How it works: the architecture of the tile backend of Sputnik cards
We, the team of Sputnik maps , are developing maps based on OpenStreetMap data. In this article, we will talk about the architecture of our solution for rendering tiles.

The map backend is written in Go using the Mapnik library , so we gave it the name Gopnik. Gopnik sources are available on Github .
The architecture of the openstreetmap.org service contains many components.
Neglecting the details, there are three main parts: the PostgreSQL database, an API for loading and editing data, and a map rendering system.
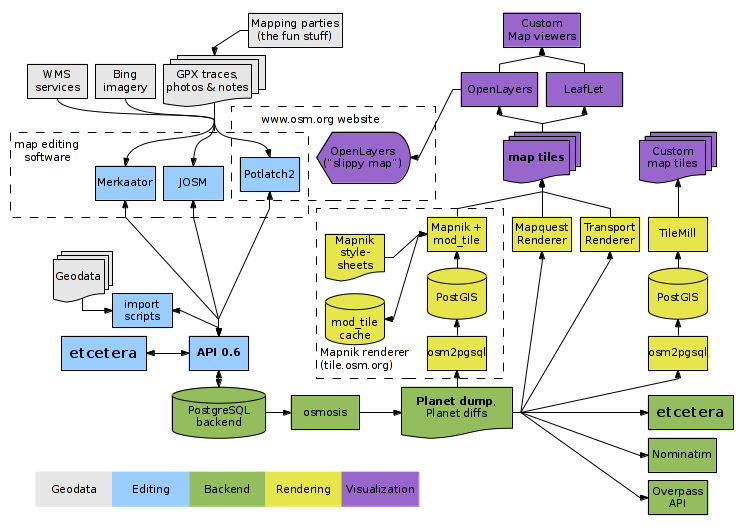
In order to create your own map based on OSM data, you will need to maintain your copy of the database and the rendering system.
We will touch on some general issues of creating on-line maps. Currently, there are several display technologies: from the option when the server gives the client a finished picture, to the option of visualizing the downloaded data on the client side. Tile cards are most popular at the moment. A tile is a small square image with a map section. The client downloads tiles from the server and then glues them into a single image.
This technology is easy to implement, minimally loads the client side. Of course, it is not without its drawbacks, but it seems to me that the use of such technology will be justified for a long time to come.
