Introduction to RapidMiner
- Tutorial
 At the moment, there are many companies that need analytics systems, but the high cost and excessive complexity of this software in most cases forces us to abandon the idea of building our own analytical system in favor of a simple, well-known Excel. Also, additional expenses for training employees, maintaining expensive storage systems, etc. And here Open Source solutions can come to the rescue - there are not so many of them, but there is very worthy software, one of which is RapidMiner. RapidMiner (hereinafter simply referred to as “the miner”) is a tool created for data mining, with the main idea that the miner (analyst) should not program when doing his job. Moreover, as you know, mining requires data,
At the moment, there are many companies that need analytics systems, but the high cost and excessive complexity of this software in most cases forces us to abandon the idea of building our own analytical system in favor of a simple, well-known Excel. Also, additional expenses for training employees, maintaining expensive storage systems, etc. And here Open Source solutions can come to the rescue - there are not so many of them, but there is very worthy software, one of which is RapidMiner. RapidMiner (hereinafter simply referred to as “the miner”) is a tool created for data mining, with the main idea that the miner (analyst) should not program when doing his job. Moreover, as you know, mining requires data,In addition to the miner itself, there is also the RapidMiner Server (previously called RapidAnalytics, up to version 6) which can be used as a repository for storing and executing miner processes (including on a schedule), “fumbling” connections to data sources between users, sending data from miner processes as a web service.
To our regret, with version 6, the creators of the miner decided to start making money on the sales of this software and changed the license from AGPL to Business Source. Nevertheless, version 5 of AGPL and we can use it freely and without restrictions. Therefore, it will be considered in the article. Also note that in the sixth version there are not many new operators and functions (perhaps the most interesting is cloud support), and for most tasks RapidMiner 5 Community is enough.
Installation
Not so long ago, the links to download RapidMiner 5 were removed from the official site, so we will collect RM from the source code that we take in the official project on the github.
To build RapidMiner from the repository, we need
- Installed Java and JDK
- Apache ant
- Git client
 Let's go to the console, go to the directory where we would like to put the miner, clone the repository
Let's go to the console, go to the directory where we would like to put the miner, clone the repositorygit clone https://github.com/rapidminer/rapidminer-5.gitthe next step we will collect the project
ant build
ant release.makePlatformIndependentnow run the miner
.\scripts\RapidMinerGUI.batfor Linux, respectively
./scripts/RapidMinerGUI.shA window will open before you as in the picture on the right. Click on New Process and move on.
Basic concepts
Before we look at the basic principles of working with RapidMiner using an example, we will make a small introduction to its basic concepts.
Process
The set of operators interconnected in a given order to perform the required task of data analysis / processing.
Operator
 The logical unit of the process. The operator performs some actions on the data, it has an input / output (the so-called "ports"), data comes in to the input, data processed by the operator goes to the output. Thus, we can do data processing chains, for example, consider customer transactions from the database, find the largest ones, convert to dollars and give the result. At the same time, you can parallelize the chains - for example, in one we read transactions from different databases, and in the other we look for customer data, then we combine and get the result (it is also possible to execute them in parallel in time!).
The logical unit of the process. The operator performs some actions on the data, it has an input / output (the so-called "ports"), data comes in to the input, data processed by the operator goes to the output. Thus, we can do data processing chains, for example, consider customer transactions from the database, find the largest ones, convert to dollars and give the result. At the same time, you can parallelize the chains - for example, in one we read transactions from different databases, and in the other we look for customer data, then we combine and get the result (it is also possible to execute them in parallel in time!). In the program interface, the Operators tab corresponds to the operators tab - where in the hierarchy they are grouped by functional feature. To use the operator, you must click on it and transfer it to the workspace of the process.
Repository
 Storage space for RM processes. It can be local as well as remote (RapidMiner Server), for which it is possible to execute processes on the server side, multi-user access to database processes / connections, scheduled launch of processes, or data transfer as a web service.
Storage space for RM processes. It can be local as well as remote (RapidMiner Server), for which it is possible to execute processes on the server side, multi-user access to database processes / connections, scheduled launch of processes, or data transfer as a web service. In the Repositories contribution to RM, only Samples, DB, and Local Repository can be seen here. The first, as is already clear from the name, is a set of processes - examples, DB - current database connections available in the miner (defined through Tools -> Manage Database Connections) and Local Repository, a place to store your own processes on the computer.
Process context
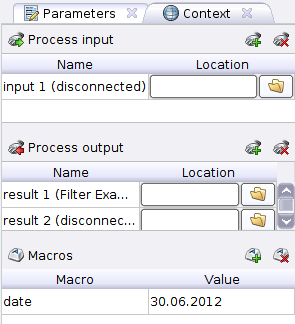
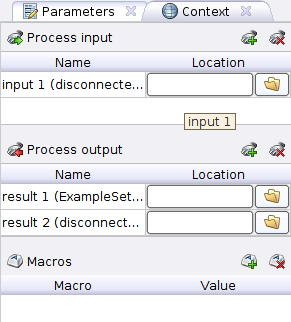 Context corresponds to the Context tab where we can see three sections:
Context corresponds to the Context tab where we can see three sections:- Process input - data transmitted to the input of the process. Here you can specify the path to the data inside the repository.
