Networks for the smallest. Part ten. Basic MPLS
The network of our imaginary company linkmeup is growing. She already has trunk lines in various cities, a client base and an excellent staff of engineers who grew up on the SDSM cycle.
But all is not enough for them. Broadband services are good and necessary, but there is still a huge potential market for corporate clients who need a VPN.
The guys thought about it, puzzled and came to the conclusion that there is no way to do without MPLS.
If multicast was the first topic that required some restructuring of the understanding of IP networks, then, when studying MPLS, you will definitely have to forget almost everything that you knew before - this is a special world with its own rules. Today in the issue:

And we start with the question: “What is wrong with IP?”
Traditional video
And really, what's wrong? Why fence MPLS?
Yes, that's right. The strengths and weaknesses of IP stem from the fact that it appeared later than classic networks and is incredibly flexible. Nowadays, there is a transition to packet switching everywhere, which is based on IP at the network level, and on the channel Ethernet is gaining more and more popularity.
This is good, because now on the basis of one backbone network and access network you can provide broadband access , IP-telephony, IPTV and other possible services.
The same can be seen in the networks of mobile operators. Second generation networks at the dawn were entirely based on circuit switching. The core of 3G networks is for the most part IP, but telephony services can still be provided in circuit-switched mode. 4G networks are already full-fledged IP networks, where voice transmission is only one of the applications, as well as broadband access.
However, there are still a huge number of segments where old technologies are used. For example, somewhere there is ATM, in another place you need to transfer PDH from one part of the network to another, and then the client wanted his piece of Ethernet-network to be accessible from the other end of the city as if it was connected directly - in other words, VPN.
As it was decided before: we need an ATM between two geographical points - a build channel between them based on ATM, PDH - a build of PDH.
But you want to do all this through one network, and not build a separate one for each type of traffic.
For this, GRE, PPPoE, PPPoA, ATM over Ethernet, TDM over IP and many other overs were invented at the time. You can create another thousand others to cover all the combinations already, and universal happiness will come in the chaos of standards ( by the way, some small manufacturers have chosen this path ).
In the mid-90s, it occurred to the hotheads of several companies (IBM, Toshiba, Cisco, Ipsilon) to create a mechanism that would allow them to look not at the inside of the packet while routing and comb the routing table in search of a better way, but to navigate by some label. Shot at Cisco, and the mechanism was named plain: TAG Switching.
Moreover, the goal pursued by the developers was to allow high-speed switches to transmit traffic exclusively in hardware. The fact is that hardware IP routing has long been an inaccessible pleasure, and it was impractical to use it on inexpensive switches, and making a decision based on a tag could be simple and quick.
But at the same time, super-large integrated circuits appeared (even though I do not agree with this term - English VLSIdescribes the essence much better), and the task of saving on the analysis of the contents of the package has become not so urgent. In addition, the concept of FIB appeared, which suggests that for each packet it is not necessary to search for a destination in the routing table and, accordingly, involve a central processor - all the hot information is already on the line card.
That is, in fact, the need for such a mechanism has disappeared.
But suddenly it became clear that label switching has unplanned potential - it does not matter what is under the label - IP, Ethernet, ATM, Frame Relay. And it also gives you the opportunity to get rid of the limitations of IP routing.
The technology approved by IETF - MPLS - MultiProtocol Label Switching originates from here. It was the 1997th year.
And this seemingly insignificant detail gave rise to a new era in telecommunications. Today you will find MPLS in any more or less large provider.
The main applications of MPLS now:
We will talk about each of them in separate articles - these are monstrously huge topics. But briefly we will touch upon them at the end of the article.
Pure MPLS alone is rarely used. The performance gain is insignificant, because the difference between glancing at the FIB / changing some fields in the headers and looking at the table of labels / changing the label in the MPLS header is not that big. Of course, its applications listed above are used.
But in this article, we still concentrate on pure MPLS to understand how it works in its most basic form.
Below we will also consider one application of pure MPLS.
Despite the fact that MPLS is not tied to the type of network on which it will operate, in our time it lives in symbiosis only with IP. That is, the network itself is built on top of IP, but at the same time it can transfer data from many other protocols.
But let's get to the point already, and first I want to say that MPLS does not replace IP routing , but works on top of it.
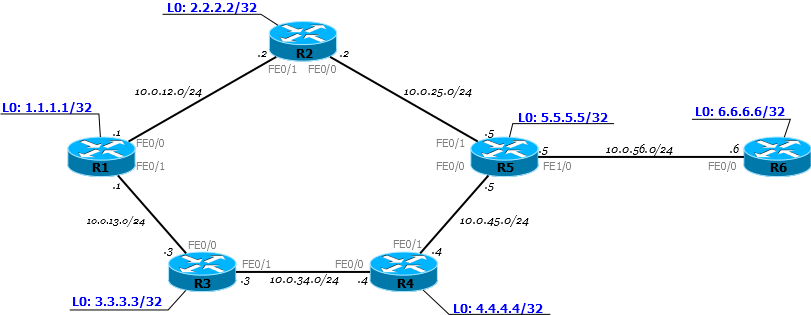
To be more specific, I will take such a network.

Now it is in full working condition, but without any hint of MPLS. That is, R1, for example, sees R6 and can ping its Loopback.
PC1 sends an ICMP request to server 172.16.0.2. An ICMP request is an IP packet. On R1, according to the basic principles, the packet leaves through the FE0 / 0 interface on R2 - the Routing Table said so.
After receiving the packet, R2 checks the destination address, looks at its FIB, sees the next router and sends the packet to the FE0 / 0 interface.
And this process is repeated over and over again. Each router independently decides the fate of the packet.
This is how traffic dump looks quite familiar:

What happens if we activate MPLS? Right now, at that very moment the world is changing. After that, label tables are populated on the routers and multiple LSPs are built.
And now the same path will be done a little differently.
When the IP packet from PC1 enters the MPLS network, the first router hangs up a label, then this packet goes to the destination, and each subsequent router changes one label to another. When you exit the MPLS network, the label is removed and then a clean IP packet is transmitted, as it was at the very beginning.
This is the basic principle of MPLS - routers switch packets by labels, without looking inside the MPLS packet. The first one adds, the last one deletes.
Let's take a look at the step-by-step transfer of a data packet from PC1 to the destination node:
1. PC1 - a regular computer - sends a regular packet to a remote server.
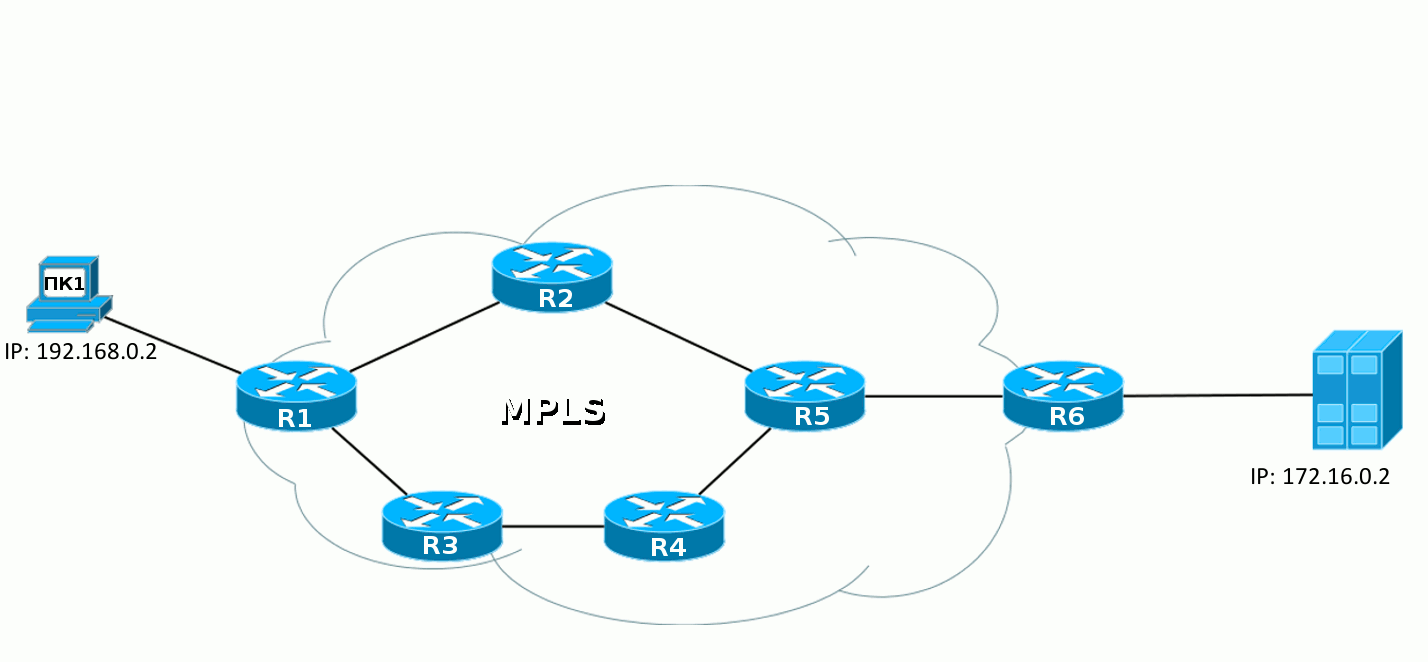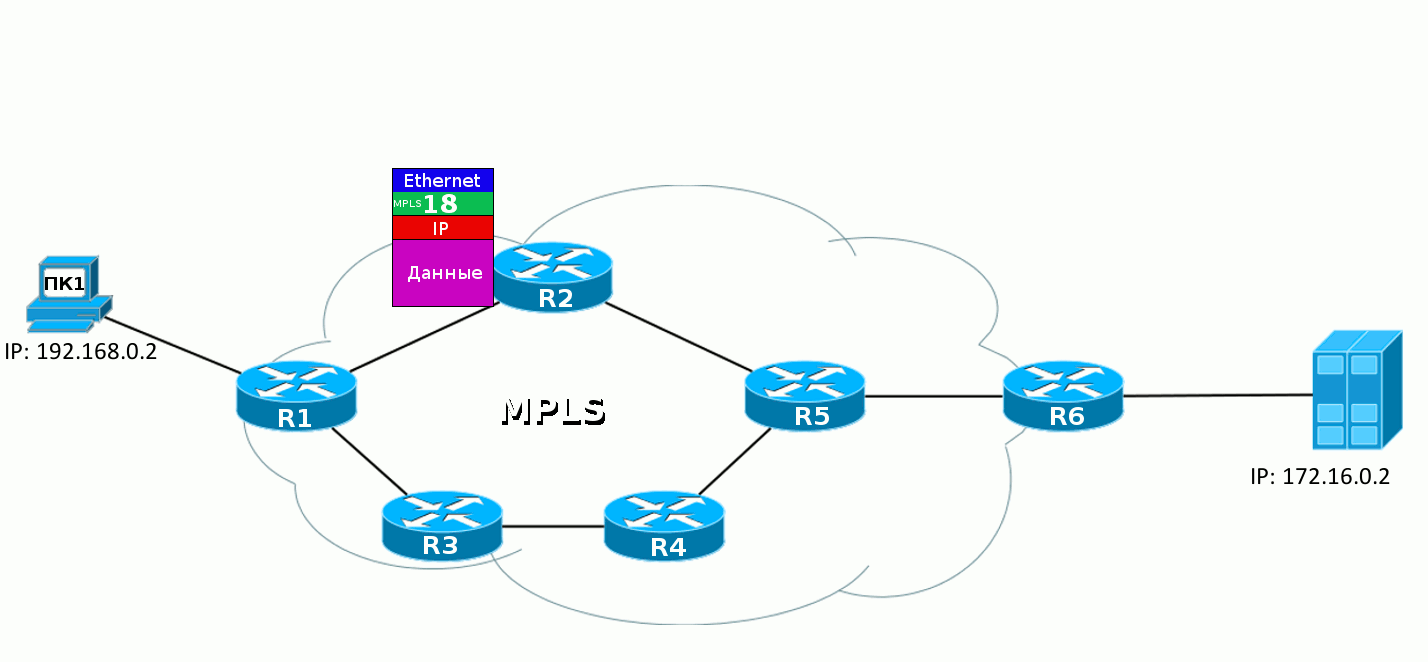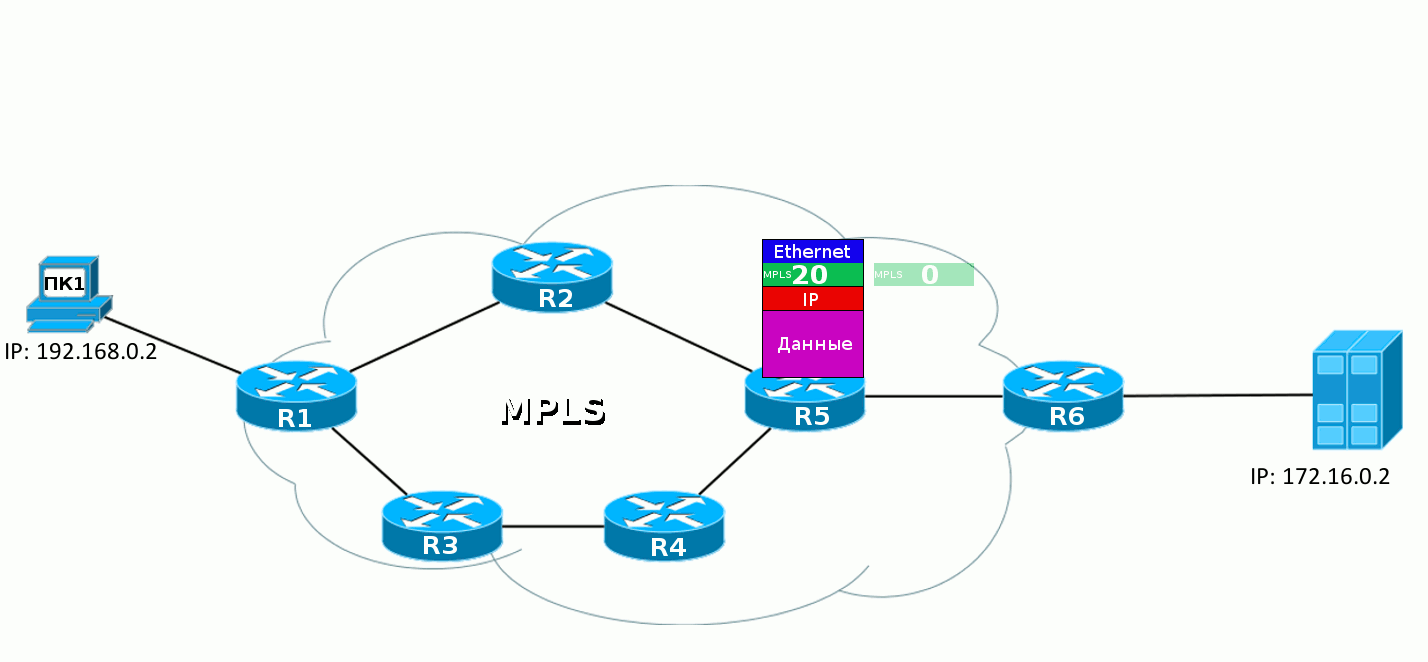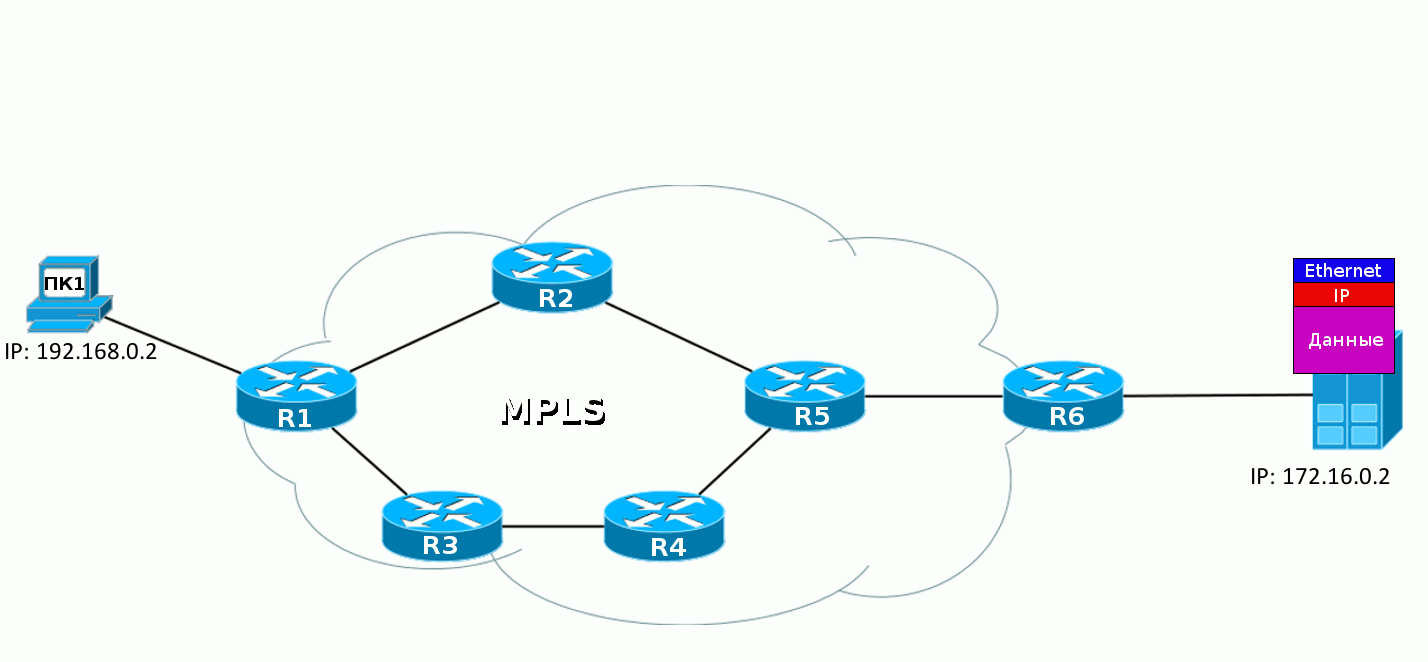
2. The package comes to R1. It adds a label of 18. It is inserted between the IP header and Ethernet.
He can take this information from the FIB:
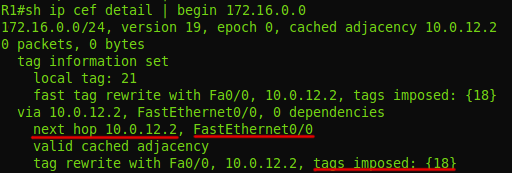
FIB shows that the packet with the destination 6.6.6.6 must be labeled 18 and sent to the FE0 / 0 interface .
Actually, he does this: he adds a header and writes 18: A

dump between R1 and R2 .
3. R2 receives this packet, in the Ethernet header sees that it is an MPLS packet (Ethertype 8847), reads the label and refers to its label table:


We read the letters: if the MPLS packet came with a label of 18, you need to change it to 20 and send the packet to the FE0 / 0 interface.

Dump after R2.
4. R5 performs similar actions - sees that a packet with label 20 has arrived, it must be changed to 0 and sent to FE1 / 0. Without any reference to the routing table.
5. R6, having received the MPLS packet, sees in its table that now the label must be unchecked. And having removed it, he sees already that the packet destination - 172.16.0.2 - is a Directly Connected network. Further, the packet is transmitted in the usual way along the routing table without any labels.
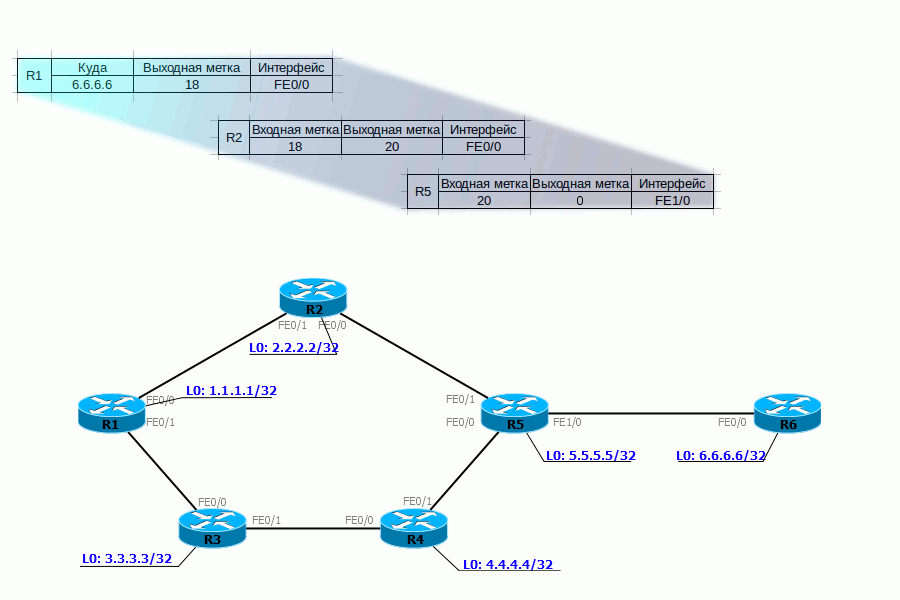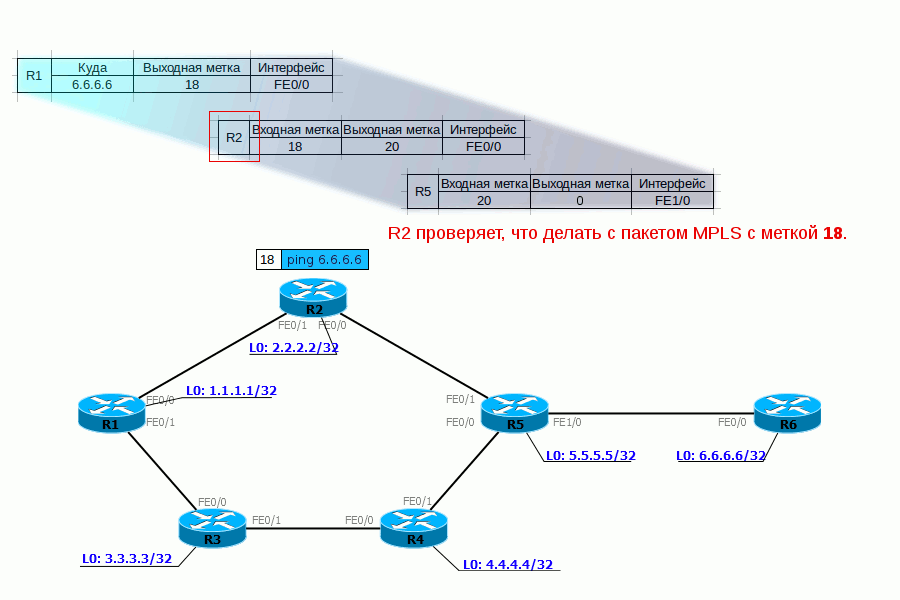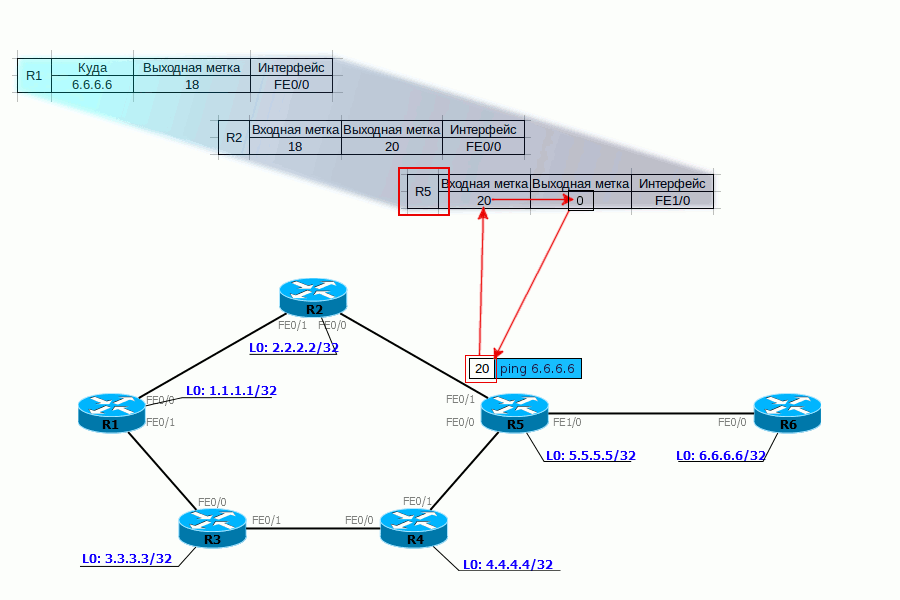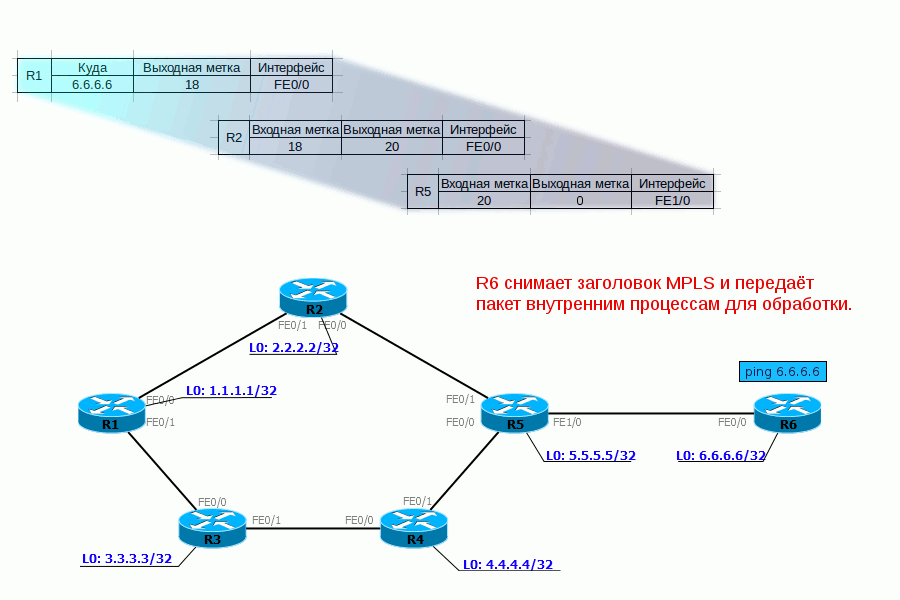
We will not consider the end nodes, so as not to complicate the scheme.
So far, everything seems to be simple, although it is not clear why.
Now the IGP and MPLS domains coincide and MPLS only promises us some goodies in the future: L2VPN, L3VPN, MPLS TE.
But, in fact, even basic MPLS gives us advantages if we recall that we are a provider.
As a provider, we do not use IGP protocols for routing between ASs. For this we use BGP. And it is in conjunction with BGP that the benefits of MPLS will become clear.
Consider our network in conjunction with neighboring ASs:
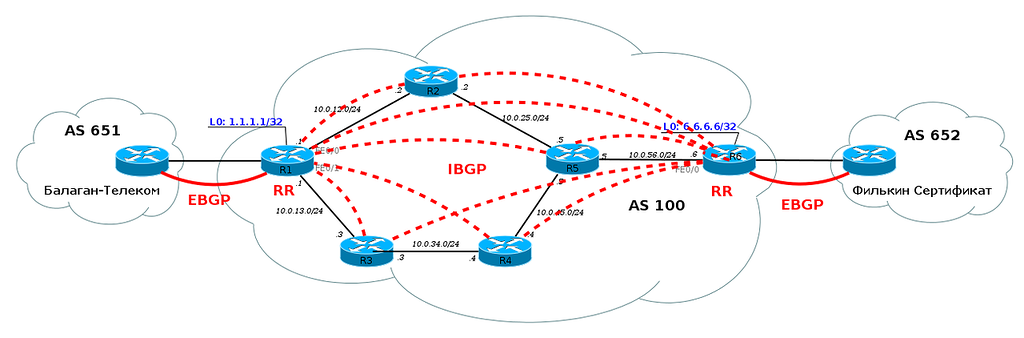
From the BGP release, we know that BGP must be configured on each router in our AS. Otherwise, we will not be able to transmit traffic to neighboring ASs and our customers through our AS. Each router must know all the routes.
But that was before MPLS!
When MPLS is configured on our network, we no longer need to configure BGP on each router in the network. It is enough to configure it only on the border routers in the AS, on those that are connected to other clients or providers.
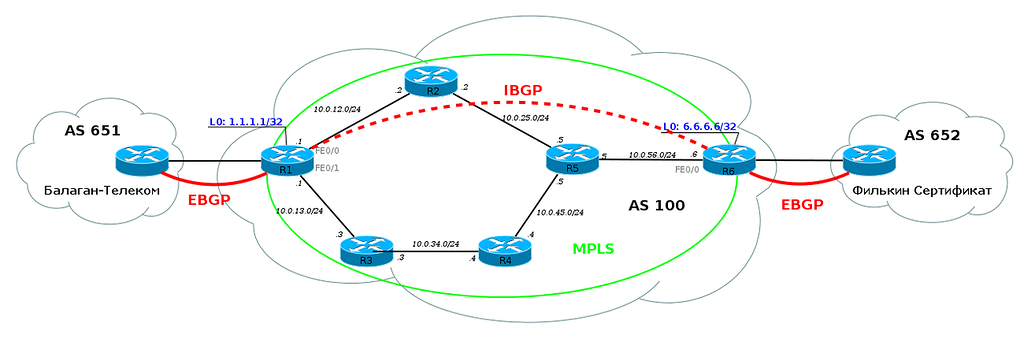
But this is not all good news. In addition to the fact that BGP can no longer be configured on every router in the AS, routers also do not need to create a label for each BGP prefix. It is enough to know how to get to the IP address, which is listed as next-hop. That is, if a BGP session is configured between Loopback0 R1 and Loopback0 R6, then nothing will change in the label table, even if each of them sends hundreds of thousands of routes via BGP:
For example, several routes came from router R6 via BGP from router R6:

Let's see how packets that go to the network 100.0.0.0/16 will be processed:

In the output above it is clear that the label 27 will be added to the packets.
And, if you look at the label table, then there are no labels for routes that are known by BGP, but there are label 27 and it corresponds to 6.6.6.6/32. And this is exactly the address that we saw in the routes that came via BGP from R6:

You can find an example of configuration below .
We ran a little ahead, but now that it has become clearer what advantages even basic MPLS provides, we can plunge into the conceptual apparatus in the world of MPLS.
Label - label - a value from 0 to 1,048,575. Based on it, LSR decides what to do with the packet: what new label to hang, where to send it.
It is part of the MPLS header.
Label Stack - a stack of tags. Each package can carry one, two, three, and at least 10 tags - one above the other. The decision on what to do with the package is made based on the top label. Each layer plays some role.
For example, when transmitting a packet, a transport label is used, that is, a label organizing transit from the first to the last MPLS router.
Others may carry information that this packet belongs to a particular VPN.
In this release, there will always be only one label - no more is needed yet.
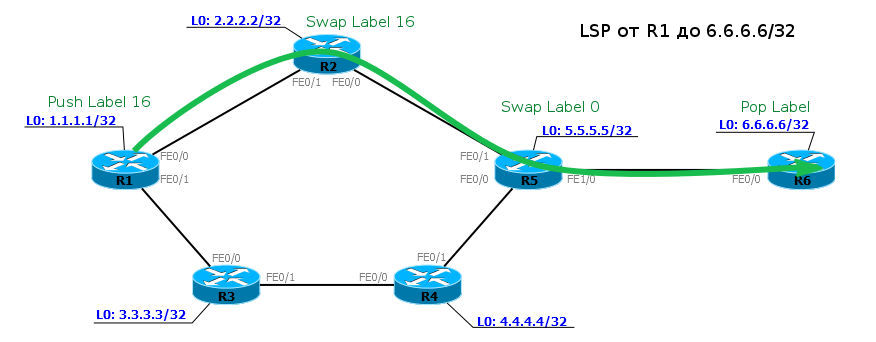
Push label- the operation of adding a label to the data packet is performed at the very beginning - on the first router in the MPLS network (in our example, R1).
Swap Label - label replacement operation - occurs on intermediate routers in the MPLS network - the node receives a packet with one label, changes it and sends it from another (R2, R5).
Pop Label - label removal operation - performed by the last router - the node receives the MPLS packet and removes the top label before passing it on (R6).
LSR - Label Switch Router is any router in an MPLS network. It is called like that because it performs some operations with labels. In our example, these are all nodes: R1, R2, R3, R4, R5, R6.
LSR is divided into 3 types:
Intermediate LSR - an intermediate MPLS router - it performs the Swap Label operation (R2, R5).
Ingress LSR - “input”, the first MPLS router - it performs the Push Label (R1) operation.
Egress LSR - "output", the last MPLS router - it performs the Pop Label (R6) operation.
LER - Label Edge Router is a router on the edge of the MPLS network.
In particular, Ingress LSR and Egress LSR are boundary, which means they are also LER.
LSP -Label Switched Path - label switching path. This is a unidirectional channel from Ingress LSR to Egress LSR, that is, the path that the packet will actually go through the MPLS network. In other words, it is an LSR sequence.
It is important to understand that LSPsare actuallyunidirectional. This means that, firstly, traffic on it is transmitted only in one direction, secondly, if there is “there”, there is not necessarily “back”, and thirdly, “back” does not necessarily go along the same path, that "go there." Well, it's like tunnel interfaces in GRE.
What does LSP look like?
Yes, it’s so unpresentable.
This is a compiled output from four LSRs - R1, R2, R5, R6. That is, on LSR you will not see a complete sequence of nodes from entry to exit, by the type of AS-PATH attribute in BGP. Here, each node knows only the input and output labels. But LSP does exist.
This seems a bit like IP routing. Despite the fact that there is a path from point A to point B, the routing table knows only the next node where traffic should be sent. But the difference is that LSR does not decide on each packet based on the destination address - the path is predetermined.
And one of the most important concepts to deal with is FEC - Forwarding Equivalence Class. For some reason it was given to me very hard, although in fact - everything is simple. FEC are traffic classes. In the simplest case, the class identifier is the destination address prefix (roughly speaking, the destination IP address or subnet).
For example, there are traffic flows from different clients and different applications that all go to the same address - all these flows belong to one class - one FEC - use one LSP.
If we take other streams from other clients and applications to a different destination address, it will be a different class and a different LSP, respectively.
If you pay attention to the label table, FEC is present there, since the label replacement parameters are determined exactly on the basis of FEC, but this is done only at the first moment in time - when these labels are distributed. When real traffic runs through LSP, no one but Ingress LSR looks at it - only labels and interfaces. Ingress LSR takes all the work on determining the FEC and in which LSP to send the traffic - after receiving a clean packet, it analyzes it, checks which class it belongs to and hangs the appropriate label. Packets of different FECs will receive different labels and will be sent to the corresponding interfaces.
Packets of the same FEC receive the same labels.
That is, intermediate LSRs are threshers that just do the switch for all transit traffic. And all the intellectual work is done by Ingress LSR.
LIB - Label Information Base - label table. An analogue of the routing table (RIB) in IP. It indicates for each input label what to do with the package - change the label or remove it and to which interface to send.
LFIB - Label Forwarding Information Base - similar to FIB - is the label base accessed by the network processor. When you receive a new package, there is no need to contact the CPU and do a lookup in the label table - everything is at hand.
One of the initial ideas of MPLS - to smash the Control Plane and Data Plane as much as possible - went into oblivion.
The developers wanted that when transmitting the packet through the router there was no analysis - just read the label, changed it to another, passed it to the desired interface.
To achieve this, there were just two separate processes - a relatively long construction of the path (Control Plane) and fast transmission of traffic along this path (Data Plane)
But with the advent of cheap chips (ASIC, FPGA) and the FIB mechanism, regular IP transmission also became quick and easy.
For a router, it does not matter where to look when transmitting a packet - in the FIB or in the LFIB.
But what is undoubtedly important and useful is that MPLS does not care about what is transmitted under its heading - IP, Ethernet, ATM. No need to fence GRE or some other uncomfortable VPN to pain in the joints. But let's talk about this again.
The entire MPLS header is 32 bits. The format of the fields and their length are fixed. Often the entire title is called a label, although this is not entirely true.

Label - the label itself. The length is 20 bits.
TC - Traffic Class. It carries the priority of the packet, like the DSCP field in IP.
The length is 3 bits. That is, it can encode 8 different values.
For example, when transmitting an IP packet through an MPLS network, the value in the DSCP field is associated with the TC value in a certain way. Thus, a packet can be processed almost equally in queues along its entire path, both in a pure IP section and in MPLS.
But, of course, this lossy conversion - six DSCP bits closely in 3 TC bits: 64 versus 8. Therefore, there is a special correspondence table where the whole range is just one value.
S - Bottom of Stack - indicator of the bottom of the 1-bit label stack. There may be several MPLS headers on a packet, for example, external for switching in an MPLS network, and internal indicates a specific VPN. So that LSR understands what it is dealing with. In bit S, “1” is written if this is the last mark (the bottom of the stack is reached) and “0” if the stack contains more than one mark (not yet the bottom). That is, LSR does not know how many total labels are on the stack, but it knows if it is one or more - and this is actually enough. After all, any decisions are made on the basis of only the topmost label, regardless of what is under it. But, removing the label, he already knows what to do next with the package: continue working with the MPLS process or give it to some other one (IP, Ethernet, ATM, FR, etc.).

In general, the stack here in the classical sense is the last to be put, the first to be taken (LIFO - Last Input - First Output).
As a result, in spite of the fact that the MPLS header length is fixed, there can be many headers themselves - and they are all located one after another.
TTL - Time To Live - A complete counterpart to IP TTL . Even the same length has - 8 bits. The only task is to prevent the packet from wandering endlessly over the network in the event of a loop. When transmitting an IP packet over an MPLS network, the IP TTL value can be copied to the MPLS TTL, and then back. Or the countdown will start again from 255, and when entering a clean IP network, the IP TTL value will be the same as before entering.
As you can see, the MPLS header is squeezed between the data link layer and the data that it carries - in the case of IP - network. Therefore, metaphorically, MPLS is called Layer 2.5 technology, and the header, Shim-header, is the wedge-header.
By the way, the label does not have to be in the MPLS header. According to the IETF, it can be embedded in ATM, AAL5, Frame Relay headers.
Here's what it looks like in life:

As mentioned above, 2 ^ 20 tags can exist.
Of these, several are reserved:
0 : IPv4 Explicit NULL Label . "Explicit blank label." It is used on the very last MPLS span - before the Egress LSR - in order to notify him that this mark 0 can be removed without looking at the label table (more precisely, LFIB).
For those FECs that originate locally (directly connected), the Egress LSR selects the 0 mark and passes it to its neighbors - the penultimate LSR (Penultimate LSR).
When transmitting a data packet, the penultimate LSR changes the current label to 0.
When Egress LSR receives the packet, it knows for sure that the top label simply needs to be deleted.
1 : The Router Alert Label - an analogue of the Router Alert option in IP - can be anywhere except the bottom of the stack. When a packet arrives with such a label, it must be passed to the local module, and then it is switched according to the label that was lower - the real transport one, and label 1 must be added to the top of the stack again.
2 : IPv6 Explicit NULL Label - the same as 0, only adjusted for the IP protocol version.
3 : Implicit Null . A dummy label that is used to optimize the process of transmitting an MPLS packet to an Egress LSR. This label may be advertised, but is never used in the MPLS header in reality. Consider it later.
4-15 : Reserved.
Depending on the vendor, other label values can be fixed, for example, on Huawei equipment, tags 16-1023 are used for static LSPs, and all that is higher in dynamic ones. At Cisco, available tags start at the 16th.
In general, it became clear how traffic is transmitted and how MPLS tags are involved.
But the tags are not taken from the bulldozer - no one needs additional chaos on the eve of the New Year. Special protocols distribute labels between the Egress LSR and Ingress LSR, creating an LSP.
Firstly, as you already understood, on some devices you can do everything manually - instill zeal and diligence!
But in the era of automatic washing machines, there are three basic protocols for distributing tags - LDP, RSVP-TE and MBGP.
In short, LDP - the easiest and most intuitive way - relies on the routing information of nodes. RSVP-TE, an evolution of the once-developed but unpopular RSVP protocol, is used by MPLS-TE to build LSPs that satisfy certain conditions. For its work, IGPs supporting Traffic Engineering (OSPF, ISIS) are needed.
MBGP is a close relative of BGP, but it is a protocol from a slightly different history, it passes labels for other purposes. Therefore, it stands apart from LDP and RSVP-TE.
Let's talk about each of them, but before that a few words about how LSR handle labels in general.
The first obvious fact is that the labels propagate from the recipient of the traffic to the sender, and more precisely from Egress LER to Ingress LER. The first non-obvious fact - in MPLS, Downstream is from sender to receiver, and Upstream from receiver to sender. I defined it for myself as follows: LSP “grows” from FEC up to Ingress LER, like a tree, and user traffic “descends” to the recipient via LSP, like rainwater along branches. That is, tags are distributed towards traffic.
They also say that LSP is built to meet the traffic.
The label distribution mechanism itself depends on the protocol, settings, and manufacturer.
Firstly , the router can distribute tags to all its neighbors immediately and without any unnecessary questions, and it can issue them on request from higher ones (we remember, yes, which direction is called Upstream?)
The first mode is called DU - Downstream Unsolicited . As soon as the LSR learns about FEC, it sends out labels to this FEC to all its MPLS neighbors.
It looks something like this:
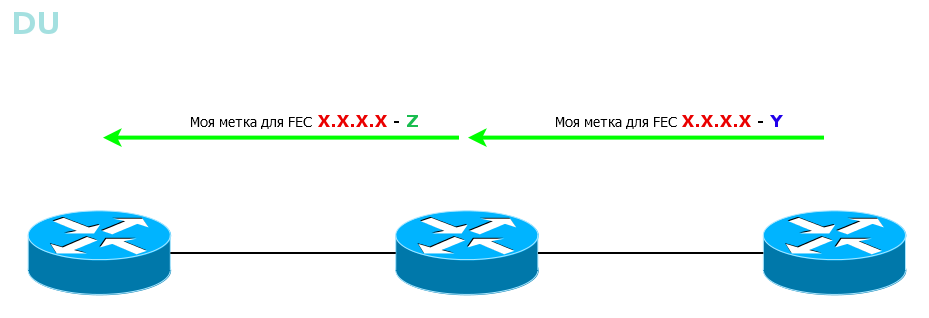
All LSRs learn about all FECs in every possible way. At first, matching the FEC tag diverges across the network from neighbor to neighbor, much like it does with BootStrap messages in PIM SM. And then each LSR selects only the one that came along the best path and uses it for the LSP - the same way Reverse Path Forwarding worksin the same PIM SM .
Quickly, simply, understandably, although it is not always necessary for everyone to know about everything.
The second mode is DoD - Downstream-on-Demand . LSR knows FEC, it has neighbors, but until they ask what label is for this FEC, LSR remains silent.

This method is convenient when some requirements are imposed on the LSP, for example, in bandwidth. Why send a tag just like that if it is immediately dropped? Better, the higher LSR will ask the lower: I need a label from you for this FEC - and that one: “ok, on”.
The mode of marking is specific to the interface and is determined at the time of the connection. Both methods can be used on the network, but on the same line, neighbors must agree on only one specific one.
Secondly , the LSR can wait for the label of the FEC to come from the Egress LER before telling the upstream neighbors. Or he could send tags to FEC as soon as he found out about him.
The first mode is called Ordered Control. It
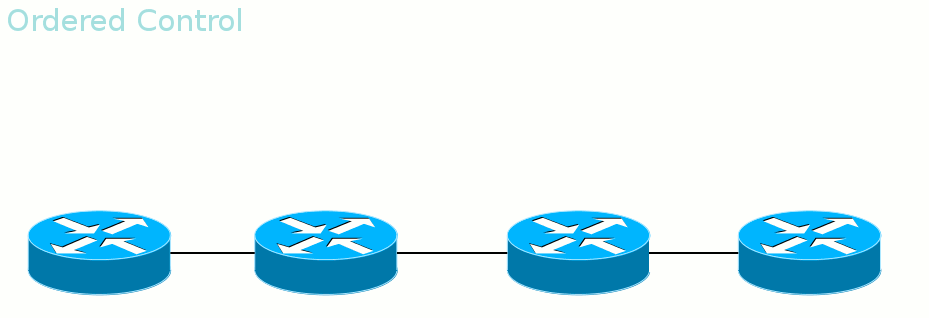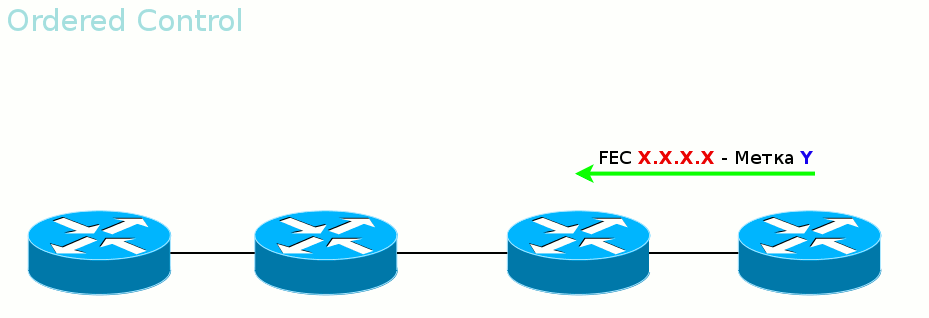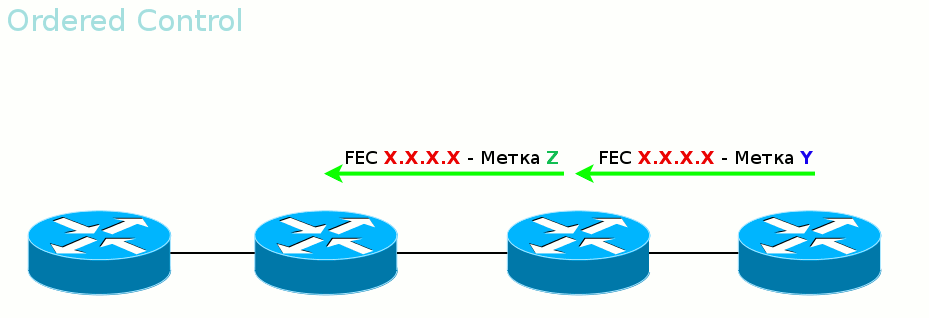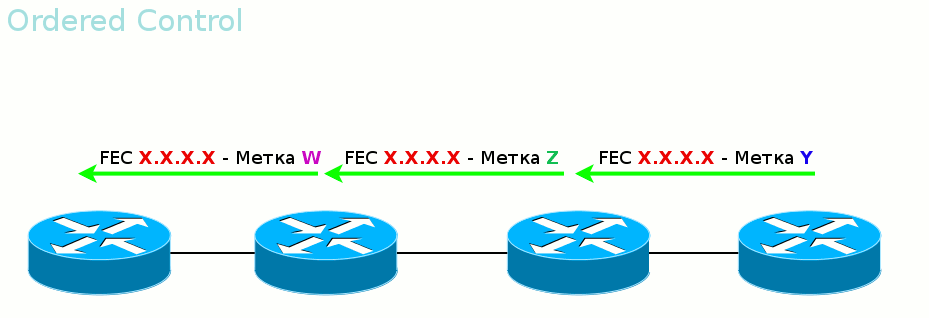
ensures that by the time data is transferred, the entire path up to the output LER will be built.
The second mode is Independent Control .
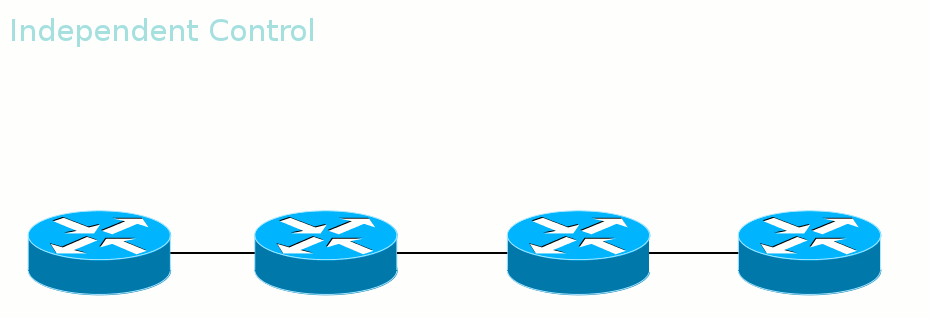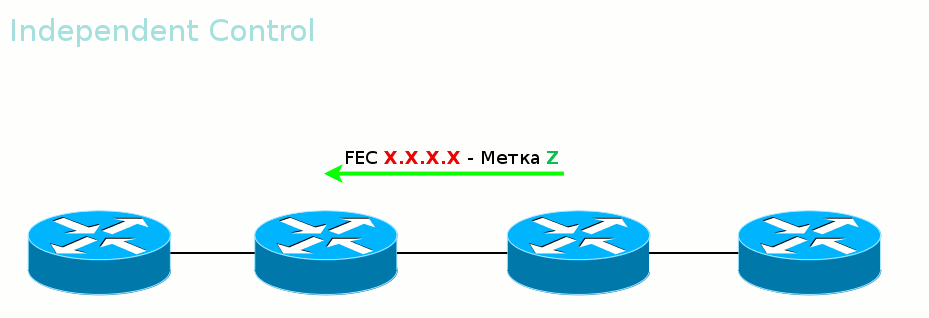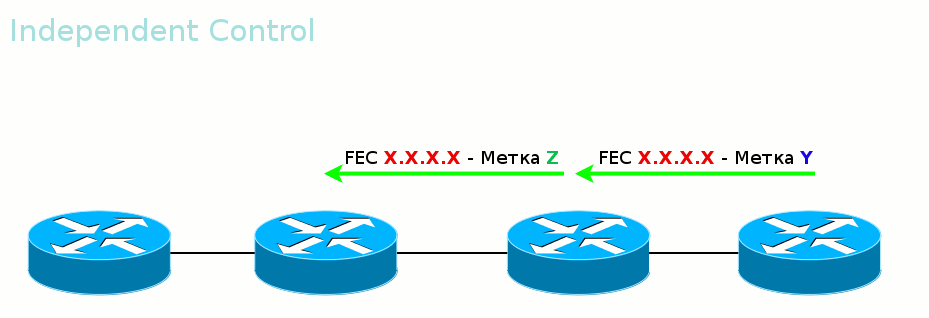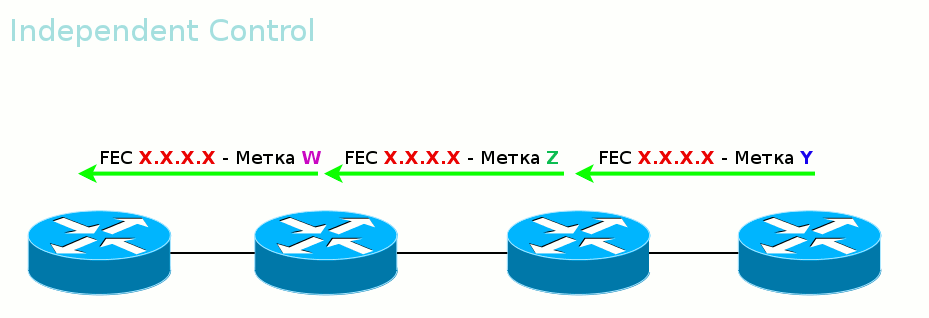
That is, tags are transmitted out of order. Convenient in that traffic can begin to be transferred even before the entire path is built. The same is dangerous.
Thirdly , it is important how the LSR handles the labels passed to it.
For example, in such a situation, should R1 store information about the label 20 received from the neighbor R3, which is not the best way to get to R6?

