How to fix a bug in Node.js and inadvertently increase performance by 2 times
 It all started with the fact that I optimized return error HTTP 408 Request Timeout in the application server Impress , running on Node.js . As you know, the http.Server node has a timeout event that should be raised for every open socket if it hasn’t closed in the specified time. I want to clarify that not for each request i.e. not for every request event, whose function has two arguments (req, res), namely for each socket. A single socket can consistently receive many keep-alive requests.. If we set this event, through server.setTimeout (2 * 60 * 1000, function (socket) {...}) we must destroy the socket socket.destroy () ourselves. But if you do not install your handler, then http.Server has a built-in one that will destroy the socket in 2 minutes automatically. At this same timeout, you can give 408 error and consider the incident settled. If it weren’t for one thing ... I was surprised to find that the timeout event is fired for those sockets that are suspended both for those that have already received a response and for those that are closed by the client side, generally for all those that are in keep-alive mode. This strange behavior turned out to be quite complicated, and I will talk about it below. It would be possible to insert one check into the timeout event, but with my idealism I could not resist and got useful to fix the bug one level deeper. It turned out that in http. Server mode keep-alive is implemented not only not by RFC, but openly not added. Instead of a separate timeout for the connection and a separate keep-alive timeout, everything is on the same timeout, which is implemented on fast pseudo-timers (enroll / unenroll), but set to 2 minutes by default. It wouldn’t be so scary if browsers worked well with keep-alive and reused it effectively or closed unused connections.
It all started with the fact that I optimized return error HTTP 408 Request Timeout in the application server Impress , running on Node.js . As you know, the http.Server node has a timeout event that should be raised for every open socket if it hasn’t closed in the specified time. I want to clarify that not for each request i.e. not for every request event, whose function has two arguments (req, res), namely for each socket. A single socket can consistently receive many keep-alive requests.. If we set this event, through server.setTimeout (2 * 60 * 1000, function (socket) {...}) we must destroy the socket socket.destroy () ourselves. But if you do not install your handler, then http.Server has a built-in one that will destroy the socket in 2 minutes automatically. At this same timeout, you can give 408 error and consider the incident settled. If it weren’t for one thing ... I was surprised to find that the timeout event is fired for those sockets that are suspended both for those that have already received a response and for those that are closed by the client side, generally for all those that are in keep-alive mode. This strange behavior turned out to be quite complicated, and I will talk about it below. It would be possible to insert one check into the timeout event, but with my idealism I could not resist and got useful to fix the bug one level deeper. It turned out that in http. Server mode keep-alive is implemented not only not by RFC, but openly not added. Instead of a separate timeout for the connection and a separate keep-alive timeout, everything is on the same timeout, which is implemented on fast pseudo-timers (enroll / unenroll), but set to 2 minutes by default. It wouldn’t be so scary if browsers worked well with keep-alive and reused it effectively or closed unused connections.Results first
After 12 lines of changes, the timeout event started to fire only when the server did not respond to the client and the client waits for it. The connection timeout remained with the default value of 2 minutes, but http.Server.keepAliveTimeout appeared with the default value of 5 seconds (like Apache). Corrections repository: tshemsedinov / node (for node.js 0.12) and tshemsedinov / io.js (for io.js). Soon I will send pool requests to joyent / node and nodejs / node, respectively (the former io.js, but now it has already glued projects).
The essence of the correctionin that the connection timeout should work if the connection hangs, leaving the request unanswered, and if the socket is open, but all requests are answered, then you need to wait much less, making it possible to send another request in keep-alive mode.
One can already guess about the side effect, a lot of memory and socket descriptors have been freed up, which immediately caused in my current highly loaded projects an increase in overall performance by more than 2 times. And here I will show a small test with code, the results of which can be seen in the graphs below and giving an idea of what is happening.