- Process output - this shows the path in the repository where the result of the process will be saved.
- Macros is a global variable available in the process from anywhere. It can take as value only strings or numbers.
Note that Process input and Process output are indicated by circles in the process along the process border with the inscriptions inp and res . To use the data from the input or save it, you need to connect the corresponding circle with the input / output of the operators.
The best training is practice. Let's make a small process on the basis of which we will see the basic principles of working with the miner.
Small task
You are the director of a small company that creates websites, industrial design, etc. Quite often, due to the large number of orders and the lack of employees, you hire freelancers from different countries (as clients from all over the world) and regularly enter information on the work done in an Excel plate indicating the name of the contractor, type of work, date of payment, amount and currency of payment . At some point, you wanted to get the amount of costs, in rubles (per CB rate), which you incurred by type of work for a specific date (more interesting cases are a breakdown by months, the employees are left to do their own experiments).
 The first thing we will do is save our excel file in CSV format and open it for reading in RapidMiner. To do this, take the Read CSV operator(Import -> Data -> Read CSV) and drag it into the workspace of the process. Next, click on it and see the operator settings on the right. We’ll click on the open daddy’s icon
The first thing we will do is save our excel file in CSV format and open it for reading in RapidMiner. To do this, take the Read CSV operator(Import -> Data -> Read CSV) and drag it into the workspace of the process. Next, click on it and see the operator settings on the right. We’ll click on the open daddy’s icon  , in the dialog box, select the file we need (the CSV used in the example can be downloaded from the link ).
, in the dialog box, select the file we need (the CSV used in the example can be downloaded from the link ). Pay attention to the pressed button
 - expert mode. It provides additional options for operators, which are usually needed almost always and marked in italics.
- expert mode. It provides additional options for operators, which are usually needed almost always and marked in italics. Set the parameters as in the picture on the right and click on the Edit list to the right of the data set meta data information below. We expose everything as in the picture below
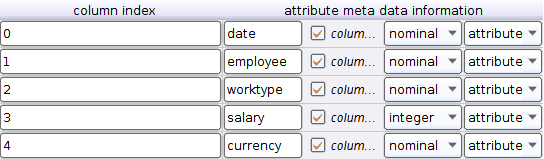
As you might guess here we put the names of the columns, a check mark is placed to exclude or include the column from the parsing result, type and role. Roles other than attribute may be needed in mining, in the usual case, they are usually not required.
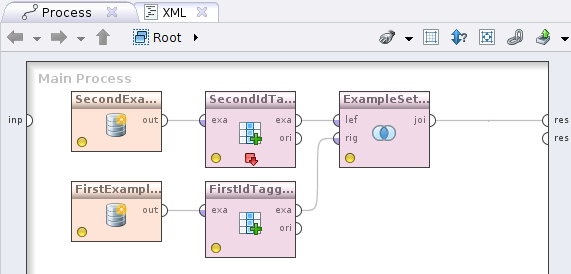
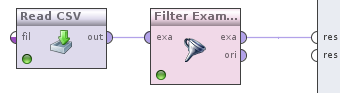
Click Apply and go to the next step. Add the Filter examples operator (Data Transformation -> Filtering), connect its input to the Read CSV output, and the output to the process output with a circle and the inscription res . You will get this picture
 Using the added operator, we select records only for the specified date, which we declare as a process macro. We go to the Context tab of the process, there we find the Macros section and click on
Using the added operator, we select records only for the specified date, which we declare as a process macro. We go to the Context tab of the process, there we find the Macros section and click on  . In the Macro column we write date, and in Value the desired date, let it be 06/30/2012.
. In the Macro column we write date, and in Value the desired date, let it be 06/30/2012. So the Context tab at this step will look like the image on the right. We defined the macro (recall, i.e., a global variable) and now use it to filter records by date from our CSVshnichka. Click on the Filter Examples operator, select in the condition class attribute_value_filter and in the parameter stringwrite: date =% {date}. On the left we indicated the name of the column by which the filtering takes place, in the center the operation of checking for equality and on the right taking the value from the macro.
Let's see what happened. We click on the button to start the process
 and the miner switching to the Result perspective (if this did not happen, click on
and the miner switching to the Result perspective (if this did not happen, click on  ) will display the filtered data for July 30, 2012.
