Increase array efficiency
This article was prepared by Nikolai Vedyashkin, an expert at the Jet Infosystems Service Center.
Imagine a situation: we added a new instance of a database or a new backup task (RK) to the database server, connected an additional server to the disk array, and in all these cases we found a decrease in its performance. Then you can go in different ways.
For example, add a database server and transfer a database instance to it, add backup drives to speed up the RK, upgrade processors, etc. However, it is worth remembering that a simple increase in hardware capacity is the least profitable in terms of material and time costs. It is much more efficient to solve such problems at the level of the logic of IT solutions.
Problems with array performance are often associated with the fact that the initial configuration does not take into account its architecture, functioning principles, and existing limitations. For example, the Achilles heel of old-generation arrays - a relatively low throughput of internal buses - about 200 Mb / s. Not so long ago, one of the customers asked us to analyze the operation of its disk array and give recommendations for optimization. In fact, the array was not loaded, while its speed periodically left much to be desired. The analysis revealed the wrong configuration: in general, during the day, the internal disks were loaded approximately the same, but the load peaks were distributed unevenly across them. As a result, one of the internal tires was overloaded. That is, the array “skidded” due to exceeding the maximum allowable threshold for one component.
The error can also sneak up when connecting servers to the storage system. An example is the incorrect disk capacity configuration that is presented to hosts. The fact is that some of the modern arrays have restrictions on such a parameter as the command queue (Queue Depth, QD). It is worth a little deeper into the story. In the SCSI-I standard, the SCSI server driver had to wait for the execution of one command and only after that send the next one. From the SCSI-II standard and higher, the SCSI driver can send several commands (QD) to a SCSI disk simultaneously. The maximum number of parallel-serviced SCSI commands is one of the most important characteristics of a disk. The IOPS (Input Output Operation per Second) parameter shows how many requests (SCSI commands) per second the SCSI LUN can execute. It turns out
The situation is quite real in which the I / O characteristics on the server side are unacceptable, the response time to requests is very long, and the array is not loaded. The reason is - the command queue is configured incorrectly (higher than the permissible one) - the commands hang in the array buffer until their turn for execution approaches. On the server, large service time is registered.
If QD is significantly below the optimal value, performance will also be lame. With a wonderful response time and an unloaded array, the number of requests processed by it will be very small. The reason for this is a long wait in the queue before sending requests to the storage system.
What to do if the response time goes off scale and the array is not loaded? Or if you just want to squeeze a little more out of the array?
Can:
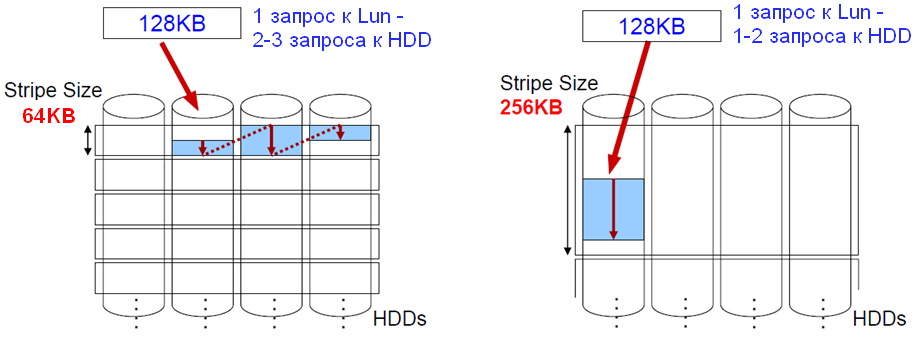
Fig. 1. Stripe Unit Size
An example from our experience: the server-array combination at the customer did not show the declared level of performance. As a result of the analysis, it turned out that the server was given a very large (several terabytes) LUN - the application was unsatisfactory, and the LUN itself was overloaded in a sequence of commands. We recommended splitting this LUN into several and distributing the types of load on different volumes. There were 4 instance databases on the server, as a result, one of them started working 6 times faster, the other 2 times.
IT specialists from customer companies do not always understand which type of RAID is best suited for a particular application load profile. Everyone knows that RAID 10 is reliable, resistant to the loss of multiple disks and shows good speed in random operations. It is not surprising that most often this particular, very expensive option is chosen. However, if the application load profile involves few random writes and many reads or sequential writes, it is best to use RAID 5. It can run 1.5 or 2 times faster on the same number of disks. One company asked us to improve disk I / O performance for one of its applications. The application created many read operations and a small number of write operations. RAID 10 was configured on the array, and statistics showed that almost half of the disks in the RAID group are idle. With the transition to RAID 5 from exactly the same number of physical disks, the application's work will be improved by more than 1.5 times.
We welcome your constructive comments.