And this is determined by the label retention mode.
Liberal Label Retention Mode - labels are saved. In the case when R3 becomes the next step (for example, problems with the main path), the traffic will be redirected sooner because the label already exists. That is, the reaction rate is higher, but the number of labels used is high.
Conservative Label Retention Mode - an extra label is discarded as soon as it is received. This reduces the number of tags used, but MPLS will also respond more slowly in the event of an accident.
No, this is not the kind of PHP you thought about. It's about Penultimate Hop Popping . All engineers are a bit of optimizers, and here the guys thought: why do we need to process the MPLS headers twice - first on the penultimate router, then on the weekend.
And they decided that the label should be removed on the penultimate LSR and called this action - PHP.
There is a special label for PHP - 3.
Returning to our example, for FEC 6.6.6.6 and 172.16.0.2 R6 selects label 3 and reports it to R5.
When transferring a packet to R6, R5 must assign it a dummy label - 3, but in fact it does not apply and a bare IP packet is sent to the interface (it is worth noting that PHP only works on IP networks) - that is, the Pop Label procedure was performed on R5 .
Let's trace the life of the package taking into account everything that we now know.
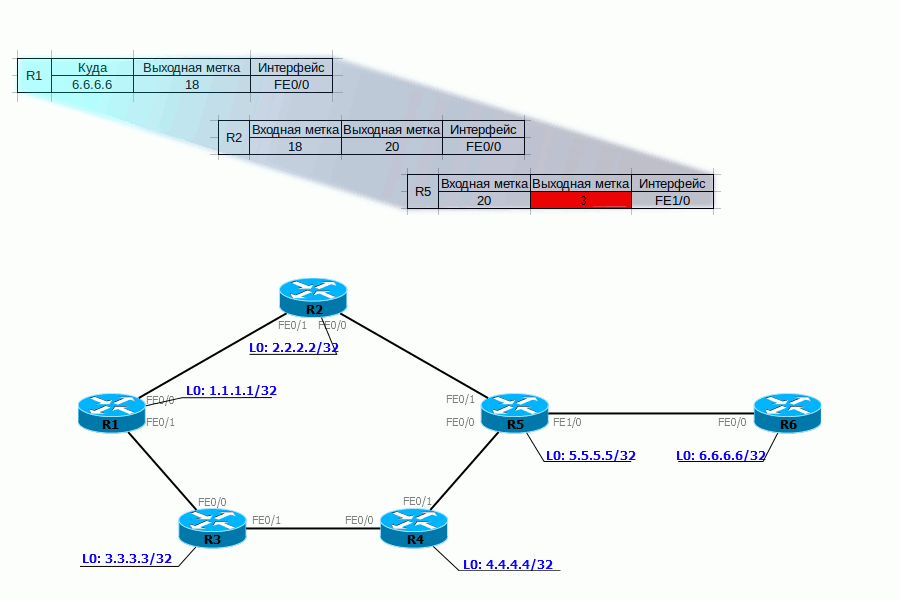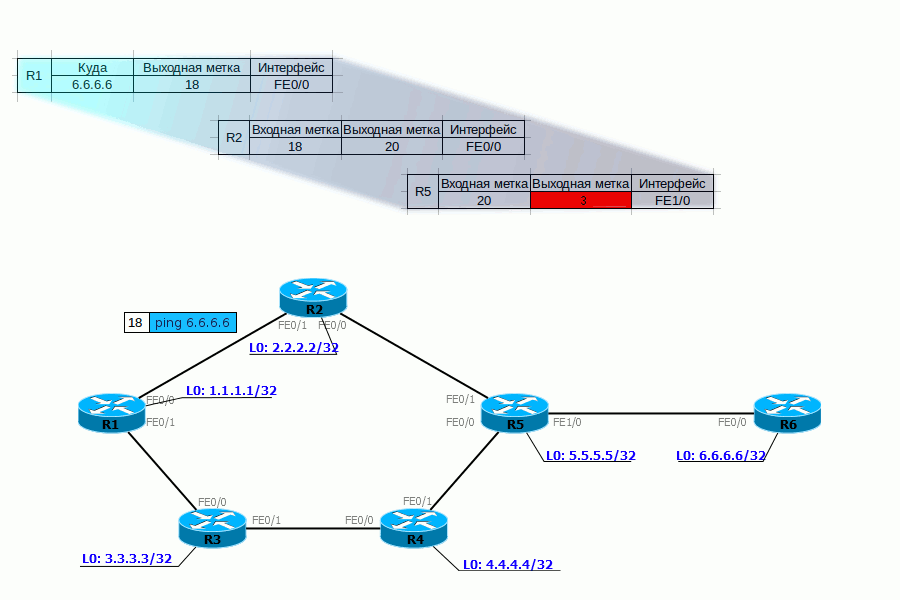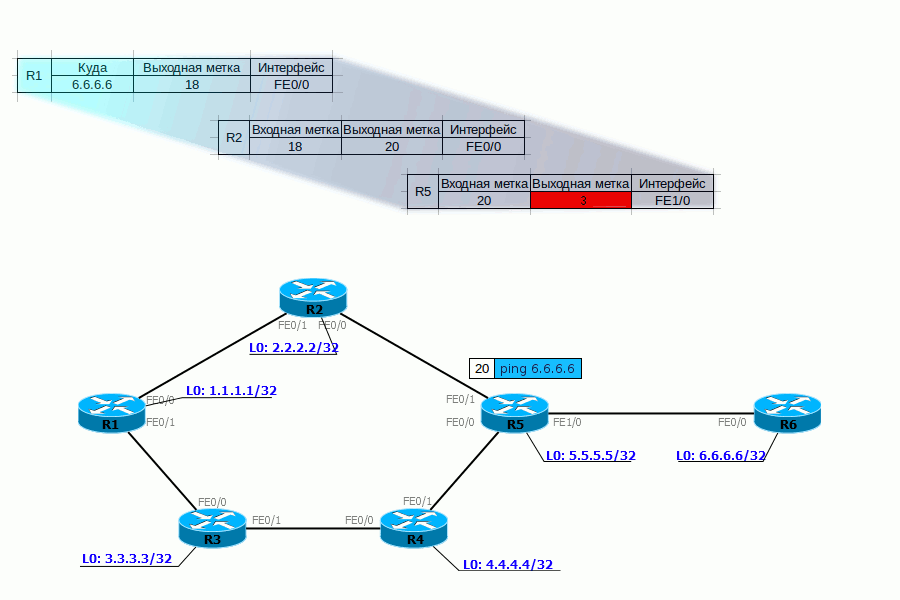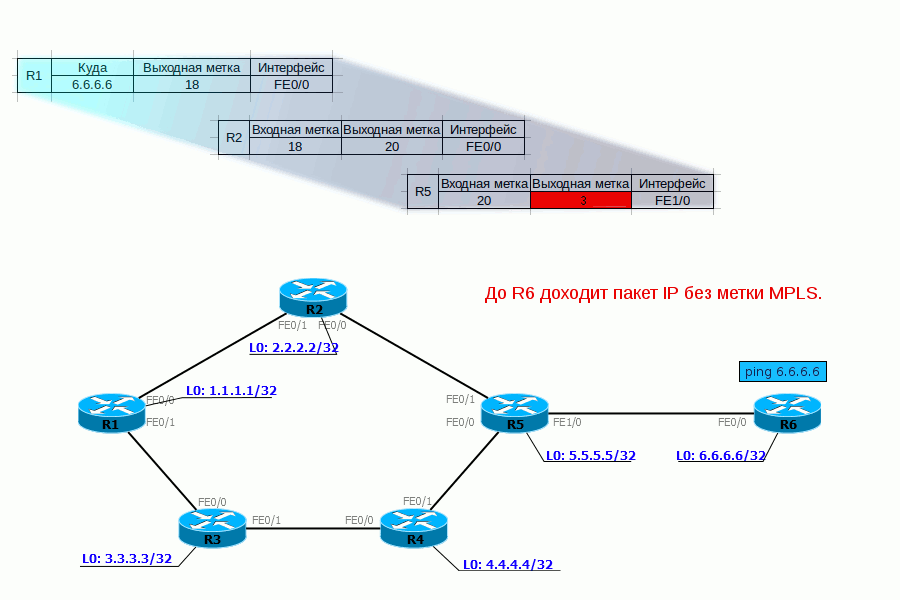
With how traffic is transmitted, it seems, more or less clear. But who does all the titanic work of creating labels, filling out tables?
There are not so many - three: LDP, RSVP-TE, MBGP.
There are two global goals - distribution of transport labels and distribution of service labels.
Let us explain: transport labels are used to transmit traffic over the MPLS network. These are just the ones we are talking about the entire issue. They use LDP and RSVP-TE.
Service tags are used to separate different services. Here MBGP and the process of LDP - tLDP enter the arena .
In particular, MBGP allows, for example, to note that such a route belongs to such a VPN. Then he passes this route, like vpn-ipv4 family, to his neighbor with a label so that he can later separate the flies from cutlets.
So, so that he can separate, he needs to be informed about the compliance of the label-FEC.
But this is the action of another play, which we will play in six months or a year.
A prerequisite for the operation of all dynamic label allocation protocols is the basic configuration of IP connectivity. That is, IGPs must be running on the network.
Well, now that I’ve completely confused you, you can begin to unravel.
So, what is the easiest way to distribute tags? The answer is to enable LDP.
The protocol with a very transparent name - Labed Distribution Protocol - has a corresponding principle of operation.
Consider it on the linkmeup network, which we’re covering the entire issue:

1. After turning on LDP, LSR multicast sends UDP datagrams to all interfaces to address 224.0.0.2 and port 646, where LDP is activated - this is how neighbors are searched.
The TTL of such packets is 1, because the LDP neighborhood is established between directly connected nodes.
These messages are called Hello .
2. When neighbors are discovered, a TCP connection is established with them, also on port 646 - Initialization . Further messages (except Hello) are already transmitted with a TTL of 255.
3. Now LSR periodically keep Keepalive messages addressed via TCP and still do not abandon attempts to find neighbors using Hello.
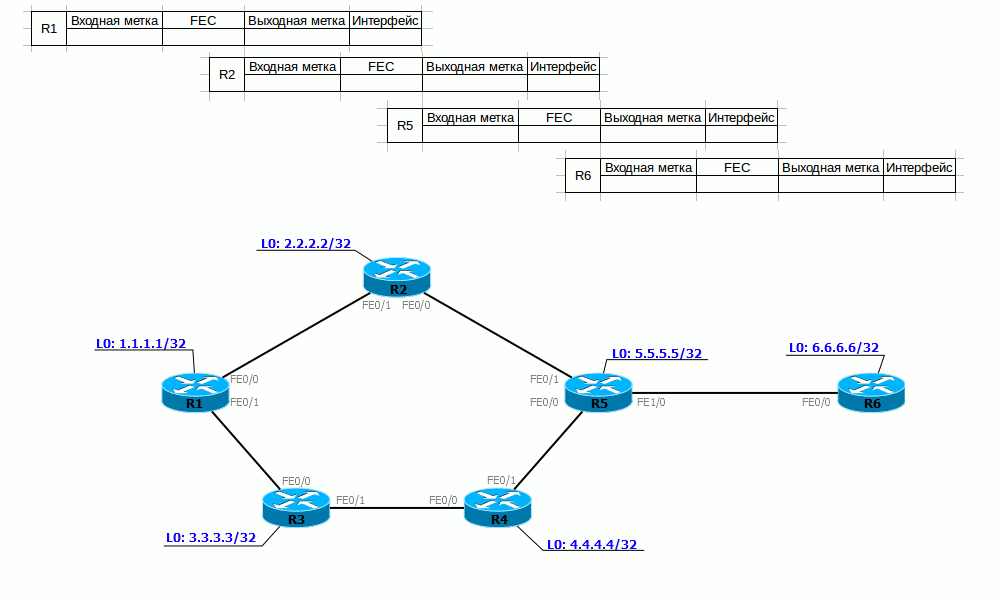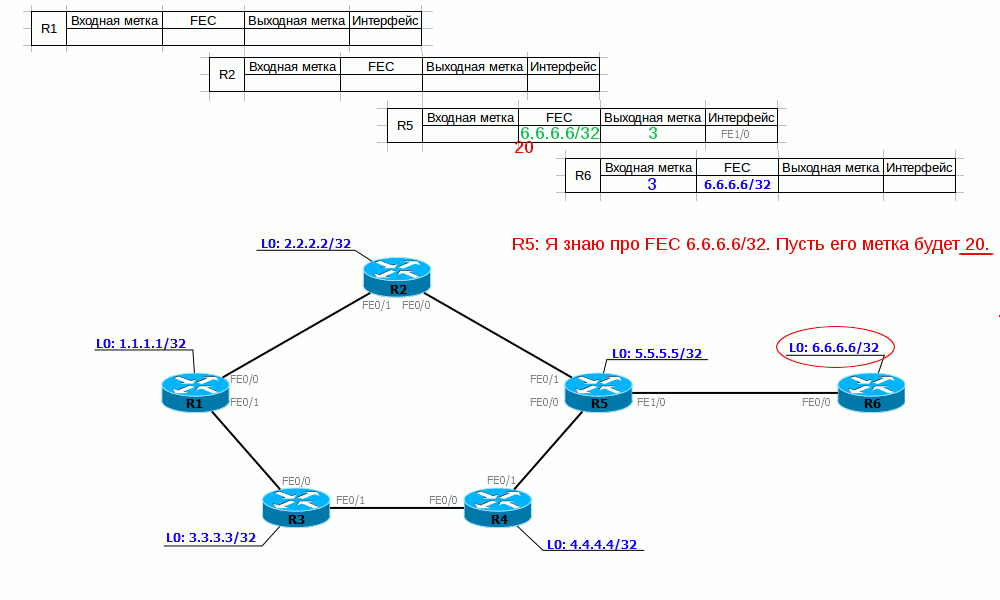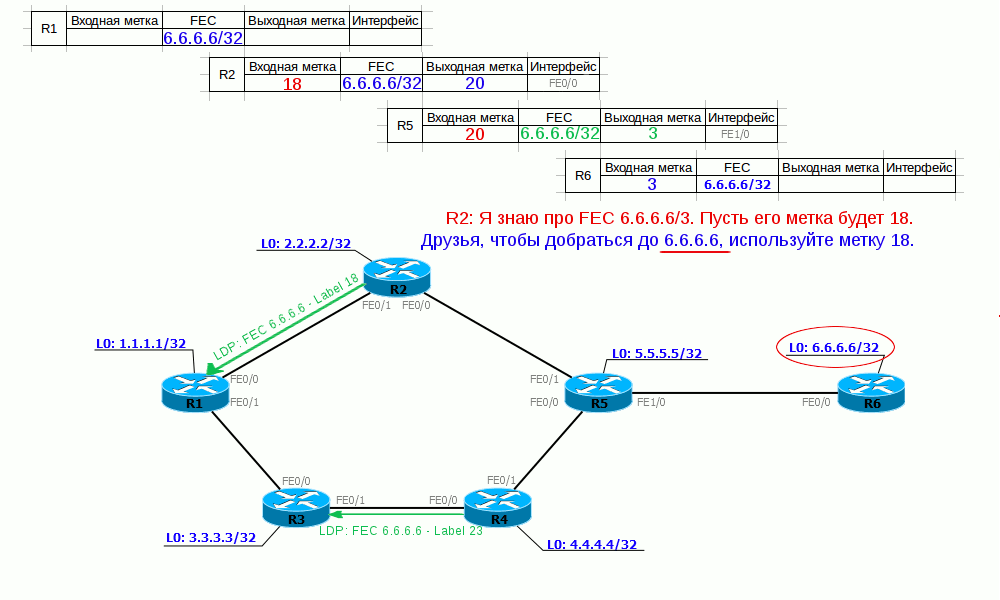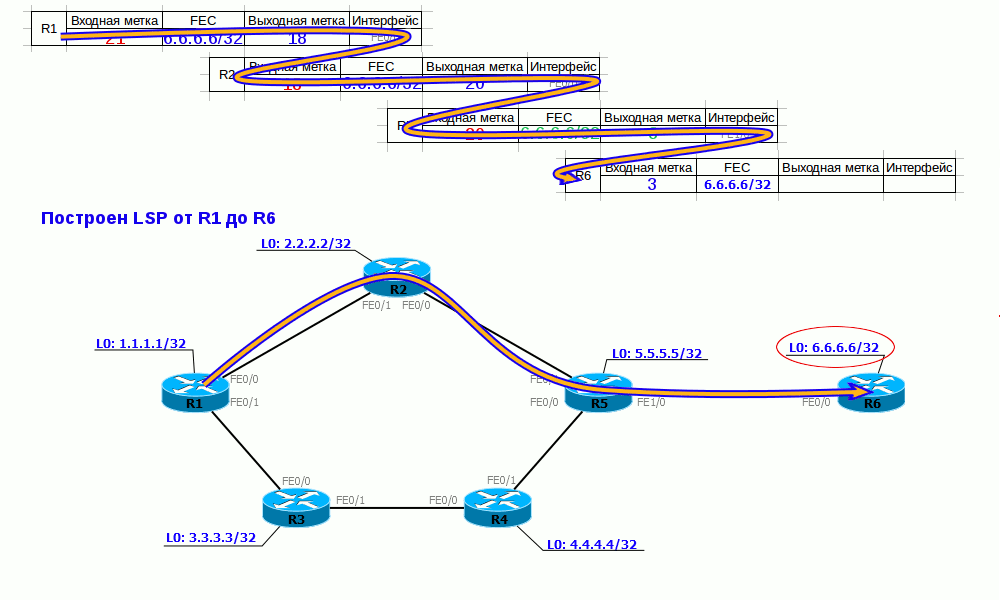
4. At some point, one of the LSR discovers within itself a second personality - Egress LSR - that is, it is the weekend for some FEC. This is a fact that needs to be reported to the world.
Depending on the mode, it waits for a label request for this FEC, or sends it right away.
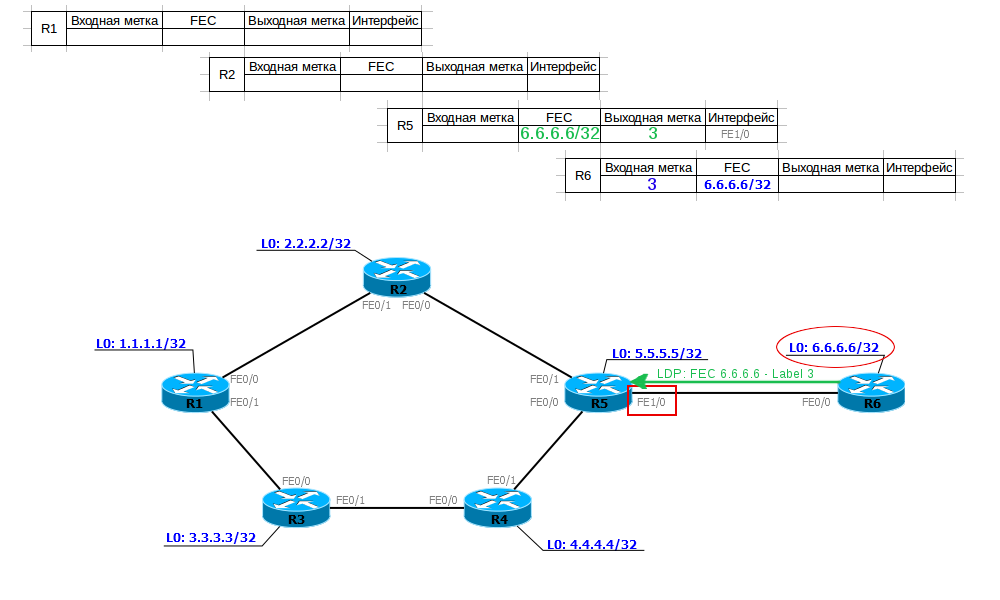
This information is transmitted in the message.Label Mapping Message . Based on the name, it carries in itself the correspondence of the FEC and the label.
R5 receives FEC 6.6.6.6/32 and label 3 (implicit null) compliance information and writes it to its label table. Now, when he needs to send data to 6.6.6.6, he will know that he needs to remove the upper MPLS header and send the remaining packet to the FE1 / 0 interface.
Then he selects the input label for the given FEC, writes this information to his label table and sends it to the higher neighbors.
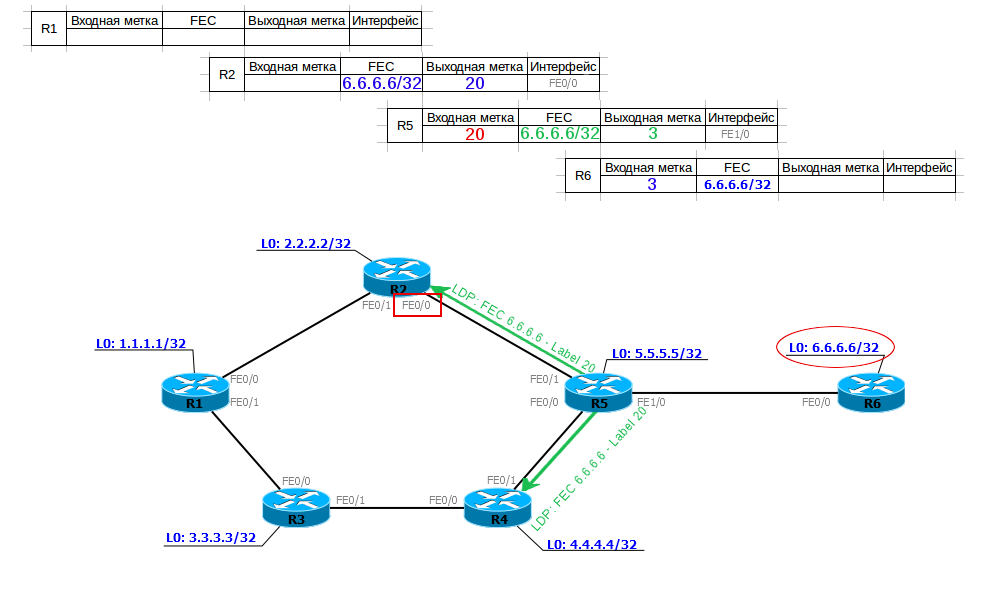
Now R5 knows that if an MPLS packet with a label of 20 has arrived, it must be transferred to the FE1 / 0 interface by removing the label, that is, by executing the PHP procedure.
R2 receives compliance information from R5 FEC-label (6.6.6.6 - 20), enters it into the table and, creating its input label (18), transfers it even higher. And so on, until all LSRs get their output label.

