Open webinar "How not to write in Python"
Hello! As part of our “Python Developer” course , we conducted another open lesson on “How not to write in Python”. The lesson was taught by Stanislav Stupnikov , a teacher and course maker , who has extensive experience in industrial and scientific development. Considered antipatterns programming, bad practice and other evil, which you need to know and which should be avoided in the process of writing code.
See the video and summary for details. Warning: some code samples are not recommended to run on your computer!
In the process of conducting an open lesson, the teacher showed slides generated from Jupyter Notebook.
So, let's begin!
So how should you not write in Python?
In order to facilitate the presentation of the material a list of techniques was prepared that should not be used in the programming process. Each example was accompanied by a clear sample code (available for free viewing in the video). Briefly describe the main anti-patterns:
There was a lot of interesting things, so it's better to watch the video, because retelling all the same kortkovat.
As always, we are waiting for questions, comments and suggestions here or at the bottom of the open door .
See the video and summary for details. Warning: some code samples are not recommended to run on your computer!
In the process of conducting an open lesson, the teacher showed slides generated from Jupyter Notebook.
So, let's begin!
So how should you not write in Python?
In order to facilitate the presentation of the material a list of techniques was prepared that should not be used in the programming process. Each example was accompanied by a clear sample code (available for free viewing in the video). Briefly describe the main anti-patterns:
- Diaper pattern. It was about the so-called “diaper” pattern, which usually means too broad try-except. For example, you call a function that is a wrapper to something, say, wraps the client for some kind of base. In a good case (the system is small) everything will be fine in 99% of cases, but if the system is large, then the probabilities of the problem are not multiplied in the best way. As a result, something constantly falls or breaks.
- Antiglobalism. Everyone knows that global variables are ineffective, except for some exceptional cases. It is much better to pass everything in the form of function attributes, etc., etc., achieving the desired results. However, some have a “great idea” - to use mutable objects. It consists in passing in functions not global variables, but changeable objects, then changing them inside and then not returning anything back. It's so cool!) In fact, a piece of a programming pattern from C, transferred to the world of Python.
- Stairway to Heaven. As you may have guessed, this is a “stairway to heaven”. Best of all, this problem is characterized by a simple picture:
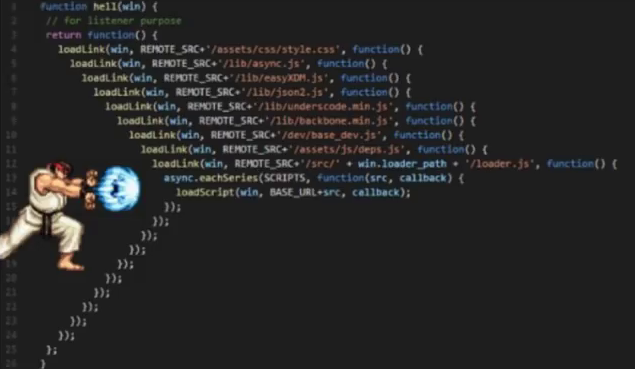
- Javatar Errors of this plan are often made by those programmers who for one reason or another have switched from Java to Python. Naturally, they come with their own charter, so they massively violate the rules of Python development. This is the emergence of mad indents, and CamelCase, and the desire to create more classes ... As a result, the structure of the code becomes more complicated. Where it would be possible to manage with a script of 300 lines, we see 10-20 files.
- Overengineering. Very often, the second iteration of a project is either never completed or is implemented in a too complex way. This happens if you want to rewrite an existing, but flawed code, making it perfect. At the same time, you forget that the best is the enemy of the good. As a result, the programmer falls into the standard reengineering trap, when the implementation becomes more expensive, cumbersome and cumbersome than is necessary to solve the tasks. And in fact: should family sedans reach speeds of up to 350 km / h, and smartphones, the fashion for which changes annually, must work for 100 years?
- Oneliner. Another actual problem is “one-liners”. We are talking about programmers who, with enviable zeal, are trying to shove everything into one line, there are five floors). Due to the excessive complexity of the code and the implementation of machine-regular expressions in Python, such scripts are sometimes stuck on parsing, so you have to use a special module to fix the problem.
- Copy-on-Read. This is not so much a mistake as a feature of Python programming. Many people know the Copy-On-Write approach. His idea is that when reading any data area, a shared copy is used, and when changed, a new copy is created, that is, it is about optimizing the performance processes. If we talk about Python, in some cases we do not just read an array of elements, but appeal to all underlying structures that are in memory, that is, we “overwrite” the memory by changing it. Thus, instead of Copy-On-Write, we get Copy-on-Read, when we seem to read the memory, but in fact we have to copy this information from the parent space to us as a child process, which makes us sad, because optimization does not work, and consumption grows.
- There is no fork. Fork - cloning the emergence of a new process. The problem is related to the specifics of working with Unix-systems and the non-obviousness of some data structures that are hidden in the implementation. A “forked” process is a process that is started at the moment when the thread captures the log in the queue in order to put something into it. That is, the new process that has arisen also wants to write something down, but for this it needs to capture the log from this queue itself, but it cannot do this, since the log is already captured. As a result, we get a lock. All this only once again confirms that you should not program without knowing the implementation features of the environment in which you work and the tools you use.
There was a lot of interesting things, so it's better to watch the video, because retelling all the same kortkovat.
As always, we are waiting for questions, comments and suggestions here or at the bottom of the open door .