entropy is transferred to the kernel pool, where random numbers / dev / random and / dev / urandom are taken from. / dev / random gets them directly from the pool if the entropy counter has the requested number of numbers. Of course, the counter decreases. Otherwise, the counter is blocked until a new portion of entropy enters the system.
The important point is that the data received / dev / random is necessarily subjected to the operation of adding white noise. C / dev / urandom has the same story, with the exception of the moment when the required amount of entropy is not found in the system: instead of applying the lock, it receives "low-quality" random numbers from CSPRNG, which works outside the system we are considering. The starting number for this CSPRNG is selected only once (or each time, no matter) based on the data in the pool. It cannot be considered safe.
For many, this is a compelling reason to avoid using / dev / urandom on Linux. When there is enough entropy, the same data is used as in the case of / dev / random, and when it is not enough, an external CSPRNG is connected, which almost never receives data with high entropy. Awful, isn't it? Unfortunately, everything described above is fundamentally wrong. In fact, the internal structure of the random number generator looks different: The
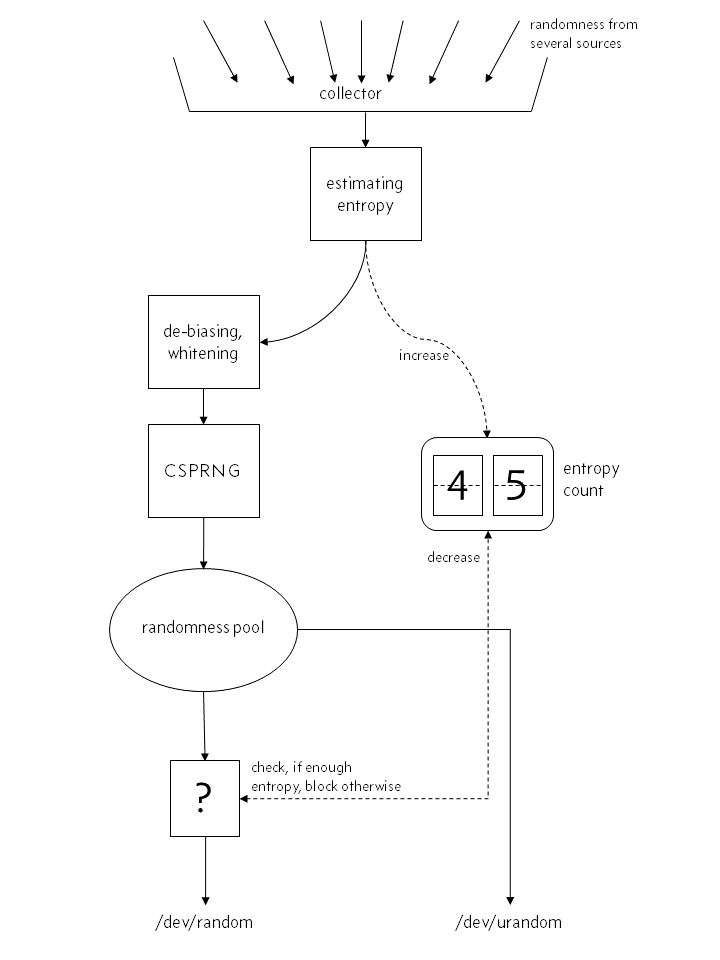
simplification is rather crude: in fact, not one, but three entropy pools are used:
- primary,
- for / dev / random,
- for / dev / urandom.
The last two pools receive data from the primary. Each pool has its own counter, but the last two have them close to zero. “Fresh” entropy is supplied from the first pool as needed, while its own counter decreases. Also, mixing and returning data back to the system is actively used, but all these nuances are unimportant for the subject of our conversation.
Notice the difference? CSPRNG does not work in addition to the main generator, but is an integral part of the random number generation process. For / dev / random, no “clean and good” random data is output that contains white noise. Incoming data from each source is thoroughly mixed and hashed inside CSPRNG and only then is given as random numbers for / dev / random or / dev / urandom.
