Technologies to Enhance VPS Resiliency
Recently, we decided to go beyond the segment of budget servers: to reconsider our vision of hosting virtual machines and create the most fault-tolerant service.
In this article I will tell you how our standard platform for VPS is organized and what techniques we used to improve it.
Our standard technology for creating VDS.
Now the hosting of virtual servers is as follows:
Single-server servers of approximately the following configuration are installed in the racks:
One of the servers is the main one. VMmanager is installed on it and nodes are connected to it - additional servers.
In addition to VMmanager, client virtual servers are located on the main server.
Each server “looks” into the world with its network interface. And to increase the speed of migration of VDS between nodes, servers are interconnected by separate interfaces.
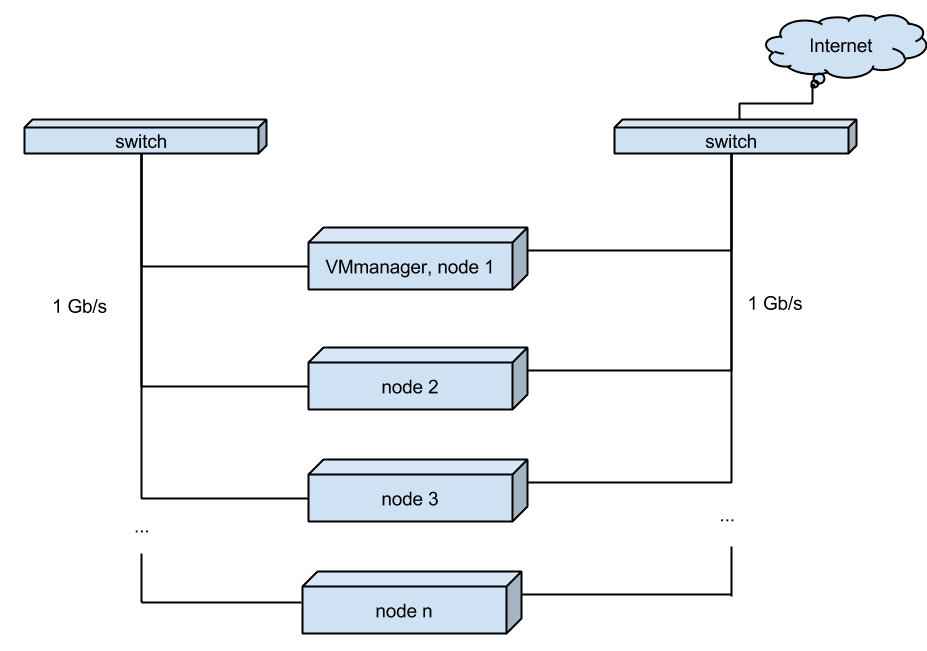
(Fig. 1. Current virtual server hosting scheme)
All servers work independently of each other, and in case of performance problems on one of the servers, all virtual servers can be distributed (the “Migration” function in VMmanager) to neighboring nodes, or Transferred to the newly added node.
Situations when a server crashes (kernel panic, spilled disks, dead PSU, etc.) entail the inaccessibility of client virtual machines. Of course, the monitoring system immediately notifies the responsible specialists about the problem, they begin to find out the causes and eliminate the accident. In 90% of cases, work on replacing failed components takes no more than an hour, plus it takes time to eliminate the consequences of an emergency shutdown of the server (storage synchronization, file system errors, etc. ...).
All this, of course, is unpleasant for us and our customers, but a simple scheme allows you to avoid unnecessary expenses and keep prices low.
New Cloud VDS
To satisfy the most demanding customers, for whom the Uptime server is critical, we have created a service with the highest possible reliability.
So, we needed new software and hardware.