Thus, we have built LSP from R1 to R6. R1, when sending a packet to 6.6.6.6/32, adds a label 18 (Push Label) to it and sends it to port FE0 / 0. R2, having received a packet with label 18, changes the label to 20 (Swap Label) and sends it to port FE0 / 0. R5 sees that for a packet with label 20, you need to execute PHP (the output label is 3 - implicit null), remove the label (Pop Label) and send data to port FE1 / 0.
At the same time, LSPs from R2 to R6, from R5 to R6, from R4 to R6, etc., were built in parallel. That is, from all LSRs - I just did not show it in the illustration.
If you have enough strength, then on the GIF below you can see the whole process in dynamics.
Naturally, you understand that not only R6 suddenly started sending out its FEC-tag correspondence, but all the others - R1 about 1.1.1.1/32, R2 - 2.2.2.2/32, etc. All of these messages are blazing fast across the MPLS network, building dozens of LSPs. As a result, each LSR will know about all existing FECs and a corresponding LSP will be built.
Again on the gif above the process is not shown to the end, R1 then transfers information to R3, R3 to R4, R4 to R5.
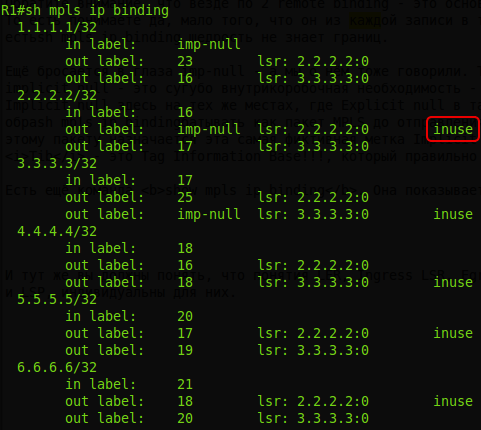
And if we look at R5, we will see that for FEC 6.6.6.6/32 we do not have one output label, as expected, but 3:
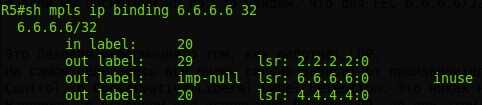
Moreover, R6 itself will record the label for FEC 6.6.6.6, which it will receive from R5:

Inuse - correct - imp-nulltowards R6. But the other two of the ring are from R2 and R4. This is neither a mistake nor a loop - just R2 and R4 generated these labels for the FEC 6.6.6.6/32 routing table known to them.
Two questions arise:
1) How does he plan to use them? They are stupid. Answer: nothing. There cannot be such a situation in our network when 2.2.2.2 or 4.4.4.4 will be the next nodes on the way to 6.6.6.6 - IGP will not build this route. And that means the labels will not be used. It's just that LDP is stupid - its messages are scattered throughout the network, breaking through every crack. A smart LSR will decide what to use.
2) What about loops? Won't LDP messages run on the network until the TTL expires?
And here everything is simple - receiving a new Label Mapping Message does not initiate the creation of a new one - the received correspondence is simply written to the LDP table. That is, in our case, R5 has already come up with a label for FEC 6.6.6.6/32 once and sent it to its higher neighbors and it will not change until the LDP process reboots.
This is basic information on how LDP works.
In fact, everything here is very dependent on the manufacturer. In principle, LDP supports all kinds of labeling modes: DoD / DU, Independent Control / Ordered Control, and Conservative / Liberal Label Retention. This is not regulated by the RFC, therefore, each vendor is free to choose its own path.
For example, basically everyone uses DU for LDP, but at the same time in Juniper labels are distributed in an orderly manner, and in Cisco independently.
Huawei and Juniper select only LSR Loopback interfaces as FECs, and Cisco FEC is created for all entries in the routing table.
But all this is unlikely to somehow affect the real network.
The most important thing to understand about LDP is that it does not use dynamic routing protocols in its work - it is similar in principle to PIM DM : it floods the entire network with tags, but it relies on information from the LSR routing table. And if two labels for one FEC from different neighbors arrive on R1, then he will choose for LSP only the one received through the best interface before this FEC according to information from TM.
This means three things:
In general, after enabling LDP, traffic will go the same as without it, with the only difference being that MPLS tags appear.
Including LDP, like IP, it supports ECMP , just the hash calculation algorithms and, accordingly, the balancing may differ.
An interesting article by Ivan Pepelnyak on LDP and a video on how the protocol works.
LDP is described in RFC 5036 .
Remain true to the linkmeup network.
OSPF is running, routers see Loopbacks and each other, MPLS is turned off.
The initial configuration file.
To enable MPLS globally, you need to give two commands:
The first one is already the de facto and de jure standard on almost any network equipment - it starts the CEF mechanism on the router, the second starts MPLS and LDP globally (it can also be given by default).
The Router ID (and in the more general (non-ciscian) LSR ID terminology) in MPLS is chosen plainly:
Naturally, you should not trust automation - we will configure LSR ID manually:
If you do not add the “force” keyword , the Router ID will change only when you reinstall the LDP session. “Force” forces the router to change the Router ID forcibly and, if necessary (if it has changed), re-establishes the LDP connection.
Next, on the necessary interfaces, we give the mpls ip command :
Cisco here again uses its principle of lazy engineer - a minimum of effort on the part of staff. The mpls ip command includes on the LDP interface simultaneously with MPLS, whether we wish it or not. Similarly, the ip pim sparse-mode command enables IGMP on the interface, as I described in the article on multicast .
After activating the LDP, the router begins to probe the soil via UDP:
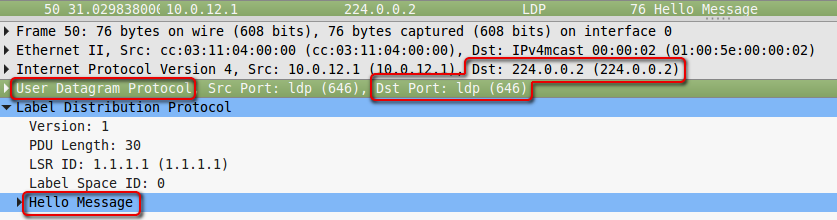
Verifications are sent to the multicast address 224.0.0.2.
Now we repeat all the same manipulations on R2
and enjoy the result.
R2 is also looking for neighbors.
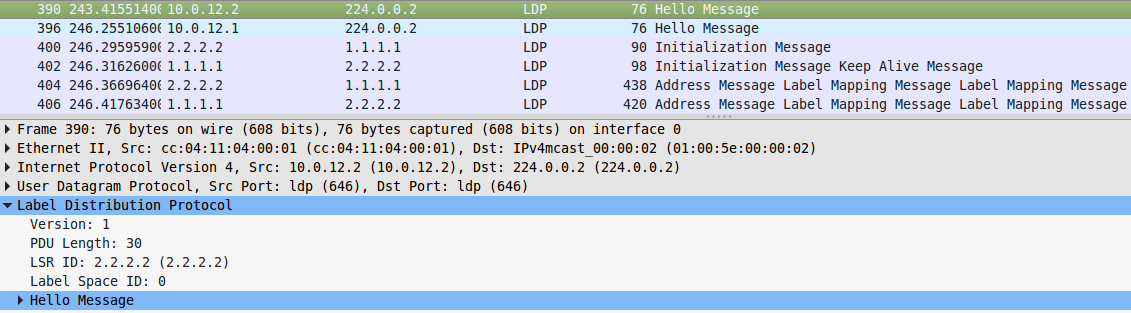
They learned about each other, and R2 raises the LDP session:
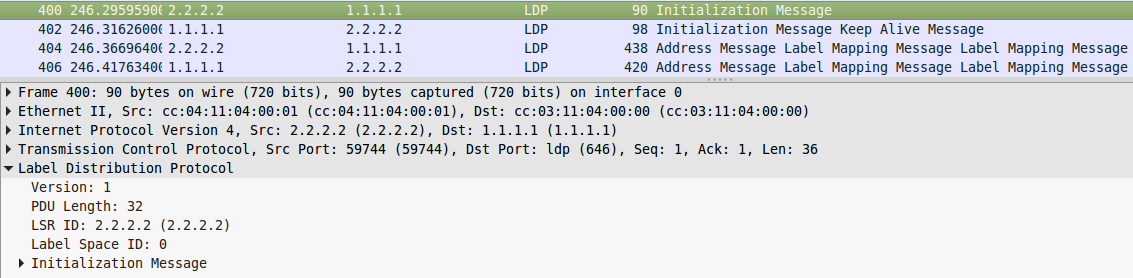
Now they are neighbors, which is easily verified by the show mpls ldp neighbor command .

And then one another tells the FEC label about its correspondences:
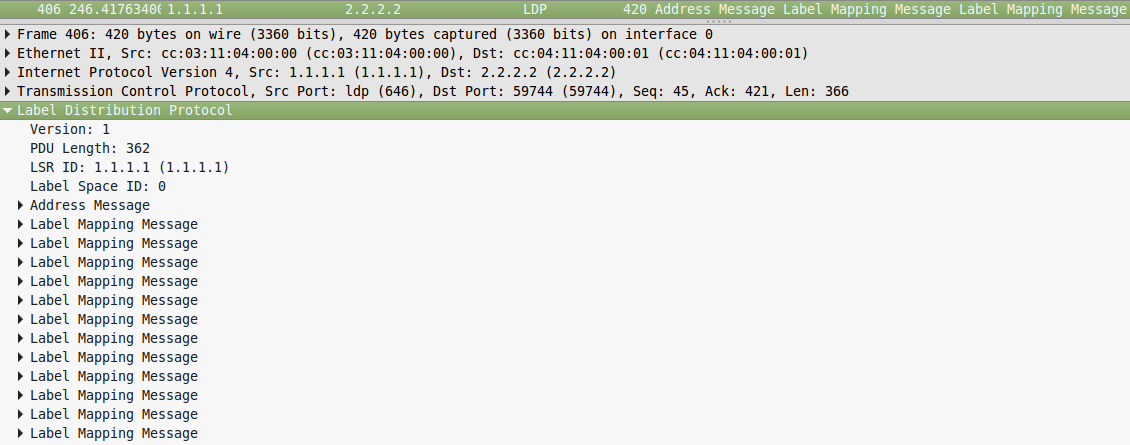
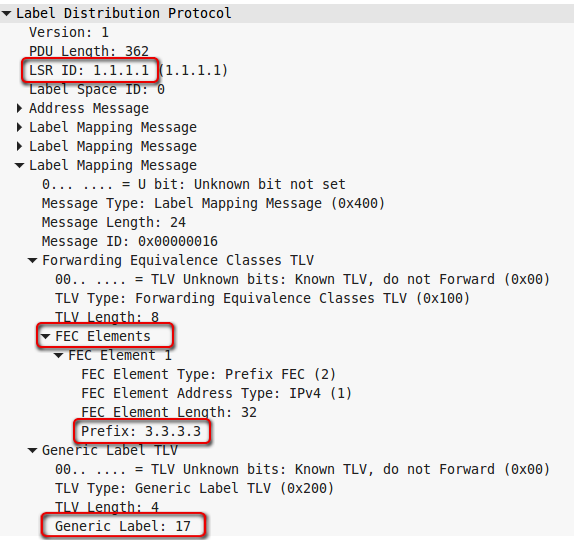
So, R1 tells R2 that if it wants to send traffic for FEC 3.3.3.3 , it should use label 17 .
Note that the LDP on R3 has not yet been raised, that is, R1 announced the label for FEC 3.3.3.3, without waiting for it from R5, this indicates that Independent Control is being used.
And the fact that there was no explicit request from R2 for this FEC suggests that the mode is Downstrean unsolicited.
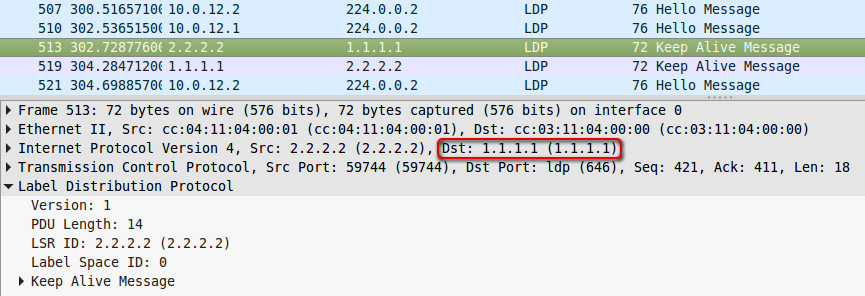
Further, the nodes will continue to monitor new neighbors using LDP Hello over UDP and exchange the LDP Keepalive already addressed:
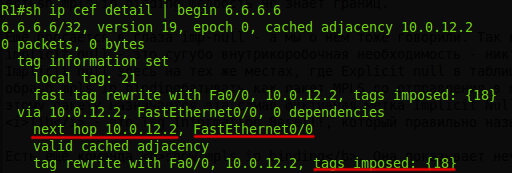
Now, using the show mpls forwarding-table command, you can see which labels have been assigned for each FEC:
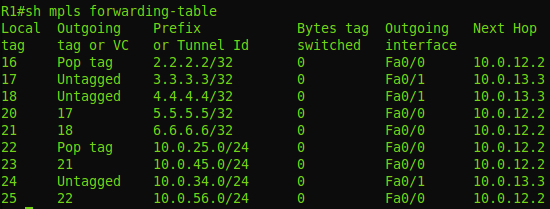
On the second line, FEC 3.3.3.3 is already considered, and we see that for it the local label is 17, that is, R1 will tell everyone that for FEC 3.3.3.3 the label is 17, which was in the dump.
But the outgoing tag or the output label - Untagged - this means that packets are forwarded with a clean IP (without any reservation to the stack). Moreover, Untagged means that between R1 and R3 there is no MPLS at all - that's right: we did not enable it on R3.
But with R2 (first line) the situation is different. Local label 16 is what R1 will transmit to everyone. And the day off is Pop tag. That is, when transferring a packet to R2, R1 must remove the label. In our case, this means that a pure IP will be transmitted (but in a more general case, only the top mark is removed). What is the difference with FEC 3.3.3.3? And the difference is that between R1 and R2 there is MPLS and what we see is the same PHP - Penultimate Hop Popping. The packet addressed to 2.2.2.2 will still be processed on R2, so in order not to produce entities beyond the required value, R1 will helpfully remove the mark.
And here an interesting question arises, how does R1 know that it is the penultimate of the Mohicans? After all, we said above that LDP does not use routing protocols, therefore, it cannot even know that the address 2.2.2.2 is configured on a directly connected R2 - it only sees that 2.2.2.2 is available through 10.0.12.2.
A traffic dump between R2 and R1 will help us answer this question:

And here the same label 3 pops up - implicit-null. Therefore, R2 reports that R1 must remove the top mark when transmitting the MPLS packet.
I want to repeat here - R1 will not transmit a packet with label 3 to R2 - it will transmit it without a top label. In our case, it will be just an IP packet. And label 3 never appears in the MPLS header.
And this label 3 is displayed in the MPLS switching table as a Pop Tag .
For nodes R5 and R6 we have labels, although MPLS was not included on them, but this is only because the route to them lies through R2, and R2 generated a FEC label match for them. In this case, packets on R6 will go with and without MPLS header between R1 and R2further.
Note that if Ordered Control was used, R2 would not be able to send a label for R5 and R6, and packets would only go over IP.
I propose to complete the configuration of MPLS + LDP on all elements of our modest network. The processes there are no different - the same Neighbor Discovery, Initialization, tag exchange, PHP.
The configuration template is as follows:
LDP configuration file.
And after that, let's look again at the MPLS switching table on R1 :

Tags have already appeared for all FECs.
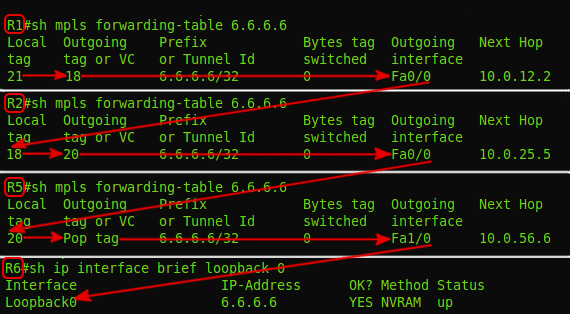
Let's go through the LSP from R1 to R6 and see how the labels change along the path
R2:

R5:

So
1. When R1 receives an MPLS packet with label 21 , it must pass it to the Fa0 / 0 interface and change the label to 18 .
2. When R2 receives the MPLS packet with label 18 , it must pass it to the Fa0 / 0 interface and change the label to 20 .
3. When R5receives an MPLS packet with tag 20 , it must pass it to the Fa1 / 0 interface and remove the tag - PHP .
In this case, LSR do not even think about looking at something in the routing table or in ip cef - they simply juggle with labels.
The switching table that we have already seen with the show mpls forwarding table command is the LFIB ( Lable Forwarding Information Base ) - an almost common truth for data transfer is the Data Plane. But what about the Control Plane? It is unlikely that LDP knows as much? Surely he still has trump cards in his sleeve?
So it is:
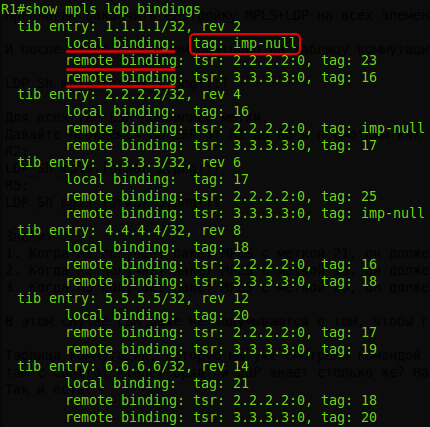
For each FEC, we see here information about various labels:
local binding- that this LSR sends
remote binding to neighbors - that this LSR received from neighbors.
In the illustration above you can see the word "tib". TIB is the Tag Information Base , which is correctly called the Label Information Base - LIB.
This is a relic of the TDP who died in the Bose , the progenitor of LDP.
Note that everywhere 2 remote bindings are two ways to get tags. For example, up to R2 can be reached directly from R1, or via R3-R4-R5-R2.
That is, understand yes? Not only does he make FEC from each entry in the routing table, so this scoundrel also uses the Liberal Retention Mode to hold labels.
Let's summarize: by default, LDP in Cisco works in the following modes:
In short, his bounties know no bounds.
There is also the show mpls ip binding command . It shows something similar and, in addition, allows you to quickly find out which path is currently active, that is, how the LSP is built:
And the last, perhaps, the question that arises in connection with all these LSPs is when the router itself is an Ingress LSR, as it understands that need to do with packages, how to choose LSP?
And for this, you’ll have to look into IP CEF. In general, it is the Ingress LSR that bears the whole burden of processing the packet, determining the FEC, and assigning the correct labels.
Then you and Next Hop and the output interface and output label
And here you should already notice that in LDP the concepts of LER, Ingress LSR, Egress LSR are not the role of any particular nodes or a characteristic of the location of a node in a network. They are inseparable from FEC and LSP, individual for them. That is, for each specific FEC, there is one or more Egress LSRs and many Ingress LSRs (usually all routers) to which the LSPs lead.
Even say so, the concepts of LER arise when we talk about a specific LSP, then we can say who is Ingress, who is Egress.
So far we have talked about how MPLS interacts with IGP protocols. We made sure that there was nothing complicated about it and that the settings were also quite simple.
But the most interesting thing is the interaction of MPLS with BGP. In this issue, we will only slightly touch on this topic. But in the following, we’ll talk in more detail about what role BGP plays and how we can use it and MPLS to organize different types of VPNs.
Now we need to understand how MPLS and BGP interact at the most basic level.
The main difference between BGP and IGP is that MPLS does not create labels for BGP routes. If you recall how many routes BGP transmits, it becomes clear that this is a very good idea. How then to combine MPLS and BGP?
Everything is simple:
Now, in order to configure BGP on each router in our AS, we can only configure it on the edge routers to which clients or other providers are connected.
Let's look at an example of a network:
If we need to get from R1 to Filkin Certificate networks, we see that they are accessible through R6 and “fly through” MPLS to address 6.6.6.6. And when we get to R6, he already knows where to go next. It will be similar and vice versa, in Balagan Telecom.
The configuration for this circuit and a couple of commands with information output can be found here .
LDP is good. It works simply and clearly. But there is such technology as MPLS TE - Traffic Engineering. And she does not have the best route that LDP can provide.
Traffic management implies that you can direct traffic between nodes as you like, given various restrictions.
For example, in our network, the client has two points of connection for its nodes - on R1 and on R6. And between them, he asks for a VPN with a guaranteed channel width of 100 Mb / s. But at the same time, in our network, we also use regular broadband video drivers from VKontakte and a dozen other clients who rent a VPN, but they do not need to reserve a band.
If you do not intervene in this situation, somewhere on R2 there may be an overload, and 100 Mb / s for an expensive client will not get.
MPLS TE allows you to go through the entire network from the sender to the recipient and reserve resources on each node. If you are familiar with the IntServ concept, then yes, it is this one - to organize QoS along the entire path, instead of allowing each router to decide for a passing packet.
Actually, RSVP ( Resource ReSerVation Protocol ) was originally (in 1993) and was conceived for organizing IntServ in IP networks. He had to convey information about QoS for a particular data stream to each node and make it reserve resources.
In a first approximation, it works simply.
1) The source node wants to send a data stream at a speed of 5 Mb / s. But before that, he sends an RSVP request to reserve the band to the receiver - Path Message . This message contains some stream identifiers, by which the node can then identify the ownership of the received IP packets to the stream, and the required bandwidth.
2) The Path message is transmitted from node to node to the receiver itself. Where to send it is determined based on the routing table.
3) Each router, having received Path, checks its resources. If he has enough free bandwidth, he adjusts his internal algorithms so that the stream packets are processed properly and there is always enough bandwidth.
4) If he does not have the necessary 5 Mb / s (occupied by other threads), he refuses to allocate resources and returns the corresponding message to the sender.
5) The Path packet reaches the receiver of the stream, it sends a Resv message back , confirming the allocation of resources along the entire path.
6) The original sender, having received Resv, understands that everything is ready for him, and he can send data.
Actually, under these four simple steps are much more complex processes, but we are not interested.
But what we are interested in is the RSVP extension for Traffic Engineering , or, more simply, RSVP TE , which was developed specifically for MPLS TE.
Its task is the same as that of LDP - to distribute labels between LSRs and eventually compile LSPs from the receiver to the sender. But now, as you already understood, there are nuances - the LSP must satisfy certain conditions.
RSVP TE allows you to build the primary and secondary LSPs, reserve resources on all nodes, detect network crashes, build workarounds in advance, make fast traffic redirection, and avoid channels that physically go along one path.
But we will discuss all this in an article on MPLS TE through a couple of issues. Today, however, we will focus on the principles according to which RSVP TE builds an LSP.
To begin with, we will discard the resource reservation functionality - let our task only be to create LSPs, i.e. distribute labels between LSRs.
To make this possible, the standard RSVP is expanded by adding several objects. Consider the simplest option.
0) R1 needs LSP before FEC 6.6.6.6/32. It looks like the Tunnel interface on R1, which has a destination address of 6.6.6.6 and type Traffic Engineering.
1) It sends an RSVP Path message in the direction of 6.6.6.6. A new object appears in this message - Label Request . The Path message provokes the node to allocate a label for this FEC — that is, it is a label request.
2) The next node forms a new Path message and also sends it to 6.6.6.6. Etc.
3) Path reaches Egress LSR. He sees that the packet is addressed to him, selects the label and sends a Resv message to the source. The latter also added a new object - Label . In it, Egress LSR passes its label for this FEC to the penultimate, penultimate penultimate last, etc.
4) Resv reaches the source, distributing labels along the path. In this way, the LSP is created, and the source is notified that everything is ready.
Labels are requested downstream (Path message from sender to recipient), and transmitted upstream (Resv message from recipient to sender).
At the same time, pay your attention to the fact that this is the most Downstream on Demand + Ordered Control. Path acts as a label request, and Resv goes from the recipient step by step, and until the label is sent by a subordinate LSR, the parent cannot send it to its neighbors.
Stop! We said that RSVP TE, unlike LDP, allows you to build as we want, without being tied to the routing table and IGP, but here it’s just “in the direction of 6.6.6.6”.
And here we come close to the fundamental difference between RSVP TE and LDP. RSVP TE is very closely connected with dynamic routing protocols, it does not just rely on the result of their work - it adapts them for itself, exploits in the literal sense of the word.
At first, only protocols based on link-state algorithms, that is, OSPF and ISIS, are suitable.
Secondly , OSPF and ISIS are expanding with the introduction of new elements in the protocols. So in OSPF there is a new type of LSA - Opaque LSA , and in ISIS - new TLV IS Neighbor and IP Reachability .
Thirdly , to calculate the path between Ingress LSR and Egress LSR, a special modification of the SPF algorithm is used - CSPF ( Constrained Shortest Path First ).
Now in more detail.
The Path message, in principle, is transmitted unicast addressfully. That is, the sender's address is R1, and the recipient's address is 6.6.6.6. And it could have come just by the routing table.

