SpecFlow and Alternative Testing Approach
 Testing with SpecFlow has firmly entered my life, into the list of necessary technologies for a “good project”. Moreover, despite SpecFlow's focus on behavior tests, I came to the conclusion that integration and even unit tests can benefit from this approach. Of course, people from BA and QA will no longer participate in writing such tests, but only the developers themselves. Of course, for small tests this introduces a considerable overhead. But how much more pleasant it is to read the human description of the test than the bare code.
Testing with SpecFlow has firmly entered my life, into the list of necessary technologies for a “good project”. Moreover, despite SpecFlow's focus on behavior tests, I came to the conclusion that integration and even unit tests can benefit from this approach. Of course, people from BA and QA will no longer participate in writing such tests, but only the developers themselves. Of course, for small tests this introduces a considerable overhead. But how much more pleasant it is to read the human description of the test than the bare code. As an example, I’ll give a test that has been redesigned from the usual type of tests in MSTest to a test in SpecFlow
source test
[TestMethod]
public void CreatePluralName_SucceedsOnSamples()
{
// setup
var target = new NameCreator();
var pluralSamples = new Dictionary
{
{ "ballista", "ballistae" },
{ "class", "classes"},
{ "box", "boxes" },
{ "byte", "bytes" },
{ "bolt", "bolts" },
{ "fish", "fishes" },
{ "guy", "guys" },
{ "ply", "plies" }
};
foreach (var sample in pluralSamples)
{
// act
var result = target.CreatePluralName(sample.Key);
// verify
Assert.AreEqual(sample.Value, result);
}
}
test in SpecFlow
Feature: PluralNameCreation
In order to assign names to Collection type of Navigation Properties
I want to convert a singular name to a plural name
@PluralName
Scenario Outline: Create a plural name
Given I have a 'Name' defined as ''
When I convert 'Name' to plural 'Result'
Then 'Result' should be equal to ''
Examples:
| name | result |
| ballista | ballistae |
| class | classes |
| box | boxes |
| byte | bytes |
| bolt | bolts |
| fish | fishes |
| guy | guys |
| ply | plies |
Classic approach
The example above does not apply to the alternative approach that I want to talk about in this article; it refers to the classical one. In this very classical approach, “input” data for the test is specially created in the test itself. This phrase can already serve as a hint, what does “alternativeness” consist of.
Another, slightly more complex example of the classic creation of data for a test, with which you can then compare the alternative:
Given that I have a insurance created in year 2006
And insurance has an assignment with type 'Dependent' and over 70 people covered
The following lines with code correspond to such lines, which I will call steps below:
insurance = new Insurance { Created = new DateTime(2006, 1, 2), Assignments = new List() };
insurance.Assignments.Add(new Assignment { Type = assignmentType, HeadCount = headCount + 1 });
Also, in the definitions of test steps, there is a code that allows you to transfer these objects between steps, but for brevity, this code was omitted.
Alternative
I want to mention right away that this approach was found and applied not by me, but by my colleague. On the hub and on the github, he is registered as a gerichhome . I undertook to describe and publish it. Well, maybe, according to the habr tradition, a comment appears, more useful than the article, it turns out that it was not in vain that he wrote and wasted time.
In some cases, as in the case of our project, a considerable amount of data is needed to display the portal page. And for testing a specific feature, only a small portion is needed. And, so that the rest of the page does not fall from the lack of data, you will have to write a considerable amount of code. And, even worse, you will likely have to write some number of SpecFlow steps. Thus, it turns out what you want, if you don’t want, but you have to test the whole page, as it were, and not the part necessary at the moment.
And in order to get around this, you can not create data, but search among the available ones. The data can be either in the test database, or in the mock files collected and serialized on a slice of some API. Of course, this approach is more suitable for the case when we already have a lot of functionality, at least the part that will allow us to manipulate this data. So that if there is no necessary data set for the test, you could first go through the test script with your hands, make a data cast, and then automate it. It is convenient to use this approach when there is a desire and / or need to cover the existing code with tests, then refactor / rewrite / expand and not be afraid that the functionality will break.
As before, the test requires an Insurance object, created in 2006 and having an Assignment with the Dependent type and a covered number of people over seventy. Any of the insurances stored in the database contains many other entities, in our project the model occupied more than 20 tables. As part of the demonstration, I did not use the full model; my simplified model includes only three entities.
In order to find the right insurance, you need to somehow determine the source in the form of IEnumerable
insurances = insurances.Where(x => x.Created.Year == year);
insurances = insurances.Where(x => x.Assignments.Any(y => y.Type == assignmentType && y.HeadCount > headCount));
Next, in the next steps, you need to open the portal, passing it the ID of the first insurance found in the HTTP request line, and actually test the necessary functionality. The specifics of these actions, of course, far beyond the scope of this topic,
Search algorithm
So, insurance was found, we opened the portal, checked that the name of the insurance is displayed in the desired section on the UI, now we need to check that the other section displays the number of depenants we need. And here the question arises, how in this step to find out exactly which Assignment allowed our insurance to pass under this condition? Which of, for example, five should be taken to compare its HeadCount with the number on the UI?
