Fun math at Hearthstone
I'm a fan of the popular Hearthstone computer card game developed by Blizzard Entertainment. Once I asked myself: “Is it possible, based only on the rules that describe the dynamics of a player’s transitions between levels when losing / winning a game, to get statistics on the distribution of players according to their level?”
Despite the fact that the network has a huge number of sites and wiki dedicated to Hearthstone, a superficial search did not give results. It was a pity for a deep search, so I solved the problem “on my knee”. I believe this decision can become a topic for classes in the school math circle.
There are 25 levels in the Hearthstone Rating Tournament and a special Legend level. Levels consist of sublevels - the so-called "Stars", and at different levels the number of sublevels differs:
Thus, the line of levels in the rating (hereinafter referred to as the line) consists of 96 sublevels (including “Legend”):

Figure 1
A new player starts in the rating from level 25. For winning a game, the player receives a “star” (sometimes two), i.e. raises its sublevel by 1 (or 2, respectively).
There are 4 ranges on the line in which the rules for changing the player’s level when winning / losing a game differ:
Table 1
Obviously, the “Springboard” serves to attract new players, as there is only a reward on the “springboard”, but no punishment for defeat. In addition, it is clear that the population of the “springboard” exponentially quickly “dies out”, since the rules inevitably push the player from the “springboard” into the “Acceleration Racing” range. The probability of staying on the “springboard” after 18 games is ~ 29%, and after 27 games - less than 1.5%.
"Acceleration Race" helps players with high skill and good decks get to the "Normal Race" faster, where the real "ruby" begins. And finally, “Legend” is a pen for top players.
I wanted to find 2 dependencies:
The first thought was to write a program in JS, simulating a lot of players whose levels as a result of interaction change according to the above rules. After a short thought on the size of the required JS code, I decided that spreadsheets are great for solving this problem.
The idea of the solution is as follows:
Let some rectangular range of 96 * 1 size (for example, the range Source! $ C $ 3: $ C $ 98 in the attached files) represent the distribution of the number of players in the line. Then, using the rules from table 1, it is easy to obtain a distribution describing the state after each player has played one game. The rules in Table 1 are in the range Source! $ D3: $ D $ 98. If these rules are “dragged” by the required number of columns, then the resulting table will represent the change in the distribution of players by levels with “time”. Time in this case is in quotation marks because here it is measured in "played games."
I started with Open Office Calc, which is good for everyone, but the 3-D graphics out of the box in it look wretched (maybe I just don’t know how to cook them). As a result, the solution is implemented on MS Excel and lies here. The option for Open Office Calc in the same place is quite functional, except for the lack of 3-D graphs and the lack of interactivity in 2-D graphs.
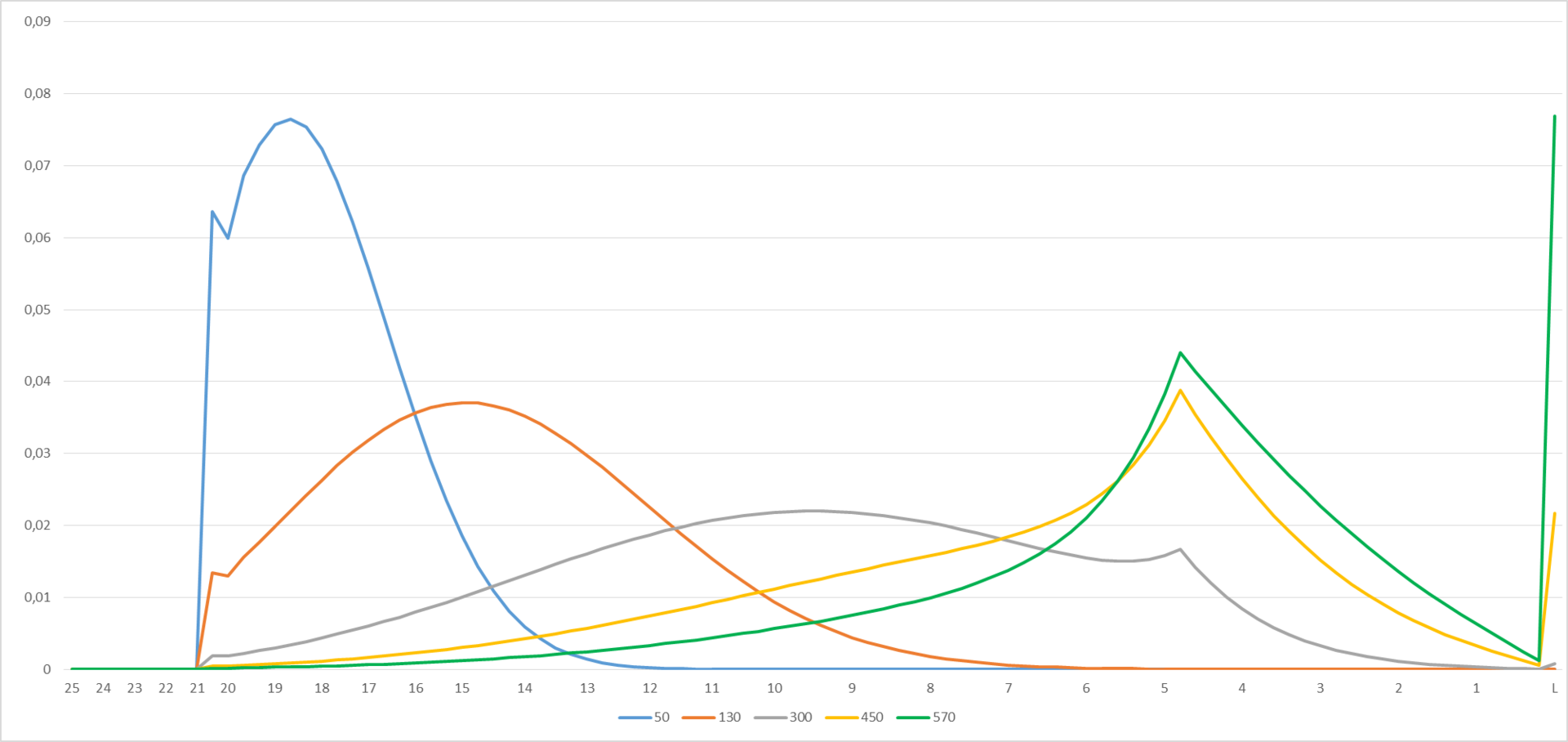
Figure 2
The graphs below describe the probability of getting one or another level for a player starting from level 25 and playing 50, 130, 300, 450 or 570 games, respectively. In Excel, the graph is interactive - you can play around with the numbers to the left of the diagram on the “Interface” tab, while the graphs (Figure 2) will change.