Since we are already working with ISPsystem products , the logical step was to look at VMmanager-Cloud. This panel was just created to solve the problem of fault tolerance, at the moment it is well designed and has reached a certain stability. She suited us and we did not consider alternatives. Ceph
was unconditionally accepted as a distributed file system. It is a free, free-growing product that is flexible and scalable. We tried other storage systems, but Ceph is the only product that fully meets our storage requirements. It seemed difficult at first, with some attempt we finally figured it out. And did not regret it.
The nodes of the new cluster are assembled on the same hardware as the working VMmanager cluster, but with minor changes:
We switched to multi-redundant power supplies.
For switching between cluster nodes, instead of the usual gigabit connection, we used Infiniband. It allows you to increase the connection speed to 56Gb (IB cards Mellanox Technologies MT27500 Family ConnectX-3, switch - Mellanox SX6012)
The CentOS 7 distribution was chosen as the operating system for the cluster nodes. However, to make all of the above work together, I had to assemble my kernel, rebuild qemu and ask for some improvements in VMmanager-Cloud.
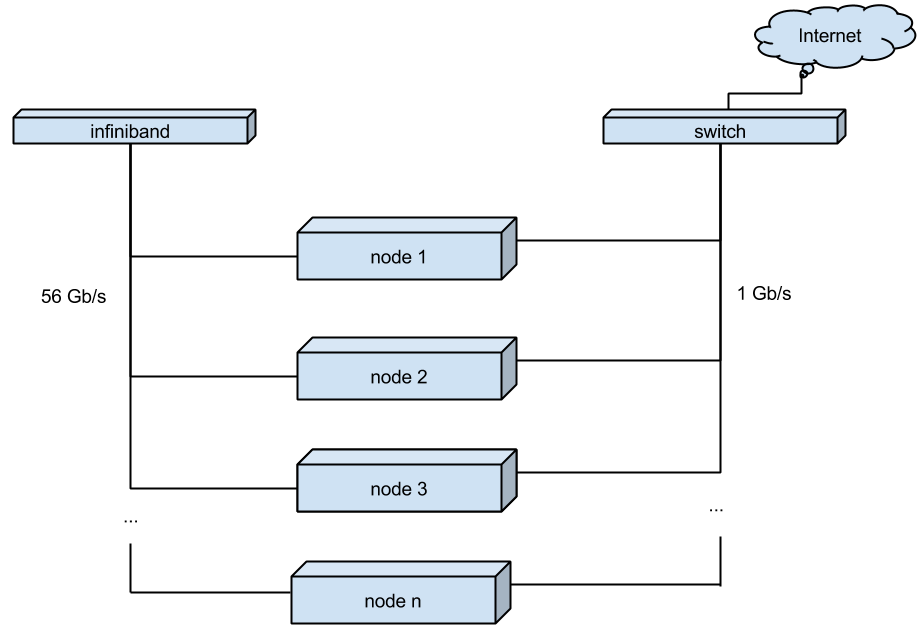
(Fig. 2. New scheme of cloud hosting of virtual servers)
Benefits of using the new technology
As a result, we got the following:
Since the beginning of December last year, the cluster has been operating in combat mode, at the moment it serves several hundred clients, during this time we stepped on a lot of rakes, sorted out bottlenecks, performed the necessary tuning and simulated all emergency situations.
While we continue testing, economists consider the cost. Due to additional redundancy and the use of more expensive technologies, it turned out to be higher than that of the previous cluster. We have taken this into account and are developing a new tariff for the most demanding customers.
There remains a number of risks that we can’t close in any way, this is the power supply of the data center and external communication channels. To solve such issues, geographically distributed geo-clusters are usually done, perhaps this will be one of our next studies.
If you are interested in the technical details of implementing the above technology, then we are ready to share them in the comments or make a separate article following the discussion.
In this article I will tell you how our standard platform for VPS is organized and what techniques we used to improve it.
Our standard technology for creating VDS.