The essence of the test: create 15 thousand HTTP / 1.1 connections (which are considered keep-alive by default, even without special headers) and check the intensity of creating and closing sockets and memory consumption. The test was run for 200 seconds, data was recorded every 10 seconds. The graphs on the left are Node.js 0.2.7 without corrections, and on the right are the patched and rebuilt Node.js. The blue line is the number of open sockets, and the red one is closed sockets. To do this, of course, I had to write all the sockets to an array, which did not completely free up memory. Therefore, there are two options for the client part of the test, with an array of sockets, and without it, to check the memory. As expected, sockets are freed up 2 times faster, which means that they do not occupy descriptors and do not load the TCP / IP stack of the operating system,
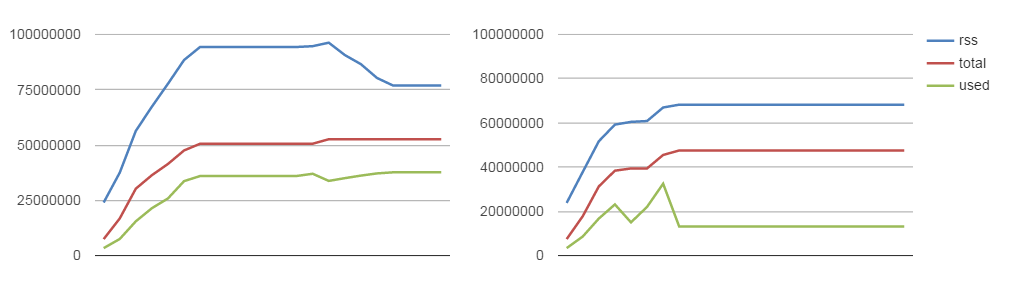
The blue line is RSS (resident set size) - how long does the total process take, the red one - heap total - the memory allocated for the application, the green one - heap used - the used memory. Naturally, all freed memory can be reused for other sockets, even faster than with the first allocation.
Test Code:
Client part of the test
var net = require('net');
var count = 0;
keepAliveConnect();
function keepAliveConnect() {
var c = net.connect({ port: 80, allowHalfOpen: true }, function() {
c.write('GET / HTTP/1.1\r\nHost: localhost\r\n\r\n');
if (count++ < 15000) keepAliveConnect();
});
}
Server side with socket counters
var http = require('http');
var pad = '';
for (var i = 0; i < 10; i++) pad += '- - - - - - - - - - - - - - - - - ';
var sockets = [];
var server = http.createServer(function (req, res) {
var socket = req.socket;
sockets.push(socket);
res.writeHead(200, {'Content-Type': 'text/plain'});
res.end(pad + 'Hello World\n');
});
setInterval(function() {
var destroyedSockets = 0;
for (var i = 0; i < sockets.length; i++) {
if (sockets[i].destroyed) destroyedSockets++;
}
var m = process.memoryUsage(),
a = [m.rss, m.heapTotal, m.heapUsed, sockets.length, destroyedSockets];
console.log(a.join(','));
}, 10000);
server.listen(80, '127.0.0.1');
Server side without socket counters
var http = require('http');
var pad = '';
for (var i = 0; i < 10; i++) pad += '- - - - - - - - - - - - - - - - - ';
var server = http.createServer(function (req, res) {
res.writeHead(200, {'Content-Type': 'text/plain'});
res.end(pad + 'Hello World\n');
});
setInterval(function() {
var m = process.memoryUsage();
console.log([m.rss, m.heapTotal, m.heapUsed].join(','));
}, 10000);
server.listen(80, '127.0.0.1');
Problem details
If the client side does not request keep-alive, then Node.js closes the socket immediately by calling res.end () and no resource leak occurs. Therefore, all the tests in which we massively do http.get ('/'). On ('error', function () {}) or curl http://domain.com/ or through ab (apache benchmark) show that all well. And browsers always want to keep-alive, which they do not work well, like a node. The keep-alive problem is that through it you can send several requests only sequentially, it does not have a batch mechanism that would mark which of the competitive requests each of the answers responds to. I agree, this is wildly inconvenient. In SPDY and HTTP / 2there is no such problem. When browsers load a page with many resources, they sometimes use keep-alive, but more often they send the correct headers, telling the server to keep open connections, and they themselves use it very little or even ignore it, guided by an incomprehensible logic to me. Here Firebug and DevTools show that requests are completed and sockets are hanging. Even if the page has already loaded completely, and several sockets have been created, they are not closed, and we need to make one unfortunate request to the API, my observations show that browsers always create a new connection, and the sockets keep holding them until the server will close. Such suspended sockets are not considered parallel requests, so they do not affect browser restrictions (as I understand them, they are marked as half-open, are not used and are excluded from the counter). This can be checked if you close the browser, then on the node server a whole bunch of sockets that do not have time to wait their 2 minutes timeout will immediately close.
The node has a timeout of 2 minutes, regardless of whether the response is sent to the client side or not. Lowering this timeout, for example to 5 seconds, is not an option, as a result, connections that objectively take more than 5 seconds will break. We need a separate timeout for keep-alive, the countdown of which does not begin immediately, but after the last activity on the socket, i.e. This is the real time waiting for the next request from the client.