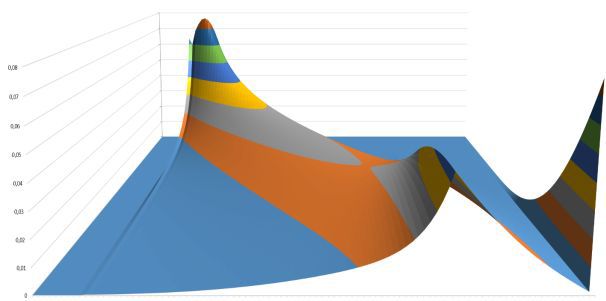
In 3-D, the evolution of the probability of getting a certain level looks very nice:
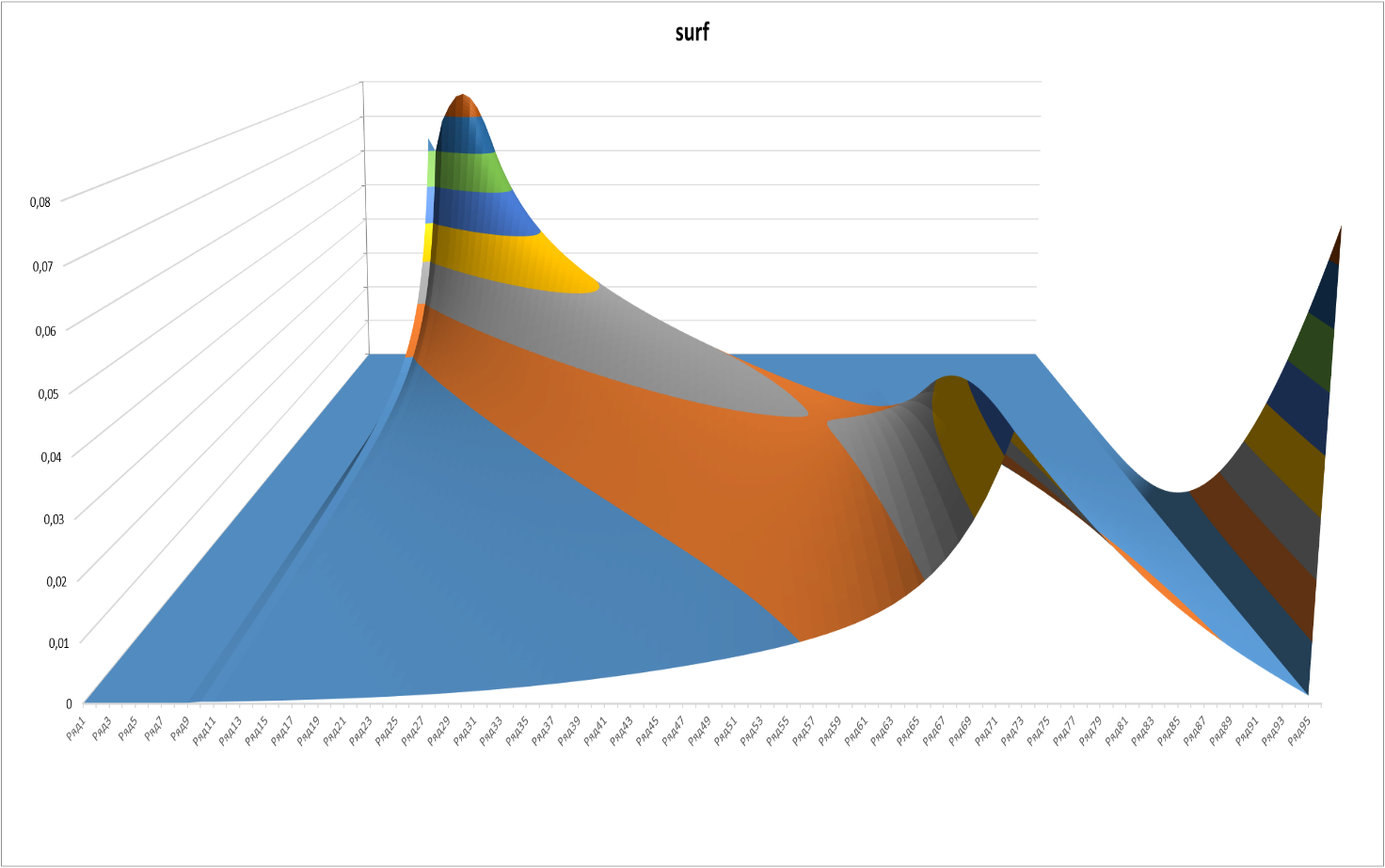
Figure 3
Here is a slice with the same minimum and maximum “time” boundaries (50 and 570 games) as in Figure 2.
The same graph from a different perspective:
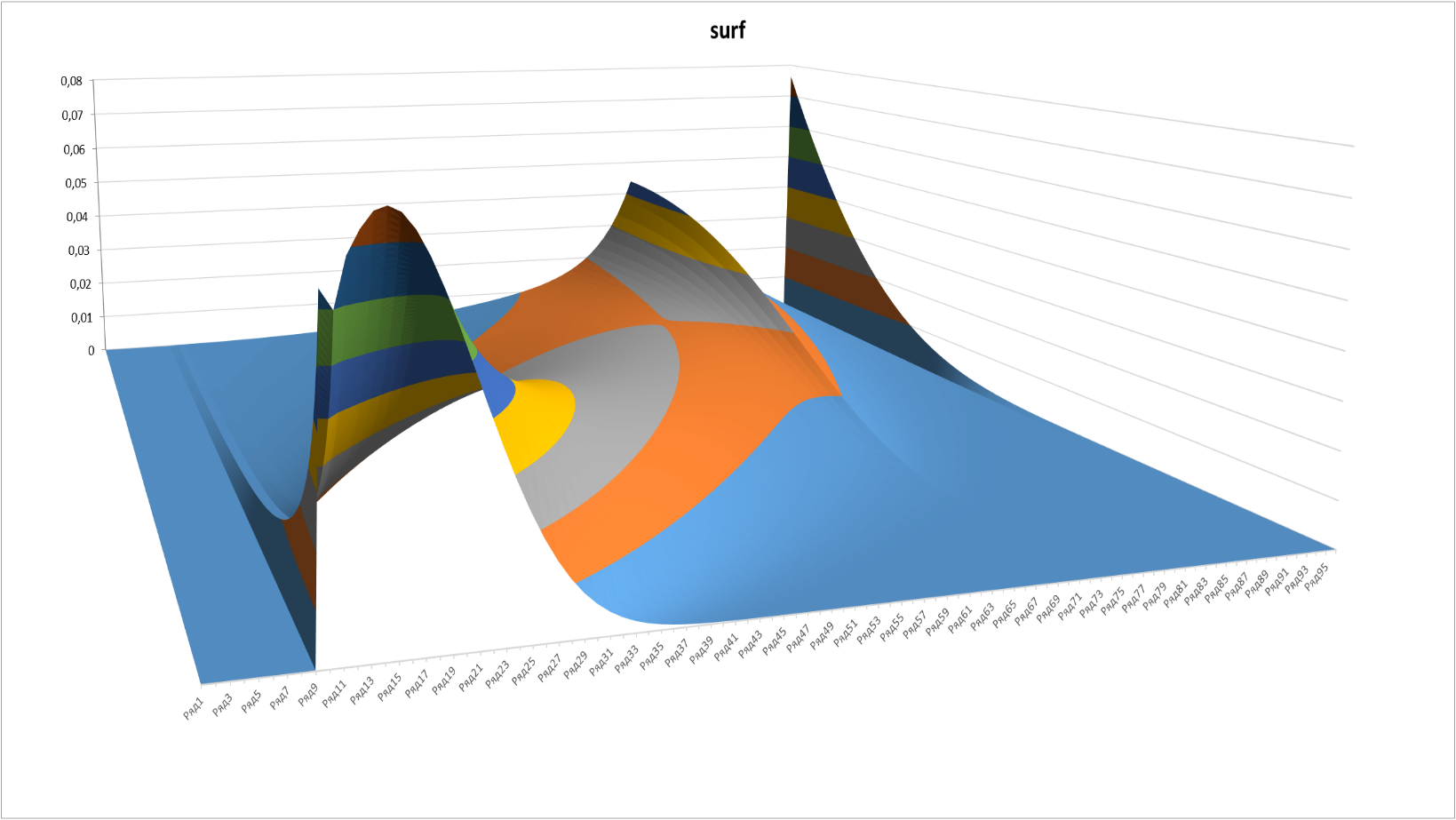
Figure 4
The appearance of a “rib” on the graphs at a point corresponding to level 5 and 2 of the “star” (72nd sublevel in order) looks somewhat unexpected. This point is the last one affected by the possibility of hitting “with acceleration” after 3+ wins in a row.