To do this, you would have to repeat this condition in the “Then” step, and code duplication is obviously bad. In addition, duplication of conditions will also have to be in the steps of SpecFlow, which is completely unacceptable.
Lyrical digression - we already had something similar on one of the projects, there was a sql query (for simplicity let it come from configs), which is looking for people by returning an SSN list. According to the scenario, these people had to have a child over 18 years old. And business people discussed for a long time, almost swearing, they could not understand why we could not decompose this request in order to find for a particular person those children who met the condition. They could not understand why we needed a second request. And since there is an idea of a brighter future, in which BA will write the test text, explaining why duplication is necessary in steps is much more difficult than eliminating this duplication, and this is the first task that is solved by the search algorithm.
In addition, in the normal search described in the previous paragraph, the second step cannot be divided into two steps of SpecFlow. This is the second problem solved by the algorithm. We will continue to discuss precisely this algorithm and its implementation.
The algorithm is schematically presented in the following picture:
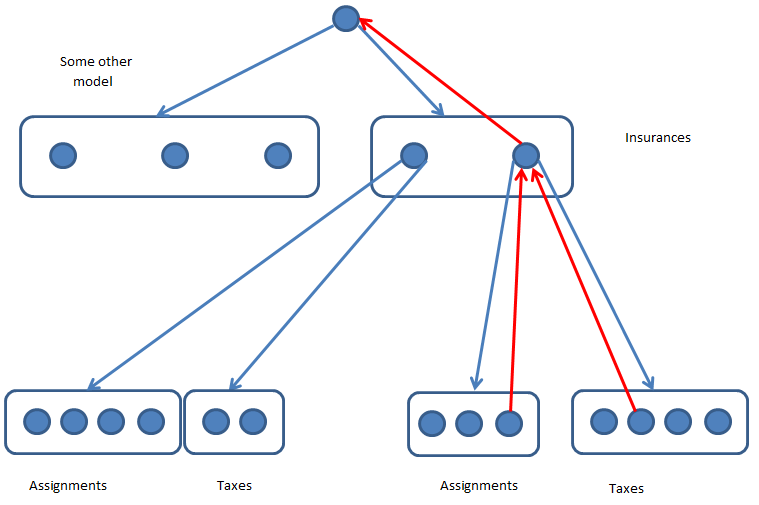
Search works quite simply. The original collection of root entities, in this case, insurance, is represented as IEnumerable
Child collections may also have conditions, the simplest of which is Exists. With such a condition, a collection will be considered valid if it has at least one element that satisfies its own conditions.
Own conditions, they are filters, are lambdas like Func
The picture shows the case where two insurances were found that fit all conditions, the first has a certain number of Assignment objects, of which are suitable for conditions 4, and also a number of Tax objects, of which two came up. Also for the second insurance there were 3 suitable Assignment and 4 Tax.
And, although this seems fairly obvious, it is worth noting that, in addition to insurances that did not fit under their own conditions, the list also did not include those insurances that did not find suitable Assignment objects or did not find suitable Tax objects.
The red arrows indicate the tree of interactions of specific elements. A specific Assignment element has only one connection to the top, it only “knows” about the particular Insurance element that generated it, and “does not know” about the Assignments collection in which it is located, and, especially, about the Insurances collection, for the element collections of parent elements may exist.
From here on we go the description and examples of using the implementation that I developed and published in NuGet (link at the end). A colleague created his own implementation of the search algorithm, which differs mainly in that it pulls the registration network into a chain, that is, a tree with a single branch. Its implementation has some of its features, which I do not have and its own shortcomings. Also, its implementation has some unnecessary dependencies, which slightly interfere with making a decision in a separate module. In addition, roofing felts for political reasons, roofing felts for personal reasons, he is not particularly keen on publishing his decisions, which would make it somewhat more difficult to use him in other projects. I had free time and a desire to implement some interesting algorithm. With which I went to write this article.
Registration of entities and filters
To achieve maximum granularity, the steps are broken as follows.
Given insurance A is taken from insurancesSource #1
And insurance A is created in year 2007 #2
And for insurance A exists an assignment A #3
And assignment A has type 'Dependent' #4
And assignment A has over 70 people covered #5
Such granularity may of course look somewhat redundant, but on the other hand, it allows you to achieve a very high level of reuse. When writing tests for the search algorithm, having 5-6 written tests, all of the following tests for a good three-quarters consisted of reused steps.
To register such sources and filters, use the following syntax
context.Register()
.Items(key, () => InsurancesSource.Insurances); #1
context.Register()
.For(key)
.IsTrue(insurance => insurance.Created.Year == year); #2
context.Register()
.For(insuranceKey)
.Exists(assignmentKey, insurance => insurance.Assignments); #3
context.Register()
.For(key)
.IsTrue(assignment => assignment.Type == type); #4
context.Register()
.For(key)
.IsTrue(assignment => assignment.HeadCount >= headCount); #5
The context used here is (TestingContext context) injected into classes containing definitions. All lines in the SpecFlow text are labeled with numbers only to indicate compliance with the definitions; the order of these lines can be any. This can be useful when using the “Background” feature. This freedom of registration is achieved due to the fact that the provider tree is built not during the registration itself, but at the first receipt of the result.