In the world of OpenStreetMap maps of tile stack rests on three pillars:
a database (often PostgreSQL);
rendering library (usually Mapnik);
Client javascript-library (in most cases - Leaflet).
To combine these technologies together, a number of things will be required: to supplement, if necessary, data, add icons, describe the drawing style, configure the generation and caching of tiles.
Developing our style, we wanted to achieve both completeness of data and ease of perception. The price for beauty has become technical complexity. The style turned out to be about twice as complex and heavy than the openstreetmap.org style.
As a result, updating the tiles takes a long time (about 5 days), you need to cache a significant amount of data (about 2TB). All this greatly complicates life.
Most often, the rendering stack is built on the basis of the Apache HTTP server with the mod_tile plugin and the backend directly involved in tile generation: Tirex or Renderd.
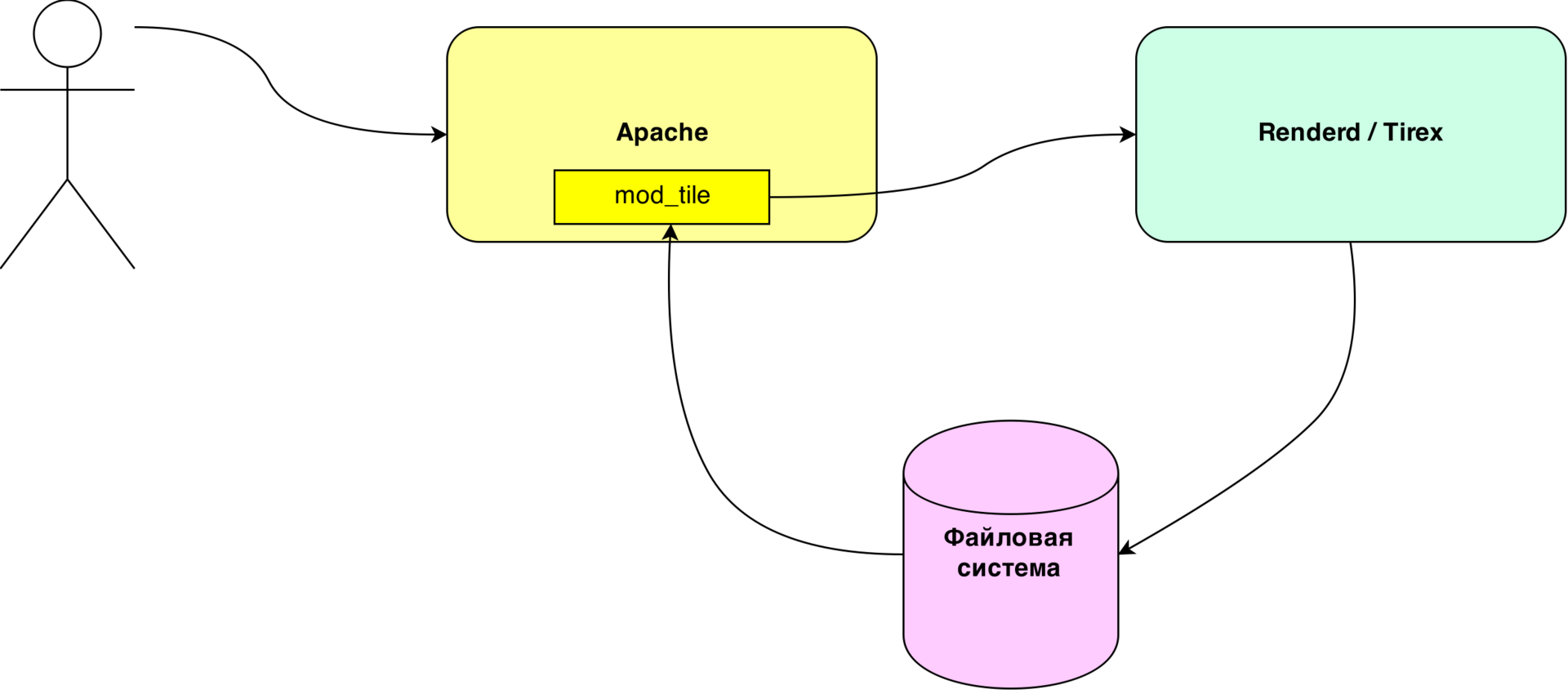
This scheme is time-tested, and the first version of maps.sputinik.ru worked just like that. However, it cannot be said that she completely suited us. The first thing we encountered was the difficulty of using cloud storage for the tile cache. mod_tile was developed with an eye on the file system, and it is completely impossible