Dual ETL project or how we built Disaster Recovery for Greenplum
In this article I want to talk about another stage in the development of DWH at Tinkoff Bank .
It's no secret that the requirements for the availability of Disaster Recovery (hereinafter referred to as DR) in modern business information systems are classified as “must have”. So, a little over a year ago, the team involved in the development of DWH in the bank was tasked with implementing DR for DWH, on which both offline and online bank processes are built.

So what was given:
Objective: to ensure, within an hour after the failure, leading to the inoperability of Greenplum at the main site, the operability of all DWH processes on the backup circuit of Greenplum. In essence, the task boils down to building a hot standby for Greenplum.
About a month was allotted to us for research and development of the concept.
Of course, the first thing that occurred to us was to dig in the direction of the vendor - Pivotal, i.e. EMC As a result of our research, we found that Greenplum does not have a standard tool for building hot standby, and the DR solution for Greenplum can potentially be built using EMC Data Domain. But with a deeper study of the Data Domain, it came to the understanding that this technology is geared towards creating a large number of backups and in view of this is quite expensive. Also, the Data Domain “out of the box” does not have the functionality to keep the second circuit up to date. We refused to consider EMC Data Domain.
The second option that we have worked on is using the third-party replication tool GreenplumToGreenplum. The option quickly became obsolete, because at that time, there were no replication tools in nature that supported Greenplum as a source.
The third option that we took up is a Dual Apply class solution. After seeing Teradata and Informatica their solution called Informatica dual load for Teradata dual active solution ( Teradata Magazine ), they began to research the technology market to build a similar solution for Greenplum. But they didn’t find anything ready.
After the research, we decided that our own development would be the best option. So we started writing our own system and called it Dual ETL (in the circles of developers, the project was called “Duet”).
The concept of building the system was based on the principle: as soon as the ETL rebuilt the table on the main circuit of Greenplum, the system should catch this event and transfer the data of this table to the backup circuit of Greenplum. Thus, observing this principle, we synchronously, with a certain time delay, build DWH on two circuits in two geographically remote data centers.
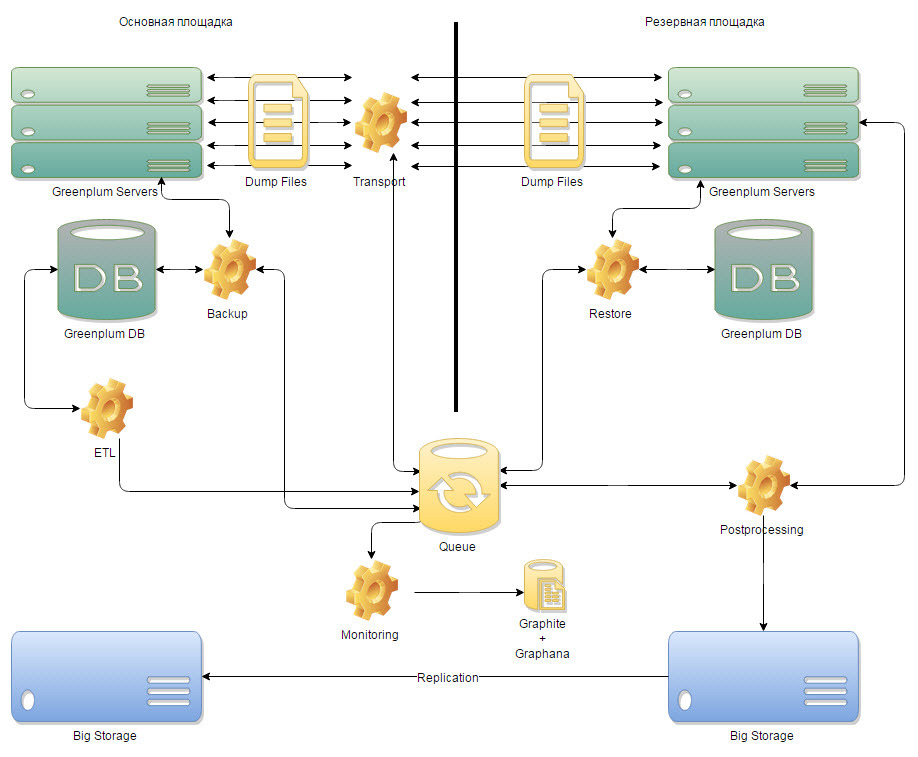
Fig. 1 Conceptual architecture
During the development of architecture, the system was divided into six components:
In order to inform the system about the readiness of the table, a queue was implemented in which we taught our ETL to add an object (i.e. a table) as soon as it finished building it. Thus, the functionality of transmitting the event to the system was realized, after which the system had to rebuild this table on the Greenplum backup circuit.