But in fact, Path is transmitted over the network not like a FIB per capita will be put on each node, because then we will not be able to provide backups or search for backup routes. No, he follows a certain path.
This path is determined on Ingress LSR to the accuracy of each node.
To build this path, RSVP TE needs to know the network topology. You see, yes, what are we approaching? RSVP itself does not bother to study it, and why, when it can be obtained from OSPF or ISIS. And then it becomes obvious why RIP, IGRP and EIGRP are not suitable here - after all, they do not study the topology, the maximum that they are capable of is the Feasible Successor.
But the classic SPF algorithm at the input has a network topology, and at the output it can only give the fastest route taking into account metrics and AD, although it can calculate all the possible ways.
And here comes the CSPF. It is this algorithm that can calculate the best path, the second highest priority path, and, for example, some other backup one, in order to at least somehow get through China .
That is, the RSVP TE may ask the CSPF to calculate for it some path between the two nodes.
Well, well, why change the IGP protocols themselves for this? Voooot. And this is Constraints - restrictions. RSVP TE can make requirements for the path — bandwidth, minimum available width, line type, or even the nodes through which the LSP must pass. So, so that the CSPF can take into account the restrictions, it must know about them and about the available resources on the nodes of the entire network. The input data for it are the restrictions specified in the tunnel and the network topology - it will be logical if the topology contains, in addition to prefixes and metrics, information about available resources.
For this purpose, routers exchange among themselves through messages OSPF and ISIS not only basic information, but also the characteristics of lines, interfaces, etc. Just in new types of messages this information is transmitted.
For example, in OSPF, 3 additional LSA types were introduced for this:
Opaque means opaque (for OSPF). These are special LSA types that are not taken into account in OSPF when calculating the routing table. They can use any other protocols for their needs. So TE uses them to build its topology (it is called TED - Traffic Egineering Database ). But theoretically, they are not assigned to TE - if you write your application for routers, which will require the exchange of some information about the topology, you can also use Opaque LSA.
ISIS works the same way. New posts: IS-IS TLV 22 (Extended IS Reachability), 134 (Traffic Engineering router ID), 135 (Extended IP reachability).
So, let's take a closer look at this whole process.
0)On R1, we enabled MPLS TE and configured ISIS (OSPF) to transmit data to support TE. Routers exchanged information about available resources. At this step, TED is formed. RSVP is silent.

1) We created a tunnel interface, where we indicated its type (Traffic Engineering), destination address (6.6.6.6) and the necessary resource requirements. LSR starts CSPF: you need to calculate the shortest path from R1 to 6.6.6.6 taking into account the imposed conditions. At this step, we get the optimal path - a list of nodes from source to destination (R2, R5, R6).
2) The result of the previous step is fed by RSVP and transformed into an ERO object. R1 compiles the RSPV Path, which naturally adds the ERO. The packet destination is 6.6.6.6. In addition, there is also a Label Request object informing that upon receipt of a packet it is necessary to select a label for this FEC (6.6.6.6/32).
3) The RSVP Path message is transmitted in a special way - not according to the routing table, but according to the ERO list. In our case, the best IGP route and ERO match, so the packet is sent to R2.
4) R2, having received the RSVP Path, checks for the availability of the required resources and, if any, allocates the MPLS label for FEC 6.6.6.6/32. The old Path package is destroyed and a new one is created, and the ERO object is changed - R2 itself is removed from it. This is done so that the next node does not try to return the packet to R2. That is, the new ERO already looks like this: (R5, R6). In accordance with it, R2 sends the updated Path to R5.
5)R5 performs similar operations: it checks the resources, selects the label, removes itself from the ERO, re-creates the Path package and passes it to the interface through which the next ERO object is known - R6.
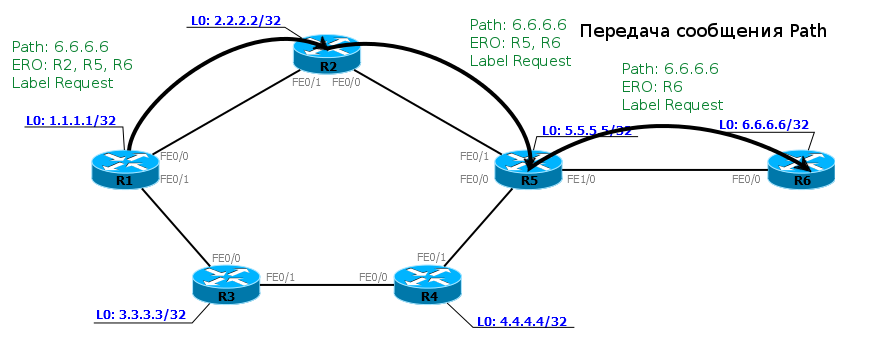
6) R6, having received the package, understands that he is the culprit of all the turmoil. It destroys the Path, selects the label for FEC 6.6.6.6, and inserts it as a Label into the Resv response message.
Note that before this step, the labels only stood out, but did not spread, but now they begin to be announced to the LSRs that requested them.
7) The RESV message advances to R1 (Ingress LSR), leaving behind the growing tail of the LSP. Resv should go through the same nodes as Path, but in reverse order.
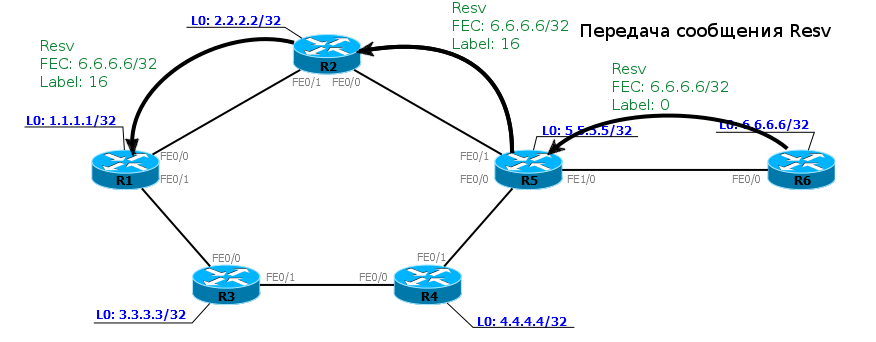
8)In the end, the LSP from R1 to 6.6.6.6 is formed. Data on it can be transmitted only from R1 to R6. To allow data transfer in the opposite direction, you need to create a tunnel interface on R6 with the destination address 1.1.1.1 - all actions will be exactly the same.
The question arises - why is the destination of the Path 6.6.6.6 packet, if it is transmitted node by node and their addresses are known? This question is not idle - it leads us to one important feature. An ERO may not actually contain all the nodes from Ingress LSR to Egress LSR — some may be omitted. Therefore, each LSR must know where the message ultimately goes. And this may not happen because Ingress LSR is too lazy to calculate the whole way.
The problem is in the IGP zones. You know that both OSPF and ISIS have this concept in order to simplify routing. In large networks (hundreds and thousands of nodes), the problem of broadcasting service packages and the calculation of a huge number of combinations by the SPF algorithm arise. Therefore, one global domain is divided into routing zones.
And the whole snag is that if inside the IGP zone it is a link-state protocol, then between them - it is a real distance-vector network topology is built only inside the zone, any internal routers do not know how the others are arranged zones - they are only informed that in order to get into a particular network, they need to send packets to a specific ABR .
In other words, if your network is divided into zones, then there are difficulties with MPLS TE - the CSPF cannot calculate the whole path, because in its topology, the destination from another zone is a cloud, not a specific node.
And here the Explicit Path comes to the rescue (not to be confused with the ERO object). This is the most straightforward way to control the way LSP is built - the administrator can independently and explicitly specify the nodes through which the LSP should be laid. Ingress LSR must follow these guidelines exactly. This brings the CSPF algorithm a little more variety.
How does the Explicit Path help break through the zone? Let's take an example.
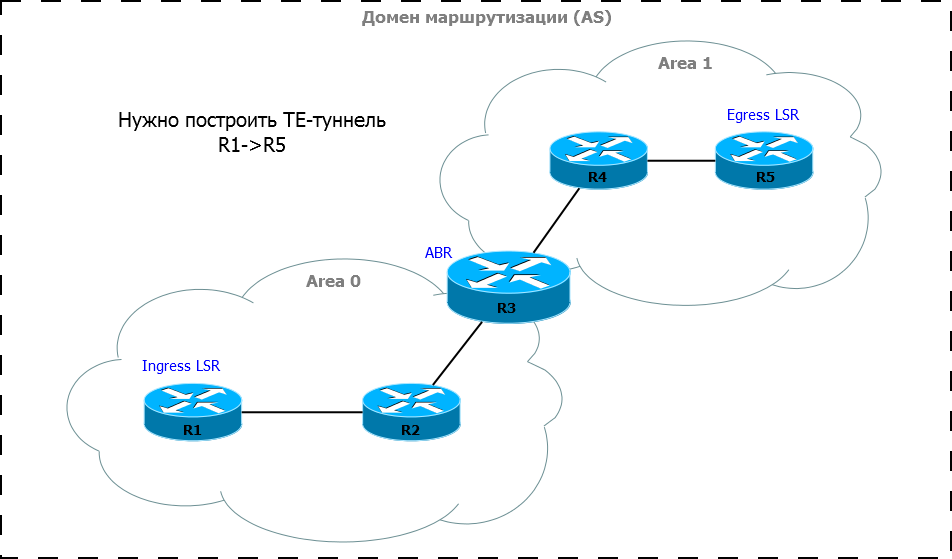
We take and indicate that there must be intermediate points:
Explicit-path: R1, R3, R5.
When we feed this Explicit Path to CSPF, it builds the piece that can, that is, within Area 0: from R1 to R3.
What he counts is entered in the ERO, plus another node from the Explicit-path is added to it - R5. It turns out: R1, R2, R3. Path is sent over the network according to ERO, comes to R3. He sees that, in general, he is not the addressee, but only a transshipment point, takes the specified conditions for the required resources and the address of the recipient node from the Explicit-path and starts CSPF. The latter gives a complete list of nodes to the destination (R3, R4, R5), which is converted to ERO, and then everything happens according to the standard scenario.
That is, if Ingress LSR and Egress LSR are in different zones, the path calculation is performed separately for each zone, and the reference point is ABR.
It should be understood that the Explicit Path is used not only for this case, but it is generally a convenient tool, because you can explicitly specify how to lay the LSP or vice versa, through which nodes it is not necessary to lay the LSP.
We will touch on this and much more in the issue devoted to MPLS TE.
We needed the mpls ip command for LDP to work. Now it is no longer needed - we delete it and start from scratch .
Now we need mpls traffic-eng tunnels . It globally includes support for TE tunnels and RSVP TE itself:
You must also enable the same on the interfaces:
Nothing is happening yet. RSVP is silent.
Now we will expand the IGP to transmit TE data. In our example, we use ISIS:
Enabling extended label mode is mandatory, otherwise TE will not work.
Set LSR-ID, as we did in LDP,
You need to set a specific ISIS level, otherwise TE will not work.
These steps need to be repeated on other routers.
Immediately after this, ISIS begins to exchange information about TE:
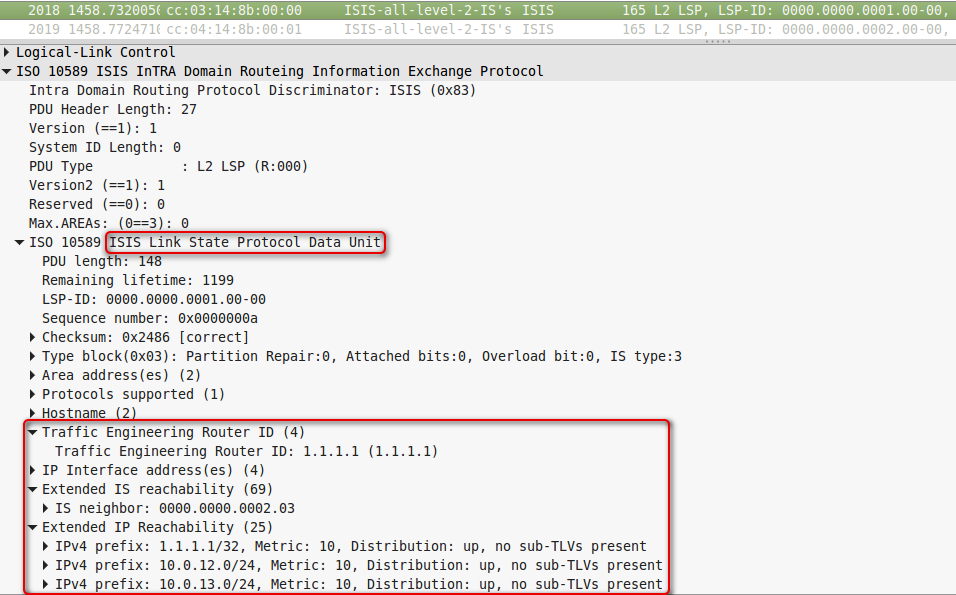
As you can see, information about LSR-ID is transmitted, extended information about neighbors (which support TE), extended information about interfaces.
At this point, a TED is formed.
You can see the topology in ISIS: #show isis database verbose
RSVP is silent for now.
Now configure the TE tunnel.
Tunnel interfaces are a very universal thing on routers. They can be used for L2TP, GRE, IPIP and, as you can see, for MPLS TE.
ip unnumbered Loopback0 means that the starting point of the tunnel should be the Loopback0 interface address.
tunnel destination 6.6.6.6 - a universal command for tunnel interfaces, determines the termination point, the end of the tunnel.
tunnel mode mpls traffic-eng - sets the type. It is here that the tunnel operation algorithm is determined, how to build it.
tunnel mpls traffic-eng path-option 10 dynamic - this command allows CSPF to build a path dynamically, without specifying intermediate nodes.
If before that you did everything correctly, then the tunnel interface should rise:
What happened?
R1 sent Path.
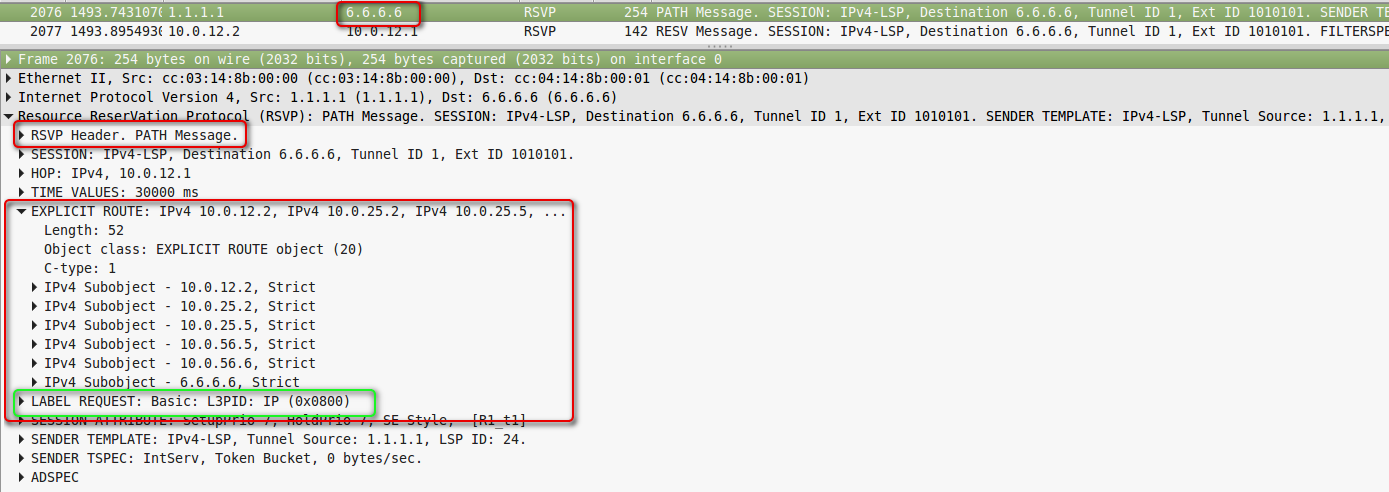
Dump removed on line R1-R2.
We are interested in the destination address, ERO and Label Request objects.
The destination address is 6.6.6.6, as configured in the tunnel.
Explicit Route:
10.0.12.2 -> 10.0.25.2 -> 10.0.25.5 -> 10.0.56.5 -> 10.0.56.6.
That is, the link address of the output interface and the link address of the next node are registered in it. Each LSR thus knows exactly which interface Path should be sent to.
There is no 10.0.12.1 in this ERO because R1 has already deleted it before sending.
The fact of having a Label Requestindicates that the LSR should allocate a label for this FEC.
However, he did not respond to this Path long - he sends updated further.
Resv below is sent after Resv came from a downstream LSR.
The same thing happens on R5: The

dump is filmed on line R2-R5.
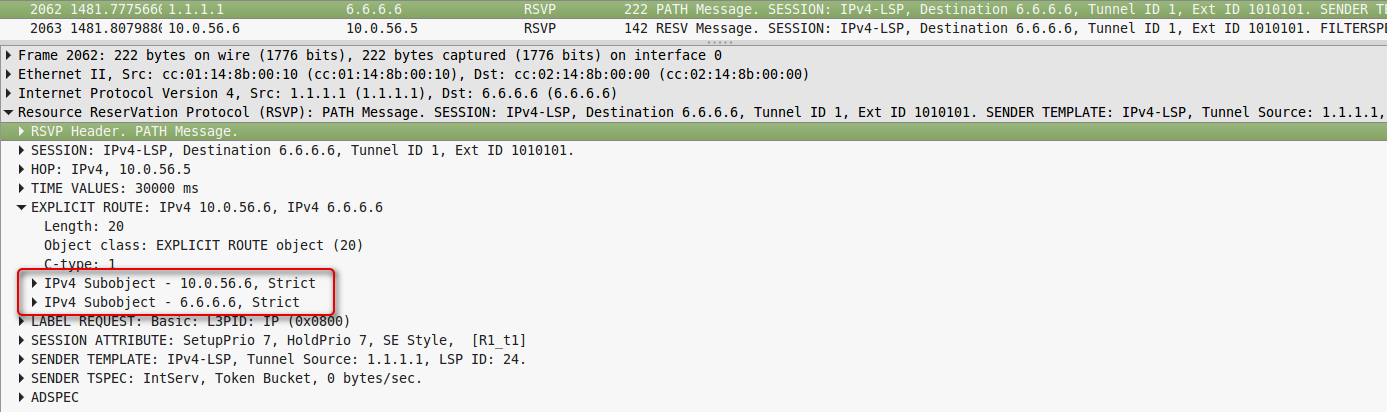
Dump removed on line R2-R5.
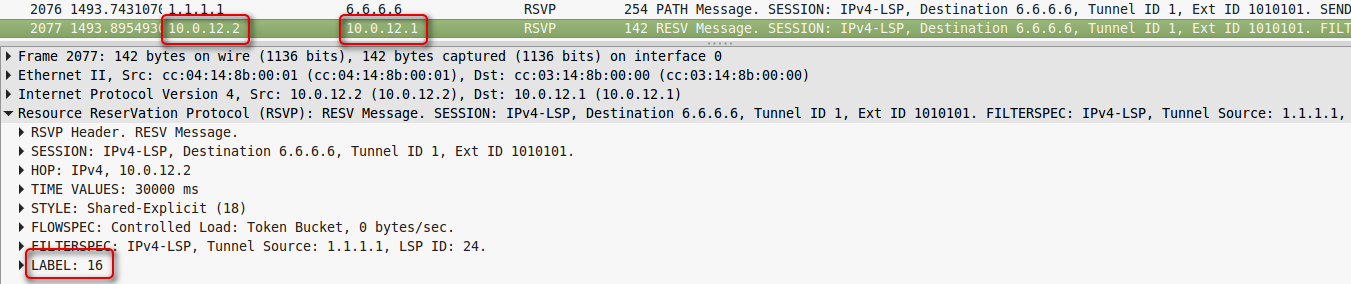
So Path comes to R6. He sends back the RSPV Resv: The

dump is taken on line R5-R6.
The dump clearly shows that Resv is transmitted from node to node.
The Label object passes the label allocated to this FEC.
Note that R6 has assigned the label 0 - Explisit Null. In general, this is a normal situation - this is done so that the MPLS label between R5 and R6 is (for processing the packet according to the value in the EXP field, for example), but R6 immediately realized that it is necessary to reset the label 0 and process what is under it, but didn’t search the label table.
The problem is that there can be more than one in a label packet (for example, for a VPN), but according to RFC 3032 (and we mentioned this before) R5 must delete the entire label stack, no matter how many there are, and transfer the packet with one label 0. In this case, of course, everything will break.
In fact, the requirement that label 0 be the only one on the stack seems unjustified - there are no applications for this. Therefore, in RFC 4182This restriction has been removed. Now label 0 may not be the only one on the stack.
An interesting feature is PHP. Despite the fact that there is a special label for this - 3 - LSR will execute PHP even if it receives the label 0. Details from the same Pepelnyak .
R5 transfers Resv to R2, and R2 to R1.
Dump removed on line R1-R2.
Here, as you can see, the mark is already normal - 16.
Let's now try to change the path - traffic must go through R1-R3-R4-R5-R6.
As simple as that: you just need to configure explicit-path:
And apply it to the tunnel interface:
Notice that we set him a priority higher than the previous rule - 5 versus 10. That is, explicit-path will be used first, and if there are any problems with it, then R1 will try to build LSP dynamically (somehow).
The tunnel configuration now looks like this:
And this is how the Path message, containing a new ERO, looks like:

To view information about the tunnel, run the show mpls traffic-eng tunnels command :
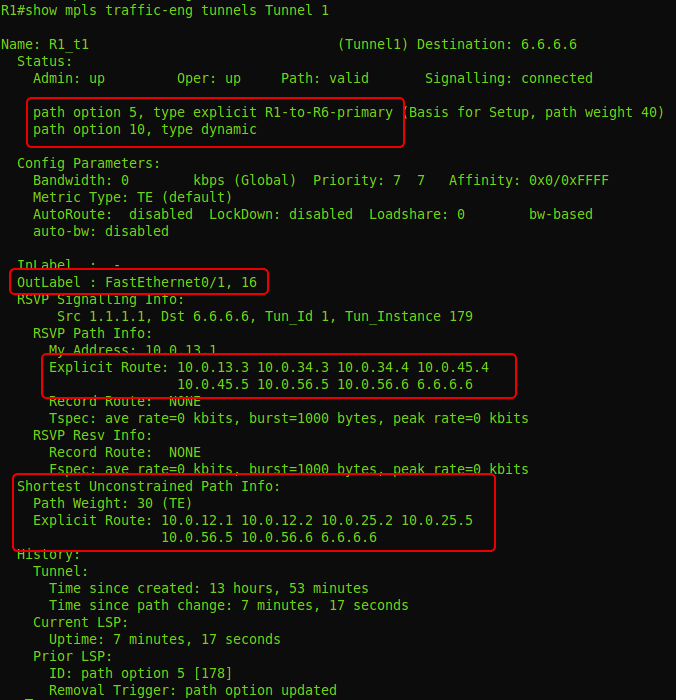
You can also see this in the intermediate:

How the LSP is formed when there are resource requirements, what is Loose and Strict, FRR and make before break, Affinity and more, read through a couple of issues in the MPLS TE article.
RSVP-TE final configuration file .
Q1: What is the difference between RSVP TE LSP and LDP LSP?
Q2: How do Explicit Path and ERO compare?
Q3: If one of the intermediate nodes does not support LDP (RSVP TE) or the protocol is turned off on the interface / platform, will the LSP be built so that, for example, it switches to IP on this node and then to MPLS again on the next one?
Q4: Well, why do you need MPLS will be clear from the following articles - while this is generally some kind of artificial nonsense to complicate the life of an engineer, but why do I need MPLS TE? After all, traffic can be directed in the way I need using IGP metrics.
Q5: So what is the difference between the labels Explicit Null and Implicit Null? Do I really need to know about them?
Q6: For one FEC, will the LSR always allocate the same label to all its neighbors?
It is important to understand that the MPLS technology does not regulate the label distribution protocol in any way, but the final results on a particular network may well differ when using different protocols. Parent protocols and applications use the LSP regardless of who it is or how it is built.
By the way, the scenario LPD over TE is often found in modern networks. In this case, RSVP-TE is used to organize transport and implement Traffic Engineering, and LDP to exchange VPN tags, for example.
Egress LSR, writing the first label in the MPLS header, defines the entire path of the packet. Intermediate routers simply change one label to another. Content can be completely anything. Just this multiprotocol allows MPLS to serve as the basis for a variety of VPN services.
For the finishing touches to the article, thanks to JDima .
Thank you Natasha Samoilenko for the tasks and help in writing this article .
KDPV is drawn by Nina Dolgopolova - a wonderful artist and friend of the project.
Error checking and inaccuracy search conducted by Maxim the gluck
But all is not enough for them. Broadband services are good and necessary, but there is still a huge potential market for corporate clients who need a VPN.
The guys thought about it, puzzled and came to the conclusion that there is no way to do without MPLS.
If multicast was the first topic that required some restructuring of the understanding of IP networks, then, when studying MPLS, you will definitely have to forget almost everything that you knew before - this is a special world with its own rules. Today in the issue:

- What is MPLS?
- MPLS network traffic
- Terminology
- Tag distribution
- - Methods for distributing tags
- - - - DU vs DoD
- - - - Ordered Control vs Independent Control
- - - - Liberal Label Retention Mode vs Conservative Label Retention Mode
- - - - PHP
- - Label Distribution Protocols
- - - - LDP
- - - - - Practice
- - - - Application of pure MPLS in conjunction with BGP
- - - - RSVP-TE
- - - - - Practice
- - Q&A
- - Useful links
And we start with the question: “What is wrong with IP?”
Traditional video
And really, what's wrong? Why fence MPLS?
Yes, that's right. The strengths and weaknesses of IP stem from the fact that it appeared later than classic networks and is incredibly flexible. Nowadays, there is a transition to packet switching everywhere, which is based on IP at the network level, and on the channel Ethernet is gaining more and more popularity.
This is good, because now on the basis of one backbone network and access network you can provide broadband access , IP-telephony, IPTV and other possible services.
The same can be seen in the networks of mobile operators. Second generation networks at the dawn were entirely based on circuit switching. The core of 3G networks is for the most part IP, but telephony services can still be provided in circuit-switched mode. 4G networks are already full-fledged IP networks, where voice transmission is only one of the applications, as well as broadband access.
However, there are still a huge number of segments where old technologies are used. For example, somewhere there is ATM, in another place you need to transfer PDH from one part of the network to another, and then the client wanted his piece of Ethernet-network to be accessible from the other end of the city as if it was connected directly - in other words, VPN.
As it was decided before: we need an ATM between two geographical points - a build channel between them based on ATM, PDH - a build of PDH.
But you want to do all this through one network, and not build a separate one for each type of traffic.
For this, GRE, PPPoE, PPPoA, ATM over Ethernet, TDM over IP and many other overs were invented at the time. You can create another thousand others to cover all the combinations already, and universal happiness will come in the chaos of standards ( by the way, some small manufacturers have chosen this path ).
In the mid-90s, it occurred to the hotheads of several companies (IBM, Toshiba, Cisco, Ipsilon) to create a mechanism that would allow them to look not at the inside of the packet while routing and comb the routing table in search of a better way, but to navigate by some label. Shot at Cisco, and the mechanism was named plain: TAG Switching.
Moreover, the goal pursued by the developers was to allow high-speed switches to transmit traffic exclusively in hardware. The fact is that hardware IP routing has long been an inaccessible pleasure, and it was impractical to use it on inexpensive switches, and making a decision based on a tag could be simple and quick.
But at the same time, super-large integrated circuits appeared (even though I do not agree with this term - English VLSIdescribes the essence much better), and the task of saving on the analysis of the contents of the package has become not so urgent. In addition, the concept of FIB appeared, which suggests that for each packet it is not necessary to search for a destination in the routing table and, accordingly, involve a central processor - all the hot information is already on the line card.
That is, in fact, the need for such a mechanism has disappeared.
But suddenly it became clear that label switching has unplanned potential - it does not matter what is under the label - IP, Ethernet, ATM, Frame Relay. And it also gives you the opportunity to get rid of the limitations of IP routing.
The technology approved by IETF - MPLS - MultiProtocol Label Switching originates from here. It was the 1997th year.
And this seemingly insignificant detail gave rise to a new era in telecommunications. Today you will find MPLS in any more or less large provider.
The main applications of MPLS now:
- MPLS L2VPN
- MPLS L3VPN
- MPLS TE
We will talk about each of them in separate articles - these are monstrously huge topics. But briefly we will touch upon them at the end of the article.
MPLS
Pure MPLS alone is rarely used. The performance gain is insignificant, because the difference between glancing at the FIB / changing some fields in the headers and looking at the table of labels / changing the label in the MPLS header is not that big. Of course, its applications listed above are used.
But in this article, we still concentrate on pure MPLS to understand how it works in its most basic form.
Below we will also consider one application of pure MPLS.
Despite the fact that MPLS is not tied to the type of network on which it will operate, in our time it lives in symbiosis only with IP. That is, the network itself is built on top of IP, but at the same time it can transfer data from many other protocols.
But let's get to the point already, and first I want to say that MPLS does not replace IP routing , but works on top of it.
To be more specific, I will take such a network.
Now it is in full working condition, but without any hint of MPLS. That is, R1, for example, sees R6 and can ping its Loopback.
PC1 sends an ICMP request to server 172.16.0.2. An ICMP request is an IP packet. On R1, according to the basic principles, the packet leaves through the FE0 / 0 interface on R2 - the Routing Table said so.
After receiving the packet, R2 checks the destination address, looks at its FIB, sees the next router and sends the packet to the FE0 / 0 interface.
And this process is repeated over and over again. Each router independently decides the fate of the packet.
This is how traffic dump looks quite familiar:
What happens if we activate MPLS? Right now, at that very moment the world is changing. After that, label tables are populated on the routers and multiple LSPs are built.
And now the same path will be done a little differently.
When the IP packet from PC1 enters the MPLS network, the first router hangs up a label, then this packet goes to the destination, and each subsequent router changes one label to another. When you exit the MPLS network, the label is removed and then a clean IP packet is transmitted, as it was at the very beginning.
This is the basic principle of MPLS - routers switch packets by labels, without looking inside the MPLS packet. The first one adds, the last one deletes.
Let's take a look at the step-by-step transfer of a data packet from PC1 to the destination node:
1. PC1 - a regular computer - sends a regular packet to a remote server.
2. The package comes to R1. It adds a label of 18. It is inserted between the IP header and Ethernet.
He can take this information from the FIB:
FIB shows that the packet with the destination 6.6.6.6 must be labeled 18 and sent to the FE0 / 0 interface .
Actually, he does this: he adds a header and writes 18: A
dump between R1 and R2 .
3. R2 receives this packet, in the Ethernet header sees that it is an MPLS packet (Ethertype 8847), reads the label and refers to its label table:
We read the letters: if the MPLS packet came with a label of 18, you need to change it to 20 and send the packet to the FE0 / 0 interface.
Dump after R2.
4. R5 performs similar actions - sees that a packet with label 20 has arrived, it must be changed to 0 and sent to FE1 / 0. Without any reference to the routing table.
5. R6, having received the MPLS packet, sees in its table that now the label must be unchecked. And having removed it, he sees already that the packet destination - 172.16.0.2 - is a Directly Connected network. Further, the packet is transmitted in the usual way along the routing table without any labels.
That is, the whole process looks like this:
We will not consider the end nodes, so as not to complicate the scheme.
So far, everything seems to be simple, although it is not clear why.
Now the IGP and MPLS domains coincide and MPLS only promises us some goodies in the future: L2VPN, L3VPN, MPLS TE.
But, in fact, even basic MPLS gives us advantages if we recall that we are a provider.
As a provider, we do not use IGP protocols for routing between ASs. For this we use BGP. And it is in conjunction with BGP that the benefits of MPLS will become clear.
Consider our network in conjunction with neighboring ASs:
From the BGP release, we know that BGP must be configured on each router in our AS. Otherwise, we will not be able to transmit traffic to neighboring ASs and our customers through our AS. Each router must know all the routes.
But that was before MPLS!
When MPLS is configured on our network, we no longer need to configure BGP on each router in the network. It is enough to configure it only on the border routers in the AS, on those that are connected to other clients or providers.
But this is not all good news. In addition to the fact that BGP can no longer be configured on every router in the AS, routers also do not need to create a label for each BGP prefix. It is enough to know how to get to the IP address, which is listed as next-hop. That is, if a BGP session is configured between Loopback0 R1 and Loopback0 R6, then nothing will change in the label table, even if each of them sends hundreds of thousands of routes via BGP:
For example, several routes came from router R6 via BGP from router R6:
Let's see how packets that go to the network 100.0.0.0/16 will be processed:
In the output above it is clear that the label 27 will be added to the packets.
And, if you look at the label table, then there are no labels for routes that are known by BGP, but there are label 27 and it corresponds to 6.6.6.6/32. And this is exactly the address that we saw in the routes that came via BGP from R6:
You can find an example of configuration below .
We ran a little ahead, but now that it has become clearer what advantages even basic MPLS provides, we can plunge into the conceptual apparatus in the world of MPLS.
Terminology
Label - label - a value from 0 to 1,048,575. Based on it, LSR decides what to do with the packet: what new label to hang, where to send it.
It is part of the MPLS header.
Label Stack - a stack of tags. Each package can carry one, two, three, and at least 10 tags - one above the other. The decision on what to do with the package is made based on the top label. Each layer plays some role.
For example, when transmitting a packet, a transport label is used, that is, a label organizing transit from the first to the last MPLS router.
Others may carry information that this packet belongs to a particular VPN.
In this release, there will always be only one label - no more is needed yet.
Push label- the operation of adding a label to the data packet is performed at the very beginning - on the first router in the MPLS network (in our example, R1).
Swap Label - label replacement operation - occurs on intermediate routers in the MPLS network - the node receives a packet with one label, changes it and sends it from another (R2, R5).
Pop Label - label removal operation - performed by the last router - the node receives the MPLS packet and removes the top label before passing it on (R6).
In fact, the label can be added and removed anywhere within the MPLS network.
It all depends on the specific services. It would be more correct to say that the label is added by the first router of the path (LSP), and deleted by the last.
But in this article, for simplicity, we will talk about the boundaries of the MPLS network.
In addition, deleting the top mark does not mean that a pure IP packet remains, if it comes to the label stack. That is, if a Pop Label operation was performed on a package with three labels, then there are two labels left and then it is still processed as MPLS. And in our example, there was one, and after that there will not be a single one - and this is IP business.
LSR - Label Switch Router is any router in an MPLS network. It is called like that because it performs some operations with labels. In our example, these are all nodes: R1, R2, R3, R4, R5, R6.
LSR is divided into 3 types:
Intermediate LSR - an intermediate MPLS router - it performs the Swap Label operation (R2, R5).
Ingress LSR - “input”, the first MPLS router - it performs the Push Label (R1) operation.
Egress LSR - "output", the last MPLS router - it performs the Pop Label (R6) operation.
LER - Label Edge Router is a router on the edge of the MPLS network.
In particular, Ingress LSR and Egress LSR are boundary, which means they are also LER.
LSP -Label Switched Path - label switching path. This is a unidirectional channel from Ingress LSR to Egress LSR, that is, the path that the packet will actually go through the MPLS network. In other words, it is an LSR sequence.
It is important to understand that LSPsare actuallyunidirectional. This means that, firstly, traffic on it is transmitted only in one direction, secondly, if there is “there”, there is not necessarily “back”, and thirdly, “back” does not necessarily go along the same path, that "go there." Well, it's like tunnel interfaces in GRE.
What does LSP look like?
Yes, it’s so unpresentable.
This is a compiled output from four LSRs - R1, R2, R5, R6. That is, on LSR you will not see a complete sequence of nodes from entry to exit, by the type of AS-PATH attribute in BGP. Here, each node knows only the input and output labels. But LSP does exist.
This seems a bit like IP routing. Despite the fact that there is a path from point A to point B, the routing table knows only the next node where traffic should be sent. But the difference is that LSR does not decide on each packet based on the destination address - the path is predetermined.
And one of the most important concepts to deal with is FEC - Forwarding Equivalence Class. For some reason it was given to me very hard, although in fact - everything is simple. FEC are traffic classes. In the simplest case, the class identifier is the destination address prefix (roughly speaking, the destination IP address or subnet).
For example, there are traffic flows from different clients and different applications that all go to the same address - all these flows belong to one class - one FEC - use one LSP.
If we take other streams from other clients and applications to a different destination address, it will be a different class and a different LSP, respectively.
In theory, in addition to the destination address, FEC can take into account, for example, QoS labels, source address, VPN identifier, or application type. It is important to understand here that packets from the same FEC are not required to go to the same destination address. And at the same time, even if two packets follow in one place, they will not necessarily belong to one FEC.
I will explain why all this is necessary. The fact is that for each FEC its own LSP is selected - its own path through the MPLS network. And then, for example, for WEB surfing you set QoS BE priority - it will be one FEC - and for VoIP - EF - another FEC. And then you can specify that for FEC BE LSP should go a broad, but long and unwarranted path, and for FEC EF, it can be narrow but fast.
Unfortunately or fortunately, now only the IP prefix can act as FEC. Things like QoS marking are not considered.
If you pay attention to the label table, FEC is present there, since the label replacement parameters are determined exactly on the basis of FEC, but this is done only at the first moment in time - when these labels are distributed. When real traffic runs through LSP, no one but Ingress LSR looks at it - only labels and interfaces. Ingress LSR takes all the work on determining the FEC and in which LSP to send the traffic - after receiving a clean packet, it analyzes it, checks which class it belongs to and hangs the appropriate label. Packets of different FECs will receive different labels and will be sent to the corresponding interfaces.
Packets of the same FEC receive the same labels.
That is, intermediate LSRs are threshers that just do the switch for all transit traffic. And all the intellectual work is done by Ingress LSR.
LIB - Label Information Base - label table. An analogue of the routing table (RIB) in IP. It indicates for each input label what to do with the package - change the label or remove it and to which interface to send.
LFIB - Label Forwarding Information Base - similar to FIB - is the label base accessed by the network processor. When you receive a new package, there is no need to contact the CPU and do a lookup in the label table - everything is at hand.
One of the initial ideas of MPLS - to smash the Control Plane and Data Plane as much as possible - went into oblivion.
The developers wanted that when transmitting the packet through the router there was no analysis - just read the label, changed it to another, passed it to the desired interface.
To achieve this, there were just two separate processes - a relatively long construction of the path (Control Plane) and fast transmission of traffic along this path (Data Plane)
But with the advent of cheap chips (ASIC, FPGA) and the FIB mechanism, regular IP transmission also became quick and easy.
For a router, it does not matter where to look when transmitting a packet - in the FIB or in the LFIB.
But what is undoubtedly important and useful is that MPLS does not care about what is transmitted under its heading - IP, Ethernet, ATM. No need to fence GRE or some other uncomfortable VPN to pain in the joints. But let's talk about this again.
MPLS Header
The entire MPLS header is 32 bits. The format of the fields and their length are fixed. Often the entire title is called a label, although this is not entirely true.
Label - the label itself. The length is 20 bits.
TC - Traffic Class. It carries the priority of the packet, like the DSCP field in IP.
The length is 3 bits. That is, it can encode 8 different values.
For example, when transmitting an IP packet through an MPLS network, the value in the DSCP field is associated with the TC value in a certain way. Thus, a packet can be processed almost equally in queues along its entire path, both in a pure IP section and in MPLS.
But, of course, this lossy conversion - six DSCP bits closely in 3 TC bits: 64 versus 8. Therefore, there is a special correspondence table where the whole range is just one value.
Initially, the field was called EXP (experimental), but its contents were not regulated. It was assumed that it can be used for research, the introduction of new functionality. But this is in the past.
If someone argues with you that this field is experimental and has not been formally approved for the QoS function, hedoes not fumbledecently behind life .
======================Task No. 1
The network has a simple QoS policy in which IP packets that go from the host 10.0.17.7 to the address 6.6.6.6, are tagged and transmitted over the MPLS network. To label packets, use the EXP field, the value of field 3.Scheme
R6 has a QoS policy configured that classifies packets by EXP field.
But, during verification, it turned out that the policy on R6 does not work out. That is, there are no packets arriving with an EXP value of 3 and all packets fall into class default.
Task: Correct the configuration so that the policy on R6 is triggered.
The R7 router is used as a client. Accordingly, MPLS between R7 and R1 is not included.
Details of the task and configuration here .
=======================
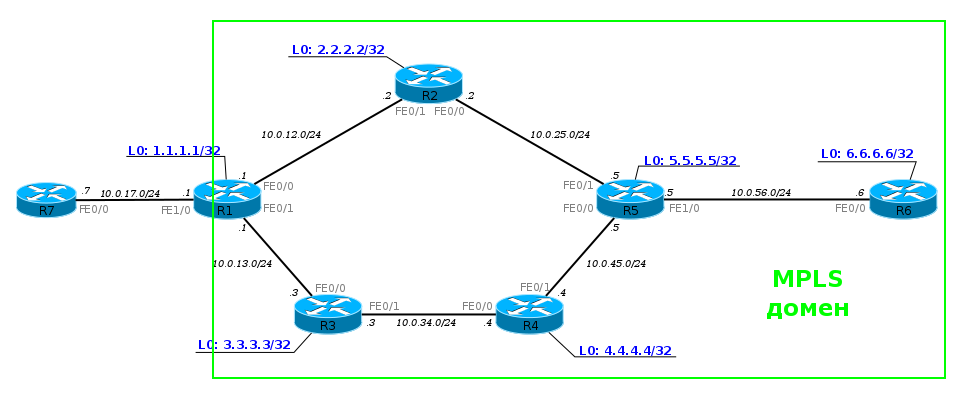
S - Bottom of Stack - indicator of the bottom of the 1-bit label stack. There may be several MPLS headers on a packet, for example, external for switching in an MPLS network, and internal indicates a specific VPN. So that LSR understands what it is dealing with. In bit S, “1” is written if this is the last mark (the bottom of the stack is reached) and “0” if the stack contains more than one mark (not yet the bottom). That is, LSR does not know how many total labels are on the stack, but it knows if it is one or more - and this is actually enough. After all, any decisions are made on the basis of only the topmost label, regardless of what is under it. But, removing the label, he already knows what to do next with the package: continue working with the MPLS process or give it to some other one (IP, Ethernet, ATM, FR, etc.).
Here to this phrase: “But, removing the label, he already knows what to do next with the package” - we need to give an explanation. In the MPLS header, as you noticed, there is no information about the content (like Ethertype in Ethernet or Protocol in IP).
This is good on the one hand - anything can be inside - higher flexibility, but on the other hand, how can I now determine which process to transfer all this economy to without process content analysis?
And here is a little trick - the router, as you will see later, always selects the label itself and passes it to its neighbors, so it knows why it allocated it - for IP or for Ethernet or something else. Therefore, he simply adds this information to his label table. And the next time, when he does the Pop Label operation, he already knows from the table (and not from the package) what to do next.
In general, the stack here in the classical sense is the last to be put, the first to be taken (LIFO - Last Input - First Output).
As a result, in spite of the fact that the MPLS header length is fixed, there can be many headers themselves - and they are all located one after another.
TTL - Time To Live - A complete counterpart to IP TTL . Even the same length has - 8 bits. The only task is to prevent the packet from wandering endlessly over the network in the event of a loop. When transmitting an IP packet over an MPLS network, the IP TTL value can be copied to the MPLS TTL, and then back. Or the countdown will start again from 255, and when entering a clean IP network, the IP TTL value will be the same as before entering.
As you can see, the MPLS header is squeezed between the data link layer and the data that it carries - in the case of IP - network. Therefore, metaphorically, MPLS is called Layer 2.5 technology, and the header, Shim-header, is the wedge-header.
By the way, the label does not have to be in the MPLS header. According to the IETF, it can be embedded in ATM, AAL5, Frame Relay headers.
Here's what it looks like in life:
Label space
As mentioned above, 2 ^ 20 tags can exist.
Of these, several are reserved:
0 : IPv4 Explicit NULL Label . "Explicit blank label." It is used on the very last MPLS span - before the Egress LSR - in order to notify him that this mark 0 can be removed without looking at the label table (more precisely, LFIB).
For those FECs that originate locally (directly connected), the Egress LSR selects the 0 mark and passes it to its neighbors - the penultimate LSR (Penultimate LSR).
When transmitting a data packet, the penultimate LSR changes the current label to 0.
When Egress LSR receives the packet, it knows for sure that the top label simply needs to be deleted.
This has not always been the case. Initially, it was suggested that label 0 can only be at the bottom of the label stack, and when a packet with such a label is received, the LSR should clear MPLS mentions altogether and start processing the data.
At some point, theorists, under pressure from practitioners, agreed that it was irrational and they could not come up with a real application, so they refused both conditions.
So now the label 0 is not necessarily the last (lower) and during the Pop Label operation only it is deleted, and the lower ones remain and the packet is further processed in accordance with the new upper label.
1 : The Router Alert Label - an analogue of the Router Alert option in IP - can be anywhere except the bottom of the stack. When a packet arrives with such a label, it must be passed to the local module, and then it is switched according to the label that was lower - the real transport one, and label 1 must be added to the top of the stack again.
2 : IPv6 Explicit NULL Label - the same as 0, only adjusted for the IP protocol version.
3 : Implicit Null . A dummy label that is used to optimize the process of transmitting an MPLS packet to an Egress LSR. This label may be advertised, but is never used in the MPLS header in reality. Consider it later.
4-15 : Reserved.
Depending on the vendor, other label values can be fixed, for example, on Huawei equipment, tags 16-1023 are used for static LSPs, and all that is higher in dynamic ones. At Cisco, available tags start at the 16th.
=====================
In the following diagram, all routers except R5 are Huawei routers. R5 - Cisco.Scheme
For the R5 router configuration below, you need to configure it so that the distribution of the label values matches Huawei. The thing is that in Huawei dynamic tags start at 1024, and in Cisco with 16.R5 configurationip cef ! interface Loopback0 ip address 5.5.5.5 255.255.255.255 ip router isis ! interface FastEthernet0/0 description to R4 ip address 10.0.45.5 255.255.255.0 ip router isis mpls ip ! interface FastEthernet0/1 description to R2 ip address 10.0.25.5 255.255.255.0 ip router isis mpls ip ! interface FastEthernet1/0 description to R6 ip address 10.0.56.5 255.255.255.0 ip router isis mpls ip ! router isis net 10.0000.0000.0005.00 ! mpls ldp router-id Loopback0 force
Details of the task are here .
=======================
In general, it became clear how traffic is transmitted and how MPLS tags are involved.
But the tags are not taken from the bulldozer - no one needs additional chaos on the eve of the New Year. Special protocols distribute labels between the Egress LSR and Ingress LSR, creating an LSP.
Tag distribution
Firstly, as you already understood, on some devices you can do everything manually - instill zeal and diligence!
But in the era of automatic washing machines, there are three basic protocols for distributing tags - LDP, RSVP-TE and MBGP.
In short, LDP - the easiest and most intuitive way - relies on the routing information of nodes. RSVP-TE, an evolution of the once-developed but unpopular RSVP protocol, is used by MPLS-TE to build LSPs that satisfy certain conditions. For its work, IGPs supporting Traffic Engineering (OSPF, ISIS) are needed.
MBGP is a close relative of BGP, but it is a protocol from a slightly different history, it passes labels for other purposes. Therefore, it stands apart from LDP and RSVP-TE.
Let's talk about each of them, but before that a few words about how LSR handle labels in general.
Label Distribution Methods
The first obvious fact is that the labels propagate from the recipient of the traffic to the sender, and more precisely from Egress LER to Ingress LER. The first non-obvious fact - in MPLS, Downstream is from sender to receiver, and Upstream from receiver to sender. I defined it for myself as follows: LSP “grows” from FEC up to Ingress LER, like a tree, and user traffic “descends” to the recipient via LSP, like rainwater along branches. That is, tags are distributed towards traffic.
They also say that LSP is built to meet the traffic.
The label distribution mechanism itself depends on the protocol, settings, and manufacturer.
DU vs DoD
Firstly , the router can distribute tags to all its neighbors immediately and without any unnecessary questions, and it can issue them on request from higher ones (we remember, yes, which direction is called Upstream?)
The first mode is called DU - Downstream Unsolicited . As soon as the LSR learns about FEC, it sends out labels to this FEC to all its MPLS neighbors.
It looks something like this:
All LSRs learn about all FECs in every possible way. At first, matching the FEC tag diverges across the network from neighbor to neighbor, much like it does with BootStrap messages in PIM SM. And then each LSR selects only the one that came along the best path and uses it for the LSP - the same way Reverse Path Forwarding worksin the same PIM SM .
Quickly, simply, understandably, although it is not always necessary for everyone to know about everything.
The second mode is DoD - Downstream-on-Demand . LSR knows FEC, it has neighbors, but until they ask what label is for this FEC, LSR remains silent.
This method is convenient when some requirements are imposed on the LSP, for example, in bandwidth. Why send a tag just like that if it is immediately dropped? Better, the higher LSR will ask the lower: I need a label from you for this FEC - and that one: “ok, on”.
The mode of marking is specific to the interface and is determined at the time of the connection. Both methods can be used on the network, but on the same line, neighbors must agree on only one specific one.
Ordered Control vs Independent Control
Secondly , the LSR can wait for the label of the FEC to come from the Egress LER before telling the upstream neighbors. Or he could send tags to FEC as soon as he found out about him.
The first mode is called Ordered Control. It
ensures that by the time data is transferred, the entire path up to the output LER will be built.
The second mode is Independent Control .
That is, tags are transmitted out of order. Convenient in that traffic can begin to be transferred even before the entire path is built. The same is dangerous.
Liberal Label Retention Mode vs Conservative Label Retention Mode
Thirdly , it is important how the LSR handles the labels passed to it.
For example, in such a situation, should R1 store information about the label 20 received from the neighbor R3, which is not the best way to get to R6?
And this is determined by the label retention mode.
Liberal Label Retention Mode - labels are saved. In the case when R3 becomes the next step (for example, problems with the main path), the traffic will be redirected sooner because the label already exists. That is, the reaction rate is higher, but the number of labels used is high.
Conservative Label Retention Mode - an extra label is discarded as soon as it is received. This reduces the number of tags used, but MPLS will also respond more slowly in the event of an accident.
Php
No, this is not the kind of PHP you thought about. It's about Penultimate Hop Popping . All engineers are a bit of optimizers, and here the guys thought: why do we need to process the MPLS headers twice - first on the penultimate router, then on the weekend.
And they decided that the label should be removed on the penultimate LSR and called this action - PHP.
There is a special label for PHP - 3.
Returning to our example, for FEC 6.6.6.6 and 172.16.0.2 R6 selects label 3 and reports it to R5.
When transferring a packet to R6, R5 must assign it a dummy label - 3, but in fact it does not apply and a bare IP packet is sent to the interface (it is worth noting that PHP only works on IP networks) - that is, the Pop Label procedure was performed on R5 .
Let's trace the life of the package taking into account everything that we now know.
With how traffic is transmitted, it seems, more or less clear. But who does all the titanic work of creating labels, filling out tables?
Label Distribution Protocols
There are not so many - three: LDP, RSVP-TE, MBGP.
There are two global goals - distribution of transport labels and distribution of service labels.
Let us explain: transport labels are used to transmit traffic over the MPLS network. These are just the ones we are talking about the entire issue. They use LDP and RSVP-TE.
Service tags are used to separate different services. Here MBGP and the process of LDP - tLDP enter the arena .
In particular, MBGP allows, for example, to note that such a route belongs to such a VPN. Then he passes this route, like vpn-ipv4 family, to his neighbor with a label so that he can later separate the flies from cutlets.
So, so that he can separate, he needs to be informed about the compliance of the label-FEC.
But this is the action of another play, which we will play in six months or a year.
A prerequisite for the operation of all dynamic label allocation protocols is the basic configuration of IP connectivity. That is, IGPs must be running on the network.
Well, now that I’ve completely confused you, you can begin to unravel.
So, what is the easiest way to distribute tags? The answer is to enable LDP.
Ldp
The protocol with a very transparent name - Labed Distribution Protocol - has a corresponding principle of operation.
Consider it on the linkmeup network, which we’re covering the entire issue:
1. After turning on LDP, LSR multicast sends UDP datagrams to all interfaces to address 224.0.0.2 and port 646, where LDP is activated - this is how neighbors are searched.
The TTL of such packets is 1, because the LDP neighborhood is established between directly connected nodes.
Generally speaking, this is not always the case - an LDP session can be established for certain purposes and with a remote host, then this is called tLDP - Targeted LDP . We will talk about him in other issues.
These messages are called Hello .
2. When neighbors are discovered, a TCP connection is established with them, also on port 646 - Initialization . Further messages (except Hello) are already transmitted with a TTL of 255.
3. Now LSR periodically keep Keepalive messages addressed via TCP and still do not abandon attempts to find neighbors using Hello.
4. At some point, one of the LSR discovers within itself a second personality - Egress LSR - that is, it is the weekend for some FEC. This is a fact that needs to be reported to the world.
Depending on the mode, it waits for a label request for this FEC, or sends it right away.
This information is transmitted in the message.Label Mapping Message . Based on the name, it carries in itself the correspondence of the FEC and the label.
R5 receives FEC 6.6.6.6/32 and label 3 (implicit null) compliance information and writes it to its label table. Now, when he needs to send data to 6.6.6.6, he will know that he needs to remove the upper MPLS header and send the remaining packet to the FE1 / 0 interface.
Then he selects the input label for the given FEC, writes this information to his label table and sends it to the higher neighbors.
Now R5 knows that if an MPLS packet with a label of 20 has arrived, it must be transferred to the FE1 / 0 interface by removing the label, that is, by executing the PHP procedure.
R2 receives compliance information from R5 FEC-label (6.6.6.6 - 20), enters it into the table and, creating its input label (18), transfers it even higher. And so on, until all LSRs get their output label.
Thus, we have built LSP from R1 to R6. R1, when sending a packet to 6.6.6.6/32, adds a label 18 (Push Label) to it and sends it to port FE0 / 0. R2, having received a packet with label 18, changes the label to 20 (Swap Label) and sends it to port FE0 / 0. R5 sees that for a packet with label 20, you need to execute PHP (the output label is 3 - implicit null), remove the label (Pop Label) and send data to port FE1 / 0.
At the same time, LSPs from R2 to R6, from R5 to R6, from R4 to R6, etc., were built in parallel. That is, from all LSRs - I just did not show it in the illustration.
If you have enough strength, then on the GIF below you can see the whole process in dynamics.
Naturally, you understand that not only R6 suddenly started sending out its FEC-tag correspondence, but all the others - R1 about 1.1.1.1/32, R2 - 2.2.2.2/32, etc. All of these messages are blazing fast across the MPLS network, building dozens of LSPs. As a result, each LSR will know about all existing FECs and a corresponding LSP will be built.
Again on the gif above the process is not shown to the end, R1 then transfers information to R3, R3 to R4, R4 to R5.
And if we look at R5, we will see that for FEC 6.6.6.6/32 we do not have one output label, as expected, but 3:
Moreover, R6 itself will record the label for FEC 6.6.6.6, which it will receive from R5:
Inuse - correct - imp-nulltowards R6. But the other two of the ring are from R2 and R4. This is neither a mistake nor a loop - just R2 and R4 generated these labels for the FEC 6.6.6.6/32 routing table known to them.
Two questions arise:
1) How does he plan to use them? They are stupid. Answer: nothing. There cannot be such a situation in our network when 2.2.2.2 or 4.4.4.4 will be the next nodes on the way to 6.6.6.6 - IGP will not build this route. And that means the labels will not be used. It's just that LDP is stupid - its messages are scattered throughout the network, breaking through every crack. A smart LSR will decide what to use.
2) What about loops? Won't LDP messages run on the network until the TTL expires?
And here everything is simple - receiving a new Label Mapping Message does not initiate the creation of a new one - the received correspondence is simply written to the LDP table. That is, in our case, R5 has already come up with a label for FEC 6.6.6.6/32 once and sent it to its higher neighbors and it will not change until the LDP process reboots.
You may already have noticed that when setting up LDP, it is possible to enable Loop Detection functionality, but I’m in a hurry to reassure you - this is for networks where there is no TTL, for example, ATM. This functionality will switch LDP to DoD mode.
This is basic information on how LDP works.
In fact, everything here is very dependent on the manufacturer. In principle, LDP supports all kinds of labeling modes: DoD / DU, Independent Control / Ordered Control, and Conservative / Liberal Label Retention. This is not regulated by the RFC, therefore, each vendor is free to choose its own path.
For example, basically everyone uses DU for LDP, but at the same time in Juniper labels are distributed in an orderly manner, and in Cisco independently.
Huawei and Juniper select only LSR Loopback interfaces as FECs, and Cisco FEC is created for all entries in the routing table.
But all this is unlikely to somehow affect the real network.
The most important thing to understand about LDP is that it does not use dynamic routing protocols in its work - it is similar in principle to PIM DM : it floods the entire network with tags, but it relies on information from the LSR routing table. And if two labels for one FEC from different neighbors arrive on R1, then he will choose for LSP only the one received through the best interface before this FEC according to information from TM.
This means three things:
- You are free to choose the IGP that you like best, at least RIP.
- LDP always builds only one (best) route and cannot build, for example, a backup one.
- When the network topology changes, the LSP will rebuild in accordance with the updated routing table, that is, IGP must converge first, and only then the LSP will rise.
In general, after enabling LDP, traffic will go the same as without it, with the only difference being that MPLS tags appear.
Including LDP, like IP, it supports ECMP , just the hash calculation algorithms and, accordingly, the balancing may differ.
An interesting article by Ivan Pepelnyak on LDP and a video on how the protocol works.
LDP is described in RFC 5036 .
LDP practice
Remain true to the linkmeup network.
OSPF is running, routers see Loopbacks and each other, MPLS is turned off.
The initial configuration file.
To enable MPLS globally, you need to give two commands:
R1(config)#ip cef
R1(config)#mpls ipThe first one is already the de facto and de jure standard on almost any network equipment - it starts the CEF mechanism on the router, the second starts MPLS and LDP globally (it can also be given by default).
The Router ID (and in the more general (non-ciscian) LSR ID terminology) in MPLS is chosen plainly:
- Largest Loopback Interface Address
- If not, the largest IP address configured on the router.
Naturally, you should not trust automation - we will configure LSR ID manually:
R1(config)# mpls ldp router-id Loopback0 forceIf you do not add the “force” keyword , the Router ID will change only when you reinstall the LDP session. “Force” forces the router to change the Router ID forcibly and, if necessary (if it has changed), re-establishes the LDP connection.
Next, on the necessary interfaces, we give the mpls ip command :
R1(config)#interface FastEthernet 0/0
R1(config-if)#mpls ip
R1(config)#interface FastEthernet 0/1
R1(config-if)#mpls ipCisco here again uses its principle of lazy engineer - a minimum of effort on the part of staff. The mpls ip command includes on the LDP interface simultaneously with MPLS, whether we wish it or not. Similarly, the ip pim sparse-mode command enables IGMP on the interface, as I described in the article on multicast .
After activating the LDP, the router begins to probe the soil via UDP:
Verifications are sent to the multicast address 224.0.0.2.
Now we repeat all the same manipulations on R2
R2(config)#ip cef
R2(config)#mpls ip
R2(config)# mpls ldp router-id Loopback0 force