to use the stack with eventual consistency without serious revision. In addition, the renderd balancing scheme has certain shortcomings; it is difficult to use it in an environment of several data centers. And regular utilities are not particularly convenient.
We conducted an experiment: we sketched a prototype of a system that does exactly what we wanted from it. The prototype took root and was further developed. At its core, the system largely repeats the mod_tile architecture, with some extensions and additions. It is written in Go using the Mapnik library, for which it got its name - Gopnik.
Gopnik can be easily scaled according to an arbitrary number of nodes, can use various storage systems, supports extension using plugins.
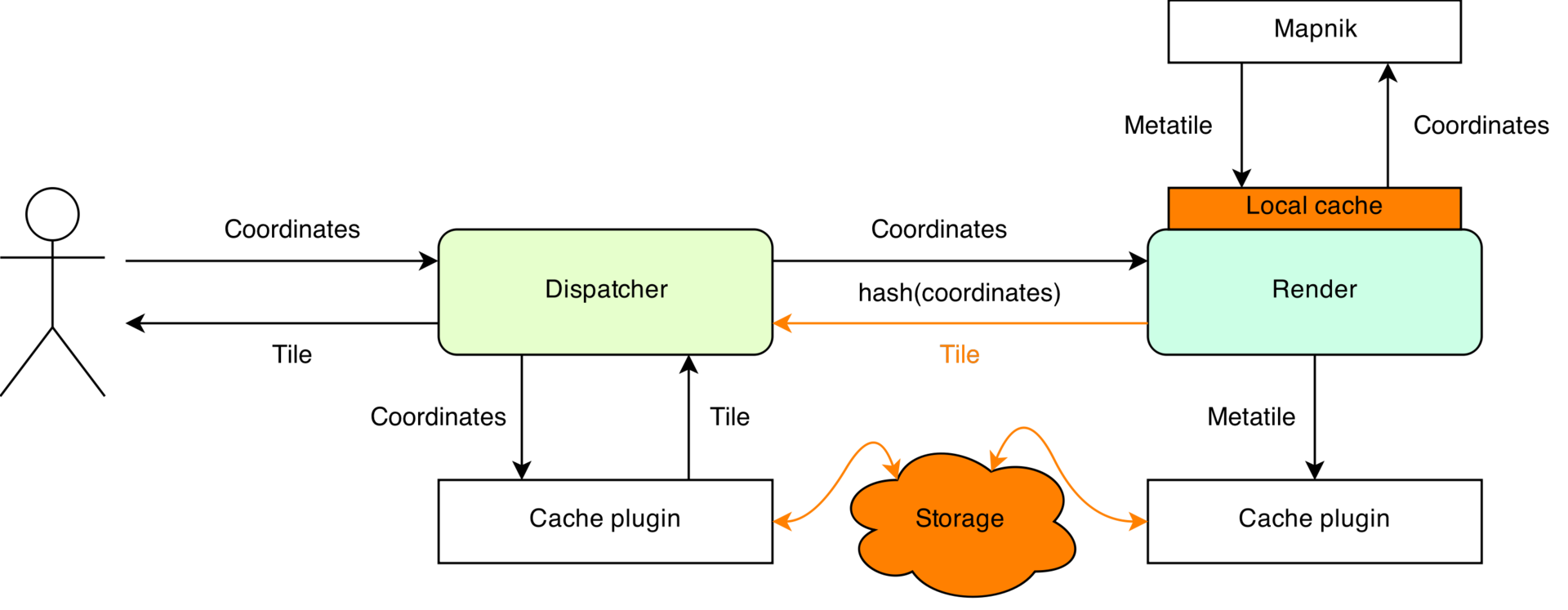
Gopnik consists of two components: dispatcher and render. Dispatcher receives requests from the user, checks for the presence of tiles in the cache, if necessary, selects a suitable node in the cluster using the hash coordinate function and sets him the task of generating tiles. Render provides direct rendering.
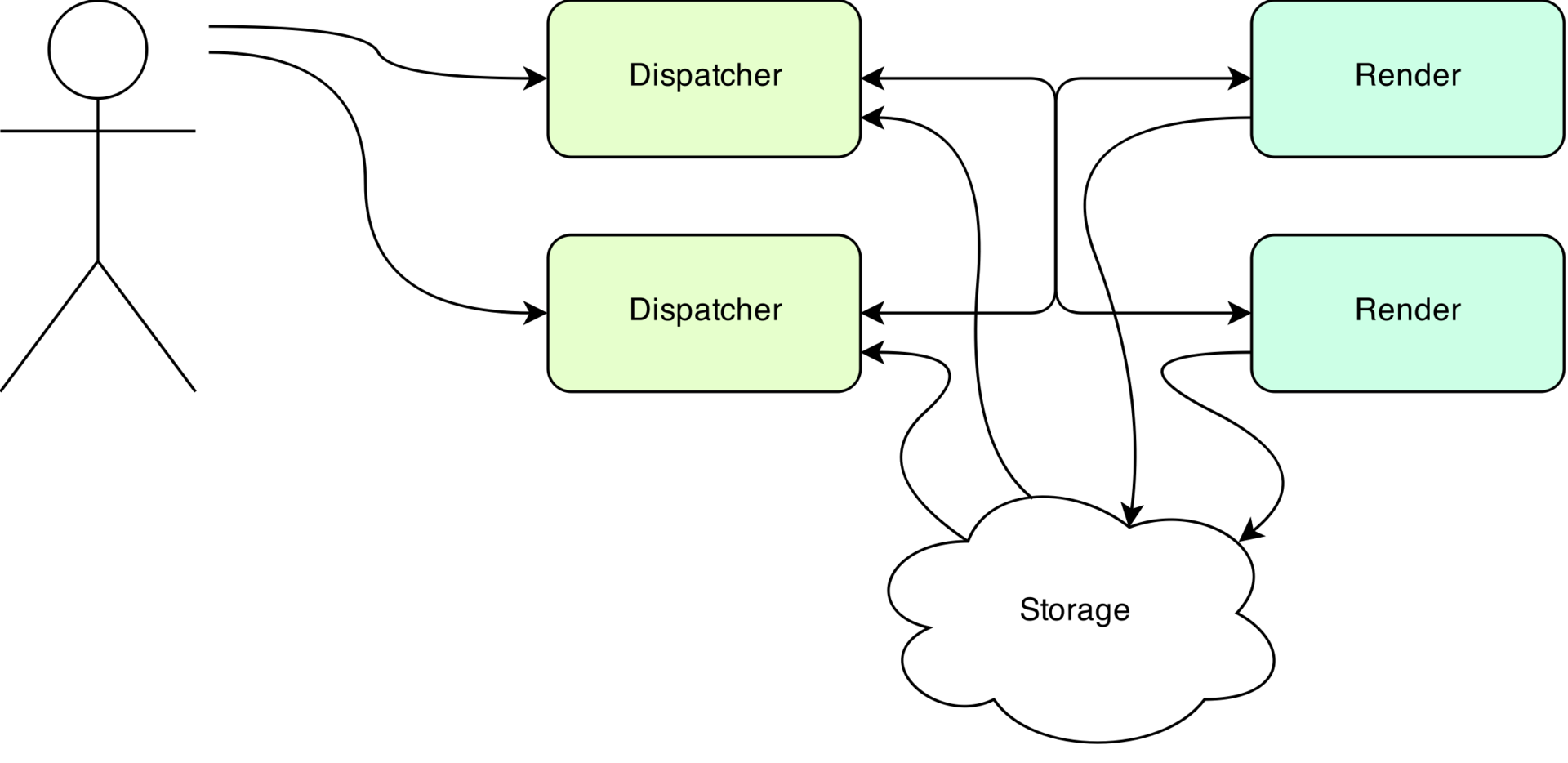
Special attention is paid to the problem of interacting with the repository. The catch is that users request tiles one at a time. The server, in order to save resources and to reduce problems with connecting individual