Another important difference is that entropy is not considered here, but estimated. The amount of entropy from any source is not something obvious, like some kind of data. Remember that your dearly beloved / dev / random only gives out the number of random numbers that is available due to the existing entropy. Unfortunately, estimating the amount of entropy is quite difficult. The Linux kernel uses this approach: it takes the start time of an event, interpolates its polynomial and calculates "how unexpectedly", according to some model, this event started. There are certain questions about the effectiveness of this approach to the estimation of entropy. Also, the effect of hardware delays on the start time of events cannot be discounted. The frequency of polling hardware components can also play a role,
In general, we only know that the estimation of entropy in the core is implemented quite well. Which means - conservatively. Someone can argue about how well everything is done, but this is already beyond the scope of our conversation. You may be nervous about the lack of entropy for generating random numbers, but I personally like the current evaluation mechanism.
To summarize: / dev / random and / dev / urandom work due to the same CSPRNG. They differ only in the behavior when the entropy pool is exhausted: / dev / random blocks, and / dev / urandom does not.
What is bad about blocking?
Have you ever had to wait for / dev / random to produce random numbers? For example, generating PGP keys inside a virtual machine? Or when connecting to a web server that expects a portion of random numbers to create a dynamic session key? This is precisely the problem. In fact, accessibility is blocked, your system is temporarily not working. She does not do what she must.
In addition, it gives a negative psychological effect: people don’t like it when something prevents them. For example, I am working on the safety of industrial automation systems. What do you think is the most likely cause of security breaches? Due to the conscious actions of the users themselves. It's just that some measure designed to provide protection takes too long, according to the employee. Or she's too uncomfortable. And when you need to find "informal solutions", people show miracles of resourcefulness. They will look for workarounds, invent fancy machinations to make the system work. People who are not versed in cryptography. Normal people.
Why not patch the random () call? Why not ask someone in the forums how to use weird ioctl to increase the entropy counter? Why not completely disable SSL ? In the end, you just teach your users how to do stupid things that compromise your security system without even knowing it. You can arbitrarily disdain the accessibility and usability of the system and other important things. Safety comes first, huh? Better let it be uncomfortable, inaccessible or useless, instead of pretending to be safe.
But this is all a fake dichotomy. Security can be provided without blocking, because / dev / urandom gives you exactly the same random numbers as / dev / random.
There is nothing wrong with CSPRNG
But now the situation looks very dull. Even if high-quality numbers from / dev / random are generated by CSPRNG, then how can they be used in tasks requiring a high level of security? It seems that the basic requirement for most of our cryptographic modules is the need to “look random.” For cryptographic hash output to be accepted by cryptographers, it must be indistinguishable from a random set of strings. And the output of a block cipher without knowing the key should be indistinguishable from random data.
Do not be afraid that someone will be able to take advantage of some weaknesses of CSPRNG and break into cryptographic modules. You still have no choice but to come to terms with this, since block ciphers, hashes, and everything else is based on the same mathematical foundation as CSPRNG. So relax.
What about running out of entropy?
It does not matter. Basic cryptographic elements are designed taking into account the fact that the attacker will not be able to predict the result if at the beginning there was a lot of randomness (entropy). Usually the lower limit of “sufficiency” is 256 bits, not more. So forget about your entropy. As we have already discussed above, the random number generator built into the kernel cannot even accurately calculate the amount of entropy entering the system. He can only appreciate it. In addition, it is not clear how the assessment is carried out.
Initial state update (re-seeding)
Но если энтропия имеет так мало значения, то для чего в генератор постоянно передаётся свежая энтропия? Надо сказать, что избыток энтропии вреден. Но для обновления начального состояния генератора есть другая важная причина. Представьте, что атакующему стало известно внутреннее состояние вашего генератора. Это самая кошмарная ситуация с точки зрения безопасности, какую вы можете вообразить, ведь атакующий получает полный доступ к системе. Вы в полном пролёте, с этого момента злоумышленник может вычислять все будущие выходные данные.
But over time, more and more portions of fresh entropy will come in, which will mix with the internal state, and the degree of its randomness will begin to grow again. So this is a kind of protective mechanism built into the generator architecture. However, note: entropy is added to the internal state; it has nothing to do with blocking the generator.
Man pages by random and urandom
Man has no equal in inspiring fears in the minds of programmers:
When reading from / dev / urandom, blocking in anticipation of the necessary entropy will not be carried out. As a result, if there is not enough entropy in the pool, then the returned data is theoretically vulnerable to cryptographic attacks on the algorithms used by the driver. Open sources do not contain information on how this can be done, but the existence of such attacks is theoretically possible. If this may concern your application, then use / dev / random.