If you look at the rules for 71 - 72 sublevels, they look like this:
71 = 1/8 * C69 + C70 *
3/8 + 0.5 * C72 72 = 1/8 * C70 + C71 * 1/2 + 0. 5 * C73
Here CNN is the number of players at the NN sublevel in the previous step:
- the first member provides “accelerated transfer” from the level of “current -2”;
- the second member provides the usual transition when winning at the level of "current -1";
- the third member provides a transition from the overlying level in case of defeat.
The difference in 1/8 in the coefficient for the second term is due to the fact that, starting from the 5th level (aka the 71st ordinal sublevel), regardless of the number of victories in a row, the increase in the sublevel is only 1, i.e. even if the victory at the 71st sublevel was for the player 3rd, he will only go to the 72nd sublevel.
This seemingly small addition leads to the fact that the “flow of players” to the 72nd sublevel is slightly higher than the average, respectively, the flow of players from the 72nd sublevel in its vicinity will also be slightly higher, i.e. the effect of increasing the flow of players to the 72nd sublevel is self-reinforcing, which leads to the appearance of this remarkable rib.
Obviously, players differ in the number of games they play at the same time. More enthusiastic players play more, casual players play less.
To calculate the model distribution of players by levels, you need to know the distribution function of players by the number of games they play.
We introduce the following notation:
Then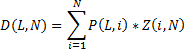
I must say right away that I have no data on the function Z (i, N). But you can speculate a bit on this topic.
The only thing that occurred to me was: “20% of people drink 80% of beer.” Perhaps “20% of the players in Hearthstone play 80% of the games”? That is, the hypothesis is that the distribution of players by the number of games played is the discrete Pareto distribution, or, more precisely, the Zipf distribution (see en.wikipedia.org/wiki/Zipf%27s_law ).