R2(config)#interface FastEthernet 0/0
R2(config-if)#mpls ip
R2(config)#interface FastEthernet 0/1
R2(config-if)#mpls ipand enjoy the result.
R2 is also looking for neighbors.
They learned about each other, and R2 raises the LDP session:
If interested, how do they establish a TCP connection
Now they are neighbors, which is easily verified by the show mpls ldp neighbor command .
And then one another tells the FEC label about its correspondences:
Вот тут уже видно детали — R1 передаёт сразу 12 FEC — по одной для каждой записи в своей таблице маршрутизации. В такой же ситуации Huawei или Juniper передали бы только шесть FEC — адреса Loopback-интерфейсов, потому что они по умолчанию считают за FEC только /32-префиксы.
В этом плане Cisco очень неэкономно относится к ресурсу меток.
Впрочем, это поведение можно изменить на любом оборудовании. В нашем случае может помочь команда mpls ldp advertise-labels.
Но как так, спросите вы? Разве достаточно иметь метки только в Loopback?
Если вспомнить о том, что мы рассматривали вначале статьи, что BGP префиксы не получают свои метки, и что метки нужны только для next-hop, то становится понятно, что меток для Loopback вполне хватит.
Для того чтобы добраться до других сетей внутри нашей AS, нам достаточно IGP.
=====================
Если в Cisco по умолчанию анонсируются метки для всех сетей (кроме полученных по BGP), то в Juniper, по умолчанию анонсируется только loopback.Схема
Все маршрутизаторы, кроме R5, это маршрутизаторы Juniper.
Для приведенной ниже конфигурации маршрутизатора R5, донастроить его так, чтобы настройки маршрутизатора Cisco, соответствовало настройкам по умолчанию в Juniper.Конфигурация R5ip cef ! interface Loopback0 ip address 5.5.5.5 255.255.255.255 ip router isis ! interface FastEthernet0/0 description to R4 ip address 10.0.45.5 255.255.255.0 ip router isis mpls ip ! interface FastEthernet0/1 description to R2 ip address 10.0.25.5 255.255.255.0 ip router isis mpls ip ! interface FastEthernet1/0 description to R6 ip address 10.0.56.5 255.255.255.0 ip router isis mpls ip ! router isis net 10.0000.0000.0005.00 ! mpls ldp router-id Loopback0 force
Подробности задачи тут.
=====================
So, R1 tells R2 that if it wants to send traffic for FEC 3.3.3.3 , it should use label 17 .
Note that the LDP on R3 has not yet been raised, that is, R1 announced the label for FEC 3.3.3.3, without waiting for it from R5, this indicates that Independent Control is being used.
And the fact that there was no explicit request from R2 for this FEC suggests that the mode is Downstrean unsolicited.
Further, the nodes will continue to monitor new neighbors using LDP Hello over UDP and exchange the LDP Keepalive already addressed:
Now, using the show mpls forwarding-table command, you can see which labels have been assigned for each FEC:
On the second line, FEC 3.3.3.3 is already considered, and we see that for it the local label is 17, that is, R1 will tell everyone that for FEC 3.3.3.3 the label is 17, which was in the dump.
But the outgoing tag or the output label - Untagged - this means that packets are forwarded with a clean IP (without any reservation to the stack). Moreover, Untagged means that between R1 and R3 there is no MPLS at all - that's right: we did not enable it on R3.
But with R2 (first line) the situation is different. Local label 16 is what R1 will transmit to everyone. And the day off is Pop tag. That is, when transferring a packet to R2, R1 must remove the label. In our case, this means that a pure IP will be transmitted (but in a more general case, only the top mark is removed). What is the difference with FEC 3.3.3.3? And the difference is that between R1 and R2 there is MPLS and what we see is the same PHP - Penultimate Hop Popping. The packet addressed to 2.2.2.2 will still be processed on R2, so in order not to produce entities beyond the required value, R1 will helpfully remove the mark.
And here an interesting question arises, how does R1 know that it is the penultimate of the Mohicans? After all, we said above that LDP does not use routing protocols, therefore, it cannot even know that the address 2.2.2.2 is configured on a directly connected R2 - it only sees that 2.2.2.2 is available through 10.0.12.2.
A traffic dump between R2 and R1 will help us answer this question:
And here the same label 3 pops up - implicit-null. Therefore, R2 reports that R1 must remove the top mark when transmitting the MPLS packet.
I want to repeat here - R1 will not transmit a packet with label 3 to R2 - it will transmit it without a top label. In our case, it will be just an IP packet. And label 3 never appears in the MPLS header.
And this label 3 is displayed in the MPLS switching table as a Pop Tag .
For nodes R5 and R6 we have labels, although MPLS was not included on them, but this is only because the route to them lies through R2, and R2 generated a FEC label match for them. In this case, packets on R6 will go with and without MPLS header between R1 and R2further.
Note that if Ordered Control was used, R2 would not be able to send a label for R5 and R6, and packets would only go over IP.
I propose to complete the configuration of MPLS + LDP on all elements of our modest network. The processes there are no different - the same Neighbor Discovery, Initialization, tag exchange, PHP.
The configuration template is as follows:
mpls ip
!
interface Loopback0
ip address 1.1.1.1 255.255.255.255
ip router isis
!
interface FastEthernet0/0
description to R2
ip address 10.0.12.1 255.255.255.0
ip router isis
mpls ip
!
interface FastEthernet0/1
description to R3
ip address 10.0.13.1 255.255.255.0
ip router isis
mpls ip
!
router isis
net 10.0000.0000.0001.00
!
mpls ldp router-id Loopback0 forceLDP configuration file.
And after that, let's look again at the MPLS switching table on R1 :
Tags have already appeared for all FECs.
Let's go through the LSP from R1 to R6 and see how the labels change along the path
R2:
R5:
So
1. When R1 receives an MPLS packet with label 21 , it must pass it to the Fa0 / 0 interface and change the label to 18 .
2. When R2 receives the MPLS packet with label 18 , it must pass it to the Fa0 / 0 interface and change the label to 20 .
3. When R5receives an MPLS packet with tag 20 , it must pass it to the Fa1 / 0 interface and remove the tag - PHP .
In this case, LSR do not even think about looking at something in the routing table or in ip cef - they simply juggle with labels.
The switching table that we have already seen with the show mpls forwarding table command is the LFIB ( Lable Forwarding Information Base ) - an almost common truth for data transfer is the Data Plane. But what about the Control Plane? It is unlikely that LDP knows as much? Surely he still has trump cards in his sleeve?
So it is:
For each FEC, we see here information about various labels:
local binding- that this LSR sends
remote binding to neighbors - that this LSR received from neighbors.
In the illustration above you can see the word "tib". TIB is the Tag Information Base , which is correctly called the Label Information Base - LIB.
This is a relic of the TDP who died in the Bose , the progenitor of LDP.
Note that everywhere 2 remote bindings are two ways to get tags. For example, up to R2 can be reached directly from R1, or via R3-R4-R5-R2.
That is, understand yes? Not only does he make FEC from each entry in the routing table, so this scoundrel also uses the Liberal Retention Mode to hold labels.
Let's summarize: by default, LDP in Cisco works in the following modes:
- DU
- Independent control
- Liberal retention mode
- All entries in the routing table are selected as FEC
In short, his bounties know no bounds.
There is also the show mpls ip binding command . It shows something similar and, in addition, allows you to quickly find out which path is currently active, that is, how the LSP is built:
And the last, perhaps, the question that arises in connection with all these LSPs is when the router itself is an Ingress LSR, as it understands that need to do with packages, how to choose LSP?
And for this, you’ll have to look into IP CEF. In general, it is the Ingress LSR that bears the whole burden of processing the packet, determining the FEC, and assigning the correct labels.
Then you and Next Hop and the output interface and output label
And here you should already notice that in LDP the concepts of LER, Ingress LSR, Egress LSR are not the role of any particular nodes or a characteristic of the location of a node in a network. They are inseparable from FEC and LSP, individual for them. That is, for each specific FEC, there is one or more Egress LSRs and many Ingress LSRs (usually all routers) to which the LSPs lead.
Even say so, the concepts of LER arise when we talk about a specific LSP, then we can say who is Ingress, who is Egress.
MPLS and BGP
So far we have talked about how MPLS interacts with IGP protocols. We made sure that there was nothing complicated about it and that the settings were also quite simple.
But the most interesting thing is the interaction of MPLS with BGP. In this issue, we will only slightly touch on this topic. But in the following, we’ll talk in more detail about what role BGP plays and how we can use it and MPLS to organize different types of VPNs.
Now we need to understand how MPLS and BGP interact at the most basic level.
The main difference between BGP and IGP is that MPLS does not create labels for BGP routes. If you recall how many routes BGP transmits, it becomes clear that this is a very good idea. How then to combine MPLS and BGP?
Everything is simple:
- создаем метки только для адресов, которые будут указаны как next-hop для маршрутов, которые мы получаем по BGP (тут надо не забыть про next-hop-self для IBGP-соседей).
- Когда нашему Ingress LSR понадобится передать пакеты по маршруту, который был получен по BGP, отправляем их к next-hop, который указан в маршруте и используем ту метку, которая была создана для него.
Now, in order to configure BGP on each router in our AS, we can only configure it on the edge routers to which clients or other providers are connected.
Let's look at an example of a network:
If we need to get from R1 to Filkin Certificate networks, we see that they are accessible through R6 and “fly through” MPLS to address 6.6.6.6. And when we get to R6, he already knows where to go next. It will be similar and vice versa, in Balagan Telecom.
The configuration for this circuit and a couple of commands with information output can be found here .
=====================
В сети настроены MPLS и OSPF. MPLS настроен во всей сети, кроме соединения между R7 и R1.
Между маршрутизаторами R1-R2-R3-R4-R5-R6 трафик должен передаваться силами MPLS.
В сети также настроен BGP, который работает между R1 и R6.
Для маршрутов BGP не генерируются метки.
Для того чтобы R1 мог добраться до маршрутов, которые получены по BGP от R6, пакеты передаются средствами MPLS до IP-адреса, который указан как next-hop в маршрутах BGP.
Сейчас с R7 недоступен маршрут, который анонсируется по BGP маршрутизатором R6.
Задание:
Восстановить работу сети, чтобы с R7 пинговался адрес 100.0.0.1.
Ограничения:
Нельзя менять настройки BGP.Схема
Подробности задачи и конфигурации узлов тут.
=====================
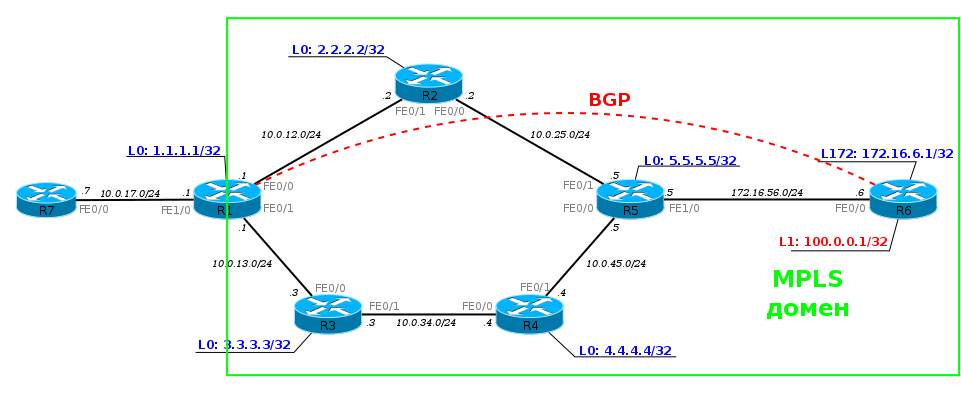
RSVP-TE
LDP is good. It works simply and clearly. But there is such technology as MPLS TE - Traffic Engineering. And she does not have the best route that LDP can provide.
Traffic management implies that you can direct traffic between nodes as you like, given various restrictions.
For example, in our network, the client has two points of connection for its nodes - on R1 and on R6. And between them, he asks for a VPN with a guaranteed channel width of 100 Mb / s. But at the same time, in our network, we also use regular broadband video drivers from VKontakte and a dozen other clients who rent a VPN, but they do not need to reserve a band.
If you do not intervene in this situation, somewhere on R2 there may be an overload, and 100 Mb / s for an expensive client will not get.
MPLS TE allows you to go through the entire network from the sender to the recipient and reserve resources on each node. If you are familiar with the IntServ concept, then yes, it is this one - to organize QoS along the entire path, instead of allowing each router to decide for a passing packet.
Actually, RSVP ( Resource ReSerVation Protocol ) was originally (in 1993) and was conceived for organizing IntServ in IP networks. He had to convey information about QoS for a particular data stream to each node and make it reserve resources.
In a first approximation, it works simply.
1) The source node wants to send a data stream at a speed of 5 Mb / s. But before that, he sends an RSVP request to reserve the band to the receiver - Path Message . This message contains some stream identifiers, by which the node can then identify the ownership of the received IP packets to the stream, and the required bandwidth.
2) The Path message is transmitted from node to node to the receiver itself. Where to send it is determined based on the routing table.
3) Each router, having received Path, checks its resources. If he has enough free bandwidth, he adjusts his internal algorithms so that the stream packets are processed properly and there is always enough bandwidth.
4) If he does not have the necessary 5 Mb / s (occupied by other threads), he refuses to allocate resources and returns the corresponding message to the sender.
5) The Path packet reaches the receiver of the stream, it sends a Resv message back , confirming the allocation of resources along the entire path.
6) The original sender, having received Resv, understands that everything is ready for him, and he can send data.
Actually, under these four simple steps are much more complex processes, but we are not interested.
But what we are interested in is the RSVP extension for Traffic Engineering , or, more simply, RSVP TE , which was developed specifically for MPLS TE.
Its task is the same as that of LDP - to distribute labels between LSRs and eventually compile LSPs from the receiver to the sender. But now, as you already understood, there are nuances - the LSP must satisfy certain conditions.
RSVP TE allows you to build the primary and secondary LSPs, reserve resources on all nodes, detect network crashes, build workarounds in advance, make fast traffic redirection, and avoid channels that physically go along one path.
But we will discuss all this in an article on MPLS TE through a couple of issues. Today, however, we will focus on the principles according to which RSVP TE builds an LSP.
From the change of protocol does not change that the LSP is unidirectional, respectively, and resources will be reserved only in one direction. If you want something else, create a reverse LSP.
To begin with, we will discard the resource reservation functionality - let our task only be to create LSPs, i.e. distribute labels between LSRs.
To make this possible, the standard RSVP is expanded by adding several objects. Consider the simplest option.
0) R1 needs LSP before FEC 6.6.6.6/32. It looks like the Tunnel interface on R1, which has a destination address of 6.6.6.6 and type Traffic Engineering.
1) It sends an RSVP Path message in the direction of 6.6.6.6. A new object appears in this message - Label Request . The Path message provokes the node to allocate a label for this FEC — that is, it is a label request.
2) The next node forms a new Path message and also sends it to 6.6.6.6. Etc.
3) Path reaches Egress LSR. He sees that the packet is addressed to him, selects the label and sends a Resv message to the source. The latter also added a new object - Label . In it, Egress LSR passes its label for this FEC to the penultimate, penultimate penultimate last, etc.
4) Resv reaches the source, distributing labels along the path. In this way, the LSP is created, and the source is notified that everything is ready.
Labels are requested downstream (Path message from sender to recipient), and transmitted upstream (Resv message from recipient to sender).
At the same time, pay your attention to the fact that this is the most Downstream on Demand + Ordered Control. Path acts as a label request, and Resv goes from the recipient step by step, and until the label is sent by a subordinate LSR, the parent cannot send it to its neighbors.
Stop! We said that RSVP TE, unlike LDP, allows you to build as we want, without being tied to the routing table and IGP, but here it’s just “in the direction of 6.6.6.6”.
And here we come close to the fundamental difference between RSVP TE and LDP. RSVP TE is very closely connected with dynamic routing protocols, it does not just rely on the result of their work - it adapts them for itself, exploits in the literal sense of the word.
At first, only protocols based on link-state algorithms, that is, OSPF and ISIS, are suitable.
Secondly , OSPF and ISIS are expanding with the introduction of new elements in the protocols. So in OSPF there is a new type of LSA - Opaque LSA , and in ISIS - new TLV IS Neighbor and IP Reachability .
Thirdly , to calculate the path between Ingress LSR and Egress LSR, a special modification of the SPF algorithm is used - CSPF ( Constrained Shortest Path First ).
Now in more detail.
The Path message, in principle, is transmitted unicast addressfully. That is, the sender's address is R1, and the recipient's address is 6.6.6.6. And it could have come just by the routing table.
But in fact, Path is transmitted over the network not like a FIB per capita will be put on each node, because then we will not be able to provide backups or search for backup routes. No, he follows a certain path.
This path is determined on Ingress LSR to the accuracy of each node.
To build this path, RSVP TE needs to know the network topology. You see, yes, what are we approaching? RSVP itself does not bother to study it, and why, when it can be obtained from OSPF or ISIS. And then it becomes obvious why RIP, IGRP and EIGRP are not suitable here - after all, they do not study the topology, the maximum that they are capable of is the Feasible Successor.
But the classic SPF algorithm at the input has a network topology, and at the output it can only give the fastest route taking into account metrics and AD, although it can calculate all the possible ways.
And here comes the CSPF. It is this algorithm that can calculate the best path, the second highest priority path, and, for example, some other backup one, in order to at least somehow get through China .
That is, the RSVP TE may ask the CSPF to calculate for it some path between the two nodes.
Well, well, why change the IGP protocols themselves for this? Voooot. And this is Constraints - restrictions. RSVP TE can make requirements for the path — bandwidth, minimum available width, line type, or even the nodes through which the LSP must pass. So, so that the CSPF can take into account the restrictions, it must know about them and about the available resources on the nodes of the entire network. The input data for it are the restrictions specified in the tunnel and the network topology - it will be logical if the topology contains, in addition to prefixes and metrics, information about available resources.
For this purpose, routers exchange among themselves through messages OSPF and ISIS not only basic information, but also the characteristics of lines, interfaces, etc. Just in new types of messages this information is transmitted.
For example, in OSPF, 3 additional LSA types were introduced for this:
- Type 9 - link-local scope
- Type 10 - area-local scope
- Type 11 - AS scope
Opaque means opaque (for OSPF). These are special LSA types that are not taken into account in OSPF when calculating the routing table. They can use any other protocols for their needs. So TE uses them to build its topology (it is called TED - Traffic Egineering Database ). But theoretically, they are not assigned to TE - if you write your application for routers, which will require the exchange of some information about the topology, you can also use Opaque LSA.
ISIS works the same way. New posts: IS-IS TLV 22 (Extended IS Reachability), 134 (Traffic Engineering router ID), 135 (Extended IP reachability).
So, let's take a closer look at this whole process.
0)On R1, we enabled MPLS TE and configured ISIS (OSPF) to transmit data to support TE. Routers exchanged information about available resources. At this step, TED is formed. RSVP is silent.
1) We created a tunnel interface, where we indicated its type (Traffic Engineering), destination address (6.6.6.6) and the necessary resource requirements. LSR starts CSPF: you need to calculate the shortest path from R1 to 6.6.6.6 taking into account the imposed conditions. At this step, we get the optimal path - a list of nodes from source to destination (R2, R5, R6).
2) The result of the previous step is fed by RSVP and transformed into an ERO object. R1 compiles the RSPV Path, which naturally adds the ERO. The packet destination is 6.6.6.6. In addition, there is also a Label Request object informing that upon receipt of a packet it is necessary to select a label for this FEC (6.6.6.6/32).
ERO - Explicit Route Object - a special RSVP Path message object. It contains a list of nodes through which this message is destined to pass.
3) The RSVP Path message is transmitted in a special way - not according to the routing table, but according to the ERO list. In our case, the best IGP route and ERO match, so the packet is sent to R2.
4) R2, having received the RSVP Path, checks for the availability of the required resources and, if any, allocates the MPLS label for FEC 6.6.6.6/32. The old Path package is destroyed and a new one is created, and the ERO object is changed - R2 itself is removed from it. This is done so that the next node does not try to return the packet to R2. That is, the new ERO already looks like this: (R5, R6). In accordance with it, R2 sends the updated Path to R5.
5)R5 performs similar operations: it checks the resources, selects the label, removes itself from the ERO, re-creates the Path package and passes it to the interface through which the next ERO object is known - R6.
6) R6, having received the package, understands that he is the culprit of all the turmoil. It destroys the Path, selects the label for FEC 6.6.6.6, and inserts it as a Label into the Resv response message.
Note that before this step, the labels only stood out, but did not spread, but now they begin to be announced to the LSRs that requested them.
7) The RESV message advances to R1 (Ingress LSR), leaving behind the growing tail of the LSP. Resv should go through the same nodes as Path, but in reverse order.
8)In the end, the LSP from R1 to 6.6.6.6 is formed. Data on it can be transmitted only from R1 to R6. To allow data transfer in the opposite direction, you need to create a tunnel interface on R6 with the destination address 1.1.1.1 - all actions will be exactly the same.
The question arises - why is the destination of the Path 6.6.6.6 packet, if it is transmitted node by node and their addresses are known? This question is not idle - it leads us to one important feature. An ERO may not actually contain all the nodes from Ingress LSR to Egress LSR — some may be omitted. Therefore, each LSR must know where the message ultimately goes. And this may not happen because Ingress LSR is too lazy to calculate the whole way.
The problem is in the IGP zones. You know that both OSPF and ISIS have this concept in order to simplify routing. In large networks (hundreds and thousands of nodes), the problem of broadcasting service packages and the calculation of a huge number of combinations by the SPF algorithm arise. Therefore, one global domain is divided into routing zones.
And the whole snag is that if inside the IGP zone it is a link-state protocol, then between them - it is a real distance-vector network topology is built only inside the zone, any internal routers do not know how the others are arranged zones - they are only informed that in order to get into a particular network, they need to send packets to a specific ABR .
In other words, if your network is divided into zones, then there are difficulties with MPLS TE - the CSPF cannot calculate the whole path, because in its topology, the destination from another zone is a cloud, not a specific node.
And here the Explicit Path comes to the rescue (not to be confused with the ERO object). This is the most straightforward way to control the way LSP is built - the administrator can independently and explicitly specify the nodes through which the LSP should be laid. Ingress LSR must follow these guidelines exactly. This brings the CSPF algorithm a little more variety.
How does the Explicit Path help break through the zone? Let's take an example.
We take and indicate that there must be intermediate points:
Explicit-path: R1, R3, R5.
When we feed this Explicit Path to CSPF, it builds the piece that can, that is, within Area 0: from R1 to R3.
What he counts is entered in the ERO, plus another node from the Explicit-path is added to it - R5. It turns out: R1, R2, R3. Path is sent over the network according to ERO, comes to R3. He sees that, in general, he is not the addressee, but only a transshipment point, takes the specified conditions for the required resources and the address of the recipient node from the Explicit-path and starts CSPF. The latter gives a complete list of nodes to the destination (R3, R4, R5), which is converted to ERO, and then everything happens according to the standard scenario.
That is, if Ingress LSR and Egress LSR are in different zones, the path calculation is performed separately for each zone, and the reference point is ABR.
It should be understood that the Explicit Path is used not only for this case, but it is generally a convenient tool, because you can explicitly specify how to lay the LSP or vice versa, through which nodes it is not necessary to lay the LSP.
We will touch on this and much more in the issue devoted to MPLS TE.
Меня могут упрекнуть в лукавстве, сказав, что не настолько уж и обязателен Link-State IGP. Ну вот хочется на моноцисочной сети запустить EIGRP, сил нет. Или вообще некрофильные позывы заставляют откопать RIP. И что теперь? Отказаться от TE?
В общем есть спасение, но только на оборудовании Cisco — называется оно Verbatim.
Ведь для чего нам нужен Link-State протокол? Он собирает информацию о топологии TE, а CSPF строит путь от Ingress LSR до Egress LSR. Таак. Отлично. А что если мы возьмём и состряпаем Explicit Path, где перечислим все узлы один за другим? Ведь тогда не надо ничего считать.
На самом деле, как бы подробно вы ни составили явный путь, он всё равно будет передан CSPF.
Но такое поведение можно отключить. Как раз для случаев, описанных выше.
The following command will help:Router(config-if)# tunnel mpls traffic-eng path-option 1 explicit name test verbatim
That is, this path will be taken as knowingly true without any checks and recalculations of the CSPF.
Such a scenario is a big question, and its advantages are very illusory. However, there is an opportunity, and don’t tell me later that I didn’t tell you about it.
RSVP TE Practice
We needed the mpls ip command for LDP to work. Now it is no longer needed - we delete it and start from scratch .
Now we need mpls traffic-eng tunnels . It globally includes support for TE tunnels and RSVP TE itself:
R1(config)#mpls traffic-eng tunnels You must also enable the same on the interfaces:
R1(config)# interface FastEthernet 0/0
R1(config-if)# mpls traffic-eng tunnels
R1(config)# interface FastEthernet 0/1
R1(config-if)# mpls traffic-eng tunnels Nothing is happening yet. RSVP is silent.
Now we will expand the IGP to transmit TE data. In our example, we use ISIS:
R1(config)#router isis
R1(config-router)# metric-style wide
R1(config-router)# mpls traffic-eng router-id Loopback0
R1(config-router)# mpls traffic-eng level-2
Enabling extended label mode is mandatory, otherwise TE will not work.
Set LSR-ID, as we did in LDP,
You need to set a specific ISIS level, otherwise TE will not work.
If you suddenly use OSPF
R1 (config) # mpls traffic-eng area 0
R1 (config) router # mpls traffic-eng router-id Loopback0
R1 (config) router # mpls traffic-eng router-id Loopback0
These steps need to be repeated on other routers.
Immediately after this, ISIS begins to exchange information about TE:
As you can see, information about LSR-ID is transmitted, extended information about neighbors (which support TE), extended information about interfaces.
At this point, a TED is formed.
You can see the topology in ISIS: #show isis database verbose
RSVP is silent for now.
Now configure the TE tunnel.
R1(config)# interface Tunnel1
R1(config-if)# ip unnumbered Loopback0
R1(config-if)# tunnel destination 6.6.6.6
R1(config-if)# tunnel mode mpls traffic-eng
R1(config-if)# tunnel mpls traffic-eng path-option 10 dynamicTunnel interfaces are a very universal thing on routers. They can be used for L2TP, GRE, IPIP and, as you can see, for MPLS TE.
ip unnumbered Loopback0 means that the starting point of the tunnel should be the Loopback0 interface address.
tunnel destination 6.6.6.6 - a universal command for tunnel interfaces, determines the termination point, the end of the tunnel.
tunnel mode mpls traffic-eng - sets the type. It is here that the tunnel operation algorithm is determined, how to build it.
tunnel mpls traffic-eng path-option 10 dynamic - this command allows CSPF to build a path dynamically, without specifying intermediate nodes.
If before that you did everything correctly, then the tunnel interface should rise:
%LINEPROTO-5-UPDOWN: Line protocol on Interface Tunnel1, changed state to upWhat happened?
R1 sent Path.
Dump removed on line R1-R2.
We are interested in the destination address, ERO and Label Request objects.
The destination address is 6.6.6.6, as configured in the tunnel.
Explicit Route:
10.0.12.2 -> 10.0.25.2 -> 10.0.25.5 -> 10.0.56.5 -> 10.0.56.6.
That is, the link address of the output interface and the link address of the next node are registered in it. Each LSR thus knows exactly which interface Path should be sent to.
There is no 10.0.12.1 in this ERO because R1 has already deleted it before sending.
The fact of having a Label Requestindicates that the LSR should allocate a label for this FEC.
However, he did not respond to this Path long - he sends updated further.
Resv below is sent after Resv came from a downstream LSR.
The same thing happens on R5: The
dump is filmed on line R2-R5.
Dump removed on line R2-R5.
So Path comes to R6. He sends back the RSPV Resv: The
dump is taken on line R5-R6.
The dump clearly shows that Resv is transmitted from node to node.
The Label object passes the label allocated to this FEC.
Note that R6 has assigned the label 0 - Explisit Null. In general, this is a normal situation - this is done so that the MPLS label between R5 and R6 is (for processing the packet according to the value in the EXP field, for example), but R6 immediately realized that it is necessary to reset the label 0 and process what is under it, but didn’t search the label table.
The problem is that there can be more than one in a label packet (for example, for a VPN), but according to RFC 3032 (and we mentioned this before) R5 must delete the entire label stack, no matter how many there are, and transfer the packet with one label 0. In this case, of course, everything will break.
In fact, the requirement that label 0 be the only one on the stack seems unjustified - there are no applications for this. Therefore, in RFC 4182This restriction has been removed. Now label 0 may not be the only one on the stack.
An interesting feature is PHP. Despite the fact that there is a special label for this - 3 - LSR will execute PHP even if it receives the label 0. Details from the same Pepelnyak .
R5 transfers Resv to R2, and R2 to R1.
Dump removed on line R1-R2.
Here, as you can see, the mark is already normal - 16.
======================
No matter how carefully you look at Resv, you will not see the path you need to go there, and the list of nodes should be in order to successfully distribute tags and build an LSP. How is this solved?
Details of the task are here .
=======================
Explicit path
Let's now try to change the path - traffic must go through R1-R3-R4-R5-R6.
As simple as that: you just need to configure explicit-path:
R1(config)# ip explicit-path name R1-to-R6-primary
R1(cfg-ip-expl-path)# next-address 10.0.13.3
R1(cfg-ip-expl-path)# next-address 10.0.34.4
R1(cfg-ip-expl-path)# next-address 10.0.45.5
R1(cfg-ip-expl-path)# next-address 10.0.56.6 And apply it to the tunnel interface:
R1(config)# Interface Tunnel 1
R1(config-if)# tunnel mpls traffic-eng path-option 5 explicit name R1-to-R6-primaryNotice that we set him a priority higher than the previous rule - 5 versus 10. That is, explicit-path will be used first, and if there are any problems with it, then R1 will try to build LSP dynamically (somehow).
The tunnel configuration now looks like this:
interface Tunnel1
ip unnumbered Loopback0
tunnel destination 6.6.6.6
tunnel mode mpls traffic-eng
tunnel mpls traffic-eng path-option 5 explicit name R1-to-R6-primary
tunnel mpls traffic-eng path-option 10 dynamic
no routing dynamicAnd this is how the Path message, containing a new ERO, looks like:
To view information about the tunnel, run the show mpls traffic-eng tunnels command :
You can also see this in the intermediate:
How the LSP is formed when there are resource requirements, what is Loose and Strict, FRR and make before break, Affinity and more, read through a couple of issues in the MPLS TE article.
RSVP-TE final configuration file .
Q&A
Q1: What is the difference between RSVP TE LSP and LDP LSP?
Strictly speaking, from the point of view of both the higher protocols and MPLS itself, there are no such concepts at all. LSP - it is LSP - it's just a way of switching labels.
We can distinguish the term CR-LSP (ConstRaint-based LSP) - it is built by RSVP TE. In this regard, the difference is that the CR-LSP meets the conditions specified in the tunnel interface.
Q2: How do Explicit Path and ERO compare?
If an Explicit Path is specified for the tunnel, then RSVP generates an ERO, taking into account the requirements of Explicit Path. In this case, even if you register each node in the Explicit-Path to Egress LSR, RSVP will still drive the data into the CSPF.
Q3: If one of the intermediate nodes does not support LDP (RSVP TE) or the protocol is turned off on the interface / platform, will the LSP be built so that, for example, it switches to IP on this node and then to MPLS again on the next one?
В случае RSVP TE Ingress LSR не будет иметь данного узла в TED и не сможет выстроить путь до Egress LSR, соответственно не пошлёт Path, соответственно, не будет и меток и LSP.
Трафик через туннель передаваться не сможет.
Если же речь о LDP, то ситуация интереснее. Например, если на R2 выключить LDP на интерфейсе FE0/0 (в сторону R5), то
1) на R1 будет метка для FEC 6.6.6.6/32. Причём их будет 2: одна через R2, другая — через R3, поскольку согласно таблице маршрутизации лучший — через R2, то и LSP будет лежать в сторону R2.
2) на R2 метка будет, но только одна — в сторону 1.1.1.1. Это не лучший путь, поэтому он не будет использован. То есть здесь LSP от R1 к FEC 6.6.6.6/32 прекращает своё существование.
3) на R5 метка для FEC 6.6.6.6/32 будет
That is, like, we get a torn LSP: {R1-R2, R5-R6}. But actually it is not. LSP for that and Label Switched so that the labels change on it all the way, and we get from R1 to R2 MPLS, from R2 to R5 IP, and from R5 to R6 again MPLS. LSP for FEC 6.6.6.6/32 is not here . Normal traffic will pass here, in principle, but if we talk about some MPLS applications, such as, for example, VPN, then this will not work.
Q4: Well, why do you need MPLS will be clear from the following articles - while this is generally some kind of artificial nonsense to complicate the life of an engineer, but why do I need MPLS TE? After all, traffic can be directed in the way I need using IGP metrics.
Начнём с того, что это тема будущих выпусков. Но…
Вообще говоря, если вы хотите определять путь, по которому пойдёт трафик, то это действительно можно сделать путём хитрой настройки стоимости линков, интерфейсов итд. Но обслуживание такой системы доставит вам те ещё хлопоты с одной стороны, а с другой у вас всё равно не получится направить два разных потока разными путями. То есть если стоит задача разгрузить сеть путём распределения трафика, то с помощью метрик вы просто перенесёте проблему с одного плеча на другое.
А вот если у вас будет несколько разных LSP и вы сможете направить в них трафик, то это пожалуйста. Хотя в плане простоты поддержки TE тоже вызывает вопросы.
Well, in general, if you need guaranteed channels of 40 Mb / s and 50 Mb / s for two clients, respectively, how will you track the utilization of the lines? Well, once you have calculated and configured in some miraculous way routing and QoS so as to provide the desired level of service, but suddenly you have 3 kilometers of optics cut off in three places at once and you can’t fix it for a week. And you even have three backup channels of 50 Mb / s, but the traffic of both clients popped into one place, spitting on all your formal SLAs .
Q5: So what is the difference between the labels Explicit Null and Implicit Null? Do I really need to know about them?
Нужно. Первоначально предполагается, что по сети MPLS пакет всегда коммутируется по меткам от первого до последнего LSR. А на последнем пролёте метка будет «0», чтоб Egress LSR сразу знал, что её нужно снять. Эта метка позволяет не потерять приоритет, заданный в поле TC заголовка MPLS, который копируется по мере передачи пакета по сети. В итоге даже последний маршрутизатор обработает данные в правильных очередях.
In the concept using the label “3” they decided to abandon unnecessary actions on the Egress LSR. If you don’t care about QoS (or you copied the priority, for example, in the DSCP field), then there is no urgent need for a transport label on the last flight - the main thing is to send it to the correct interface, and there Egress LSR will figure it out. If there was a clean IP packet, give it to the IP process, if there was any E1, transfer the stream to the desired interface, if the label stack, then lookup in LFIB and see what further actions should be taken.
Q6: For one FEC, will the LSR always allocate the same label to all its neighbors?
There is a concept of label space:
- interface label space
- slot label space
- platform label space
Если метки специфичны для каждого интерфейса, тогда для одного FEC в разные порты могут быть отправлены разные метки.
И наоборот — если метки специфичны для платформы (читай всего LSR), то маршрутизатор во все порты для одного FEC обязан отправить одинаковые метки.
В примерах ниже вы увидите, что у нас для одного FEC отправляются одинаковые метки разным соседям, но это ещё не говорит о том, как организовано пространство меток. Это вещь сугубо индивидуальная и завязана на аппаратном обеспечении.
It is important to understand that the MPLS technology does not regulate the label distribution protocol in any way, but the final results on a particular network may well differ when using different protocols. Parent protocols and applications use the LSP regardless of who it is or how it is built.
By the way, the scenario LPD over TE is often found in modern networks. In this case, RSVP-TE is used to organize transport and implement Traffic Engineering, and LDP to exchange VPN tags, for example.
Egress LSR, writing the first label in the MPLS header, defines the entire path of the packet. Intermediate routers simply change one label to another. Content can be completely anything. Just this multiprotocol allows MPLS to serve as the basis for a variety of VPN services.
useful links
- A great document for those who have a general idea of what MPLS is: MPLS for Dummies .
- The set of Russian translations of the RFC is not bad at all:
- Desperately recommend reading all of Jeff Doyle's publications . I sincerely envy his ability to explain complex things so simply even in English.
- Understanding the Role of FECs in MPLS
- Understanding MPLS Label Stacking
- Understanding Signaling in MPLS Networks
- Understanding MPLS Label Distribution
- Understanding MPLS Explicit and Implicit Null Labels
- Understanding MPLS CSPF
For the finishing touches to the article, thanks to JDima .
Thank you Natasha Samoilenko for the tasks and help in writing this article .
KDPV is drawn by Nina Dolgopolova - a wonderful artist and friend of the project.
Error checking and inaccuracy search conducted by Maxim the gluck