pictures, immediately generates a large area of the card (usually 8x8 tiles + additional buffer), which is then cut into pieces. This area is called a metatile. Gopnik groups requests from a user by meta-files, the first time a request is made to a meta file that is not saved in the cache, rendering begins. All requests received later are added to the wait. When rendering is complete, tiles are returned for all pending requests and background caching begins. In addition, for some (custom) time, the rendering results are stored in the local cache of the node in case the client requests other tiles from the newly generated meta file,
However, on the fly you can only generate parts of the map where the amount of data is limited. In other cases, you have to prepare tiles in advance. There is a special set of utilities for this in Gopnik.
Using the importer utility, a generation plan is prepared. Prerender coordinates the process. The prerender slave node cluster directly renders.
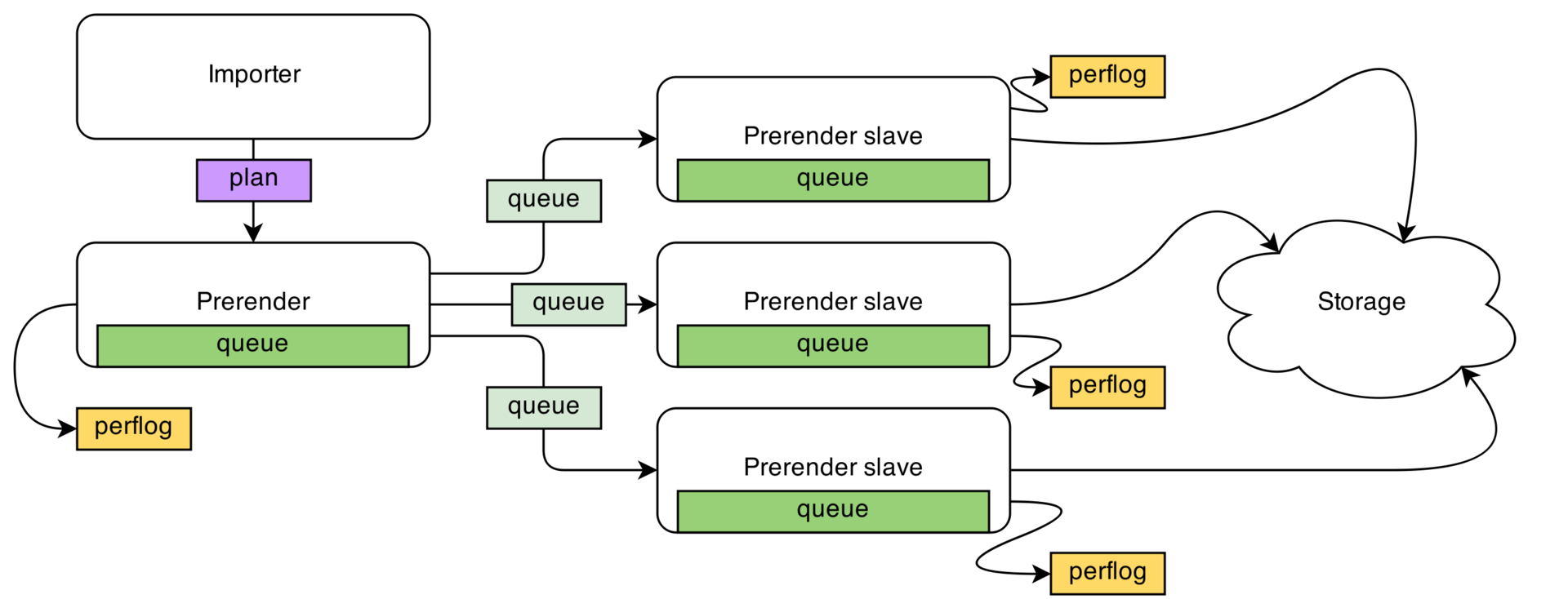
The system is distributed, resistant to network failures and slave node failure. The coordinator is the single point of failure, however, due to the rendering logs, the process can be continued from the point of failure. This solution allows you to avoid complex, fully distributed systems, while ensuring the proper level of fault tolerance.