In general, for the full implementation of keep-alive, you need to do much more, take the desired timeout time from the HTTP headers sent by the client, send the actual timeout time set in the response headers to the client, process the max and Keep-Alive Extensions parameter. But modern browsers do not use all these things, in any case, from the experiments I conducted, they ignored these HTTP headers. Therefore, I calmed down with small edits that gave great results.
Corrections in Node.js
At first I decided to fix the problem with extra timeouts in a simple way, preventing emit events: ae9a1a5 . But for this I had to familiarize myself with the code and I did not like the way it was written. In some places there are comments that one cannot write like that, that large closures need to be decomposed, to get rid of nesting of functions, but no one touches these libraries, because then you can’t collect the tests and you can ruin a lot of people all the dependent code. Okay, everything will not work, but the leak of sockets did not give me rest. And I decided to solve the problem by destroying the socket after on ServerResponse.prototype.detachSocket when one res.end () was already sent, but this broke a lot of useful keep-alive behavior : 9d9484b. After experimenting, reading the RFC and documentation for other servers, it became obvious that we needed to implement a keep-alive timeout, and that it was different from just a connection timeout.
Corrections:
- Added server.keepAliveTimeout parameter, which can be set manually /lib/_http_server.js#L259
- Renamed the prefinish event function to use it elsewhere /lib/_http_server.js#L455,L456
- I hung the finish event to catch the moment when everything is already answered. To no, I remove handlers from the EventEmitter hung on the socket's timeout event and broadcast the event that destroys the socket /lib/_http_server.js#L483,L491
- For the https server, add the keepAliveTimeout parameter, because it inherits everything else from the /lib/https.js#L51 prototype
For Impress Application Server, all these changes are implemented internally, in the form of a beautiful patch and the effect is available even without a patch on Node.js, in its source you can see how simple it is. In addition, on recent projects, we have achieved other, impressive results, for example, 10 million permanent connections on 4 servers combined in a cluster (2.5 million per server) based on the SSE protocol (Server-Sent Events), and now we are preparing to do same for web sockets. Implemented application balancing for the Impress cluster, linked the cluster nodes with their TCP-based protocol, instead of the previously used ZMQfrom which they received tangible acceleration. The results of this work are also going to be partially published in the following articles. Many people tell me that nobody needs this optimization and performance, everyone is indifferent. But, at least in four live high-loaded examples, for my customers from China and for the seventh sense interactive television format, I can observe a general increase in productivity from 2-3 times to 1 order, and this is already significant. To do this, I had to abandon the principle of middleware, and rewrite interprocess communication, and implement application balancing (hardware balancers can not cope), etc. This will be a separate article about the horrors of performance when using middleware: "What the node gave, then the middleware took." For which I have already prepared enough facts, statistics and examples,
Do you want everything right away, right now?
Then you need to test such a patch and not on the basis of your build, but to show its effect on the official version of Node.js 0.12.7. Now we’ll check what happens if we add an additional 7 lines of code to the request event. Sockets will close as needed and even an error with an extra timeout event also disappears, this is understandable. But with memory, the situation is certainly much better, but not as much as it was when rebuilding Node.js.
http.createServer(function (req, res) {
var socket = req.socket;
res.on('finish', function() {
socket.removeAllListeners('timeout');
socket.setTimeout(5000, function() {
socket.destroy();
});
});
res.writeHead(200, {'Content-Type': 'text/plain'});
res.end('Hello World\n');
});
Compare the results on the graphs: on the left is the initial state of Node.js 0.12.7, in the middle is the addition of 7 lines to the request and launched on the official 0.12.7, on the right is the patched Node.js from my repository. The reasons for this are clear, I did not clone 0.12.7, but a slightly newer version and made a start from it. Of course, all tests except the last were performed on my repository, with and without a patch. And I compared the last test with the official version 0.12.7, so that it was clear how this would affect your code now.

The version of V8 in my repository is the same as in 0.12.7, but it is obvious that optimizations happened in the node. If you wait quite a bit, you can use either the patch above or fixes will get into the node. The results of these two options are almost the same. In general, I’m going to continue to engage in experiments and optimization in this direction, and if you have ideas, please - do not hesitate to suggest and connect to bringing the code of the most critical built-in node libraries to a decent look. Believe me, there is a lot of work for a specialist of any level. In addition, studying the source code is the best way I know of developing the platform.
Update : I found another problem there with _last, no one calculated it. Now merged with neighboring edits, tested and posted a pool request andhttps://github.com/nodejs/node/pull/2534