We introduce the following notation:
Then the Zipf distribution with exponent exponent s:
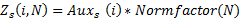
Let's look at the graphs of the desired function D (L, N) under the assumption that the distribution of players by the number of games played is the Zipf distribution with exponent 1.
Here and in the next graph, D (L, N) is displayed in moments of “time” N from 50 to 700.
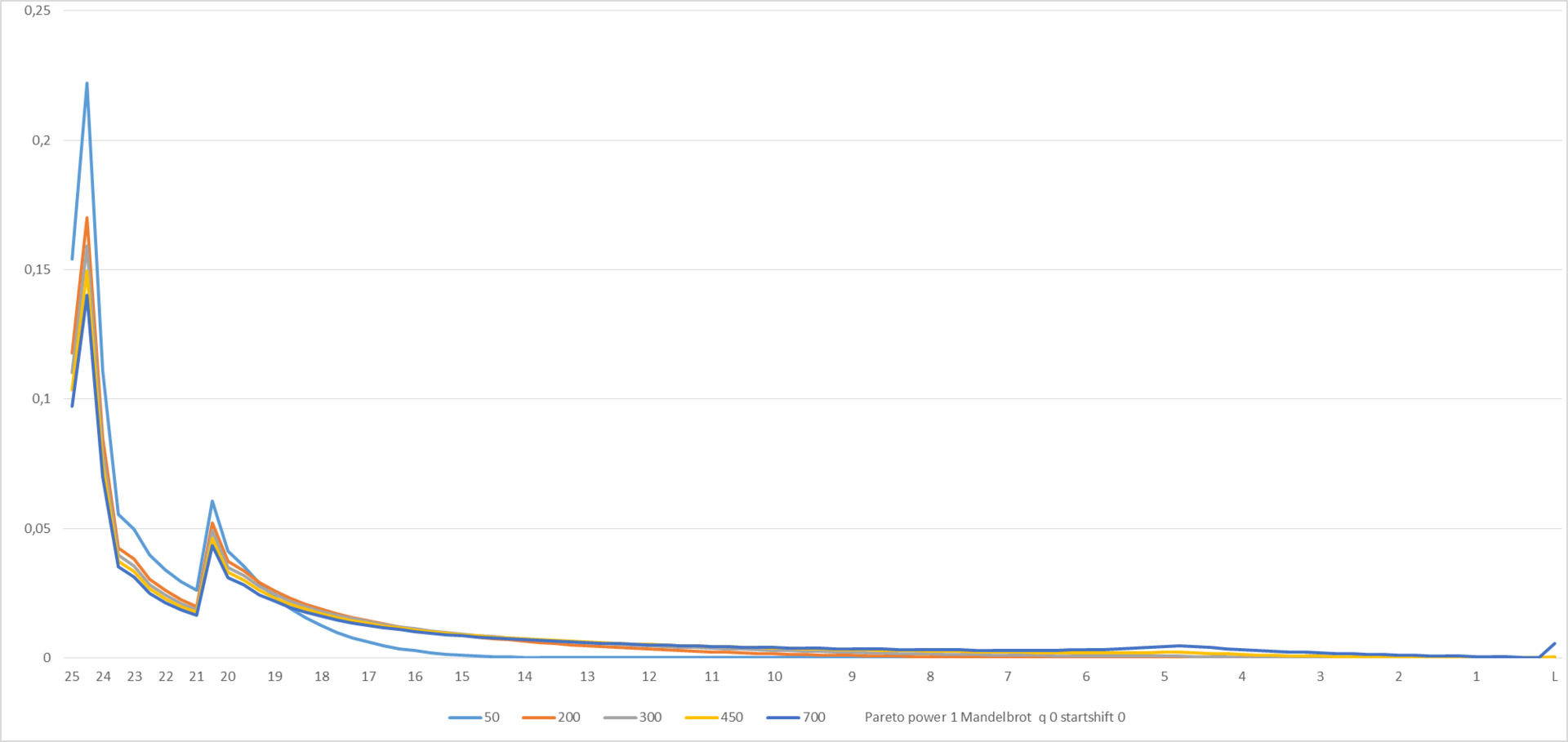
Figure 5
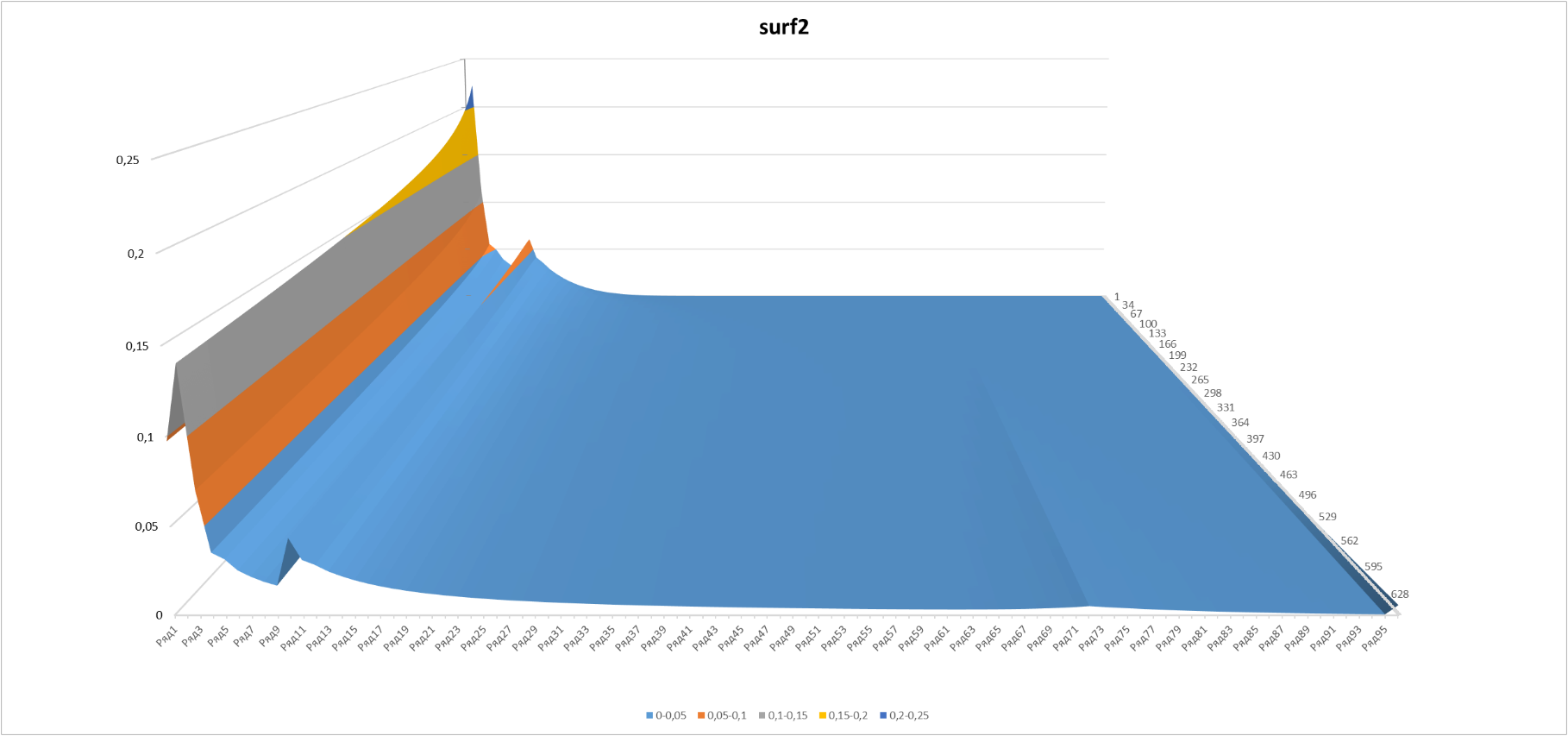
Figure 6
It looks pretty ugly, although it’s understandable why - a significant part of the players, according to Zipf’s distribution, remained on the “springboard”. Well, speculate - so in full. We construct the modified Zipf-Mandelbrot distribution (see en.wikipedia.org/wiki/Zipf%E2%80%93Mandelbrot_law ).
1. Replace the auxiliary function
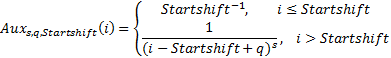
The idea of introducing an integer parameter Startshift is as follows: the beginning of the "action" of the standard Zipf distribution behavior is shifted to the Startshift steps.
Indeed, it seems improbable that a player who has gone through all the difficulties of training and has just entered rating games is likely to quit playing after one or two rating games. It can be assumed that the beginning of the “action” of the Zipf distribution approximately coincides with the beginning of the difficulties in promotion in the rating, i.e. with the moment when the probability of leaving the “springboard” exceeds ½ (this means that startshift = 18). In addition, it follows from the definition of an auxiliary function that the total number of players “accidentally entering Hearthstone” (that is, those who played ≤Startshift games) coincides with the number of players at the maximum distribution. All this, of course, is pure speculation, but why not see what happens?
The Mandelbrot parameter q was introduced without any justification, just in case.