Due to the fact that our ETL task scheduler is written in SAS, plus the DWH team has a lot of expertise in working with the SAS Macro language, it was decided to write a control mechanism in SAS.
The implemented mechanism performs such simple actions as: getting a new table from the queue, starting the Backup component, sending the dump table to the backup site, starting the Restore component. In addition to this, multithreading is implemented, despite the fact that the number of threads can be adjusted for each type of task (Backup, transport, Restore, transfer of buckups to storage systems), and of course, such necessary functionality as journaling and e-mail notifications .
The Backup component, for the transferred table, calls the gp_dump utility. We get dump tables spread over the Greenplum segment servers of the main site. An example of calling the gp_dump utility:
The main task of the transport component is to quickly transfer dump files from the Greenplum segment server of the main site to the corresponding Greenplum server segment of the backup site. Here we are faced with a network limitation, namely: segments of the main circuit do not see backup circuit segments on the network. Thanks to the knowledge of our DWH administrators, we came up with a way how to get around this using SSH tunnels. SSH tunnels were raised on the Greenplum secondary master servers of each circuit. Thus, each piece of the table dump was transferred from the segment server of the main site to the server segment of the backup site.
After the shutdown of the transport component, we get a dump table spread over the Greenplum segment servers of the backup site. For this table, the Restore component runs the gp_restore utility. As a result, we get an updated table on the reserve site. The following is an example of calling the gp_restore utility:
After the development of the main components and the first launches were completed, we got a generally working system. Tables were set up on a backup site, journaling worked, letters came to the post office and it seemed like the system worked, but we did not have a transparent understanding of what was happening inside at a particular moment in time. We were concerned about the monitoring issue, which was divided into two steps: allocation of metrics for monitoring the system and the technological component of monitoring implementation.