Performance problems affect almost every company operating a computing complex. The examples given here are not the only ones. Many problems associated with the unsatisfactory operation of arrays can be avoided by considering its architecture and application load profile when configuring equipment. At the same time, the improvement of the computing complex should not be limited to any one of its components - a server, an array, software or a data transmission network. The best results can be achieved after analyzing the entire complex as a whole and changing the configuration of not only the array, but also the server and applications.
Imagine a situation: we added a new instance of a database or a new backup task (RK) to the database server, connected an additional server to the disk array, and in all these cases we found a decrease in its performance. Then you can go in different ways.
For example, add a database server and transfer a database instance to it, add backup drives to speed up the RK, upgrade processors, etc. However, it is worth remembering that a simple increase in hardware capacity is the least profitable in terms of material and time costs. It is much more efficient to solve such problems at the level of the logic of IT solutions.
Reasons for slipping
Problems with array performance are often associated with the fact that the initial configuration does not take into account its architecture, functioning principles, and existing limitations. For example, the Achilles heel of old-generation arrays - a relatively low throughput of internal buses - about 200 Mb / s. Not so long ago, one of the customers asked us to analyze the operation of its disk array and give recommendations for optimization. In fact, the array was not loaded, while its speed periodically left much to be desired. The analysis revealed the wrong configuration: in general, during the day, the internal disks were loaded approximately the same, but the load peaks were distributed unevenly across them. As a result, one of the internal tires was overloaded. That is, the array “skidded” due to exceeding the maximum allowable threshold for one component.
The error can also sneak up when connecting servers to the storage system. An example is the incorrect disk capacity configuration that is presented to hosts. The fact is that some of the modern arrays have restrictions on such a parameter as the command queue (Queue Depth, QD). It is worth a little deeper into the story. In the SCSI-I standard, the SCSI server driver had to wait for the execution of one command and only after that send the next one. From the SCSI-II standard and higher, the SCSI driver can send several commands (QD) to a SCSI disk simultaneously. The maximum number of parallel-serviced SCSI commands is one of the most important characteristics of a disk. The IOPS (Input Output Operation per Second) parameter shows how many requests (SCSI commands) per second the SCSI LUN can execute. It turns out
The situation is quite real in which the I / O characteristics on the server side are unacceptable, the response time to requests is very long, and the array is not loaded. The reason is - the command queue is configured incorrectly (higher than the permissible one) - the commands hang in the array buffer until their turn for execution approaches. On the server, large service time is registered.
If QD is significantly below the optimal value, performance will also be lame. With a wonderful response time and an unloaded array, the number of requests processed by it will be very small. The reason for this is a long wait in the queue before sending requests to the storage system.
Catch IOPS by the tail
What to do if the response time goes off scale and the array is not loaded? Or if you just want to squeeze a little more out of the array?
Can:
- look at the Queue Depth settings on the server and compare the maximum allowable queue of commands with the LUN array. Adjust settings;
- look at the statistics from the array. It is possible that a queue of commands to the LUN is accumulating on it;
- split one LUN into several and connect to the host in stripe or at least to concatenation, depending on the configuration. Concatenation is useful if the load is distributed across all LUNs.
- select the stripe unit size on the array and host so that a typical application operation loads as few physical disks in the array as possible.
Fig. 1. Stripe Unit Size
An example from our experience: the server-array combination at the customer did not show the declared level of performance. As a result of the analysis, it turned out that the server was given a very large (several terabytes) LUN - the application was unsatisfactory, and the LUN itself was overloaded in a sequence of commands. We recommended splitting this LUN into several and distributing the types of load on different volumes. There were 4 instance databases on the server, as a result, one of them started working 6 times faster, the other 2 times.
More doesn't mean better
IT specialists from customer companies do not always understand which type of RAID is best suited for a particular application load profile. Everyone knows that RAID 10 is reliable, resistant to the loss of multiple disks and shows good speed in random operations. It is not surprising that most often this particular, very expensive option is chosen. However, if the application load profile involves few random writes and many reads or sequential writes, it is best to use RAID 5. It can run 1.5 or 2 times faster on the same number of disks. One company asked us to improve disk I / O performance for one of its applications. The application created many read operations and a small number of write operations. RAID 10 was configured on the array, and statistics showed that almost half of the disks in the RAID group are idle. With the transition to RAID 5 from exactly the same number of physical disks, the application's work will be improved by more than 1.5 times.
We welcome your constructive comments.
Performance problems affect almost every company operating a computing complex. The examples given here are not the only ones. Many problems associated with the unsatisfactory operation of arrays can be avoided by considering its architecture and application load profile when configuring equipment. At the same time, the improvement of the computing complex should not be limited to any one of its components - a server, an array, software or a data transmission network. The best results can be achieved after analyzing the entire complex as a whole and changing the configuration of not only the array, but also the server and applications.