Nothing is said about such attacks anywhere, but the NSA / FSB probably has something in service, right? And if it excites you (it should excite!), Then / dev / random will solve all your problems. Even if the method of carrying out such an attack is known to special services, kulkhatskers or a granny, then just taking and arranging it will be irrational. I will say more: in the open literature, practical methods of attacks on AES, SHA-3 or any other similar ciphers and hashes are also not described. Will you refuse them too? Of course not. Especially touches the advice " use / dev / random"In light of what we already know about the common source of it and / dev / urandom. If you desperately need information-theoretically safe random numbers (and you don’t need them!) And for this reason you cannot use CSPRNG, then / dev / random is useless for you! In the reference book is written nonsense, that's all. But the authors are at least trying to somehow correct themselves:
If you are not sure that you should use - / dev / random or / dev / urandom, then most likely it will be better to use the second. In most cases, with the exception of generating reusable GPG / SSL / SSH keys, / dev / urandom should be used.
Wonderful. If you want to use / dev / random for reusable keys, the flag is in your hands, although I don’t think it is necessary. Well, wait a few seconds before you can type anything on the keyboard, think about it. Just I beg you, do not force endlessly connect to the mail server just because you "want to be safe."
Orthodox consecrated
Below are some interesting sayings that I found on the Internet. And if you really want someone to support you with / dev / random, then refer to real cryptographers.
Daniel Bernstein aka djb:
Cryptographers have nothing to do with this superstition. Think about it: the one who wrote the manual on / dev / random really believes in it.
- We don’t know how to deterministically transform one 256-bit number from / dev / random into an endless stream of unpredictable keys (which we need from urandom), but
- we can figure out how to use a single key to securely encrypt multiple messages. What, in fact, we need from SSL, PGP, etc.
Cryptographers will not even smile at all of this.
Thomas Pornin , one of the most useful users I've come across on Stack Exchange:
In short, yes. If deployed, yes too. / dev / urandom provides data that cannot be distinguished from truly random using available technologies. There is no point in striving for an even “better” chance than the one provided by / dev / urandom, unless you use one of several “information-theoretic” cryptographic algorithms. And you definitely do not use them, otherwise you would know about it. The urandom reference is misleading in its suggestion that / dev / urandom should use / dev / random because of “drying up entropy”.
Thomas ptacekIt is not a real cryptographer in terms of developing algorithms or creating cryptosystems. But then he founded a security consulting agency that has earned a good reputation with numerous penetration tests and hacking low-quality cryptography:
Use urandom. Use urandom. Use urandom. Use urandom. Use urandom. Use urandom.
There is no perfection in the world
/ dev / urandom is not perfect, and there are two reasons for this. Unlike FreeBSD, on Linux it never causes locks. And as you remember, the entire security system is based on a certain initial randomness, i.e., on the choice of the starting number. On Linux / dev / urandom, without a twinge of conscience, it gives you not too random numbers even before the kernel has at least some opportunity to collect entropy. When does this happen? At the start of the machine, during computer startup. In FreeBSD, everything is more correctly arranged: there is no difference between / dev / urandom and / dev / random, they are one and the same. Only at boot / dev / random blocks once, until enough entropy has accumulated. After this, there are no more locks.
On Linux, everything is not as bad as it looks at first glance. In all distributions at the boot stage, a certain amount of random numbers is stored in the seed file, which is read the next time the system boots. But recording is done only after a sufficient amount of entropy is typed, since the script does not start immediately after pressing the power button. So you are responsible for accumulating entropy from a previous work session. Of course, this is not as good as if you allowed to write the starting number to the scripts that terminate the system. After all, it takes much longer to accumulate entropy. But you do not depend on the correctness of the completion of the system with the execution of the corresponding scripts (for example, you are not afraid of resets and system crashes). In addition, such a solution will not help you at the very first start of the machine.
At the same time, Linux introduced the new getrandom (2) system call, which originally appeared in OpenBSD as getentropy (2). It blocks until it accumulates a sufficient initial amount of entropy, and subsequently no longer blocks. True, this is not a character device, but a system call, so it is not so easy to access it from the terminal or scripting languages.
Another problem is with virtual machines. People like to clone them or return to previous states, and in these cases the seed-file will not help you. But this is not solved by using / dev / random, but by a very accurate choice of the starting number for each virtual machine after cloning, returning to the previous state, etc.
Tl; dr
Just use / dev / urandom.