Metrics were identified quite quickly, which, in our opinion, should have unambiguously made it clear on a specific point in time what is happening in the system:
We also decided on the technical implementation quite quickly - Graphite + Graphana. Deploying Graphite on a separate virtual machine and programming the invented metrics was easy. And with Graphana, a beautiful dashboard was developed on working Graphite.
All of the above metrics have found visualization and, not least important, onlineness:
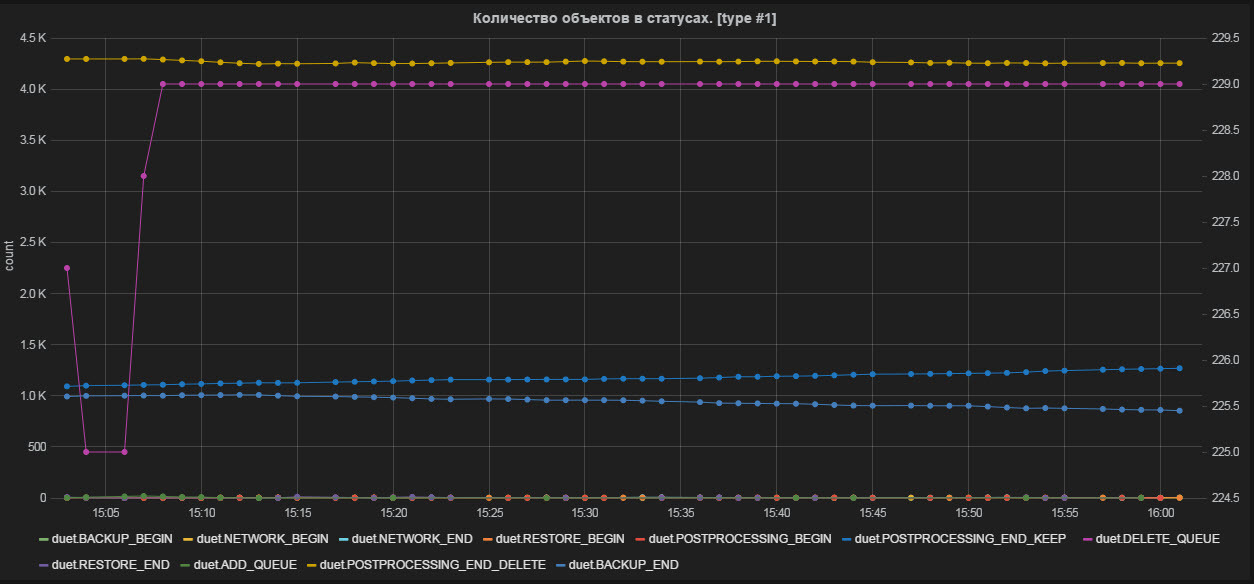
Fig. 2 Number of objects in statuses
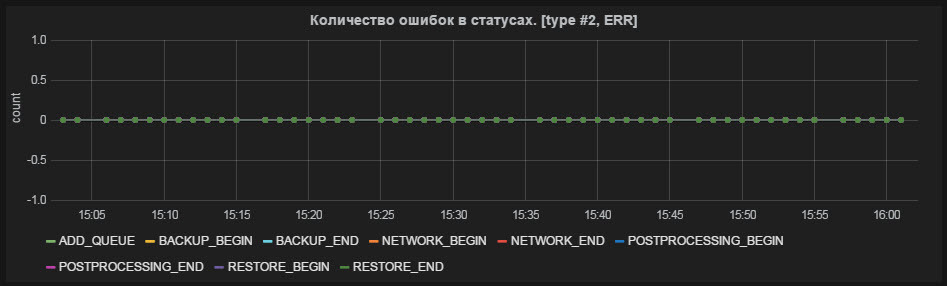
Fig. 3 Number of errors in statuses

Fig. 4 Lag from the moment of getting into the queue
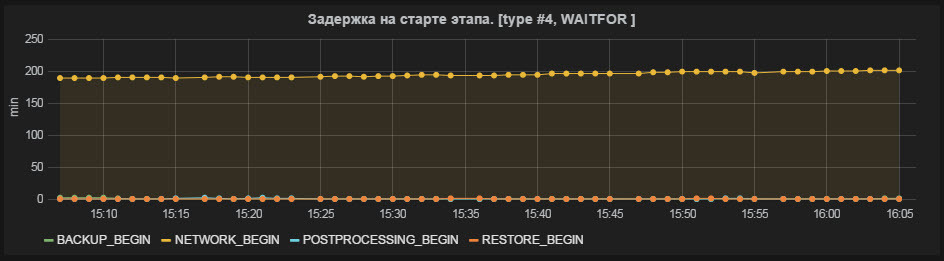
Fig. 5 Delay at the start of the stage
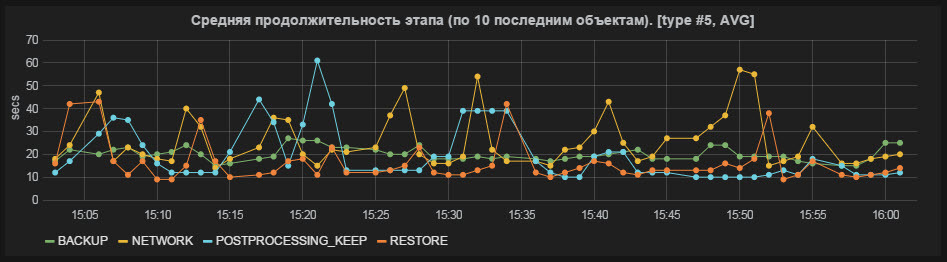
Fig. 6 Average stage duration (for the last 10 objects)

Fig. 7 The number of working threads at each stage
After the restore process is completed, dump files are transferred to the storage system, on the backup site. Replication is configured between the storage on the backup site and the storage on the main site, this replication is based on NetApp SnapMirror technology. Thus, if a failure occurs on the main site that requires data recovery, we already have a prepared backup for storage for these works.
The system was developed and everything turned out not very bad. The tasks that the system was intended to solve are completely closed to it. After the development was completed, a number of regulations were developed that allowed the transition to the backup site as part of the DWH support process.
The main thing that we got is, of course, the ability to move to the backup site within 30 minutes in the event of a failure on the main one, which significantly minimizes the simple DWH as an information system and as a result enables the business to continuously work with reports and data for analysis, performing ad- hoc and do not stop a number of online processes. The system also allowed us to abandon the daily routine backup procedure, in favor of the backup received by the Dual ETL system.