) will display the filtered data for July 30, 2012.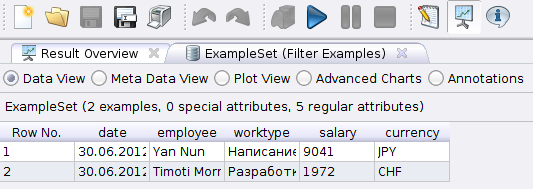
The first result was obtained, but we would like to see the costs in rubles at the rate of the Central Bank of the Russian Federation. Switch to Design Perspective by clicking on
 and add the Open file operator (Utility -> Files -> Open file). Click on it and set the following settings
and add the Open file operator (Utility -> Files -> Open file). Click on it and set the following settings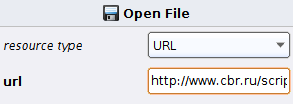
Where url: http://www.cbr.ru/scripts/XML_daily.asp?date_req=%{date}
Note that we substituted the macro in the operator parameter.
We will get the data, but something must convert it to an ExampleSet - i.e. table with data. In the first case, Read CSV performed this role , but now, as it’s not hard to guess, we will use Read XML (Import -> Data -> Read XML). Pull the operator, connect its input to the output of the Open file operator and make the following settings (if you are having difficulty with xpath, use the import wizard by clicking on the Import configuration wizard).
 Please note that the checkbox is checked parse numbersand a comma is set between the integer and fractional part.
Please note that the checkbox is checked parse numbersand a comma is set between the integer and fractional part. It is necessary to determine what attributes RapidMiner will take for the ExampleSet . Click on Edit enumeration to the right of xpath for attributes, add two entries
Value [1] / text () - cost in rubles of a currency unit
CharCode [1] / text () - letter currency code
Now we need to set the value types for the attributes. To do this, click on the Edit list to the right of the data set meta datainformation and set it as in the picture below

At this stage, we have a process that you should look like this
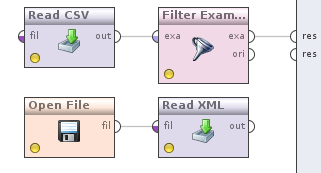
It's time to convert currencies into date-filtered data. For this, as you might guess, we will need to somehow combine quotes and data. The Join operator (Data Transformation -> Set Operations -> Join) will help us with this . Now do the following. We take the output of the Filter examples operator, which is currently connected with the output of the process and connect it with the Join operator , we do the same with the Read XML operator .
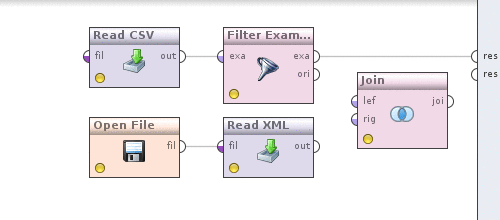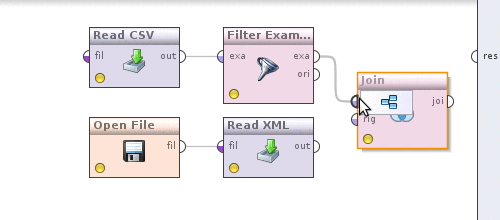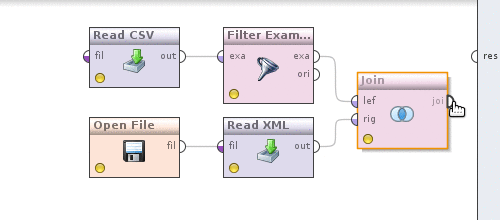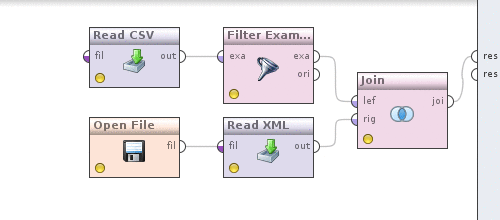
Now click on the Join operator and determine how the data will be combined. Uncheck the use id attribute as key , since we are combining in the currency field , a new key attributes parameter will appear, click on the Edit list to the left of it , in the Add entry dialog and write in both fields - currency . Save changes. We can see what happened, similar to how it was done above by clicking on the button
. The result will be like this
We are getting closer to our cherished goal - to find out how much we spent in rubles on our tasks. There was the last touch, actually the conversion itself. Add the Generate Attributes operator (Data Transformation -> Attribute Set Reduction and Transformation -> Generation ) to the process and connect its input to the output of the Join operator , and the first output of which is written exp (abbreviated ExampleSet ) to the output of the process. As it is clear from the name of the operator, his task is to add a new attribute. To do this, click on the operator and on the right in its settings on the Edit list , the button opposite the function descriptions . Let's name the attribute and how to read it.

Save changes and execute the process, our result

Hurrah! Here it is the treasured figure of costs in rubles that we incurred at the Central Bank rate on the payment date. You can develop this task very far, for example, draw information for a month, grouped by type of work, artist or date. In general, the scope of imagination.