2. Normalization factor (for the “time” moment N)
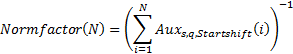
Then a modified distribution with power exponent s, Mandelbrot parameter q and “start shift” parameter Startshift:
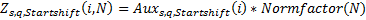
Let's see what happens with the parameters given at the bottom of the graph:
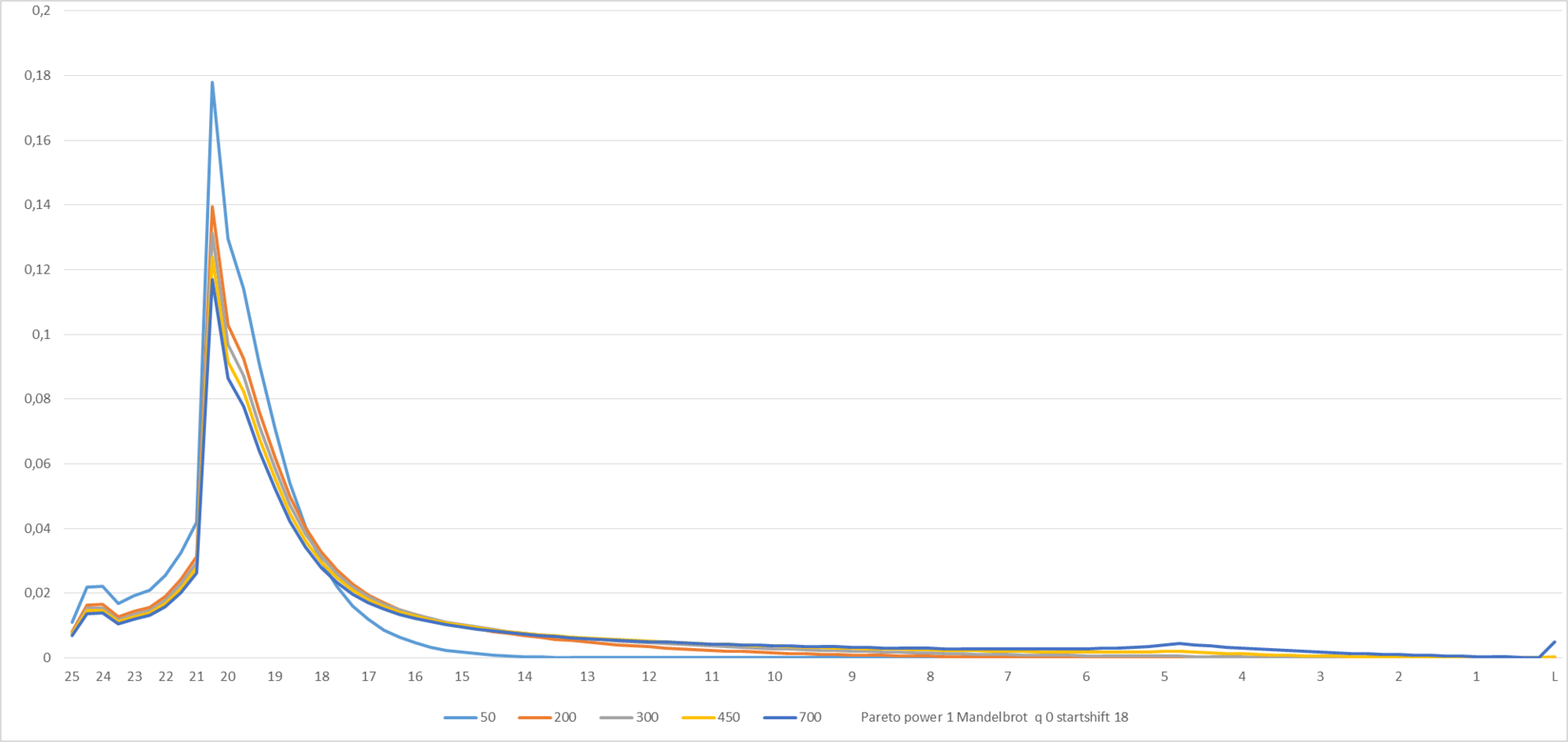
Figure 7
For manual experiments, the graph made interactive in Excel - you can play around with the distribution parameters and the displayed “times” to the left of the diagram on the “Interface” tab, while the graphs (Figure 7 and Figure 8) will change.
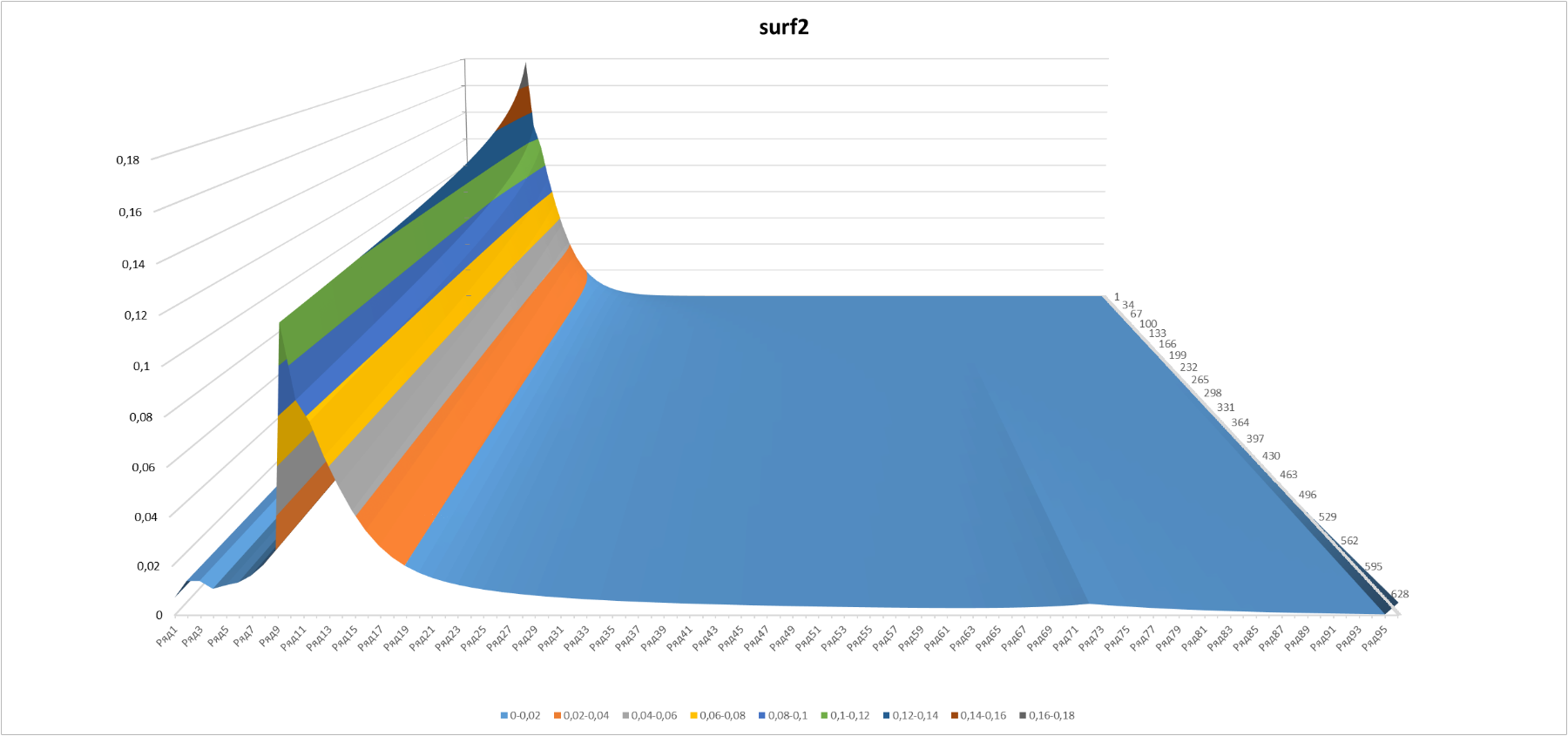
Figure 8
And finally, the last spurt for today. Let's try to select distribution parameters using "real" data (http://www.reddit.com/r/hearthstone/comments/23ed7l/how_good_are_you_at_constructed_ladder/). These are the results of some kind of simulation, the details of which are unknown to me, it is unclear, in particular, at what point in "time" N the measurement was taken, etc. This is the only thing I have found. But I did not try very hard to search. I hope readers of the article will tell you the source of more relevant data.