About 6,500 objects (tables) pass through the system per day with a total volume of about 20 TB .
On the example of the metric "Lagging from the moment of getting into the queue" (see Fig. 8)
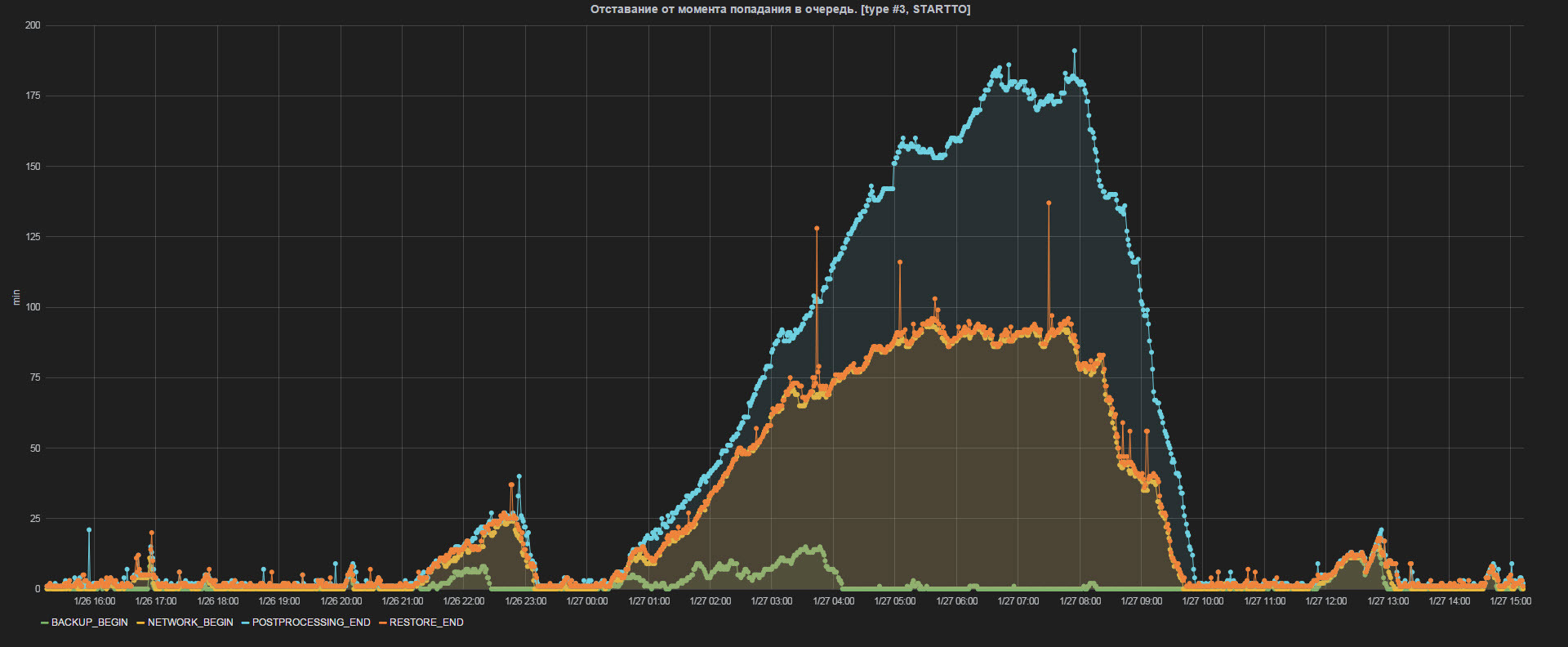
Fig. 8 Lag
behind the moment of getting into the queue, you can observe the backlog of the backup site from the main one. During the work of the night scheduler, when the ETL is actively building a warehouse, the lag in peak reaches 2-3 hours. By the time the storage is completed, at 10 in the morning, the backlog is reduced and remains at the level of 5-10 minutes. During the day, lag bursts may appear during the online scheduler, within 30 minutes.
And also, relatively recently, our system has had a small anniversary, a 1,000,000 (millionth) object flew through it !
