Tests that test tests
Or why they are not necessary.
Often, when you tell newbies about automatic testing, the same question pops up: “Who will test the tests themselves? We’ll have to write tests for tests, then tests for tests for tests ... ”Everyone loves recursion and even more loves to tell her interlocutor.
Strange, the question has never come across: “Who is testing the testers?” - in fact, the same problem is a side view.
But really, why is there no need to test the tests? (and testers)
To stop the imaginary recursion, you should perceive the tests as part of the project, and not as an entity external to it.
Tests are a good example of duplication, a method of increasing reliability by implementing multiple copies of a critical part of the system. The nuance is that in our case, duplication is controlled not by the operation of the resulting system, but by the accuracy of its formal model.
The following diagram should clarify the idea.
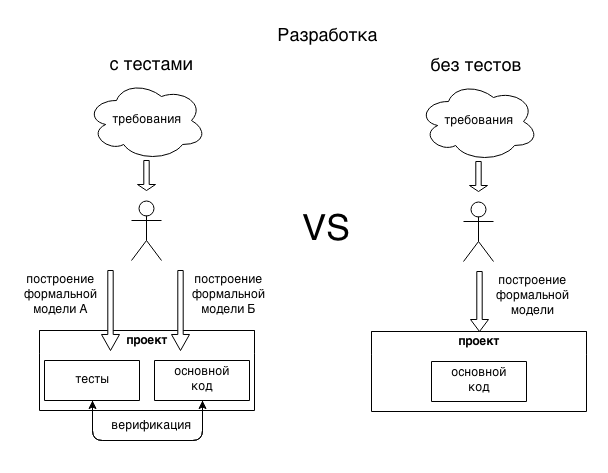
When we write code (no matter tests or functionality), we build a formal model of a piece of the real world. This model, of course, differs both from the real state of things in the universe (due to simplification) and from the ideal result that we want to get (due to errors and not understanding the ultimate goal).
At the same time, when writing tests and functionality, we look at the subject area from different angles, which leads to the appearance of two different models of the same subject area, exaggerating:
Thus, two models of the problem to be solved appear in the project, created according to different principles. Comparing their behavior (through running tests), we can identify mismatches in the models and eliminate them.
Accordingly, the tests check the code, the code checks the tests. Together, a more reliable model of the problem is obtained.
In fact, we can distinguish not two, but three models of the subject area:
All three models are built on different principles, which means that you can use this to determine whether a particular model belongs to an error: if two models say A and third B, then it is logical to assume that the third is wrong and that it contains the error.
During the work on the article, not a single test was harmed. Thanks for attention.
Often, when you tell newbies about automatic testing, the same question pops up: “Who will test the tests themselves? We’ll have to write tests for tests, then tests for tests for tests ... ”Everyone loves recursion and even more loves to tell her interlocutor.
Strange, the question has never come across: “Who is testing the testers?” - in fact, the same problem is a side view.
But really, why is there no need to test the tests? (and testers)
To stop the imaginary recursion, you should perceive the tests as part of the project, and not as an entity external to it.
Tests are a good example of duplication, a method of increasing reliability by implementing multiple copies of a critical part of the system. The nuance is that in our case, duplication is controlled not by the operation of the resulting system, but by the accuracy of its formal model.
The following diagram should clarify the idea.
When we write code (no matter tests or functionality), we build a formal model of a piece of the real world. This model, of course, differs both from the real state of things in the universe (due to simplification) and from the ideal result that we want to get (due to errors and not understanding the ultimate goal).
At the same time, when writing tests and functionality, we look at the subject area from different angles, which leads to the appearance of two different models of the same subject area, exaggerating:
- The functionality code describes the device model in terms of its internal mechanisms.
- The test code describes the model of the device, from the point of view of an external observer.
Thus, two models of the problem to be solved appear in the project, created according to different principles. Comparing their behavior (through running tests), we can identify mismatches in the models and eliminate them.
Accordingly, the tests check the code, the code checks the tests. Together, a more reliable model of the problem is obtained.
garden stone TDD
I take this opportunity to throw a stone in the garden of a classic TDD, whose followers preach fast cycles of switching between models: wrote a test, wrote functionality, repeated it.
Due to the frequent change of context, it is difficult to keep in the head the integral structure of each model (all the more, think it over well).
Therefore, I prefer the development of long runs:
The order (what to write first: tests or functionality) is not important - the main thing is that in the end two models are implemented. I usually start with a simpler one.
Due to the frequent change of context, it is difficult to keep in the head the integral structure of each model (all the more, think it over well).
Therefore, I prefer the development of long runs:
- designing parts of one model (any);
- implementation of the designed;
- designing a similar part of the second model;
- implementation of the designed;
The order (what to write first: tests or functionality) is not important - the main thing is that in the end two models are implemented. I usually start with a simpler one.
In fact, we can distinguish not two, but three models of the subject area:
- model in the functionality code;
- model in test code;
- model in the head of the developer.
All three models are built on different principles, which means that you can use this to determine whether a particular model belongs to an error: if two models say A and third B, then it is logical to assume that the third is wrong and that it contains the error.
During the work on the article, not a single test was harmed. Thanks for attention.