Retrieving Search Results
var insurance = context.Value(insuranceKey);
var insurances = context.All(insuranceKey);
var assignments = context.All(assignmentKey);
The first line returns the first policy that matches all conditions, i.e. created in 2007, and has at least one Assignment of the Dependent type in which there are 70 people.
The second line returns all policies that meet these conditions.
The third line returns all matching Assignment objects from matching policies. That is, the result does not contain suitable Coverage from inappropriate policies.
The "All" method at the same time returns IEnumerable
var insurances = context.All(insuranceKey);
var firstPolicyCoverages = insurances.First().Get(assignmentKey);
It is important to mention here that, for any two pairs T1-key1 and T2-key2, the following condition is true - If from the context T1-key1, let's say this is a variable
IResolutionContext c1 IEnumerable> cs2 = c1.Get(key2) cs2.All(x => x.Get(key1).Contains(c1)) == true In addition, between c1 and cs2 elements all the conditions indicated in the combined filters will be fulfilled.
Combined Filters
In some cases, it is necessary to compare the fields of two entities. An example of such a filter:
And assignment A covers less people than maximum dependents specified in insurance A
The condition, of course, is unrealistic, as are some others. I hope this does not bother anyone, an example is an example.
The definition of such a step:
context
.For(assignmentKey)
.For(insuranceKey)
.IsTrue((assignment, insurance) => assignment.HeadCount < insurance.MaximumDependents);
The filter is assigned to the entity farthest from the root of the tree, in this case it is Assignment, and during execution it searches for insurance by going up the red arrow (in the first figure).
If two entities of the same type, with different keys, participate in the filter, then an inequality filter is automatically applied between them.
that is, in the case of .For
I limited myself to the fact that you can use two entities in the filter, since most likely a condition using 3 entities can be broken into pieces. There is no technical limitation, I can add a “triple” filter at will.
Filters on the collection
Several filters for the collection have already been laid, and one of them - Exists, has already been used previously. There are also DoesNotExist and Each filters.
They literally mean the following - the parent entity, in this case insurance, is considered eligible, if there is at least one child entity - Assignment eligible. This is for Exists. For DoesNotExist - if there is no Assignment matching the conditions, and Each - if all the Assignment of this insurance matches the conditions.
In addition, you can set your own filters for collections. For instance:
context.ForAll(key)
.IsTrue(assignments => assignments.Sum(x => x.HeadCount) > 0);
Of course, only suitable Assignments fall into the filter for collections, that is, those that first went through their own filters.
The second example involves comparing two collections.
SpecFlow text for example:
And average payment per person in assignments B, specified in taxes B is over 10$
and corresponding definition:
context
.ForAll(assignmentKey)
.ForAll(taxKey)
.IsTrue((assignments, taxes) => taxes.Sum(x => x.Amount) / assignments.Sum(x => x.HeadCount) > average);
Another testing technique
The trick is to first prepare a fully-filled object, check that the page (meaning that we are testing a web application) fulfills the happy-path script successfully, and then use the same object in each subsequent test to break something one at a time and Check that the page issues an appropriate warning to the user. For example, a user who falls under happy-path must have a password, mail, address, access rights, etc. And for bad tests, the same user is taken and the password is broken, for the next test mail is nullified, etc.
The same technique can be used when searching for data:
Background:
Given insurance B is taken from insurancesSource
And for insurance B exists an assignment B
And for insurance B exists a tax B
Scenario: No assignment with needed count and type
Given there is no suitable assignment B
Scenario: No tax with needed amount and type
Given there is no suitable tax B
The text I cited is not complete, only significant lines. In the example, in the Background section, all registrations necessary for happy-path are specified, and in specific “bad” scenarios one of the filters is inverted. In the happy-path test, insurance will be found in which there is a suitable Assignment and a suitable Tax. For the first “bad” test, insurance will be found in which there is no suitable Assignment, for the second, respectively, insurance in which there is no suitable Tax. Such an inversion can be included as follows:
context.InvertCollectionValidity(key);
In addition, you can assign a certain key to any filter, then invert this filter by this key.
Failed Search Logging
In the case when many filters are specified, it is not immediately possible to understand why the search returns nothing. Of course, it is quite easy to deal with this by the dichotomy method, that is, comment out half of the filters and see what changes, then half from half, etc. However, for convenience, and to reduce time costs, it was decided to give the opportunity to print to the log the filter that disabled the last available entity. This means that if the first filter out half of the entities from the three filters, the second filter out the second half, and the matter did not even reach the third filter, then in this case the second specified filter will be printed. To do this, you need to subscribe to the OnSearchFailure event.
That's all. The project is available at github github.com/repinvv/TestingContext
The finished assembly can be taken at NuGet www.nuget.org/packages/TestingContext