The DWH team at Tinkoff Bank takes a strategic course towards Hadoop. In future articles, we plan to cover the topics “ETL / ELT on Hadoop” and “Ad-hoc reporting on Hadoop”.
It's no secret that the requirements for the availability of Disaster Recovery (hereinafter referred to as DR) in modern business information systems are classified as “must have”. So, a little over a year ago, the team involved in the development of DWH in the bank was tasked with implementing DR for DWH, on which both offline and online bank processes are built.
Formulation of the problem
So what was given:
- The system for capturing changes on the side of data sources and applying them to the layer Online Operational Data (hereinafter OOD) - Attunity Replicate ;
- Download, data conversion, IN / OUT data integration, window dressing and the entire ETL / ELT - SAS Data Integration Studio , ~ 1700 ETL tasks ;
- The main DBMS on which DWH is built in the bank is MPP DBMS Pivotal Greenplum, data volume ~ 30TB ;
- Reporting, Business Intelligence, Ad-hoc - SAP BusinessObjects + SAS Enterprise Guide;
- Two data centers, geographically distributed on different ends of Moscow, between which there is a network channel.
Objective: to ensure, within an hour after the failure, leading to the inoperability of Greenplum at the main site, the operability of all DWH processes on the backup circuit of Greenplum. In essence, the task boils down to building a hot standby for Greenplum.
Study
About a month was allotted to us for research and development of the concept.
Of course, the first thing that occurred to us was to dig in the direction of the vendor - Pivotal, i.e. EMC As a result of our research, we found that Greenplum does not have a standard tool for building hot standby, and the DR solution for Greenplum can potentially be built using EMC Data Domain. But with a deeper study of the Data Domain, it came to the understanding that this technology is geared towards creating a large number of backups and in view of this is quite expensive. Also, the Data Domain “out of the box” does not have the functionality to keep the second circuit up to date. We refused to consider EMC Data Domain.
The second option that we have worked on is using the third-party replication tool GreenplumToGreenplum. The option quickly became obsolete, because at that time, there were no replication tools in nature that supported Greenplum as a source.
The third option that we took up is a Dual Apply class solution. After seeing Teradata and Informatica their solution called Informatica dual load for Teradata dual active solution ( Teradata Magazine ), they began to research the technology market to build a similar solution for Greenplum. But they didn’t find anything ready.
After the research, we decided that our own development would be the best option. So we started writing our own system and called it Dual ETL (in the circles of developers, the project was called “Duet”).
Duet and how we built it
Conceptual architecture
The concept of building the system was based on the principle: as soon as the ETL rebuilt the table on the main circuit of Greenplum, the system should catch this event and transfer the data of this table to the backup circuit of Greenplum. Thus, observing this principle, we synchronously, with a certain time delay, build DWH on two circuits in two geographically remote data centers.
Fig. 1 Conceptual architecture
During the development of architecture, the system was divided into six components:
- Backup component, which should work on the main site and be responsible for receiving data;
- A transport component responsible for the transfer of data between the main and reserve sites;
- The Restore component, which should operate on a backup site and be responsible for the application of data;
- The component of transferring to storage and collecting daily backup;
- A control component that should steer all the processes of the system;
- And the monitoring component, which was supposed to give an understanding of what is happening in the system and how much the reserve site is behind the main site.
Refining an existing ETL
In order to inform the system about the readiness of the table, a queue was implemented in which we taught our ETL to add an object (i.e. a table) as soon as it finished building it. Thus, the functionality of transmitting the event to the system was realized, after which the system had to rebuild this table on the Greenplum backup circuit.
Control component implementation
Due to the fact that our ETL task scheduler is written in SAS, plus the DWH team has a lot of expertise in working with the SAS Macro language, it was decided to write a control mechanism in SAS.
The implemented mechanism performs such simple actions as: getting a new table from the queue, starting the Backup component, sending the dump table to the backup site, starting the Restore component. In addition to this, multithreading is implemented, despite the fact that the number of threads can be adjusted for each type of task (Backup, transport, Restore, transfer of buckups to storage systems), and of course, such necessary functionality as journaling and e-mail notifications .