Iterative data processing by the solver add-in and manual fitting gave the following values of the distribution parameters: s = 1.19; q = 0.287; Startshift = 110. The startshift is expectedly large, since there is no population information for levels 25-21 in the source data of the simulation, i.e. The “springboard” was obviously not simulated.
Final pictures:
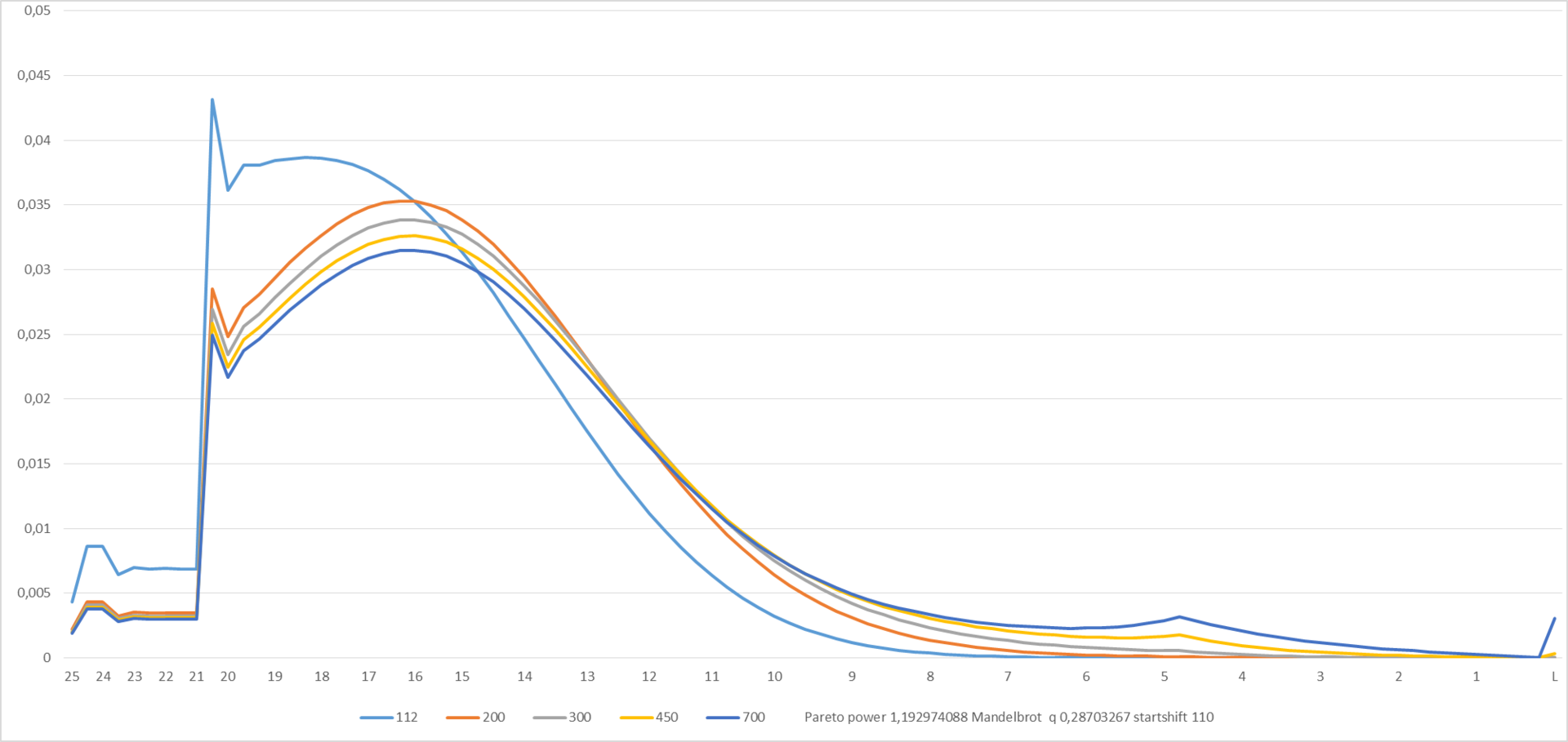
Figure 9
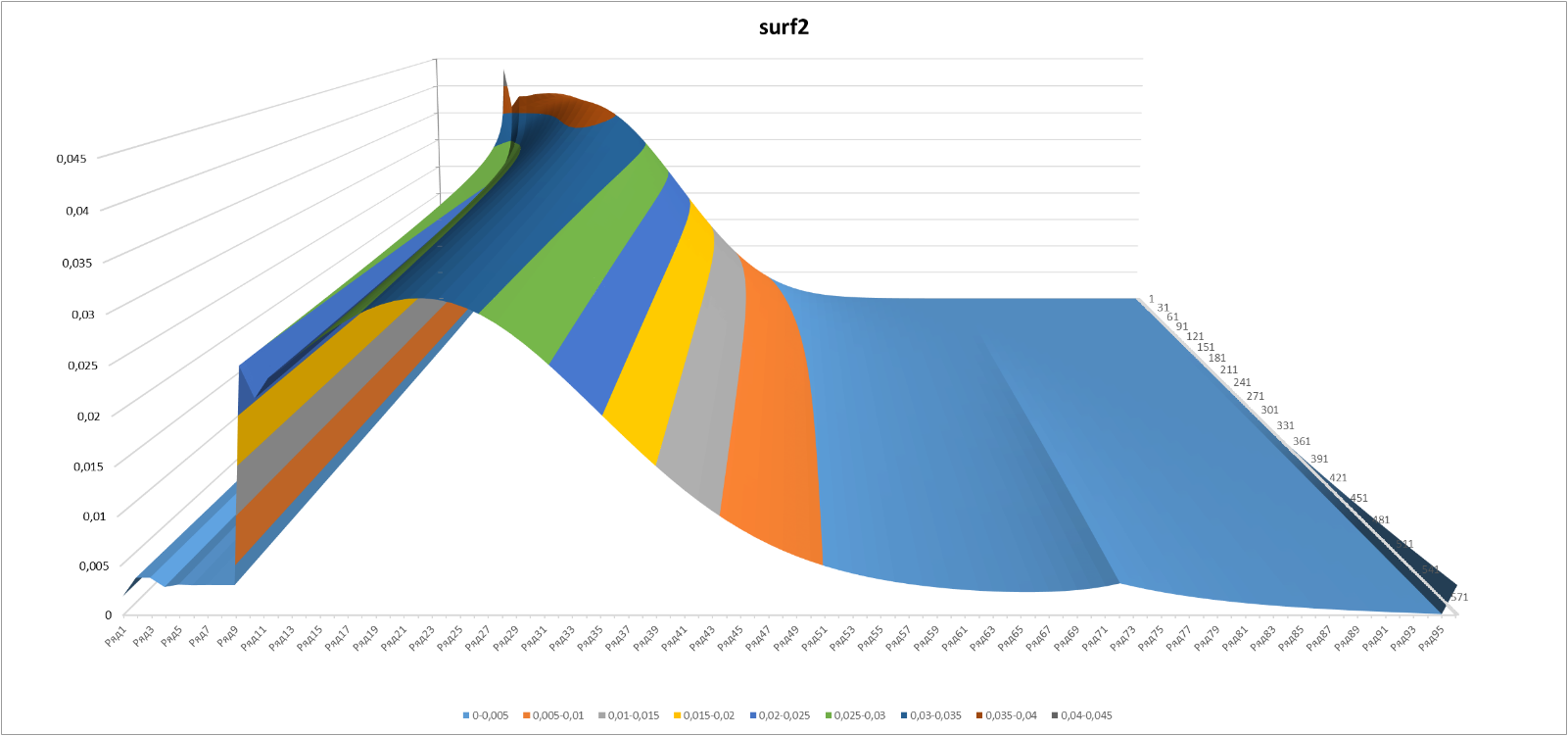
Figure 10
In conclusion, I repeat that the problem that I began to solve out of pure curiosity seemed to me a good topic for classes in the school math circle. I consider it important for future engineers and scientists to use all available improvised tools for solving suddenly arising problems: paper and pencil, spreadsheets, the WOLFRAM MATHEMATICA package. Hopefully this example spreadsheet application will be useful to someone.
If desired, the teacher can lay bridges from this task to a variety of topics.
Offhand:
You can also come up with some extensions to this task. For example, these:
1) When the season ends, players who have reached certain levels in the previous season will get some head start. For example, at the end of the season at level 4, the player receives 21 "stars", i.e. It starts in the new season not from level 25, but from level 17. ** - It is also the 21st level sublevel (see Figure 1). I am sure that the corresponding numbers describing the dependence of the size of the handicap on the level achieved are easy to find on the network.
Questions:
2) Come up with some intelligible theory to calculate the function Z (i, N).
Despite the fact that the network has a huge number of sites and wiki dedicated to Hearthstone, a superficial search did not give results. It was a pity for a deep search, so I solved the problem “on my knee”. I believe this decision can become a topic for classes in the school math circle.
Task description
There are 25 levels in the Hearthstone Rating Tournament and a special Legend level. Levels consist of sublevels - the so-called "Stars", and at different levels the number of sublevels differs:
- Levels 25 through 21 consist of 2 sublevels;
- Levels 20 through 16 consist of 3 sublevels;
- Levels 15 through 11 consist of 4 sublevels;
- Levels 10 to 1 consist of 5 sublevels;
- There are no sublevels on Legend.
Thus, the line of levels in the rating (hereinafter referred to as the line) consists of 96 sublevels (including “Legend”):
Figure 1
A new player starts in the rating from level 25. For winning a game, the player receives a “star” (sometimes two), i.e. raises its sublevel by 1 (or 2, respectively).
There are 4 ranges on the line in which the rules for changing the player’s level when winning / losing a game differ:
Table 1
| Conditional name | Level range | Rules for changing a sublevel when winning / losing |
|---|---|---|
| "Springboard" | 25-21 | Defeat: sublevel does not change Victory: +1 3 (or more) victories in a row: +2 |
| “Acceleration Race” | 20-6 | Defeat: -1 Win: +1 3 (or more) wins in a row: +2 |
| "Normal race" | 5-1 | Defeat: -1 Win: +1 |