Now the hosting of virtual servers is as follows:
Single-server servers of approximately the following configuration are installed in the racks:
- CPU - 2 x Intel Xeon CPU E5-2630 v2 @ 2.60GHz
- Motherboard: Intel Corporation S2600JF
- RAM: 64 Gb
- DISK: 2 x HGST HDN724040ALE640 / 4000 GB, INTEL SSDSC2BP480G4 480 GB
One of the servers is the main one. VMmanager is installed on it and nodes are connected to it - additional servers.
In addition to VMmanager, client virtual servers are located on the main server.
Each server “looks” into the world with its network interface. And to increase the speed of migration of VDS between nodes, servers are interconnected by separate interfaces.
(Fig. 1. Current virtual server hosting scheme)
All servers work independently of each other, and in case of performance problems on one of the servers, all virtual servers can be distributed (the “Migration” function in VMmanager) to neighboring nodes, or Transferred to the newly added node.
Situations when a server crashes (kernel panic, spilled disks, dead PSU, etc.) entail the inaccessibility of client virtual machines. Of course, the monitoring system immediately notifies the responsible specialists about the problem, they begin to find out the causes and eliminate the accident. In 90% of cases, work on replacing failed components takes no more than an hour, plus it takes time to eliminate the consequences of an emergency shutdown of the server (storage synchronization, file system errors, etc. ...).
All this, of course, is unpleasant for us and our customers, but a simple scheme allows you to avoid unnecessary expenses and keep prices low.
New Cloud VDS
To satisfy the most demanding customers, for whom the Uptime server is critical, we have created a service with the highest possible reliability.
So, we needed new software and hardware.
Since we are already working with ISPsystem products , the logical step was to look at VMmanager-Cloud. This panel was just created to solve the problem of fault tolerance, at the moment it is well designed and has reached a certain stability. She suited us and we did not consider alternatives. Ceph
was unconditionally accepted as a distributed file system. It is a free, free-growing product that is flexible and scalable. We tried other storage systems, but Ceph is the only product that fully meets our storage requirements. It seemed difficult at first, with some attempt we finally figured it out. And did not regret it.
The nodes of the new cluster are assembled on the same hardware as the working VMmanager cluster, but with minor changes:
We switched to multi-redundant power supplies.
For switching between cluster nodes, instead of the usual gigabit connection, we used Infiniband. It allows you to increase the connection speed to 56Gb (IB cards Mellanox Technologies MT27500 Family ConnectX-3, switch - Mellanox SX6012)
The CentOS 7 distribution was chosen as the operating system for the cluster nodes. However, to make all of the above work together, I had to assemble my kernel, rebuild qemu and ask for some improvements in VMmanager-Cloud.
(Fig. 2. New scheme of cloud hosting of virtual servers)
Benefits of using the new technology
As a result, we got the following:
- an even more professional virtual server service with high uptime. Its stability does not depend on problems with the hardware of the cluster nodes.
- increased reliability of data storage due to the distributed file system with the storage of several copies.
- fast migration of virtual machines. The transfer of a working VPS from node to node occurs almost instantly without loss of packets and pings. If necessary, this quickly frees the node for maintenance.
- when a node fails, client virtual machines automatically start on other nodes. For the client, it looks like an unscheduled reboot on power, the downtime is equal to the OS reboot time.
Since the beginning of December last year, the cluster has been operating in combat mode, at the moment it serves several hundred clients, during this time we stepped on a lot of rakes, sorted out bottlenecks, performed the necessary tuning and simulated all emergency situations.
While we continue testing, economists consider the cost. Due to additional redundancy and the use of more expensive technologies, it turned out to be higher than that of the previous cluster. We have taken this into account and are developing a new tariff for the most demanding customers.
There remains a number of risks that we can’t close in any way, this is the power supply of the data center and external communication channels. To solve such issues, geographically distributed geo-clusters are usually done, perhaps this will be one of our next studies.
If you are interested in the technical details of implementing the above technology, then we are ready to share them in the comments or make a separate article following the discussion.