Implementing the Backup Component
The Backup component, for the transferred table, calls the gp_dump utility. We get dump tables spread over the Greenplum segment servers of the main site. An example of calling the gp_dump utility:
gp_dump --username=gpadmin --gp-d=$DIRECTORY --gp-r=$REPORT_DIR $COMPRESS -t $TABLE db_$DWH_DP_MODE &> /tmp/gp_dump_$NOW
Implementation of the transport component
The main task of the transport component is to quickly transfer dump files from the Greenplum segment server of the main site to the corresponding Greenplum server segment of the backup site. Here we are faced with a network limitation, namely: segments of the main circuit do not see backup circuit segments on the network. Thanks to the knowledge of our DWH administrators, we came up with a way how to get around this using SSH tunnels. SSH tunnels were raised on the Greenplum secondary master servers of each circuit. Thus, each piece of the table dump was transferred from the segment server of the main site to the server segment of the backup site.
Implementations of Restore Components
After the shutdown of the transport component, we get a dump table spread over the Greenplum segment servers of the backup site. For this table, the Restore component runs the gp_restore utility. As a result, we get an updated table on the reserve site. The following is an example of calling the gp_restore utility:
gp_restore $COMPRESS --gp-d=$SOURCE --gp-r=$REPORT_DIR --gp-k=$KEY -s --status=$SOURCE -d db_$DWH_DP_MODE > /tmp/gp_restore_$(echo $KEY)_$RAND 2>>/tmp/gp_restore_$(echo $KEY)_$RAND
Monitoring implementation
After the development of the main components and the first launches were completed, we got a generally working system. Tables were set up on a backup site, journaling worked, letters came to the post office and it seemed like the system worked, but we did not have a transparent understanding of what was happening inside at a particular moment in time. We were concerned about the monitoring issue, which was divided into two steps: allocation of metrics for monitoring the system and the technological component of monitoring implementation.
Metrics were identified quite quickly, which, in our opinion, should have unambiguously made it clear on a specific point in time what is happening in the system:
- The number of objects in statuses;
- The number of errors in statuses;
- Lag from the moment of getting into the queue;
- Delay at the start of the stage;
- The average duration of the stage (for the last 10 objects);
- As well as monitoring the number of working threads at each stage.
We also decided on the technical implementation quite quickly - Graphite + Graphana. Deploying Graphite on a separate virtual machine and programming the invented metrics was easy. And with Graphana, a beautiful dashboard was developed on working Graphite.
All of the above metrics have found visualization and, not least important, onlineness:
Fig. 2 Number of objects in statuses
Fig. 3 Number of errors in statuses
Fig. 4 Lag from the moment of getting into the queue
Fig. 5 Delay at the start of the stage
Fig. 6 Average stage duration (for the last 10 objects)
Fig. 7 The number of working threads at each stage
Post processing
After the restore process is completed, dump files are transferred to the storage system, on the backup site. Replication is configured between the storage on the backup site and the storage on the main site, this replication is based on NetApp SnapMirror technology. Thus, if a failure occurs on the main site that requires data recovery, we already have a prepared backup for storage for these works.
Summary
What we got
The system was developed and everything turned out not very bad. The tasks that the system was intended to solve are completely closed to it. After the development was completed, a number of regulations were developed that allowed the transition to the backup site as part of the DWH support process.
The main thing that we got is, of course, the ability to move to the backup site within 30 minutes in the event of a failure on the main one, which significantly minimizes the simple DWH as an information system and as a result enables the business to continuously work with reports and data for analysis, performing ad- hoc and do not stop a number of online processes. The system also allowed us to abandon the daily routine backup procedure, in favor of the backup received by the Dual ETL system.
Work statistics
About 6,500 objects (tables) pass through the system per day with a total volume of about 20 TB .
On the example of the metric "Lagging from the moment of getting into the queue" (see Fig. 8)
Fig. 8 Lag
behind the moment of getting into the queue, you can observe the backlog of the backup site from the main one. During the work of the night scheduler, when the ETL is actively building a warehouse, the lag in peak reaches 2-3 hours. By the time the storage is completed, at 10 in the morning, the backlog is reduced and remains at the level of 5-10 minutes. During the day, lag bursts may appear during the online scheduler, within 30 minutes.
And also, relatively recently, our system has had a small anniversary, a 1,000,000 (millionth) object flew through it !
Epilogue
The DWH team at Tinkoff Bank takes a strategic course towards Hadoop. In future articles, we plan to cover the topics “ETL / ELT on Hadoop” and “Ad-hoc reporting on Hadoop”.