| "Legend" | Legend | Defeat: sublevel does not change Victory: sublevel does not change |
Obviously, the “Springboard” serves to attract new players, as there is only a reward on the “springboard”, but no punishment for defeat. In addition, it is clear that the population of the “springboard” exponentially quickly “dies out”, since the rules inevitably push the player from the “springboard” into the “Acceleration Racing” range. The probability of staying on the “springboard” after 18 games is ~ 29%, and after 27 games - less than 1.5%.
"Acceleration Race" helps players with high skill and good decks get to the "Normal Race" faster, where the real "ruby" begins. And finally, “Legend” is a pen for top players.
I wanted to find 2 dependencies:
- Calculate the probability of a player getting a certain level after a certain number of games played;
- Calculate the distribution of all players by level depending on time.
Choosing a solution method and tool
The first thought was to write a program in JS, simulating a lot of players whose levels as a result of interaction change according to the above rules. After a short thought on the size of the required JS code, I decided that spreadsheets are great for solving this problem.
The idea of the solution is as follows:
Let some rectangular range of 96 * 1 size (for example, the range Source! $ C $ 3: $ C $ 98 in the attached files) represent the distribution of the number of players in the line. Then, using the rules from table 1, it is easy to obtain a distribution describing the state after each player has played one game. The rules in Table 1 are in the range Source! $ D3: $ D $ 98. If these rules are “dragged” by the required number of columns, then the resulting table will represent the change in the distribution of players by levels with “time”. Time in this case is in quotation marks because here it is measured in "played games."
I started with Open Office Calc, which is good for everyone, but the 3-D graphics out of the box in it look wretched (maybe I just don’t know how to cook them). As a result, the solution is implemented on MS Excel and lies here. The option for Open Office Calc in the same place is quite functional, except for the lack of 3-D graphs and the lack of interactivity in 2-D graphs.
The probability of a player getting a certain level
Figure 2
The graphs below describe the probability of getting one or another level for a player starting from level 25 and playing 50, 130, 300, 450 or 570 games, respectively. In Excel, the graph is interactive - you can play around with the numbers to the left of the diagram on the “Interface” tab, while the graphs (Figure 2) will change.
In 3-D, the evolution of the probability of getting a certain level looks very nice:
Figure 3
Here is a slice with the same minimum and maximum “time” boundaries (50 and 570 games) as in Figure 2.
The same graph from a different perspective:
Figure 4
The appearance of a “rib” on the graphs at a point corresponding to level 5 and 2 of the “star” (72nd sublevel in order) looks somewhat unexpected. This point is the last one affected by the possibility of hitting “with acceleration” after 3+ wins in a row.