Sources on Github
Documentation
Based onMaxim Dementiev's report at Highload ++ 2014
The map backend is written in Go using the Mapnik library , so we gave it the name Gopnik. Gopnik sources are available on Github .
The architecture of the openstreetmap.org service contains many components.
Neglecting the details, there are three main parts: the PostgreSQL database, an API for loading and editing data, and a map rendering system.
In order to create your own map based on OSM data, you will need to maintain your copy of the database and the rendering system.
We will touch on some general issues of creating on-line maps. Currently, there are several display technologies: from the option when the server gives the client a finished picture, to the option of visualizing the downloaded data on the client side. Tile cards are most popular at the moment. A tile is a small square image with a map section. The client downloads tiles from the server and then glues them into a single image.
This technology is easy to implement, minimally loads the client side. Of course, it is not without its drawbacks, but it seems to me that the use of such technology will be justified for a long time to come.
In the world of OpenStreetMap maps of tile stack rests on three pillars:
a database (often PostgreSQL);
rendering library (usually Mapnik);
Client javascript-library (in most cases - Leaflet).
To combine these technologies together, a number of things will be required: to supplement, if necessary, data, add icons, describe the drawing style, configure the generation and caching of tiles.
Developing our style, we wanted to achieve both completeness of data and ease of perception. The price for beauty has become technical complexity. The style turned out to be about twice as complex and heavy than the openstreetmap.org style.
As a result, updating the tiles takes a long time (about 5 days), you need to cache a significant amount of data (about 2TB). All this greatly complicates life.
Most often, the rendering stack is built on the basis of the Apache HTTP server with the mod_tile plugin and the backend directly involved in tile generation: Tirex or Renderd.
This scheme is time-tested, and the first version of maps.sputinik.ru worked just like that. However, it cannot be said that she completely suited us. The first thing we encountered was the difficulty of using cloud storage for the tile cache. mod_tile was developed with an eye on the file system, and it is completely impossible to use the stack with eventual consistency without serious revision. In addition, the renderd balancing scheme has certain shortcomings; it is difficult to use it in an environment of several data centers. And regular utilities are not particularly convenient.
We conducted an experiment: we sketched a prototype of a system that does exactly what we wanted from it. The prototype took root and was further developed. At its core, the system largely repeats the mod_tile architecture, with some extensions and additions. It is written in Go using the Mapnik library, for which it got its name - Gopnik.
Gopnik can be easily scaled according to an arbitrary number of nodes, can use various storage systems, supports extension using plugins.
Gopnik consists of two components: dispatcher and render. Dispatcher receives requests from the user, checks for the presence of tiles in the cache, if necessary, selects a suitable node in the cluster using the hash coordinate function and sets him the task of generating tiles. Render provides direct rendering.
Special attention is paid to the problem of interacting with the repository. The catch is that users request tiles one at a time. The server, in order to save resources and to reduce problems with connecting individual pictures, immediately generates a large area of the card (usually 8x8 tiles + additional buffer), which is then cut into pieces. This area is called a metatile. Gopnik groups requests from a user by meta-files, the first time a request is made to a meta file that is not saved in the cache, rendering begins. All requests received later are added to the wait. When rendering is complete, tiles are returned for all pending requests and background caching begins. In addition, for some (custom) time, the rendering results are stored in the local cache of the node in case the client requests other tiles from the newly generated meta file,
However, on the fly you can only generate parts of the map where the amount of data is limited. In other cases, you have to prepare tiles in advance. There is a special set of utilities for this in Gopnik.
Using the importer utility, a generation plan is prepared. Prerender coordinates the process. The prerender slave node cluster directly renders.
The system is distributed, resistant to network failures and slave node failure. The coordinator is the single point of failure, however, due to the rendering logs, the process can be continued from the point of failure. This solution allows you to avoid complex, fully distributed systems, while ensuring the proper level of fault tolerance.
Sources on Github
Documentation
Based onMaxim Dementiev's report at Highload ++ 2014