If you look at the rules for 71 - 72 sublevels, they look like this:
71 = 1/8 * C69 + C70 *
3/8 + 0.5 * C72 72 = 1/8 * C70 + C71 * 1/2 + 0. 5 * C73
Here CNN is the number of players at the NN sublevel in the previous step:
- the first member provides “accelerated transfer” from the level of “current -2”;
- the second member provides the usual transition when winning at the level of "current -1";
- the third member provides a transition from the overlying level in case of defeat.
The difference in 1/8 in the coefficient for the second term is due to the fact that, starting from the 5th level (aka the 71st ordinal sublevel), regardless of the number of victories in a row, the increase in the sublevel is only 1, i.e. even if the victory at the 71st sublevel was for the player 3rd, he will only go to the 72nd sublevel.
This seemingly small addition leads to the fact that the “flow of players” to the 72nd sublevel is slightly higher than the average, respectively, the flow of players from the 72nd sublevel in its vicinity will also be slightly higher, i.e. the effect of increasing the flow of players to the 72nd sublevel is self-reinforcing, which leads to the appearance of this remarkable rib.
Calculation of the distribution of all players by level
Obviously, players differ in the number of games they play at the same time. More enthusiastic players play more, casual players play less.
To calculate the model distribution of players by levels, you need to know the distribution function of players by the number of games they play.
We introduce the following notation:
- P (L, i)) - the probability of a player getting a certain level (L) after a given number of games (i) (graphs are shown in figures 2-4)
- N is the maximum number of games played by the most enthusiastic player. Note that N plays the role of time here. Of course, this is not an ordinary time. However, between ordinary time t and N there is the following relation:
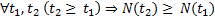 therefore, N as a “time” is quite suitable.
therefore, N as a “time” is quite suitable. - Z (i, N) - the probability that a player has played i games by the time “N” or the distribution of players according to the number of games played in the “time” N.
- D (L, N) - the desired probability of finding a player at level L, at the moment of “time” N or the distribution of players by levels at the moment of “time” N.
Then
I must say right away that I have no data on the function Z (i, N). But you can speculate a bit on this topic.
The only thing that occurred to me was: “20% of people drink 80% of beer.” Perhaps “20% of the players in Hearthstone play 80% of the games”? That is, the hypothesis is that the distribution of players by the number of games played is the discrete Pareto distribution, or, more precisely, the Zipf distribution (see en.wikipedia.org/wiki/Zipf%27s_law ).
We introduce the following notation:
- Helper function
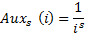
- Normalization factor (for the moment of "time" N)
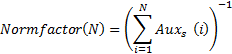
Then the Zipf distribution with exponent exponent s:
Let's look at the graphs of the desired function D (L, N) under the assumption that the distribution of players by the number of games played is the Zipf distribution with exponent 1.
Here and in the next graph, D (L, N) is displayed in moments of “time” N from 50 to 700.
Figure 5
Figure 6
It looks pretty ugly, although it’s understandable why - a significant part of the players, according to Zipf’s distribution, remained on the “springboard”. Well, speculate - so in full. We construct the modified Zipf-Mandelbrot distribution (see en.wikipedia.org/wiki/Zipf%E2%80%93Mandelbrot_law ).
1. Replace the auxiliary function
The idea of introducing an integer parameter Startshift is as follows: the beginning of the "action" of the standard Zipf distribution behavior is shifted to the Startshift steps.
Indeed, it seems improbable that a player who has gone through all the difficulties of training and has just entered rating games is likely to quit playing after one or two rating games. It can be assumed that the beginning of the “action” of the Zipf distribution approximately coincides with the beginning of the difficulties in promotion in the rating, i.e. with the moment when the probability of leaving the “springboard” exceeds ½ (this means that startshift = 18). In addition, it follows from the definition of an auxiliary function that the total number of players “accidentally entering Hearthstone” (that is, those who played ≤Startshift games) coincides with the number of players at the maximum distribution. All this, of course, is pure speculation, but why not see what happens?
The Mandelbrot parameter q was introduced without any justification, just in case.
2. Normalization factor (for the “time” moment N)
Then a modified distribution with power exponent s, Mandelbrot parameter q and “start shift” parameter Startshift:
Let's see what happens with the parameters given at the bottom of the graph:
Figure 7
For manual experiments, the graph made interactive in Excel - you can play around with the distribution parameters and the displayed “times” to the left of the diagram on the “Interface” tab, while the graphs (Figure 7 and Figure 8) will change.
Figure 8
And finally, the last spurt for today. Let's try to select distribution parameters using "real" data (http://www.reddit.com/r/hearthstone/comments/23ed7l/how_good_are_you_at_constructed_ladder/). These are the results of some kind of simulation, the details of which are unknown to me, it is unclear, in particular, at what point in "time" N the measurement was taken, etc. This is the only thing I have found. But I did not try very hard to search. I hope readers of the article will tell you the source of more relevant data.
Iterative data processing by the solver add-in and manual fitting gave the following values of the distribution parameters: s = 1.19; q = 0.287; Startshift = 110. The startshift is expectedly large, since there is no population information for levels 25-21 in the source data of the simulation, i.e. The “springboard” was obviously not simulated.
Final pictures:
Figure 9
Figure 10
Conclusion
In conclusion, I repeat that the problem that I began to solve out of pure curiosity seemed to me a good topic for classes in the school math circle. I consider it important for future engineers and scientists to use all available improvised tools for solving suddenly arising problems: paper and pencil, spreadsheets, the WOLFRAM MATHEMATICA package. Hopefully this example spreadsheet application will be useful to someone.
If desired, the teacher can lay bridges from this task to a variety of topics.
Offhand:
- Theorver - Pareto distribution - Zeta function - John Derbyshire. Prime Obsession: Bernhard Riemann and the Greatest Unsolved Problem in Mathematics
- Numerical methods for solving partial differential diffurs. (by the way - a task for advanced students: show that P (L, i) in the "Normal Race" range approximates some particular solution of the equation
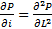 on the corresponding scale, and in the "Race with Acceleration" range - equations
on the corresponding scale, and in the "Race with Acceleration" range - equations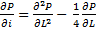
- The choice of the optimal type of the residual function for the problem.
You can also come up with some extensions to this task. For example, these:
1) When the season ends, players who have reached certain levels in the previous season will get some head start. For example, at the end of the season at level 4, the player receives 21 "stars", i.e. It starts in the new season not from level 25, but from level 17. ** - It is also the 21st level sublevel (see Figure 1). I am sure that the corresponding numbers describing the dependence of the size of the handicap on the level achieved are easy to find on the network.
Questions:
- How will P (L, i) and D (L, N) change when taking into account the handicap at the start of the season?
- Does a series of D functions (L, N, season number) converge to something with a season number tending to ∞? If so, what restrictions does this impose on Z (i, N)?
- Is Z (i, N) enough to correctly answer the 2nd question?
2) Come up with some intelligible theory to calculate the function Z (i, N).